
minimax 3 什么时候开源?

以上

预计下周

will it fit 256GB unified or we can only dream ? <3 😀

will it fit 256GB unified or we can only dream ? <3 😀
Probably gotta keep dreaming. Even if it fits, we'd need about 60-70 GB just for the KV cache to handle a 1M context.

It has sparser attention than M2.7. I expect KV cache size to drop 10x compared to the M2.7
https://filecdn.minimax.chat/public/m3-msa-arch.png

will it fit 256GB unified or we can only dream ? <3 😀
It had 100T tokens of training data so my guess is 500b+ params

预计下周
特地注册个账号过来点赞👍

周一是个好日子

已经下周了。哈哈

预计下周
时间到了哦,快开源

will it be out this week?

时间差不多咯

waiting

waiting :)
😶🌫️

Can't write here :D
w8ing!

10天之期已到

im not movin from dis spot
怎么回事 啊
We are drafting a community-friendly license and plan to open-source M3 by this Friday evening. Thank you all for your support.
我们正在拟一个社区友好的 license,预计本周五晚上开源 M3. 感谢大家支持

I haven't seen MiniMax-M3 submit a model pull request to frameworks like Transformers or vLLM; how will the model be deployed after release?
We are drafting a community-friendly license and plan to open-source M3 by this Friday evening. Thank you all for your support.
我们正在拟一个社区友好的 license,预计本周五晚上开源 M3. 感谢大家支持
open-source? open-weights?

I haven't seen MiniMax-M3 submit a model pull request to frameworks like Transformers or vLLM; how will the model be deployed after release?
I was thinking for a minute maybe its because its the same architecture like m2.7 and m2.5 were then I remembered m3 is both multimodal and has a new sparse attention. So it has me wondering if we will get a massive delay in being able to properly run the model.

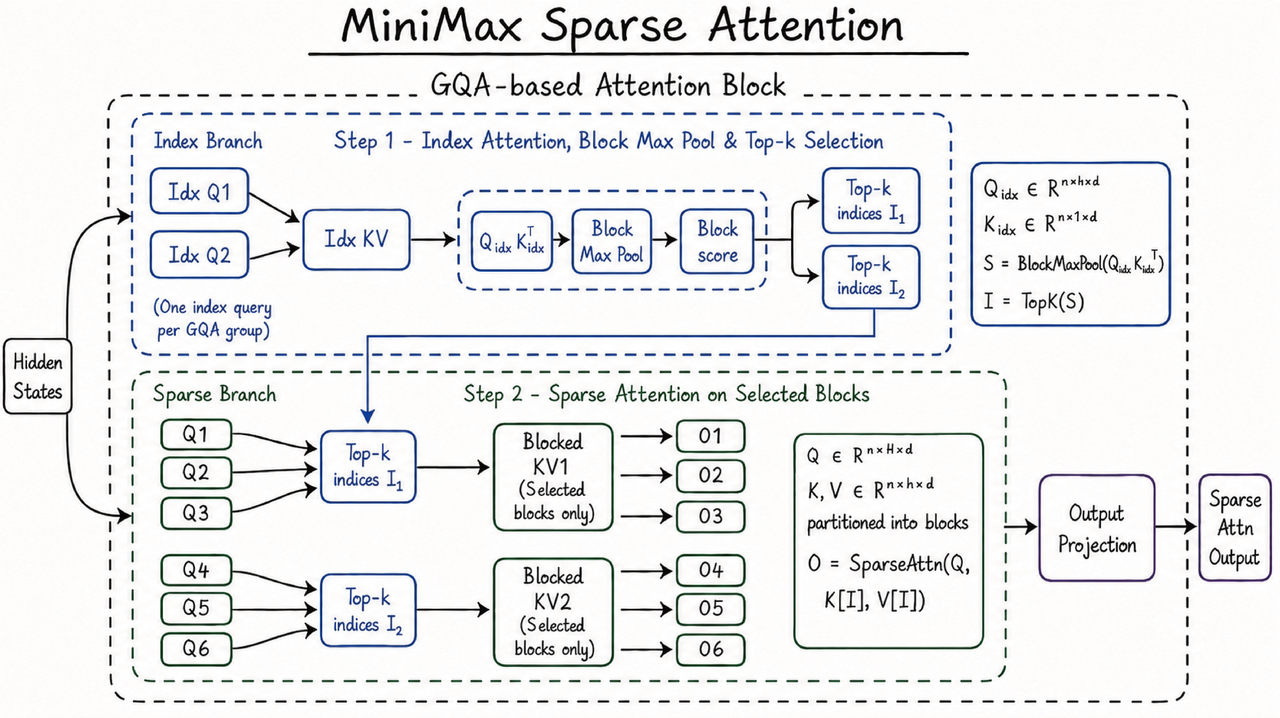{kind=link}
I haven't seen MiniMax-M3 submit a model pull request to frameworks like Transformers or vLLM; how will the model be deployed after release?
I was thinking for a minute maybe its because its the same architecture like m2.7 and m2.5 were then I remembered m3 is both multimodal and has a new sparse attention. So it has me wondering if we will get a massive delay in being able to properly run the model.
I anticipate that full support will not be available for several weeks, especially for vLLM.