📄 PDF Support in the Hugging Face Dataset Viewer



PDFs are a common format for sharing unstructured content — including legal documents, research papers, digitized books, and scanned reports. Until now, working with PDF-based datasets on the Hub required downloading files and relying on external tools to inspect or process them.
Hugging Face Dataset Viewer now supports native PDF rendering — allowing users to preview and interact with documents directly in the browser.
🔧 New Viewer Capabilities
- Thumbnail previews: The viewer now generates and displays a thumbnail (cover page) for each PDF file.

- Inline rendering: PDFs can be opened and browsed directly within the viewer, without requiring local downloads.

- Searchable by modality: PDF datasets can be discovered via the Document modality filter in the Hub.
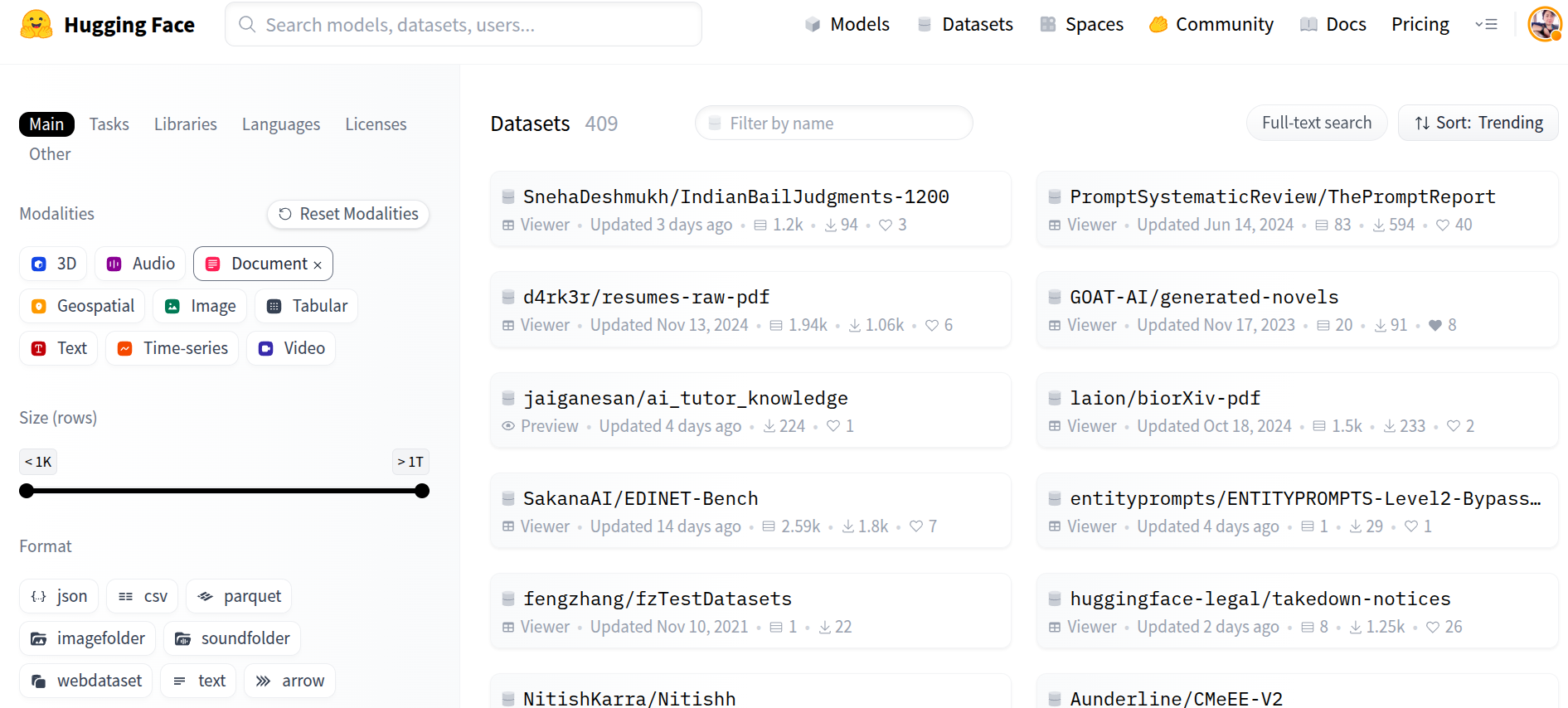
These capabilities improve transparency, reproducibility, and early-stage dataset inspection — particularly in document-heavy domains.
🐍 Programmatic PDF Processing with datasets and pdfplumber
Starting from datasets version 3.5.0, PDF content can be loaded as typed objects using the Pdf feature.
Each entry is represented as a PdfDocument, supporting:
- Page-level navigation
- Text extraction
- Table detection
- Embedded image access
- Thumbnail rendering
Low-level operations are powered by pdfplumber, which handles PDF parsing internally.
▶️ Example
from datasets import load_dataset
# Load a dataset with PDF files
dataset = load_dataset("GOAT-AI/generated-novels", split="train")
# Access the first PDF document
first_pdf = dataset['pdf'][0]
# Check total number of pages
print(f"Total pages: {len(first_pdf.pages)}")
# Generate a thumbnail image
cover_image = first_pdf.pages[0].to_image()
# Optionally save: cover_image.save("cover.png")
# Extract text from the second page
if len(first_pdf.pages) > 1:
page_text = first_pdf.pages[1].extract_text()
print("Page 2 text:", page_text)
✅ Conclusion
Support for PDFs in both the Dataset Viewer and datasets library streamlines exploration and programmatic processing of document-based datasets. This is especially useful in workflows involving legal documents, OCR pipelines, large-scale report mining, or research paper analysis.
For more information and tooling: