
text
stringlengths 3
7.31k
| source
stringclasses 40
values | url
stringlengths 53
184
| source_section
stringlengths 0
105
| file_type
stringclasses 1
value | id
stringlengths 3
6
|
|---|---|---|---|---|---|
```python
Frozen data structure holding information about a cached repository.
Args:
repo_id (`str`):
Repo id of the repo on the Hub. Example: `"google/fleurs"`.
repo_type (`Literal["dataset", "model", "space"]`):
Type of the cached repo.
repo_path (`Path`):
Local path to the cached repo.
size_on_disk (`int`):
Sum of the blob file sizes in the cached repo.
nb_files (`int`):
Total number of blob files in the cached repo.
revisions (`FrozenSet[CachedRevisionInfo]`):
Set of [`~CachedRevisionInfo`] describing all revisions cached in the repo.
last_accessed (`float`):
Timestamp of the last time a blob file of the repo has been accessed.
last_modified (`float`):
Timestamp of the last time a blob file of the repo has been modified/created.
<Tip warning={true}>
`size_on_disk` is not necessarily the sum of all revisions sizes because of
duplicated files. Besides, only blobs are taken into account, not the (negligible)
size of folders and symlinks.
</Tip>
<Tip warning={true}>
`last_accessed` and `last_modified` reliability can depend on the OS you are using.
See [python documentation](https://docs.python.org/3/library/os.html#os.stat_result)
for more details.
</Tip>
```
- size_on_disk_str
- refs
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cache.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cache/#huggingfacehubcachedrepoinfo
|
#huggingfacehubcachedrepoinfo
|
.md
|
20_10
|
```python
Frozen data structure holding information about a revision.
A revision correspond to a folder in the `snapshots` folder and is populated with
the exact tree structure as the repo on the Hub but contains only symlinks. A
revision can be either referenced by 1 or more `refs` or be "detached" (no refs).
Args:
commit_hash (`str`):
Hash of the revision (unique).
Example: `"9338f7b671827df886678df2bdd7cc7b4f36dffd"`.
snapshot_path (`Path`):
Path to the revision directory in the `snapshots` folder. It contains the
exact tree structure as the repo on the Hub.
files: (`FrozenSet[CachedFileInfo]`):
Set of [`~CachedFileInfo`] describing all files contained in the snapshot.
refs (`FrozenSet[str]`):
Set of `refs` pointing to this revision. If the revision has no `refs`, it
is considered detached.
Example: `{"main", "2.4.0"}` or `{"refs/pr/1"}`.
size_on_disk (`int`):
Sum of the blob file sizes that are symlink-ed by the revision.
last_modified (`float`):
Timestamp of the last time the revision has been created/modified.
<Tip warning={true}>
`last_accessed` cannot be determined correctly on a single revision as blob files
are shared across revisions.
</Tip>
<Tip warning={true}>
`size_on_disk` is not necessarily the sum of all file sizes because of possible
duplicated files. Besides, only blobs are taken into account, not the (negligible)
size of folders and symlinks.
</Tip>
```
- size_on_disk_str
- nb_files
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cache.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cache/#huggingfacehubcachedrevisioninfo
|
#huggingfacehubcachedrevisioninfo
|
.md
|
20_11
|
```python
Frozen data structure holding information about a single cached file.
Args:
file_name (`str`):
Name of the file. Example: `config.json`.
file_path (`Path`):
Path of the file in the `snapshots` directory. The file path is a symlink
referring to a blob in the `blobs` folder.
blob_path (`Path`):
Path of the blob file. This is equivalent to `file_path.resolve()`.
size_on_disk (`int`):
Size of the blob file in bytes.
blob_last_accessed (`float`):
Timestamp of the last time the blob file has been accessed (from any
revision).
blob_last_modified (`float`):
Timestamp of the last time the blob file has been modified/created.
<Tip warning={true}>
`blob_last_accessed` and `blob_last_modified` reliability can depend on the OS you
are using. See [python documentation](https://docs.python.org/3/library/os.html#os.stat_result)
for more details.
</Tip>
```
- size_on_disk_str
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cache.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cache/#huggingfacehubcachedfileinfo
|
#huggingfacehubcachedfileinfo
|
.md
|
20_12
|
```python
Frozen data structure holding the strategy to delete cached revisions.
This object is not meant to be instantiated programmatically but to be returned by
[`~utils.HFCacheInfo.delete_revisions`]. See documentation for usage example.
Args:
expected_freed_size (`float`):
Expected freed size once strategy is executed.
blobs (`FrozenSet[Path]`):
Set of blob file paths to be deleted.
refs (`FrozenSet[Path]`):
Set of reference file paths to be deleted.
repos (`FrozenSet[Path]`):
Set of entire repo paths to be deleted.
snapshots (`FrozenSet[Path]`):
Set of snapshots to be deleted (directory of symlinks).
```
- expected_freed_size_str
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cache.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cache/#huggingfacehubdeletecachestrategy
|
#huggingfacehubdeletecachestrategy
|
.md
|
20_13
|
```python
Exception for any unexpected structure in the Huggingface cache-system.
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cache.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cache/#huggingfacehubcorruptedcacheexception
|
#huggingfacehubcorruptedcacheexception
|
.md
|
20_14
|
<!--⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/
|
.md
|
21_0
|
|
`huggingface_hub` can be configured using environment variables.
If you are unfamiliar with environment variable, here are generic articles about them
[on macOS and Linux](https://linuxize.com/post/how-to-set-and-list-environment-variables-in-linux/)
and on [Windows](https://phoenixnap.com/kb/windows-set-environment-variable).
This page will guide you through all environment variables specific to `huggingface_hub`
and their meaning.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#environment-variables
|
#environment-variables
|
.md
|
21_1
|
To configure the inference api base url. You might want to set this variable if your organization
is pointing at an API Gateway rather than directly at the inference api.
Defaults to `"https://api-inference.huggingface.co"`.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hfinferenceendpoint
|
#hfinferenceendpoint
|
.md
|
21_2
|
To configure where `huggingface_hub` will locally store data. In particular, your token
and the cache will be stored in this folder.
Defaults to `"~/.cache/huggingface"` unless [XDG_CACHE_HOME](#xdgcachehome) is set.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hfhome
|
#hfhome
|
.md
|
21_3
|
To configure where repositories from the Hub will be cached locally (models, datasets and
spaces).
Defaults to `"$HF_HOME/hub"` (e.g. `"~/.cache/huggingface/hub"` by default).
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hfhubcache
|
#hfhubcache
|
.md
|
21_4
|
To configure where [assets](../guides/manage-cache#caching-assets) created by downstream libraries
will be cached locally. Those assets can be preprocessed data, files downloaded from GitHub,
logs,...
Defaults to `"$HF_HOME/assets"` (e.g. `"~/.cache/huggingface/assets"` by default).
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hfassetscache
|
#hfassetscache
|
.md
|
21_5
|
To configure the User Access Token to authenticate to the Hub. If set, this value will
overwrite the token stored on the machine (in either `$HF_TOKEN_PATH` or `"$HF_HOME/token"` if the former is not set).
For more details about authentication, check out [this section](../quick-start#authentication).
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hftoken
|
#hftoken
|
.md
|
21_6
|
To configure where `huggingface_hub` should store the User Access Token. Defaults to `"$HF_HOME/token"` (e.g. `~/.cache/huggingface/token` by default).
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hftokenpath
|
#hftokenpath
|
.md
|
21_7
|
Set the verbosity level of the `huggingface_hub`'s logger. Must be one of
`{"debug", "info", "warning", "error", "critical"}`.
Defaults to `"warning"`.
For more details, see [logging reference](../package_reference/utilities#huggingface_hub.utils.logging.get_verbosity).
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hfhubverbosity
|
#hfhubverbosity
|
.md
|
21_8
|
This environment variable has been deprecated and is now ignored by `huggingface_hub`. Downloading files to the local dir does not rely on symlinks anymore.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hfhublocaldirautosymlinkthreshold
|
#hfhublocaldirautosymlinkthreshold
|
.md
|
21_9
|
Integer value to define the number of seconds to wait for server response when fetching the latest metadata from a repo before downloading a file. If the request times out, `huggingface_hub` will default to the locally cached files. Setting a lower value speeds up the workflow for machines with a slow connection that have already cached files. A higher value guarantees the metadata call to succeed in more cases. Default to 10s.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hfhubetagtimeout
|
#hfhubetagtimeout
|
.md
|
21_10
|
Integer value to define the number of seconds to wait for server response when downloading a file. If the request times out, a TimeoutError is raised. Setting a higher value is beneficial on machine with a slow connection. A smaller value makes the process fail quicker in case of complete network outage. Default to 10s.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hfhubdownloadtimeout
|
#hfhubdownloadtimeout
|
.md
|
21_11
|
The following environment variables expect a boolean value. The variable will be considered
as `True` if its value is one of `{"1", "ON", "YES", "TRUE"}` (case-insensitive). Any other value
(or undefined) will be considered as `False`.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#boolean-values
|
#boolean-values
|
.md
|
21_12
|
If set, no HTTP calls will be made to the Hugging Face Hub. If you try to download files, only the cached files will be accessed. If no cache file is detected, an error is raised This is useful in case your network is slow and you don't care about having the latest version of a file.
If `HF_HUB_OFFLINE=1` is set as environment variable and you call any method of [`HfApi`], an [`~huggingface_hub.utils.OfflineModeIsEnabled`] exception will be raised.
**Note:** even if the latest version of a file is cached, calling `hf_hub_download` still triggers a HTTP request to check that a new version is not available. Setting `HF_HUB_OFFLINE=1` will skip this call which speeds up your loading time.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hfhuboffline
|
#hfhuboffline
|
.md
|
21_13
|
Authentication is not mandatory for every requests to the Hub. For instance, requesting
details about `"gpt2"` model does not require to be authenticated. However, if a user is
[logged in](../package_reference/login), the default behavior will be to always send the token
in order to ease user experience (never get a HTTP 401 Unauthorized) when accessing private or gated repositories. For privacy, you can
disable this behavior by setting `HF_HUB_DISABLE_IMPLICIT_TOKEN=1`. In this case,
the token will be sent only for "write-access" calls (example: create a commit).
**Note:** disabling implicit sending of token can have weird side effects. For example,
if you want to list all models on the Hub, your private models will not be listed. You
would need to explicitly pass `token=True` argument in your script.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hfhubdisableimplicittoken
|
#hfhubdisableimplicittoken
|
.md
|
21_14
|
For time consuming tasks, `huggingface_hub` displays a progress bar by default (using tqdm).
You can disable all the progress bars at once by setting `HF_HUB_DISABLE_PROGRESS_BARS=1`.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hfhubdisableprogressbars
|
#hfhubdisableprogressbars
|
.md
|
21_15
|
If you are on a Windows machine, it is recommended to enable the developer mode or to run
`huggingface_hub` in admin mode. If not, `huggingface_hub` will not be able to create
symlinks in your cache system. You will be able to execute any script but your user experience
will be degraded as some huge files might end-up duplicated on your hard-drive. A warning
message is triggered to warn you about this behavior. Set `HF_HUB_DISABLE_SYMLINKS_WARNING=1`,
to disable this warning.
For more details, see [cache limitations](../guides/manage-cache#limitations).
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hfhubdisablesymlinkswarning
|
#hfhubdisablesymlinkswarning
|
.md
|
21_16
|
Some features of `huggingface_hub` are experimental. This means you can use them but we do not guarantee they will be
maintained in the future. In particular, we might update the API or behavior of such features without any deprecation
cycle. A warning message is triggered when using an experimental feature to warn you about it. If you're comfortable debugging any potential issues using an experimental feature, you can set `HF_HUB_DISABLE_EXPERIMENTAL_WARNING=1` to disable the warning.
If you are using an experimental feature, please let us know! Your feedback can help us design and improve it.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hfhubdisableexperimentalwarning
|
#hfhubdisableexperimentalwarning
|
.md
|
21_17
|
By default, some data is collected by HF libraries (`transformers`, `datasets`, `gradio`,..) to monitor usage, debug issues and help prioritize features.
Each library defines its own policy (i.e. which usage to monitor) but the core implementation happens in `huggingface_hub` (see [`send_telemetry`]).
You can set `HF_HUB_DISABLE_TELEMETRY=1` as environment variable to globally disable telemetry.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hfhubdisabletelemetry
|
#hfhubdisabletelemetry
|
.md
|
21_18
|
Set to `True` for faster uploads and downloads from the Hub using `hf_transfer`.
By default, `huggingface_hub` uses the Python-based `requests.get` and `requests.post` functions.
Although these are reliable and versatile,
they may not be the most efficient choice for machines with high bandwidth.
[`hf_transfer`](https://github.com/huggingface/hf_transfer) is a Rust-based package developed to
maximize the bandwidth used by dividing large files into smaller parts
and transferring them simultaneously using multiple threads.
This approach can potentially double the transfer speed.
To use `hf_transfer`:
1. Specify the `hf_transfer` extra when installing `huggingface_hub`
(e.g. `pip install huggingface_hub[hf_transfer]`).
2. Set `HF_HUB_ENABLE_HF_TRANSFER=1` as an environment variable.
Please note that using `hf_transfer` comes with certain limitations. Since it is not purely Python-based, debugging errors may be challenging. Additionally, `hf_transfer` lacks several user-friendly features such as resumable downloads and proxies. These omissions are intentional to maintain the simplicity and speed of the Rust logic. Consequently, `hf_transfer` is not enabled by default in `huggingface_hub`.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#hfhubenablehftransfer
|
#hfhubenablehftransfer
|
.md
|
21_19
|
In order to standardize all environment variables within the Hugging Face ecosystem, some variables have been marked as deprecated. Although they remain functional, they no longer take precedence over their replacements. The following table outlines the deprecated variables and their corresponding alternatives:
| Deprecated Variable | Replacement |
| --- | --- |
| `HUGGINGFACE_HUB_CACHE` | `HF_HUB_CACHE` |
| `HUGGINGFACE_ASSETS_CACHE` | `HF_ASSETS_CACHE` |
| `HUGGING_FACE_HUB_TOKEN` | `HF_TOKEN` |
| `HUGGINGFACE_HUB_VERBOSITY` | `HF_HUB_VERBOSITY` |
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#deprecated-environment-variables
|
#deprecated-environment-variables
|
.md
|
21_20
|
Some environment variables are not specific to `huggingface_hub` but are still taken into account when they are set.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#from-external-tools
|
#from-external-tools
|
.md
|
21_21
|
Boolean value. Equivalent to `HF_HUB_DISABLE_TELEMETRY`. When set to true, telemetry is globally disabled in the Hugging Face Python ecosystem (`transformers`, `diffusers`, `gradio`, etc.). See https://consoledonottrack.com/ for more details.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#donottrack
|
#donottrack
|
.md
|
21_22
|
Boolean value. When set, `huggingface-cli` tool will not print any ANSI color.
See [no-color.org](https://no-color.org/).
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#nocolor
|
#nocolor
|
.md
|
21_23
|
Used only when `HF_HOME` is not set!
This is the default way to configure where [user-specific non-essential (cached) data should be written](https://wiki.archlinux.org/title/XDG_Base_Directory)
on linux machines.
If `HF_HOME` is not set, the default home will be `"$XDG_CACHE_HOME/huggingface"` instead
of `"~/.cache/huggingface"`.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/environment_variables.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/environment_variables/#xdgcachehome
|
#xdgcachehome
|
.md
|
21_24
|
<!--⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/
|
.md
|
22_0
|
|
The huggingface_hub library provides a Python interface to create, share, and update Model/Dataset Cards.
Visit the [dedicated documentation page](https://huggingface.co/docs/hub/models-cards) for a deeper view of what
Model Cards on the Hub are, and how they work under the hood. You can also check out our [Model Cards guide](../how-to-model-cards) to
get a feel for how you would use these utilities in your own projects.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#repository-cards
|
#repository-cards
|
.md
|
22_1
|
The `RepoCard` object is the parent class of [`ModelCard`], [`DatasetCard`] and `SpaceCard`.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#repo-card
|
#repo-card
|
.md
|
22_2
|
No docstring found for huggingface_hub.repocard.RepoCard
- __init__
- all
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#huggingfacehubrepocardrepocard
|
#huggingfacehubrepocardrepocard
|
.md
|
22_3
|
The [`CardData`] object is the parent class of [`ModelCardData`] and [`DatasetCardData`].
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#card-data
|
#card-data
|
.md
|
22_4
|
```python
Structure containing metadata from a RepoCard.
[`CardData`] is the parent class of [`ModelCardData`] and [`DatasetCardData`].
Metadata can be exported as a dictionary or YAML. Export can be customized to alter the representation of the data
(example: flatten evaluation results). `CardData` behaves as a dictionary (can get, pop, set values) but do not
inherit from `dict` to allow this export step.
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#huggingfacehubrepocarddatacarddata
|
#huggingfacehubrepocarddatacarddata
|
.md
|
22_5
|
No docstring found for huggingface_hub.ModelCard
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#modelcard
|
#modelcard
|
.md
|
22_6
|
```python
Model Card Metadata that is used by Hugging Face Hub when included at the top of your README.md
Args:
base_model (`str` or `List[str]`, *optional*):
The identifier of the base model from which the model derives. This is applicable for example if your model is a
fine-tune or adapter of an existing model. The value must be the ID of a model on the Hub (or a list of IDs
if your model derives from multiple models). Defaults to None.
datasets (`Union[str, List[str]]`, *optional*):
Dataset or list of datasets that were used to train this model. Should be a dataset ID
found on https://hf.co/datasets. Defaults to None.
eval_results (`Union[List[EvalResult], EvalResult]`, *optional*):
List of `huggingface_hub.EvalResult` that define evaluation results of the model. If provided,
`model_name` is used to as a name on PapersWithCode's leaderboards. Defaults to `None`.
language (`Union[str, List[str]]`, *optional*):
Language of model's training data or metadata. It must be an ISO 639-1, 639-2 or
639-3 code (two/three letters), or a special value like "code", "multilingual". Defaults to `None`.
library_name (`str`, *optional*):
Name of library used by this model. Example: keras or any library from
https://github.com/huggingface/huggingface.js/blob/main/packages/tasks/src/model-libraries.ts.
Defaults to None.
license (`str`, *optional*):
License of this model. Example: apache-2.0 or any license from
https://huggingface.co/docs/hub/repositories-licenses. Defaults to None.
license_name (`str`, *optional*):
Name of the license of this model. Defaults to None. To be used in conjunction with `license_link`.
Common licenses (Apache-2.0, MIT, CC-BY-SA-4.0) do not need a name. In that case, use `license` instead.
license_link (`str`, *optional*):
Link to the license of this model. Defaults to None. To be used in conjunction with `license_name`.
Common licenses (Apache-2.0, MIT, CC-BY-SA-4.0) do not need a link. In that case, use `license` instead.
metrics (`List[str]`, *optional*):
List of metrics used to evaluate this model. Should be a metric name that can be found
at https://hf.co/metrics. Example: 'accuracy'. Defaults to None.
model_name (`str`, *optional*):
A name for this model. It is used along with
`eval_results` to construct the `model-index` within the card's metadata. The name
you supply here is what will be used on PapersWithCode's leaderboards. If None is provided
then the repo name is used as a default. Defaults to None.
pipeline_tag (`str`, *optional*):
The pipeline tag associated with the model. Example: "text-classification".
tags (`List[str]`, *optional*):
List of tags to add to your model that can be used when filtering on the Hugging
Face Hub. Defaults to None.
ignore_metadata_errors (`str`):
If True, errors while parsing the metadata section will be ignored. Some information might be lost during
the process. Use it at your own risk.
kwargs (`dict`, *optional*):
Additional metadata that will be added to the model card. Defaults to None.
Example:
```python
>>> from huggingface_hub import ModelCardData
>>> card_data = ModelCardData(
... language="en",
... license="mit",
... library_name="timm",
... tags=['image-classification', 'resnet'],
... )
>>> card_data.to_dict()
{'language': 'en', 'license': 'mit', 'library_name': 'timm', 'tags': ['image-classification', 'resnet']}
```
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#modelcarddata
|
#modelcarddata
|
.md
|
22_7
|
Dataset cards are also known as Data Cards in the ML Community.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#dataset-cards
|
#dataset-cards
|
.md
|
22_8
|
No docstring found for huggingface_hub.DatasetCard
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#datasetcard
|
#datasetcard
|
.md
|
22_9
|
```python
Dataset Card Metadata that is used by Hugging Face Hub when included at the top of your README.md
Args:
language (`List[str]`, *optional*):
Language of dataset's data or metadata. It must be an ISO 639-1, 639-2 or
639-3 code (two/three letters), or a special value like "code", "multilingual".
license (`Union[str, List[str]]`, *optional*):
License(s) of this dataset. Example: apache-2.0 or any license from
https://huggingface.co/docs/hub/repositories-licenses.
annotations_creators (`Union[str, List[str]]`, *optional*):
How the annotations for the dataset were created.
Options are: 'found', 'crowdsourced', 'expert-generated', 'machine-generated', 'no-annotation', 'other'.
language_creators (`Union[str, List[str]]`, *optional*):
How the text-based data in the dataset was created.
Options are: 'found', 'crowdsourced', 'expert-generated', 'machine-generated', 'other'
multilinguality (`Union[str, List[str]]`, *optional*):
Whether the dataset is multilingual.
Options are: 'monolingual', 'multilingual', 'translation', 'other'.
size_categories (`Union[str, List[str]]`, *optional*):
The number of examples in the dataset. Options are: 'n<1K', '1K<n<10K', '10K<n<100K',
'100K<n<1M', '1M<n<10M', '10M<n<100M', '100M<n<1B', '1B<n<10B', '10B<n<100B', '100B<n<1T', 'n>1T', and 'other'.
source_datasets (`List[str]]`, *optional*):
Indicates whether the dataset is an original dataset or extended from another existing dataset.
Options are: 'original' and 'extended'.
task_categories (`Union[str, List[str]]`, *optional*):
What categories of task does the dataset support?
task_ids (`Union[str, List[str]]`, *optional*):
What specific tasks does the dataset support?
paperswithcode_id (`str`, *optional*):
ID of the dataset on PapersWithCode.
pretty_name (`str`, *optional*):
A more human-readable name for the dataset. (ex. "Cats vs. Dogs")
train_eval_index (`Dict`, *optional*):
A dictionary that describes the necessary spec for doing evaluation on the Hub.
If not provided, it will be gathered from the 'train-eval-index' key of the kwargs.
config_names (`Union[str, List[str]]`, *optional*):
A list of the available dataset configs for the dataset.
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#datasetcarddata
|
#datasetcarddata
|
.md
|
22_10
|
No docstring found for huggingface_hub.SpaceCard
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#spacecard
|
#spacecard
|
.md
|
22_11
|
```python
Space Card Metadata that is used by Hugging Face Hub when included at the top of your README.md
To get an exhaustive reference of Spaces configuration, please visit https://huggingface.co/docs/hub/spaces-config-reference#spaces-configuration-reference.
Args:
title (`str`, *optional*)
Title of the Space.
sdk (`str`, *optional*)
SDK of the Space (one of `gradio`, `streamlit`, `docker`, or `static`).
sdk_version (`str`, *optional*)
Version of the used SDK (if Gradio/Streamlit sdk).
python_version (`str`, *optional*)
Python version used in the Space (if Gradio/Streamlit sdk).
app_file (`str`, *optional*)
Path to your main application file (which contains either gradio or streamlit Python code, or static html code).
Path is relative to the root of the repository.
app_port (`str`, *optional*)
Port on which your application is running. Used only if sdk is `docker`.
license (`str`, *optional*)
License of this model. Example: apache-2.0 or any license from
https://huggingface.co/docs/hub/repositories-licenses.
duplicated_from (`str`, *optional*)
ID of the original Space if this is a duplicated Space.
models (List[`str`], *optional*)
List of models related to this Space. Should be a dataset ID found on https://hf.co/models.
datasets (`List[str]`, *optional*)
List of datasets related to this Space. Should be a dataset ID found on https://hf.co/datasets.
tags (`List[str]`, *optional*)
List of tags to add to your Space that can be used when filtering on the Hub.
ignore_metadata_errors (`str`):
If True, errors while parsing the metadata section will be ignored. Some information might be lost during
the process. Use it at your own risk.
kwargs (`dict`, *optional*):
Additional metadata that will be added to the space card.
Example:
```python
>>> from huggingface_hub import SpaceCardData
>>> card_data = SpaceCardData(
... title="Dreambooth Training",
... license="mit",
... sdk="gradio",
... duplicated_from="multimodalart/dreambooth-training"
... )
>>> card_data.to_dict()
{'title': 'Dreambooth Training', 'sdk': 'gradio', 'license': 'mit', 'duplicated_from': 'multimodalart/dreambooth-training'}
```
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#spacecarddata
|
#spacecarddata
|
.md
|
22_12
|
```python
Flattened representation of individual evaluation results found in model-index of Model Cards.
For more information on the model-index spec, see https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1.
Args:
task_type (`str`):
The task identifier. Example: "image-classification".
dataset_type (`str`):
The dataset identifier. Example: "common_voice". Use dataset id from https://hf.co/datasets.
dataset_name (`str`):
A pretty name for the dataset. Example: "Common Voice (French)".
metric_type (`str`):
The metric identifier. Example: "wer". Use metric id from https://hf.co/metrics.
metric_value (`Any`):
The metric value. Example: 0.9 or "20.0 ± 1.2".
task_name (`str`, *optional*):
A pretty name for the task. Example: "Speech Recognition".
dataset_config (`str`, *optional*):
The name of the dataset configuration used in `load_dataset()`.
Example: fr in `load_dataset("common_voice", "fr")`. See the `datasets` docs for more info:
https://hf.co/docs/datasets/package_reference/loading_methods#datasets.load_dataset.name
dataset_split (`str`, *optional*):
The split used in `load_dataset()`. Example: "test".
dataset_revision (`str`, *optional*):
The revision (AKA Git Sha) of the dataset used in `load_dataset()`.
Example: 5503434ddd753f426f4b38109466949a1217c2bb
dataset_args (`Dict[str, Any]`, *optional*):
The arguments passed during `Metric.compute()`. Example for `bleu`: `{"max_order": 4}`
metric_name (`str`, *optional*):
A pretty name for the metric. Example: "Test WER".
metric_config (`str`, *optional*):
The name of the metric configuration used in `load_metric()`.
Example: bleurt-large-512 in `load_metric("bleurt", "bleurt-large-512")`.
See the `datasets` docs for more info: https://huggingface.co/docs/datasets/v2.1.0/en/loading#load-configurations
metric_args (`Dict[str, Any]`, *optional*):
The arguments passed during `Metric.compute()`. Example for `bleu`: max_order: 4
verified (`bool`, *optional*):
Indicates whether the metrics originate from Hugging Face's [evaluation service](https://huggingface.co/spaces/autoevaluate/model-evaluator) or not. Automatically computed by Hugging Face, do not set.
verify_token (`str`, *optional*):
A JSON Web Token that is used to verify whether the metrics originate from Hugging Face's [evaluation service](https://huggingface.co/spaces/autoevaluate/model-evaluator) or not.
source_name (`str`, *optional*):
The name of the source of the evaluation result. Example: "Open LLM Leaderboard".
source_url (`str`, *optional*):
The URL of the source of the evaluation result. Example: "https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard".
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#evalresult
|
#evalresult
|
.md
|
22_13
|
```python
Takes in a model index and returns the model name and a list of `huggingface_hub.EvalResult` objects.
A detailed spec of the model index can be found here:
https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
Args:
model_index (`List[Dict[str, Any]]`):
A model index data structure, likely coming from a README.md file on the
Hugging Face Hub.
Returns:
model_name (`str`):
The name of the model as found in the model index. This is used as the
identifier for the model on leaderboards like PapersWithCode.
eval_results (`List[EvalResult]`):
A list of `huggingface_hub.EvalResult` objects containing the metrics
reported in the provided model_index.
Example:
```python
>>> from huggingface_hub.repocard_data import model_index_to_eval_results
>>> # Define a minimal model index
>>> model_index = [
... {
... "name": "my-cool-model",
... "results": [
... {
... "task": {
... "type": "image-classification"
... },
... "dataset": {
... "type": "beans",
... "name": "Beans"
... },
... "metrics": [
... {
... "type": "accuracy",
... "value": 0.9
... }
... ]
... }
... ]
... }
... ]
>>> model_name, eval_results = model_index_to_eval_results(model_index)
>>> model_name
'my-cool-model'
>>> eval_results[0].task_type
'image-classification'
>>> eval_results[0].metric_type
'accuracy'
```
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#huggingfacehubrepocarddatamodelindextoevalresults
|
#huggingfacehubrepocarddatamodelindextoevalresults
|
.md
|
22_14
|
```python
Takes in given model name and list of `huggingface_hub.EvalResult` and returns a
valid model-index that will be compatible with the format expected by the
Hugging Face Hub.
Args:
model_name (`str`):
Name of the model (ex. "my-cool-model"). This is used as the identifier
for the model on leaderboards like PapersWithCode.
eval_results (`List[EvalResult]`):
List of `huggingface_hub.EvalResult` objects containing the metrics to be
reported in the model-index.
Returns:
model_index (`List[Dict[str, Any]]`): The eval_results converted to a model-index.
Example:
```python
>>> from huggingface_hub.repocard_data import eval_results_to_model_index, EvalResult
>>> # Define minimal eval_results
>>> eval_results = [
... EvalResult(
... task_type="image-classification", # Required
... dataset_type="beans", # Required
... dataset_name="Beans", # Required
... metric_type="accuracy", # Required
... metric_value=0.9, # Required
... )
... ]
>>> eval_results_to_model_index("my-cool-model", eval_results)
[{'name': 'my-cool-model', 'results': [{'task': {'type': 'image-classification'}, 'dataset': {'name': 'Beans', 'type': 'beans'}, 'metrics': [{'type': 'accuracy', 'value': 0.9}]}]}]
```
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#huggingfacehubrepocarddataevalresultstomodelindex
|
#huggingfacehubrepocarddataevalresultstomodelindex
|
.md
|
22_15
|
```python
Creates a metadata dict with the result from a model evaluated on a dataset.
Args:
model_pretty_name (`str`):
The name of the model in natural language.
task_pretty_name (`str`):
The name of a task in natural language.
task_id (`str`):
Example: automatic-speech-recognition. A task id.
metrics_pretty_name (`str`):
A name for the metric in natural language. Example: Test WER.
metrics_id (`str`):
Example: wer. A metric id from https://hf.co/metrics.
metrics_value (`Any`):
The value from the metric. Example: 20.0 or "20.0 ± 1.2".
dataset_pretty_name (`str`):
The name of the dataset in natural language.
dataset_id (`str`):
Example: common_voice. A dataset id from https://hf.co/datasets.
metrics_config (`str`, *optional*):
The name of the metric configuration used in `load_metric()`.
Example: bleurt-large-512 in `load_metric("bleurt", "bleurt-large-512")`.
metrics_verified (`bool`, *optional*, defaults to `False`):
Indicates whether the metrics originate from Hugging Face's [evaluation service](https://huggingface.co/spaces/autoevaluate/model-evaluator) or not. Automatically computed by Hugging Face, do not set.
dataset_config (`str`, *optional*):
Example: fr. The name of the dataset configuration used in `load_dataset()`.
dataset_split (`str`, *optional*):
Example: test. The name of the dataset split used in `load_dataset()`.
dataset_revision (`str`, *optional*):
Example: 5503434ddd753f426f4b38109466949a1217c2bb. The name of the dataset dataset revision
used in `load_dataset()`.
metrics_verification_token (`bool`, *optional*):
A JSON Web Token that is used to verify whether the metrics originate from Hugging Face's [evaluation service](https://huggingface.co/spaces/autoevaluate/model-evaluator) or not.
Returns:
`dict`: a metadata dict with the result from a model evaluated on a dataset.
Example:
```python
>>> from huggingface_hub import metadata_eval_result
>>> results = metadata_eval_result(
... model_pretty_name="RoBERTa fine-tuned on ReactionGIF",
... task_pretty_name="Text Classification",
... task_id="text-classification",
... metrics_pretty_name="Accuracy",
... metrics_id="accuracy",
... metrics_value=0.2662102282047272,
... dataset_pretty_name="ReactionJPEG",
... dataset_id="julien-c/reactionjpeg",
... dataset_config="default",
... dataset_split="test",
... )
>>> results == {
... 'model-index': [
... {
... 'name': 'RoBERTa fine-tuned on ReactionGIF',
... 'results': [
... {
... 'task': {
... 'type': 'text-classification',
... 'name': 'Text Classification'
... },
... 'dataset': {
... 'name': 'ReactionJPEG',
... 'type': 'julien-c/reactionjpeg',
... 'config': 'default',
... 'split': 'test'
... },
... 'metrics': [
... {
... 'type': 'accuracy',
... 'value': 0.2662102282047272,
... 'name': 'Accuracy',
... 'verified': False
... }
... ]
... }
... ]
... }
... ]
... }
True
```
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#huggingfacehubrepocardmetadataevalresult
|
#huggingfacehubrepocardmetadataevalresult
|
.md
|
22_16
|
```python
Updates the metadata in the README.md of a repository on the Hugging Face Hub.
If the README.md file doesn't exist yet, a new one is created with metadata and an
the default ModelCard or DatasetCard template. For `space` repo, an error is thrown
as a Space cannot exist without a `README.md` file.
Args:
repo_id (`str`):
The name of the repository.
metadata (`dict`):
A dictionary containing the metadata to be updated.
repo_type (`str`, *optional*):
Set to `"dataset"` or `"space"` if updating to a dataset or space,
`None` or `"model"` if updating to a model. Default is `None`.
overwrite (`bool`, *optional*, defaults to `False`):
If set to `True` an existing field can be overwritten, otherwise
attempting to overwrite an existing field will cause an error.
token (`str`, *optional*):
The Hugging Face authentication token.
commit_message (`str`, *optional*):
The summary / title / first line of the generated commit. Defaults to
`f"Update metadata with huggingface_hub"`
commit_description (`str` *optional*)
The description of the generated commit
revision (`str`, *optional*):
The git revision to commit from. Defaults to the head of the
`"main"` branch.
create_pr (`boolean`, *optional*):
Whether or not to create a Pull Request from `revision` with that commit.
Defaults to `False`.
parent_commit (`str`, *optional*):
The OID / SHA of the parent commit, as a hexadecimal string. Shorthands (7 first characters) are also supported.
If specified and `create_pr` is `False`, the commit will fail if `revision` does not point to `parent_commit`.
If specified and `create_pr` is `True`, the pull request will be created from `parent_commit`.
Specifying `parent_commit` ensures the repo has not changed before committing the changes, and can be
especially useful if the repo is updated / committed to concurrently.
Returns:
`str`: URL of the commit which updated the card metadata.
Example:
```python
>>> from huggingface_hub import metadata_update
>>> metadata = {'model-index': [{'name': 'RoBERTa fine-tuned on ReactionGIF',
... 'results': [{'dataset': {'name': 'ReactionGIF',
... 'type': 'julien-c/reactiongif'},
... 'metrics': [{'name': 'Recall',
... 'type': 'recall',
... 'value': 0.7762102282047272}],
... 'task': {'name': 'Text Classification',
... 'type': 'text-classification'}}]}]}
>>> url = metadata_update("hf-internal-testing/reactiongif-roberta-card", metadata)
```
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/package_reference/cards.md
|
https://huggingface.co/docs/huggingface_hub/en/package_reference/cards/#huggingfacehubrepocardmetadataupdate
|
#huggingfacehubrepocardmetadataupdate
|
.md
|
22_17
|
Inference Endpoints provides a secure production solution to easily deploy any `transformers`, `sentence-transformers`, and `diffusers` models on a dedicated and autoscaling infrastructure managed by Hugging Face. An Inference Endpoint is built from a model from the [Hub](https://huggingface.co/models).
In this guide, we will learn how to programmatically manage Inference Endpoints with `huggingface_hub`. For more information about the Inference Endpoints product itself, check out its [official documentation](https://huggingface.co/docs/inference-endpoints/index).
This guide assumes `huggingface_hub` is correctly installed and that your machine is logged in. Check out the [Quick Start guide](https://huggingface.co/docs/huggingface_hub/quick-start#quickstart) if that's not the case yet. The minimal version supporting Inference Endpoints API is `v0.19.0`.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference_endpoints/#inference-endpoints
|
#inference-endpoints
|
.md
|
23_0
|
The first step is to create an Inference Endpoint using [`create_inference_endpoint`]:
```py
>>> from huggingface_hub import create_inference_endpoint
>>> endpoint = create_inference_endpoint(
... "my-endpoint-name",
... repository="gpt2",
... framework="pytorch",
... task="text-generation",
... accelerator="cpu",
... vendor="aws",
... region="us-east-1",
... type="protected",
... instance_size="x2",
... instance_type="intel-icl"
... )
```
In this example, we created a `protected` Inference Endpoint named `"my-endpoint-name"`, to serve [gpt2](https://huggingface.co/gpt2) for `text-generation`. A `protected` Inference Endpoint means your token is required to access the API. We also need to provide additional information to configure the hardware requirements, such as vendor, region, accelerator, instance type, and size. You can check out the list of available resources [here](https://api.endpoints.huggingface.cloud/#/v2%3A%3Aprovider/list_vendors). Alternatively, you can create an Inference Endpoint manually using the [Web interface](https://ui.endpoints.huggingface.co/new) for convenience. Refer to this [guide](https://huggingface.co/docs/inference-endpoints/guides/advanced) for details on advanced settings and their usage.
The value returned by [`create_inference_endpoint`] is an [`InferenceEndpoint`] object:
```py
>>> endpoint
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
```
It's a dataclass that holds information about the endpoint. You can access important attributes such as `name`, `repository`, `status`, `task`, `created_at`, `updated_at`, etc. If you need it, you can also access the raw response from the server with `endpoint.raw`.
Once your Inference Endpoint is created, you can find it on your [personal dashboard](https://ui.endpoints.huggingface.co/).
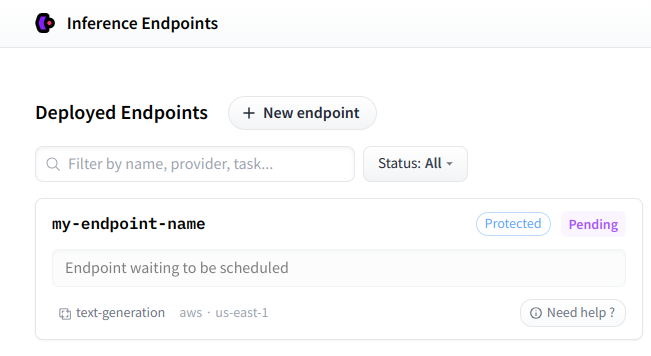
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference_endpoints/#create-an-inference-endpoint
|
#create-an-inference-endpoint
|
.md
|
23_1
|
By default the Inference Endpoint is built from a docker image provided by Hugging Face. However, it is possible to specify any docker image using the `custom_image` parameter. A common use case is to run LLMs using the [text-generation-inference](https://github.com/huggingface/text-generation-inference) framework. This can be done like this:
```python
# Start an Inference Endpoint running Zephyr-7b-beta on TGI
>>> from huggingface_hub import create_inference_endpoint
>>> endpoint = create_inference_endpoint(
... "aws-zephyr-7b-beta-0486",
... repository="HuggingFaceH4/zephyr-7b-beta",
... framework="pytorch",
... task="text-generation",
... accelerator="gpu",
... vendor="aws",
... region="us-east-1",
... type="protected",
... instance_size="x1",
... instance_type="nvidia-a10g",
... custom_image={
... "health_route": "/health",
... "env": {
... "MAX_BATCH_PREFILL_TOKENS": "2048",
... "MAX_INPUT_LENGTH": "1024",
... "MAX_TOTAL_TOKENS": "1512",
... "MODEL_ID": "/repository"
... },
... "url": "ghcr.io/huggingface/text-generation-inference:1.1.0",
... },
... )
```
The value to pass as `custom_image` is a dictionary containing a url to the docker container and configuration to run it. For more details about it, checkout the [Swagger documentation](https://api.endpoints.huggingface.cloud/#/v2%3A%3Aendpoint/create_endpoint).
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference_endpoints/#using-a-custom-image
|
#using-a-custom-image
|
.md
|
23_2
|
In some cases, you might need to manage Inference Endpoints you created previously. If you know the name, you can fetch it using [`get_inference_endpoint`], which returns an [`InferenceEndpoint`] object. Alternatively, you can use [`list_inference_endpoints`] to retrieve a list of all Inference Endpoints. Both methods accept an optional `namespace` parameter. You can set the `namespace` to any organization you are a part of. Otherwise, it defaults to your username.
```py
>>> from huggingface_hub import get_inference_endpoint, list_inference_endpoints
# Get one
>>> get_inference_endpoint("my-endpoint-name")
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
# List all endpoints from an organization
>>> list_inference_endpoints(namespace="huggingface")
[InferenceEndpoint(name='aws-starchat-beta', namespace='huggingface', repository='HuggingFaceH4/starchat-beta', status='paused', url=None), ...]
# List all endpoints from all organizations the user belongs to
>>> list_inference_endpoints(namespace="*")
[InferenceEndpoint(name='aws-starchat-beta', namespace='huggingface', repository='HuggingFaceH4/starchat-beta', status='paused', url=None), ...]
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference_endpoints/#get-or-list-existing-inference-endpoints
|
#get-or-list-existing-inference-endpoints
|
.md
|
23_3
|
In the rest of this guide, we will assume that we have a [`InferenceEndpoint`] object called `endpoint`. You might have noticed that the endpoint has a `status` attribute of type [`InferenceEndpointStatus`]. When the Inference Endpoint is deployed and accessible, the status should be `"running"` and the `url` attribute is set:
```py
>>> endpoint
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='running', url='https://jpj7k2q4j805b727.us-east-1.aws.endpoints.huggingface.cloud')
```
Before reaching a `"running"` state, the Inference Endpoint typically goes through an `"initializing"` or `"pending"` phase. You can fetch the new state of the endpoint by running [`~InferenceEndpoint.fetch`]. Like every other method from [`InferenceEndpoint`] that makes a request to the server, the internal attributes of `endpoint` are mutated in place:
```py
>>> endpoint.fetch()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
```
Instead of fetching the Inference Endpoint status while waiting for it to run, you can directly call [`~InferenceEndpoint.wait`]. This helper takes as input a `timeout` and a `fetch_every` parameter (in seconds) and will block the thread until the Inference Endpoint is deployed. Default values are respectively `None` (no timeout) and `5` seconds.
```py
# Pending endpoint
>>> endpoint
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
# Wait 10s => raises a InferenceEndpointTimeoutError
>>> endpoint.wait(timeout=10)
raise InferenceEndpointTimeoutError("Timeout while waiting for Inference Endpoint to be deployed.")
huggingface_hub._inference_endpoints.InferenceEndpointTimeoutError: Timeout while waiting for Inference Endpoint to be deployed.
# Wait more
>>> endpoint.wait()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='running', url='https://jpj7k2q4j805b727.us-east-1.aws.endpoints.huggingface.cloud')
```
If `timeout` is set and the Inference Endpoint takes too much time to load, a [`InferenceEndpointTimeoutError`] timeout error is raised.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference_endpoints/#check-deployment-status
|
#check-deployment-status
|
.md
|
23_4
|
Once your Inference Endpoint is up and running, you can finally run inference on it!
[`InferenceEndpoint`] has two properties `client` and `async_client` returning respectively an [`InferenceClient`] and an [`AsyncInferenceClient`] objects.
```py
# Run text_generation task:
>>> endpoint.client.text_generation("I am")
' not a fan of the idea of a "big-budget" movie. I think it\'s a'
# Or in an asyncio context:
>>> await endpoint.async_client.text_generation("I am")
```
If the Inference Endpoint is not running, an [`InferenceEndpointError`] exception is raised:
```py
>>> endpoint.client
huggingface_hub._inference_endpoints.InferenceEndpointError: Cannot create a client for this Inference Endpoint as it is not yet deployed. Please wait for the Inference Endpoint to be deployed using `endpoint.wait()` and try again.
```
For more details about how to use the [`InferenceClient`], check out the [Inference guide](../guides/inference).
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference_endpoints/#run-inference
|
#run-inference
|
.md
|
23_5
|
Now that we saw how to create an Inference Endpoint and run inference on it, let's see how to manage its lifecycle.
<Tip>
In this section, we will see methods like [`~InferenceEndpoint.pause`], [`~InferenceEndpoint.resume`], [`~InferenceEndpoint.scale_to_zero`], [`~InferenceEndpoint.update`] and [`~InferenceEndpoint.delete`]. All of those methods are aliases added to [`InferenceEndpoint`] for convenience. If you prefer, you can also use the generic methods defined in `HfApi`: [`pause_inference_endpoint`], [`resume_inference_endpoint`], [`scale_to_zero_inference_endpoint`], [`update_inference_endpoint`], and [`delete_inference_endpoint`].
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference_endpoints/#manage-lifecycle
|
#manage-lifecycle
|
.md
|
23_6
|
To reduce costs when your Inference Endpoint is not in use, you can choose to either pause it using [`~InferenceEndpoint.pause`] or scale it to zero using [`~InferenceEndpoint.scale_to_zero`].
<Tip>
An Inference Endpoint that is *paused* or *scaled to zero* doesn't cost anything. The difference between those two is that a *paused* endpoint needs to be explicitly *resumed* using [`~InferenceEndpoint.resume`]. On the contrary, a *scaled to zero* endpoint will automatically start if an inference call is made to it, with an additional cold start delay. An Inference Endpoint can also be configured to scale to zero automatically after a certain period of inactivity.
</Tip>
```py
# Pause and resume endpoint
>>> endpoint.pause()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='paused', url=None)
>>> endpoint.resume()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='pending', url=None)
>>> endpoint.wait().client.text_generation(...)
...
# Scale to zero
>>> endpoint.scale_to_zero()
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2', status='scaledToZero', url='https://jpj7k2q4j805b727.us-east-1.aws.endpoints.huggingface.cloud')
# Endpoint is not 'running' but still has a URL and will restart on first call.
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference_endpoints/#pause-or-scale-to-zero
|
#pause-or-scale-to-zero
|
.md
|
23_7
|
In some cases, you might also want to update your Inference Endpoint without creating a new one. You can either update the hosted model or the hardware requirements to run the model. You can do this using [`~InferenceEndpoint.update`]:
```py
# Change target model
>>> endpoint.update(repository="gpt2-large")
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2-large', status='pending', url=None)
# Update number of replicas
>>> endpoint.update(min_replica=2, max_replica=6)
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2-large', status='pending', url=None)
# Update to larger instance
>>> endpoint.update(accelerator="cpu", instance_size="x4", instance_type="intel-icl")
InferenceEndpoint(name='my-endpoint-name', namespace='Wauplin', repository='gpt2-large', status='pending', url=None)
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference_endpoints/#update-model-or-hardware-requirements
|
#update-model-or-hardware-requirements
|
.md
|
23_8
|
Finally if you won't use the Inference Endpoint anymore, you can simply call [`~InferenceEndpoint.delete()`].
<Tip warning={true}>
This is a non-revertible action that will completely remove the endpoint, including its configuration, logs and usage metrics. You cannot restore a deleted Inference Endpoint.
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference_endpoints/#delete-the-endpoint
|
#delete-the-endpoint
|
.md
|
23_9
|
A typical use case of Inference Endpoints is to process a batch of jobs at once to limit the infrastructure costs. You can automate this process using what we saw in this guide:
```py
>>> import asyncio
>>> from huggingface_hub import create_inference_endpoint
# Start endpoint + wait until initialized
>>> endpoint = create_inference_endpoint(name="batch-endpoint",...).wait()
# Run inference
>>> client = endpoint.client
>>> results = [client.text_generation(...) for job in jobs]
# Or with asyncio
>>> async_client = endpoint.async_client
>>> results = asyncio.gather(*[async_client.text_generation(...) for job in jobs])
# Pause endpoint
>>> endpoint.pause()
```
Or if your Inference Endpoint already exists and is paused:
```py
>>> import asyncio
>>> from huggingface_hub import get_inference_endpoint
# Get endpoint + wait until initialized
>>> endpoint = get_inference_endpoint("batch-endpoint").resume().wait()
# Run inference
>>> async_client = endpoint.async_client
>>> results = asyncio.gather(*[async_client.text_generation(...) for job in jobs])
# Pause endpoint
>>> endpoint.pause()
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference_endpoints.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference_endpoints/#an-end-to-end-example
|
#an-end-to-end-example
|
.md
|
23_10
|
<!--⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/
|
.md
|
24_0
|
|
Inference is the process of using a trained model to make predictions on new data. As this process can be compute-intensive,
running on a dedicated server can be an interesting option. The `huggingface_hub` library provides an easy way to call a
service that runs inference for hosted models. There are several services you can connect to:
- [Inference API](https://huggingface.co/docs/api-inference/index): a service that allows you to run accelerated inference
on Hugging Face's infrastructure for free. This service is a fast way to get started, test different models, and
prototype AI products.
- [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index): a product to easily deploy models to production.
Inference is run by Hugging Face in a dedicated, fully managed infrastructure on a cloud provider of your choice.
These services can be called with the [`InferenceClient`] object. It acts as a replacement for the legacy
[`InferenceApi`] client, adding specific support for tasks and handling inference on both
[Inference API](https://huggingface.co/docs/api-inference/index) and [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index).
Learn how to migrate to the new client in the [Legacy InferenceAPI client](#legacy-inferenceapi-client) section.
<Tip>
[`InferenceClient`] is a Python client making HTTP calls to our APIs. If you want to make the HTTP calls directly using
your preferred tool (curl, postman,...), please refer to the [Inference API](https://huggingface.co/docs/api-inference/index)
or to the [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index) documentation pages.
For web development, a [JS client](https://huggingface.co/docs/huggingface.js/inference/README) has been released.
If you are interested in game development, you might have a look at our [C# project](https://github.com/huggingface/unity-api).
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#run-inference-on-servers
|
#run-inference-on-servers
|
.md
|
24_1
|
Let's get started with a text-to-image task:
```python
>>> from huggingface_hub import InferenceClient
>>> client = InferenceClient()
>>> image = client.text_to_image("An astronaut riding a horse on the moon.")
>>> image.save("astronaut.png") # 'image' is a PIL.Image object
```
In the example above, we initialized an [`InferenceClient`] with the default parameters. The only thing you need to know is the [task](#supported-tasks) you want to perform. By default, the client will connect to the Inference API and select a model to complete the task. In our example, we generated an image from a text prompt. The returned value is a `PIL.Image` object that can be saved to a file. For more details, check out the [`~InferenceClient.text_to_image`] documentation.
Let's now see an example using the [~`InferenceClient.chat_completion`] API. This task uses an LLM to generate a response from a list of messages:
```python
>>> from huggingface_hub import InferenceClient
>>> messages = [{"role": "user", "content": "What is the capital of France?"}]
>>> client = InferenceClient("meta-llama/Meta-Llama-3-8B-Instruct")
>>> client.chat_completion(messages, max_tokens=100)
ChatCompletionOutput(
choices=[
ChatCompletionOutputComplete(
finish_reason='eos_token',
index=0,
message=ChatCompletionOutputMessage(
role='assistant',
content='The capital of France is Paris.',
name=None,
tool_calls=None
),
logprobs=None
)
],
created=1719907176,
id='',
model='meta-llama/Meta-Llama-3-8B-Instruct',
object='text_completion',
system_fingerprint='2.0.4-sha-f426a33',
usage=ChatCompletionOutputUsage(
completion_tokens=8,
prompt_tokens=17,
total_tokens=25
)
)
```
In this example, we specified which model we want to use (`"meta-llama/Meta-Llama-3-8B-Instruct"`). You can find a list of compatible models [on this page](https://huggingface.co/models?other=conversational&sort=likes). We then gave a list of messages to complete (here, a single question) and passed an additional parameter to API (`max_token=100`). The output is a `ChatCompletionOutput` object that follows the OpenAI specification. The generated content can be accessed with `output.choices[0].message.content`. For more details, check out the [`~InferenceClient.chat_completion`] documentation.
<Tip warning={true}>
The API is designed to be simple. Not all parameters and options are available or described for the end user. Check out
[this page](https://huggingface.co/docs/api-inference/detailed_parameters) if you are interested in learning more about
all the parameters available for each task.
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#getting-started
|
#getting-started
|
.md
|
24_2
|
What if you want to use a specific model? You can specify it either as a parameter or directly at an instance level:
```python
>>> from huggingface_hub import InferenceClient
# Initialize client for a specific model
>>> client = InferenceClient(model="prompthero/openjourney-v4")
>>> client.text_to_image(...)
# Or use a generic client but pass your model as an argument
>>> client = InferenceClient()
>>> client.text_to_image(..., model="prompthero/openjourney-v4")
```
<Tip>
There are more than 200k models on the Hugging Face Hub! Each task in the [`InferenceClient`] comes with a recommended
model. Be aware that the HF recommendation can change over time without prior notice. Therefore it is best to explicitly
set a model once you are decided. Also, in most cases you'll be interested in finding a model specific to _your_ needs.
Visit the [Models](https://huggingface.co/models) page on the Hub to explore your possibilities.
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#using-a-specific-model
|
#using-a-specific-model
|
.md
|
24_3
|
The examples we saw above use the Serverless Inference API. This proves to be very useful for prototyping
and testing things quickly. Once you're ready to deploy your model to production, you'll need to use a dedicated infrastructure.
That's where [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index) comes into play. It allows you to deploy
any model and expose it as a private API. Once deployed, you'll get a URL that you can connect to using exactly the same
code as before, changing only the `model` parameter:
```python
>>> from huggingface_hub import InferenceClient
>>> client = InferenceClient(model="https://uu149rez6gw9ehej.eu-west-1.aws.endpoints.huggingface.cloud/deepfloyd-if")
# or
>>> client = InferenceClient()
>>> client.text_to_image(..., model="https://uu149rez6gw9ehej.eu-west-1.aws.endpoints.huggingface.cloud/deepfloyd-if")
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#using-a-specific-url
|
#using-a-specific-url
|
.md
|
24_4
|
Calls made with the [`InferenceClient`] can be authenticated using a [User Access Token](https://huggingface.co/docs/hub/security-tokens).
By default, it will use the token saved on your machine if you are logged in (check out
[how to authenticate](https://huggingface.co/docs/huggingface_hub/quick-start#authentication)). If you are not logged in, you can pass
your token as an instance parameter:
```python
>>> from huggingface_hub import InferenceClient
>>> client = InferenceClient(token="hf_***")
```
<Tip>
Authentication is NOT mandatory when using the Inference API. However, authenticated users get a higher free-tier to
play with the service. Token is also mandatory if you want to run inference on your private models or on private
endpoints.
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#authentication
|
#authentication
|
.md
|
24_5
|
The `chat_completion` task follows [OpenAI's Python client](https://github.com/openai/openai-python) syntax. What does it mean for you? It means that if you are used to play with `OpenAI`'s APIs you will be able to switch to `huggingface_hub.InferenceClient` to work with open-source models by updating just 2 line of code!
```diff
- from openai import OpenAI
+ from huggingface_hub import InferenceClient
- client = OpenAI(
+ client = InferenceClient(
base_url=...,
api_key=...,
)
output = client.chat.completions.create(
model="meta-llama/Meta-Llama-3-8B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Count to 10"},
],
stream=True,
max_tokens=1024,
)
for chunk in output:
print(chunk.choices[0].delta.content)
```
And that's it! The only required changes are to replace `from openai import OpenAI` by `from huggingface_hub import InferenceClient` and `client = OpenAI(...)` by `client = InferenceClient(...)`. You can choose any LLM model from the Hugging Face Hub by passing its model id as `model` parameter. [Here is a list](https://huggingface.co/models?pipeline_tag=text-generation&other=conversational,text-generation-inference&sort=trending) of supported models. For authentication, you should pass a valid [User Access Token](https://huggingface.co/settings/tokens) as `api_key` or authenticate using `huggingface_hub` (see the [authentication guide](https://huggingface.co/docs/huggingface_hub/quick-start#authentication)).
All input parameters and output format are strictly the same. In particular, you can pass `stream=True` to receive tokens as they are generated. You can also use the [`AsyncInferenceClient`] to run inference using `asyncio`:
```diff
import asyncio
- from openai import AsyncOpenAI
+ from huggingface_hub import AsyncInferenceClient
- client = AsyncOpenAI()
+ client = AsyncInferenceClient()
async def main():
stream = await client.chat.completions.create(
model="meta-llama/Meta-Llama-3-8B-Instruct",
messages=[{"role": "user", "content": "Say this is a test"}],
stream=True,
)
async for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
asyncio.run(main())
```
You might wonder why using [`InferenceClient`] instead of OpenAI's client? There are a few reasons for that:
1. [`InferenceClient`] is configured for Hugging Face services. You don't need to provide a `base_url` to run models on the serverless Inference API. You also don't need to provide a `token` or `api_key` if your machine is already correctly logged in.
2. [`InferenceClient`] is tailored for both Text-Generation-Inference (TGI) and `transformers` frameworks, meaning you are assured it will always be on-par with the latest updates.
3. [`InferenceClient`] is integrated with our Inference Endpoints service, making it easier to launch an Inference Endpoint, check its status and run inference on it. Check out the [Inference Endpoints](./inference_endpoints.md) guide for more details.
<Tip>
`InferenceClient.chat.completions.create` is simply an alias for `InferenceClient.chat_completion`. Check out the package reference of [`~InferenceClient.chat_completion`] for more details. `base_url` and `api_key` parameters when instantiating the client are also aliases for `model` and `token`. These aliases have been defined to reduce friction when switching from `OpenAI` to `InferenceClient`.
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#openai-compatibility
|
#openai-compatibility
|
.md
|
24_6
|
[`InferenceClient`]'s goal is to provide the easiest interface to run inference on Hugging Face models. It
has a simple API that supports the most common tasks. Here is a list of the currently supported tasks:
| Domain | Task | Supported | Documentation |
|--------|--------------------------------|--------------|------------------------------------|
| Audio | [Audio Classification](https://huggingface.co/tasks/audio-classification) | ✅ | [`~InferenceClient.audio_classification`] |
| Audio | [Audio-to-Audio](https://huggingface.co/tasks/audio-to-audio) | ✅ | [`~InferenceClient.audio_to_audio`] |
| | [Automatic Speech Recognition](https://huggingface.co/tasks/automatic-speech-recognition) | ✅ | [`~InferenceClient.automatic_speech_recognition`] |
| | [Text-to-Speech](https://huggingface.co/tasks/text-to-speech) | ✅ | [`~InferenceClient.text_to_speech`] |
| Computer Vision | [Image Classification](https://huggingface.co/tasks/image-classification) | ✅ | [`~InferenceClient.image_classification`] |
| | [Image Segmentation](https://huggingface.co/tasks/image-segmentation) | ✅ | [`~InferenceClient.image_segmentation`] |
| | [Image-to-Image](https://huggingface.co/tasks/image-to-image) | ✅ | [`~InferenceClient.image_to_image`] |
| | [Image-to-Text](https://huggingface.co/tasks/image-to-text) | ✅ | [`~InferenceClient.image_to_text`] |
| | [Object Detection](https://huggingface.co/tasks/object-detection) | ✅ | [`~InferenceClient.object_detection`] |
| | [Text-to-Image](https://huggingface.co/tasks/text-to-image) | ✅ | [`~InferenceClient.text_to_image`] |
| | [Zero-Shot-Image-Classification](https://huggingface.co/tasks/zero-shot-image-classification) | ✅ | [`~InferenceClient.zero_shot_image_classification`] |
| Multimodal | [Documentation Question Answering](https://huggingface.co/tasks/document-question-answering) | ✅ | [`~InferenceClient.document_question_answering`]
| | [Visual Question Answering](https://huggingface.co/tasks/visual-question-answering) | ✅ | [`~InferenceClient.visual_question_answering`] |
| NLP | Conversational | | *deprecated*, use Chat Completion |
| | [Chat Completion](https://huggingface.co/tasks/text-generation) | ✅ | [`~InferenceClient.chat_completion`] |
| | [Feature Extraction](https://huggingface.co/tasks/feature-extraction) | ✅ | [`~InferenceClient.feature_extraction`] |
| | [Fill Mask](https://huggingface.co/tasks/fill-mask) | ✅ | [`~InferenceClient.fill_mask`] |
| | [Question Answering](https://huggingface.co/tasks/question-answering) | ✅ | [`~InferenceClient.question_answering`]
| | [Sentence Similarity](https://huggingface.co/tasks/sentence-similarity) | ✅ | [`~InferenceClient.sentence_similarity`] |
| | [Summarization](https://huggingface.co/tasks/summarization) | ✅ | [`~InferenceClient.summarization`] |
| | [Table Question Answering](https://huggingface.co/tasks/table-question-answering) | ✅ | [`~InferenceClient.table_question_answering`] |
| | [Text Classification](https://huggingface.co/tasks/text-classification) | ✅ | [`~InferenceClient.text_classification`] |
| | [Text Generation](https://huggingface.co/tasks/text-generation) | ✅ | [`~InferenceClient.text_generation`] |
| | [Token Classification](https://huggingface.co/tasks/token-classification) | ✅ | [`~InferenceClient.token_classification`] |
| | [Translation](https://huggingface.co/tasks/translation) | ✅ | [`~InferenceClient.translation`] |
| | [Zero Shot Classification](https://huggingface.co/tasks/zero-shot-classification) | ✅ | [`~InferenceClient.zero_shot_classification`] |
| Tabular | [Tabular Classification](https://huggingface.co/tasks/tabular-classification) | ✅ | [`~InferenceClient.tabular_classification`] |
| | [Tabular Regression](https://huggingface.co/tasks/tabular-regression) | ✅ | [`~InferenceClient.tabular_regression`] |
<Tip>
Check out the [Tasks](https://huggingface.co/tasks) page to learn more about each task, how to use them, and the
most popular models for each task.
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#supported-tasks
|
#supported-tasks
|
.md
|
24_7
|
However, it is not always possible to cover all use cases. For custom requests, the [`InferenceClient.post`] method
gives you the flexibility to send any request to the Inference API. For example, you can specify how to parse the inputs
and outputs. In the example below, the generated image is returned as raw bytes instead of parsing it as a `PIL Image`.
This can be helpful if you don't have `Pillow` installed in your setup and just care about the binary content of the
image. [`InferenceClient.post`] is also useful to handle tasks that are not yet officially supported.
```python
>>> from huggingface_hub import InferenceClient
>>> client = InferenceClient()
>>> response = client.post(json={"inputs": "An astronaut riding a horse on the moon."}, model="stabilityai/stable-diffusion-2-1")
>>> response.content # raw bytes
b'...'
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#custom-requests
|
#custom-requests
|
.md
|
24_8
|
An async version of the client is also provided, based on `asyncio` and `aiohttp`. You can either install `aiohttp`
directly or use the `[inference]` extra:
```sh
pip install --upgrade huggingface_hub[inference]
# or
# pip install aiohttp
```
After installation all async API endpoints are available via [`AsyncInferenceClient`]. Its initialization and APIs are
strictly the same as the sync-only version.
```py
# Code must be run in an asyncio concurrent context.
# $ python -m asyncio
>>> from huggingface_hub import AsyncInferenceClient
>>> client = AsyncInferenceClient()
>>> image = await client.text_to_image("An astronaut riding a horse on the moon.")
>>> image.save("astronaut.png")
>>> async for token in await client.text_generation("The Huggingface Hub is", stream=True):
... print(token, end="")
a platform for sharing and discussing ML-related content.
```
For more information about the `asyncio` module, please refer to the [official documentation](https://docs.python.org/3/library/asyncio.html).
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#async-client
|
#async-client
|
.md
|
24_9
|
In the above section, we saw the main aspects of [`InferenceClient`]. Let's dive into some more advanced tips.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#advanced-tips
|
#advanced-tips
|
.md
|
24_10
|
When doing inference, there are two main causes for a timeout:
- The inference process takes a long time to complete.
- The model is not available, for example when Inference API is loading it for the first time.
[`InferenceClient`] has a global `timeout` parameter to handle those two aspects. By default, it is set to `None`,
meaning that the client will wait indefinitely for the inference to complete. If you want more control in your workflow,
you can set it to a specific value in seconds. If the timeout delay expires, an [`InferenceTimeoutError`] is raised.
You can catch it and handle it in your code:
```python
>>> from huggingface_hub import InferenceClient, InferenceTimeoutError
>>> client = InferenceClient(timeout=30)
>>> try:
... client.text_to_image(...)
... except InferenceTimeoutError:
... print("Inference timed out after 30s.")
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#timeout
|
#timeout
|
.md
|
24_11
|
Some tasks require binary inputs, for example, when dealing with images or audio files. In this case, [`InferenceClient`]
tries to be as permissive as possible and accept different types:
- raw `bytes`
- a file-like object, opened as binary (`with open("audio.flac", "rb") as f: ...`)
- a path (`str` or `Path`) pointing to a local file
- a URL (`str`) pointing to a remote file (e.g. `https://...`). In this case, the file will be downloaded locally before
sending it to the Inference API.
```py
>>> from huggingface_hub import InferenceClient
>>> client = InferenceClient()
>>> client.image_classification("https://upload.wikimedia.org/wikipedia/commons/thumb/4/43/Cute_dog.jpg/320px-Cute_dog.jpg")
[{'score': 0.9779096841812134, 'label': 'Blenheim spaniel'}, ...]
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#binary-inputs
|
#binary-inputs
|
.md
|
24_12
|
[`InferenceClient`] acts as a replacement for the legacy [`InferenceApi`] client. It adds specific support for tasks and
handles inference on both [Inference API](https://huggingface.co/docs/api-inference/index) and [Inference Endpoints](https://huggingface.co/docs/inference-endpoints/index).
Here is a short guide to help you migrate from [`InferenceApi`] to [`InferenceClient`].
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#legacy-inferenceapi-client
|
#legacy-inferenceapi-client
|
.md
|
24_13
|
Change from
```python
>>> from huggingface_hub import InferenceApi
>>> inference = InferenceApi(repo_id="bert-base-uncased", token=API_TOKEN)
```
to
```python
>>> from huggingface_hub import InferenceClient
>>> inference = InferenceClient(model="bert-base-uncased", token=API_TOKEN)
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#initialization
|
#initialization
|
.md
|
24_14
|
Change from
```python
>>> from huggingface_hub import InferenceApi
>>> inference = InferenceApi(repo_id="paraphrase-xlm-r-multilingual-v1", task="feature-extraction")
>>> inference(...)
```
to
```python
>>> from huggingface_hub import InferenceClient
>>> inference = InferenceClient()
>>> inference.feature_extraction(..., model="paraphrase-xlm-r-multilingual-v1")
```
<Tip>
This is the recommended way to adapt your code to [`InferenceClient`]. It lets you benefit from the task-specific
methods like `feature_extraction`.
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#run-on-a-specific-task
|
#run-on-a-specific-task
|
.md
|
24_15
|
Change from
```python
>>> from huggingface_hub import InferenceApi
>>> inference = InferenceApi(repo_id="bert-base-uncased")
>>> inference(inputs="The goal of life is [MASK].")
[{'sequence': 'the goal of life is life.', 'score': 0.10933292657136917, 'token': 2166, 'token_str': 'life'}]
```
to
```python
>>> from huggingface_hub import InferenceClient
>>> client = InferenceClient()
>>> response = client.post(json={"inputs": "The goal of life is [MASK]."}, model="bert-base-uncased")
>>> response.json()
[{'sequence': 'the goal of life is life.', 'score': 0.10933292657136917, 'token': 2166, 'token_str': 'life'}]
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#run-custom-request
|
#run-custom-request
|
.md
|
24_16
|
Change from
```python
>>> from huggingface_hub import InferenceApi
>>> inference = InferenceApi(repo_id="typeform/distilbert-base-uncased-mnli")
>>> inputs = "Hi, I recently bought a device from your company but it is not working as advertised and I would like to get reimbursed!"
>>> params = {"candidate_labels":["refund", "legal", "faq"]}
>>> inference(inputs, params)
{'sequence': 'Hi, I recently bought a device from your company but it is not working as advertised and I would like to get reimbursed!', 'labels': ['refund', 'faq', 'legal'], 'scores': [0.9378499388694763, 0.04914155602455139, 0.013008488342165947]}
```
to
```python
>>> from huggingface_hub import InferenceClient
>>> client = InferenceClient()
>>> inputs = "Hi, I recently bought a device from your company but it is not working as advertised and I would like to get reimbursed!"
>>> params = {"candidate_labels":["refund", "legal", "faq"]}
>>> response = client.post(json={"inputs": inputs, "parameters": params}, model="typeform/distilbert-base-uncased-mnli")
>>> response.json()
{'sequence': 'Hi, I recently bought a device from your company but it is not working as advertised and I would like to get reimbursed!', 'labels': ['refund', 'faq', 'legal'], 'scores': [0.9378499388694763, 0.04914155602455139, 0.013008488342165947]}
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/inference.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/inference/#run-with-parameters
|
#run-with-parameters
|
.md
|
24_17
|
<!--⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/search.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/search/
|
.md
|
25_0
|
|
In this tutorial, you will learn how to search models, datasets and spaces on the Hub using `huggingface_hub`.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/search.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/search/#search-the-hub
|
#search-the-hub
|
.md
|
25_1
|
`huggingface_hub` library includes an HTTP client [`HfApi`] to interact with the Hub.
Among other things, it can list models, datasets and spaces stored on the Hub:
```py
>>> from huggingface_hub import HfApi
>>> api = HfApi()
>>> models = api.list_models()
```
The output of [`list_models`] is an iterator over the models stored on the Hub.
Similarly, you can use [`list_datasets`] to list datasets and [`list_spaces`] to list Spaces.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/search.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/search/#how-to-list-repositories-
|
#how-to-list-repositories-
|
.md
|
25_2
|
Listing repositories is great but now you might want to filter your search.
The list helpers have several attributes like:
- `filter`
- `author`
- `search`
- ...
Let's see an example to get all models on the Hub that does image classification, have been trained on the imagenet dataset and that runs with PyTorch.
```py
models = hf_api.list_models(
task="image-classification",
library="pytorch",
trained_dataset="imagenet",
)
```
While filtering, you can also sort the models and take only the top results. For example,
the following example fetches the top 5 most downloaded datasets on the Hub:
```py
>>> list(list_datasets(sort="downloads", direction=-1, limit=5))
[DatasetInfo(
id='argilla/databricks-dolly-15k-curated-en',
author='argilla',
sha='4dcd1dedbe148307a833c931b21ca456a1fc4281',
last_modified=datetime.datetime(2023, 10, 2, 12, 32, 53, tzinfo=datetime.timezone.utc),
private=False,
downloads=8889377,
(...)
```
To explore available filters on the Hub, visit [models](https://huggingface.co/models) and [datasets](https://huggingface.co/datasets) pages
in your browser, search for some parameters and look at the values in the URL.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/search.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/search/#how-to-filter-repositories-
|
#how-to-filter-repositories-
|
.md
|
25_3
|
<!--⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/overview.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/overview/
|
.md
|
26_0
|
|
In this section, you will find practical guides to help you achieve a specific goal.
Take a look at these guides to learn how to use huggingface_hub to solve real-world problems:
<div class="mt-10">
<div class="w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-3 md:gap-y-4 md:gap-x-5">
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./repository">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Repository
</div><p class="text-gray-700">
How to create a repository on the Hub? How to configure it? How to interact with it?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./download">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Download files
</div><p class="text-gray-700">
How do I download a file from the Hub? How do I download a repository?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./upload">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Upload files
</div><p class="text-gray-700">
How to upload a file or a folder? How to make changes to an existing repository on the Hub?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./search">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Search
</div><p class="text-gray-700">
How to efficiently search through the 200k+ public models, datasets and spaces?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./hf_file_system">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
HfFileSystem
</div><p class="text-gray-700">
How to interact with the Hub through a convenient interface that mimics Python's file interface?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./inference">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Inference
</div><p class="text-gray-700">
How to make predictions using the accelerated Inference API?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./community">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Community Tab
</div><p class="text-gray-700">
How to interact with the Community tab (Discussions and Pull Requests)?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./collections">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Collections
</div><p class="text-gray-700">
How to programmatically build collections?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./manage-cache">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Cache
</div><p class="text-gray-700">
How does the cache-system work? How to benefit from it?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./model-cards">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Model Cards
</div><p class="text-gray-700">
How to create and share Model Cards?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./manage-spaces">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Manage your Space
</div><p class="text-gray-700">
How to manage your Space hardware and configuration?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./integrations">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Integrate a library
</div><p class="text-gray-700">
What does it mean to integrate a library with the Hub? And how to do it?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./webhooks_server">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Webhooks server
</div><p class="text-gray-700">
How to create a server to receive Webhooks and deploy it as a Space?
</p>
</a>
</div>
</div>
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/overview.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/overview/#how-to-guides
|
#how-to-guides
|
.md
|
26_1
|
<!--⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/collections.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/collections/
|
.md
|
27_0
|
|
A collection is a group of related items on the Hub (models, datasets, Spaces, papers) that are organized together on the same page. Collections are useful for creating your own portfolio, bookmarking content in categories, or presenting a curated list of items you want to share. Check out this [guide](https://huggingface.co/docs/hub/collections) to understand in more detail what collections are and how they look on the Hub.
You can directly manage collections in the browser, but in this guide, we will focus on how to manage them programmatically.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/collections.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/collections/#collections
|
#collections
|
.md
|
27_1
|
Use [`get_collection`] to fetch your collections or any public ones. You must have the collection's *slug* to retrieve a collection. A slug is an identifier for a collection based on the title and a unique ID. You can find the slug in the URL of the collection page.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hfh_collection_slug.png"/>
</div>
Let's fetch the collection with, `"TheBloke/recent-models-64f9a55bb3115b4f513ec026"`:
```py
>>> from huggingface_hub import get_collection
>>> collection = get_collection("TheBloke/recent-models-64f9a55bb3115b4f513ec026")
>>> collection
Collection(
slug='TheBloke/recent-models-64f9a55bb3115b4f513ec026',
title='Recent models',
owner='TheBloke',
items=[...],
last_updated=datetime.datetime(2023, 10, 2, 22, 56, 48, 632000, tzinfo=datetime.timezone.utc),
position=1,
private=False,
theme='green',
upvotes=90,
description="Models I've recently quantized. Please note that currently this list has to be updated manually, and therefore is not guaranteed to be up-to-date."
)
>>> collection.items[0]
CollectionItem(
item_object_id='651446103cd773a050bf64c2',
item_id='TheBloke/U-Amethyst-20B-AWQ',
item_type='model',
position=88,
note=None
)
```
The [`Collection`] object returned by [`get_collection`] contains:
- high-level metadata: `slug`, `owner`, `title`, `description`, etc.
- a list of [`CollectionItem`] objects; each item represents a model, a dataset, a Space, or a paper.
All collection items are guaranteed to have:
- a unique `item_object_id`: this is the id of the collection item in the database
- an `item_id`: this is the id on the Hub of the underlying item (model, dataset, Space, paper); it is not necessarily unique, and only the `item_id`/`item_type` pair is unique
- an `item_type`: model, dataset, Space, paper
- the `position` of the item in the collection, which can be updated to reorganize your collection (see [`update_collection_item`] below)
A `note` can also be attached to the item. This is useful to add additional information about the item (a comment, a link to a blog post, etc.). The attribute still has a `None` value if an item doesn't have a note.
In addition to these base attributes, returned items can have additional attributes depending on their type: `author`, `private`, `lastModified`, `gated`, `title`, `likes`, `upvotes`, etc. None of these attributes are guaranteed to be returned.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/collections.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/collections/#fetch-a-collection
|
#fetch-a-collection
|
.md
|
27_2
|
We can also retrieve collections using [`list_collections`]. Collections can be filtered using some parameters. Let's list all the collections from the user [`teknium`](https://huggingface.co/teknium).
```py
>>> from huggingface_hub import list_collections
>>> collections = list_collections(owner="teknium")
```
This returns an iterable of `Collection` objects. We can iterate over them to print, for example, the number of upvotes for each collection.
```py
>>> for collection in collections:
... print("Number of upvotes:", collection.upvotes)
Number of upvotes: 1
Number of upvotes: 5
```
<Tip warning={true}>
When listing collections, the item list per collection is truncated to 4 items maximum. To retrieve all items from a collection, you must use [`get_collection`].
</Tip>
It is possible to do more advanced filtering. Let's get all collections containing the model [TheBloke/OpenHermes-2.5-Mistral-7B-GGUF](https://huggingface.co/TheBloke/OpenHermes-2.5-Mistral-7B-GGUF), sorted by trending, and limit the count to 5.
```py
>>> collections = list_collections(item="models/TheBloke/OpenHermes-2.5-Mistral-7B-GGUF", sort="trending", limit=5):
>>> for collection in collections:
... print(collection.slug)
teknium/quantized-models-6544690bb978e0b0f7328748
AmeerH/function-calling-65560a2565d7a6ef568527af
PostArchitekt/7bz-65479bb8c194936469697d8c
gnomealone/need-to-test-652007226c6ce4cdacf9c233
Crataco/favorite-7b-models-651944072b4fffcb41f8b568
```
Parameter `sort` must be one of `"last_modified"`, `"trending"` or `"upvotes"`. Parameter `item` accepts any particular item. For example:
* `"models/teknium/OpenHermes-2.5-Mistral-7B"`
* `"spaces/julien-c/open-gpt-rhyming-robot"`
* `"datasets/squad"`
* `"papers/2311.12983"`
For more details, please check out [`list_collections`] reference.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/collections.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/collections/#list-collections
|
#list-collections
|
.md
|
27_3
|
Now that we know how to get a [`Collection`], let's create our own! Use [`create_collection`] with a title and description. To create a collection on an organization page, pass `namespace="my-cool-org"` when creating the collection. Finally, you can also create private collections by passing `private=True`.
```py
>>> from huggingface_hub import create_collection
>>> collection = create_collection(
... title="ICCV 2023",
... description="Portfolio of models, papers and demos I presented at ICCV 2023",
... )
```
It will return a [`Collection`] object with the high-level metadata (title, description, owner, etc.) and an empty list of items. You will now be able to refer to this collection using its `slug`.
```py
>>> collection.slug
'owner/iccv-2023-15e23b46cb98efca45'
>>> collection.title
"ICCV 2023"
>>> collection.owner
"username"
>>> collection.url
'https://huggingface.co/collections/owner/iccv-2023-15e23b46cb98efca45'
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/collections.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/collections/#create-a-new-collection
|
#create-a-new-collection
|
.md
|
27_4
|
Now that we have a [`Collection`], we want to add items to it and organize them.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/collections.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/collections/#manage-items-in-a-collection
|
#manage-items-in-a-collection
|
.md
|
27_5
|
Items have to be added one by one using [`add_collection_item`]. You only need to know the `collection_slug`, `item_id` and `item_type`. Optionally, you can also add a `note` to the item (500 characters maximum).
```py
>>> from huggingface_hub import create_collection, add_collection_item
>>> collection = create_collection(title="OS Week Highlights - Sept 18 - 24", namespace="osanseviero")
>>> collection.slug
"osanseviero/os-week-highlights-sept-18-24-650bfed7f795a59f491afb80"
>>> add_collection_item(collection.slug, item_id="coqui/xtts", item_type="space")
>>> add_collection_item(
... collection.slug,
... item_id="warp-ai/wuerstchen",
... item_type="model",
... note="Würstchen is a new fast and efficient high resolution text-to-image architecture and model"
... )
>>> add_collection_item(collection.slug, item_id="lmsys/lmsys-chat-1m", item_type="dataset")
>>> add_collection_item(collection.slug, item_id="warp-ai/wuerstchen", item_type="space") # same item_id, different item_type
```
If an item already exists in a collection (same `item_id`/`item_type` pair), an HTTP 409 error will be raised. You can choose to ignore this error by setting `exists_ok=True`.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/collections.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/collections/#add-items
|
#add-items
|
.md
|
27_6
|
You can modify an existing item to add or modify the note attached to it using [`update_collection_item`]. Let's reuse the example above:
```py
>>> from huggingface_hub import get_collection, update_collection_item
# Fetch collection with newly added items
>>> collection_slug = "osanseviero/os-week-highlights-sept-18-24-650bfed7f795a59f491afb80"
>>> collection = get_collection(collection_slug)
# Add note the `lmsys-chat-1m` dataset
>>> update_collection_item(
... collection_slug=collection_slug,
... item_object_id=collection.items[2].item_object_id,
... note="This dataset contains one million real-world conversations with 25 state-of-the-art LLMs.",
... )
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/collections.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/collections/#add-a-note-to-an-existing-item
|
#add-a-note-to-an-existing-item
|
.md
|
27_7
|
Items in a collection are ordered. The order is determined by the `position` attribute of each item. By default, items are ordered by appending new items at the end of the collection. You can update the order using [`update_collection_item`] the same way you would add a note.
Let's reuse our example above:
```py
>>> from huggingface_hub import get_collection, update_collection_item
# Fetch collection
>>> collection_slug = "osanseviero/os-week-highlights-sept-18-24-650bfed7f795a59f491afb80"
>>> collection = get_collection(collection_slug)
# Reorder to place the two `Wuerstchen` items together
>>> update_collection_item(
... collection_slug=collection_slug,
... item_object_id=collection.items[3].item_object_id,
... position=2,
... )
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/collections.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/collections/#reorder-items
|
#reorder-items
|
.md
|
27_8
|
Finally, you can also remove an item using [`delete_collection_item`].
```py
>>> from huggingface_hub import get_collection, update_collection_item
# Fetch collection
>>> collection_slug = "osanseviero/os-week-highlights-sept-18-24-650bfed7f795a59f491afb80"
>>> collection = get_collection(collection_slug)
# Remove `coqui/xtts` Space from the list
>>> delete_collection_item(collection_slug=collection_slug, item_object_id=collection.items[0].item_object_id)
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/collections.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/collections/#remove-items
|
#remove-items
|
.md
|
27_9
|
A collection can be deleted using [`delete_collection`].
<Tip warning={true}>
This is a non-revertible action. A deleted collection cannot be restored.
</Tip>
```py
>>> from huggingface_hub import delete_collection
>>> collection = delete_collection("username/useless-collection-64f9a55bb3115b4f513ec026", missing_ok=True)
```
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/collections.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/collections/#delete-collection
|
#delete-collection
|
.md
|
27_10
|
<!--⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/cli.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/cli/
|
.md
|
28_0
|
|
The `huggingface_hub` Python package comes with a built-in CLI called `huggingface-cli`. This tool allows you to interact with the Hugging Face Hub directly from a terminal. For example, you can login to your account, create a repository, upload and download files, etc. It also comes with handy features to configure your machine or manage your cache. In this guide, we will have a look at the main features of the CLI and how to use them.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/cli.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/cli/#command-line-interface-cli
|
#command-line-interface-cli
|
.md
|
28_1
|
First of all, let's install the CLI:
```
>>> pip install -U "huggingface_hub[cli]"
```
<Tip>
In the snippet above, we also installed the `[cli]` extra dependencies to make the user experience better, especially when using the `delete-cache` command.
</Tip>
Once installed, you can check that the CLI is correctly setup:
```
>>> huggingface-cli --help
usage: huggingface-cli <command> [<args>]
positional arguments:
{env,login,whoami,logout,repo,upload,download,lfs-enable-largefiles,lfs-multipart-upload,scan-cache,delete-cache,tag}
huggingface-cli command helpers
env Print information about the environment.
login Log in using a token from huggingface.co/settings/tokens
whoami Find out which huggingface.co account you are logged in as.
logout Log out
repo {create} Commands to interact with your huggingface.co repos.
upload Upload a file or a folder to a repo on the Hub
download Download files from the Hub
lfs-enable-largefiles
Configure your repository to enable upload of files > 5GB.
scan-cache Scan cache directory.
delete-cache Delete revisions from the cache directory.
tag (create, list, delete) tags for a repo in the hub
options:
-h, --help show this help message and exit
```
If the CLI is correctly installed, you should see a list of all the options available in the CLI. If you get an error message such as `command not found: huggingface-cli`, please refer to the [Installation](../installation) guide.
<Tip>
The `--help` option is very convenient for getting more details about a command. You can use it anytime to list all available options and their details. For example, `huggingface-cli upload --help` provides more information on how to upload files using the CLI.
</Tip>
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/cli.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/cli/#getting-started
|
#getting-started
|
.md
|
28_2
|
[Pkgx](https://pkgx.sh) is a blazingly fast cross platform package manager that runs anything. You can install huggingface-cli using pkgx as follows:
```bash
>>> pkgx install huggingface-cli
```
Or you can run huggingface-cli directly:
```bash
>>> pkgx huggingface-cli --help
```
Check out the pkgx huggingface page [here](https://pkgx.dev/pkgs/huggingface.co/) for more details.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/cli.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/cli/#using-pkgx
|
#using-pkgx
|
.md
|
28_3
|
You can also install the CLI using [Homebrew](https://brew.sh/):
```bash
>>> brew install huggingface-cli
```
Check out the Homebrew huggingface page [here](https://formulae.brew.sh/formula/huggingface-cli) for more details.
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/cli.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/cli/#using-homebrew
|
#using-homebrew
|
.md
|
28_4
|
In many cases, you must be logged in to a Hugging Face account to interact with the Hub (download private repos, upload files, create PRs, etc.). To do so, you need a [User Access Token](https://huggingface.co/docs/hub/security-tokens) from your [Settings page](https://huggingface.co/settings/tokens). The User Access Token is used to authenticate your identity to the Hub. Make sure to set a token with write access if you want to upload or modify content.
Once you have your token, run the following command in your terminal:
```bash
>>> huggingface-cli login
```
This command will prompt you for a token. Copy-paste yours and press *Enter*. Then, you'll be asked if the token should also be saved as a git credential. Press *Enter* again (default to yes) if you plan to use `git` locally. Finally, it will call the Hub to check that your token is valid and save it locally.
```
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
To log in, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Enter your token (input will not be visible):
Add token as git credential? (Y/n)
Token is valid (permission: write).
Your token has been saved in your configured git credential helpers (store).
Your token has been saved to /home/wauplin/.cache/huggingface/token
Login successful
```
Alternatively, if you want to log-in without being prompted, you can pass the token directly from the command line. To be more secure, we recommend passing your token as an environment variable to avoid pasting it in your command history.
```bash
# Or using an environment variable
>>> huggingface-cli login --token $HF_TOKEN --add-to-git-credential
Token is valid (permission: write).
The token `token_name` has been saved to /home/wauplin/.cache/huggingface/stored_tokens
Your token has been saved in your configured git credential helpers (store).
Your token has been saved to /home/wauplin/.cache/huggingface/token
Login successful
The current active token is: `token_name`
```
For more details about authentication, check out [this section](../quick-start#authentication).
|
/Users/nielsrogge/Documents/python_projecten/huggingface_hub/docs/source/en/guides/cli.md
|
https://huggingface.co/docs/huggingface_hub/en/guides/cli/#huggingface-cli-login
|
#huggingface-cli-login
|
.md
|
28_5
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.