

Upload 10 files
Browse files- config.json +25 -0
- confusion_matrix.png +0 -0
- evaluation_report.txt +29 -0
- model.safetensors +3 -0
- prediction_errors.csv +3 -0
- special_tokens_map.json +7 -0
- tokenizer.json +0 -0
- tokenizer_config.json +56 -0
- training_config.json +15 -0
- vocab.txt +0 -0
config.json
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"activation": "gelu",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"DistilBertForSequenceClassification"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.1,
|
| 7 |
+
"dim": 768,
|
| 8 |
+
"dropout": 0.1,
|
| 9 |
+
"hidden_dim": 3072,
|
| 10 |
+
"initializer_range": 0.02,
|
| 11 |
+
"max_position_embeddings": 512,
|
| 12 |
+
"model_type": "distilbert",
|
| 13 |
+
"n_heads": 12,
|
| 14 |
+
"n_layers": 6,
|
| 15 |
+
"output_past": true,
|
| 16 |
+
"pad_token_id": 0,
|
| 17 |
+
"problem_type": "single_label_classification",
|
| 18 |
+
"qa_dropout": 0.1,
|
| 19 |
+
"seq_classif_dropout": 0.2,
|
| 20 |
+
"sinusoidal_pos_embds": false,
|
| 21 |
+
"tie_weights_": true,
|
| 22 |
+
"torch_dtype": "float32",
|
| 23 |
+
"transformers_version": "4.53.1",
|
| 24 |
+
"vocab_size": 119547
|
| 25 |
+
}
|
confusion_matrix.png
ADDED
|
evaluation_report.txt
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
=== Name SMS Classifier - Evaluation Report ===
|
| 2 |
+
|
| 3 |
+
Model: distilbert-base-multilingual-cased
|
| 4 |
+
Training time: 2025-07-30 21:13:45
|
| 5 |
+
|
| 6 |
+
=== Main Metrics ===
|
| 7 |
+
Accuracy: 0.9977
|
| 8 |
+
Precision: 0.9916
|
| 9 |
+
Recall: 1.0000
|
| 10 |
+
F1-Score: 0.9958
|
| 11 |
+
ROC-AUC: 0.9998
|
| 12 |
+
|
| 13 |
+
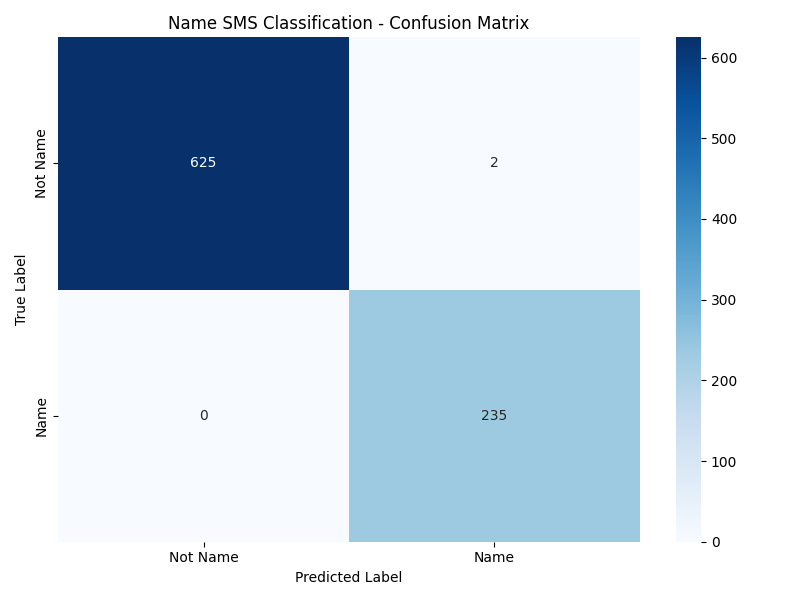
=== Confusion Matrix ===
|
| 14 |
+
True\Pred 0(Not Name) 1(Name)
|
| 15 |
+
0(Not Name) 625 2
|
| 16 |
+
1(Name) 0 235
|
| 17 |
+
|
| 18 |
+
=== 預測錯誤分析 ===
|
| 19 |
+
總錯誤數: 2
|
| 20 |
+
False Positive (誤判為姓名): 2
|
| 21 |
+
False Negative (漏判姓名): 0
|
| 22 |
+
|
| 23 |
+
--- False Positive 錯誤樣本 (前10個) ---
|
| 24 |
+
1. 真實標籤: 0(非姓名), 預測標籤: 1(姓名), 信心度: 0.995
|
| 25 |
+
簡訊ID: 71773 簡訊內容: 高雄小華,您已報名「英語聽力測驗」並成功確認,測驗將於6月2日舉行,請攜帶有效身份證明文件。
|
| 26 |
+
|
| 27 |
+
2. 真實標籤: 0(非姓名), 預測標籤: 1(姓名), 信心度: 0.995
|
| 28 |
+
簡訊ID: 111908 簡訊內容: 提醒您,系統顯示林誠支付平台會員編號FA5620帳務餘額為負NT$720,逾期未補繳將暫停交易與提款功能,請即刻處理以恢復帳戶正常。
|
| 29 |
+
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f386bb52592bf9d5f6ba0e5742f481c7e084eabe874c12514271602eaa6a15ae
|
| 3 |
+
size 541317368
|
prediction_errors.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
sms_id,index,text,true_label,pred_label,error_type,confidence,prob_not_name,prob_name
|
| 2 |
+
71773,143,高雄小華,您已報名「英語聽力測驗」並成功確認,測驗將於6月2日舉行,請攜帶有效身份證明文件。,0,1,False Positive,0.9946750402450562,0.005324934143573046,0.9946750402450562
|
| 3 |
+
111908,241,提醒您,系統顯示林誠支付平台會員編號FA5620帳務餘額為負NT$720,逾期未補繳將暫停交易與提款功能,請即刻處理以恢復帳戶正常。,0,1,False Positive,0.994642972946167,0.005357014015316963,0.994642972946167
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": "[CLS]",
|
| 3 |
+
"mask_token": "[MASK]",
|
| 4 |
+
"pad_token": "[PAD]",
|
| 5 |
+
"sep_token": "[SEP]",
|
| 6 |
+
"unk_token": "[UNK]"
|
| 7 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "[PAD]",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"100": {
|
| 12 |
+
"content": "[UNK]",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"101": {
|
| 20 |
+
"content": "[CLS]",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"102": {
|
| 28 |
+
"content": "[SEP]",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"103": {
|
| 36 |
+
"content": "[MASK]",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
}
|
| 43 |
+
},
|
| 44 |
+
"clean_up_tokenization_spaces": false,
|
| 45 |
+
"cls_token": "[CLS]",
|
| 46 |
+
"do_lower_case": false,
|
| 47 |
+
"extra_special_tokens": {},
|
| 48 |
+
"mask_token": "[MASK]",
|
| 49 |
+
"model_max_length": 512,
|
| 50 |
+
"pad_token": "[PAD]",
|
| 51 |
+
"sep_token": "[SEP]",
|
| 52 |
+
"strip_accents": null,
|
| 53 |
+
"tokenize_chinese_chars": true,
|
| 54 |
+
"tokenizer_class": "DistilBertTokenizer",
|
| 55 |
+
"unk_token": "[UNK]"
|
| 56 |
+
}
|
training_config.json
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_name": "distilbert-base-multilingual-cased",
|
| 3 |
+
"max_length": 512,
|
| 4 |
+
"batch_size": 16,
|
| 5 |
+
"learning_rate": 2e-05,
|
| 6 |
+
"num_epochs": 5,
|
| 7 |
+
"warmup_steps": 500,
|
| 8 |
+
"weight_decay": 0.01,
|
| 9 |
+
"random_seed": 42,
|
| 10 |
+
"device": "mps",
|
| 11 |
+
"use_wandb": true,
|
| 12 |
+
"wandb_project": "\"forensic-name-classifier\"",
|
| 13 |
+
"wandb_run_name": null,
|
| 14 |
+
"training_time": "2025-07-30T21:13:46.023856"
|
| 15 |
+
}
|
vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|