
source
stringclasses 470
values | url
stringlengths 49
167
| file_type
stringclasses 1
value | chunk
stringlengths 1
512
| chunk_id
stringlengths 5
9
|
|---|---|---|---|---|
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md | https://huggingface.co/docs/transformers/en/contributing/#sync-a-forked-repository-with-upstream-main-the-hugging-face-repository | .md | When updating the main branch of a forked repository, please follow these steps to avoid pinging the upstream repository which adds reference notes to each upstream PR, and sends unnecessary notifications to the developers involved in these PRs.
1. When possible, avoid syncing with the upstream using a branch and PR on the forked repository. Instead, merge directly into the forked main.
2. If a PR is absolutely necessary, use the following steps after checking out your branch:
```bash | 44_14_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/contributing.md | https://huggingface.co/docs/transformers/en/contributing/#sync-a-forked-repository-with-upstream-main-the-hugging-face-repository | .md | 2. If a PR is absolutely necessary, use the following steps after checking out your branch:
```bash
git checkout -b your-branch-for-syncing
git pull --squash --no-commit upstream main
git commit -m '<your message without GitHub references>'
git push --set-upstream origin your-branch-for-syncing
``` | 44_14_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/ | .md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the | 45_0_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/ | .md | an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
--> | 45_0_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#pipelines-for-inference | .md | The [`pipeline`] makes it simple to use any model from the [Hub](https://huggingface.co/models) for inference on any language, computer vision, speech, and multimodal tasks. Even if you don't have experience with a specific modality or aren't familiar with the underlying code behind the models, you can still use them for inference with the [`pipeline`]! This tutorial will teach you to:
* Use a [`pipeline`] for inference.
* Use a specific tokenizer or model. | 45_1_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#pipelines-for-inference | .md | * Use a [`pipeline`] for inference.
* Use a specific tokenizer or model.
* Use a [`pipeline`] for audio, vision, and multimodal tasks.
<Tip>
Take a look at the [`pipeline`] documentation for a complete list of supported tasks and available parameters.
</Tip> | 45_1_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#pipeline-usage | .md | While each task has an associated [`pipeline`], it is simpler to use the general [`pipeline`] abstraction which contains
all the task-specific pipelines. The [`pipeline`] automatically loads a default model and a preprocessing class capable
of inference for your task. Let's take the example of using the [`pipeline`] for automatic speech recognition (ASR), or
speech-to-text.
1. Start by creating a [`pipeline`] and specify the inference task:
```py
>>> from transformers import pipeline | 45_2_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#pipeline-usage | .md | >>> transcriber = pipeline(task="automatic-speech-recognition")
```
2. Pass your input to the [`pipeline`]. In the case of speech recognition, this is an audio input file:
```py
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}
``` | 45_2_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#pipeline-usage | .md | {'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}
```
Not the result you had in mind? Check out some of the [most downloaded automatic speech recognition models](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&sort=trending)
on the Hub to see if you can get a better transcription.
Let's try the [Whisper large-v2](https://huggingface.co/openai/whisper-large-v2) model from OpenAI. Whisper was released | 45_2_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#pipeline-usage | .md | Let's try the [Whisper large-v2](https://huggingface.co/openai/whisper-large-v2) model from OpenAI. Whisper was released
2 years later than Wav2Vec2, and was trained on close to 10x more data. As such, it beats Wav2Vec2 on most downstream
benchmarks. It also has the added benefit of predicting punctuation and casing, neither of which are possible with
Wav2Vec2. | 45_2_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#pipeline-usage | .md | benchmarks. It also has the added benefit of predicting punctuation and casing, neither of which are possible with
Wav2Vec2.
Let's give it a try here to see how it performs. Set `torch_dtype="auto"` to automatically load the most memory-efficient data type the weights are stored in.
```py
>>> transcriber = pipeline(model="openai/whisper-large-v2", torch_dtype="auto")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac") | 45_2_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#pipeline-usage | .md | >>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
```
Now this result looks more accurate! For a deep-dive comparison on Wav2Vec2 vs Whisper, refer to the [Audio Transformers Course](https://huggingface.co/learn/audio-course/chapter5/asr_models). | 45_2_5 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#pipeline-usage | .md | We really encourage you to check out the Hub for models in different languages, models specialized in your field, and more.
You can check out and compare model results directly from your browser on the Hub to see if it fits or
handles corner cases better than other ones.
And if you don't find a model for your use case, you can always start [training](training) your own!
If you have several inputs, you can pass your input as a list:
```py
transcriber(
[ | 45_2_6 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#pipeline-usage | .md | If you have several inputs, you can pass your input as a list:
```py
transcriber(
[
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac",
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
]
)
``` | 45_2_7 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#pipeline-usage | .md | "https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
]
)
```
Pipelines are great for experimentation as switching from one model to another is trivial; however, there are some ways to optimize them for larger workloads than experimentation. See the following guides that dive into iterating over whole datasets or using pipelines in a webserver:
of the docs:
* [Using pipelines on a dataset](#using-pipelines-on-a-dataset)
* [Using pipelines for a webserver](./pipeline_webserver) | 45_2_8 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#parameters | .md | [`pipeline`] supports many parameters; some are task specific, and some are general to all pipelines.
In general, you can specify parameters anywhere you want:
```py
transcriber = pipeline(model="openai/whisper-large-v2", my_parameter=1)
out = transcriber(...) # This will use `my_parameter=1`.
out = transcriber(..., my_parameter=2) # This will override and use `my_parameter=2`.
out = transcriber(...) # This will go back to using `my_parameter=1`.
```
Let's check out 3 important ones: | 45_3_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#device | .md | If you use `device=n`, the pipeline automatically puts the model on the specified device.
This will work regardless of whether you are using PyTorch or Tensorflow.
```py
transcriber = pipeline(model="openai/whisper-large-v2", device=0)
```
If the model is too large for a single GPU and you are using PyTorch, you can set `torch_dtype='float16'` to enable FP16 precision inference. Usually this would not cause significant performance drops but make sure you evaluate it on your models! | 45_4_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#device | .md | Alternatively, you can set `device_map="auto"` to automatically
determine how to load and store the model weights. Using the `device_map` argument requires the 🤗 [Accelerate](https://huggingface.co/docs/accelerate)
package:
```bash
pip install --upgrade accelerate
```
The following code automatically loads and stores model weights across devices:
```py
transcriber = pipeline(model="openai/whisper-large-v2", device_map="auto")
``` | 45_4_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#device | .md | ```py
transcriber = pipeline(model="openai/whisper-large-v2", device_map="auto")
```
Note that if `device_map="auto"` is passed, there is no need to add the argument `device=device` when instantiating your `pipeline` as you may encounter some unexpected behavior! | 45_4_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#batch-size | .md | By default, pipelines will not batch inference for reasons explained in detail [here](https://huggingface.co/docs/transformers/main_classes/pipelines#pipeline-batching). The reason is that batching is not necessarily faster, and can actually be quite slower in some cases.
But if it works in your use case, you can use:
```py
transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2) | 45_5_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#batch-size | .md | ```py
transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
audio_filenames = [f"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/{i}.flac" for i in range(1, 5)]
texts = transcriber(audio_filenames)
```
This runs the pipeline on the 4 provided audio files, but it will pass them in batches of 2
to the model (which is on a GPU, where batching is more likely to help) without requiring any further code from you. | 45_5_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#batch-size | .md | to the model (which is on a GPU, where batching is more likely to help) without requiring any further code from you.
The output should always match what you would have received without batching. It is only meant as a way to help you get more speed out of a pipeline. | 45_5_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#batch-size | .md | Pipelines can also alleviate some of the complexities of batching because, for some pipelines, a single item (like a long audio file) needs to be chunked into multiple parts to be processed by a model. The pipeline performs this [*chunk batching*](./main_classes/pipelines#pipeline-chunk-batching) for you. | 45_5_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#task-specific-parameters | .md | All tasks provide task specific parameters which allow for additional flexibility and options to help you get your job done.
For instance, the [`transformers.AutomaticSpeechRecognitionPipeline.__call__`] method has a `return_timestamps` parameter which sounds promising for subtitling videos:
```py
>>> transcriber = pipeline(model="openai/whisper-large-v2", return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac") | 45_6_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#task-specific-parameters | .md | >>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.', 'chunks': [{'timestamp': (0.0, 11.88), 'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its'}, {'timestamp': (11.88, 12.38), 'text': ' creed.'}]}
```
As you can see, the model inferred the text and also outputted **when** the various sentences were pronounced. | 45_6_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#task-specific-parameters | .md | ```
As you can see, the model inferred the text and also outputted **when** the various sentences were pronounced.
There are many parameters available for each task, so check out each task's API reference to see what you can tinker with!
For instance, the [`~transformers.AutomaticSpeechRecognitionPipeline`] has a `chunk_length_s` parameter which is helpful
for working on really long audio files (for example, subtitling entire movies or hour-long videos) that a model typically | 45_6_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#task-specific-parameters | .md | for working on really long audio files (for example, subtitling entire movies or hour-long videos) that a model typically
cannot handle on its own:
```python
>>> transcriber = pipeline(model="openai/whisper-large-v2", chunk_length_s=30)
>>> transcriber("https://huggingface.co/datasets/reach-vb/random-audios/resolve/main/ted_60.wav") | 45_6_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#task-specific-parameters | .md | {'text': " So in college, I was a government major, which means I had to write a lot of papers. Now, when a normal student writes a paper, they might spread the work out a little like this. So, you know. You get started maybe a little slowly, but you get enough done in the first week that with some heavier days later on, everything gets done and things stay civil. And I would want to do that like that. That would be the plan. I would have it all ready to go, but then actually the paper would come along, | 45_6_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#task-specific-parameters | .md | to do that like that. That would be the plan. I would have it all ready to go, but then actually the paper would come along, and then I would kind of do this. And that would happen every single paper. But then came my 90-page senior thesis, a paper you're supposed to spend a year on. I knew for a paper like that, my normal workflow was not an option, it was way too big a project. So I planned things out and I decided I kind of had to go something like this. This is how the year would go. So I'd start off | 45_6_5 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#task-specific-parameters | .md | So I planned things out and I decided I kind of had to go something like this. This is how the year would go. So I'd start off light and I'd bump it up"} | 45_6_6 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#task-specific-parameters | .md | ```
If you can't find a parameter that would really help you out, feel free to [request it](https://github.com/huggingface/transformers/issues/new?assignees=&labels=feature&template=feature-request.yml)! | 45_6_7 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#using-pipelines-on-a-dataset | .md | The pipeline can also run inference on a large dataset. The easiest way we recommend doing this is by using an iterator:
```py
def data():
for i in range(1000):
yield f"My example {i}" | 45_7_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#using-pipelines-on-a-dataset | .md | pipe = pipeline(model="openai-community/gpt2", device=0)
generated_characters = 0
for out in pipe(data()):
generated_characters += len(out[0]["generated_text"])
```
The iterator `data()` yields each result, and the pipeline automatically
recognizes the input is iterable and will start fetching the data while
it continues to process it on the GPU (this uses [DataLoader](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) under the hood). | 45_7_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#using-pipelines-on-a-dataset | .md | This is important because you don't have to allocate memory for the whole dataset
and you can feed the GPU as fast as possible.
Since batching could speed things up, it may be useful to try tuning the `batch_size` parameter here.
The simplest way to iterate over a dataset is to just load one from 🤗 [Datasets](https://github.com/huggingface/datasets/):
```py
# KeyDataset is a util that will just output the item we're interested in.
from transformers.pipelines.pt_utils import KeyDataset | 45_7_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#using-pipelines-on-a-dataset | .md | from transformers.pipelines.pt_utils import KeyDataset
from datasets import load_dataset | 45_7_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#using-pipelines-on-a-dataset | .md | pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
for out in pipe(KeyDataset(dataset, "audio")):
print(out)
``` | 45_7_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#using-pipelines-for-a-webserver | .md | <Tip>
Creating an inference engine is a complex topic which deserves it's own
page.
</Tip>
[Link](./pipeline_webserver) | 45_8_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#vision-pipeline | .md | Using a [`pipeline`] for vision tasks is practically identical.
Specify your task and pass your image to the classifier. The image can be a link, a local path or a base64-encoded image. For example, what species of cat is shown below?

```py
>>> from transformers import pipeline | 45_9_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#vision-pipeline | .md | >>> vision_classifier = pipeline(model="google/vit-base-patch16-224")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds | 45_9_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#vision-pipeline | .md | ... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
``` | 45_9_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#text-pipeline | .md | Using a [`pipeline`] for NLP tasks is practically identical.
```py
>>> from transformers import pipeline | 45_10_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#text-pipeline | .md | >>> # This model is a `zero-shot-classification` model.
>>> # It will classify text, except you are free to choose any label you might imagine
>>> classifier = pipeline(model="facebook/bart-large-mnli")
>>> classifier(
... "I have a problem with my iphone that needs to be resolved asap!!",
... candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
... ) | 45_10_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#text-pipeline | .md | ... candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
... )
{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}
``` | 45_10_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#multimodal-pipeline | .md | The [`pipeline`] supports more than one modality. For example, a visual question answering (VQA) task combines text and image. Feel free to use any image link you like and a question you want to ask about the image. The image can be a URL or a local path to the image.
For example, if you use this [invoice image](https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png):
```py
>>> from transformers import pipeline | 45_11_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#multimodal-pipeline | .md | >>> vqa = pipeline(model="impira/layoutlm-document-qa")
>>> output = vqa(
... image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
... question="What is the invoice number?",
... )
>>> output[0]["score"] = round(output[0]["score"], 3)
>>> output
[{'score': 0.425, 'answer': 'us-001', 'start': 16, 'end': 16}]
```
<Tip> | 45_11_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#multimodal-pipeline | .md | >>> output
[{'score': 0.425, 'answer': 'us-001', 'start': 16, 'end': 16}]
```
<Tip>
To run the example above you need to have [`pytesseract`](https://pypi.org/project/pytesseract/) installed in addition to 🤗 Transformers:
```bash
sudo apt install -y tesseract-ocr
pip install pytesseract
```
</Tip> | 45_11_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#using-pipeline-on-large-models-with--accelerate | .md | You can easily run `pipeline` on large models using 🤗 `accelerate`! First make sure you have installed `accelerate` with `pip install accelerate`.
First load your model using `device_map="auto"`! We will use `facebook/opt-1.3b` for our example.
```py
# pip install accelerate
import torch
from transformers import pipeline | 45_12_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#using-pipeline-on-large-models-with--accelerate | .md | pipe = pipeline(model="facebook/opt-1.3b", torch_dtype=torch.bfloat16, device_map="auto")
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
```
You can also pass 8-bit loaded models if you install `bitsandbytes` and add the argument `load_in_8bit=True`
```py
# pip install accelerate bitsandbytes
import torch
from transformers import pipeline | 45_12_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#using-pipeline-on-large-models-with--accelerate | .md | pipe = pipeline(model="facebook/opt-1.3b", device_map="auto", model_kwargs={"load_in_8bit": True})
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
```
Note that you can replace the checkpoint with any Hugging Face model that supports large model loading, such as BLOOM. | 45_12_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#creating-web-demos-from-pipelines-with-gradio | .md | Pipelines are automatically supported in [Gradio](https://github.com/gradio-app/gradio/), a library that makes creating beautiful and user-friendly machine learning apps on the web a breeze. First, make sure you have Gradio installed:
```
pip install gradio
``` | 45_13_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#creating-web-demos-from-pipelines-with-gradio | .md | ```
pip install gradio
```
Then, you can create a web demo around an image classification pipeline (or any other pipeline) in a single line of code by calling Gradio's [`Interface.from_pipeline`](https://www.gradio.app/docs/interface#interface-from-pipeline) function to launch the pipeline. This creates an intuitive drag-and-drop interface in your browser:
```py
from transformers import pipeline
import gradio as gr | 45_13_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#creating-web-demos-from-pipelines-with-gradio | .md | pipe = pipeline("image-classification", model="google/vit-base-patch16-224") | 45_13_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/pipeline_tutorial.md | https://huggingface.co/docs/transformers/en/pipeline_tutorial/#creating-web-demos-from-pipelines-with-gradio | .md | gr.Interface.from_pipeline(pipe).launch()
```
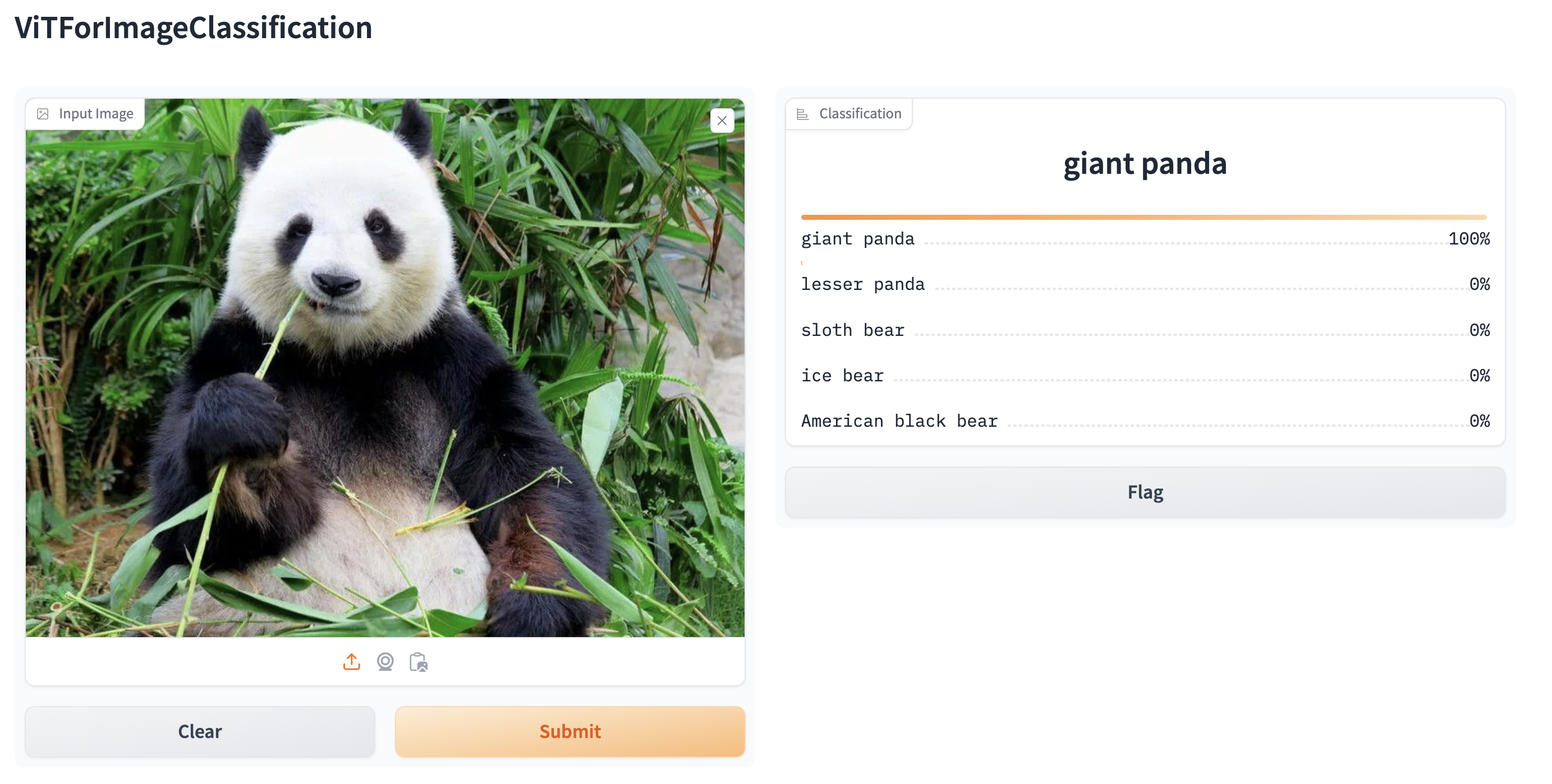
By default, the web demo runs on a local server. If you'd like to share it with others, you can generate a temporary public
link by setting `share=True` in `launch()`. You can also host your demo on [Hugging Face Spaces](https://huggingface.co/spaces) for a permanent link. | 45_13_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/ | .md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the | 46_0_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/ | .md | an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
--> | 46_0_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#fully-sharded-data-parallel | .md | [Fully Sharded Data Parallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) is a data parallel method that shards a model's parameters, gradients and optimizer states across the number of available GPUs (also called workers or *rank*). Unlike [DistributedDataParallel (DDP)](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html), FSDP reduces memory-usage because a model is replicated on each GPU. This improves GPU memory-efficiency | 46_1_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#fully-sharded-data-parallel | .md | FSDP reduces memory-usage because a model is replicated on each GPU. This improves GPU memory-efficiency and allows you to train much larger models on fewer GPUs. FSDP is integrated with the Accelerate, a library for easily managing training in distributed environments, which means it is available for use from the [`Trainer`] class. | 46_1_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#fully-sharded-data-parallel | .md | Before you start, make sure Accelerate is installed and at least PyTorch 2.1.0 or newer.
```bash
pip install accelerate
``` | 46_1_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#fsdp-configuration | .md | To start, run the [`accelerate config`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-config) command to create a configuration file for your training environment. Accelerate uses this configuration file to automatically setup the correct training environment based on your selected training options in `accelerate config`.
```bash
accelerate config
``` | 46_2_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#fsdp-configuration | .md | ```bash
accelerate config
```
When you run `accelerate config`, you'll be prompted with a series of options to configure your training environment. This section covers some of the most important FSDP options. To learn more about the other available FSDP options, take a look at the [fsdp_config](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.fsdp_config) parameters. | 46_2_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#sharding-strategy | .md | FSDP offers a number of sharding strategies to select from:
* `FULL_SHARD` - shards model parameters, gradients and optimizer states across workers; select `1` for this option
* `SHARD_GRAD_OP`- shard gradients and optimizer states across workers; select `2` for this option
* `NO_SHARD` - don't shard anything (this is equivalent to DDP); select `3` for this option | 46_3_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#sharding-strategy | .md | * `NO_SHARD` - don't shard anything (this is equivalent to DDP); select `3` for this option
* `HYBRID_SHARD` - shard model parameters, gradients and optimizer states within each worker where each worker also has a full copy; select `4` for this option
* `HYBRID_SHARD_ZERO2` - shard gradients and optimizer states within each worker where each worker also has a full copy; select `5` for this option
This is enabled by the `fsdp_sharding_strategy` flag. | 46_3_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#cpu-offload | .md | You could also offload parameters and gradients when they are not in use to the CPU to save even more GPU memory and help you fit large models where even FSDP may not be sufficient. This is enabled by setting `fsdp_offload_params: true` when running `accelerate config`. | 46_4_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#wrapping-policy | .md | FSDP is applied by wrapping each layer in the network. The wrapping is usually applied in a nested way where the full weights are discarded after each forward pass to save memory for use in the next layer. The *auto wrapping* policy is the simplest way to implement this and you don't need to change any code. You should select `fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP` to wrap a Transformer layer and `fsdp_transformer_layer_cls_to_wrap` to specify which layer to wrap (for example `BertLayer`). | 46_5_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#wrapping-policy | .md | Otherwise, you can choose a size-based wrapping policy where FSDP is applied to a layer if it exceeds a certain number of parameters. This is enabled by setting `fsdp_wrap_policy: SIZE_BASED_WRAP` and `min_num_param` to the desired size threshold. | 46_5_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#checkpointing | .md | Intermediate checkpoints should be saved with `fsdp_state_dict_type: SHARDED_STATE_DICT` because saving the full state dict with CPU offloading on rank 0 takes a lot of time and often results in `NCCL Timeout` errors due to indefinite hanging during broadcasting. You can resume training with the sharded state dicts with the [`~accelerate.Accelerator.load_state`] method.
```py
# directory containing checkpoints
accelerator.load_state("ckpt")
``` | 46_6_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#checkpointing | .md | ```py
# directory containing checkpoints
accelerator.load_state("ckpt")
```
However, when training ends, you want to save the full state dict because sharded state dict is only compatible with FSDP.
```py
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT") | 46_6_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#checkpointing | .md | trainer.save_model(script_args.output_dir)
``` | 46_6_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#tpu | .md | [PyTorch XLA](https://pytorch.org/xla/release/2.1/index.html) supports FSDP training for TPUs and it can be enabled by modifying the FSDP configuration file generated by `accelerate config`. In addition to the sharding strategies and wrapping options specified above, you can add the parameters shown below to the file.
```yaml
xla: True # must be set to True to enable PyTorch/XLA
xla_fsdp_settings: # XLA-specific FSDP parameters
xla_fsdp_grad_ckpt: True # use gradient checkpointing
``` | 46_7_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#tpu | .md | xla_fsdp_settings: # XLA-specific FSDP parameters
xla_fsdp_grad_ckpt: True # use gradient checkpointing
```
The [`xla_fsdp_settings`](https://github.com/pytorch/xla/blob/2e6e183e0724818f137c8135b34ef273dea33318/torch_xla/distributed/fsdp/xla_fully_sharded_data_parallel.py#L128) allow you to configure additional XLA-specific parameters for FSDP. | 46_7_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#launch-training | .md | An example FSDP configuration file may look like:
```yaml
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_cpu_ram_efficient_loading: true
fsdp_forward_prefetch: false
fsdp_offload_params: true
fsdp_sharding_strategy: 1
fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_transformer_layer_cls_to_wrap: BertLayer | 46_8_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#launch-training | .md | fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_transformer_layer_cls_to_wrap: BertLayer
fsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
``` | 46_8_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#launch-training | .md | rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
To launch training, run the [`accelerate launch`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-launch) command and it'll automatically use the configuration file you previously created with `accelerate config`.
```bash
accelerate launch my-trainer-script.py
```
```bash
accelerate launch --fsdp="full shard" --fsdp_config="path/to/fsdp_config/ my-trainer-script.py | 46_8_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#launch-training | .md | ```
```bash
accelerate launch --fsdp="full shard" --fsdp_config="path/to/fsdp_config/ my-trainer-script.py
``` | 46_8_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#next-steps | .md | FSDP can be a powerful tool for training really large models and you have access to more than one GPU or TPU. By sharding the model parameters, optimizer and gradient states, and even offloading them to the CPU when they're inactive, FSDP can reduce the high cost of large-scale training. If you're interested in learning more, the following may be helpful:
* Follow along with the more in-depth Accelerate guide for [FSDP](https://huggingface.co/docs/accelerate/usage_guides/fsdp). | 46_9_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/fsdp.md | https://huggingface.co/docs/transformers/en/fsdp/#next-steps | .md | * Follow along with the more in-depth Accelerate guide for [FSDP](https://huggingface.co/docs/accelerate/usage_guides/fsdp).
* Read the [Introducing PyTorch Fully Sharded Data Parallel (FSDP) API](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) blog post.
* Read the [Scaling PyTorch models on Cloud TPUs with FSDP](https://pytorch.org/blog/scaling-pytorch-models-on-cloud-tpus-with-fsdp/) blog post. | 46_9_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/ | .md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the | 47_0_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/ | .md | an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
--> | 47_0_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#the-transformer-model-family | .md | Since its introduction in 2017, the [original Transformer](https://arxiv.org/abs/1706.03762) model (see the [Annotated Transformer](http://nlp.seas.harvard.edu/2018/04/03/attention.html) blog post for a gentle technical introduction) has inspired many new and exciting models that extend beyond natural language processing (NLP) tasks. There are models for [predicting the folded structure of proteins](https://huggingface.co/blog/deep-learning-with-proteins), [training a cheetah to | 47_1_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#the-transformer-model-family | .md | [predicting the folded structure of proteins](https://huggingface.co/blog/deep-learning-with-proteins), [training a cheetah to run](https://huggingface.co/blog/train-decision-transformers), and [time series forecasting](https://huggingface.co/blog/time-series-transformers). With so many Transformer variants available, it can be easy to miss the bigger picture. What all these models have in common is they're based on the original Transformer architecture. Some models only use the encoder or decoder, while | 47_1_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#the-transformer-model-family | .md | have in common is they're based on the original Transformer architecture. Some models only use the encoder or decoder, while others use both. This provides a useful taxonomy to categorize and examine the high-level differences within models in the Transformer family, and it'll help you understand Transformers you haven't encountered before. | 47_1_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#the-transformer-model-family | .md | If you aren't familiar with the original Transformer model or need a refresher, check out the [How do Transformers work](https://huggingface.co/course/chapter1/4?fw=pt) chapter from the Hugging Face course.
<div align="center">
<iframe width="560" height="315" src="https://www.youtube.com/embed/H39Z_720T5s" title="YouTube video player"
frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope;
picture-in-picture" allowfullscreen></iframe>
</div> | 47_1_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#computer-vision | .md | <iframe style="border: 1px solid rgba(0, 0, 0, 0.1);" width="1000" height="450" src="https://www.figma.com/embed?embed_host=share&url=https%3A%2F%2Fwww.figma.com%2Ffile%2FacQBpeFBVvrDUlzFlkejoz%2FModelscape-timeline%3Fnode-id%3D0%253A1%26t%3Dm0zJ7m2BQ9oe0WtO-1" allowfullscreen></iframe> | 47_2_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#convolutional-network | .md | For a long time, convolutional networks (CNNs) were the dominant paradigm for computer vision tasks until the [Vision Transformer](https://arxiv.org/abs/2010.11929) demonstrated its scalability and efficiency. Even then, some of a CNN's best qualities, like translation invariance, are so powerful (especially for certain tasks) that some Transformers incorporate convolutions in their architecture. [ConvNeXt](model_doc/convnext) flipped this exchange around and incorporated design choices from Transformers to | 47_3_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#convolutional-network | .md | architecture. [ConvNeXt](model_doc/convnext) flipped this exchange around and incorporated design choices from Transformers to modernize a CNN. For example, ConvNeXt uses non-overlapping sliding windows to patchify an image and a larger kernel to increase its global receptive field. ConvNeXt also makes several layer design choices to be more memory-efficient and improve performance, so it competes favorably with Transformers! | 47_3_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#encodercv-encoder | .md | The [Vision Transformer (ViT)](model_doc/vit) opened the door to computer vision tasks without convolutions. ViT uses a standard Transformer encoder, but its main breakthrough was how it treated an image. It splits an image into fixed-size patches and uses them to create an embedding, just like how a sentence is split into tokens. ViT capitalized on the Transformers' efficient architecture to demonstrate competitive results with the CNNs at the time while requiring fewer resources to train. ViT was soon | 47_4_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#encodercv-encoder | .md | to demonstrate competitive results with the CNNs at the time while requiring fewer resources to train. ViT was soon followed by other vision models that could also handle dense vision tasks like segmentation as well as detection. | 47_4_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#encodercv-encoder | .md | One of these models is the [Swin](model_doc/swin) Transformer. It builds hierarchical feature maps (like a CNN 👀 and unlike ViT) from smaller-sized patches and merges them with neighboring patches in deeper layers. Attention is only computed within a local window, and the window is shifted between attention layers to create connections to help the model learn better. Since the Swin Transformer can produce hierarchical feature maps, it is a good candidate for dense prediction tasks like segmentation and | 47_4_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#encodercv-encoder | .md | Swin Transformer can produce hierarchical feature maps, it is a good candidate for dense prediction tasks like segmentation and detection. The [SegFormer](model_doc/segformer) also uses a Transformer encoder to build hierarchical feature maps, but it adds a simple multilayer perceptron (MLP) decoder on top to combine all the feature maps and make a prediction. | 47_4_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#encodercv-encoder | .md | Other vision models, like BeIT and ViTMAE, drew inspiration from BERT's pretraining objective. [BeIT](model_doc/beit) is pretrained by *masked image modeling (MIM)*; the image patches are randomly masked, and the image is also tokenized into visual tokens. BeIT is trained to predict the visual tokens corresponding to the masked patches. [ViTMAE](model_doc/vitmae) has a similar pretraining objective, except it must predict the pixels instead of visual tokens. What's unusual is 75% of the image patches are | 47_4_4 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#encodercv-encoder | .md | objective, except it must predict the pixels instead of visual tokens. What's unusual is 75% of the image patches are masked! The decoder reconstructs the pixels from the masked tokens and encoded patches. After pretraining, the decoder is thrown away, and the encoder is ready to be used in downstream tasks. | 47_4_5 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#decodercv-decoder | .md | Decoder-only vision models are rare because most vision models rely on an encoder to learn an image representation. But for use cases like image generation, the decoder is a natural fit, as we've seen from text generation models like GPT-2. [ImageGPT](model_doc/imagegpt) uses the same architecture as GPT-2, but instead of predicting the next token in a sequence, it predicts the next pixel in an image. In addition to image generation, ImageGPT could also be finetuned for image classification. | 47_5_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#encoder-decodercv-encoder-decoder | .md | Vision models commonly use an encoder (also known as a backbone) to extract important image features before passing them to a Transformer decoder. [DETR](model_doc/detr) has a pretrained backbone, but it also uses the complete Transformer encoder-decoder architecture for object detection. The encoder learns image representations and combines them with object queries (each object query is a learned embedding that focuses on a region or object in an image) in the decoder. DETR predicts the bounding box | 47_6_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#encoder-decodercv-encoder-decoder | .md | query is a learned embedding that focuses on a region or object in an image) in the decoder. DETR predicts the bounding box coordinates and class label for each object query. | 47_6_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#natural-language-processing | .md | <iframe style="border: 1px solid rgba(0, 0, 0, 0.1);" width="1000" height="450" src="https://www.figma.com/embed?embed_host=share&url=https%3A%2F%2Fwww.figma.com%2Ffile%2FUhbQAZDlpYW5XEpdFy6GoG%2Fnlp-model-timeline%3Fnode-id%3D0%253A1%26t%3D4mZMr4r1vDEYGJ50-1" allowfullscreen></iframe> | 47_7_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#encodernlp-encoder | .md | [BERT](model_doc/bert) is an encoder-only Transformer that randomly masks certain tokens in the input to avoid seeing other tokens, which would allow it to "cheat". The pretraining objective is to predict the masked token based on the context. This allows BERT to fully use the left and right contexts to help it learn a deeper and richer representation of the inputs. However, there was still room for improvement in BERT's pretraining strategy. [RoBERTa](model_doc/roberta) improved upon this by introducing a | 47_8_0 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#encodernlp-encoder | .md | was still room for improvement in BERT's pretraining strategy. [RoBERTa](model_doc/roberta) improved upon this by introducing a new pretraining recipe that includes training for longer and on larger batches, randomly masking tokens at each epoch instead of just once during preprocessing, and removing the next-sentence prediction objective. | 47_8_1 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#encodernlp-encoder | .md | The dominant strategy to improve performance is to increase the model size. But training large models is computationally expensive. One way to reduce computational costs is using a smaller model like [DistilBERT](model_doc/distilbert). DistilBERT uses [knowledge distillation](https://arxiv.org/abs/1503.02531) - a compression technique - to create a smaller version of BERT while keeping nearly all of its language understanding capabilities. | 47_8_2 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#encodernlp-encoder | .md | However, most Transformer models continued to trend towards more parameters, leading to new models focused on improving training efficiency. [ALBERT](model_doc/albert) reduces memory consumption by lowering the number of parameters in two ways: separating the larger vocabulary embedding into two smaller matrices and allowing layers to share parameters. [DeBERTa](model_doc/deberta) added a disentangled attention mechanism where the word and its position are separately encoded in two vectors. The attention | 47_8_3 |
/Users/nielsrogge/Documents/python_projecten/transformers/docs/source/en/model_summary.md | https://huggingface.co/docs/transformers/en/model_summary/#encodernlp-encoder | .md | added a disentangled attention mechanism where the word and its position are separately encoded in two vectors. The attention is computed from these separate vectors instead of a single vector containing the word and position embeddings. [Longformer](model_doc/longformer) also focused on making attention more efficient, especially for processing documents with longer sequence lengths. It uses a combination of local windowed attention (attention only calculated from fixed window size around each token) and | 47_8_4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.