
source
stringclasses 470
values | url
stringlengths 49
167
| file_type
stringclasses 1
value | chunk
stringlengths 1
512
| chunk_id
stringlengths 5
9
|
|---|---|---|---|---|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/seggpt.md | https://huggingface.co/docs/transformers/en/model_doc/seggpt/#seggptimageprocessor | .md | Size of the output image after resizing. Can be overridden by the `size` parameter in the `preprocess`
method.
resample (`PILImageResampling`, *optional*, defaults to `Resampling.BICUBIC`):
Resampling filter to use if resizing the image. Can be overridden by the `resample` parameter in the
`preprocess` method.
do_rescale (`bool`, *optional*, defaults to `True`):
Whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the `do_rescale`
parameter in the `preprocess` method. | 136_3_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/seggpt.md | https://huggingface.co/docs/transformers/en/model_doc/seggpt/#seggptimageprocessor | .md | parameter in the `preprocess` method.
rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
Scale factor to use if rescaling the image. Can be overridden by the `rescale_factor` parameter in the
`preprocess` method.
do_normalize (`bool`, *optional*, defaults to `True`):
Whether to normalize the image. Can be overridden by the `do_normalize` parameter in the `preprocess`
method.
image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_MEAN`): | 136_3_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/seggpt.md | https://huggingface.co/docs/transformers/en/model_doc/seggpt/#seggptimageprocessor | .md | method.
image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_MEAN`):
Mean to use if normalizing the image. This is a float or list of floats the length of the number of
channels in the image. Can be overridden by the `image_mean` parameter in the `preprocess` method.
image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_DEFAULT_STD`):
Standard deviation to use if normalizing the image. This is a float or list of floats the length of the | 136_3_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/seggpt.md | https://huggingface.co/docs/transformers/en/model_doc/seggpt/#seggptimageprocessor | .md | Standard deviation to use if normalizing the image. This is a float or list of floats the length of the
number of channels in the image. Can be overridden by the `image_std` parameter in the `preprocess` method.
do_convert_rgb (`bool`, *optional*, defaults to `True`):
Whether to convert the prompt mask to RGB format. Can be overridden by the `do_convert_rgb` parameter in the
`preprocess` method.
Methods: preprocess
- post_process_semantic_segmentation | 136_3_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/seggpt.md | https://huggingface.co/docs/transformers/en/model_doc/seggpt/#seggptmodel | .md | The bare SegGpt Model transformer outputting raw hidden-states without any specific head on top.
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
Parameters:
config ([`SegGptConfig`]): Model configuration class with all the parameters of the model. | 136_4_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/seggpt.md | https://huggingface.co/docs/transformers/en/model_doc/seggpt/#seggptmodel | .md | behavior.
Parameters:
config ([`SegGptConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
Methods: forward | 136_4_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/seggpt.md | https://huggingface.co/docs/transformers/en/model_doc/seggpt/#seggptforimagesegmentation | .md | SegGpt model with a decoder on top for one-shot image segmentation.
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
Parameters:
config ([`SegGptConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the | 136_5_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/seggpt.md | https://huggingface.co/docs/transformers/en/model_doc/seggpt/#seggptforimagesegmentation | .md | Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
Methods: forward | 136_5_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/ | .md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the | 137_0_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/ | .md | an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
--> | 137_0_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#overview | .md | The FastSpeech2Conformer model was proposed with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
The abstract from the original FastSpeech2 paper is the following: | 137_1_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#overview | .md | *Non-autoregressive text to speech (TTS) models such as FastSpeech (Ren et al., 2019) can synthesize speech significantly faster than previous autoregressive models with comparable quality. The training of FastSpeech model relies on an autoregressive teacher model for duration prediction (to provide more information as input) and knowledge distillation (to simplify the data distribution in output), which can ease the one-to-many mapping problem (i.e., multiple speech variations correspond to the same text) | 137_1_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#overview | .md | in output), which can ease the one-to-many mapping problem (i.e., multiple speech variations correspond to the same text) in TTS. However, FastSpeech has several disadvantages: 1) the teacher-student distillation pipeline is complicated and time-consuming, 2) the duration extracted from the teacher model is not accurate enough, and the target mel-spectrograms distilled from teacher model suffer from information loss due to data simplification, both of which limit the voice quality. In this paper, we | 137_1_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#overview | .md | teacher model suffer from information loss due to data simplification, both of which limit the voice quality. In this paper, we propose FastSpeech 2, which addresses the issues in FastSpeech and better solves the one-to-many mapping problem in TTS by 1) directly training the model with ground-truth target instead of the simplified output from teacher, and 2) introducing more variation information of speech (e.g., pitch, energy and more accurate duration) as conditional inputs. Specifically, we extract | 137_1_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#overview | .md | information of speech (e.g., pitch, energy and more accurate duration) as conditional inputs. Specifically, we extract duration, pitch and energy from speech waveform and directly take them as conditional inputs in training and use predicted values in inference. We further design FastSpeech 2s, which is the first attempt to directly generate speech waveform from text in parallel, enjoying the benefit of fully end-to-end inference. Experimental results show that 1) FastSpeech 2 achieves a 3x training | 137_1_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#overview | .md | enjoying the benefit of fully end-to-end inference. Experimental results show that 1) FastSpeech 2 achieves a 3x training speed-up over FastSpeech, and FastSpeech 2s enjoys even faster inference speed; 2) FastSpeech 2 and 2s outperform FastSpeech in voice quality, and FastSpeech 2 can even surpass autoregressive models. Audio samples are available at https://speechresearch.github.io/fastspeech2/.* | 137_1_5 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#overview | .md | This model was contributed by [Connor Henderson](https://huggingface.co/connor-henderson). The original code can be found [here](https://github.com/espnet/espnet/blob/master/espnet2/tts/fastspeech2/fastspeech2.py). | 137_1_6 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#-model-architecture | .md | FastSpeech2's general structure with a Mel-spectrogram decoder was implemented, and the traditional transformer blocks were replaced with conformer blocks as done in the ESPnet library. | 137_2_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2-model-architecture | .md |  | 137_3_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#conformer-blocks | .md |  | 137_4_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#convolution-module | .md | 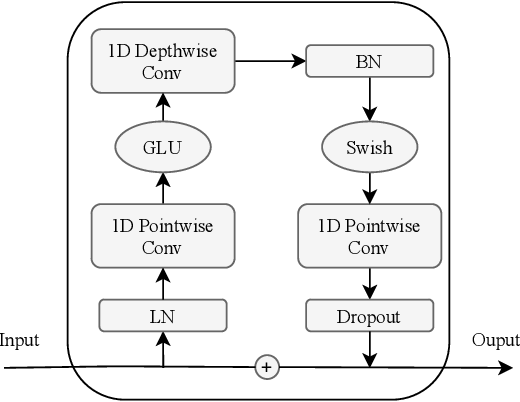 | 137_5_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#-transformers-usage | .md | You can run FastSpeech2Conformer locally with the 🤗 Transformers library.
1. First install the 🤗 [Transformers library](https://github.com/huggingface/transformers), g2p-en:
```bash
pip install --upgrade pip
pip install --upgrade transformers g2p-en
```
2. Run inference via the Transformers modelling code with the model and hifigan separately
```python
from transformers import FastSpeech2ConformerTokenizer, FastSpeech2ConformerModel, FastSpeech2ConformerHifiGan
import soundfile as sf | 137_6_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#-transformers-usage | .md | tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt")
input_ids = inputs["input_ids"]
model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer")
output_dict = model(input_ids, return_dict=True)
spectrogram = output_dict["spectrogram"]
hifigan = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
waveform = hifigan(spectrogram) | 137_6_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#-transformers-usage | .md | hifigan = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
waveform = hifigan(spectrogram)
sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)
```
3. Run inference via the Transformers modelling code with the model and hifigan combined
```python
from transformers import FastSpeech2ConformerTokenizer, FastSpeech2ConformerWithHifiGan
import soundfile as sf | 137_6_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#-transformers-usage | .md | tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt")
input_ids = inputs["input_ids"]
model = FastSpeech2ConformerWithHifiGan.from_pretrained("espnet/fastspeech2_conformer_with_hifigan")
output_dict = model(input_ids, return_dict=True)
waveform = output_dict["waveform"] | 137_6_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#-transformers-usage | .md | sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)
```
4. Run inference with a pipeline and specify which vocoder to use
```python
from transformers import pipeline, FastSpeech2ConformerHifiGan
import soundfile as sf
vocoder = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
synthesiser = pipeline(model="espnet/fastspeech2_conformer", vocoder=vocoder)
speech = synthesiser("Hello, my dog is cooler than you!") | 137_6_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#-transformers-usage | .md | speech = synthesiser("Hello, my dog is cooler than you!")
sf.write("speech.wav", speech["audio"].squeeze(), samplerate=speech["sampling_rate"])
``` | 137_6_5 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | This is the configuration class to store the configuration of a [`FastSpeech2ConformerModel`]. It is used to
instantiate a FastSpeech2Conformer model according to the specified arguments, defining the model architecture.
Instantiating a configuration with the defaults will yield a similar configuration to that of the
FastSpeech2Conformer [espnet/fastspeech2_conformer](https://huggingface.co/espnet/fastspeech2_conformer)
architecture. | 137_7_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | FastSpeech2Conformer [espnet/fastspeech2_conformer](https://huggingface.co/espnet/fastspeech2_conformer)
architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
hidden_size (`int`, *optional*, defaults to 384):
The dimensionality of the hidden layers.
vocab_size (`int`, *optional*, defaults to 78):
The size of the vocabulary. | 137_7_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | The dimensionality of the hidden layers.
vocab_size (`int`, *optional*, defaults to 78):
The size of the vocabulary.
num_mel_bins (`int`, *optional*, defaults to 80):
The number of mel filters used in the filter bank.
encoder_num_attention_heads (`int`, *optional*, defaults to 2):
The number of attention heads in the encoder.
encoder_layers (`int`, *optional*, defaults to 4):
The number of layers in the encoder.
encoder_linear_units (`int`, *optional*, defaults to 1536): | 137_7_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | The number of layers in the encoder.
encoder_linear_units (`int`, *optional*, defaults to 1536):
The number of units in the linear layer of the encoder.
decoder_layers (`int`, *optional*, defaults to 4):
The number of layers in the decoder.
decoder_num_attention_heads (`int`, *optional*, defaults to 2):
The number of attention heads in the decoder.
decoder_linear_units (`int`, *optional*, defaults to 1536):
The number of units in the linear layer of the decoder. | 137_7_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | decoder_linear_units (`int`, *optional*, defaults to 1536):
The number of units in the linear layer of the decoder.
speech_decoder_postnet_layers (`int`, *optional*, defaults to 5):
The number of layers in the post-net of the speech decoder.
speech_decoder_postnet_units (`int`, *optional*, defaults to 256):
The number of units in the post-net layers of the speech decoder.
speech_decoder_postnet_kernel (`int`, *optional*, defaults to 5):
The kernel size in the post-net of the speech decoder. | 137_7_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | speech_decoder_postnet_kernel (`int`, *optional*, defaults to 5):
The kernel size in the post-net of the speech decoder.
positionwise_conv_kernel_size (`int`, *optional*, defaults to 3):
The size of the convolution kernel used in the position-wise layer.
encoder_normalize_before (`bool`, *optional*, defaults to `False`):
Specifies whether to normalize before encoder layers.
decoder_normalize_before (`bool`, *optional*, defaults to `False`):
Specifies whether to normalize before decoder layers. | 137_7_5 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | decoder_normalize_before (`bool`, *optional*, defaults to `False`):
Specifies whether to normalize before decoder layers.
encoder_concat_after (`bool`, *optional*, defaults to `False`):
Specifies whether to concatenate after encoder layers.
decoder_concat_after (`bool`, *optional*, defaults to `False`):
Specifies whether to concatenate after decoder layers.
reduction_factor (`int`, *optional*, defaults to 1):
The factor by which the speech frame rate is reduced. | 137_7_6 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | reduction_factor (`int`, *optional*, defaults to 1):
The factor by which the speech frame rate is reduced.
speaking_speed (`float`, *optional*, defaults to 1.0):
The speed of the speech produced.
use_macaron_style_in_conformer (`bool`, *optional*, defaults to `True`):
Specifies whether to use macaron style in the conformer.
use_cnn_in_conformer (`bool`, *optional*, defaults to `True`):
Specifies whether to use convolutional neural networks in the conformer. | 137_7_7 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | Specifies whether to use convolutional neural networks in the conformer.
encoder_kernel_size (`int`, *optional*, defaults to 7):
The kernel size used in the encoder.
decoder_kernel_size (`int`, *optional*, defaults to 31):
The kernel size used in the decoder.
duration_predictor_layers (`int`, *optional*, defaults to 2):
The number of layers in the duration predictor.
duration_predictor_channels (`int`, *optional*, defaults to 256):
The number of channels in the duration predictor. | 137_7_8 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | duration_predictor_channels (`int`, *optional*, defaults to 256):
The number of channels in the duration predictor.
duration_predictor_kernel_size (`int`, *optional*, defaults to 3):
The kernel size used in the duration predictor.
energy_predictor_layers (`int`, *optional*, defaults to 2):
The number of layers in the energy predictor.
energy_predictor_channels (`int`, *optional*, defaults to 256):
The number of channels in the energy predictor. | 137_7_9 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | energy_predictor_channels (`int`, *optional*, defaults to 256):
The number of channels in the energy predictor.
energy_predictor_kernel_size (`int`, *optional*, defaults to 3):
The kernel size used in the energy predictor.
energy_predictor_dropout (`float`, *optional*, defaults to 0.5):
The dropout rate in the energy predictor.
energy_embed_kernel_size (`int`, *optional*, defaults to 1):
The kernel size used in the energy embed layer.
energy_embed_dropout (`float`, *optional*, defaults to 0.0): | 137_7_10 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | The kernel size used in the energy embed layer.
energy_embed_dropout (`float`, *optional*, defaults to 0.0):
The dropout rate in the energy embed layer.
stop_gradient_from_energy_predictor (`bool`, *optional*, defaults to `False`):
Specifies whether to stop gradients from the energy predictor.
pitch_predictor_layers (`int`, *optional*, defaults to 5):
The number of layers in the pitch predictor.
pitch_predictor_channels (`int`, *optional*, defaults to 256):
The number of channels in the pitch predictor. | 137_7_11 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | pitch_predictor_channels (`int`, *optional*, defaults to 256):
The number of channels in the pitch predictor.
pitch_predictor_kernel_size (`int`, *optional*, defaults to 5):
The kernel size used in the pitch predictor.
pitch_predictor_dropout (`float`, *optional*, defaults to 0.5):
The dropout rate in the pitch predictor.
pitch_embed_kernel_size (`int`, *optional*, defaults to 1):
The kernel size used in the pitch embed layer.
pitch_embed_dropout (`float`, *optional*, defaults to 0.0): | 137_7_12 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | The kernel size used in the pitch embed layer.
pitch_embed_dropout (`float`, *optional*, defaults to 0.0):
The dropout rate in the pitch embed layer.
stop_gradient_from_pitch_predictor (`bool`, *optional*, defaults to `True`):
Specifies whether to stop gradients from the pitch predictor.
encoder_dropout_rate (`float`, *optional*, defaults to 0.2):
The dropout rate in the encoder.
encoder_positional_dropout_rate (`float`, *optional*, defaults to 0.2):
The positional dropout rate in the encoder. | 137_7_13 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | encoder_positional_dropout_rate (`float`, *optional*, defaults to 0.2):
The positional dropout rate in the encoder.
encoder_attention_dropout_rate (`float`, *optional*, defaults to 0.2):
The attention dropout rate in the encoder.
decoder_dropout_rate (`float`, *optional*, defaults to 0.2):
The dropout rate in the decoder.
decoder_positional_dropout_rate (`float`, *optional*, defaults to 0.2):
The positional dropout rate in the decoder.
decoder_attention_dropout_rate (`float`, *optional*, defaults to 0.2): | 137_7_14 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | The positional dropout rate in the decoder.
decoder_attention_dropout_rate (`float`, *optional*, defaults to 0.2):
The attention dropout rate in the decoder.
duration_predictor_dropout_rate (`float`, *optional*, defaults to 0.2):
The dropout rate in the duration predictor.
speech_decoder_postnet_dropout (`float`, *optional*, defaults to 0.5):
The dropout rate in the speech decoder postnet.
max_source_positions (`int`, *optional*, defaults to 5000): | 137_7_15 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | The dropout rate in the speech decoder postnet.
max_source_positions (`int`, *optional*, defaults to 5000):
if `"relative"` position embeddings are used, defines the maximum source input positions.
use_masking (`bool`, *optional*, defaults to `True`):
Specifies whether to use masking in the model.
use_weighted_masking (`bool`, *optional*, defaults to `False`):
Specifies whether to use weighted masking in the model.
num_speakers (`int`, *optional*): | 137_7_16 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | Specifies whether to use weighted masking in the model.
num_speakers (`int`, *optional*):
Number of speakers. If set to > 1, assume that the speaker ids will be provided as the input and use
speaker id embedding layer.
num_languages (`int`, *optional*):
Number of languages. If set to > 1, assume that the language ids will be provided as the input and use the
languge id embedding layer.
speaker_embed_dim (`int`, *optional*): | 137_7_17 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | languge id embedding layer.
speaker_embed_dim (`int`, *optional*):
Speaker embedding dimension. If set to > 0, assume that speaker_embedding will be provided as the input.
is_encoder_decoder (`bool`, *optional*, defaults to `True`):
Specifies whether the model is an encoder-decoder.
Example:
```python
>>> from transformers import FastSpeech2ConformerModel, FastSpeech2ConformerConfig | 137_7_18 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerconfig | .md | >>> # Initializing a FastSpeech2Conformer style configuration
>>> configuration = FastSpeech2ConformerConfig()
>>> # Initializing a model from the FastSpeech2Conformer style configuration
>>> model = FastSpeech2ConformerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
``` | 137_7_19 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerhifiganconfig | .md | This is the configuration class to store the configuration of a [`FastSpeech2ConformerHifiGanModel`]. It is used to
instantiate a FastSpeech2Conformer HiFi-GAN vocoder model according to the specified arguments, defining the model
architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the
FastSpeech2Conformer
[espnet/fastspeech2_conformer_hifigan](https://huggingface.co/espnet/fastspeech2_conformer_hifigan) architecture. | 137_8_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerhifiganconfig | .md | [espnet/fastspeech2_conformer_hifigan](https://huggingface.co/espnet/fastspeech2_conformer_hifigan) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
model_in_dim (`int`, *optional*, defaults to 80):
The number of frequency bins in the input log-mel spectrogram.
upsample_initial_channel (`int`, *optional*, defaults to 512): | 137_8_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerhifiganconfig | .md | The number of frequency bins in the input log-mel spectrogram.
upsample_initial_channel (`int`, *optional*, defaults to 512):
The number of input channels into the upsampling network.
upsample_rates (`Tuple[int]` or `List[int]`, *optional*, defaults to `[8, 8, 2, 2]`):
A tuple of integers defining the stride of each 1D convolutional layer in the upsampling network. The
length of *upsample_rates* defines the number of convolutional layers and has to match the length of
*upsample_kernel_sizes*. | 137_8_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerhifiganconfig | .md | length of *upsample_rates* defines the number of convolutional layers and has to match the length of
*upsample_kernel_sizes*.
upsample_kernel_sizes (`Tuple[int]` or `List[int]`, *optional*, defaults to `[16, 16, 4, 4]`):
A tuple of integers defining the kernel size of each 1D convolutional layer in the upsampling network. The
length of *upsample_kernel_sizes* defines the number of convolutional layers and has to match the length of
*upsample_rates*. | 137_8_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerhifiganconfig | .md | length of *upsample_kernel_sizes* defines the number of convolutional layers and has to match the length of
*upsample_rates*.
resblock_kernel_sizes (`Tuple[int]` or `List[int]`, *optional*, defaults to `[3, 7, 11]`):
A tuple of integers defining the kernel sizes of the 1D convolutional layers in the multi-receptive field
fusion (MRF) module.
resblock_dilation_sizes (`Tuple[Tuple[int]]` or `List[List[int]]`, *optional*, defaults to `[[1, 3, 5], [1, 3, 5], [1, 3, 5]]`): | 137_8_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerhifiganconfig | .md | A nested tuple of integers defining the dilation rates of the dilated 1D convolutional layers in the
multi-receptive field fusion (MRF) module.
initializer_range (`float`, *optional*, defaults to 0.01):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
leaky_relu_slope (`float`, *optional*, defaults to 0.1):
The angle of the negative slope used by the leaky ReLU activation.
normalize_before (`bool`, *optional*, defaults to `True`): | 137_8_5 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerhifiganconfig | .md | The angle of the negative slope used by the leaky ReLU activation.
normalize_before (`bool`, *optional*, defaults to `True`):
Whether or not to normalize the spectrogram before vocoding using the vocoder's learned mean and variance.
Example:
```python
>>> from transformers import FastSpeech2ConformerHifiGan, FastSpeech2ConformerHifiGanConfig | 137_8_6 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerhifiganconfig | .md | >>> # Initializing a FastSpeech2ConformerHifiGan configuration
>>> configuration = FastSpeech2ConformerHifiGanConfig()
>>> # Initializing a model (with random weights) from the configuration
>>> model = FastSpeech2ConformerHifiGan(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
``` | 137_8_7 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerwithhifiganconfig | .md | This is the configuration class to store the configuration of a [`FastSpeech2ConformerWithHifiGan`]. It is used to
instantiate a `FastSpeech2ConformerWithHifiGanModel` model according to the specified sub-models configurations,
defining the model architecture.
Instantiating a configuration with the defaults will yield a similar configuration to that of the
FastSpeech2ConformerModel [espnet/fastspeech2_conformer](https://huggingface.co/espnet/fastspeech2_conformer) and
FastSpeech2ConformerHifiGan | 137_9_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerwithhifiganconfig | .md | FastSpeech2ConformerHifiGan
[espnet/fastspeech2_conformer_hifigan](https://huggingface.co/espnet/fastspeech2_conformer_hifigan) architectures.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
model_config (`typing.Dict`, *optional*):
Configuration of the text-to-speech model.
vocoder_config (`typing.Dict`, *optional*):
Configuration of the vocoder model. | 137_9_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerwithhifiganconfig | .md | Configuration of the text-to-speech model.
vocoder_config (`typing.Dict`, *optional*):
Configuration of the vocoder model.
model_config ([`FastSpeech2ConformerConfig`], *optional*):
Configuration of the text-to-speech model.
vocoder_config ([`FastSpeech2ConformerHiFiGanConfig`], *optional*):
Configuration of the vocoder model.
Example:
```python
>>> from transformers import (
... FastSpeech2ConformerConfig,
... FastSpeech2ConformerHifiGanConfig,
... FastSpeech2ConformerWithHifiGanConfig, | 137_9_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerwithhifiganconfig | .md | ... FastSpeech2ConformerConfig,
... FastSpeech2ConformerHifiGanConfig,
... FastSpeech2ConformerWithHifiGanConfig,
... FastSpeech2ConformerWithHifiGan,
... ) | 137_9_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerwithhifiganconfig | .md | >>> # Initializing FastSpeech2ConformerWithHifiGan sub-modules configurations.
>>> model_config = FastSpeech2ConformerConfig()
>>> vocoder_config = FastSpeech2ConformerHifiGanConfig()
>>> # Initializing a FastSpeech2ConformerWithHifiGan module style configuration
>>> configuration = FastSpeech2ConformerWithHifiGanConfig(model_config.to_dict(), vocoder_config.to_dict())
>>> # Initializing a model (with random weights)
>>> model = FastSpeech2ConformerWithHifiGan(configuration) | 137_9_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerwithhifiganconfig | .md | >>> # Initializing a model (with random weights)
>>> model = FastSpeech2ConformerWithHifiGan(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
``` | 137_9_5 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformertokenizer | .md | Construct a FastSpeech2Conformer tokenizer.
Args:
vocab_file (`str`):
Path to the vocabulary file.
bos_token (`str`, *optional*, defaults to `"<sos/eos>"`):
The begin of sequence token. Note that for FastSpeech2, it is the same as the `eos_token`.
eos_token (`str`, *optional*, defaults to `"<sos/eos>"`):
The end of sequence token. Note that for FastSpeech2, it is the same as the `bos_token`.
pad_token (`str`, *optional*, defaults to `"<blank>"`): | 137_10_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformertokenizer | .md | pad_token (`str`, *optional*, defaults to `"<blank>"`):
The token used for padding, for example when batching sequences of different lengths.
unk_token (`str`, *optional*, defaults to `"<unk>"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
should_strip_spaces (`bool`, *optional*, defaults to `False`):
Whether or not to strip the spaces from the list of tokens.
Methods: __call__
- save_vocabulary
- decode
- batch_decode | 137_10_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformermodel | .md | FastSpeech2Conformer Model.
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior. | 137_11_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformermodel | .md | and behavior.
Parameters:
config ([`FastSpeech2ConformerConfig`]):
Model configuration class with all the parameters of the model. Initializing with a config file does not
load the weights associated with the model, only the configuration. Check out the
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
FastSpeech 2 module.
This is a module of FastSpeech 2 described in 'FastSpeech 2: Fast and High-Quality End-to-End Text to Speech' | 137_11_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformermodel | .md | This is a module of FastSpeech 2 described in 'FastSpeech 2: Fast and High-Quality End-to-End Text to Speech'
https://arxiv.org/abs/2006.04558. Instead of quantized pitch and energy, we use token-averaged value introduced in
FastPitch: Parallel Text-to-speech with Pitch Prediction. The encoder and decoder are Conformers instead of regular
Transformers.
Methods: forward | 137_11_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerhifigan | .md | HiFi-GAN vocoder.
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters: | 137_12_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerhifigan | .md | and behavior.
Parameters:
config ([`FastSpeech2ConformerConfig`]):
Model configuration class with all the parameters of the model. Initializing with a config file does not
load the weights associated with the model, only the configuration. Check out the
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
Methods: forward | 137_12_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerwithhifigan | .md | The FastSpeech2ConformerModel with a FastSpeech2ConformerHifiGan vocoder head that performs text-to-speech (waveform).
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. | 137_13_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerwithhifigan | .md | etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`FastSpeech2ConformerWithHifiGanConfig`]):
Model configuration class with all the parameters of the model. Initializing with a config file does not
load the weights associated with the model, only the configuration. Check out the | 137_13_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/fastspeech2_conformer.md | https://huggingface.co/docs/transformers/en/model_doc/fastspeech2_conformer/#fastspeech2conformerwithhifigan | .md | load the weights associated with the model, only the configuration. Check out the
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
Methods: forward | 137_13_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/ | .md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the | 138_0_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/ | .md | an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
--> | 138_0_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#overview | .md | The X-CLIP model was proposed in [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
X-CLIP is a minimal extension of [CLIP](clip) for video. The model consists of a text encoder, a cross-frame vision encoder, a multi-frame integration Transformer, and a video-specific prompt generator.
The abstract from the paper is the following: | 138_1_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#overview | .md | *Contrastive language-image pretraining has shown great success in learning visual-textual joint representation from web-scale data, demonstrating remarkable "zero-shot" generalization ability for various image tasks. However, how to effectively expand such new language-image pretraining methods to video domains is still an open problem. In this work, we present a simple yet effective approach that adapts the pretrained language-image models to video recognition directly, instead of pretraining a new model | 138_1_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#overview | .md | approach that adapts the pretrained language-image models to video recognition directly, instead of pretraining a new model from scratch. More concretely, to capture the long-range dependencies of frames along the temporal dimension, we propose a cross-frame attention mechanism that explicitly exchanges information across frames. Such module is lightweight and can be plugged into pretrained language-image models seamlessly. Moreover, we propose a video-specific prompting scheme, which leverages video | 138_1_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#overview | .md | into pretrained language-image models seamlessly. Moreover, we propose a video-specific prompting scheme, which leverages video content information for generating discriminative textual prompts. Extensive experiments demonstrate that our approach is effective and can be generalized to different video recognition scenarios. In particular, under fully-supervised settings, our approach achieves a top-1 accuracy of 87.1% on Kinectics-400, while using 12 times fewer FLOPs compared with Swin-L and ViViT-H. In | 138_1_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#overview | .md | achieves a top-1 accuracy of 87.1% on Kinectics-400, while using 12 times fewer FLOPs compared with Swin-L and ViViT-H. In zero-shot experiments, our approach surpasses the current state-of-the-art methods by +7.6% and +14.9% in terms of top-1 accuracy under two popular protocols. In few-shot scenarios, our approach outperforms previous best methods by +32.1% and +23.1% when the labeled data is extremely limited.* | 138_1_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#overview | .md | Tips:
- Usage of X-CLIP is identical to [CLIP](clip).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/xclip_architecture.png"
alt="drawing" width="600"/>
<small> X-CLIP architecture. Taken from the <a href="https://arxiv.org/abs/2208.02816">original paper.</a> </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/VideoX/tree/master/X-CLIP). | 138_1_5 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#resources | .md | A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with X-CLIP.
- Demo notebooks for X-CLIP can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/X-CLIP).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource. | 138_2_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xclipprocessor | .md | Constructs an X-CLIP processor which wraps a VideoMAE image processor and a CLIP tokenizer into a single processor.
[`XCLIPProcessor`] offers all the functionalities of [`VideoMAEImageProcessor`] and [`CLIPTokenizerFast`]. See the
[`~XCLIPProcessor.__call__`] and [`~XCLIPProcessor.decode`] for more information.
Args:
image_processor ([`VideoMAEImageProcessor`], *optional*):
The image processor is a required input.
tokenizer ([`CLIPTokenizerFast`], *optional*):
The tokenizer is a required input. | 138_3_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xclipconfig | .md | [`XCLIPConfig`] is the configuration class to store the configuration of a [`XCLIPModel`]. It is used to
instantiate X-CLIP model according to the specified arguments, defining the text model and vision model configs.
Instantiating a configuration with the defaults will yield a similar configuration to that of the X-CLIP
[microsoft/xclip-base-patch32](https://huggingface.co/microsoft/xclip-base-patch32) architecture. | 138_4_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xclipconfig | .md | [microsoft/xclip-base-patch32](https://huggingface.co/microsoft/xclip-base-patch32) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
text_config (`dict`, *optional*):
Dictionary of configuration options used to initialize [`XCLIPTextConfig`].
vision_config (`dict`, *optional*):
Dictionary of configuration options used to initialize [`XCLIPVisionConfig`]. | 138_4_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xclipconfig | .md | vision_config (`dict`, *optional*):
Dictionary of configuration options used to initialize [`XCLIPVisionConfig`].
projection_dim (`int`, *optional*, defaults to 512):
Dimensionality of text and vision projection layers.
prompt_layers (`int`, *optional*, defaults to 2):
Number of layers in the video specific prompt generator.
prompt_alpha (`float`, *optional*, defaults to 0.1):
Alpha value to use in the video specific prompt generator. | 138_4_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xclipconfig | .md | prompt_alpha (`float`, *optional*, defaults to 0.1):
Alpha value to use in the video specific prompt generator.
prompt_hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
The non-linear activation function (function or string) in the video specific prompt generator. If string,
`"gelu"`, `"relu"`, `"selu"` and `"gelu_new"` `"quick_gelu"` are supported.
prompt_num_attention_heads (`int`, *optional*, defaults to 8): | 138_4_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xclipconfig | .md | prompt_num_attention_heads (`int`, *optional*, defaults to 8):
Number of attention heads in the cross-attention of the video specific prompt generator.
prompt_attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout probability for the attention layers in the video specific prompt generator.
prompt_projection_dropout (`float`, *optional*, defaults to 0.0):
The dropout probability for the projection layers in the video specific prompt generator. | 138_4_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xclipconfig | .md | The dropout probability for the projection layers in the video specific prompt generator.
logit_scale_init_value (`float`, *optional*, defaults to 2.6592):
The inital value of the *logit_scale* parameter. Default is used as per the original XCLIP implementation.
kwargs (*optional*):
Dictionary of keyword arguments.
Methods: from_text_vision_configs | 138_4_5 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xcliptextconfig | .md | This is the configuration class to store the configuration of a [`XCLIPModel`]. It is used to instantiate an X-CLIP
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the X-CLIP
[microsoft/xclip-base-patch32](https://huggingface.co/microsoft/xclip-base-patch32) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the | 138_5_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xcliptextconfig | .md | Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 49408):
Vocabulary size of the X-CLIP text model. Defines the number of different tokens that can be represented by
the `inputs_ids` passed when calling [`XCLIPModel`].
hidden_size (`int`, *optional*, defaults to 512):
Dimensionality of the encoder layers and the pooler layer. | 138_5_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xcliptextconfig | .md | hidden_size (`int`, *optional*, defaults to 512):
Dimensionality of the encoder layers and the pooler layer.
intermediate_size (`int`, *optional*, defaults to 2048):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 8):
Number of attention heads for each attention layer in the Transformer encoder. | 138_5_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xcliptextconfig | .md | Number of attention heads for each attention layer in the Transformer encoder.
max_position_embeddings (`int`, *optional*, defaults to 77):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`, | 138_5_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xcliptextconfig | .md | The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` `"quick_gelu"` are supported.
layer_norm_eps (`float`, *optional*, defaults to 1e-5):
The epsilon used by the layer normalization layers.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02): | 138_5_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xcliptextconfig | .md | The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
initializer_factor (`float`, *optional*, defaults to 1):
A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
testing).
Example:
```python
>>> from transformers import XCLIPTextModel, XCLIPTextConfig | 138_5_5 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xcliptextconfig | .md | >>> # Initializing a XCLIPTextModel with microsoft/xclip-base-patch32 style configuration
>>> configuration = XCLIPTextConfig()
>>> # Initializing a XCLIPTextConfig from the microsoft/xclip-base-patch32 style configuration
>>> model = XCLIPTextModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
``` | 138_5_6 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xclipvisionconfig | .md | This is the configuration class to store the configuration of a [`XCLIPModel`]. It is used to instantiate an X-CLIP
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the X-CLIP
[microsoft/xclip-base-patch32](https://huggingface.co/microsoft/xclip-base-patch32) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the | 138_6_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xclipvisionconfig | .md | Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
hidden_size (`int`, *optional*, defaults to 768):
Dimensionality of the encoder layers and the pooler layer.
intermediate_size (`int`, *optional*, defaults to 3072):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
num_hidden_layers (`int`, *optional*, defaults to 12): | 138_6_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xclipvisionconfig | .md | num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
mit_hidden_size (`int`, *optional*, defaults to 512):
Dimensionality of the encoder layers of the Multiframe Integration Transformer (MIT).
mit_intermediate_size (`int`, *optional*, defaults to 2048): | 138_6_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xclipvisionconfig | .md | mit_intermediate_size (`int`, *optional*, defaults to 2048):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Multiframe Integration Transformer
(MIT).
mit_num_hidden_layers (`int`, *optional*, defaults to 1):
Number of hidden layers in the Multiframe Integration Transformer (MIT).
mit_num_attention_heads (`int`, *optional*, defaults to 8):
Number of attention heads for each attention layer in the Multiframe Integration Transformer (MIT). | 138_6_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xclipvisionconfig | .md | Number of attention heads for each attention layer in the Multiframe Integration Transformer (MIT).
image_size (`int`, *optional*, defaults to 224):
The size (resolution) of each image.
patch_size (`int`, *optional*, defaults to 32):
The size (resolution) of each patch.
hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`, | 138_6_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_doc/xclip.md | https://huggingface.co/docs/transformers/en/model_doc/xclip/#xclipvisionconfig | .md | The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"`, `"gelu_new"` and `"quick_gelu"` are supported.
layer_norm_eps (`float`, *optional*, defaults to 1e-5):
The epsilon used by the layer normalization layers.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02): | 138_6_5 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.