
brutalist website introducing this model
Browse filesTitle: zai-org/GLM-4.5V · Hugging Face
URL Source: https://huggingface.co/zai-org/GLM-4.5V
Markdown Content:

This model is part of the GLM-V family of models, introduced in the paper [GLM-4.1V-Thinking and GLM-4.5V: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning](https://huggingface.co/papers/2507.01006).
* **Paper**: [https://huggingface.co/papers/2507.01006](https://huggingface.co/papers/2507.01006)
* **GitHub Repository**: [https://github.com/zai-org/GLM-V/](https://github.com/zai-org/GLM-V/)
* **Online Demo**: [https://chat.z.ai/](https://chat.z.ai/)
* **API Access**: [ZhipuAI Open Platform](https://docs.z.ai/guides/vlm/glm-4.5v)
* **Desktop Assistant App**: [https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App](https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App)
* **Discord Community**: [https://discord.com/invite/8cnQKdAprg](https://discord.com/invite/8cnQKdAprg)
[](https://huggingface.co/zai-org/GLM-4.5V#introduction--model-overview) Introduction & Model Overview
------------------------------------------------------------------------------------------------------
Vision-language models (VLMs) have become a key cornerstone of intelligent systems. As real-world AI tasks grow increasingly complex, VLMs urgently need to enhance reasoning capabilities beyond basic multimodal perception — improving accuracy, comprehensiveness, and intelligence — to enable complex problem solving, long-context understanding, and multimodal agents.
Through our open-source work, we aim to explore the technological frontier together with the community while empowering more developers to create exciting and innovative applications.
**This Hugging Face repository hosts the `GLM-4.5V` model, part of the `GLM-V` series.**
### [](https://huggingface.co/zai-org/GLM-4.5V#glm-45v-1) GLM-4.5V
GLM-4.5V is based on ZhipuAI’s next-generation flagship text foundation model GLM-4.5-Air (106B parameters, 12B active). It continues the technical approach of GLM-4.1V-Thinking, achieving SOTA performance among models of the same scale on 42 public vision-language benchmarks. It covers common tasks such as image, video, and document understanding, as well as GUI agent operations.
[](https://raw.githubusercontent.com/zai-org/GLM-V/refs/heads/main/resources/bench_45v.jpeg)
Beyond benchmark performance, GLM-4.5V focuses on real-world usability. Through efficient hybrid training, it can handle diverse types of visual content, enabling full-spectrum vision reasoning, including:
* **Image reasoning** (scene understanding, complex multi-image analysis, spatial recognition)
* **Video understanding** (long video segmentation and event recognition)
* **GUI tasks** (screen reading, icon recognition, desktop operation assistance)
* **Complex chart & long document parsing** (research report analysis, information extraction)
* **Grounding** (precise visual element localization)
The model also introduces a **Thinking Mode** switch, allowing users to balance between quick responses and deep reasoning. This switch works the same as in the `GLM-4.5` language model.
### [](https://huggingface.co/zai-org/GLM-4.5V#glm-41v-9b) GLM-4.1V-9B
_Contextual information about GLM-4.1V-9B is provided for completeness, as it is part of the GLM-V series and foundational to GLM-4.5V's development._
Built on the [GLM-4-9B-0414](https://github.com/zai-org/GLM-4) foundation model, the **GLM-4.1V-9B-Thinking** model introduces a reasoning paradigm and uses RLCS (Reinforcement Learning with Curriculum Sampling) to comprehensively enhance model capabilities. It achieves the strongest performance among 10B-level VLMs and matches or surpasses the much larger Qwen-2.5-VL-72B in 18 benchmark tasks.
We also open-sourced the base model **GLM-4.1V-9B-Base** to support researchers in exploring the limits of vision-language model capabilities.
[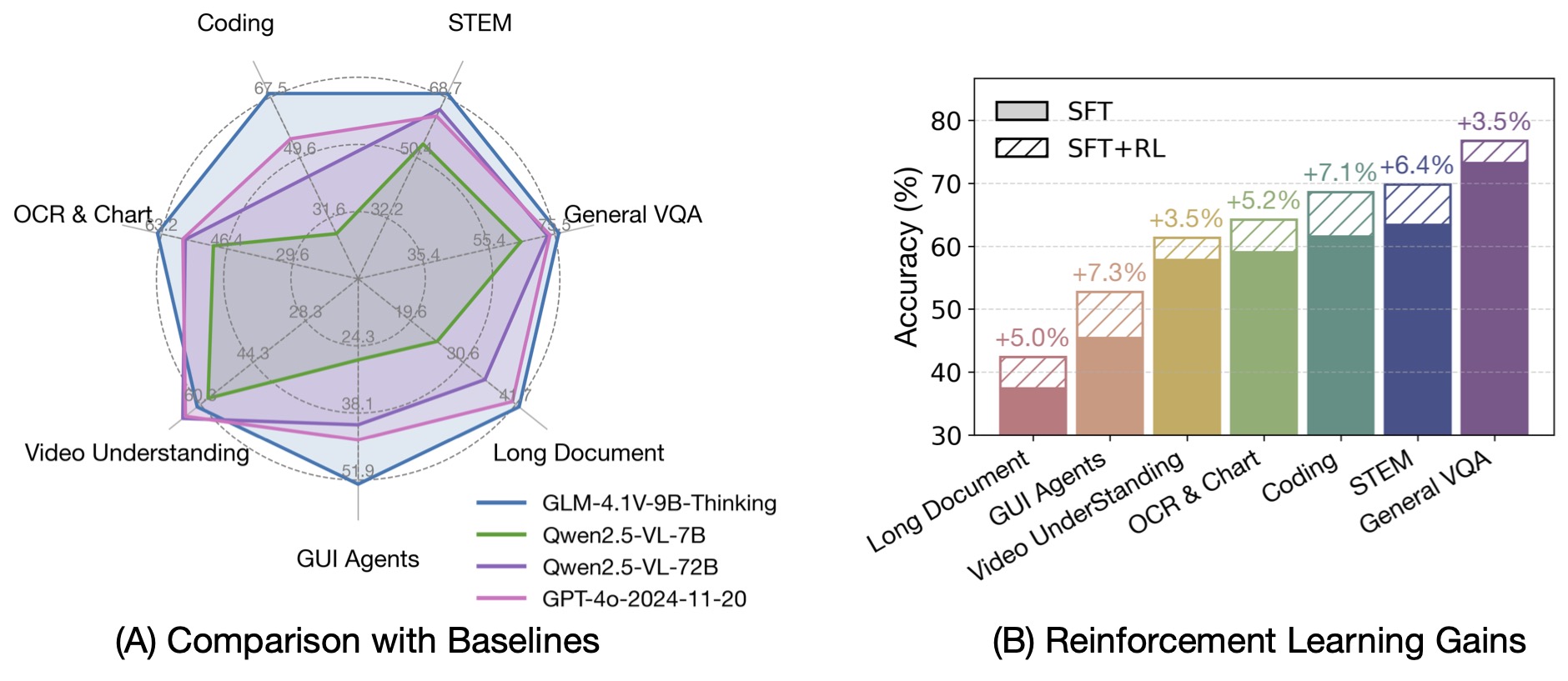](https://raw.githubusercontent.com/zai-org/GLM-V/refs/heads/main/resources/rl.jpeg)
Compared with the previous generation CogVLM2 and GLM-4V series, **GLM-4.1V-Thinking** brings:
1. The series’ first reasoning-focused model, excelling in multiple domains beyond mathematics.
2. **64k** context length support.
3. Support for **any aspect ratio** and up to **4k** image resolution.
4. A bilingual (Chinese/English) open-source version.
GLM-4.1V-9B-Thinking integrates the **Chain-of-Thought** reasoning mechanism, improving accuracy, richness, and interpretability. It leads on 23 out of 28 benchmark tasks at the 10B parameter scale, and outperforms Qwen-2.5-VL-72B on 18 tasks despite its smaller size.
[](https://raw.githubusercontent.com/zai-org/GLM-V/refs/heads/main/resources/bench.jpeg)
[](https://huggingface.co/zai-org/GLM-4.5V#project-updates) Project Updates
---------------------------------------------------------------------------
* 🔥 **News**: `2025/08/11`: We released **GLM-4.5V** with significant improvements across multiple benchmarks. We also open-sourced our handcrafted **desktop assistant app** for debugging. Once connected to GLM-4.5V, it can capture visual information from your PC screen via screenshots or screen recordings. Feel free to try it out or customize it into your own multimodal assistant. Click [here](https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App) to download the installer or [build from source](https://github.com/zai-org/GLM-V/blob/main/examples/vllm-chat-helper/README.md)!
* **News**: `2025/07/16`: We have open-sourced the **VLM Reward System** used to train GLM-4.1V-Thinking. View the [code repository](https://github.com/zai-org/GLM-V/tree/main/glmv_reward) and run locally: `python examples/reward_system_demo.py`.
* **News**: `2025/07/01`: We released **GLM-4.1V-9B-Thinking** and its [technical report](https://arxiv.org/abs/2507.01006).
[](https://huggingface.co/zai-org/GLM-4.5V#model-implementation-code) Model Implementation Code
-----------------------------------------------------------------------------------------------
* GLM-4.5V model algorithm: see the full implementation in [transformers](https://github.com/huggingface/transformers/tree/main/src/transformers/models/glm4v_moe).
* GLM-4.1V-9B-Thinking model algorithm: see the full implementation in [transformers](https://github.com/huggingface/transformers/tree/main/src/transformers/models/glm4v).
* Both models share identical multimodal preprocessing, but use different conversation templates — please distinguish carefully.
[](https://huggingface.co/zai-org/GLM-4.5V#usage) Usage
-------------------------------------------------------
### [](https://huggingface.co/zai-org/GLM-4.5V#environment-installation) Environment Installation
For `SGLang` and `transformers`:
```
pip install -r https://raw.githubusercontent.com/zai-org/GLM-V/main/requirements.txt
```
For `vLLM`:
```
pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
pip install transformers-v4.55.0-GLM-4.5V-preview
```
### [](https://huggingface.co/zai-org/GLM-4.5V#quick-start-with-transformers) Quick Start with Transformers
```
from transformers import AutoProcessor, Glm4vMoeForConditionalGeneration
import torch
MODEL_PATH = "zai-org/GLM-4.5V"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://upload.wikimedia.org/wikipedia/commons/f/fa/Grayscale_8bits_palette_sample_image.png"
},
{
"type": "text",
"text": "describe this image"
}
],
}
]
processor = AutoProcessor.from_pretrained(MODEL_PATH)
model = Glm4vMoeForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype="auto",
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
inputs.pop("token_type_ids", None)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
```
The special tokens `<|begin_of_box|>` and `<|end_of_box|>` in the response mark the answer’s bounding box in the image. The bounding box is given as four numbers — for example `[x1, y1, x2, y2]`, where `(x1, y1)` is the top-left corner and `(x2, y2`)` is the bottom-right corner. The bracket style may vary ([], [[]], (), <>, etc.), but the meaning is the same: it encloses the coordinates of the box. These coordinates are relative values between 0 and 1000, normalized to the image size.
For more code information, please visit our [GitHub](https://github.com/zai-org/GLM-V/).
### [](https://huggingface.co/zai-org/GLM-4.5V#grounding-example) Grounding Example
GLM-4.5V equips precise grounding capabilities. Given a prompt that requests the location of a specific object, GLM-4.5V is able to reasoning step-by-step and identify the bounding boxes of the target object. The query prompt supports complex descriptions of the target object as well as specified output formats, for example:
> * Help me to locate in the image and give me its bounding boxes.
> * Please pinpoint the bounding box [[x1,y1,x2,y2], …] in the image as per the given description.
Here, `<expr>` is the description of the target object. The output bounding box is a quadruple $$[x_1,y_1,x_2,y_2]$$ composed of the coordinates of the top-left and bottom-right corners, where each value is normalized by the image width (for x) or height (for y) and scaled by 1000.
In the response, the special tokens `<|begin_of_box|>` a
- README.md +7 -4
- index.html +157 -18
|
@@ -1,10 +1,13 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
|
| 4 |
-
colorFrom: purple
|
| 5 |
colorTo: blue
|
|
|
|
| 6 |
sdk: static
|
| 7 |
pinned: false
|
|
|
|
|
|
|
| 8 |
---
|
| 9 |
|
| 10 |
-
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: GLM-4.5V Brutalist Portal 🚧
|
| 3 |
+
colorFrom: green
|
|
|
|
| 4 |
colorTo: blue
|
| 5 |
+
emoji: 🐳
|
| 6 |
sdk: static
|
| 7 |
pinned: false
|
| 8 |
+
tags:
|
| 9 |
+
- deepsite-v3
|
| 10 |
---
|
| 11 |
|
| 12 |
+
# Welcome to your new DeepSite project!
|
| 13 |
+
This project was created with [DeepSite](https://deepsite.hf.co).
|
|
@@ -1,19 +1,158 @@
|
|
| 1 |
-
<!
|
| 2 |
-
<html>
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 19 |
</html>
|
|
|
|
| 1 |
+
<!DOCTYPE html>
|
| 2 |
+
<html lang="en">
|
| 3 |
+
<head>
|
| 4 |
+
<meta charset="UTF-8">
|
| 5 |
+
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
| 6 |
+
<title>GLM-4.5V · zai-org</title>
|
| 7 |
+
<link rel="icon" type="image/x-icon" href="/static/favicon.ico">
|
| 8 |
+
<script src="https://cdn.tailwindcss.com"></script>
|
| 9 |
+
<script src="https://unpkg.com/feather-icons"></script>
|
| 10 |
+
<script src="https://cdn.jsdelivr.net/npm/feather-icons/dist/feather.min.js"></script>
|
| 11 |
+
<script>
|
| 12 |
+
tailwind.config = {
|
| 13 |
+
theme: {
|
| 14 |
+
extend: {
|
| 15 |
+
colors: {
|
| 16 |
+
brutal: {
|
| 17 |
+
50: '#fafafa',
|
| 18 |
+
100: '#f5f5f5',
|
| 19 |
+
200: '#eeeeee',
|
| 20 |
+
300: '#e0e0e0',
|
| 21 |
+
400: '#bdbdbd',
|
| 22 |
+
500: '#9e9e9e',
|
| 23 |
+
600: '#757575',
|
| 24 |
+
700: '#616161',
|
| 25 |
+
800: '#424242',
|
| 26 |
+
900: '#212121'
|
| 27 |
+
}
|
| 28 |
+
}
|
| 29 |
+
}
|
| 30 |
+
}
|
| 31 |
+
}
|
| 32 |
+
</script>
|
| 33 |
+
</head>
|
| 34 |
+
<body class="bg-brutal-100 text-brutal-900 font-mono">
|
| 35 |
+
<!-- Navigation -->
|
| 36 |
+
<nav class="border-b-4 border-brutal-900 bg-brutal-200 p-4">
|
| 37 |
+
<div class="container mx-auto px-4 flex justify-between items-center">
|
| 38 |
+
<div class="flex items-center space-x-4">
|
| 39 |
+
<div class="w-8 h-8 bg-brutal-900"></div>
|
| 40 |
+
<div class="hidden md:flex space-x-6">
|
| 41 |
+
<a href="#overview" class="hover:bg-brutal-300 px-3 py-1">Overview</a>
|
| 42 |
+
<a href="#capabilities" class="hover:bg-brutal-300 px-3 py-1">Capabilities</a>
|
| 43 |
+
<a href="#implementation" class="hover:bg-brutal-300 px-3 py-1">Implementation</a>
|
| 44 |
+
<a href="#updates" class="hover:bg-brutal-300 px-3 py-1">Updates</a>
|
| 45 |
+
<a href="#citation" class="hover:bg-brutal-300 px-3 py-1">Citation</a>
|
| 46 |
+
</div>
|
| 47 |
+
<button class="md:hidden p-2">
|
| 48 |
+
<i data-feather="menu"></i>
|
| 49 |
+
</button>
|
| 50 |
+
</div>
|
| 51 |
+
</nav>
|
| 52 |
+
|
| 53 |
+
<!-- Hero Section -->
|
| 54 |
+
<section class="border-b-4 border-brutal-900 bg-brutal-200">
|
| 55 |
+
<div class="container mx-auto px-4 py-20">
|
| 56 |
+
<div class="max-w-6xl mx-auto">
|
| 57 |
+
<!-- Model Title -->
|
| 58 |
+
<div class="bg-brutal-300 p-6 mb-8">
|
| 59 |
+
<h1 class="text-4xl md:text-6xl font-black tracking-tight">zai-org/GLM-4.5V</h1>
|
| 60 |
+
<p class="text-xl mt-4">A Vision-Language Model with 1M Context and Grounding</p>
|
| 61 |
+
</div>
|
| 62 |
+
<!-- Model Logo -->
|
| 63 |
+
<div class="flex justify-center mb-8">
|
| 64 |
+
<div class="w-32 h-32 bg-brutal-900 flex items-center justify-center">
|
| 65 |
+
<div class="w-24 h-24 bg-brutal-100 border-4 border-brutal-900">
|
| 66 |
+
<div class="w-20 h-20 bg-brutal-500"></div>
|
| 67 |
+
</div>
|
| 68 |
+
</div>
|
| 69 |
+
</div>
|
| 70 |
+
</div>
|
| 71 |
+
</section>
|
| 72 |
+
|
| 73 |
+
<!-- Main Content Sections -->
|
| 74 |
+
<main class="container mx-auto px-4 py-12">
|
| 75 |
+
<!-- Introduction -->
|
| 76 |
+
<section id="overview" class="mb-16">
|
| 77 |
+
<div class="border-4 border-brutal-900 bg-brutal-200 p-8">
|
| 78 |
+
<h2 class="text-3xl font-black mb-6">GLM-4.5V: The Multimodal Powerhouse</h2>
|
| 79 |
+
<div class="grid grid-cols-1 md:grid-cols-2 gap-8">
|
| 80 |
+
<div>
|
| 81 |
+
<p class="text-lg leading-relaxed">GLM-4.5V is zai-org's latest vision-language model featuring 1M context length, superior multimodal capabilities, and advanced grounding functionality.</p>
|
| 82 |
+
</div>
|
| 83 |
+
</div>
|
| 84 |
+
</section>
|
| 85 |
+
|
| 86 |
+
<!-- Capabilities Grid -->
|
| 87 |
+
<section id="capabilities" class="mb-16">
|
| 88 |
+
<div class="border-4 border-brutal-900 bg-brutal-200 p-6">
|
| 89 |
+
<h3 class="text-2xl font-black mb-6 border-b-4 border-brutal-900 p-4">
|
| 90 |
+
<h3 class="text-xl font-black mb-4">Multimodal Capabilities</h3>
|
| 91 |
+
<div class="grid grid-cols-1 md:grid-cols-3 gap-4">
|
| 92 |
+
<div class="border-4 border-brutal-900 bg-brutal-200 p-6">
|
| 93 |
+
<div class="text-center">
|
| 94 |
+
<div class="w-16 h-16 bg-brutal-900"></div>
|
| 95 |
+
<div class="bg-brutal-300 p-4">
|
| 96 |
+
<h4 class="text-lg font-black">Image Reasoning</h4>
|
| 97 |
+
<p class="mt-2">Advanced visual question answering and detailed image analysis</p>
|
| 98 |
+
</div>
|
| 99 |
+
</div>
|
| 100 |
+
</section>
|
| 101 |
+
|
| 102 |
+
<!-- Implementation Section -->
|
| 103 |
+
<section id="implementation" class="mb-16">
|
| 104 |
+
<h2 class="text-3xl font-black mb-6">Implementation & Usage</h2>
|
| 105 |
+
<div class="border-4 border-brutal-900 bg-brutal-200 p-4">
|
| 106 |
+
<h3 class="text-xl font-black mb-4">Quick Start</h3>
|
| 107 |
+
<div class="bg-brutal-900 text-brutal-100 p-6">
|
| 108 |
+
<h3 class="text-lg font-black mb-4">Environment Setup</h3>
|
| 109 |
+
<div class="bg-brutal-300 p-4">
|
| 110 |
+
<code class="block p-4 bg-brutal-800 text-brutal-100 overflow-x-auto">
|
| 111 |
+
# Install dependencies
|
| 112 |
+
pip install torch torchvision transformers
|
| 113 |
+
pip install git+https://github.com/zai-org/glm-4.5v
|
| 114 |
+
</code>
|
| 115 |
+
</div>
|
| 116 |
+
</section>
|
| 117 |
+
|
| 118 |
+
<!-- Updates Section -->
|
| 119 |
+
<section id="updates" class="mb-16">
|
| 120 |
+
<h2 class="text-3xl font-black mb-6">Project Updates</h2>
|
| 121 |
+
<div class="border-4 border-brutal-900 bg-brutal-200 p-4">
|
| 122 |
+
<h3 class="text-lg font-black">Latest Release: v1.0.0</h3>
|
| 123 |
+
<div class="space-y-4">
|
| 124 |
+
<div class="border-4 border-brutal-900 bg-brutal-300 p-4">
|
| 125 |
+
<p class="text-sm text-brutal-600">2024-12-19</p>
|
| 126 |
+
<p class="text-lg">Initial release with comprehensive vision-language capabilities</p>
|
| 127 |
+
</div>
|
| 128 |
+
</section>
|
| 129 |
+
|
| 130 |
+
<!-- Citation -->
|
| 131 |
+
<section id="citation" class="mb-16">
|
| 132 |
+
<div class="border-4 border-brutal-900 bg-brutal-200 p-4">
|
| 133 |
+
<p class="font-medium">If you use GLM-4.5V in your research, please cite:</p>
|
| 134 |
+
<div class="bg-brutal-900 text-brutal-100 p-6">
|
| 135 |
+
<p class="text-sm">@misc{glm45v2024,<br>
|
| 136 |
+
title={GLM-4.5V: A Vision-Language Model with 1M Context</p>
|
| 137 |
+
</section>
|
| 138 |
+
</main>
|
| 139 |
+
|
| 140 |
+
<!-- Footer -->
|
| 141 |
+
<footer class="border-t-4 border-brutal-900 bg-brutal-200 p-8">
|
| 142 |
+
<div class="flex flex-wrap justify-between items-center">
|
| 143 |
+
<div class="flex space-x-6">
|
| 144 |
+
<a href="https://github.com/zai-org/GLM-4.5V">
|
| 145 |
+
<div class="flex space-x-4">
|
| 146 |
+
<a href="https://github.com/zai-org/GLM-4.5V" class="hover:bg-brutal-300 px-3 py-1">GitHub</a>
|
| 147 |
+
<a href="https://huggingface.co/zai-org/GLM-4.5V" class="hover:bg-brutal-300 px-3 py-1">Demo</a>
|
| 148 |
+
<a href="https://huggingface.co/zai-org/GLM-4.5V" class="hover:bg-brutal-300 px-3 py-1">API</a>
|
| 149 |
+
<a href="https://discord.gg/zai-org" class="hover:bg-brutal-300 px-3 py-1">Discord</a>
|
| 150 |
+
</div>
|
| 151 |
+
</div>
|
| 152 |
+
</footer>
|
| 153 |
+
|
| 154 |
+
<script>
|
| 155 |
+
feather.replace();
|
| 156 |
+
</script>
|
| 157 |
+
</body>
|
| 158 |
</html>
|