
text
stringlengths 20
57.3k
| labels
class label 4
classes |
|---|---|
Title: [BUG] column parameter of read_pdf currently needs to be list, not generic iterable
Body: ### Summary
Docs say columns parameter can be iterable, but code requires it to be list.
### Did you read the FAQ?
- [X] I have read the FAQ
### Did you search GitHub issues?
- [X] I have searched the issues
### Did you search GitHub Discussions?
- [X] I have searched the discussions
### (Optional) PDF URL
_No response_
### About your environment
```markdown
Python version:
3.12.3 (main, Apr 9 2024, 08:09:14) [Clang 15.0.0 (clang-1500.3.9.4)]
Java version:
openjdk version "21.0.3" 2024-04-16
OpenJDK Runtime Environment Homebrew (build 21.0.3)
OpenJDK 64-Bit Server VM Homebrew (build 21.0.3, mixed mode, sharing)
tabula-py version: 2.9.1
platform: macOS-14.5-arm64-arm-64bit
uname:
uname_result(system='Darwin', node='Russs-MacBook-Pro-2.local', release='23.5.0', version='Darwin Kernel Version 23.5.0: Wed May 1 20:12:58 PDT 2024; root:xnu-10063.121.3~5/RELEASE_ARM64_T6000', machine='arm64')
linux_distribution: ('Darwin', '23.5.0', '')
mac_ver: ('14.5', ('', '', ''), 'arm64')
```
### What did you do when you faced the problem?
Used the read_pdf function with columns parameter being a tuple.
Problem arises because of this line 238 in `util.py`:
```
if self.columns != sorted(self.columns):
```
It should presumably say:
```
if list(self.columns) != sorted(self.columns):
```
### Code
```py
import tabula
# Read pdf into list of DataFrame
dfs = tabula.read_pdf("test.pdf",
stream=True,
area = (145.39, 26.05, 584.21, 584.02),
columns = (26.05, 142.55, 175.47, 215.61, 252.32, 385.59, 487.44, 583.15),
pages='all')
```
### Expected behavior
function executes successfully.
### Actual behavior
Relevant part of Traceback
```
File "/Users/russ/project/venv/lib/python3.12/site-packages/tabula/util.py", line 239, in build_option_list
raise ValueError("columns option should be sorted")
ValueError: columns option should be sorted
```
### Related issues
_No response_ | 0easy
|
Title: Dirichlet Likelihood TFT model
Body: Hello,
I'm tring to use DirichletLikelihood in TFT model, but I got this issue. How can I fix it?
```python
`ValueError: Expected value argument (Tensor of shape (32, 12, 1)) to be within the support (Simplex()) of the distribution Dirichlet(concentration: torch.Size([12, 1])), but found invalid values:
tensor([[[0.5691],
[0.8910],
[0.6211],
[0.0000],
[0.3685],
[0.3022],
[0.5626],
[0.3967],
[0.6753],
[0.6197],
[0.4106],
[0.6041]],
...
[[0.0000],
[0.0000],
[0.0000],
[0.0000],
[0.0000],
[0.0000],
[0.4241],
[0.3950],
[0.3232],
[0.2716],
[0.3947],
[0.2650]]])`
```
Thanks | 0easy
|
Title: Replace reflect.DeepEqual with cmp.Diff in tests
Body: /kind feature
**Describe the solution you'd like**
[A clear and concise description of what you want to happen.]
To improve visibility, we should replace `reflect.DeepEqual` with `cmp.Diff` in all test cases: https://github.com/kubeflow/katib/blob/master/docs/developer-guide.md#go-development
Here is an example for using `cmp.Diff`: https://github.com/kubeflow/katib/blob/8df3c5c8383db6ee601f0ed8642cd554ee2234b6/pkg/apis/config/v1beta1/defaults_test.go#L88-L90
**Anything else you would like to add:**
[Miscellaneous information that will assist in solving the issue.]
---
<!-- Don't delete this message to encourage users to support your issue! -->
Love this feature? Give it a 👍 We prioritize the features with the most 👍
| 0easy
|
Title: Marketplace - agent page - fix font on section headers, current font is too big
Body: ### Describe your issue.
<img width="1424" alt="Screenshot 2024-12-16 at 21 44 17" src="https://github.com/user-attachments/assets/83914baa-5c1a-4a2d-8cba-b21f368a0dfd" />
<img width="1471" alt="Screenshot 2024-12-16 at 21 47 08" src="https://github.com/user-attachments/assets/3d1dc831-a920-4368-b38e-da71626617f6" />
Change these fonts to use the **large-poppins** typography style.
Find typography style here: https://www.figma.com/design/Ll8EOTAVIlNlbfOCqa1fG9/Agent-Store-V2?node-id=2759-9596&t=2JI1c3X9fIXeTTbE-1
font-family: Poppins;
font-size: 18px;
font-weight: 600;
line-height: 28px;
text-align: left;
text-underline-position: from-font;
text-decoration-skip-ink: none;
| 0easy
|
Title: Update `__init__.pyi` after running `rye run generate-stubs`
Body: When I run `rye run generate-stubs`, I immediately have to run `test_override_init_pyi` afterwards to fix `__init__.pyi`, during which the test fails. Then I run it again to make sure it passes. This should be automated within the rye command. | 0easy
|
Title: BUG: to_parquet doesn't set correct geometry_type in GeoParquet metadata for 3D geometries
Body: The geometry_type should be "POINT Z" and not just "POINT":
```
In [12]: df = geopandas.GeoDataFrame({'col': [1, 2, 3]}, geometry=geopandas.points_from_xy([1, 2, 3], [2, 3, 4], [1, 1, 1]))
In [13]: df
Out[13]:
col geometry
0 1 POINT Z (1.00000 2.00000 1.00000)
1 2 POINT Z (2.00000 3.00000 1.00000)
2 3 POINT Z (3.00000 4.00000 1.00000)
In [14]: df.to_parquet("test_z_dimension.parquet")
In [15]: import pyarrow.parquet as pq
In [16]: meta = pq.read_metadata("test_z_dimension.parquet")
In [19]: meta.metadata[b"geo"]
Out[19]: b'{"primary_column": "geometry", "columns": {"geometry": {"encoding": "WKB", "crs": null, "geometry_types": ["Point"], "bbox": [1.0, 2.0, 3.0, 4.0]}}, "version": "1.0.0-beta.1", "creator": {"library": "geopandas", "version": "0.12.1+62.ga24aad54"}}'
``` | 0easy
|
Title: Add custom usage message
Body: So my bad, I missed this bug when I made the change to run it with -m, but the default argparse usage message no longer fits with how the program should be run. (It says to run '_ _main_ _.py')
```python
python3.5 -m pyt example/vulnerable_code/sql/sqli.py
usage: __main__.py [-h] (-f FILEPATH | -gr GIT_REPOS) [-pr PROJECT_ROOT] [-d]
[-o OUTPUT_FILENAME] [-csv CSV_PATH] [-p | -vp]
[-t TRIGGER_WORD_FILE] [-l LOG_LEVEL] [-a ADAPTOR] [-db]
[-dl DRAW_LATTICE [DRAW_LATTICE ...]] [-li | -re | -rt]
[-intra] [-ppm]
{save,github_search} ...
__main__.py: error: invalid choice: 'example/vulnerable_code/sql/sqli.py' (choose from 'save', 'github_search')
```
Hopefully it's something simple like http://stackoverflow.com/questions/21185526/custom-usage-function-in-argparse | 0easy
|
Title: MCMC returns no samples when model contains deterministic variables only
Body: # Steps to reproduce
```python
from jax import numpy as jnp
from numpyro import sample, deterministic, distributions as dist
def test_model():
x = deterministic('x', jnp.array([1.0, 2.0]))
mcmc = MCMC(NUTS(test_model), num_warmup=1000, num_samples=1000)
mcmc.run(random.PRNGKey(0))
samples = mcmc.get_samples()
samples # {}
mcmc.print_summary() # ERROR
```
# Expected behaviour
`samples` should contain `x`, an array of shape `(1000, 2)`.
# Observed behaviour
`samples` is `{}`. Unrelated to this, `mcmc.print_summary()` is not able to deal with `samples` being empty.
```
in print_summary(samples, prob, group_by_chain)
296 summary_dict = summary(samples, prob, group_by_chain=True)
298 row_names = {
299 k: k + "[" + ",".join(map(lambda x: str(x - 1), v.shape[2:])) + "]"
300 for k, v in samples.items()
301 }
--> 302 max_len = max(max(map(lambda x: len(x), row_names.values())), 10)
303 name_format = "{:>" + str(max_len) + "}"
304 header_format = name_format + " {:>9}" * 7
ValueError: max() iterable argument is empty
``` | 0easy
|
Title: "Empty" should not be displayed on "Top Categories" section of Creator Profile
Body: <img src="https://uploads.linear.app/a47946b5-12cd-4b3d-8822-df04c855879f/9a222f5c-f591-45b0-aacc-a1e1b080bb22/053815c5-9277-4ece-b97f-b101ed831fdd?signature=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJwYXRoIjoiL2E0Nzk0NmI1LTEyY2QtNGIzZC04ODIyLWRmMDRjODU1ODc5Zi85YTIyMmY1Yy1mNTkxLTQ1YjAtYWFjYy1hMWUxYjA4MGJiMjIvMDUzODE1YzUtOTI3Ny00ZWNlLWI5N2YtYjEwMWVkODMxZmRkIiwiaWF0IjoxNzM1ODY2MDY2LCJleHAiOjMzMzA2NDI2MDY2fQ._PiDpaGz3lSxxGi90TziZRwNW8ePNyRVgzYDDjCLjGU " alt="image.png" width="571" data-linear-height="821" />
Some Agents Created by [https://platform.agpt.co/store/creator/autogpt](https://platform.agpt.co/store/creator/autogpt) have no category assigned, this GUI element appears to be picking up on this and displaying "nothing" as a top category. | 0easy
|
Title: Deprecate pipe-separated format
Body: The pipe-separated format is very little used and for the reasons explained in #5199 we have decided to remove it. Removing it is a backwards incompatible change and this issue covers deprecating it. | 0easy
|
Title: Allow pandas series as value to `info_box_content`
Body: The following should work:
```py
import gmaps
import gmaps.datasets
gmaps.configure(api_key="AI...")
df = gmaps.datasets.load_dataset_as_df('starbucks_kfc_uk').sample(200)
fig = gmaps.figure()
marker_layer = gmaps.marker_layer(
df[['latitude', 'longitude']],
info_box_content=df['chain_name']
)
fig.add_layer(marker_layer)
fig
```
At the moment, we have to call `.values` on `df['chain_name']` for this example to work. See issue #200. | 0easy
|
Title: [Feature request] Add apply_to_images to TextImage
Body: | 0easy
|
Title: Extend support for group-level service-accounts
Body: In addition of [issue 2812](https://github.com/python-gitlab/python-gitlab/issues/2812) and [feature 2851](https://github.com/python-gitlab/python-gitlab/pull/2851) it would be nice to extend the interaction with group-level service-accounts.
Currently only creation is supported, but it would be a nice feature to also support listing and deleting of service-accounts under a specific group.
API documentation:
- https://docs.gitlab.com/ee/api/groups.html#list-service-account-users
- https://docs.gitlab.com/ee/api/groups.html#list-service-account-users
| 0easy
|
Title: ichimoku cloud is a delayed 1 day
Body: when I use ichimoku indicator and check with the tradingview default ichimoku cloud, values calculated with this package seems 1 day delayed.
In other words, as an example values seen on 28th June on tradingview are written to Dataframe to date 29th June. So it creates 1 day mismatch | 0easy
|
Title: Truncate long column names ?
Body: # Brief Description
Often when exporting CSVs from questionnaires, the column names are paragraphs, or really long strings.
I would like to propose that we add an option to `clean_names` that truncates long sentence column names to something shorter. This would be useful not just in looking at the df in a notebook, but also when renaming it. Currently my workaround is to print the column names, and then use a dictionary with existing:new column names that gets passed into the rename column method.
# Example API
```python
cleaned_df = (
pd.read_csv('data/Learning Log #1 Survey Student Analysis Report.csv')
.clean_names(remove_special = True, truncate_limit = 50)
.remove_empty()
)
```
^ the tuncate_limit can be defaulted to None to avoid truncating, and a number enables the maximum number of characters in the column.
| 0easy
|
Title: CHANGELOG.rst on master branch is flagged
Body: ### AutoKey is a Xorg application and will not function in a Wayland session. Do you use Xorg (X11) or Wayland?
Xorg
### Has this issue already been reported?
- [x] I have searched through the existing issues.
### Is this a question rather than an issue?
- [x] This is not a question.
### What type of issue is this?
Documentation
### Choose one or more terms that describe this issue:
- [ ] autokey triggers
- [ ] autokey-gtk
- [ ] autokey-qt
- [ ] beta
- [ ] bug
- [ ] critical
- [x] development
- [ ] documentation
- [ ] enhancement
- [ ] installation/configuration
- [ ] phrase expansion
- [ ] scripting
- [ ] technical debt
- [ ] user interface
### Other terms that describe this issue if not provided above:
_No response_
### Which Linux distribution did you use?
_No response_
### Which AutoKey GUI did you use?
None
### Which AutoKey version did you use?
_No response_
### How did you install AutoKey?
_No response_
### Can you briefly describe the issue?
The

file on the **master** branch is flagged as failing. I see why it's flagged. It's got two section headers that are out of sequence (on [line 49](https://github.com/autokey/autokey/blob/87ace10981b00bee1e5069fb7b1b5da9770a80bb/CHANGELOG.rst#L49) and [line 223](https://github.com/autokey/autokey/blob/87ace10981b00bee1e5069fb7b1b5da9770a80bb/CHANGELOG.rst#L223). It's an easy fix.
Note that the flag is for **Python 3.13**, which we don't yet use. It may have been put there by our PR tests because of a recent attempt to use **Python 3.13** that was since undone or it was put there by Sphinx or it was put there by GitHub as a friendly alert.
The [CHANGELOG.rst](https://github.com/autokey/autokey/blob/develop/CHANGELOG.rst) file on the **develop** branch isn't flagged, but we do still make changes to the **master** branch that involve updating [CHANGELOG.RST](https://github.com/autokey/autokey/blob/master/CHANGELOG.rst) file on the **master** branch.
Should I fix the issue? Don't bother?
### Can the issue be reproduced?
Always
### What are the steps to reproduce the issue?
1. Visit the [CHANGELOG.RST](https://github.com/autokey/autokey/blob/master/CHANGELOG.rst) page.
2. Look above the document for the red x (marked with a green arrow in the image below).

### What should have happened?
No flag.
### What actually happened?
_No response_
### Do you have screenshots?
_No response_
### Can you provide the output of the AutoKey command?
```bash
```
### Anything else?
_No response_
<br/>
<hr/>
<details><summary>This repo is using Opire - what does it mean? 👇</summary><br/>💵 Everyone can add rewards for this issue commenting <code>/reward 100</code> (replace <code>100</code> with the amount).<br/>🕵️♂️ If someone starts working on this issue to earn the rewards, they can comment <code>/try</code> to let everyone know!<br/>🙌 And when they open the PR, they can comment <code>/claim #1027</code> either in the PR description or in a PR's comment.<br/><br/>🪙 Also, everyone can tip any user commenting <code>/tip 20 @Elliria</code> (replace <code>20</code> with the amount, and <code>@Elliria</code> with the user to tip).<br/><br/>📖 If you want to learn more, check out our <a href="https://docs.opire.dev">documentation</a>.</details> | 0easy
|
Title: NameError: name 'Nmf' is not defined
Body: #### Problem description
Trying to run NMF using gensim, but it doesn't work.
#### Steps/code/corpus to reproduce
I tried to run what documentation suggests:
```python
from gensim.test.utils import common_texts
from gensim.corpora.dictionary import Dictionary
# Create a corpus from a list of texts
common_dictionary = Dictionary(common_texts)
common_corpus = [common_dictionary.doc2bow(text) for text in common_texts]
# Train the model on the corpus.
nmf = Nmf(common_corpus, num_topics=10)
```
but it throws the error in subject.
I tried to inspect the package and it seems it's not installed or doesn't exist. I don't understand why.
#### Versions
gensim 3.8.3
| 0easy
|
Title: pylint_copyright_checker doesn't work with pylint 3
Body: The custom pylint rule in dev_tools/pylint_copyright_checker doesn't work with the latest major version of pylint. The specific problem is that `IRawChecker` doesn't exist anymore. I quickly snooped the changelog and I think this is relevant: https://github.com/pylint-dev/pylint/pull/8404 | 0easy
|
Title: Add smoke tests verifying basic functionality without any 3rd party deps
Body: Starting from 2.0, Falcon (proudly) has no hard dependencies except the Python standard library.
We need to add smoke tests verifying basic functionality such as WSGI, ASGI, media handling, WebSocket etc without any other packages installed in the environment. | 0easy
|
Title: Consider using super() to initialize httpx clients
Body: **Describe the bug**
Hi,
I believe there may be an issue when mixing this library with [opentelemetry-instrumentation-httpx](https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation/opentelemetry-instrumentation-httpx).
Until recently all was well, but today I suddenly had a failure:
```python
File "venv/lib/python3.11/site-packages/reliably_app/login/service.py", line 138, in login_with_provider
response = await client.authorize_redirect(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File ".venv/lib/python3.11/site-packages/authlib/integrations/starlette_client/apps.py", line 34, in authorize_redirect
rv = await self.create_authorization_url(redirect_uri, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File ".venv/lib/python3.11/site-packages/authlib/integrations/base_client/async_app.py", line 103, in create_authorization_url
async with self._get_oauth_client(**metadata) as client:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File ".venv/lib/python3.11/site-packages/authlib/integrations/base_client/sync_app.py", line 215, in _get_oauth_client
session = self.client_cls(
^^^^^^^^^^^^^^^^
File ".venv/lib/python3.11/site-packages/authlib/integrations/httpx_client/oauth2_client.py", line 65, in __init__
httpx.AsyncClient.__init__(self, **client_kwargs)
File ".venv/lib/python3.11/site-packages/opentelemetry/instrumentation/httpx/__init__.py", line 483, in __init__
super().__init__(*args, **kwargs)
^^^^^^^
TypeError: super(type, obj): obj must be an instance or subtype of type"
```
When you look at how the instrumentation lib works, you can see they subclass `httpx.AsyncClient`:
https://github.com/open-telemetry/opentelemetry-python-contrib/blob/main/instrumentation/opentelemetry-instrumentation-httpx/src/opentelemetry/instrumentation/httpx/__init__.py#L483C9-L483C42
They use the `super` keyword. However, authlib does use the "older" mechanism to initialize its subclass https://github.com/lepture/authlib/blob/master/authlib/integrations/httpx_client/oauth2_client.py#L65
I wonder if that means the tree isn't properly constructed by Python 3.11 which leads to this error.
**Error Stacks**
```python
File "venv/lib/python3.11/site-packages/reliably_app/login/service.py", line 138, in login_with_provider
response = await client.authorize_redirect(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File ".venv/lib/python3.11/site-packages/authlib/integrations/starlette_client/apps.py", line 34, in authorize_redirect
rv = await self.create_authorization_url(redirect_uri, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File ".venv/lib/python3.11/site-packages/authlib/integrations/base_client/async_app.py", line 103, in create_authorization_url
async with self._get_oauth_client(**metadata) as client:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File ".venv/lib/python3.11/site-packages/authlib/integrations/base_client/sync_app.py", line 215, in _get_oauth_client
session = self.client_cls(
^^^^^^^^^^^^^^^^
File ".venv/lib/python3.11/site-packages/authlib/integrations/httpx_client/oauth2_client.py", line 65, in __init__
httpx.AsyncClient.__init__(self, **client_kwargs)
File ".venv/lib/python3.11/site-packages/opentelemetry/instrumentation/httpx/__init__.py", line 483, in __init__
super().__init__(*args, **kwargs)
^^^^^^^
TypeError: super(type, obj): obj must be an instance or subtype of type"
```
**To Reproduce**
It's not trivial to set a basic example. I'll do my best to update accordingly.
**Expected behavior**
A clear and concise description of what you expected to happen.
**Environment:**
* Ubuntu
* Python 3.11.2
* authlib 1.2.1
* opentelemetry-instrumentation-httpx 0.39b0
* httpx 0.24.1
| 0easy
|
Title: Cannot specify `allowed_updates` while using `dp.run_polling`
Body: ref #564 | 0easy
|
Title: The best model and final model in RANSAC are not same.
Body: ### Describe the bug
The best model and final model in RANSAC are not same. Therefore, the final model inliers may not be same as the best model inliers.
In `_ransac.py`, the following code snippet computes the final model using all inliers so the final model is not same as the best model computed using the selected samples before.
```python
estimator.fit(X_inlier_best, y_inlier_best, **fit_params_best_idxs_subset)
self.estimator_ = estimator
self.inlier_mask_ = inlier_mask_best
```
### Steps/Code to Reproduce
Please debug the code using a custom loss function. Probably, you would observe the difference for default loss functions as well.
### Expected Results
Different `estimator.coef_` and `estimator.intercept_` for the best and final estimators. Accordingly, `inlier_mask_best` are not same for the best estimator and the final estimator. However, the code uses the best estimator's `inlier_mask_best` for the final estimator.
### Actual Results
The best estimator:
```python
estimator.coef_
array([0.03249012], dtype=float32)
estimator.intercept_
-0.0016712397
```
The final estimator:
```python
estimator.coef_
array([0.03334882], dtype=float32)
estimator.intercept_
-0.0047605336
```
### Versions
```shell
System:
python: 3.10.9 | packaged by conda-forge | (main, Feb 2 2023, 20:20:04) [GCC 11.3.0]
executable: /opt/conda/bin/python
machine: Linux
Python dependencies:
sklearn: 1.5.2
pip: 24.2
setuptools: 75.1.0
numpy: 1.26.4
scipy: 1.13.0
Cython: None
pandas: 2.1.1
matplotlib: 3.5.3
joblib: 1.4.2
threadpoolctl: 3.5.0
Built with OpenMP: True
threadpoolctl info:
user_api: openmp
internal_api: openmp
num_threads: 8
prefix: libgomp
filepath: /opt/conda/lib/libgomp.so.1.0.0
version: None
user_api: blas
internal_api: mkl
num_threads: 4
prefix: libmkl_rt
filepath: /opt/conda/lib/libmkl_rt.so.2
version: 2023.1-Product
threading_layer: intel
user_api: openmp
internal_api: openmp
num_threads: 4
prefix: libomp
filepath: /opt/conda/lib/libomp.so
version: None
user_api: blas
internal_api: openblas
num_threads: 8
prefix: libopenblas
filepath: /opt/conda/lib/python3.10/site-packages/scipy.libs/libopenblasp-r0-24bff013.3.26.dev.so
version: 0.3.26.dev
threading_layer: pthreads
architecture: SkylakeX
user_api: openmp
internal_api: openmp
num_threads: 8
prefix: libgomp
filepath: /opt/conda/lib/python3.10/site-packages/scikit_learn.libs/libgomp-a34b3233.so.1.0.0
version: None
```
| 0easy
|
Title: `solara.DataFrame` doesn't display row index names
Body: Here's the default display of a dataframe in a Jupyter notebook:
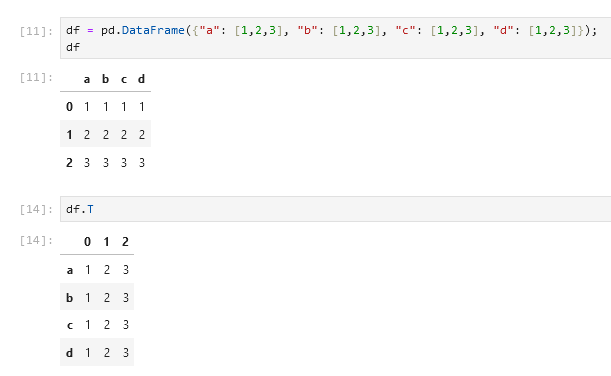
Here's how solara displays it:

In the second display of the transposed dataframe the row names should be `a, b, c, d` instead of `0, 1, 2, 3`. | 0easy
|
Title: Process: Support configuring log level keywords use
Body: I'd like to have the ability to set `log_level` for builtin `Run Process` keyword so that I can specify the loglevel of messages logged by this keyword. | 0easy
|
Title: Small edit to the contributors guide
Body: The way we tell people to run unit tests will not work..
We need to tell users to run
`python setup.py build_ext --inplace` | 0easy
|
Title: Cleanup code from TODOs
Body: Cleanup the following TODOs:
* [x] https://github.com/aio-libs/aioredis/blob/master/aioredis/commands/server.py#L223
* [x] https://github.com/aio-libs/aioredis/blob/master/aioredis/commands/generic.py#L146
pass `encoding='utf-8'` parameter to command. | 0easy
|
Title: Replace flake8 with ruff
Body: https://github.com/charliermarsh/ruff
This is so much better than flake8. We should be able to replace all our flake8 integrations with ruff for speed improvements and fewer dependencies. | 0easy
|
Title: [Feature request] Add apply_to_images to RandomGamma
Body: | 0easy
|
Title: [ENH] interface `simdkalman` filters as a panel transformer
Body: Quite randomly I discovered the `simdkalman` package, which is an alternative to `pykalman` and `filterpy`, and the only package that offers - in `sktime` parlance - an optimized `Panel` mode (= collections of time series).
https://github.com/oseiskar/simdkalman
Since filters are one area of very commonly used pre-processing steps, it would be great to have an `sktime` native interface!
The main options are:
* directly in `sktime`, using the extension template https://www.sktime.net/en/latest/developer_guide/add_estimators.html
* or, in `simdkalman` directly, and linking the estimator registry to the package so it appears in the estimator overview - this would require collaboration with the authors.
FYI @oseiskar, @winedarksea, @microprediction. | 0easy
|
Title: Conditional join
Body: # Brief Description
<!-- Please provide a brief description of what you'd like to propose. -->
I would like to propose conditional join, also known as non-equi joins, which is obtainable in SQL and R's datatable.
# Example API
```python
df1 = pd.DataFrame({'col_a': [1,2,3], 'col_b': ["A", "B", "C"]})
col_a col_b
0 1 A
1 2 B
2 3 C
df2 = pd.DataFrame({'col_a': [0, 2, 3], 'col_c': ["Z", "X", "Y"]})
col_a col_c
0 0 Z
1 2 X
2 3 Y
```
Please modify the example API below to illustrate your proposed API, and then delete this sentence.
```python
# the join can be >, < or !=. I guess as we get a stable function, we can add others, and combine with equi-joins
df1.conditional_join(df2, left_column = "col_a", right_column = "col_a", join_operator = ">")
col_a col_b col_c
0 1 A Z
1 2 B Z
2 3 C Z
3 3 C X
```
| 0easy
|
Title: ZeroDivisionError when using SmoothingFunction's method4 with a single word as hypothesis
Body: When using the SmoothingFunction's [method4](https://www.kite.com/python/docs/nltk.bleu_score.SmoothingFunction.method4) with a a single word as a hypothesis I get the following error. Which is of course because math.log(1) is 0.
I ended up using just method2 or method1 which doesn't use the function that throws the error, but I guess it would be useful to report it, as some other poor soul may stumble with it.
```
from nltk.translate.bleu_score import sentence_bleu
from nltk.translate.bleu_score import SmoothingFunction
refs = [['short', 'skirts'], ['too', 'expensive'], ['girls', 'wearing'], ['being', 'laughed', 'at']]
hyp = ['too']
chencherry = SmoothingFunction()
sentence_bleu(refs, hyp, weights=(1, 0, 0, 0), smoothing_function=chencherry.method4)
```
```
ZeroDivisionError Traceback (most recent call last)
<ipython-input-130-00301cf17f56> in <module>()
6
7 chencherry = SmoothingFunction()
----> 8 sentence_bleu(refs, hyp, weights=(1, 0, 0, 0), smoothing_function=chencherry.method4)
2 frames
/usr/local/lib/python3.7/dist-packages/nltk/translate/bleu_score.py in sentence_bleu(references, hypothesis, weights, smoothing_function, auto_reweigh, emulate_multibleu)
87 return corpus_bleu([references], [hypothesis],
88 weights, smoothing_function, auto_reweigh,
---> 89 emulate_multibleu)
90
91
/usr/local/lib/python3.7/dist-packages/nltk/translate/bleu_score.py in corpus_bleu(list_of_references, hypotheses, weights, smoothing_function, auto_reweigh, emulate_multibleu)
197 # smoothing method allows.
198 p_n = smoothing_function(p_n, references=references, hypothesis=hypothesis,
--> 199 hyp_len=hyp_len, emulate_multibleu=emulate_multibleu)
200 s = (w * math.log(p_i) for i, (w, p_i) in enumerate(zip(weights, p_n)))
201 s = bp * math.exp(math.fsum(s))
/usr/local/lib/python3.7/dist-packages/nltk/translate/bleu_score.py in method4(self, p_n, references, hypothesis, hyp_len, *args, **kwargs)
542 for i, p_i in enumerate(p_n):
543 if p_i.numerator == 0 and hyp_len != 0:
--> 544 incvnt = i+1 * self.k / math.log(hyp_len) # Note that this K is different from the K from NIST.
545 p_n[i] = 1 / incvnt
546 return p_n
ZeroDivisionError: float division by zero
``` | 0easy
|
Title: Add MinMaxScaler Estimator
Body: The MinMaxScaler estimator scales the data to a range set by the minimum and maximum. Use the IncrementalBasicStatistics
estimator to generate the min and max to scale the data. Investigate where the new implementation may be low performance and
include guards in the code to use Scikit-learn as necessary. The final deliverable would be to add this estimator to the 'spmd'
interfaces which are effective on MPI-enabled supercomputers, this will use the underlying MPI-enabled minimum and maximum
calculators in IncrementalBasicStatistics. This is similar to the MaxAbsScaler and can be combined into a small project.
This is an easy difficulty project.
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html | 0easy
|
Title: [FEATURE] hall of fame
Body: if we're gonna do a sprint someday, it might be nice to add a hall of fame. feature?
https://github.com/sourcerer-io/hall-of-fame | 0easy
|
Title: [Feature request] Add apply_to_images to Morphological
Body: | 0easy
|
Title: Missing exchange config between Shetland Islands (GB-ZET) and Great Britain (GB)
Body: ## Description
There are a new interconnector between these zones but we are missing a config for it.
It would be great if someone could add this! | 0easy
|
Title: Add batch mutation for update and delete operation
Body: ## Description
Even though batch creation of objects was already implemented a while ago (see https://github.com/strawberry-graphql/strawberry-graphql-django/issues/3), it is still not possible to update/delete objects in a batch. | 0easy
|
Title: Cumulative Volume Delta (CVD)
Body: Hi, I am wondering if we can support CVD? Or if anyone else has a working CVD?
Reference below for a nice CVD indicator:
https://www.tradingview.com/script/NlM312nK-CVD-Cumulative-Volume-Delta-Candles/
| 0easy
|
Title: Listeners are not notified about actions they initiate
Body: If a listener runs a keyword using `BuiltIn.run_keyword` or logs a message using `robot.api.logger`, their `start/end_keyword` or `log_message` methods are not called. This is inconsistent, because if listeners modify the data so that they add new keyword calls, their `start/end_keyword` methods are called and, if keywords log something. also `log_message` is called. This also leads to a situation where the result model will have more information that listeners have received. I noticed this when enhancing the result model created during execution so that it contains also log messages (#5260).
The reason that listeners don't get notifications from actions they initiate is that it is explicitly prohibited to avoid recursion. Recursion is a valid concern, because if `start_keyword` blindly calls `BuiltIn.run_keyword` or `log_message` blindly calls `logger.info`, they end up being called again until the recursion limit is exceeded. That is, however, a bug in a listener and it should be fixed. The change is nevertheless backwards incompatible, because buggy listeners won't work anymore. | 0easy
|
Title: Upgrading lightGBM API usage
Body: ## 🐛 Bug Description
<!-- A clear and concise description of what the bug is. -->
The current usage of lightGBM API is deprecated.

```
/home/xiaoyang/miniconda3/envs/kaggle/lib/python3.7/site-packages/lightgbm/engine.py:177: UserWarning: Found `n_estimators` in params. Will use it instead of argument
_log_warning(f"Found `{alias}` in params. Will use it instead of argument")
/home/xiaoyang/miniconda3/envs/kaggle/lib/python3.7/site-packages/lightgbm/engine.py:181: UserWarning: 'early_stopping_rounds' argument is deprecated and will be removed in a future release of LightGBM. Pass 'early_stopping()'
callback via 'callbacks' argument instead. _log_warning("'early_stopping_rounds' argument is deprecated and will be removed in a future release of LightGBM. "
/home/xiaoyang/miniconda3/envs/kaggle/lib/python3.7/site-packages/lightgbm/engine.py:239: UserWarning: 'verbose_eval' argument is deprecated and will be removed in a future release of LightGBM. Pass 'log_evaluation()' callback
via 'callbacks' argument instead.
_log_warning("'verbose_eval' argument is deprecated and will be removed in a future release of LightGBM. "
/home/xiaoyang/miniconda3/envs/kaggle/lib/python3.7/site-packages/lightgbm/engine.py:260: UserWarning: 'evals_result' argument is deprecated and will be removed in a future release of LightGBM. Pass 'record_evaluation()' callba
ck via 'callbacks' argument instead.
_log_warning("'evals_result' argument is deprecated and will be removed in a future release of LightGBM. "
```
## To Reproduce
Steps to reproduce the behavior:
1. train Qlib models based on lightGBM
## Expected Behavior
<!-- A clear and concise description of what you expected to happen. -->
## Screenshot
<!-- A screenshot of the error message or anything shouldn't appear-->
## Environment
**Note**: User could run `cd scripts && python collect_info.py all` under project directory to get system information
and paste them here directly.
- Qlib version:
- Python version:
- OS (`Windows`, `Linux`, `MacOS`):
- Commit number (optional, please provide it if you are using the dev version):
## Additional Notes
<!-- Add any other information about the problem here. -->
| 0easy
|
Title: Cannot add JSONB value to lookup table via UI
Body: Expected object got string.
<img width="1153" alt="Image" src="https://github.com/user-attachments/assets/a9379b63-57fb-447f-ad73-d2b108fbac89" /> | 0easy
|
Title: Argument conversion should be attempted with all possible types even if some type wouldn't be recognized
Body: If we have a keyword like
```
def kw(arg: Union[T, int]):
...
```
and the type `T` isn't recognized (i.e. doesn't have a converter), the used argument is returned as-is without attempting conversion with remaining types. For example, if we'd use
```
Kw 42
```
the argument value passed to the keyword would be a string and not an integer.
This is pretty strange and inconsistent. It would be better to try conversion with all argument types in the order they are specified. If a type has a converter and conversion succeeds, the converted value should be returned.
It's a somewhat separate question to decide what to do if conversion doesn't succeed with any converter and there are some unrecognized types. Because we pass values without conversion when using only an unrecognized type like `arg: T`, I believe we should do that also with unions. That way this change would also be mostly backwards incompatible. We can revisit this decision later.
This change would be backwards incompatible simply because the argument passed to the keyword in the above example would change. I consider that fine even in a non-major release because the current behavior is, in my opinion, buggy. It's also pretty unlikely tat unrecognized types are used with recognized types like this so there shouldn't be many/any who are actually affected. | 0easy
|
Title: Automatically generate the `docs/api/internal/*.rst` files
Body: These files need to be manually kept in sync which is a lot of work and error-prone. Would be better to maintain the project's entire API docs in a more automated way
---
The ridgeplot [API docs](https://ridgeplot.readthedocs.io/en/latest/api/) include a `Internals` section that should include the entire project's documentation
<img width="1182" alt="image" src="https://github.com/user-attachments/assets/0ec5c984-acbf-4cc8-8777-d2eafd52c25e">
Currently, each sub-package (e.g. `ridgeplot._color`) is documented in a separate page.
<img width="1477" alt="image" src="https://github.com/user-attachments/assets/a52ba2f6-745b-4c4d-8944-bd311dca5147">
However, this does not need to be the case. I am okay (and maybe even prefer) if we list all modules in the main API doc page and then a single doc page per module. i.e.,
- [ridgeplot._color](https://ridgeplot.readthedocs.io/en/latest/api/internal/color.html)
- [ridgeplot._color.colorscale](https://ridgeplot.readthedocs.io/en/latest/api/internal/_color/colorscale.html)
- [ridgeplot._color.css_colors](https://ridgeplot.readthedocs.io/en/latest/api/internal/_color/css_colors.html)
- [ridgeplot._color.interpolation](https://ridgeplot.readthedocs.io/en/latest/api/internal/_color/interpolation.html)
- [ridgeplot._color.utils](https://ridgeplot.readthedocs.io/en/latest/api/internal/_color/utils.html)
- [ridgeplot._figure_factory](https://ridgeplot.readthedocs.io/en/latest/api/internal/figure_factory.html)
- [ridgeplot._hist](https://ridgeplot.readthedocs.io/en/latest/api/internal/hist.html)
- [ridgeplot._kde](https://ridgeplot.readthedocs.io/en/latest/api/internal/kde.html)
- [ridgeplot._missing](https://ridgeplot.readthedocs.io/en/latest/api/internal/missing.html)
- [ridgeplot._obj](https://ridgeplot.readthedocs.io/en/latest/api/internal/obj.html)
- [ridgeplot._obj.traces](https://ridgeplot.readthedocs.io/en/latest/api/internal/_obj/traces.html)
- [ridgeplot._types](https://ridgeplot.readthedocs.io/en/latest/api/internal/types.html)
- [ridgeplot._utils](https://ridgeplot.readthedocs.io/en/latest/api/internal/utils.html)
---
The way that we currently implement and maintain the current solution is to represent the package structure and modules in RST files, with each RST file containing a `.. automodule:: ridgeplot._color.css_colors` directive.
<img width="279" alt="image" src="https://github.com/user-attachments/assets/45c31693-4340-4577-a367-832b627007f3">
Note that currently each module contains a short description inside each RST file (e.g., _"Continuous colorscale utilities."_ for `ridgeplot._color.colorscale`). This could probably be represented as a module docstring when considering a more automated approach.
--
The solution to this problem is not clear to me. Maybe there are already tools out there that solve this nicely (e.g. `sphinx.ext.autodoc`, `sphinx.ext.autosummary`, `sphinx_toolbox.more_autodoc`, etc...). We could take a look at other prominent projects in the Python open-source space that currently use Sphinx and autodoc for API documentation. | 0easy
|
Title: [FEA] refactor pygraphistry[ai] logger to be more pythonic & friendly
Body: The pygraphistry[ai] files (feature_utils, umap, ..) are doing some surprising & awkward use of `logging` that make dev + usage difficult, it should probably be:
- [ ] files initializes as `logger = setup_logger(__filename__)`, drop parameter `verbose`, and drop use of static config file
- [ ] maybe add level `TRACE` as deeper than current `DEBUG`:
- TRACE: include data outputs (df values, ...)
- DEBUG: verbose but limit data outputs (just df shapes, ...)
- INFO: just occasional status
- WARN/ERROR/CRITICAL: as usual
- [ ] use env var `GRAPHISTRY_LOG_LEVEL` if available
- [ ] enable library to easily dynamically toggle:
- `logging.getLogger('graphistry').set_level(logging.DEBUG)`
- `logging.getLogger('graphistry.some_file').set_level(logging.DEBUG)`
- maybe a convenience getter, `graphistry.logger` | 0easy
|
Title: CI: add pydantic for checking types during runtime
Body: https://pydantic-docs.helpmanual.io/
Need to make sure it is consistent with our usage of mypy. | 0easy
|
Title: More Parameter Options
Body: It'd be great if there were more parameter options such as:
- Format of days (y-axis)
- Format of months (x-axis) | 0easy
|
Title: [Storage] Support disable exclude .gitignore
Body: <!-- Describe the bug report / feature request here -->
The file in .gitignore can be useful and one could want to sync them to cluster sometimes. Could we provide an API to suppress the ignore and sync every file to the cluster?
Current workaround: I modified this constant to a random string so it cannot read the excluded file list.
https://github.com/skypilot-org/skypilot/blob/13ce397264484a65f34d89dee609484bcf537326/sky/skylet/constants.py#L11
| 0easy
|
Title: [FEATURE] Bold search terms in results
Body: <!--
DO NOT REQUEST UI/THEME/GUI/APPEARANCE IMPROVEMENTS HERE
THESE SHOULD GO IN ISSUE #60
REQUESTING A NEW FEATURE SHOULD BE STRICTLY RELATED TO NEW FUNCTIONALITY
-->
**Describe the feature you'd like to see added**
Individual words in a search query should be bolded throughout the search results. If parts of a query are wrapped in quotes, only exact matches to contents within the results should be bolded.
**Additional context**
See discussion here: https://github.com/benbusby/whoogle-search/discussions/450#discussioncomment-1528544 (also includes implementation ideas for anyone interested in helping).
| 0easy
|
Title: Cryptic error if permission directive returns non-bool
Body: If I have a permission directive (e.g. a class with `@gql.schema_directive(locations=[Location.FIELD_DEFINITION])`) for which `check_condition` returns a non-bool value (let's say `None`) things may break badly.
I'm getting 500 errors with the following stack trace:
<details>
<summary>Stack trace</summary>
```
Internal Server Error: /graphql/
Traceback (most recent call last):
File "/home/edomora97/.cache/pypoetry/virtualenvs/olimanager--mAs8BZ3-py3.10/lib/python3.10/site-packages/django/core/handlers/exception.py", line 55, in inner
response = get_response(request)
File "/home/edomora97/.cache/pypoetry/virtualenvs/olimanager--mAs8BZ3-py3.10/lib/python3.10/site-packages/django/core/handlers/base.py", line 197, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/home/edomora97/.cache/pypoetry/virtualenvs/olimanager--mAs8BZ3-py3.10/lib/python3.10/site-packages/django/views/generic/base.py", line 103, in view
return self.dispatch(request, *args, **kwargs)
File "/home/edomora97/.cache/pypoetry/virtualenvs/olimanager--mAs8BZ3-py3.10/lib/python3.10/site-packages/django/utils/decorators.py", line 46, in _wrapper
return bound_method(*args, **kwargs)
File "/home/edomora97/.cache/pypoetry/virtualenvs/olimanager--mAs8BZ3-py3.10/lib/python3.10/site-packages/django/views/decorators/csrf.py", line 54, in wrapped_view
return view_func(*args, **kwargs)
File "/home/edomora97/.cache/pypoetry/virtualenvs/olimanager--mAs8BZ3-py3.10/lib/python3.10/site-packages/strawberry/django/views.py", line 194, in dispatch
result = self.schema.execute_sync(
File "/home/edomora97/.cache/pypoetry/virtualenvs/olimanager--mAs8BZ3-py3.10/lib/python3.10/site-packages/strawberry/schema/schema.py", line 241, in execute_sync
result = execute_sync(
File "/home/edomora97/.cache/pypoetry/virtualenvs/olimanager--mAs8BZ3-py3.10/lib/python3.10/site-packages/strawberry/schema/execute.py", line 206, in execute_sync
ensure_future(result).cancel()
File "/usr/lib/python3.10/asyncio/tasks.py", line 615, in ensure_future
return _ensure_future(coro_or_future, loop=loop)
File "/usr/lib/python3.10/asyncio/tasks.py", line 634, in _ensure_future
loop = events._get_event_loop(stacklevel=4)
File "/usr/lib/python3.10/asyncio/events.py", line 656, in get_event_loop
raise RuntimeError('There is no current event loop in thread %r.'
RuntimeError: There is no current event loop in thread 'Thread-1 (process_request_thread)'.
```
</details>
The API is not super clear about this:
https://github.com/blb-ventures/strawberry-django-plus/blob/b416aa235aea2cc78facde305dbf0e11fc8c85cb/strawberry_django_plus/permissions.py#L389-L390
Note how the return type is not documented.
I think the culprit is:
https://github.com/blb-ventures/strawberry-django-plus/blob/b416aa235aea2cc78facde305dbf0e11fc8c85cb/strawberry_django_plus/permissions.py#L297-L302
Here if the value returned is not a boolean it assumes it is a future (which is not the case for `None` for example).
---
I'm not saying this is a bug of this library, however the resulting error is very cryptic (and finding the root cause of the problem was quite hard as well). I'm proposing to _at least_ document this behavior, and maybe add an assertion or a proper check for the values returned by `check_condition`. Is `is_awaitable` really that slow? | 0easy
|
Title: `data.create_image_fetcher` should be private
Body: ### Description:
https://github.com/scikit-image/scikit-image/blob/c90bfccbc930262eebd1149b10660bfa4f56ec61/skimage/data/__init__.pyi#L16
has no docstring and is probably intended as a private initializer for pooch. So remove it from the PYI file and probably add an underscore to the function name to be totally explicit about it. :wink:
### Way to reproduce:
```python
import skimage as ski
assert ski.data.create_image_fetcher.__doc__ # passes
```
### Version information:
```Shell
3.10.10 (main, Mar 5 2023, 22:26:53) [GCC 12.2.1 20230201]
Linux-6.2.7-arch1-1-x86_64-with-glibc2.37
scikit-image version: 0.21.0rc0.dev0+git20230323.c90bfccbc
numpy version: 1.24.1
```
| 0easy
|
Title: Finding indexes with `np.where(condition)` or `np.asarray(condition).nonzero()`
Body: Throughout the repo, we use `np.where(condition)` for getting indexes, for instance in [SelectorMixin.get_support()](https://github.com/scikit-learn/scikit-learn/blob/fba028b07ed2b4e52dd3719dad0d990837bde28c/sklearn/feature_selection/_base.py#L73), in [SimpleImputer.transform()](https://github.com/scikit-learn/scikit-learn/blob/fba028b07ed2b4e52dd3719dad0d990837bde28c/sklearn/impute/_base.py#L670) and in several of our examples ([example](https://github.com/scikit-learn/scikit-learn/blob/fba028b07ed2b4e52dd3719dad0d990837bde28c/examples/linear_model/plot_sgd_iris.py#L58)).
The numpy documentation [discourages](https://numpy.org/doc/2.1/reference/generated/numpy.where.html) the use of `np.where` with just passing a condition and recommends `np.asarray(condition).nonzero()` instead.
For cleanliness of code, should we adopt this recommendation, at least in the examples? Or are there good reasons why we do that? | 0easy
|
Title: Documentation - Clean up the *Reference > Pages* sub-pages to be only about Page models
Body: ### Pertinent section of the Wagtail docs
> https://docs.wagtail.org/en/stable/reference/pages/index.html

### Details
* Within the `Reference` section of our documentation, we have a sub-page called `Pages`. This contains the 'Model reference' and 'Panel types' documentation, however, these are not specific to the Page models.
* I have found it confusing but have kind of gotten used to it, but from a newcomer perspective it feels odd. Panels are now fully supported across Snippets and Pages, the Model reference page has all models (not just pages).
* There are a few other changes that would make this 'Reference > Pages' section a bit more consistent and predictable.
#### Proposed changes
1. Move [`Panel types`](https://docs.wagtail.org/en/stable/reference/pages/panels.html) directly under [`Reference`](https://docs.wagtail.org/en/stable/reference/index.html).
2. Move [`Model Reference`](https://docs.wagtail.org/en/stable/reference/pages/model_reference.html) directly under [`Reference`](https://docs.wagtail.org/en/stable/reference/index.html).
3. Update the title of [`Model Reference`](https://docs.wagtail.org/en/stable/reference/pages/model_reference.html) to `Model reference` (lower case `r`, as this is the way most page titles are capitalised and `Reference` is not a proper noun.
4. Split the **tagging** section from [`Recipes`](https://docs.wagtail.org/en/stable/reference/pages/model_recipes.html) out to a new page called Tags to directly under `Advanced topics` called `Tags`.
5. Fix the incorrect heading level nesting in [`Recipes`](https://docs.wagtail.org/en/stable/reference/pages/model_recipes.html) for the 'adding endpoints with custom route methods, it should be the same level as 'overriding the serve method' not one under it.
6. Minor update to the text `wagtail.models` to use double backticks so that it appears highlighted as code. See https://github.com/wagtail/wagtail/blob/105338d0d63c5a8adf285d3c077a922f53a15d02/wagtail/models/__init__.py#L2 (we may also want to fix up the other backtick usage in that docstring to be double backticks) * See https://github.com/wagtail/wagtail/blob/105338d0d63c5a8adf285d3c077a922f53a15d02/wagtail/models/__init__.py#L331C16-L331C31 for an example of the double backticks being used correctly to style as pre/code in the published docs.
### Working on this
* Feel free to cover items 1-3 as a stand-alone PR, it may make reviews easier.
* Anyone can contribute to this. View our [contributing guidelines](https://docs.wagtail.org/en/latest/contributing/index.html), add a comment to the issue once you’re ready to start.
| 0easy
|
Title: Add `drop_tables` function
Body: We recently added a `create_tables` function:
https://github.com/piccolo-orm/piccolo/blob/bded0f62c6aa14ed4ac294cd560f56c6dd160f2e/piccolo/table.py#L978
It is a great convenience when writing unit tests, or writing a simple data science script using Piccolo.
```python
create_tables(Band, Manager)
```
It would be nice to have a companion function called `drop_tables`. It will sort the tables based on `ForeignKey` columns, and drop them in the correct order (or else just call `drop_table(cascade=True)`. The implementation will be very similar to `create_tables`.
```python
drop_tables(Band, Manager)
``` | 0easy
|
Title: Replace underscores with dashes in CSS classnames
Body: - [ ] Do a search and find (e.g. `className=`) and replace all underscores with dashes in CSS classnames (except for vizro_dark and vizro_light)
- [ ] Replace double underscores with dashes (e.g. container__title to container-title)
- [ ] Ensure all tests pass | 0easy
|
Title: BlockingIOError multiprocessing error
Body: ```
Traceback (most recent call last):
File "/Users/maopinglin/Desktop/my/xiangmu/bwl/bwl.gouyungou.com/pachong/index.py", line 136, in <module>
xsTimeOut = m.dict()
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/multiprocessing/managers.py", line 662, in temp
token, exp = self._create(typeid, *args, **kwds)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/multiprocessing/managers.py", line 554, in _create
conn = self._Client(self._address, authkey=self._authkey)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/multiprocessing/connection.py", line 493, in Client
answer_challenge(c, authkey)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/multiprocessing/connection.py", line 732, in answer_challenge
message = connection.recv_bytes(256) # reject large message
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/multiprocessing/connection.py", line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/multiprocessing/connection.py", line 407, in _recv_bytes
buf = self._recv(4)
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/multiprocessing/connection.py", line 379, in _recv
chunk = read(handle, remaining)
BlockingIOError: [Errno 35] Resource temporarily unavailable
```
The above is an error message, using multi-process + multi-threading+gevent | 0easy
|
Title: Version 3.0 on the way
Body: Hello Everyone, I have been a good time away from the repository.
I Wanted to tell you that I am working on version 3.0 where all errors are corrected and of course, will have many innovative improvements built in.
Best regards! | 0easy
|
Title: 网站的公告栏在火狐浏览器显示下出现排版问题
Body: 目前使用过几款浏览器在火狐浏览器下打开网页,公告栏出现排版问题,如图所示。
<img width="579" alt="截屏2021-08-06 22 58 40" src="https://user-images.githubusercontent.com/39561185/128530939-7cb9749f-c7d3-4502-8f7f-c9dae05035c5.png">
| 0easy
|
Title: Annotate return type of DiffusionPipeline.from_pretrained as Self | None
Body: DiffusionPipeline.from_pretrained returns Any | None. Return type should be explicitly annotated as Self | None. | 0easy
|
Title: Smaller figures in examples
Body: The figures in our example notebooks are very large. Making them a bit smaller will make things more readable.
| 0easy
|
Title: http.lifecycle.response should be dispatched in exception handler
Body: Currently the `http.lifecycle.response` is only dispatched from `handle_request`. It also should be dispatched from `handle_exception`. | 0easy
|
Title: allow feature selectors to take in other types of cross-validation functions
Body: At the moment the following selector classes:
- [recursive feature addition](https://github.com/solegalli/feature_engine/blob/master/feature_engine/selection/recursive_feature_addition.py)
- [recursive feature elimination ](https://github.com/solegalli/feature_engine/blob/master/feature_engine/selection/recursive_feature_elimination.py)
- [SelectBySingleFeaturePerformance](https://github.com/solegalli/feature_engine/blob/master/feature_engine/selection/single_feature_performance.py)
- [SmartCorrelatedSelection](https://github.com/solegalli/feature_engine/blob/master/feature_engine/selection/smart_correlation_selection.py)
- [SelectByShuffling](https://github.com/solegalli/feature_engine/blob/master/feature_engine/selection/shuffle_features.py)
take only a positive value for the cv parameter.
However, Scikit-learn's cross_validate, which is used by all the above transformers, can also take internal cross-validation schemes like stratified k-fold, loocv and others.
The aim of this PR, is to allow all the selectors to also be able to pass to cross_validate other cross-validation schemes and not just an integer.
This is indeed a minor change in the code:
If we remove the **check for the positive value** that we added in the init method of the class. that should do the trick.
In addition, apart from removing this check, we should add a few tests to each transformer a test that it can succesfully take other cross-validation schemes without throwing an error.
More details on sklearn cross-validation classes here:
https://scikit-learn.org/stable/modules/cross_validation.html
| 0easy
|
Title: Add GitHub action to test gql on windows
Body: It happened multiple times already that the test suite is working well under Linux but it fails under Windows.
I think it should be possible to add a GitHub action to test GQL under windows automatically for each push. | 0easy
|
Title: Add unit tests for the `__repr__` method of the EndpointNode class
Body: ## Unit Test
### Description
Add unit tests for the `__repr__` method of the **EndpointNode** class: https://github.com/scanapi/scanapi/blob/main/scanapi/tree/endpoint_node.py#L55
[ScanAPI Writing Tests Documentation](https://github.com/scanapi/scanapi/wiki/Writing-Tests) | 0easy
|
Title: Revamp Landing README
Body: Gorilla project has evolved from just a recipe and model that could call APIs to now consist of an ecosystem that includes OpenFunctions, The Berkeley Function Calling Leaderboard (aka Berkeley Tool Calling Leaderboard), RAFT, GoEx, and the APIZoo with 63,000+ APIs. ToDo: Revamp the README to highlight this. | 0easy
|
Title: Marketplace - agent page - star rating is not visible in dark mode
Body: ### Describe your issue.
<img width="1398" alt="Screenshot 2024-12-17 at 19 26 15" src="https://github.com/user-attachments/assets/dad177a3-8af5-4336-9619-74e8b4bd9cd9" />
<img width="602" alt="Screenshot 2024-12-17 at 19 27 03" src="https://github.com/user-attachments/assets/20239766-9087-400c-bdd0-53a27f0c89db" />
Star icons are not visible when in dark mode. Please update so that the color is the same as the neighboring elements
| 0easy
|
Title: Set FEED_EXPORT_ENCODING="utf-8" in the default template
Body: The default value for FEED_EXPORT_ENCODING (`None`) means `ensure_ascii=True` for JSON exports, because that was the existing behavior before that option was added. A better default is `"utf-8"`, which creates JSON files with `ensure_ascii=False`, so we decided to add this setting to the default template like we currently do with some other settings.
The setting doc should also get a note about this like in https://docs.scrapy.org/en/latest/topics/settings.html#twisted-reactor | 0easy
|
Title: Allow complete override of a Session's Headers
Body: **Is your feature request related to a problem? Please describe.**
It would be nice if I could set the entire `session.headers` and not just update individual keys.
**Describe the solution you'd like**
I want to be able to override the `session.headers` property entirely:
```
self.session.headers = other_consumer_class.headers.copy()
```
This would require adding a setter for the `headers` property on the [`Session`](https://github.com/prkumar/uplink/blob/master/uplink/session.py) class:
```python
class Session(object):
...
@headers.setter
def headers(self, headers):
...
``` | 0easy
|
Title: Loudly deprecate variables used as embedded arguments not matching custom patterns
Body: If you have a keyword accepting embedded arguments with a custom pattern like
```
Perform ${arg:[^ ]+}
Log To Console ${arg}
```
and use it with a variable like
```
Perform ${variable}
```
Robot will call the keyword regardless the variable value. This means that the keyword may be called with a value that doesn't match the explicit custom pattern. That's not great and needs to be changed.
We initially planned to change this already in RF 6.0 (#4069), but it turned out that the change would cause too much backwards compatibility problems and the change was reverted. The main reason for backwards compatibility problems was that custom patterns were often used to resolve conflicts with various keyword implementations matching a keyword usage. Conflict resolution was enhanced heavily in RF 6.0 (#4454), so it is now safer to require patters to match also when using variables as embedded arguments. The change is still backwards incompatible and cannot really be done in RF 6.1, but we can now deprecate it loudly. The actual change can then be finally done in RF 7.0. | 0easy
|
Title: Marketplace - The clickable area on the navbar is very small and doesn't include the icon
Body: Current dev clickable area:
<img src="https://uploads.linear.app/a47946b5-12cd-4b3d-8822-df04c855879f/d2007730-a8e5-4ea8-ae34-a28bb5e96c71/381fbf8f-615f-4a40-b0a9-cff6e313e3c5?signature=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJwYXRoIjoiL2E0Nzk0NmI1LTEyY2QtNGIzZC04ODIyLWRmMDRjODU1ODc5Zi9kMjAwNzczMC1hOGU1LTRlYTgtYWUzNC1hMjhiYjVlOTZjNzEvMzgxZmJmOGYtNjE1Zi00YTQwLWIwYTktY2ZmNmUzMTNlM2M1IiwiaWF0IjoxNzM0NjAzMjEwLCJleHAiOjMzMzA1MTYzMjEwfQ.N51lpXPP5T3w-zz9P2zDwAMShB4RNyEXwGg82kSVXck " alt="image.png" width="676" data-linear-height="93" />
VS current prod (*clickable area of the build button shown here for demonstration purposes*):
<img src="https://uploads.linear.app/a47946b5-12cd-4b3d-8822-df04c855879f/27c27fa0-9760-4e22-9c4a-6b03d2b376ce/1952241d-e86c-46e6-b5c4-11a7dde684f5?signature=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJwYXRoIjoiL2E0Nzk0NmI1LTEyY2QtNGIzZC04ODIyLWRmMDRjODU1ODc5Zi8yN2MyN2ZhMC05NzYwLTRlMjItOWM0YS02YjAzZDJiMzc2Y2UvMTk1MjI0MWQtZTg2Yy00NmU2LWI1YzQtMTFhN2RkZTY4NGY1IiwiaWF0IjoxNzM0NjAzMjEwLCJleHAiOjMzMzA1MTYzMjEwfQ.inGDLF9w9xXjKisCY2dUjdoyEPNNtA1i7MKWjoKbD3Y " alt="image.png" width="696" data-linear-height="93" />
The clickable area should be expanded to match that in prod. | 0easy
|
Title: Missing .delete() for some SQL product classes
Body: Add a basic .delete() implementation for `GenericSQLRelation` and `SQLRelation` to delete tables/views. I ran into an issue where I had to manually execute a `DROP TABLE` statement, but since metadata still marked the table as "up-to-date", it didn't execute, we should encourage users to use this method instead of dropping tables directly.
However, we should also think how to prevent this. Maybe implement the `exists()` method? The main issue is that we'd have to execute a different query for some databases. | 0easy
|
Title: Local dev server
Body: I think this would be mostly useful for developing Mangum itself, but it could be useful for application developers. Currently I've relied on [Serverless Offline](https://github.com/dherault/serverless-offline) to test deployments, but this requires a Serverless Framework configuration and gives me a lot more than I need for certain debugging tasks.
Essentially what I think needs to be done is provide a layer to convert normal HTTP/WebSocket requests into AWS events and feed that to the adapter, then emulate the AWS response. Can probably create some tooling that can be re-used in the tests as well. | 0easy
|
Title: Replace `get_artifact_uri` with `model_info.model_uri` in `tests/evaluate/test_evaluation.py`
Body: ### Summary
Make the following change to remove an unnecessary URI construction:
```diff
diff --git a/tests/evaluate/test_evaluation.py b/tests/evaluate/test_evaluation.py
index 09a225ef5..10f28e8db 100644
--- a/tests/evaluate/test_evaluation.py
+++ b/tests/evaluate/test_evaluation.py
@@ -239,9 +239,9 @@ def get_linear_regressor_model_uri():
reg = sklearn.linear_model.LinearRegression()
reg.fit(X, y)
- with mlflow.start_run() as run:
- mlflow.sklearn.log_model(reg, "reg_model")
- return get_artifact_uri(run.info.run_id, "reg_model")
+ with mlflow.start_run():
+ model_info = mlflow.sklearn.log_model(reg, "reg_model")
+ return model_info.model_uri
@pytest.fixture
@@ -254,9 +254,9 @@ def get_spark_linear_regressor_model_uri():
reg = SparkLinearRegression()
spark_reg_model = reg.fit(spark_df)
- with mlflow.start_run() as run:
- mlflow.spark.log_model(spark_reg_model, "spark_reg_model")
- return get_artifact_uri(run.info.run_id, "spark_reg_model")
+ with mlflow.start_run():
+ model_info = mlflow.spark.log_model(spark_reg_model, "spark_reg_model")
+ return model_info.model_uri
@pytest.fixture
@@ -269,9 +269,9 @@ def multiclass_logistic_regressor_model_uri_by_max_iter(max_iter):
clf = sklearn.linear_model.LogisticRegression(max_iter=max_iter)
clf.fit(X, y)
- with mlflow.start_run() as run:
- mlflow.sklearn.log_model(clf, f"clf_model_{max_iter}_iters")
- return get_artifact_uri(run.info.run_id, f"clf_model_{max_iter}_iters")
+ with mlflow.start_run():
+ model_info = mlflow.sklearn.log_model(clf, f"clf_model_{max_iter}_iters")
+ return model_info.model_uri
@pytest.fixture
@@ -284,9 +284,9 @@ def get_binary_logistic_regressor_model_uri():
clf = sklearn.linear_model.LogisticRegression()
clf.fit(X, y)
- with mlflow.start_run() as run:
- mlflow.sklearn.log_model(clf, "bin_clf_model")
- return get_artifact_uri(run.info.run_id, "bin_clf_model")
+ with mlflow.start_run():
+ model_info = mlflow.sklearn.log_model(clf, "bin_clf_model")
+ return model_info.model_uri
@pytest.fixture
@@ -299,9 +299,9 @@ def get_svm_model_url():
clf = sklearn.svm.LinearSVC()
clf.fit(X, y)
- with mlflow.start_run() as run:
- mlflow.sklearn.log_model(clf, "svm_model")
- return get_artifact_uri(run.info.run_id, "svm_model")
+ with mlflow.start_run():
+ model_info = mlflow.sklearn.log_model(clf, "svm_model")
+ return model_info.model_uri
@pytest.fixture
```
### Notes
- Make sure to open a PR from a **non-master** branch.
- Sign off the commit using the `-s` flag when making a commit:
```sh
git commit -s -m "..."
# ^^ make sure to use this
```
- Include `#{issue_number}` (e.g. `#123`) in the PR description when opening a PR.
| 0easy
|
Title: data description not rendering line breaks in html output
Body: ### Current Behaviour
The dataset description field as documented [here](https://ydata-profiling.ydata.ai/docs/master/pages/use_cases/metadata.html) doesn't render line breaks correctly. For example, "line1\nline2" is shown as "line1line2" in the html report.
### Expected Behaviour
Handle line breaks correctly in the html output.
### Data Description
For example,
```
from sklearn import datasets
report = df.profile_report(
dataset={"description": datasets.load_iris().DESCR}, # DESCR contains line breaks
)
```
### Code that reproduces the bug
_No response_
### pandas-profiling version
N/A
### Dependencies
```Text
N/A
```
### OS
Windows 10
### Checklist
- [X] There is not yet another bug report for this issue in the [issue tracker](https://github.com/ydataai/pandas-profiling/issues)
- [X] The problem is reproducible from this bug report. [This guide](http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports) can help to craft a minimal bug report.
- [X] The issue has not been resolved by the entries listed under [Common Issues](https://pandas-profiling.ydata.ai/docs/master/pages/support_contrib/common_issues.html). | 0easy
|
Title: Retry k8s-event posting if failed
Body: ## Problem
K8s-event posting can fail to post an event (`kind: Event`) for any reasons, such as API rate limiting, temporary API failures (HTTP 5xx), control plane connectivity issues, SSL handshake failures, etc.
This leads to the events being lost, while they can represent some value. This applies both to the events created from the per-object `logger` messages (`logger.info(...)` from the handlers and the framework itself), and to explicitly posted events (`kopf.events.info(...)`, [docs](https://kopf.readthedocs.io/en/latest/events/)). The latter ones are definitely of value for the operator's maintainers.
## Proposal
Instead of giving up on the event posting immediately, retry up to N times before really giving up.
Acceptance criteria:
* [ ] The retries should be with increasing time interval (similar to throttling, see [this PR](https://github.com/nolar/kopf/pull/510/files#diff-e574d9e725549b44bfe94ff48af4d178R126-R143)).
* [ ] Ensure that one specific object's events are posted in order, i.e. newer events are not posted before the older events; but this should not be applied to different objects.
* [ ] Make the number of retries configurable in `kopf.events...` function as a kwarg, to be used on a case-by-case basis (the developers knows better).
* [ ] Make the default number of retries configurable via `settings.posting.default_retries` ([code](https://github.com/nolar/kopf/blob/0.27/kopf/structs/configuration.py#L42-L62)), use it when the number of retries is not explicitly passed to the `kopf.events...` functions.
* [ ] Make the number of retries for implicit logging-to-posting events configurable via `settings.posting.logging_retries`. This is applied to all events generated from the `logger....` calls, without fine-grained control on any other criteria.
The names of settings are negotiable: whatever feels more natural and English-like.
```python
import kopf
@kopf.on.create('zalando.org', 'v1', 'kopfexamples')
def create_fn(body, **_):
kopf.event(body,
type='SomeType',
reason='SomeReason',
message='Some message',
retries=5)
```
## Checklist
- [x] Many users can benefit from this feature, it is not a one-time case
- [x] The proposal is related to the K8s operator framework, not to the K8s client libraries
Related: #117 — event aggregation. It should be taken into account when designing a solution, despite it is not directly a part of this feature request. | 0easy
|
Title: cannot import name 'F1Score' from 'dataprofiler.labelers.character_level_cnn_model'
Body: **General Information:**
- OS: Windows
- Python version: 3.10
- Library version: DataProfiler 0.8.8
**Describe the bug:**
I was just simply running add_new_model_to_data_labeler.ipynb file. not able to import
from dataprofiler.labelers.character_level_cnn_model import CharacterLevelCnnModel, F1Score, \
create_glove_char, build_embd_dictionary
Getting this error
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
Cell In[10], line 3
1 import tensorflow as tf
2 import numpy as np
----> 3 from dataprofiler.labelers.character_level_cnn_model import CharacterLevelCnnModel, F1Score, \
4 create_glove_char, build_embd_dictionary
5 from dataprofiler.labelers.base_model import BaseModel
7 # CharacterLevelLstmModel derives from CharacterLevelCnnModel
8 #########################################################
9 #########################################################
ImportError: cannot import name 'F1Score' from 'dataprofiler.labelers.character_level_cnn_model'
**To Reproduce:**
**Expected behavior:**
**Screenshots:**

**Additional context:**
| 0easy
|
Title: New Dependency Language Parsers
Body: 1. Rust
2. Go
3. Kotlin
Code location for examples.
https://github.com/chaoss/augur/tree/main/augur/tasks/git/dependency_tasks/dependency_util
| 0easy
|
Title: Modify app template to use `table_finder`
Body: When using `piccolo app new my_app` to create a new Piccolo app, the `piccolo_app.py` file generated doesn't use `table_finder` (note below how `table_classes=[]`).
https://github.com/piccolo-orm/piccolo/blob/eb6ba32e85c2357969e0131a2991b7e50a1dcfb1/piccolo/apps/app/commands/templates/piccolo_app.py.jinja#L14-L20
If you look at what we do with the `piccolo asgi new command`:
https://github.com/piccolo-orm/piccolo/blob/eb6ba32e85c2357969e0131a2991b7e50a1dcfb1/piccolo/apps/asgi/commands/templates/app/home/piccolo_app.py.jinja#L14-L22
Note how `table_classes=table_finder(modules=["home.tables"], exclude_imported=True)`.
Using `table_finder` is easier, as it means you don't have to manually register the tables for migrations to work. Sometimes people might want to do it manually, but doing it automatic is preferred in most situations. | 0easy
|
Title: [BUG] analyst notebook links to labs instead of hub for UI Guide
Body: 
New link is: https://hub.graphistry.com/docs/ui/index/ | 0easy
|
Title: Marketplace - Reduce margin from 16px to 10px
Body:
### Describe your issue.
Reduce margin from 16px to 10px

| 0easy
|
Title: tutorials
Body: To help users get started with the tutorial, it would be nice to have a set of tutorials that go over the main features (something like this: http://cdl-quail.readthedocs.io/en/latest/tutorial.html). Each tutorial can be a separate Jupyter notebook.
- Notebook titles should written in a markdown cell using `#` to make it large
- Subtitles should be written in a markdown cell using `##` to make them a bit smaller
- Descriptions should be written in a markdown cell with no pound sign
- Code examples should in in python
See [here](https://github.com/ContextLab/quail/blob/master/docs/tutorial/basic_analyze_and_plot.ipynb) for an example of how to format as described above.
Here is what I'm thinking. Please check these off as you go so we can keep track, and if you run into any issues, leave a message on this thread and move on to the next thing.
1. A notebook highlighting the `hyp.plot` function - examples of:
- [x] importing the toolbox
- [x] loading in some example data i.e. `mushrooms`
- [x] plotting with defaults i.e. `geo = hyp.plot(data, '.')`
- [x] plotting in 2D (setting `ndims=2`)
- [x] plotting with different dimensionality reduction (TSNE)
- [x] plotting with grouping (setting `group=list_of_group_labels`)
- [x] plotting with labels (labelling a subset of points to `labels`)
- [x] plotting with a legend (setting `legend=True`)
- [x] interpolating missing data (set some of the points to nan)
- [x] plotting with clusters (setting `n_clusters`)
- [x] plotting with normalization (setting normalize='within')
- [x] plotting with alignment ([example](http://hypertools.readthedocs.io/en/latest/auto_examples/plot_align.html#sphx-glr-auto-examples-plot-align-py))
- [x] saving a plot (`save_path=something`)
2. A notebook highlighting the `hyp.analyze` function. examples of:
- [x] importing the toolbox
- [x] loading in some example data i.e. `weights_avg`
- [x] an example normalizing the data
- [x] normalizing + reducing
- [x] normalizing + reducing + aligning
3. A notebook highlighting `hyp.normalize` examples of:
- [x] importing the toolbox
- [x] generate some synthetic data (see [this](http://hypertools.readthedocs.io/en/latest/auto_examples/plot_normalize.html#sphx-glr-auto-examples-plot-normalize-py) example)
- [x] normalize `within`
- [x] normalizing `across`
- [x] normalizing by `row`
4. A notebook highlighting dimensionality reduction with `hyp.reduce`. examples of:
- [x] importing the toolbox
- [x] loading in some example data i.e. `mushrooms`
- [x] reducing a single array
- [x] reducing a list of arrays
- [x] reducing a list of arrays with TSNE
- [x] reducing a list of arrays where ndims>3
- [x] reducing a list of arrays and tweaking the model parameters using the dictionary syntax
5. A notebook highlighting `hyp.align`. examples of:
- [x] importing the toolbox
- [x] loading in some example data i.e. `weights`
- [x] plotting two unaligned datasets (using the line plot not '.')
- [x] plotting two aligned datasets aligned with hyperalignment
- [x] plotting two aligned datasets aligned with SRM
6. A notebook highlighting `hyp.cluster` examples of:
- [x] importing the toolbox
- [x] loading in some example data i.e. `mushrooms`
- [x] return cluster labels with default args
- [x] setting `n_clusters` equal to something other than the default
- [x] using a different cluster model e.g. `cluster='AgglomerativeClustering'`
7. A notebook highlighting the `geo` class. examples of:
- [x] importing the toolbox
- [x] loading in some example data i.e. `mushrooms`
- [x] plot the data and generate a `geo`
- [x] description of each of the fields (see [here](http://hypertools.readthedocs.io/en/latest/hypertools.DataGeometry.html#hypertools.DataGeometry) for API description)
- [x] using `geo.plot`
- [x] transforming new data `geo.transform(new_data)`
- [x] saving data with `geo.save` | 0easy
|
Title: Shortcut_Summarizing Data
Body: ### 🚀 The feature
Getting an outline at once for a Pandas Dataframe helps saving time. For this purpose a summarization shortcut can be added:
> Summarize data to group for each distinct value in a column
> For each distinct value :
calculate subtotal of rows
calculate the percentage of the total count for each group
It can be applicable to different columns in the dataframe
There is an example table for student's exam status:
Student ID Count of Exam Perc of of Exam Pass Perc of pass Fail Fail Pec
1 10 0.25 5 0.17 4 0.25
2 10 0.25 10 0.33 0 0
3 20 0.50 15 0.5 12 0.75
### Motivation, pitch
Getting an outline at once for a Pandas Dataframe helps saving time.
### Alternatives
_No response_
### Additional context
_No response_ | 0easy
|
Title: Add examples for how to use consumer methods in documentation
Body: Suggested by @Shanoir on Gitter:
> One thing that I can suggest though: Overall the documentation of uplink is very nice. it clearly lays out how the API classes can be set up, and how to use the decorators. However, there is almost no examples available for the "use" of the methods. I think that across the board, providing these usage examples could really help newcomers get onboarded on the library :) | 0easy
|
Title: Add option to force the user to reset its password at first login
Body: ### Please confirm the following
- [x] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [x] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [x] I understand that AWX is open source software provided for free and that I might not receive a timely response.
### Feature type
New Feature
### Feature Summary
We are creating users with the `awx.awx.user` module. For user creation, it is required to input a password and not leave it blank, so let's say we are putting a dummy password, the same for all users in our code. Users are created nicely but then, we would like an option to force users to reset their passwords at first login. And somehow after some search, we were surprised that this option seems missing.
Maybe we really missed it somewhere and the option already exists. In this case, kindly shows us where it is.
### Select the relevant components
- [x] UI
- [x] API
- [ ] Docs
- [x] Collection
- [ ] CLI
- [ ] Other
### Steps to reproduce
Create user with some password (by UI, API or anything else).
### Current results
User is created and can login with the specified password but is not forced to reset its password.
### Sugested feature result
An option like : _force reset password at first login_ to enable or not.
### Additional information
_No response_ | 0easy
|
Title: Disguise database connection errors as 503?
Body: When the database connection cannot be established, this is usually because of the deployment process restarting the cluster. Currently, this leads to `500 Internal Server Error` due to an error raised by the local database client library. As the error cause is known and intended, it would be justified to replace this with `503 Service Unavailable`.
The question is for which error codes to do that. Here's the server error codes reference: https://mariadb.com/kb/en/library/mariadb-error-codes/ However, errors generated by the database server (as opposed to connection errors on the client side) are real errors and should not be disguised.
This is the client error code reference: https://dev.mysql.com/doc/refman/8.0/en/client-error-reference.html The following list appears reasonable: 2002, 2003, 2005, 2007, 2009, 2026
@nils-wisiol | 0easy
|
Title: Marketplace - Reduce this margin here so that it's 12px
Body:
### Describe your issue.
Reduce this margin here so that it's 12px

| 0easy
|
Title: Track device automatically.
Body: Track `self.device = device` automatically as a property of the API class | 0easy
|
Title: Is the requirements.txt missing on master?
Body: There is no "requirements.txt" under master branch. | 0easy
|
Title: Multi-user conversations in a thread
Body: Allow for the conversation system to send multiple users to GPT3 in the conversation history.
For example, we should key the user based on their discord name and the conversations should look like this:
{CONVERSATION CONTEXT PRE-TEXT}
Kaveen: Hey!
GPTie: Hello there Kaveen, how can I help?
Bob: Hey GPTie!
GPTie: Hey to you as well Bob!
For the initial version of this, each message sent by any user should cause an API Request to happen. In later, and more sophisticated versions of this, I want the API request to happen 10 seconds after no conversation activity has happened, so that we don't have to make an individual request for each user's message, especially if the users are talking to each other and not GPTie.
| 0easy
|
Title: TypeError: GraphQLView() received an invalid keyword 'subscriptions_enabled'. as_view only accepts arguments that are already attributes of the class.
Body: ## Describe the Bug
When using subscriptions in a view as [according to the docs here](https://strawberry.rocks/docs/django/guide/subscriptions), you update your urls.py to look like:
```py
urlpatterns = [
...
path(
'graphql/',
AsyncGraphQLView.as_view(
schema=schema,
graphiql=settings.DEBUG,
subscriptions_enabled=True,
),
),
...
]
```
However, this causes an error during testing:
```
TypeError: AsyncGraphQLView() received an invalid keyword 'subscriptions_enabled'. as_view only accepts arguments that are already attributes of the class.
```
**The same error occurs using `GraphQLView()` rather than `AsyncGraphQLView()`.**
## System Information
```
# from my pyproject.toml
strawberry-graphql = {version = "^0.246.2", extras = ["debug-server"]}
strawberry-graphql-django = "^0.49.0"
``` | 0easy
|
Title: Refine Qlib's code style reported by pylint and flake8
Body: ## 🌟 Feature Description
<!-- A clear and concise description of the feature proposal -->
## Motivation
`Qlib` has integrated pylint and flake8 to automatically detect the problem of coding style
But [some errors](https://github.com/microsoft/qlib/blob/main/.github/workflows/test.yml#L39) are not fixed due to the limited bandwidth of the maintainers.
It will be very helpful if the community would like to contribute to refine them :)

## Alternatives
<!-- A short description of any alternative solutions or features you've considered. -->
## Additional Notes
<!-- Add any other context or screenshots about the feature request here. --> | 0easy
|
Title: Cleanup and import SKL Feature Pre-processing: OneHotEncoder
Body: We have the original draft of the OneHotEncoder code uploaded in this [branch](https://github.com/microsoft/hummingbird/tree/cleanup/one-hot-enc). All credit here goes to @scnakandala, the original author and brains behind this.
It contains an un-edited implementation of OneHotEncoder [here](https://github.com/microsoft/hummingbird/blob/cleanup/one-hot-enc/hummingbird/ml/operator_converters/one_hot_encoder.py).
There is a single test file [here](https://github.com/microsoft/hummingbird/blob/cleanup/one-hot-enc/tests/test_sklearn_one_hot_encoder_converter.py) that needs to be cleaned up and passing.
Notes:
* We had to treat strings a bit differently because of the way they are represented in tensors
* We should add more robust tests here
* the `retain_order` flag in `OneHotEncoder` is not yet implemented. We can wait on that for later unless someone gets inspired. | 0easy
|
Title: error when running training/main.py
Body: I am getting a ModuleNotFoundError for training when running src/training/main.py. It points to line 19 in main.py, the import function.
Edit: Fixed it. Forgot to add pythonpath | 0easy
|
Title: [New feature] Add apply_to_images to HEStain
Body: | 0easy
|
Title: The weekly model zoo CI has been failing
Body: https://github.com/onnx/onnx/actions/runs/8871371005
@ramkrishna2910 do you have any suggestions? | 0easy
|
Title: "local-shell-script" does not work on read only file systems
Body: ## SUMMARY
While using the action runner type "local-shell-script", the action always try to set execute permission for the action script before the execution.
For example, action runner logs for the core.sendmail action
```
2022-03-09 07:02:06,866 INFO [-] Executing action via LocalRunner: dcc6c28d-5674-4cc2-9174-ca6c1e7b23a3
2022-03-09 07:02:06,866 INFO [-] [Action info] name: sendmail, Id: 622850eead44b087ebe77063, command: chmod +x /opt/stackstorm/packs/core/actions/send_mail/send_mail ; sudo -E -H -u stanley -- bash -c '/opt/stackstorm/packs/core/actions/send_mail/send_mail None stanley test@testmail.com '"'"'validate st2 local-shell-script runner'"'"' 1 text/html '"'"'validate st2 local-shell-script runner content'"'"' '"'"''"'"'', user: stanley, sudo: False
```
This "chmod +x " operation cause failure when you are using stackstorm-ha helm chart based deployment with an immutable file system for packs.
https://docs.stackstorm.com/install/k8s_ha.html#method-1-st2packs-images-the-default
For example, my custom pack deployed via the st2pack image method fails to run the action since the "chmod +x" instruction cannot be executed on a read-only file system.
```
{
"failed": true,
"succeeded": false,
"return_code": 1,
"stdout": "",
"stderr": "chmod: changing permissions of '/opt/stackstorm/packs/workflow/actions/verify_env.sh': Read-only file system"
}
```
**Logs:**
```
2022-03-08 13:06:39,736 INFO [-] Executing action via LocalRunner: a2bdfba5-682b-47b2-9485-4241b94501cf
2022-03-08 13:06:39,737 INFO [-] [Action info] name: verify_env, Id: 622754dfb56ccf38de50a292, command: chmod +x /opt/stackstorm/packs/workflow/actions/verify_env.sh ; sudo -E -H -u stanley -- bash -c '/opt/stackstorm/packs/workflow/actions/verify_env.sh '"'"'MY_ARGUMENTS_HERE'"'"'', user: stanley, sudo: False
2022-03-08 13:06:39,748 INFO [-] [622754de749089f0a983f6c3] Action execution "622754dfb56ccf38de50a293" for task "verify_env" is updated and in "running" state.
2022-03-08 13:06:39,848 INFO [-] [622754de749089f0a983f6c3] Action execution "622754dfb56ccf38de50a293" for task "verify_env" is updated and in "failed" state.
2022-03-08 13:06:39,855 INFO [-] Found 0 rules defined for trigger core.st2.generic.actiontrigger
2022-03-08 13:06:39,856 INFO [-] No matching rules found for trigger instance 622754dfe3850ebc7fd8d8c8.
```
I guess it's failing because of the condition mentioned here below for the local shell script runner.
https://github.com/StackStorm/st2/blob/master/contrib/runners/local_runner/local_runner/base.py#L121
### STACKSTORM VERSION
```
root@m1-staging-st2actionrunner-6664d699c-55z5t:/opt/stackstorm# st2 --version
st2 3.6.0, on Python 3.6.9
```
### OS, environment, install method
stackstorm-ha helm deployed k8s environment running on EKS cluster
### Steps to reproduce the problem
Follow the method mentioned here to deploy a custom st2 pack image and try to execute the action with runner type as "local-shell-script"
https://docs.stackstorm.com/install/k8s_ha.html#method-1-st2packs-images-the-default
### Expected Results
The action executes fine without a "chmod: changing permissions of '/opt/stackstorm/packs/custom-pack/actions/custom-script.sh': Read-only file system" failure and return the results.
### Actual Results
```
{
"failed": true,
"succeeded": false,
"return_code": 1,
"stdout": "",
"stderr": "chmod: changing permissions of '/opt/stackstorm/packs/workflow/actions/verify_env.sh': Read-only file system"
}
```
Thanks!
| 0easy
|
Title: Implement various output modules for go-bot
Body: The go-bot defaults to template-based response generation (i.e. the model learns to respond with relevant templates) though both non-templated and non-natural-language (e.g. #1196 verbose intermediate calculations logs) output features seem relevant.
There has been done some refactoring to allow such extensions of the go-bot (yet some ideas are to be finished).
To implement some additional output modules **the contribution could implement the [NLG module interface](https://github.com/deepmipt/DeepPavlov/blob/master/deeppavlov/models/go_bot/nlg/nlg_manager_interface.py).** The contribution could require the further refactor of the main go-bot codebase, do not hesitate to start a discussion on such a case. | 0easy
|
Title: Iframe component
Body: Should be pretty simple to implement. | 0easy
|
Title: Fix punycode deprecation warning
Body: # Description
`(node:19052) [DEP0040] DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead.`
# Plausible causes
- Local node version being v21.7.1. Even numbers are LTS.
# Fix
Likely - Upgrade yarn / pnpm and lock the version in package.json
# Resources
https://github.com/yarnpkg/yarn/issues/9013 | 0easy
|
Title: Write a script to sync translation in EN with other locales
Body: The script should accept an option locales params, example signature in TS
```ts
type Params = {
locales?: string[]
}
``` | 0easy
|
Title: How to get two coaxial pieces of data to be displayed together instead of divided into two views?
Body: How to get two coaxial pieces of data to be displayed together instead of divided into two views?
Such as a dataset that there is the same X-axis of date but two attribute | 0easy
|
Title: Add Merge Request merge_status and detailed_merge_status constants
Body: ## Description of the problem, including code/CLI snippet
There are a bunch of possible `merge_status` and `detailed_merge_status` values for a Merge Request. Add these as constants.
## Expected Behavior
You can find the possible values in the `const` module.
## Actual Behavior
The values are not to be found in the library.
## Specifications
- python-gitlab version: 3.15.0
- API version you are using (v3/v4): v4
- Gitlab server version (or gitlab.com): n/a
| 0easy
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.