
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +624 -0
- .gradio/certificate.pem +31 -0
- LICENSE +21 -0
- README.md +210 -7
- accelerate_configs/1_gpu.yaml +15 -0
- accelerate_configs/1_node_8_gpus_deepspeed_zero2.yaml +21 -0
- accelerate_configs/1_node_8_gpus_deepspeed_zero3.yaml +24 -0
- accelerate_configs/8_node_8_gpus_deepspeed_zero2.yaml +21 -0
- app.py +894 -0
- assets/WX-mmada-2.jpeg +3 -0
- assets/WX-mmada-3.jpeg +3 -0
- assets/WX-mmada.jpeg +3 -0
- assets/example_compare.png +3 -0
- assets/llm.png +0 -0
- assets/mmu.png +0 -0
- assets/pipeline.png +3 -0
- assets/random.png +0 -0
- assets/reward_trend.png +0 -0
- assets/showcase0.8.gif +3 -0
- assets/t2i.png +0 -0
- assets/title.png +3 -0
- assets/wx-mmada-0613.jpeg +3 -0
- configs/mmada_demo.yaml +95 -0
- configs/mmada_pretraining_stage1_llada_instruct.yaml +100 -0
- configs/mmada_pretraining_stage2_llada_instruct.yaml +109 -0
- configs/mmada_pretraining_stage3_llada_instruct.yaml +112 -0
- configs/mmada_pretraining_stage3_llada_instruct_512_cot.yaml +123 -0
- configs/mmada_pretraining_stage4_llada_instruct.yaml +134 -0
- generate.py +131 -0
- inference_mmu.py +114 -0
- inference_t2i.py +129 -0
- lm_chat_validation/description.txt +5 -0
- lm_chat_validation/questions.jsonl +11 -0
- mmu_validation/Decoupling Visual Encoding.png +3 -0
- mmu_validation/ai2d.png +3 -0
- mmu_validation/clevr.jpg +0 -0
- mmu_validation/docvqa.png +0 -0
- mmu_validation/dog.png +0 -0
- mmu_validation/geo.jpg +0 -0
- mmu_validation/llava1.jpg +3 -0
- mmu_validation/llava2.jpg +0 -0
- mmu_validation/prompts.jsonl +10 -0
- mmu_validation/prompts_with_vqa.json +116 -0
- mmu_validation/sofa_under_water.jpg +3 -0
- models/__init__.py +3 -0
- models/__pycache__/__init__.cpython-311.pyc +0 -0
- models/__pycache__/common_modules.cpython-311.pyc +0 -0
- models/__pycache__/configuration_llada.cpython-311.pyc +0 -0
- models/__pycache__/misc.cpython-311.pyc +0 -0
- models/__pycache__/modeling_llada.cpython-311.pyc +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,627 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/WX-mmada-2.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/WX-mmada-3.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
assets/WX-mmada.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
assets/example_compare.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
assets/pipeline.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
assets/showcase0.8.gif filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
assets/title.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
assets/wx-mmada-0613.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
mmu_validation/Decoupling[[:space:]]Visual[[:space:]]Encoding.png filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
mmu_validation/ai2d.png filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
mmu_validation/llava1.jpg filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
mmu_validation/sofa_under_water.jpg filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
training/questions.json filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
venv/bin/ninja filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
venv/bin/ruff filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
venv/lib/python3.11/site-packages/PIL/.dylibs/libbrotlicommon.1.1.0.dylib filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
venv/lib/python3.11/site-packages/PIL/.dylibs/libbrotlidec.1.1.0.dylib filter=lfs diff=lfs merge=lfs -text
|
| 53 |
+
venv/lib/python3.11/site-packages/PIL/.dylibs/libfreetype.6.dylib filter=lfs diff=lfs merge=lfs -text
|
| 54 |
+
venv/lib/python3.11/site-packages/PIL/.dylibs/libharfbuzz.0.dylib filter=lfs diff=lfs merge=lfs -text
|
| 55 |
+
venv/lib/python3.11/site-packages/PIL/.dylibs/libjpeg.62.4.0.dylib filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
venv/lib/python3.11/site-packages/PIL/.dylibs/liblcms2.2.dylib filter=lfs diff=lfs merge=lfs -text
|
| 57 |
+
venv/lib/python3.11/site-packages/PIL/.dylibs/liblzma.5.dylib filter=lfs diff=lfs merge=lfs -text
|
| 58 |
+
venv/lib/python3.11/site-packages/PIL/.dylibs/libopenjp2.2.5.3.dylib filter=lfs diff=lfs merge=lfs -text
|
| 59 |
+
venv/lib/python3.11/site-packages/PIL/.dylibs/libpng16.16.dylib filter=lfs diff=lfs merge=lfs -text
|
| 60 |
+
venv/lib/python3.11/site-packages/PIL/.dylibs/libtiff.6.dylib filter=lfs diff=lfs merge=lfs -text
|
| 61 |
+
venv/lib/python3.11/site-packages/PIL/.dylibs/libwebp.7.dylib filter=lfs diff=lfs merge=lfs -text
|
| 62 |
+
venv/lib/python3.11/site-packages/PIL/.dylibs/libwebpmux.3.dylib filter=lfs diff=lfs merge=lfs -text
|
| 63 |
+
venv/lib/python3.11/site-packages/PIL/.dylibs/libxcb.1.1.0.dylib filter=lfs diff=lfs merge=lfs -text
|
| 64 |
+
venv/lib/python3.11/site-packages/PIL/.dylibs/libz.1.3.1.zlib-ng.dylib filter=lfs diff=lfs merge=lfs -text
|
| 65 |
+
venv/lib/python3.11/site-packages/PIL/__pycache__/Image.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 66 |
+
venv/lib/python3.11/site-packages/PIL/__pycache__/TiffImagePlugin.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 67 |
+
venv/lib/python3.11/site-packages/PIL/_imaging.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 68 |
+
venv/lib/python3.11/site-packages/PIL/_imagingft.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 69 |
+
venv/lib/python3.11/site-packages/__pycache__/typing_extensions.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 70 |
+
venv/lib/python3.11/site-packages/accelerate/__pycache__/accelerator.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 71 |
+
venv/lib/python3.11/site-packages/accelerate/utils/__pycache__/dataclasses.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 72 |
+
venv/lib/python3.11/site-packages/accelerate/utils/__pycache__/modeling.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 73 |
+
venv/lib/python3.11/site-packages/aiohttp/_http_parser.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 74 |
+
venv/lib/python3.11/site-packages/aiohttp/_http_writer.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 75 |
+
venv/lib/python3.11/site-packages/aiohttp/_websocket/reader_c.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 76 |
+
venv/lib/python3.11/site-packages/anyio/_backends/__pycache__/_asyncio.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 77 |
+
venv/lib/python3.11/site-packages/attr/__pycache__/_make.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 78 |
+
venv/lib/python3.11/site-packages/charset_normalizer/md.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 79 |
+
venv/lib/python3.11/site-packages/charset_normalizer/md__mypyc.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 80 |
+
venv/lib/python3.11/site-packages/click/__pycache__/core.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 81 |
+
venv/lib/python3.11/site-packages/cpuinfo/__pycache__/cpuinfo.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 82 |
+
venv/lib/python3.11/site-packages/datasets/__pycache__/arrow_dataset.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 83 |
+
venv/lib/python3.11/site-packages/datasets/__pycache__/builder.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 84 |
+
venv/lib/python3.11/site-packages/datasets/__pycache__/dataset_dict.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 85 |
+
venv/lib/python3.11/site-packages/datasets/__pycache__/iterable_dataset.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 86 |
+
venv/lib/python3.11/site-packages/datasets/__pycache__/load.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 87 |
+
venv/lib/python3.11/site-packages/datasets/__pycache__/table.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 88 |
+
venv/lib/python3.11/site-packages/datasets/features/__pycache__/features.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 89 |
+
venv/lib/python3.11/site-packages/deepspeed/runtime/__pycache__/engine.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 90 |
+
venv/lib/python3.11/site-packages/deepspeed/runtime/zero/__pycache__/partition_parameters.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 91 |
+
venv/lib/python3.11/site-packages/deepspeed/runtime/zero/__pycache__/stage3.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 92 |
+
venv/lib/python3.11/site-packages/deepspeed/runtime/zero/__pycache__/stage_1_and_2.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 93 |
+
venv/lib/python3.11/site-packages/diffusers/loaders/__pycache__/lora_pipeline.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 94 |
+
venv/lib/python3.11/site-packages/diffusers/loaders/__pycache__/single_file_utils.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 95 |
+
venv/lib/python3.11/site-packages/diffusers/models/__pycache__/attention_processor.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 96 |
+
venv/lib/python3.11/site-packages/diffusers/models/__pycache__/embeddings.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 97 |
+
venv/lib/python3.11/site-packages/diffusers/models/unets/__pycache__/unet_2d_blocks.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 98 |
+
venv/lib/python3.11/site-packages/diffusers/pipelines/__pycache__/pipeline_utils.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 99 |
+
venv/lib/python3.11/site-packages/diffusers/pipelines/deprecated/versatile_diffusion/__pycache__/modeling_text_unet.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 100 |
+
venv/lib/python3.11/site-packages/diffusers/utils/__pycache__/dummy_torch_and_transformers_objects.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 101 |
+
venv/lib/python3.11/site-packages/dill/__pycache__/_dill.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 102 |
+
venv/lib/python3.11/site-packages/fairscale/nn/data_parallel/__pycache__/fully_sharded_data_parallel.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 103 |
+
venv/lib/python3.11/site-packages/frozenlist/_frozenlist.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 104 |
+
venv/lib/python3.11/site-packages/fsspec/__pycache__/spec.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 105 |
+
venv/lib/python3.11/site-packages/functorch/_C.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 106 |
+
venv/lib/python3.11/site-packages/google/_upb/_message.abi3.so filter=lfs diff=lfs merge=lfs -text
|
| 107 |
+
venv/lib/python3.11/site-packages/google/protobuf/__pycache__/descriptor_pb2.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 108 |
+
venv/lib/python3.11/site-packages/gradio/__pycache__/blocks.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 109 |
+
venv/lib/python3.11/site-packages/gradio/__pycache__/routes.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 110 |
+
venv/lib/python3.11/site-packages/gradio/_frontend_code/imageslider/img_01.png filter=lfs diff=lfs merge=lfs -text
|
| 111 |
+
venv/lib/python3.11/site-packages/gradio/_frontend_code/imageslider/img_02.png filter=lfs diff=lfs merge=lfs -text
|
| 112 |
+
venv/lib/python3.11/site-packages/gradio/_frontend_code/imageslider/img_03.png filter=lfs diff=lfs merge=lfs -text
|
| 113 |
+
venv/lib/python3.11/site-packages/gradio/templates/frontend/assets/PlotlyPlot-BIRorb_T.js.map filter=lfs diff=lfs merge=lfs -text
|
| 114 |
+
venv/lib/python3.11/site-packages/gradio/templates/frontend/static/fonts/Source[[:space:]]Sans[[:space:]]Pro/SourceSansPro-Bold.woff2 filter=lfs diff=lfs merge=lfs -text
|
| 115 |
+
venv/lib/python3.11/site-packages/gradio/templates/frontend/static/fonts/Source[[:space:]]Sans[[:space:]]Pro/SourceSansPro-Regular.woff2 filter=lfs diff=lfs merge=lfs -text
|
| 116 |
+
venv/lib/python3.11/site-packages/gradio/templates/frontend/static/img/Duck.glb filter=lfs diff=lfs merge=lfs -text
|
| 117 |
+
venv/lib/python3.11/site-packages/gradio/templates/node/build/client/_app/immutable/chunks/2.CWSJHAMp.js.br filter=lfs diff=lfs merge=lfs -text
|
| 118 |
+
venv/lib/python3.11/site-packages/gradio/templates/node/build/client/_app/immutable/chunks/AltairPlot.BVZ9FdNy.js.br filter=lfs diff=lfs merge=lfs -text
|
| 119 |
+
venv/lib/python3.11/site-packages/gradio/templates/node/build/client/_app/immutable/chunks/Index.BYFpraYw.js.br filter=lfs diff=lfs merge=lfs -text
|
| 120 |
+
venv/lib/python3.11/site-packages/gradio/templates/node/build/client/_app/immutable/chunks/Index.DFkbfyNu.js.br filter=lfs diff=lfs merge=lfs -text
|
| 121 |
+
venv/lib/python3.11/site-packages/gradio/templates/node/build/client/_app/immutable/chunks/PlotlyPlot.BUZq7W7Q.js.br filter=lfs diff=lfs merge=lfs -text
|
| 122 |
+
venv/lib/python3.11/site-packages/gradio/templates/node/build/client/_app/immutable/chunks/cytoscape.esm.C_mCjcvO.js.br filter=lfs diff=lfs merge=lfs -text
|
| 123 |
+
venv/lib/python3.11/site-packages/gradio/templates/node/build/client/_app/immutable/chunks/hls.CFPBCiRi.js.br filter=lfs diff=lfs merge=lfs -text
|
| 124 |
+
venv/lib/python3.11/site-packages/gradio/templates/node/build/client/_app/immutable/chunks/index.B4f7kVg_.js.br filter=lfs diff=lfs merge=lfs -text
|
| 125 |
+
venv/lib/python3.11/site-packages/gradio/templates/node/build/client/_app/immutable/chunks/mermaid.core.LHBCPQoh.js.br filter=lfs diff=lfs merge=lfs -text
|
| 126 |
+
venv/lib/python3.11/site-packages/gradio/templates/node/build/client/_app/immutable/chunks/vega-embed.module.GWvvoORA.js.br filter=lfs diff=lfs merge=lfs -text
|
| 127 |
+
venv/lib/python3.11/site-packages/gradio/templates/node/build/client/_app/immutable/chunks/vega-tooltip.module.DwwcB-rx.js.br filter=lfs diff=lfs merge=lfs -text
|
| 128 |
+
venv/lib/python3.11/site-packages/gradio/templates/node/build/server/chunks/PlotlyPlot-DgUTa5VG.js.map filter=lfs diff=lfs merge=lfs -text
|
| 129 |
+
venv/lib/python3.11/site-packages/gradio_client/__pycache__/media_data.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 130 |
+
venv/lib/python3.11/site-packages/hf_xet/hf_xet.abi3.so filter=lfs diff=lfs merge=lfs -text
|
| 131 |
+
venv/lib/python3.11/site-packages/huggingface_hub/__pycache__/hf_api.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 132 |
+
venv/lib/python3.11/site-packages/huggingface_hub/inference/__pycache__/_client.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 133 |
+
venv/lib/python3.11/site-packages/huggingface_hub/inference/_generated/__pycache__/_async_client.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 134 |
+
venv/lib/python3.11/site-packages/idna/__pycache__/idnadata.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 135 |
+
venv/lib/python3.11/site-packages/idna/__pycache__/uts46data.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 136 |
+
venv/lib/python3.11/site-packages/jinja2/__pycache__/compiler.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 137 |
+
venv/lib/python3.11/site-packages/latex2sympy2_extended/gen/antlr4_11_0/__pycache__/PSLexer.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 138 |
+
venv/lib/python3.11/site-packages/latex2sympy2_extended/gen/antlr4_11_0/__pycache__/PSParser.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 139 |
+
venv/lib/python3.11/site-packages/latex2sympy2_extended/gen/antlr4_13_2/__pycache__/PSLexer.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 140 |
+
venv/lib/python3.11/site-packages/latex2sympy2_extended/gen/antlr4_13_2/__pycache__/PSParser.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 141 |
+
venv/lib/python3.11/site-packages/latex2sympy2_extended/gen/antlr4_9_3/__pycache__/PSLexer.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 142 |
+
venv/lib/python3.11/site-packages/latex2sympy2_extended/gen/antlr4_9_3/__pycache__/PSParser.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 143 |
+
venv/lib/python3.11/site-packages/mpmath/__pycache__/function_docs.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 144 |
+
venv/lib/python3.11/site-packages/mpmath/tests/__pycache__/test_fp.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 145 |
+
venv/lib/python3.11/site-packages/mpmath/tests/__pycache__/test_functions2.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 146 |
+
venv/lib/python3.11/site-packages/msgpack/_cmsgpack.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 147 |
+
venv/lib/python3.11/site-packages/multidict/_multidict.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 148 |
+
venv/lib/python3.11/site-packages/multiprocess/tests/__pycache__/__init__.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 149 |
+
venv/lib/python3.11/site-packages/networkx/algorithms/isomorphism/tests/__pycache__/test_vf2pp_helpers.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 150 |
+
venv/lib/python3.11/site-packages/networkx/drawing/__pycache__/nx_pylab.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 151 |
+
venv/lib/python3.11/site-packages/networkx/drawing/tests/__pycache__/test_pylab.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 152 |
+
venv/lib/python3.11/site-packages/networkx/drawing/tests/baseline/test_display_complex.png filter=lfs diff=lfs merge=lfs -text
|
| 153 |
+
venv/lib/python3.11/site-packages/numpy/_core/__pycache__/_add_newdocs.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 154 |
+
venv/lib/python3.11/site-packages/numpy/_core/__pycache__/fromnumeric.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 155 |
+
venv/lib/python3.11/site-packages/numpy/_core/_multiarray_tests.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 156 |
+
venv/lib/python3.11/site-packages/numpy/_core/_multiarray_umath.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 157 |
+
venv/lib/python3.11/site-packages/numpy/_core/_simd.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 158 |
+
venv/lib/python3.11/site-packages/numpy/_core/tests/__pycache__/test_datetime.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 159 |
+
venv/lib/python3.11/site-packages/numpy/_core/tests/__pycache__/test_dtype.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 160 |
+
venv/lib/python3.11/site-packages/numpy/_core/tests/__pycache__/test_multiarray.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 161 |
+
venv/lib/python3.11/site-packages/numpy/_core/tests/__pycache__/test_nditer.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 162 |
+
venv/lib/python3.11/site-packages/numpy/_core/tests/__pycache__/test_numeric.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 163 |
+
venv/lib/python3.11/site-packages/numpy/_core/tests/__pycache__/test_regression.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 164 |
+
venv/lib/python3.11/site-packages/numpy/_core/tests/__pycache__/test_stringdtype.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 165 |
+
venv/lib/python3.11/site-packages/numpy/_core/tests/__pycache__/test_ufunc.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 166 |
+
venv/lib/python3.11/site-packages/numpy/_core/tests/__pycache__/test_umath.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 167 |
+
venv/lib/python3.11/site-packages/numpy/distutils/__pycache__/ccompiler_opt.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 168 |
+
venv/lib/python3.11/site-packages/numpy/distutils/__pycache__/misc_util.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 169 |
+
venv/lib/python3.11/site-packages/numpy/distutils/__pycache__/system_info.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 170 |
+
venv/lib/python3.11/site-packages/numpy/f2py/__pycache__/crackfortran.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 171 |
+
venv/lib/python3.11/site-packages/numpy/fft/_pocketfft_umath.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 172 |
+
venv/lib/python3.11/site-packages/numpy/lib/__pycache__/_function_base_impl.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 173 |
+
venv/lib/python3.11/site-packages/numpy/lib/__pycache__/_npyio_impl.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 174 |
+
venv/lib/python3.11/site-packages/numpy/lib/tests/__pycache__/test_function_base.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 175 |
+
venv/lib/python3.11/site-packages/numpy/lib/tests/__pycache__/test_io.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 176 |
+
venv/lib/python3.11/site-packages/numpy/lib/tests/__pycache__/test_nanfunctions.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 177 |
+
venv/lib/python3.11/site-packages/numpy/linalg/__pycache__/_linalg.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 178 |
+
venv/lib/python3.11/site-packages/numpy/linalg/_umath_linalg.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 179 |
+
venv/lib/python3.11/site-packages/numpy/linalg/tests/__pycache__/test_linalg.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 180 |
+
venv/lib/python3.11/site-packages/numpy/ma/__pycache__/core.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 181 |
+
venv/lib/python3.11/site-packages/numpy/ma/tests/__pycache__/test_core.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 182 |
+
venv/lib/python3.11/site-packages/numpy/ma/tests/__pycache__/test_extras.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 183 |
+
venv/lib/python3.11/site-packages/numpy/random/_bounded_integers.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 184 |
+
venv/lib/python3.11/site-packages/numpy/random/_common.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 185 |
+
venv/lib/python3.11/site-packages/numpy/random/_generator.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 186 |
+
venv/lib/python3.11/site-packages/numpy/random/_mt19937.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 187 |
+
venv/lib/python3.11/site-packages/numpy/random/_pcg64.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 188 |
+
venv/lib/python3.11/site-packages/numpy/random/_philox.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 189 |
+
venv/lib/python3.11/site-packages/numpy/random/bit_generator.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 190 |
+
venv/lib/python3.11/site-packages/numpy/random/mtrand.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 191 |
+
venv/lib/python3.11/site-packages/numpy/random/tests/__pycache__/test_generator_mt19937.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 192 |
+
venv/lib/python3.11/site-packages/numpy/random/tests/__pycache__/test_random.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 193 |
+
venv/lib/python3.11/site-packages/numpy/random/tests/__pycache__/test_randomstate.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 194 |
+
venv/lib/python3.11/site-packages/numpy/testing/_private/__pycache__/utils.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 195 |
+
venv/lib/python3.11/site-packages/numpy/testing/tests/__pycache__/test_utils.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 196 |
+
venv/lib/python3.11/site-packages/numpy/typing/tests/data/pass/__pycache__/random.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 197 |
+
venv/lib/python3.11/site-packages/omegaconf/grammar/gen/__pycache__/OmegaConfGrammarParser.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 198 |
+
venv/lib/python3.11/site-packages/orjson/orjson.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 199 |
+
venv/lib/python3.11/site-packages/pandas/_libs/algos.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 200 |
+
venv/lib/python3.11/site-packages/pandas/_libs/arrays.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 201 |
+
venv/lib/python3.11/site-packages/pandas/_libs/groupby.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 202 |
+
venv/lib/python3.11/site-packages/pandas/_libs/hashing.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 203 |
+
venv/lib/python3.11/site-packages/pandas/_libs/hashtable.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 204 |
+
venv/lib/python3.11/site-packages/pandas/_libs/index.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 205 |
+
venv/lib/python3.11/site-packages/pandas/_libs/internals.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 206 |
+
venv/lib/python3.11/site-packages/pandas/_libs/interval.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 207 |
+
venv/lib/python3.11/site-packages/pandas/_libs/join.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 208 |
+
venv/lib/python3.11/site-packages/pandas/_libs/lib.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 209 |
+
venv/lib/python3.11/site-packages/pandas/_libs/missing.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 210 |
+
venv/lib/python3.11/site-packages/pandas/_libs/ops.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 211 |
+
venv/lib/python3.11/site-packages/pandas/_libs/parsers.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 212 |
+
venv/lib/python3.11/site-packages/pandas/_libs/reshape.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 213 |
+
venv/lib/python3.11/site-packages/pandas/_libs/sas.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 214 |
+
venv/lib/python3.11/site-packages/pandas/_libs/sparse.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 215 |
+
venv/lib/python3.11/site-packages/pandas/_libs/testing.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 216 |
+
venv/lib/python3.11/site-packages/pandas/_libs/tslib.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 217 |
+
venv/lib/python3.11/site-packages/pandas/_libs/tslibs/conversion.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 218 |
+
venv/lib/python3.11/site-packages/pandas/_libs/tslibs/dtypes.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 219 |
+
venv/lib/python3.11/site-packages/pandas/_libs/tslibs/fields.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 220 |
+
venv/lib/python3.11/site-packages/pandas/_libs/tslibs/nattype.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 221 |
+
venv/lib/python3.11/site-packages/pandas/_libs/tslibs/np_datetime.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 222 |
+
venv/lib/python3.11/site-packages/pandas/_libs/tslibs/offsets.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 223 |
+
venv/lib/python3.11/site-packages/pandas/_libs/tslibs/parsing.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 224 |
+
venv/lib/python3.11/site-packages/pandas/_libs/tslibs/period.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 225 |
+
venv/lib/python3.11/site-packages/pandas/_libs/tslibs/strptime.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 226 |
+
venv/lib/python3.11/site-packages/pandas/_libs/tslibs/timedeltas.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 227 |
+
venv/lib/python3.11/site-packages/pandas/_libs/tslibs/timestamps.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 228 |
+
venv/lib/python3.11/site-packages/pandas/_libs/tslibs/timezones.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 229 |
+
venv/lib/python3.11/site-packages/pandas/_libs/tslibs/tzconversion.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 230 |
+
venv/lib/python3.11/site-packages/pandas/_libs/tslibs/vectorized.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 231 |
+
venv/lib/python3.11/site-packages/pandas/_libs/window/aggregations.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 232 |
+
venv/lib/python3.11/site-packages/pandas/_libs/window/indexers.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 233 |
+
venv/lib/python3.11/site-packages/pandas/_libs/writers.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 234 |
+
venv/lib/python3.11/site-packages/pandas/core/__pycache__/frame.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 235 |
+
venv/lib/python3.11/site-packages/pandas/core/__pycache__/generic.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 236 |
+
venv/lib/python3.11/site-packages/pandas/core/__pycache__/indexing.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 237 |
+
venv/lib/python3.11/site-packages/pandas/core/__pycache__/resample.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 238 |
+
venv/lib/python3.11/site-packages/pandas/core/__pycache__/series.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 239 |
+
venv/lib/python3.11/site-packages/pandas/core/arrays/__pycache__/categorical.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 240 |
+
venv/lib/python3.11/site-packages/pandas/core/arrays/__pycache__/datetimelike.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 241 |
+
venv/lib/python3.11/site-packages/pandas/core/arrays/arrow/__pycache__/array.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 242 |
+
venv/lib/python3.11/site-packages/pandas/core/groupby/__pycache__/generic.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 243 |
+
venv/lib/python3.11/site-packages/pandas/core/groupby/__pycache__/groupby.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 244 |
+
venv/lib/python3.11/site-packages/pandas/core/indexes/__pycache__/base.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 245 |
+
venv/lib/python3.11/site-packages/pandas/core/indexes/__pycache__/multi.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 246 |
+
venv/lib/python3.11/site-packages/pandas/core/internals/__pycache__/blocks.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 247 |
+
venv/lib/python3.11/site-packages/pandas/core/internals/__pycache__/managers.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 248 |
+
venv/lib/python3.11/site-packages/pandas/core/reshape/__pycache__/merge.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 249 |
+
venv/lib/python3.11/site-packages/pandas/core/strings/__pycache__/accessor.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 250 |
+
venv/lib/python3.11/site-packages/pandas/core/window/__pycache__/rolling.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 251 |
+
venv/lib/python3.11/site-packages/pandas/io/__pycache__/pytables.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 252 |
+
venv/lib/python3.11/site-packages/pandas/io/__pycache__/sql.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 253 |
+
venv/lib/python3.11/site-packages/pandas/io/__pycache__/stata.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 254 |
+
venv/lib/python3.11/site-packages/pandas/io/formats/__pycache__/style.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 255 |
+
venv/lib/python3.11/site-packages/pandas/io/formats/__pycache__/style_render.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 256 |
+
venv/lib/python3.11/site-packages/pandas/tests/__pycache__/test_algos.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 257 |
+
venv/lib/python3.11/site-packages/pandas/tests/apply/__pycache__/test_frame_apply.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 258 |
+
venv/lib/python3.11/site-packages/pandas/tests/arithmetic/__pycache__/test_datetime64.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 259 |
+
venv/lib/python3.11/site-packages/pandas/tests/arithmetic/__pycache__/test_period.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 260 |
+
venv/lib/python3.11/site-packages/pandas/tests/arithmetic/__pycache__/test_timedelta64.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 261 |
+
venv/lib/python3.11/site-packages/pandas/tests/computation/__pycache__/test_eval.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 262 |
+
venv/lib/python3.11/site-packages/pandas/tests/copy_view/__pycache__/test_methods.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 263 |
+
venv/lib/python3.11/site-packages/pandas/tests/dtypes/__pycache__/test_inference.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 264 |
+
venv/lib/python3.11/site-packages/pandas/tests/extension/__pycache__/test_arrow.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 265 |
+
venv/lib/python3.11/site-packages/pandas/tests/frame/__pycache__/test_arithmetic.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 266 |
+
venv/lib/python3.11/site-packages/pandas/tests/frame/__pycache__/test_constructors.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 267 |
+
venv/lib/python3.11/site-packages/pandas/tests/frame/__pycache__/test_query_eval.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 268 |
+
venv/lib/python3.11/site-packages/pandas/tests/frame/__pycache__/test_reductions.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 269 |
+
venv/lib/python3.11/site-packages/pandas/tests/frame/__pycache__/test_stack_unstack.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 270 |
+
venv/lib/python3.11/site-packages/pandas/tests/frame/indexing/__pycache__/test_indexing.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 271 |
+
venv/lib/python3.11/site-packages/pandas/tests/groupby/__pycache__/test_apply.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 272 |
+
venv/lib/python3.11/site-packages/pandas/tests/groupby/__pycache__/test_categorical.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 273 |
+
venv/lib/python3.11/site-packages/pandas/tests/groupby/__pycache__/test_groupby.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 274 |
+
venv/lib/python3.11/site-packages/pandas/tests/groupby/aggregate/__pycache__/test_aggregate.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 275 |
+
venv/lib/python3.11/site-packages/pandas/tests/groupby/transform/__pycache__/test_transform.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 276 |
+
venv/lib/python3.11/site-packages/pandas/tests/indexes/__pycache__/test_base.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 277 |
+
venv/lib/python3.11/site-packages/pandas/tests/indexing/__pycache__/test_loc.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 278 |
+
venv/lib/python3.11/site-packages/pandas/tests/io/__pycache__/test_sql.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 279 |
+
venv/lib/python3.11/site-packages/pandas/tests/io/__pycache__/test_stata.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 280 |
+
venv/lib/python3.11/site-packages/pandas/tests/io/formats/__pycache__/test_format.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 281 |
+
venv/lib/python3.11/site-packages/pandas/tests/io/formats/style/__pycache__/test_style.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 282 |
+
venv/lib/python3.11/site-packages/pandas/tests/io/json/__pycache__/test_pandas.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 283 |
+
venv/lib/python3.11/site-packages/pandas/tests/plotting/__pycache__/test_datetimelike.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 284 |
+
venv/lib/python3.11/site-packages/pandas/tests/plotting/frame/__pycache__/test_frame.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 285 |
+
venv/lib/python3.11/site-packages/pandas/tests/reductions/__pycache__/test_reductions.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 286 |
+
venv/lib/python3.11/site-packages/pandas/tests/resample/__pycache__/test_datetime_index.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 287 |
+
venv/lib/python3.11/site-packages/pandas/tests/reshape/__pycache__/test_pivot.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 288 |
+
venv/lib/python3.11/site-packages/pandas/tests/reshape/merge/__pycache__/test_merge.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 289 |
+
venv/lib/python3.11/site-packages/pandas/tests/series/__pycache__/test_constructors.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 290 |
+
venv/lib/python3.11/site-packages/pandas/tests/series/indexing/__pycache__/test_setitem.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 291 |
+
venv/lib/python3.11/site-packages/pandas/tests/tools/__pycache__/test_to_datetime.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 292 |
+
venv/lib/python3.11/site-packages/pandas/tests/window/__pycache__/test_rolling.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 293 |
+
venv/lib/python3.11/site-packages/pip/_vendor/__pycache__/typing_extensions.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 294 |
+
venv/lib/python3.11/site-packages/pip/_vendor/chardet/__pycache__/langrussianmodel.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 295 |
+
venv/lib/python3.11/site-packages/pip/_vendor/distlib/t64-arm.exe filter=lfs diff=lfs merge=lfs -text
|
| 296 |
+
venv/lib/python3.11/site-packages/pip/_vendor/distlib/t64.exe filter=lfs diff=lfs merge=lfs -text
|
| 297 |
+
venv/lib/python3.11/site-packages/pip/_vendor/distlib/w64-arm.exe filter=lfs diff=lfs merge=lfs -text
|
| 298 |
+
venv/lib/python3.11/site-packages/pip/_vendor/distlib/w64.exe filter=lfs diff=lfs merge=lfs -text
|
| 299 |
+
venv/lib/python3.11/site-packages/pip/_vendor/idna/__pycache__/uts46data.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 300 |
+
venv/lib/python3.11/site-packages/pip/_vendor/pkg_resources/__pycache__/__init__.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 301 |
+
venv/lib/python3.11/site-packages/pip/_vendor/pyparsing/__pycache__/core.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 302 |
+
venv/lib/python3.11/site-packages/pip/_vendor/rich/__pycache__/_emoji_codes.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 303 |
+
venv/lib/python3.11/site-packages/pip/_vendor/rich/__pycache__/console.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 304 |
+
venv/lib/python3.11/site-packages/pkg_resources/__pycache__/__init__.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 305 |
+
venv/lib/python3.11/site-packages/pkg_resources/_vendor/more_itertools/__pycache__/more.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 306 |
+
venv/lib/python3.11/site-packages/pkg_resources/_vendor/pyparsing/__pycache__/core.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 307 |
+
venv/lib/python3.11/site-packages/propcache/_helpers_c.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 308 |
+
venv/lib/python3.11/site-packages/psutil/__pycache__/_pslinux.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 309 |
+
venv/lib/python3.11/site-packages/psutil/tests/__pycache__/__init__.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 310 |
+
venv/lib/python3.11/site-packages/psutil/tests/__pycache__/test_linux.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 311 |
+
venv/lib/python3.11/site-packages/psutil/tests/__pycache__/test_process.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 312 |
+
venv/lib/python3.11/site-packages/pyarrow/_acero.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 313 |
+
venv/lib/python3.11/site-packages/pyarrow/_azurefs.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 314 |
+
venv/lib/python3.11/site-packages/pyarrow/_compute.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 315 |
+
venv/lib/python3.11/site-packages/pyarrow/_csv.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 316 |
+
venv/lib/python3.11/site-packages/pyarrow/_dataset.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 317 |
+
venv/lib/python3.11/site-packages/pyarrow/_dataset_orc.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 318 |
+
venv/lib/python3.11/site-packages/pyarrow/_dataset_parquet.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 319 |
+
venv/lib/python3.11/site-packages/pyarrow/_dataset_parquet_encryption.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 320 |
+
venv/lib/python3.11/site-packages/pyarrow/_feather.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 321 |
+
venv/lib/python3.11/site-packages/pyarrow/_flight.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 322 |
+
venv/lib/python3.11/site-packages/pyarrow/_fs.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 323 |
+
venv/lib/python3.11/site-packages/pyarrow/_gcsfs.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 324 |
+
venv/lib/python3.11/site-packages/pyarrow/_hdfs.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 325 |
+
venv/lib/python3.11/site-packages/pyarrow/_json.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 326 |
+
venv/lib/python3.11/site-packages/pyarrow/_orc.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 327 |
+
venv/lib/python3.11/site-packages/pyarrow/_parquet.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 328 |
+
venv/lib/python3.11/site-packages/pyarrow/_parquet_encryption.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 329 |
+
venv/lib/python3.11/site-packages/pyarrow/_pyarrow_cpp_tests.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 330 |
+
venv/lib/python3.11/site-packages/pyarrow/_s3fs.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 331 |
+
venv/lib/python3.11/site-packages/pyarrow/_substrait.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 332 |
+
venv/lib/python3.11/site-packages/pyarrow/lib.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 333 |
+
venv/lib/python3.11/site-packages/pyarrow/libarrow.2000.dylib filter=lfs diff=lfs merge=lfs -text
|
| 334 |
+
venv/lib/python3.11/site-packages/pyarrow/libarrow_acero.2000.dylib filter=lfs diff=lfs merge=lfs -text
|
| 335 |
+
venv/lib/python3.11/site-packages/pyarrow/libarrow_dataset.2000.dylib filter=lfs diff=lfs merge=lfs -text
|
| 336 |
+
venv/lib/python3.11/site-packages/pyarrow/libarrow_flight.2000.dylib filter=lfs diff=lfs merge=lfs -text
|
| 337 |
+
venv/lib/python3.11/site-packages/pyarrow/libarrow_python.2000.0.0.dylib filter=lfs diff=lfs merge=lfs -text
|
| 338 |
+
venv/lib/python3.11/site-packages/pyarrow/libarrow_python.2000.dylib filter=lfs diff=lfs merge=lfs -text
|
| 339 |
+
venv/lib/python3.11/site-packages/pyarrow/libarrow_python.dylib filter=lfs diff=lfs merge=lfs -text
|
| 340 |
+
venv/lib/python3.11/site-packages/pyarrow/libarrow_python_flight.2000.0.0.dylib filter=lfs diff=lfs merge=lfs -text
|
| 341 |
+
venv/lib/python3.11/site-packages/pyarrow/libarrow_python_flight.2000.dylib filter=lfs diff=lfs merge=lfs -text
|
| 342 |
+
venv/lib/python3.11/site-packages/pyarrow/libarrow_python_flight.dylib filter=lfs diff=lfs merge=lfs -text
|
| 343 |
+
venv/lib/python3.11/site-packages/pyarrow/libarrow_substrait.2000.dylib filter=lfs diff=lfs merge=lfs -text
|
| 344 |
+
venv/lib/python3.11/site-packages/pyarrow/libparquet.2000.dylib filter=lfs diff=lfs merge=lfs -text
|
| 345 |
+
venv/lib/python3.11/site-packages/pyarrow/tests/__pycache__/test_array.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 346 |
+
venv/lib/python3.11/site-packages/pyarrow/tests/__pycache__/test_compute.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 347 |
+
venv/lib/python3.11/site-packages/pyarrow/tests/__pycache__/test_convert_builtin.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 348 |
+
venv/lib/python3.11/site-packages/pyarrow/tests/__pycache__/test_csv.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 349 |
+
venv/lib/python3.11/site-packages/pyarrow/tests/__pycache__/test_dataset.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 350 |
+
venv/lib/python3.11/site-packages/pyarrow/tests/__pycache__/test_extension_type.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 351 |
+
venv/lib/python3.11/site-packages/pyarrow/tests/__pycache__/test_flight.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 352 |
+
venv/lib/python3.11/site-packages/pyarrow/tests/__pycache__/test_fs.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 353 |
+
venv/lib/python3.11/site-packages/pyarrow/tests/__pycache__/test_io.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 354 |
+
venv/lib/python3.11/site-packages/pyarrow/tests/__pycache__/test_pandas.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 355 |
+
venv/lib/python3.11/site-packages/pyarrow/tests/__pycache__/test_table.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 356 |
+
venv/lib/python3.11/site-packages/pyarrow/tests/__pycache__/test_types.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 357 |
+
venv/lib/python3.11/site-packages/pydantic/__pycache__/json_schema.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 358 |
+
venv/lib/python3.11/site-packages/pydantic/__pycache__/types.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 359 |
+
venv/lib/python3.11/site-packages/pydantic/_internal/__pycache__/_generate_schema.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 360 |
+
venv/lib/python3.11/site-packages/pydantic_core/__pycache__/core_schema.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 361 |
+
venv/lib/python3.11/site-packages/pydantic_core/_pydantic_core.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 362 |
+
venv/lib/python3.11/site-packages/pygments/lexers/__pycache__/lisp.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 363 |
+
venv/lib/python3.11/site-packages/regex/__pycache__/_regex_core.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 364 |
+
venv/lib/python3.11/site-packages/regex/__pycache__/test_regex.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 365 |
+
venv/lib/python3.11/site-packages/regex/_regex.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 366 |
+
venv/lib/python3.11/site-packages/rich/__pycache__/_emoji_codes.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 367 |
+
venv/lib/python3.11/site-packages/rich/__pycache__/console.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 368 |
+
venv/lib/python3.11/site-packages/safetensors/_safetensors_rust.abi3.so filter=lfs diff=lfs merge=lfs -text
|
| 369 |
+
venv/lib/python3.11/site-packages/setuptools/_vendor/__pycache__/typing_extensions.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 370 |
+
venv/lib/python3.11/site-packages/setuptools/_vendor/more_itertools/__pycache__/more.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 371 |
+
venv/lib/python3.11/site-packages/setuptools/_vendor/pyparsing/__pycache__/core.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 372 |
+
venv/lib/python3.11/site-packages/setuptools/cli-arm64.exe filter=lfs diff=lfs merge=lfs -text
|
| 373 |
+
venv/lib/python3.11/site-packages/setuptools/command/__pycache__/easy_install.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 374 |
+
venv/lib/python3.11/site-packages/setuptools/config/_validate_pyproject/__pycache__/fastjsonschema_validations.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 375 |
+
venv/lib/python3.11/site-packages/setuptools/gui-arm64.exe filter=lfs diff=lfs merge=lfs -text
|
| 376 |
+
venv/lib/python3.11/site-packages/sympy/assumptions/tests/__pycache__/test_query.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 377 |
+
venv/lib/python3.11/site-packages/sympy/combinatorics/__pycache__/perm_groups.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 378 |
+
venv/lib/python3.11/site-packages/sympy/combinatorics/__pycache__/permutations.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 379 |
+
venv/lib/python3.11/site-packages/sympy/concrete/tests/__pycache__/test_sums_products.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 380 |
+
venv/lib/python3.11/site-packages/sympy/core/__pycache__/expr.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 381 |
+
venv/lib/python3.11/site-packages/sympy/core/__pycache__/function.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 382 |
+
venv/lib/python3.11/site-packages/sympy/core/__pycache__/numbers.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 383 |
+
venv/lib/python3.11/site-packages/sympy/core/tests/__pycache__/test_args.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 384 |
+
venv/lib/python3.11/site-packages/sympy/core/tests/__pycache__/test_arit.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 385 |
+
venv/lib/python3.11/site-packages/sympy/core/tests/__pycache__/test_expr.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 386 |
+
venv/lib/python3.11/site-packages/sympy/core/tests/__pycache__/test_function.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 387 |
+
venv/lib/python3.11/site-packages/sympy/core/tests/__pycache__/test_numbers.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 388 |
+
venv/lib/python3.11/site-packages/sympy/core/tests/__pycache__/test_relational.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 389 |
+
venv/lib/python3.11/site-packages/sympy/crypto/__pycache__/crypto.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 390 |
+
venv/lib/python3.11/site-packages/sympy/diffgeom/__pycache__/diffgeom.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 391 |
+
venv/lib/python3.11/site-packages/sympy/functions/combinatorial/__pycache__/numbers.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 392 |
+
venv/lib/python3.11/site-packages/sympy/functions/combinatorial/tests/__pycache__/test_comb_numbers.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 393 |
+
venv/lib/python3.11/site-packages/sympy/functions/elementary/__pycache__/hyperbolic.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 394 |
+
venv/lib/python3.11/site-packages/sympy/functions/elementary/__pycache__/trigonometric.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 395 |
+
venv/lib/python3.11/site-packages/sympy/functions/elementary/tests/__pycache__/test_hyperbolic.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 396 |
+
venv/lib/python3.11/site-packages/sympy/functions/elementary/tests/__pycache__/test_piecewise.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 397 |
+
venv/lib/python3.11/site-packages/sympy/functions/elementary/tests/__pycache__/test_trigonometric.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 398 |
+
venv/lib/python3.11/site-packages/sympy/functions/special/__pycache__/bessel.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 399 |
+
venv/lib/python3.11/site-packages/sympy/functions/special/__pycache__/error_functions.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 400 |
+
venv/lib/python3.11/site-packages/sympy/functions/special/tests/__pycache__/test_bessel.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 401 |
+
venv/lib/python3.11/site-packages/sympy/functions/special/tests/__pycache__/test_error_functions.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 402 |
+
venv/lib/python3.11/site-packages/sympy/geometry/__pycache__/polygon.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 403 |
+
venv/lib/python3.11/site-packages/sympy/holonomic/__pycache__/holonomic.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 404 |
+
venv/lib/python3.11/site-packages/sympy/integrals/__pycache__/laplace.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 405 |
+
venv/lib/python3.11/site-packages/sympy/integrals/__pycache__/manualintegrate.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 406 |
+
venv/lib/python3.11/site-packages/sympy/integrals/__pycache__/meijerint.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 407 |
+
venv/lib/python3.11/site-packages/sympy/integrals/tests/__pycache__/test_integrals.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 408 |
+
venv/lib/python3.11/site-packages/sympy/integrals/tests/__pycache__/test_manual.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 409 |
+
venv/lib/python3.11/site-packages/sympy/integrals/tests/__pycache__/test_risch.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 410 |
+
venv/lib/python3.11/site-packages/sympy/logic/__pycache__/boolalg.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 411 |
+
venv/lib/python3.11/site-packages/sympy/logic/tests/__pycache__/test_boolalg.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 412 |
+
venv/lib/python3.11/site-packages/sympy/matrices/__pycache__/common.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 413 |
+
venv/lib/python3.11/site-packages/sympy/matrices/__pycache__/matrixbase.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 414 |
+
venv/lib/python3.11/site-packages/sympy/matrices/tests/__pycache__/test_matrices.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 415 |
+
venv/lib/python3.11/site-packages/sympy/matrices/tests/__pycache__/test_matrixbase.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 416 |
+
venv/lib/python3.11/site-packages/sympy/ntheory/__pycache__/factor_.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 417 |
+
venv/lib/python3.11/site-packages/sympy/parsing/autolev/__pycache__/_listener_autolev_antlr.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 418 |
+
venv/lib/python3.11/site-packages/sympy/parsing/autolev/_antlr/__pycache__/autolevparser.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 419 |
+
venv/lib/python3.11/site-packages/sympy/parsing/latex/_antlr/__pycache__/latexparser.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 420 |
+
venv/lib/python3.11/site-packages/sympy/parsing/tests/__pycache__/test_c_parser.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 421 |
+
venv/lib/python3.11/site-packages/sympy/physics/__pycache__/secondquant.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 422 |
+
venv/lib/python3.11/site-packages/sympy/physics/biomechanics/tests/__pycache__/test_curve.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 423 |
+
venv/lib/python3.11/site-packages/sympy/physics/continuum_mechanics/__pycache__/beam.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 424 |
+
venv/lib/python3.11/site-packages/sympy/physics/control/__pycache__/lti.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 425 |
+
venv/lib/python3.11/site-packages/sympy/physics/control/tests/__pycache__/test_lti.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 426 |
+
venv/lib/python3.11/site-packages/sympy/physics/mechanics/tests/__pycache__/test_joint.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 427 |
+
venv/lib/python3.11/site-packages/sympy/physics/quantum/__pycache__/spin.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 428 |
+
venv/lib/python3.11/site-packages/sympy/physics/quantum/tests/__pycache__/test_spin.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 429 |
+
venv/lib/python3.11/site-packages/sympy/physics/tests/__pycache__/test_secondquant.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 430 |
+
venv/lib/python3.11/site-packages/sympy/plotting/__pycache__/series.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 431 |
+
venv/lib/python3.11/site-packages/sympy/plotting/tests/__pycache__/test_series.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 432 |
+
venv/lib/python3.11/site-packages/sympy/polys/__pycache__/compatibility.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 433 |
+
venv/lib/python3.11/site-packages/sympy/polys/__pycache__/polyclasses.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 434 |
+
venv/lib/python3.11/site-packages/sympy/polys/__pycache__/polyquinticconst.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 435 |
+
venv/lib/python3.11/site-packages/sympy/polys/__pycache__/polytools.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 436 |
+
venv/lib/python3.11/site-packages/sympy/polys/__pycache__/rings.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 437 |
+
venv/lib/python3.11/site-packages/sympy/polys/benchmarks/__pycache__/bench_solvers.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 438 |
+
venv/lib/python3.11/site-packages/sympy/polys/domains/tests/__pycache__/test_domains.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 439 |
+
venv/lib/python3.11/site-packages/sympy/polys/matrices/__pycache__/domainmatrix.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 440 |
+
venv/lib/python3.11/site-packages/sympy/polys/matrices/tests/__pycache__/test_domainmatrix.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 441 |
+
venv/lib/python3.11/site-packages/sympy/polys/numberfields/__pycache__/resolvent_lookup.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 442 |
+
venv/lib/python3.11/site-packages/sympy/polys/tests/__pycache__/test_polytools.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 443 |
+
venv/lib/python3.11/site-packages/sympy/polys/tests/__pycache__/test_ring_series.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 444 |
+
venv/lib/python3.11/site-packages/sympy/polys/tests/__pycache__/test_rings.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 445 |
+
venv/lib/python3.11/site-packages/sympy/printing/__pycache__/latex.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 446 |
+
venv/lib/python3.11/site-packages/sympy/printing/__pycache__/mathml.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 447 |
+
venv/lib/python3.11/site-packages/sympy/printing/pretty/__pycache__/pretty.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 448 |
+
venv/lib/python3.11/site-packages/sympy/printing/pretty/tests/__pycache__/test_pretty.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 449 |
+
venv/lib/python3.11/site-packages/sympy/printing/tests/__pycache__/test_latex.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 450 |
+
venv/lib/python3.11/site-packages/sympy/printing/tests/__pycache__/test_mathml.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 451 |
+
venv/lib/python3.11/site-packages/sympy/printing/tests/__pycache__/test_str.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 452 |
+
venv/lib/python3.11/site-packages/sympy/series/tests/__pycache__/test_limits.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 453 |
+
venv/lib/python3.11/site-packages/sympy/sets/__pycache__/sets.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 454 |
+
venv/lib/python3.11/site-packages/sympy/sets/tests/__pycache__/test_fancysets.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 455 |
+
venv/lib/python3.11/site-packages/sympy/sets/tests/__pycache__/test_sets.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 456 |
+
venv/lib/python3.11/site-packages/sympy/simplify/__pycache__/hyperexpand.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 457 |
+
venv/lib/python3.11/site-packages/sympy/simplify/tests/__pycache__/test_simplify.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 458 |
+
venv/lib/python3.11/site-packages/sympy/solvers/__pycache__/solvers.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 459 |
+
venv/lib/python3.11/site-packages/sympy/solvers/__pycache__/solveset.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 460 |
+
venv/lib/python3.11/site-packages/sympy/solvers/diophantine/__pycache__/diophantine.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 461 |
+
venv/lib/python3.11/site-packages/sympy/solvers/diophantine/tests/__pycache__/test_diophantine.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 462 |
+
venv/lib/python3.11/site-packages/sympy/solvers/ode/__pycache__/ode.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 463 |
+
venv/lib/python3.11/site-packages/sympy/solvers/ode/__pycache__/single.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 464 |
+
venv/lib/python3.11/site-packages/sympy/solvers/ode/__pycache__/systems.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 465 |
+
venv/lib/python3.11/site-packages/sympy/solvers/ode/tests/__pycache__/test_ode.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 466 |
+
venv/lib/python3.11/site-packages/sympy/solvers/ode/tests/__pycache__/test_single.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 467 |
+
venv/lib/python3.11/site-packages/sympy/solvers/ode/tests/__pycache__/test_systems.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 468 |
+
venv/lib/python3.11/site-packages/sympy/solvers/tests/__pycache__/test_solvers.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 469 |
+
venv/lib/python3.11/site-packages/sympy/solvers/tests/__pycache__/test_solveset.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 470 |
+
venv/lib/python3.11/site-packages/sympy/stats/__pycache__/crv_types.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 471 |
+
venv/lib/python3.11/site-packages/sympy/stats/__pycache__/stochastic_process_types.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 472 |
+
venv/lib/python3.11/site-packages/sympy/stats/tests/__pycache__/test_continuous_rv.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 473 |
+
venv/lib/python3.11/site-packages/sympy/stats/tests/__pycache__/test_stochastic_process.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 474 |
+
venv/lib/python3.11/site-packages/sympy/tensor/__pycache__/tensor.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 475 |
+
venv/lib/python3.11/site-packages/sympy/tensor/array/expressions/__pycache__/array_expressions.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 476 |
+
venv/lib/python3.11/site-packages/sympy/tensor/tests/__pycache__/test_tensor.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 477 |
+
venv/lib/python3.11/site-packages/sympy/testing/__pycache__/runtests.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 478 |
+
venv/lib/python3.11/site-packages/sympy/utilities/__pycache__/codegen.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 479 |
+
venv/lib/python3.11/site-packages/sympy/utilities/__pycache__/iterables.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 480 |
+
venv/lib/python3.11/site-packages/sympy/utilities/tests/__pycache__/test_lambdify.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 481 |
+
venv/lib/python3.11/site-packages/sympy/utilities/tests/__pycache__/test_wester.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 482 |
+
venv/lib/python3.11/site-packages/tokenizers/tokenizers.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 483 |
+
venv/lib/python3.11/site-packages/tomlkit/__pycache__/items.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 484 |
+
venv/lib/python3.11/site-packages/torch/__pycache__/__init__.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 485 |
+
venv/lib/python3.11/site-packages/torch/__pycache__/_meta_registrations.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 486 |
+
venv/lib/python3.11/site-packages/torch/__pycache__/_tensor_docs.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 487 |
+
venv/lib/python3.11/site-packages/torch/__pycache__/_torch_docs.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 488 |
+
venv/lib/python3.11/site-packages/torch/__pycache__/overrides.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 489 |
+
venv/lib/python3.11/site-packages/torch/_decomp/__pycache__/decompositions.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 490 |
+
venv/lib/python3.11/site-packages/torch/_dynamo/__pycache__/guards.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 491 |
+
venv/lib/python3.11/site-packages/torch/_dynamo/__pycache__/output_graph.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 492 |
+
venv/lib/python3.11/site-packages/torch/_dynamo/__pycache__/symbolic_convert.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 493 |
+
venv/lib/python3.11/site-packages/torch/_dynamo/__pycache__/trace_rules.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 494 |
+
venv/lib/python3.11/site-packages/torch/_dynamo/__pycache__/utils.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 495 |
+
venv/lib/python3.11/site-packages/torch/_dynamo/variables/__pycache__/builder.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 496 |
+
venv/lib/python3.11/site-packages/torch/_dynamo/variables/__pycache__/builtin.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 497 |
+
venv/lib/python3.11/site-packages/torch/_dynamo/variables/__pycache__/functions.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 498 |
+
venv/lib/python3.11/site-packages/torch/_dynamo/variables/__pycache__/higher_order_ops.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 499 |
+
venv/lib/python3.11/site-packages/torch/_export/serde/__pycache__/serialize.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 500 |
+
venv/lib/python3.11/site-packages/torch/_functorch/__pycache__/partitioners.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 501 |
+
venv/lib/python3.11/site-packages/torch/_inductor/__pycache__/codecache.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 502 |
+
venv/lib/python3.11/site-packages/torch/_inductor/__pycache__/compile_fx.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 503 |
+
venv/lib/python3.11/site-packages/torch/_inductor/__pycache__/cudagraph_trees.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 504 |
+
venv/lib/python3.11/site-packages/torch/_inductor/__pycache__/graph.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 505 |
+
venv/lib/python3.11/site-packages/torch/_inductor/__pycache__/ir.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 506 |
+
venv/lib/python3.11/site-packages/torch/_inductor/__pycache__/lowering.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 507 |
+
venv/lib/python3.11/site-packages/torch/_inductor/__pycache__/pattern_matcher.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 508 |
+
venv/lib/python3.11/site-packages/torch/_inductor/__pycache__/scheduler.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 509 |
+
venv/lib/python3.11/site-packages/torch/_inductor/__pycache__/select_algorithm.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 510 |
+
venv/lib/python3.11/site-packages/torch/_inductor/__pycache__/utils.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 511 |
+
venv/lib/python3.11/site-packages/torch/_inductor/codegen/__pycache__/common.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 512 |
+
venv/lib/python3.11/site-packages/torch/_inductor/codegen/__pycache__/cpp.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 513 |
+
venv/lib/python3.11/site-packages/torch/_inductor/codegen/__pycache__/cpp_wrapper_cpu.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 514 |
+
venv/lib/python3.11/site-packages/torch/_inductor/codegen/__pycache__/halide.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 515 |
+
venv/lib/python3.11/site-packages/torch/_inductor/codegen/__pycache__/simd.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 516 |
+
venv/lib/python3.11/site-packages/torch/_inductor/codegen/__pycache__/triton.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 517 |
+
venv/lib/python3.11/site-packages/torch/_inductor/codegen/__pycache__/wrapper.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 518 |
+
venv/lib/python3.11/site-packages/torch/_inductor/fx_passes/__pycache__/quantization.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 519 |
+
venv/lib/python3.11/site-packages/torch/_inductor/fx_passes/__pycache__/split_cat.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 520 |
+
venv/lib/python3.11/site-packages/torch/_inductor/kernel/__pycache__/flex_attention.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 521 |
+
venv/lib/python3.11/site-packages/torch/_inductor/runtime/__pycache__/triton_heuristics.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 522 |
+
venv/lib/python3.11/site-packages/torch/_refs/__pycache__/__init__.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 523 |
+
venv/lib/python3.11/site-packages/torch/_subclasses/__pycache__/fake_tensor.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 524 |
+
venv/lib/python3.11/site-packages/torch/autograd/__pycache__/gradcheck.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 525 |
+
venv/lib/python3.11/site-packages/torch/backends/_nnapi/__pycache__/serializer.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 526 |
+
venv/lib/python3.11/site-packages/torch/bin/protoc filter=lfs diff=lfs merge=lfs -text
|
| 527 |
+
venv/lib/python3.11/site-packages/torch/bin/protoc-3.13.0.0 filter=lfs diff=lfs merge=lfs -text
|
| 528 |
+
venv/lib/python3.11/site-packages/torch/distributed/__pycache__/distributed_c10d.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 529 |
+
venv/lib/python3.11/site-packages/torch/distributed/fsdp/__pycache__/_flat_param.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 530 |
+
venv/lib/python3.11/site-packages/torch/distributed/fsdp/__pycache__/fully_sharded_data_parallel.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 531 |
+
venv/lib/python3.11/site-packages/torch/distributed/pipelining/__pycache__/schedules.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 532 |
+
venv/lib/python3.11/site-packages/torch/fx/experimental/__pycache__/proxy_tensor.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 533 |
+
venv/lib/python3.11/site-packages/torch/fx/experimental/__pycache__/symbolic_shapes.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 534 |
+
venv/lib/python3.11/site-packages/torch/lib/libc10.dylib filter=lfs diff=lfs merge=lfs -text
|
| 535 |
+
venv/lib/python3.11/site-packages/torch/lib/libomp.dylib filter=lfs diff=lfs merge=lfs -text
|
| 536 |
+
venv/lib/python3.11/site-packages/torch/lib/libtorch_cpu.dylib filter=lfs diff=lfs merge=lfs -text
|
| 537 |
+
venv/lib/python3.11/site-packages/torch/lib/libtorch_python.dylib filter=lfs diff=lfs merge=lfs -text
|
| 538 |
+
venv/lib/python3.11/site-packages/torch/linalg/__pycache__/__init__.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 539 |
+
venv/lib/python3.11/site-packages/torch/nested/_internal/__pycache__/ops.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 540 |
+
venv/lib/python3.11/site-packages/torch/nn/__pycache__/functional.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 541 |
+
venv/lib/python3.11/site-packages/torch/nn/modules/__pycache__/loss.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 542 |
+
venv/lib/python3.11/site-packages/torch/nn/modules/__pycache__/module.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 543 |
+
venv/lib/python3.11/site-packages/torch/nn/parallel/__pycache__/distributed.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 544 |
+
venv/lib/python3.11/site-packages/torch/onnx/__pycache__/symbolic_helper.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 545 |
+
venv/lib/python3.11/site-packages/torch/onnx/__pycache__/symbolic_opset9.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 546 |
+
venv/lib/python3.11/site-packages/torch/optim/__pycache__/lr_scheduler.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 547 |
+
venv/lib/python3.11/site-packages/torch/sparse/__pycache__/_triton_ops_meta.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 548 |
+
venv/lib/python3.11/site-packages/torch/testing/_internal/__pycache__/common_methods_invocations.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 549 |
+
venv/lib/python3.11/site-packages/torch/testing/_internal/__pycache__/common_modules.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 550 |
+
venv/lib/python3.11/site-packages/torch/testing/_internal/__pycache__/common_nn.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 551 |
+
venv/lib/python3.11/site-packages/torch/testing/_internal/__pycache__/common_quantization.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 552 |
+
venv/lib/python3.11/site-packages/torch/testing/_internal/__pycache__/common_utils.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 553 |
+
venv/lib/python3.11/site-packages/torch/testing/_internal/distributed/__pycache__/distributed_test.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 554 |
+
venv/lib/python3.11/site-packages/torch/testing/_internal/distributed/rpc/__pycache__/dist_autograd_test.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 555 |
+
venv/lib/python3.11/site-packages/torch/testing/_internal/distributed/rpc/__pycache__/rpc_test.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 556 |
+
venv/lib/python3.11/site-packages/torch/testing/_internal/generated/__pycache__/annotated_fn_args.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 557 |
+
venv/lib/python3.11/site-packages/torch/testing/_internal/opinfo/__pycache__/core.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 558 |
+
venv/lib/python3.11/site-packages/torch/utils/__pycache__/cpp_extension.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 559 |
+
venv/lib/python3.11/site-packages/torch/utils/hipify/__pycache__/cuda_to_hip_mappings.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 560 |
+
venv/lib/python3.11/site-packages/torchgen/__pycache__/gen.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 561 |
+
venv/lib/python3.11/site-packages/torchgen/__pycache__/model.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 562 |
+
venv/lib/python3.11/site-packages/torchvision/.dylibs/libc++.1.0.dylib filter=lfs diff=lfs merge=lfs -text
|
| 563 |
+
venv/lib/python3.11/site-packages/torchvision/.dylibs/libjpeg.8.2.2.dylib filter=lfs diff=lfs merge=lfs -text
|
| 564 |
+
venv/lib/python3.11/site-packages/torchvision/.dylibs/libpng16.16.dylib filter=lfs diff=lfs merge=lfs -text
|
| 565 |
+
venv/lib/python3.11/site-packages/torchvision/.dylibs/libwebp.7.1.8.dylib filter=lfs diff=lfs merge=lfs -text
|
| 566 |
+
venv/lib/python3.11/site-packages/torchvision/.dylibs/libz.1.2.13.dylib filter=lfs diff=lfs merge=lfs -text
|
| 567 |
+
venv/lib/python3.11/site-packages/torchvision/_C.so filter=lfs diff=lfs merge=lfs -text
|
| 568 |
+
venv/lib/python3.11/site-packages/torchvision/image.so filter=lfs diff=lfs merge=lfs -text
|
| 569 |
+
venv/lib/python3.11/site-packages/torchvision/transforms/__pycache__/transforms.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 570 |
+
venv/lib/python3.11/site-packages/torchvision/transforms/v2/functional/__pycache__/_geometry.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 571 |
+
venv/lib/python3.11/site-packages/transformers/__pycache__/__init__.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 572 |
+
venv/lib/python3.11/site-packages/transformers/__pycache__/cache_utils.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 573 |
+
venv/lib/python3.11/site-packages/transformers/__pycache__/modeling_outputs.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 574 |
+
venv/lib/python3.11/site-packages/transformers/__pycache__/modeling_tf_utils.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 575 |
+
venv/lib/python3.11/site-packages/transformers/__pycache__/modeling_utils.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 576 |
+
venv/lib/python3.11/site-packages/transformers/__pycache__/testing_utils.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 577 |
+
venv/lib/python3.11/site-packages/transformers/__pycache__/tokenization_utils_base.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 578 |
+
venv/lib/python3.11/site-packages/transformers/__pycache__/trainer.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 579 |
+
venv/lib/python3.11/site-packages/transformers/__pycache__/training_args.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 580 |
+
venv/lib/python3.11/site-packages/transformers/generation/__pycache__/logits_process.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 581 |
+
venv/lib/python3.11/site-packages/transformers/generation/__pycache__/tf_utils.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 582 |
+
venv/lib/python3.11/site-packages/transformers/generation/__pycache__/utils.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 583 |
+
venv/lib/python3.11/site-packages/transformers/integrations/__pycache__/integration_utils.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 584 |
+
venv/lib/python3.11/site-packages/transformers/models/autoformer/__pycache__/modeling_autoformer.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 585 |
+
venv/lib/python3.11/site-packages/transformers/models/bart/__pycache__/modeling_bart.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 586 |
+
venv/lib/python3.11/site-packages/transformers/models/bert/__pycache__/modeling_tf_bert.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 587 |
+
venv/lib/python3.11/site-packages/transformers/models/big_bird/__pycache__/modeling_big_bird.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 588 |
+
venv/lib/python3.11/site-packages/transformers/models/big_bird/__pycache__/modeling_flax_big_bird.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 589 |
+
venv/lib/python3.11/site-packages/transformers/models/bigbird_pegasus/__pycache__/modeling_bigbird_pegasus.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 590 |
+
venv/lib/python3.11/site-packages/transformers/models/blip_2/__pycache__/modeling_blip_2.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 591 |
+
venv/lib/python3.11/site-packages/transformers/models/bridgetower/__pycache__/modeling_bridgetower.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 592 |
+
venv/lib/python3.11/site-packages/transformers/models/clap/__pycache__/modeling_clap.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 593 |
+
venv/lib/python3.11/site-packages/transformers/models/clvp/__pycache__/modeling_clvp.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 594 |
+
venv/lib/python3.11/site-packages/transformers/models/conditional_detr/__pycache__/modeling_conditional_detr.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 595 |
+
venv/lib/python3.11/site-packages/transformers/models/deberta_v2/__pycache__/modeling_tf_deberta_v2.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 596 |
+
venv/lib/python3.11/site-packages/transformers/models/deformable_detr/__pycache__/modeling_deformable_detr.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 597 |
+
venv/lib/python3.11/site-packages/transformers/models/deprecated/deta/__pycache__/modeling_deta.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 598 |
+
venv/lib/python3.11/site-packages/transformers/models/deprecated/jukebox/__pycache__/modeling_jukebox.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 599 |
+
venv/lib/python3.11/site-packages/transformers/models/deprecated/mega/__pycache__/modeling_mega.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 600 |
+
venv/lib/python3.11/site-packages/transformers/models/deprecated/xlm_prophetnet/__pycache__/modeling_xlm_prophetnet.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 601 |
+
venv/lib/python3.11/site-packages/transformers/models/detr/__pycache__/image_processing_detr.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 602 |
+
venv/lib/python3.11/site-packages/transformers/models/esm/__pycache__/modeling_esmfold.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 603 |
+
venv/lib/python3.11/site-packages/transformers/models/flava/__pycache__/modeling_flava.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 604 |
+
venv/lib/python3.11/site-packages/transformers/models/grounding_dino/__pycache__/modeling_grounding_dino.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 605 |
+
venv/lib/python3.11/site-packages/transformers/models/groupvit/__pycache__/modeling_tf_groupvit.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 606 |
+
venv/lib/python3.11/site-packages/transformers/models/informer/__pycache__/modeling_informer.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 607 |
+
venv/lib/python3.11/site-packages/transformers/models/kosmos2/__pycache__/modeling_kosmos2.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 608 |
+
venv/lib/python3.11/site-packages/transformers/models/led/__pycache__/modeling_led.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 609 |
+
venv/lib/python3.11/site-packages/transformers/models/led/__pycache__/modeling_tf_led.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 610 |
+
venv/lib/python3.11/site-packages/transformers/models/longformer/__pycache__/modeling_longformer.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 611 |
+
venv/lib/python3.11/site-packages/transformers/models/longformer/__pycache__/modeling_tf_longformer.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 612 |
+
venv/lib/python3.11/site-packages/transformers/models/longt5/__pycache__/modeling_flax_longt5.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 613 |
+
venv/lib/python3.11/site-packages/transformers/models/longt5/__pycache__/modeling_longt5.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 614 |
+
venv/lib/python3.11/site-packages/transformers/models/luke/__pycache__/modeling_luke.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 615 |
+
venv/lib/python3.11/site-packages/transformers/models/mask2former/__pycache__/modeling_mask2former.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 616 |
+
venv/lib/python3.11/site-packages/transformers/models/maskformer/__pycache__/modeling_maskformer.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 617 |
+
venv/lib/python3.11/site-packages/transformers/models/mbart/__pycache__/modeling_mbart.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 618 |
+
venv/lib/python3.11/site-packages/transformers/models/mllama/__pycache__/modeling_mllama.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 619 |
+
venv/lib/python3.11/site-packages/transformers/models/mobilebert/__pycache__/modeling_tf_mobilebert.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 620 |
+
venv/lib/python3.11/site-packages/transformers/models/moshi/__pycache__/modeling_moshi.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 621 |
+
venv/lib/python3.11/site-packages/transformers/models/mt5/__pycache__/modeling_mt5.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 622 |
+
venv/lib/python3.11/site-packages/transformers/models/musicgen/__pycache__/modeling_musicgen.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 623 |
+
venv/lib/python3.11/site-packages/transformers/models/musicgen_melody/__pycache__/modeling_musicgen_melody.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 624 |
+
venv/lib/python3.11/site-packages/transformers/models/omdet_turbo/__pycache__/modeling_omdet_turbo.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 625 |
+
venv/lib/python3.11/site-packages/transformers/models/oneformer/__pycache__/modeling_oneformer.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 626 |
+
venv/lib/python3.11/site-packages/transformers/models/patchtsmixer/__pycache__/modeling_patchtsmixer.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 627 |
+
venv/lib/python3.11/site-packages/transformers/models/patchtst/__pycache__/modeling_patchtst.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 628 |
+
venv/lib/python3.11/site-packages/transformers/models/perceiver/__pycache__/modeling_perceiver.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 629 |
+
venv/lib/python3.11/site-packages/transformers/models/prophetnet/__pycache__/modeling_prophetnet.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 630 |
+
venv/lib/python3.11/site-packages/transformers/models/qwen2_vl/__pycache__/modeling_qwen2_vl.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 631 |
+
venv/lib/python3.11/site-packages/transformers/models/reformer/__pycache__/modeling_reformer.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 632 |
+
venv/lib/python3.11/site-packages/transformers/models/rt_detr/__pycache__/modeling_rt_detr.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 633 |
+
venv/lib/python3.11/site-packages/transformers/models/seamless_m4t/__pycache__/modeling_seamless_m4t.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 634 |
+
venv/lib/python3.11/site-packages/transformers/models/seamless_m4t_v2/__pycache__/modeling_seamless_m4t_v2.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 635 |
+
venv/lib/python3.11/site-packages/transformers/models/speecht5/__pycache__/modeling_speecht5.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 636 |
+
venv/lib/python3.11/site-packages/transformers/models/t5/__pycache__/modeling_t5.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 637 |
+
venv/lib/python3.11/site-packages/transformers/models/tapas/__pycache__/modeling_tapas.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 638 |
+
venv/lib/python3.11/site-packages/transformers/models/tapas/__pycache__/modeling_tf_tapas.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 639 |
+
venv/lib/python3.11/site-packages/transformers/models/tapas/__pycache__/tokenization_tapas.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 640 |
+
venv/lib/python3.11/site-packages/transformers/models/udop/__pycache__/modeling_udop.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 641 |
+
venv/lib/python3.11/site-packages/transformers/models/unispeech_sat/__pycache__/modeling_unispeech_sat.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 642 |
+
venv/lib/python3.11/site-packages/transformers/models/wav2vec2/__pycache__/modeling_tf_wav2vec2.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 643 |
+
venv/lib/python3.11/site-packages/transformers/models/wav2vec2/__pycache__/modeling_wav2vec2.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 644 |
+
venv/lib/python3.11/site-packages/transformers/models/wav2vec2_conformer/__pycache__/modeling_wav2vec2_conformer.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 645 |
+
venv/lib/python3.11/site-packages/transformers/models/whisper/__pycache__/modeling_whisper.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 646 |
+
venv/lib/python3.11/site-packages/transformers/models/xlnet/__pycache__/modeling_xlnet.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 647 |
+
venv/lib/python3.11/site-packages/transformers/utils/__pycache__/dummy_pt_objects.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 648 |
+
venv/lib/python3.11/site-packages/transformers/utils/__pycache__/dummy_tf_objects.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 649 |
+
venv/lib/python3.11/site-packages/wandb/bin/gpu_stats filter=lfs diff=lfs merge=lfs -text
|
| 650 |
+
venv/lib/python3.11/site-packages/wandb/bin/wandb-core filter=lfs diff=lfs merge=lfs -text
|
| 651 |
+
venv/lib/python3.11/site-packages/wandb/cli/__pycache__/cli.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 652 |
+
venv/lib/python3.11/site-packages/wandb/sdk/__pycache__/wandb_run.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 653 |
+
venv/lib/python3.11/site-packages/wandb/sdk/artifacts/__pycache__/artifact.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 654 |
+
venv/lib/python3.11/site-packages/wandb/sdk/internal/__pycache__/internal_api.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 655 |
+
venv/lib/python3.11/site-packages/wandb/vendor/pygments/lexers/__pycache__/lisp.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 656 |
+
venv/lib/python3.11/site-packages/wandb/vendor/pynvml/__pycache__/pynvml.cpython-311.pyc filter=lfs diff=lfs merge=lfs -text
|
| 657 |
+
venv/lib/python3.11/site-packages/xxhash/_xxhash.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 658 |
+
venv/lib/python3.11/site-packages/yaml/_yaml.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
| 659 |
+
venv/lib/python3.11/site-packages/yarl/_quoting_c.cpython-311-darwin.so filter=lfs diff=lfs merge=lfs -text
|
.gradio/certificate.pem
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
-----BEGIN CERTIFICATE-----
|
| 2 |
+
MIIFazCCA1OgAwIBAgIRAIIQz7DSQONZRGPgu2OCiwAwDQYJKoZIhvcNAQELBQAw
|
| 3 |
+
TzELMAkGA1UEBhMCVVMxKTAnBgNVBAoTIEludGVybmV0IFNlY3VyaXR5IFJlc2Vh
|
| 4 |
+
cmNoIEdyb3VwMRUwEwYDVQQDEwxJU1JHIFJvb3QgWDEwHhcNMTUwNjA0MTEwNDM4
|
| 5 |
+
WhcNMzUwNjA0MTEwNDM4WjBPMQswCQYDVQQGEwJVUzEpMCcGA1UEChMgSW50ZXJu
|
| 6 |
+
ZXQgU2VjdXJpdHkgUmVzZWFyY2ggR3JvdXAxFTATBgNVBAMTDElTUkcgUm9vdCBY
|
| 7 |
+
MTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAK3oJHP0FDfzm54rVygc
|
| 8 |
+
h77ct984kIxuPOZXoHj3dcKi/vVqbvYATyjb3miGbESTtrFj/RQSa78f0uoxmyF+
|
| 9 |
+
0TM8ukj13Xnfs7j/EvEhmkvBioZxaUpmZmyPfjxwv60pIgbz5MDmgK7iS4+3mX6U
|
| 10 |
+
A5/TR5d8mUgjU+g4rk8Kb4Mu0UlXjIB0ttov0DiNewNwIRt18jA8+o+u3dpjq+sW
|
| 11 |
+
T8KOEUt+zwvo/7V3LvSye0rgTBIlDHCNAymg4VMk7BPZ7hm/ELNKjD+Jo2FR3qyH
|
| 12 |
+
B5T0Y3HsLuJvW5iB4YlcNHlsdu87kGJ55tukmi8mxdAQ4Q7e2RCOFvu396j3x+UC
|
| 13 |
+
B5iPNgiV5+I3lg02dZ77DnKxHZu8A/lJBdiB3QW0KtZB6awBdpUKD9jf1b0SHzUv
|
| 14 |
+
KBds0pjBqAlkd25HN7rOrFleaJ1/ctaJxQZBKT5ZPt0m9STJEadao0xAH0ahmbWn
|
| 15 |
+
OlFuhjuefXKnEgV4We0+UXgVCwOPjdAvBbI+e0ocS3MFEvzG6uBQE3xDk3SzynTn
|
| 16 |
+
jh8BCNAw1FtxNrQHusEwMFxIt4I7mKZ9YIqioymCzLq9gwQbooMDQaHWBfEbwrbw
|
| 17 |
+
qHyGO0aoSCqI3Haadr8faqU9GY/rOPNk3sgrDQoo//fb4hVC1CLQJ13hef4Y53CI
|
| 18 |
+
rU7m2Ys6xt0nUW7/vGT1M0NPAgMBAAGjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNV
|
| 19 |
+
HRMBAf8EBTADAQH/MB0GA1UdDgQWBBR5tFnme7bl5AFzgAiIyBpY9umbbjANBgkq
|
| 20 |
+
hkiG9w0BAQsFAAOCAgEAVR9YqbyyqFDQDLHYGmkgJykIrGF1XIpu+ILlaS/V9lZL
|
| 21 |
+
ubhzEFnTIZd+50xx+7LSYK05qAvqFyFWhfFQDlnrzuBZ6brJFe+GnY+EgPbk6ZGQ
|
| 22 |
+
3BebYhtF8GaV0nxvwuo77x/Py9auJ/GpsMiu/X1+mvoiBOv/2X/qkSsisRcOj/KK
|
| 23 |
+
NFtY2PwByVS5uCbMiogziUwthDyC3+6WVwW6LLv3xLfHTjuCvjHIInNzktHCgKQ5
|
| 24 |
+
ORAzI4JMPJ+GslWYHb4phowim57iaztXOoJwTdwJx4nLCgdNbOhdjsnvzqvHu7Ur
|
| 25 |
+
TkXWStAmzOVyyghqpZXjFaH3pO3JLF+l+/+sKAIuvtd7u+Nxe5AW0wdeRlN8NwdC
|
| 26 |
+
jNPElpzVmbUq4JUagEiuTDkHzsxHpFKVK7q4+63SM1N95R1NbdWhscdCb+ZAJzVc
|
| 27 |
+
oyi3B43njTOQ5yOf+1CceWxG1bQVs5ZufpsMljq4Ui0/1lvh+wjChP4kqKOJ2qxq
|
| 28 |
+
4RgqsahDYVvTH9w7jXbyLeiNdd8XM2w9U/t7y0Ff/9yi0GE44Za4rF2LN9d11TPA
|
| 29 |
+
mRGunUHBcnWEvgJBQl9nJEiU0Zsnvgc/ubhPgXRR4Xq37Z0j4r7g1SgEEzwxA57d
|
| 30 |
+
emyPxgcYxn/eR44/KJ4EBs+lVDR3veyJm+kXQ99b21/+jh5Xos1AnX5iItreGCc=
|
| 31 |
+
-----END CERTIFICATE-----
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2025 Ling Yang
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,12 +1,215 @@
|
|
| 1 |
---
|
| 2 |
title: MMaDA
|
| 3 |
-
emoji: 📊
|
| 4 |
-
colorFrom: green
|
| 5 |
-
colorTo: indigo
|
| 6 |
-
sdk: gradio
|
| 7 |
-
sdk_version: 5.34.2
|
| 8 |
app_file: app.py
|
| 9 |
-
|
|
|
|
| 10 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
|
| 12 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
title: MMaDA
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
app_file: app.py
|
| 4 |
+
sdk: gradio
|
| 5 |
+
sdk_version: 3.41.2
|
| 6 |
---
|
| 7 |
+
<div align="center">
|
| 8 |
+
<br>
|
| 9 |
+
<img src="assets/title.png" width="166">
|
| 10 |
+
<h3>Multimodal Large Diffusion Language Models</h3></div>
|
| 11 |
+
|
| 12 |
+
<p align="center">
|
| 13 |
+
<a href="https://arxiv.org/abs/2505.15809">
|
| 14 |
+
<img
|
| 15 |
+
src="https://img.shields.io/badge/MMaDA-Paper-red?logo=arxiv&logoColor=red"
|
| 16 |
+
alt="MMaDA Paper on arXiv"
|
| 17 |
+
/>
|
| 18 |
+
</a>
|
| 19 |
+
<a href="https://huggingface.co/spaces/Gen-Verse/MMaDA">
|
| 20 |
+
<img
|
| 21 |
+
src="https://img.shields.io/badge/MMaDA%20Demo-Hugging%20Face%20Space-blue?logo=huggingface&logoColor=blue"
|
| 22 |
+
alt="MMaDA on Hugging Face"
|
| 23 |
+
/>
|
| 24 |
+
</a>
|
| 25 |
+
<a href="https://huggingface.co/Gen-Verse/MMaDA-8B-Base">
|
| 26 |
+
<img
|
| 27 |
+
src="https://img.shields.io/badge/MMaDA--8B--Base-Hugging%20Face%20Model-orange?logo=huggingface&logoColor=yellow"
|
| 28 |
+
alt="MMaDA on Hugging Face"
|
| 29 |
+
/>
|
| 30 |
+
</a>
|
| 31 |
+
<a href="https://huggingface.co/Gen-Verse/MMaDA-8B-MixCoT">
|
| 32 |
+
<img
|
| 33 |
+
src="https://img.shields.io/badge/MMaDA--8B--MixCoT-Hugging%20Face%20Model-orange?logo=huggingface&logoColor=yellow"
|
| 34 |
+
alt="MMaDA on Hugging Face"
|
| 35 |
+
/>
|
| 36 |
+
</a>
|
| 37 |
+
<a href="https://github.com/Gen-Verse/MMaDA/blob/main/assets/wx-mmada-0613.jpeg">
|
| 38 |
+
<img
|
| 39 |
+
src="https://img.shields.io/badge/Wechat-Join-green?logo=wechat&"
|
| 40 |
+
alt="Wechat Group Link"
|
| 41 |
+
/>
|
| 42 |
+
</a>
|
| 43 |
+
|
| 44 |
+
</p>
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
## 🌌 Introduction
|
| 48 |
+
MMaDA is a new family of **multimodal diffusion foundation models** designed to achieve superior performance across diverse domains such as textual reasoning, multimodal understanding, and text-to-image generation. MMaDA is distinguished by three key innovations:
|
| 49 |
+
1. MMaDA adopts a **unified diffusion architecture** with a shared probabilistic formulation and a modality-agnostic design, eliminating the need for modality-specific components.
|
| 50 |
+
2. MMaDA introduces a **mixed long chain-of-thought (CoT) fine-tuning** strategy that curates a unified CoT format across modalities.
|
| 51 |
+
3. MMaDA adopts a unified policy-gradient-based RL algorithm, which we call **UniGRPO**, tailored for diffusion foundation models. Utilizing diversified reward modeling, **UniGRPO** unifies post-training across both reasoning and generation tasks, ensuring consistent performance improvements.
|
| 52 |
+
|
| 53 |
+
<div align="center" style="width: 600px; margin: auto;">
|
| 54 |
+
<img src="assets/showcase0.8.gif" alt="MMaDA decoding demo" width="550" />
|
| 55 |
+
<p style="font-style: italic; font-size: 14px; color: #555; margin-top: 6px;">
|
| 56 |
+
MMaDA's decoding demo. This video showcases how a diffusion foundation model generates text and image.<br>
|
| 57 |
+
The "Text Generation" part uses a semi-autoregressive sampling method, while the "Multimodal Generation" part adopts non-autoregressive diffusion denoising.
|
| 58 |
+
</p>
|
| 59 |
+
</div>
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
<!--
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
## Decoding Demo
|
| 72 |
+
We demonstrate the decoding process of MMaDA with a teaser video to show how a diffusion model generates text and image. The "Text Generation" part adopts a "semi-autoregressive" sampling method and the "MultiModal Generation" part adopts a non-autoregressive sampling method which is purely diffusion denoising.
|
| 73 |
+
|
| 74 |
+
<!-- <div style="display: flex; justify-content: center; flex-wrap: wrap;">
|
| 75 |
+
<img src="assets/showcase0.8.gif" style="width: 90%" />
|
| 76 |
+
</div> -->
|
| 77 |
+
|
| 78 |
+
## 📰 Latest Updates
|
| 79 |
+
* **[2025-06-02]** We open source our **MMaDA-8B-MixCoT** at [Huggingface](https://huggingface.co/Gen-Verse/MMaDA-8B-MixCoT).
|
| 80 |
+
* **[2025-05-24]** We add support for MPS inference, tested on M4.
|
| 81 |
+
* **[2025-05-22]** We release the inference and training code of MMaDA for text generation, multimodal generation and image generation.
|
| 82 |
+
* **[2025-05-22]** We open source our **MMaDA-8B-Base** at [Huggingface](https://huggingface.co/Gen-Verse/MMaDA-8B-Base). **MMaDA-8B-MixCoT** and **MMaDA-8B-Max** will be released in the near future.
|
| 83 |
+
* **[2025-05-22]** We release our [research paper](https://arxiv.org/abs/2505.15809) and [demo](https://huggingface.co/spaces/Gen-Verse/MMaDA) for the first unified multimodal diffusion model: MMaDA.
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
## 🧬 MMaDA Series Overview
|
| 87 |
+
|
| 88 |
+
MMaDA includes a series of checkpoints reflecting different training stages:
|
| 89 |
+
1. **[MMaDA-8B-Base](https://huggingface.co/Gen-Verse/MMaDA-8B-Base)**: After pretraining and instruction tuning. Capable of basic text generation, image generation, image captioning and **thinking ablities**.
|
| 90 |
+
2. **[MMaDA-8B-MixCoT](https://huggingface.co/Gen-Verse/MMaDA-8B-MixCoT)**: After mixed long chain-of-thought (CoT) fine-tuning. Capable of **complex** textual, multimodal and image generation reasoning.
|
| 91 |
+
3. **MMaDA-8B-Max (coming soon)**: After UniGRPO reinforment learning. Excels at complex reasoning and awesome visual generation. Will be released in the future.
|
| 92 |
+
<div align="center">
|
| 93 |
+
<img src="assets/example_compare.png" width="800">
|
| 94 |
+
<p><i>Overview of MMaDA's capablities.</i></p>
|
| 95 |
+
</div>
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
## ✅ TODO
|
| 101 |
+
- [x] Release [MMaDA-8B-MixCoT](https://huggingface.co/Gen-Verse/MMaDA-8B-MixCoT)
|
| 102 |
+
- [ ] Release MMaDA-8B-Max and OpenRLHF-based UniGRPO training code.
|
| 103 |
+
|
| 104 |
+
## ⚙️ Quick Start
|
| 105 |
+
First, set up the enviroment:
|
| 106 |
+
```
|
| 107 |
+
pip install -r requirements.txt
|
| 108 |
+
```
|
| 109 |
+
Launch local Gradio demo:
|
| 110 |
+
```
|
| 111 |
+
python app.py
|
| 112 |
+
```
|
| 113 |
+
Or try it online via our [Huggingface Demo](https://huggingface.co/spaces/Gen-Verse/MMaDA).
|
| 114 |
+
|
| 115 |
+
## 🚀 Inference
|
| 116 |
+
For batch-level inference, we provide our inference scripts here.
|
| 117 |
+
### 1. Text Generation
|
| 118 |
+
For text generation, we follow LLaDA's configuration and generation script. Simple run:
|
| 119 |
+
```bash
|
| 120 |
+
python generate.py
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
### 2. MultiModal Generation
|
| 124 |
+
For multimodal generation and text-to-image generation, first login your wandb account:
|
| 125 |
+
```
|
| 126 |
+
wandb login
|
| 127 |
+
```
|
| 128 |
+
Inference demo for MultiModal Generation and you can view the results on wandb:
|
| 129 |
+
```
|
| 130 |
+
python3 inference_mmu.py config=configs/mmada_demo.yaml mmu_image_root=./mmu_validation question='Please describe this image in detail.'
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
### 3. Text-to-Image Genertion
|
| 134 |
+
For multimodal generation and text-to-image generation, first login your wandb account:
|
| 135 |
+
```
|
| 136 |
+
wandb login
|
| 137 |
+
```
|
| 138 |
+
Inference demo for Text-to-Image Genertion and you can view the results on wandb:
|
| 139 |
+
```
|
| 140 |
+
python3 inference_t2i.py config=configs/mmada_demo.yaml batch_size=1 validation_prompts_file=validation_prompts/text2image_prompts.txt guidance_scale=3.5 generation_timesteps=15
|
| 141 |
+
mode='t2i'
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
## 🔧 Training
|
| 145 |
+
**Update your training data path in `configs/xx.yaml`.**
|
| 146 |
+
|
| 147 |
+
### Stage 0. Prepare your accelerate configs
|
| 148 |
+
Please first prepare your accelerate configs. You can simple run
|
| 149 |
+
```
|
| 150 |
+
accelerate config
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
Or use our provided configs in `accelerate_configs`:
|
| 154 |
+
```
|
| 155 |
+
├── accelerate_configs/
|
| 156 |
+
| ├── 1_gpu.yaml
|
| 157 |
+
| └── 8_node_8_gpus_deepspeed_zero2.yaml (for 8 * 8 gpus)
|
| 158 |
+
```
|
| 159 |
+
|
| 160 |
+
### Stage 1.1: Pre-training on ImageNet
|
| 161 |
+
First we use LLaDA-8B-Instruct to initialize our model, and train on ImageNet for basic visual capbalities.
|
| 162 |
+
```
|
| 163 |
+
accelerate launch --config_file path/to/your/accelerate_config --main_process_port=8888 training/train_mmada.py config=configs/mmada_pretraining_stage1_llada_instruct.yaml
|
| 164 |
+
```
|
| 165 |
+
|
| 166 |
+
### Stage 1.2 Pre-training on Image-Text Dataset
|
| 167 |
+
Then we replace the ImageNet dataset in Stage 1.1 with Image-Text Dataset. Please change the pretrained model path in `mmada_pretraining_stage2_llada_instruct.yaml` with your checkpoint in Stage 1.1
|
| 168 |
+
```
|
| 169 |
+
accelerate launch --config_file path/to/your/accelerate_config --main_process_port=8888 training/train_mmada_stage2.py config=configs/mmada_pretraining_stage2_llada_instruct.yaml
|
| 170 |
+
```
|
| 171 |
+
|
| 172 |
+
### Stage 1.3 Pre-training on Text Instruction following
|
| 173 |
+
In this stage, we begin training on text instruction following and include corresponding validations. Please change the pretrained model path in `mmada_pretraining_stage3_llada_instruct.yaml` with your checkpoint in Stage 1.2
|
| 174 |
+
```
|
| 175 |
+
accelerate launch --config_file path/to/your/accelerate_config --main_process_port=8888 training/train_mmada_stage3.py config=configs/mmada_pretraining_stage3_llada_instruct.yaml
|
| 176 |
+
```
|
| 177 |
+
|
| 178 |
+
### Stage 2.1 Mix-CoT Training (Text Only)
|
| 179 |
+
In this stage, we begin our Mix-CoT finetuning with text reasoning first, along with improved image quality. Please change the pretrained model path in `mmada_pretraining_stage3_llada_instruct.yaml` with your checkpoint in Stage 1.3 and prepare your CoT data.
|
| 180 |
+
```
|
| 181 |
+
accelerate launch --config_file path/to/your/accelerate_config --main_process_port=8888 training/train_mmada_stage_cot_sft.py config=configs/mmada_pretraining_stage3_llada_instruct_512_cot.yaml
|
| 182 |
+
```
|
| 183 |
+
|
| 184 |
+
### Stage 2.2 Mix-CoT Training (with MultiModal Reasoning)
|
| 185 |
+
In this stage, we include multimodal reasoning, along with improved image quality. Please change the pretrained model path in `mmada_pretraining_stage3_llada_instruct.yaml` with your checkpoint in Stage 2.1 and prepare your CoT data.
|
| 186 |
+
```
|
| 187 |
+
accelerate launch --config_file path/to/your/accelerate_config --main_process_port=8888 training/train_mmada_stage4.py config=configs/mmada_pretraining_stage4_llada_instruct.yaml
|
| 188 |
+
```
|
| 189 |
+
|
| 190 |
+
### Stage 3 UniGRPO RL
|
| 191 |
+
[Will be released once we finished our code transition to OpenRLHF]
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
## 📖 Citation
|
| 195 |
+
```
|
| 196 |
+
@article{yang2025mmada,
|
| 197 |
+
title={MMaDA: Multimodal Large Diffusion Language Models},
|
| 198 |
+
author={Yang, Ling and Tian, Ye and Li, Bowen and Zhang, Xinchen and Shen, Ke and Tong, Yunhai and Wang, Mengdi},
|
| 199 |
+
journal={arXiv preprint arXiv:2505.15809},
|
| 200 |
+
year={2025}
|
| 201 |
+
}
|
| 202 |
+
```
|
| 203 |
+
|
| 204 |
+
## 🤝 Acknowledgments
|
| 205 |
+
This work is heavily based on [Show-o](https://github.com/showlab/Show-o), [LLaDA](https://github.com/ML-GSAI/LLaDA), [maskgit](https://github.com/google-research/maskgit), [transformers](https://github.com/huggingface/transformers), [accelerate](https://github.com/huggingface/accelerate) and [webdataset](https://github.com/webdataset/webdataset). Thanks to all the authors for their great work.
|
| 206 |
+
|
| 207 |
+
## 💬 Discussion and Collaboration
|
| 208 |
+
|
| 209 |
+
Welcome to discuss and collaborate with us for continuously improving MMaDA. If you have any bad cases, please kindly share them in the [Issue](https://github.com/Gen-Verse/MMaDA/issues/4#issue-3083196081).
|
| 210 |
+
|
| 211 |
+
Also, you can reach us with this WeChat QR code!
|
| 212 |
+
<p align="center">
|
| 213 |
+
<img src="assets/wx-mmada-0613.jpeg" width="256">
|
| 214 |
+
</p>
|
| 215 |
|
|
|
accelerate_configs/1_gpu.yaml
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
compute_environment: LOCAL_MACHINE
|
| 2 |
+
distributed_type: 'NO'
|
| 3 |
+
downcast_bf16: 'no'
|
| 4 |
+
gpu_ids: '0'
|
| 5 |
+
machine_rank: 0
|
| 6 |
+
main_training_function: main
|
| 7 |
+
mixed_precision: bf16
|
| 8 |
+
num_machines: 1
|
| 9 |
+
num_processes: 1
|
| 10 |
+
rdzv_backend: static
|
| 11 |
+
same_network: true
|
| 12 |
+
tpu_env: []
|
| 13 |
+
tpu_use_cluster: false
|
| 14 |
+
tpu_use_sudo: false
|
| 15 |
+
use_cpu: false
|
accelerate_configs/1_node_8_gpus_deepspeed_zero2.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
compute_environment: LOCAL_MACHINE
|
| 2 |
+
deepspeed_config:
|
| 3 |
+
deepspeed_multinode_launcher: standard
|
| 4 |
+
gradient_accumulation_steps: 1
|
| 5 |
+
gradient_clipping: 1.0
|
| 6 |
+
offload_optimizer_device: cpu
|
| 7 |
+
offload_param_device: cpu
|
| 8 |
+
zero3_init_flag: true
|
| 9 |
+
zero_stage: 2
|
| 10 |
+
distributed_type: DEEPSPEED
|
| 11 |
+
downcast_bf16: 'no'
|
| 12 |
+
main_training_function: main
|
| 13 |
+
mixed_precision: bf16
|
| 14 |
+
num_machines: 1
|
| 15 |
+
num_processes: 8
|
| 16 |
+
rdzv_backend: static
|
| 17 |
+
same_network: true
|
| 18 |
+
tpu_env: []
|
| 19 |
+
tpu_use_cluster: false
|
| 20 |
+
tpu_use_sudo: false
|
| 21 |
+
use_cpu: false
|
accelerate_configs/1_node_8_gpus_deepspeed_zero3.yaml
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
compute_environment: LOCAL_MACHINE
|
| 2 |
+
deepspeed_config:
|
| 3 |
+
deepspeed_multinode_launcher: standard
|
| 4 |
+
gradient_accumulation_steps: 2
|
| 5 |
+
gradient_clipping: 1.0
|
| 6 |
+
offload_optimizer_device: cpu
|
| 7 |
+
offload_param_device: cpu
|
| 8 |
+
zero3_init_flag: true
|
| 9 |
+
zero3_save_16bit_model: true
|
| 10 |
+
zero_stage: 3
|
| 11 |
+
zero_optimization:
|
| 12 |
+
overlap_comm: false
|
| 13 |
+
distributed_type: DEEPSPEED
|
| 14 |
+
downcast_bf16: 'no'
|
| 15 |
+
main_training_function: main
|
| 16 |
+
mixed_precision: bf16
|
| 17 |
+
num_machines: 1
|
| 18 |
+
num_processes: 8
|
| 19 |
+
rdzv_backend: static
|
| 20 |
+
same_network: true
|
| 21 |
+
tpu_env: []
|
| 22 |
+
tpu_use_cluster: false
|
| 23 |
+
tpu_use_sudo: false
|
| 24 |
+
use_cpu: false
|
accelerate_configs/8_node_8_gpus_deepspeed_zero2.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
compute_environment: LOCAL_MACHINE
|
| 2 |
+
deepspeed_config:
|
| 3 |
+
deepspeed_multinode_launcher: standard
|
| 4 |
+
gradient_accumulation_steps: 1
|
| 5 |
+
gradient_clipping: 1.0
|
| 6 |
+
offload_optimizer_device: cpu
|
| 7 |
+
offload_param_device: cpu
|
| 8 |
+
zero3_init_flag: true
|
| 9 |
+
zero_stage: 2
|
| 10 |
+
distributed_type: DEEPSPEED
|
| 11 |
+
downcast_bf16: 'no'
|
| 12 |
+
main_training_function: main
|
| 13 |
+
mixed_precision: bf16
|
| 14 |
+
num_machines: 8
|
| 15 |
+
num_processes: 64
|
| 16 |
+
rdzv_backend: static
|
| 17 |
+
same_network: true
|
| 18 |
+
tpu_env: []
|
| 19 |
+
tpu_use_cluster: false
|
| 20 |
+
tpu_use_sudo: false
|
| 21 |
+
use_cpu: false
|
app.py
ADDED
|
@@ -0,0 +1,894 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import torch
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from transformers import AutoTokenizer
|
| 6 |
+
from torchvision import transforms
|
| 7 |
+
from models import MAGVITv2, get_mask_schedule, MMadaModelLM
|
| 8 |
+
from training.prompting_utils import UniversalPrompting
|
| 9 |
+
from PIL import Image
|
| 10 |
+
|
| 11 |
+
def image_transform(image, resolution=256, normalize=True):
|
| 12 |
+
image = transforms.Resize(resolution, interpolation=transforms.InterpolationMode.BICUBIC)(image)
|
| 13 |
+
image = transforms.CenterCrop((resolution, resolution))(image)
|
| 14 |
+
image = transforms.ToTensor()(image)
|
| 15 |
+
if normalize:
|
| 16 |
+
image = transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5], inplace=True)(image)
|
| 17 |
+
return image
|
| 18 |
+
|
| 19 |
+
def add_gumbel_noise(logits, temperature):
|
| 20 |
+
"""
|
| 21 |
+
Adds Gumbel noise to logits for stochastic sampling.
|
| 22 |
+
Equivalent to argmax(logits + temperature * G) where G ~ Gumbel(0,1).
|
| 23 |
+
This version is more numerically stable than a version involving exp() and division.
|
| 24 |
+
"""
|
| 25 |
+
if abs(temperature) < 1e-9: # Effectively zero temperature
|
| 26 |
+
return logits
|
| 27 |
+
# Ensure logits are float64 for precision with noise, as suggested by user context
|
| 28 |
+
if DEVICE == "mps":
|
| 29 |
+
logits = logits.to(torch.float32)
|
| 30 |
+
else:
|
| 31 |
+
logits = logits.to(torch.float64)
|
| 32 |
+
# Standard Gumbel noise: -log(-log(U)), U ~ Uniform(0,1)
|
| 33 |
+
# Add small epsilon for numerical stability inside logs
|
| 34 |
+
if DEVICE == "mps":
|
| 35 |
+
noise = torch.rand_like(logits, dtype=torch.float32)
|
| 36 |
+
else:
|
| 37 |
+
noise = torch.rand_like(logits, dtype=torch.float64)
|
| 38 |
+
standard_gumbel_noise = -torch.log(-torch.log(noise + 1e-20) + 1e-20)
|
| 39 |
+
return logits + temperature * standard_gumbel_noise
|
| 40 |
+
|
| 41 |
+
def get_num_transfer_tokens(mask_index, steps):
|
| 42 |
+
mask_num = mask_index.sum(dim=1, keepdim=True)
|
| 43 |
+
# Ensure steps is at least 1 to avoid division by zero if mask_num is also 0 (though sum should be >=0)
|
| 44 |
+
steps = max(1, int(steps)) # Ensure steps is a positive integer
|
| 45 |
+
base = mask_num // steps
|
| 46 |
+
remainder = mask_num % steps
|
| 47 |
+
num_transfer_tokens = torch.zeros(mask_num.size(0), steps, device=mask_index.device, dtype=torch.long) + base
|
| 48 |
+
for i in range(mask_num.size(0)): # Iterate over batch
|
| 49 |
+
if remainder[i] > 0 : # Ensure remainder is positive before indexing
|
| 50 |
+
num_transfer_tokens[i, :remainder[i].item()] += 1 # .item() for single value tensor to int
|
| 51 |
+
return num_transfer_tokens
|
| 52 |
+
|
| 53 |
+
MODEL = None
|
| 54 |
+
TOKENIZER = None
|
| 55 |
+
DEVICE = (
|
| 56 |
+
"cuda"
|
| 57 |
+
if torch.cuda.is_available()
|
| 58 |
+
else "mps" if torch.backends.mps.is_available() else "cpu"
|
| 59 |
+
)
|
| 60 |
+
MASK_ID = None
|
| 61 |
+
uni_prompting = None
|
| 62 |
+
VQ_MODEL = MAGVITv2().from_pretrained("showlab/magvitv2").to(DEVICE)
|
| 63 |
+
|
| 64 |
+
DEFAULT_MODEL_PATH = "Gen-Verse/MMaDA-8B-Base" # Default
|
| 65 |
+
CURRENT_MODEL_PATH = None
|
| 66 |
+
|
| 67 |
+
MODEL_CHOICES = [
|
| 68 |
+
"MMaDA-8B-Base",
|
| 69 |
+
"MMaDA-8B-MixCoT (coming soon)",
|
| 70 |
+
"MMaDA-8B-Max (coming soon)"
|
| 71 |
+
]
|
| 72 |
+
MODEL_ACTUAL_PATHS = {
|
| 73 |
+
"MMaDA-8B-Base": DEFAULT_MODEL_PATH,
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
def clear_outputs_action():
|
| 77 |
+
return None, None
|
| 78 |
+
|
| 79 |
+
def _load_model_and_tokenizer_core(model_path_to_load, model_display_name_for_status):
|
| 80 |
+
global MODEL, TOKENIZER, MASK_ID, CURRENT_MODEL_PATH, DEVICE, uni_prompting
|
| 81 |
+
|
| 82 |
+
if MODEL is not None and CURRENT_MODEL_PATH == model_path_to_load:
|
| 83 |
+
return f"Model '{model_display_name_for_status}' from '{model_path_to_load}' is already loaded. MASK_ID: {MASK_ID}"
|
| 84 |
+
|
| 85 |
+
CURRENT_MODEL_PATH = model_path_to_load
|
| 86 |
+
|
| 87 |
+
status_msg_parts = [f"Loading '{model_display_name_for_status}'..."]
|
| 88 |
+
try:
|
| 89 |
+
TOKENIZER = AutoTokenizer.from_pretrained(model_path_to_load, trust_remote_code=True)
|
| 90 |
+
status_msg_parts.append(f"Tokenizer for '{model_display_name_for_status}' loaded.")
|
| 91 |
+
|
| 92 |
+
MODEL = MMadaModelLM.from_pretrained(model_path_to_load, trust_remote_code=True, torch_dtype=torch.bfloat16).to(DEVICE).eval()
|
| 93 |
+
status_msg_parts.append(f"Model '{model_display_name_for_status}' loaded to {DEVICE}.")
|
| 94 |
+
|
| 95 |
+
uni_prompting = UniversalPrompting(TOKENIZER, max_text_len=512, special_tokens=("<|soi|>", "<|eoi|>", "<|sov|>", "<|eov|>", "<|t2i|>", "<|mmu|>", "<|t2v|>", "<|v2v|>", "<|lvg|>"),ignore_id=-100, cond_dropout_prob=0.1, use_reserved_token=True)
|
| 96 |
+
|
| 97 |
+
if hasattr(TOKENIZER, 'mask_token_id') and TOKENIZER.mask_token_id is not None:
|
| 98 |
+
MASK_ID = TOKENIZER.mask_token_id
|
| 99 |
+
status_msg_parts.append(f"Using MASK_ID from tokenizer: {MASK_ID}.")
|
| 100 |
+
else:
|
| 101 |
+
MASK_ID = 126336
|
| 102 |
+
status_msg_parts.append(f"Using default MASK_ID: {MASK_ID}.")
|
| 103 |
+
|
| 104 |
+
if TOKENIZER.pad_token_id is None:
|
| 105 |
+
if TOKENIZER.eos_token_id is not None:
|
| 106 |
+
TOKENIZER.pad_token_id = TOKENIZER.eos_token_id
|
| 107 |
+
TOKENIZER.pad_token = TOKENIZER.eos_token
|
| 108 |
+
status_msg_parts.append(f"Set pad_token_id to eos_token_id ({TOKENIZER.eos_token_id}).")
|
| 109 |
+
else:
|
| 110 |
+
status_msg_parts.append("Warning: pad_token_id is None and no eos_token_id.")
|
| 111 |
+
|
| 112 |
+
if TOKENIZER.eos_token_id is None: # Important for cleaning up output in visualization
|
| 113 |
+
status_msg_parts.append("Warning: tokenizer.eos_token_id is None. EOS cleanup might not work.")
|
| 114 |
+
|
| 115 |
+
TOKENIZER.chat_template = "{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{{ '<|start_header_id|>assistant<|end_header_id|>\n' }}"
|
| 116 |
+
|
| 117 |
+
return " ".join(status_msg_parts)
|
| 118 |
+
except Exception as e:
|
| 119 |
+
MODEL = None
|
| 120 |
+
TOKENIZER = None
|
| 121 |
+
MASK_ID = None
|
| 122 |
+
CURRENT_MODEL_PATH = None
|
| 123 |
+
return f"Error loading model '{model_display_name_for_status}': {str(e)}"
|
| 124 |
+
|
| 125 |
+
def handle_model_selection_change(selected_model_name_ui):
|
| 126 |
+
if "coming soon" in selected_model_name_ui.lower():
|
| 127 |
+
global MODEL, TOKENIZER, MASK_ID, CURRENT_MODEL_PATH
|
| 128 |
+
MODEL = None
|
| 129 |
+
TOKENIZER = None
|
| 130 |
+
MASK_ID = None
|
| 131 |
+
CURRENT_MODEL_PATH = None
|
| 132 |
+
return f"'{selected_model_name_ui}' is not yet available. Please select 'Model A'."
|
| 133 |
+
|
| 134 |
+
actual_path = MODEL_ACTUAL_PATHS.get(selected_model_name_ui)
|
| 135 |
+
if not actual_path:
|
| 136 |
+
return f"Path for '{selected_model_name_ui}' is not defined. Cannot load."
|
| 137 |
+
|
| 138 |
+
return _load_model_and_tokenizer_core(actual_path, selected_model_name_ui)
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
def get_highlighted_text_tuples(current_x_ids_batch, prompt_input_ids, prompt_len, tk, current_mask_id, raw_prompt_attention_mask):
|
| 142 |
+
if current_x_ids_batch is None or current_x_ids_batch.ndim == 0 or current_x_ids_batch.shape[0] == 0:
|
| 143 |
+
return [("Error in sequence data for visualization.", "ERROR")]
|
| 144 |
+
# only answer part
|
| 145 |
+
current_x_ids_batch = current_x_ids_batch[:, prompt_len:]
|
| 146 |
+
seq_ids = current_x_ids_batch[0].tolist()
|
| 147 |
+
eos_token_id = tk.eos_token_id # Get EOS token ID
|
| 148 |
+
|
| 149 |
+
# Stage 1: Build initial list of tuples with (token_str, label, token_id_int)
|
| 150 |
+
# This helps in identifying EOS tokens later without re-checking the type.
|
| 151 |
+
intermediate_tuples = []
|
| 152 |
+
for j, token_id_int in enumerate(seq_ids):
|
| 153 |
+
try:
|
| 154 |
+
token_str = tk.decode([token_id_int], skip_special_tokens=True, clean_up_tokenization_spaces=False)
|
| 155 |
+
except Exception: # Handle cases where a token ID might be problematic (e.g. with mock)
|
| 156 |
+
token_str = f"[ID:{token_id_int}]"
|
| 157 |
+
|
| 158 |
+
label = "ERROR"
|
| 159 |
+
if token_id_int == current_mask_id:
|
| 160 |
+
token_str = "[MASK]"
|
| 161 |
+
label = "MASK"
|
| 162 |
+
else:
|
| 163 |
+
label = "GEN"
|
| 164 |
+
intermediate_tuples.append((token_str, label, token_id_int))
|
| 165 |
+
|
| 166 |
+
return intermediate_tuples
|
| 167 |
+
|
| 168 |
+
@torch.no_grad()
|
| 169 |
+
def generate_viz_wrapper_t2i(prompt_text, steps, guidance_scale, mask_schedule="cosine"):
|
| 170 |
+
global MODEL, TOKENIZER, MASK_ID, DEVICE, uni_prompting
|
| 171 |
+
|
| 172 |
+
if MODEL is None or TOKENIZER is None or MASK_ID is None:
|
| 173 |
+
yield [("Error: Model not loaded. Please load the model first.", "ERROR")], "Model not loaded."
|
| 174 |
+
return
|
| 175 |
+
steps = int(steps)
|
| 176 |
+
guidance_scale = float(guidance_scale)
|
| 177 |
+
|
| 178 |
+
image_tokens = torch.ones((1, 1024), dtype=torch.long, device=DEVICE) * MASK_ID
|
| 179 |
+
prompt_text = [prompt_text]
|
| 180 |
+
input_ids, attention_mask = uni_prompting((prompt_text, image_tokens), 't2i_gen')
|
| 181 |
+
|
| 182 |
+
if guidance_scale > 0:
|
| 183 |
+
uncond_input_ids, uncond_attention_mask = uni_prompting(([''], image_tokens), 't2i_gen')
|
| 184 |
+
else:
|
| 185 |
+
uncond_input_ids, uncond_attention_mask = None, None
|
| 186 |
+
|
| 187 |
+
mask_schedule = get_mask_schedule(mask_schedule)
|
| 188 |
+
blank_image = Image.new("RGB", (512, 512), (255, 255, 255))
|
| 189 |
+
yield blank_image, "Starting generation..."
|
| 190 |
+
for image_step, status_msg_step in MODEL.t2i_generate_decoding_stepwise(
|
| 191 |
+
input_ids = input_ids,
|
| 192 |
+
uncond_input_ids = uncond_input_ids,
|
| 193 |
+
attention_mask = attention_mask,
|
| 194 |
+
uncond_attention_mask = uncond_attention_mask,
|
| 195 |
+
temperature=1.0,
|
| 196 |
+
timesteps = steps,
|
| 197 |
+
guidance_scale = guidance_scale,
|
| 198 |
+
noise_schedule = mask_schedule,
|
| 199 |
+
noise_type = "mask",
|
| 200 |
+
seq_len = 1024,
|
| 201 |
+
vq_model = VQ_MODEL,
|
| 202 |
+
uni_prompting=uni_prompting):
|
| 203 |
+
yield image_step, status_msg_step
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
@torch.no_grad()
|
| 209 |
+
def generate_viz_wrapper_lm(prompt_text, steps, gen_length, block_length, temperature,
|
| 210 |
+
cfg_scale, remasking_strategy, thinking_mode_lm):
|
| 211 |
+
global MODEL, TOKENIZER, MASK_ID, DEVICE
|
| 212 |
+
print(f"thinking_mode_lm: {thinking_mode_lm}")
|
| 213 |
+
if MODEL is None or TOKENIZER is None or MASK_ID is None:
|
| 214 |
+
yield [("Error: Model not loaded. Please load the model first.", "ERROR")], "Model not loaded."
|
| 215 |
+
return
|
| 216 |
+
|
| 217 |
+
steps = int(steps)
|
| 218 |
+
gen_length = int(gen_length)
|
| 219 |
+
block_length = int(block_length)
|
| 220 |
+
|
| 221 |
+
if thinking_mode_lm:
|
| 222 |
+
prompt_text = "You should first think about the reasoning process in the mind and then provide the user with the answer. The reasoning process is enclosed within <think> </think> tags, i.e. <think> reasoning process here </think> answer here\n" + prompt_text
|
| 223 |
+
|
| 224 |
+
try:
|
| 225 |
+
m = [{"role": "user", "content": prompt_text}]
|
| 226 |
+
processed_prompt_text = TOKENIZER.apply_chat_template(m, add_generation_prompt=True, tokenize=False)
|
| 227 |
+
except Exception as e:
|
| 228 |
+
yield [("Error applying chat template.", "ERROR")], f"Chat template error: {e}"
|
| 229 |
+
processed_prompt_text = prompt_text
|
| 230 |
+
try:
|
| 231 |
+
if TOKENIZER.pad_token_id is None:
|
| 232 |
+
if TOKENIZER.eos_token_id is not None:
|
| 233 |
+
TOKENIZER.pad_token_id = TOKENIZER.eos_token_id
|
| 234 |
+
else: # Should have been caught by load_model, but double check
|
| 235 |
+
yield [("Tokenizer Error", "ERROR")], "pad_token_id is not set in tokenizer."
|
| 236 |
+
return
|
| 237 |
+
|
| 238 |
+
input_ids = TOKENIZER(text=processed_prompt_text, return_tensors="pt", padding="longest", padding_side="left", truncation=True, max_length=MODEL.config.max_position_embeddings if hasattr(MODEL.config, 'max_position_embeddings') else 2048)['input_ids'].to(DEVICE)
|
| 239 |
+
raw_prompt_attention_mask = None
|
| 240 |
+
|
| 241 |
+
except Exception as e:
|
| 242 |
+
yield [("Error tokenizing prompt.", "ERROR")], f"Tokenization error: {e}"
|
| 243 |
+
return
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
batch_size = input_ids.shape[0]
|
| 248 |
+
prompt_len = input_ids.shape[1]
|
| 249 |
+
|
| 250 |
+
x = torch.full((batch_size, prompt_len + gen_length), MASK_ID, dtype=torch.long, device=DEVICE)
|
| 251 |
+
x[:, :prompt_len] = input_ids.clone()
|
| 252 |
+
|
| 253 |
+
yield get_highlighted_text_tuples(x, input_ids, prompt_len, TOKENIZER, MASK_ID, raw_prompt_attention_mask), "Starting generation: Prompt + Initial Masks"
|
| 254 |
+
|
| 255 |
+
if gen_length == 0:
|
| 256 |
+
final_text_output = TOKENIZER.batch_decode(x[:,prompt_len:], skip_special_tokens=True)
|
| 257 |
+
yield get_highlighted_text_tuples(x, input_ids, prompt_len, TOKENIZER, MASK_ID, raw_prompt_attention_mask), final_text_output[0] if final_text_output else ""
|
| 258 |
+
return
|
| 259 |
+
|
| 260 |
+
if block_length <= 0 or gen_length % block_length != 0 :
|
| 261 |
+
yield get_highlighted_text_tuples(x, input_ids, prompt_len, TOKENIZER, MASK_ID, raw_prompt_attention_mask), \
|
| 262 |
+
f"Error: gen_length ({gen_length}) must be divisible by block_length ({block_length}) and block_length > 0."
|
| 263 |
+
return
|
| 264 |
+
num_blocks = gen_length // block_length
|
| 265 |
+
|
| 266 |
+
if steps <=0 or steps % num_blocks != 0:
|
| 267 |
+
yield get_highlighted_text_tuples(x, input_ids, prompt_len, TOKENIZER, MASK_ID, raw_prompt_attention_mask), \
|
| 268 |
+
f"Error: steps ({steps}) must be positive and divisible by num_blocks ({num_blocks}). Steps: {steps}, Num Blocks: {num_blocks}"
|
| 269 |
+
return
|
| 270 |
+
steps_per_block = steps // num_blocks
|
| 271 |
+
|
| 272 |
+
for num_block_iter in range(num_blocks):
|
| 273 |
+
current_block_start_idx_in_x = prompt_len + num_block_iter * block_length
|
| 274 |
+
current_block_end_idx_in_x = prompt_len + (num_block_iter + 1) * block_length
|
| 275 |
+
|
| 276 |
+
block_masks_bool_current = torch.zeros_like(x, dtype=torch.bool)
|
| 277 |
+
block_masks_bool_current[:, current_block_start_idx_in_x:current_block_end_idx_in_x] = \
|
| 278 |
+
(x[:, current_block_start_idx_in_x:current_block_end_idx_in_x] == MASK_ID)
|
| 279 |
+
|
| 280 |
+
num_transfer_tokens_for_this_block = get_num_transfer_tokens(
|
| 281 |
+
block_masks_bool_current[:, current_block_start_idx_in_x:current_block_end_idx_in_x],
|
| 282 |
+
steps_per_block
|
| 283 |
+
)
|
| 284 |
+
|
| 285 |
+
for i_step_in_block in range(steps_per_block):
|
| 286 |
+
mask_index_global = (x == MASK_ID)
|
| 287 |
+
|
| 288 |
+
if cfg_scale > 0.:
|
| 289 |
+
un_x = x.clone()
|
| 290 |
+
# For unconditional pass, mask out the original prompt tokens that are not padding
|
| 291 |
+
# raw_prompt_attention_mask is (B, prompt_len)
|
| 292 |
+
prompt_active_tokens_mask = raw_prompt_attention_mask.bool() # True where actual prompt tokens are
|
| 293 |
+
un_x[:, :prompt_len][prompt_active_tokens_mask] = MASK_ID
|
| 294 |
+
|
| 295 |
+
x_cfg_input = torch.cat([x, un_x], dim=0)
|
| 296 |
+
# Pass attention_mask for CFG if model expects it, covering both parts
|
| 297 |
+
# For simplicity, not passing explicit attention_mask here; relies on model's internal handling.
|
| 298 |
+
model_output = MODEL(x_cfg_input)
|
| 299 |
+
logits_cond, logits_uncond = torch.chunk(model_output.logits, 2, dim=0)
|
| 300 |
+
logits = logits_uncond + (cfg_scale + 1) * (logits_cond - logits_uncond)
|
| 301 |
+
else:
|
| 302 |
+
# Not passing explicit attention_mask here; relies on model's internal handling.
|
| 303 |
+
model_output = MODEL(x)
|
| 304 |
+
logits = model_output.logits
|
| 305 |
+
|
| 306 |
+
logits_with_noise = add_gumbel_noise(logits, temperature=temperature)
|
| 307 |
+
x0_predicted_tokens = torch.argmax(logits_with_noise, dim=-1)
|
| 308 |
+
|
| 309 |
+
if remasking_strategy == 'low_confidence':
|
| 310 |
+
if DEVICE == "mps":
|
| 311 |
+
probs = F.softmax(logits.to(torch.float32), dim=-1)
|
| 312 |
+
else:
|
| 313 |
+
probs = F.softmax(logits.to(torch.float64), dim=-1)
|
| 314 |
+
x0_probs = torch.gather(probs, dim=-1, index=x0_predicted_tokens.unsqueeze(-1)).squeeze(-1)
|
| 315 |
+
elif remasking_strategy == 'random':
|
| 316 |
+
if DEVICE == "mps":
|
| 317 |
+
x0_probs = torch.rand(x.shape, device=x.device, dtype=torch.float32)
|
| 318 |
+
else:
|
| 319 |
+
x0_probs = torch.rand(x.shape, device=x.device, dtype=torch.float64)
|
| 320 |
+
else:
|
| 321 |
+
yield get_highlighted_text_tuples(x, input_ids, prompt_len, TOKENIZER, MASK_ID, raw_prompt_attention_mask), f"Error: Unknown remasking strategy '{remasking_strategy}'"
|
| 322 |
+
return
|
| 323 |
+
|
| 324 |
+
confidence_for_selection = torch.full_like(x0_probs, -torch.inf)
|
| 325 |
+
candidate_positions_for_unmasking = mask_index_global & block_masks_bool_current
|
| 326 |
+
confidence_for_selection = torch.where(
|
| 327 |
+
candidate_positions_for_unmasking,
|
| 328 |
+
x0_probs,
|
| 329 |
+
-torch.inf
|
| 330 |
+
)
|
| 331 |
+
|
| 332 |
+
x0_final_candidates = torch.where(mask_index_global, x0_predicted_tokens, x)
|
| 333 |
+
|
| 334 |
+
transfer_indices_bool = torch.zeros_like(x, dtype=torch.bool)
|
| 335 |
+
num_to_transfer_this_step_batch = num_transfer_tokens_for_this_block[:, i_step_in_block]
|
| 336 |
+
|
| 337 |
+
for j_batch_idx in range(batch_size):
|
| 338 |
+
k_val = min(num_to_transfer_this_step_batch[j_batch_idx].item(),
|
| 339 |
+
candidate_positions_for_unmasking[j_batch_idx].sum().item()) # ensure k isn't too large
|
| 340 |
+
|
| 341 |
+
if k_val > 0:
|
| 342 |
+
# Ensure confidence_for_selection[j_batch_idx] is 1D for topk
|
| 343 |
+
conf_slice = confidence_for_selection[j_batch_idx]
|
| 344 |
+
if conf_slice.ndim > 1: conf_slice = conf_slice.view(-1) # Should already be 1D from x0_probs
|
| 345 |
+
|
| 346 |
+
# Check if there are enough valid (non -inf) confidences
|
| 347 |
+
valid_conf_count = (conf_slice > -torch.inf).sum().item()
|
| 348 |
+
actual_k = min(k_val, valid_conf_count)
|
| 349 |
+
|
| 350 |
+
if actual_k > 0:
|
| 351 |
+
_, topk_indices_in_x = torch.topk(conf_slice, k=actual_k)
|
| 352 |
+
transfer_indices_bool[j_batch_idx, topk_indices_in_x] = True
|
| 353 |
+
|
| 354 |
+
x[transfer_indices_bool] = x0_final_candidates[transfer_indices_bool]
|
| 355 |
+
|
| 356 |
+
current_total_step = num_block_iter * steps_per_block + i_step_in_block + 1
|
| 357 |
+
total_overall_steps = num_blocks * steps_per_block
|
| 358 |
+
status_msg = f"Block {num_block_iter+1}/{num_blocks}, Step {i_step_in_block+1}/{steps_per_block} (Total: {current_total_step}/{total_overall_steps})"
|
| 359 |
+
yield get_highlighted_text_tuples(x, input_ids, prompt_len, TOKENIZER, MASK_ID, raw_prompt_attention_mask), status_msg
|
| 360 |
+
|
| 361 |
+
final_generated_ids = x[:, prompt_len:]
|
| 362 |
+
final_text_output = TOKENIZER.batch_decode(final_generated_ids, skip_special_tokens=True)
|
| 363 |
+
|
| 364 |
+
final_text_str = final_text_output[0] if final_text_output and len(final_text_output) > 0 else ""
|
| 365 |
+
yield get_highlighted_text_tuples(x, input_ids, prompt_len, TOKENIZER, MASK_ID, raw_prompt_attention_mask), final_text_str
|
| 366 |
+
|
| 367 |
+
@torch.no_grad()
|
| 368 |
+
def generate_viz_wrapper(uploaded_image_pil, prompt_text, steps, gen_length, block_length, temperature,
|
| 369 |
+
cfg_scale, remasking_strategy, thinking_mode_mmu):
|
| 370 |
+
global MODEL, TOKENIZER, MASK_ID, DEVICE
|
| 371 |
+
|
| 372 |
+
if MODEL is None or TOKENIZER is None or MASK_ID is None:
|
| 373 |
+
yield [("Error: Model not loaded. Please load the model first.", "ERROR")], "Model not loaded."
|
| 374 |
+
return
|
| 375 |
+
|
| 376 |
+
steps = int(steps)
|
| 377 |
+
gen_length = int(gen_length)
|
| 378 |
+
block_length = int(block_length)
|
| 379 |
+
|
| 380 |
+
if thinking_mode_mmu:
|
| 381 |
+
prompt_text = "You should first think about the reasoning process in the mind and then provide the user with the answer. The reasoning process is enclosed within <think> </think> tags, i.e. <think> reasoning process here </think> answer here\n" + prompt_text
|
| 382 |
+
|
| 383 |
+
try:
|
| 384 |
+
m = [{"role": "user", "content": prompt_text}]
|
| 385 |
+
processed_prompt_text = TOKENIZER.apply_chat_template(m, add_generation_prompt=True, tokenize=False)
|
| 386 |
+
except Exception as e:
|
| 387 |
+
yield [("Error applying chat template.", "ERROR")], f"Chat template error: {e}"
|
| 388 |
+
processed_prompt_text = prompt_text
|
| 389 |
+
|
| 390 |
+
image_vq_ids_tensor = None
|
| 391 |
+
if uploaded_image_pil is not None:
|
| 392 |
+
try:
|
| 393 |
+
|
| 394 |
+
image = image_transform(uploaded_image_pil, resolution=512).to(DEVICE)
|
| 395 |
+
image = image.unsqueeze(0)
|
| 396 |
+
image_vq_ids_tensor = VQ_MODEL.get_code(image) + 126349
|
| 397 |
+
except Exception as e:
|
| 398 |
+
yield [("Error processing image.", "ERROR")], f"Image to VQ tokens conversion failed: {str(e)}"
|
| 399 |
+
return
|
| 400 |
+
|
| 401 |
+
|
| 402 |
+
try:
|
| 403 |
+
if TOKENIZER.pad_token_id is None:
|
| 404 |
+
if TOKENIZER.eos_token_id is not None:
|
| 405 |
+
TOKENIZER.pad_token_id = TOKENIZER.eos_token_id
|
| 406 |
+
else:
|
| 407 |
+
yield [("Tokenizer Error", "ERROR")], "pad_token_id is not set in tokenizer."
|
| 408 |
+
return
|
| 409 |
+
|
| 410 |
+
input_ids = TOKENIZER(text=processed_prompt_text, return_tensors="pt", padding="longest", padding_side="left", truncation=True, max_length=MODEL.config.max_position_embeddings if hasattr(MODEL.config, 'max_position_embeddings') else 2048)['input_ids'].to(DEVICE)
|
| 411 |
+
raw_prompt_attention_mask = None
|
| 412 |
+
if image_vq_ids_tensor is not None:
|
| 413 |
+
if image_vq_ids_tensor.ndim == 1:
|
| 414 |
+
image_vq_ids_tensor = image_vq_ids_tensor.unsqueeze(0)
|
| 415 |
+
|
| 416 |
+
input_ids = torch.cat([
|
| 417 |
+
(torch.ones(input_ids.shape[0], 1) * torch.tensor([126089])).to(DEVICE),
|
| 418 |
+
(torch.ones(input_ids.shape[0], 1) * torch.tensor([126084])).to(DEVICE),
|
| 419 |
+
image_vq_ids_tensor,
|
| 420 |
+
(torch.ones(input_ids.shape[0], 1) * torch.tensor([126085])).to(DEVICE),
|
| 421 |
+
input_ids
|
| 422 |
+
], dim=1).long()
|
| 423 |
+
|
| 424 |
+
else:
|
| 425 |
+
input_ids = input_ids
|
| 426 |
+
|
| 427 |
+
|
| 428 |
+
except Exception as e:
|
| 429 |
+
yield [("Error tokenizing prompt.", "ERROR")], f"Tokenization error: {e}"
|
| 430 |
+
return
|
| 431 |
+
|
| 432 |
+
|
| 433 |
+
|
| 434 |
+
batch_size = input_ids.shape[0]
|
| 435 |
+
prompt_len = input_ids.shape[1]
|
| 436 |
+
|
| 437 |
+
x = torch.full((batch_size, prompt_len + gen_length), MASK_ID, dtype=torch.long, device=DEVICE)
|
| 438 |
+
x[:, :prompt_len] = input_ids.clone()
|
| 439 |
+
|
| 440 |
+
yield get_highlighted_text_tuples(x, input_ids, prompt_len, TOKENIZER, MASK_ID, raw_prompt_attention_mask), "Starting generation: Prompt + Initial Masks"
|
| 441 |
+
|
| 442 |
+
if gen_length == 0:
|
| 443 |
+
final_text_output = TOKENIZER.batch_decode(x[:,prompt_len:], skip_special_tokens=True)
|
| 444 |
+
yield get_highlighted_text_tuples(x, input_ids, prompt_len, TOKENIZER, MASK_ID, raw_prompt_attention_mask), final_text_output[0] if final_text_output else ""
|
| 445 |
+
return
|
| 446 |
+
|
| 447 |
+
if block_length <= 0 or gen_length % block_length != 0 :
|
| 448 |
+
yield get_highlighted_text_tuples(x, input_ids, prompt_len, TOKENIZER, MASK_ID, raw_prompt_attention_mask), \
|
| 449 |
+
f"Error: gen_length ({gen_length}) must be divisible by block_length ({block_length}) and block_length > 0."
|
| 450 |
+
return
|
| 451 |
+
num_blocks = gen_length // block_length
|
| 452 |
+
|
| 453 |
+
if steps <=0 or steps % num_blocks != 0:
|
| 454 |
+
yield get_highlighted_text_tuples(x, input_ids, prompt_len, TOKENIZER, MASK_ID, raw_prompt_attention_mask), \
|
| 455 |
+
f"Error: steps ({steps}) must be positive and divisible by num_blocks ({num_blocks}). Steps: {steps}, Num Blocks: {num_blocks}"
|
| 456 |
+
return
|
| 457 |
+
steps_per_block = steps // num_blocks
|
| 458 |
+
|
| 459 |
+
for num_block_iter in range(num_blocks):
|
| 460 |
+
current_block_start_idx_in_x = prompt_len + num_block_iter * block_length
|
| 461 |
+
current_block_end_idx_in_x = prompt_len + (num_block_iter + 1) * block_length
|
| 462 |
+
|
| 463 |
+
block_masks_bool_current = torch.zeros_like(x, dtype=torch.bool)
|
| 464 |
+
block_masks_bool_current[:, current_block_start_idx_in_x:current_block_end_idx_in_x] = \
|
| 465 |
+
(x[:, current_block_start_idx_in_x:current_block_end_idx_in_x] == MASK_ID)
|
| 466 |
+
|
| 467 |
+
num_transfer_tokens_for_this_block = get_num_transfer_tokens(
|
| 468 |
+
block_masks_bool_current[:, current_block_start_idx_in_x:current_block_end_idx_in_x],
|
| 469 |
+
steps_per_block
|
| 470 |
+
)
|
| 471 |
+
|
| 472 |
+
for i_step_in_block in range(steps_per_block):
|
| 473 |
+
mask_index_global = (x == MASK_ID)
|
| 474 |
+
|
| 475 |
+
if cfg_scale > 0.:
|
| 476 |
+
un_x = x.clone()
|
| 477 |
+
# For unconditional pass, mask out the original prompt tokens that are not padding
|
| 478 |
+
# raw_prompt_attention_mask is (B, prompt_len)
|
| 479 |
+
prompt_active_tokens_mask = raw_prompt_attention_mask.bool() # True where actual prompt tokens are
|
| 480 |
+
un_x[:, :prompt_len][prompt_active_tokens_mask] = MASK_ID
|
| 481 |
+
|
| 482 |
+
x_cfg_input = torch.cat([x, un_x], dim=0)
|
| 483 |
+
# Pass attention_mask for CFG if model expects it, covering both parts
|
| 484 |
+
# For simplicity, not passing explicit attention_mask here; relies on model's internal handling.
|
| 485 |
+
model_output = MODEL(x_cfg_input)
|
| 486 |
+
logits_cond, logits_uncond = torch.chunk(model_output.logits, 2, dim=0)
|
| 487 |
+
logits = logits_uncond + (cfg_scale + 1) * (logits_cond - logits_uncond)
|
| 488 |
+
else:
|
| 489 |
+
# Not passing explicit attention_mask here; relies on model's internal handling.
|
| 490 |
+
model_output = MODEL(x)
|
| 491 |
+
logits = model_output.logits
|
| 492 |
+
|
| 493 |
+
logits_with_noise = add_gumbel_noise(logits, temperature=temperature)
|
| 494 |
+
x0_predicted_tokens = torch.argmax(logits_with_noise, dim=-1)
|
| 495 |
+
|
| 496 |
+
if remasking_strategy == 'low_confidence':
|
| 497 |
+
if DEVICE == "mps":
|
| 498 |
+
probs = F.softmax(logits.to(torch.float32), dim=-1)
|
| 499 |
+
else:
|
| 500 |
+
probs = F.softmax(logits.to(torch.float64), dim=-1)
|
| 501 |
+
x0_probs = torch.gather(probs, dim=-1, index=x0_predicted_tokens.unsqueeze(-1)).squeeze(-1)
|
| 502 |
+
elif remasking_strategy == 'random':
|
| 503 |
+
if DEVICE == "mps":
|
| 504 |
+
x0_probs = torch.rand(x.shape, device=x.device, dtype=torch.float32)
|
| 505 |
+
else:
|
| 506 |
+
x0_probs = torch.rand(x.shape, device=x.device, dtype=torch.float64)
|
| 507 |
+
else:
|
| 508 |
+
yield get_highlighted_text_tuples(x, input_ids, prompt_len, TOKENIZER, MASK_ID, raw_prompt_attention_mask), f"Error: Unknown remasking strategy '{remasking_strategy}'"
|
| 509 |
+
return
|
| 510 |
+
|
| 511 |
+
confidence_for_selection = torch.full_like(x0_probs, -torch.inf)
|
| 512 |
+
candidate_positions_for_unmasking = mask_index_global & block_masks_bool_current
|
| 513 |
+
confidence_for_selection = torch.where(
|
| 514 |
+
candidate_positions_for_unmasking,
|
| 515 |
+
x0_probs,
|
| 516 |
+
-torch.inf
|
| 517 |
+
)
|
| 518 |
+
|
| 519 |
+
x0_final_candidates = torch.where(mask_index_global, x0_predicted_tokens, x)
|
| 520 |
+
|
| 521 |
+
transfer_indices_bool = torch.zeros_like(x, dtype=torch.bool)
|
| 522 |
+
num_to_transfer_this_step_batch = num_transfer_tokens_for_this_block[:, i_step_in_block]
|
| 523 |
+
|
| 524 |
+
for j_batch_idx in range(batch_size):
|
| 525 |
+
k_val = min(num_to_transfer_this_step_batch[j_batch_idx].item(),
|
| 526 |
+
candidate_positions_for_unmasking[j_batch_idx].sum().item()) # ensure k isn't too large
|
| 527 |
+
|
| 528 |
+
if k_val > 0:
|
| 529 |
+
# Ensure confidence_for_selection[j_batch_idx] is 1D for topk
|
| 530 |
+
conf_slice = confidence_for_selection[j_batch_idx]
|
| 531 |
+
if conf_slice.ndim > 1: conf_slice = conf_slice.view(-1) # Should already be 1D from x0_probs
|
| 532 |
+
|
| 533 |
+
# Check if there are enough valid (non -inf) confidences
|
| 534 |
+
valid_conf_count = (conf_slice > -torch.inf).sum().item()
|
| 535 |
+
actual_k = min(k_val, valid_conf_count)
|
| 536 |
+
|
| 537 |
+
if actual_k > 0:
|
| 538 |
+
_, topk_indices_in_x = torch.topk(conf_slice, k=actual_k)
|
| 539 |
+
transfer_indices_bool[j_batch_idx, topk_indices_in_x] = True
|
| 540 |
+
|
| 541 |
+
x[transfer_indices_bool] = x0_final_candidates[transfer_indices_bool]
|
| 542 |
+
|
| 543 |
+
current_total_step = num_block_iter * steps_per_block + i_step_in_block + 1
|
| 544 |
+
total_overall_steps = num_blocks * steps_per_block
|
| 545 |
+
status_msg = f"Block {num_block_iter+1}/{num_blocks}, Step {i_step_in_block+1}/{steps_per_block} (Total: {current_total_step}/{total_overall_steps})"
|
| 546 |
+
yield get_highlighted_text_tuples(x, input_ids, prompt_len, TOKENIZER, MASK_ID, raw_prompt_attention_mask), status_msg
|
| 547 |
+
|
| 548 |
+
final_generated_ids = x[:, prompt_len:]
|
| 549 |
+
final_text_output = TOKENIZER.batch_decode(final_generated_ids, skip_special_tokens=True)
|
| 550 |
+
|
| 551 |
+
final_text_str = final_text_output[0] if final_text_output and len(final_text_output) > 0 else ""
|
| 552 |
+
yield get_highlighted_text_tuples(x, input_ids, prompt_len, TOKENIZER, MASK_ID, raw_prompt_attention_mask), final_text_str
|
| 553 |
+
|
| 554 |
+
|
| 555 |
+
css_styles = """
|
| 556 |
+
.gradio-container{font-family:'IBM Plex Sans',sans-serif;margin:auto;}
|
| 557 |
+
.gr-input {background:#f9f9f9 !important;border:1px solid #e0e0e0 !important;}
|
| 558 |
+
.gr-output{background:#f0f0f0 !important;border:1px solid #d0d0d0 !important;}
|
| 559 |
+
|
| 560 |
+
.highlighted-text span{
|
| 561 |
+
padding:2px 4px;border-radius:4px;margin:1px 2px;display:inline-block;line-height:1.6;
|
| 562 |
+
}
|
| 563 |
+
|
| 564 |
+
footer{display:none !important}
|
| 565 |
+
|
| 566 |
+
#live-update-scrollable-box {
|
| 567 |
+
max-height: 800px; /* 您可以根据需要调整这个最大高度,例如 '300px', '50vh' 等 */
|
| 568 |
+
overflow-y: auto !important; /* 当内容超出 max-height 时显示垂直滚动条 */
|
| 569 |
+
display: block; /* 确保元素是块级元素,以便 max-height 生效 */
|
| 570 |
+
|
| 571 |
+
}
|
| 572 |
+
#think_btn {
|
| 573 |
+
background-color: #f3f4f6 !important;
|
| 574 |
+
border: 1px solid #d0d0d0 !important;
|
| 575 |
+
color: #111827 !important;
|
| 576 |
+
font-size: 16px !important;
|
| 577 |
+
font-weight: bold !important;
|
| 578 |
+
}
|
| 579 |
+
#think_btn:hover {
|
| 580 |
+
background-color: #e0e0e0 !important;
|
| 581 |
+
border: 1px solid #c0c0c0 !important;
|
| 582 |
+
color: #222 !important;
|
| 583 |
+
}
|
| 584 |
+
#think_btn:active {
|
| 585 |
+
background-color: #2563eb !important;
|
| 586 |
+
border: 1px solid #b0b0b0 !important;
|
| 587 |
+
color: white !important;
|
| 588 |
+
}
|
| 589 |
+
"""
|
| 590 |
+
|
| 591 |
+
|
| 592 |
+
# thinking_mode_t2i = gr.State(False)
|
| 593 |
+
def toggle_thinking_mode_lm(current_thinking_mode):
|
| 594 |
+
# print(f"current_thinking_mode: {current_thinking_mode}")
|
| 595 |
+
new_state = not current_thinking_mode
|
| 596 |
+
new_label = "Thinking Mode ✅" if new_state else "Thinking Mode ❌"
|
| 597 |
+
return new_state, gr.update(value=new_label)
|
| 598 |
+
|
| 599 |
+
def toggle_thinking_mode_mmu(current_thinking_mode):
|
| 600 |
+
new_state = not current_thinking_mode
|
| 601 |
+
new_label = "Thinking Mode ✅" if new_state else "Thinking Mode ❌"
|
| 602 |
+
return new_state, gr.update(value=new_label)
|
| 603 |
+
|
| 604 |
+
|
| 605 |
+
color_map_config = {
|
| 606 |
+
"MASK": "lightgrey",
|
| 607 |
+
"GEN": "#DCABFA",
|
| 608 |
+
}
|
| 609 |
+
|
| 610 |
+
theme = gr.themes.Ocean(
|
| 611 |
+
primary_hue="fuchsia",
|
| 612 |
+
)
|
| 613 |
+
with gr.Blocks(css=css_styles, theme=theme) as demo:
|
| 614 |
+
# with gr.Blocks(css=css_styles, theme=gr.themes.Soft(primary_hue=gr.themes.colors.blue, secondary_hue=gr.themes.colors.sky)) as demo:
|
| 615 |
+
# with gr.Blocks() as demo:
|
| 616 |
+
thinking_mode_lm = gr.State(False)
|
| 617 |
+
thinking_mode_mmu = gr.State(False)
|
| 618 |
+
gr.Markdown("<h1 style='text-align: center; margin-bottom: 20px;'>MMaDA: Multimodal Large Diffusion Language Models</h1>")
|
| 619 |
+
gr.Markdown("MMaDA is a novel class of multimodal diffusion foundation models designed to achieve superior performance across diverse domains such as textual reasoning, multimodal understanding, and text-to-image generation")
|
| 620 |
+
gr.Markdown("Github: [Gen-Verse/MMaDA](https://github.com/Gen-Verse/MMaDA)")
|
| 621 |
+
gr.Markdown("Paper: [MMaDA: Multimodal Large Diffusion Language Models]()")
|
| 622 |
+
gr.Markdown("### Select Model")
|
| 623 |
+
with gr.Row():
|
| 624 |
+
model_select_radio = gr.Radio(
|
| 625 |
+
label="Select Text Generation Model",
|
| 626 |
+
choices=MODEL_CHOICES,
|
| 627 |
+
value=MODEL_CHOICES[0]
|
| 628 |
+
)
|
| 629 |
+
model_load_status_box = gr.Textbox(
|
| 630 |
+
label="Model Load Status",
|
| 631 |
+
interactive=False,
|
| 632 |
+
lines=3,
|
| 633 |
+
max_lines=5
|
| 634 |
+
)
|
| 635 |
+
|
| 636 |
+
gr.Markdown("## Part 1. Text Generation")
|
| 637 |
+
with gr.Row():
|
| 638 |
+
with gr.Column(scale=2):
|
| 639 |
+
prompt_input_box_lm = gr.Textbox(label="Enter your prompt:", lines=3, value="A rectangular prism has a length of 5 units, a width of 4 units, and a height of 3 units. What is the volume of the prism?")
|
| 640 |
+
think_button_lm = gr.Button("🧠 Enable Thinking Mode", elem_id="think_btn")
|
| 641 |
+
with gr.Accordion("Generation Parameters", open=True):
|
| 642 |
+
with gr.Row():
|
| 643 |
+
gen_length_slider_lm = gr.Slider(minimum=8, maximum=1024, value=512, step=64, label="Generation Length", info="Number of tokens to generate.")
|
| 644 |
+
steps_slider_lm = gr.Slider(minimum=1, maximum=512, value=256, step=32, label="Total Sampling Steps", info="Must be divisible by (gen_length / block_length).")
|
| 645 |
+
with gr.Row():
|
| 646 |
+
block_length_slider_lm = gr.Slider(minimum=8, maximum=1024, value=128, step=32, label="Block Length", info="gen_length must be divisible by this.")
|
| 647 |
+
remasking_dropdown_lm = gr.Dropdown(choices=['low_confidence', 'random'], value='low_confidence', label="Remasking Strategy")
|
| 648 |
+
with gr.Row():
|
| 649 |
+
cfg_scale_slider_lm = gr.Slider(minimum=0.0, maximum=2.0, value=0.0, step=0.1, label="CFG Scale", info="Classifier-Free Guidance. 0 disables it.")
|
| 650 |
+
temperature_slider_lm = gr.Slider(minimum=0.0, maximum=2.0, value=1, step=0.05, label="Temperature", info="Controls randomness via Gumbel noise. 0 is deterministic.")
|
| 651 |
+
|
| 652 |
+
|
| 653 |
+
with gr.Row():
|
| 654 |
+
run_button_ui_lm = gr.Button("Generate Sequence", variant="primary", scale=3)
|
| 655 |
+
clear_button_ui_lm = gr.Button("Clear Outputs", scale=1)
|
| 656 |
+
|
| 657 |
+
with gr.Column(scale=3):
|
| 658 |
+
# gr.Markdown("## Live Generation Process")
|
| 659 |
+
output_visualization_box_lm = gr.HighlightedText(
|
| 660 |
+
label="Live Generation Process",
|
| 661 |
+
show_legend=True,
|
| 662 |
+
color_map=color_map_config,
|
| 663 |
+
combine_adjacent=False,
|
| 664 |
+
interactive=False,
|
| 665 |
+
elem_id="live-update-scrollable-box",
|
| 666 |
+
)
|
| 667 |
+
# gr.Markdown("## Final Generated Text")
|
| 668 |
+
output_final_text_box_lm = gr.Textbox(label="Final Output", lines=8, interactive=False, show_copy_button=True)
|
| 669 |
+
|
| 670 |
+
|
| 671 |
+
|
| 672 |
+
gr.Examples(
|
| 673 |
+
examples=[
|
| 674 |
+
["A rectangular prism has a length of 5 units, a width of 4 units, and a height of 3 units. What is the volume of the prism?", 256, 512, 128, 1, 0, "low_confidence"],
|
| 675 |
+
["Lily can run 12 kilometers per hour for 4 hours. After that, she can run 6 kilometers per hour. How many kilometers can she run in 8 hours?", 256, 512, 64, 1, 0, "low_confidence"]
|
| 676 |
+
],
|
| 677 |
+
inputs=[prompt_input_box_lm, steps_slider_lm, gen_length_slider_lm, block_length_slider_lm, temperature_slider_lm, cfg_scale_slider_lm, remasking_dropdown_lm],
|
| 678 |
+
outputs=[output_visualization_box_lm, output_final_text_box_lm],
|
| 679 |
+
fn=generate_viz_wrapper_lm,
|
| 680 |
+
)
|
| 681 |
+
|
| 682 |
+
gr.Markdown("---")
|
| 683 |
+
gr.Markdown("## Part 2. Multimodal Understanding")
|
| 684 |
+
with gr.Row():
|
| 685 |
+
with gr.Column(scale=2):
|
| 686 |
+
prompt_input_box_mmu = gr.Textbox(
|
| 687 |
+
label="Enter your prompt:",
|
| 688 |
+
lines=3,
|
| 689 |
+
value="Please describe this image in detail."
|
| 690 |
+
)
|
| 691 |
+
think_button_mmu = gr.Button("🧠 Enable Thinking Mode", elem_id="think_btn")
|
| 692 |
+
with gr.Accordion("Generation Parameters", open=True):
|
| 693 |
+
with gr.Row():
|
| 694 |
+
gen_length_slider_mmu = gr.Slider(minimum=64, maximum=1024, value=512, step=64, label="Generation Length", info="Number of tokens to generate.")
|
| 695 |
+
steps_slider_mmu = gr.Slider(minimum=1, maximum=512, value=256, step=32, label="Total Sampling Steps", info="Must be divisible by (gen_length / block_length).")
|
| 696 |
+
with gr.Row():
|
| 697 |
+
block_length_slider_mmu = gr.Slider(minimum=32, maximum=1024, value=128, step=32, label="Block Length", info="gen_length must be divisible by this.")
|
| 698 |
+
remasking_dropdown_mmu = gr.Dropdown(choices=['low_confidence', 'random'], value='low_confidence', label="Remasking Strategy")
|
| 699 |
+
with gr.Row():
|
| 700 |
+
cfg_scale_slider_mmu = gr.Slider(minimum=0.0, maximum=2.0, value=0.0, step=0.1, label="CFG Scale", info="Classifier-Free Guidance. 0 disables it.")
|
| 701 |
+
temperature_slider_mmu = gr.Slider(minimum=0.0, maximum=2.0, value=1, step=0.05, label="Temperature", info="Controls randomness via Gumbel noise. 0 is deterministic.")
|
| 702 |
+
|
| 703 |
+
with gr.Row():
|
| 704 |
+
image_upload_box = gr.Image(type="pil", label="Upload Image")
|
| 705 |
+
|
| 706 |
+
with gr.Row():
|
| 707 |
+
run_button_ui_mmu = gr.Button("Generate Description", variant="primary", scale=3)
|
| 708 |
+
clear_button_ui_mmu = gr.Button("Clear Outputs", scale=1)
|
| 709 |
+
|
| 710 |
+
with gr.Column(scale=3):
|
| 711 |
+
gr.Markdown("## Live Generation Process")
|
| 712 |
+
output_visualization_box_mmu = gr.HighlightedText(
|
| 713 |
+
label="Token Sequence (Live Update)",
|
| 714 |
+
show_legend=True,
|
| 715 |
+
color_map=color_map_config,
|
| 716 |
+
combine_adjacent=False,
|
| 717 |
+
interactive=False,
|
| 718 |
+
elem_id="live-update-scrollable-box",
|
| 719 |
+
)
|
| 720 |
+
gr.Markdown("## Final Generated Text")
|
| 721 |
+
output_final_text_box_mmu = gr.Textbox(label="Final Output", lines=8, interactive=False, show_copy_button=True)
|
| 722 |
+
|
| 723 |
+
|
| 724 |
+
gr.Examples(
|
| 725 |
+
examples=[
|
| 726 |
+
[
|
| 727 |
+
"mmu_validation_2/sunflower.jpg",
|
| 728 |
+
"Please describe this image in detail.",
|
| 729 |
+
256,
|
| 730 |
+
512,
|
| 731 |
+
128,
|
| 732 |
+
1,
|
| 733 |
+
0,
|
| 734 |
+
"low_confidence"
|
| 735 |
+
],
|
| 736 |
+
[
|
| 737 |
+
"mmu_validation_2/woman.jpg",
|
| 738 |
+
"Please describe this image in detail.",
|
| 739 |
+
256,
|
| 740 |
+
512,
|
| 741 |
+
128,
|
| 742 |
+
1,
|
| 743 |
+
0,
|
| 744 |
+
"low_confidence"
|
| 745 |
+
]
|
| 746 |
+
],
|
| 747 |
+
inputs=[
|
| 748 |
+
image_upload_box,
|
| 749 |
+
prompt_input_box_mmu,
|
| 750 |
+
steps_slider_mmu,
|
| 751 |
+
gen_length_slider_mmu,
|
| 752 |
+
block_length_slider_mmu,
|
| 753 |
+
temperature_slider_mmu,
|
| 754 |
+
cfg_scale_slider_mmu,
|
| 755 |
+
remasking_dropdown_mmu
|
| 756 |
+
],
|
| 757 |
+
outputs=[output_visualization_box_mmu, output_final_text_box_mmu],
|
| 758 |
+
fn=generate_viz_wrapper,
|
| 759 |
+
)
|
| 760 |
+
|
| 761 |
+
gr.Markdown("---")
|
| 762 |
+
gr.Markdown("## Part 3. Text-to-Image Generation")
|
| 763 |
+
with gr.Row():
|
| 764 |
+
with gr.Column(scale=2):
|
| 765 |
+
prompt_input_box_t2i = gr.Textbox(label="Enter your prompt:", lines=3, value="A sea turtle swimming near a coral reef in the ocean, with a clear blue sky and water in the background.")
|
| 766 |
+
|
| 767 |
+
with gr.Accordion("Generation Parameters", open=True):
|
| 768 |
+
with gr.Row():
|
| 769 |
+
steps_slider_t2i = gr.Slider(minimum=5, maximum=100, value=15, step=5, label="Total Sampling Steps", info="Must be divisible by (gen_length / block_length).")
|
| 770 |
+
guidance_scale_slider_t2i = gr.Slider(minimum=0.0, maximum=7.0, value=3.5, step=0.5, label="Guidance Scale", info="Classifier-Free Guidance. 0 disables it.")
|
| 771 |
+
|
| 772 |
+
|
| 773 |
+
with gr.Row():
|
| 774 |
+
scheduler_radio_t2i = gr.Radio(
|
| 775 |
+
choices=["cosine", "sigmoid", "linear"],
|
| 776 |
+
value="cosine",
|
| 777 |
+
label="Scheduler",
|
| 778 |
+
)
|
| 779 |
+
|
| 780 |
+
with gr.Row():
|
| 781 |
+
run_button_ui_t2i = gr.Button("Generate Image", variant="primary", scale=3)
|
| 782 |
+
clear_button_ui_t2i = gr.Button("Clear Outputs", scale=1)
|
| 783 |
+
|
| 784 |
+
|
| 785 |
+
with gr.Column(scale=3):
|
| 786 |
+
# gr.Markdown("## Live Generation Process")
|
| 787 |
+
output_image_t2i = gr.Image(label="Generated Image", interactive=False, type="pil")
|
| 788 |
+
output_status_t2i = gr.Textbox(label="Generation Status", interactive=False)
|
| 789 |
+
|
| 790 |
+
gr.Examples(
|
| 791 |
+
examples=[
|
| 792 |
+
["A sea turtle swimming near a coral reef in the ocean, with a clear blue sky and water in the background.", 15, 3.5, "cosine"],
|
| 793 |
+
["A beautiful sunset over a calm ocean, with a few clouds in the sky.", 15, 3.5, "cosine"]
|
| 794 |
+
],
|
| 795 |
+
inputs=[prompt_input_box_t2i, steps_slider_t2i, guidance_scale_slider_t2i, scheduler_radio_t2i],
|
| 796 |
+
outputs=[output_image_t2i, output_status_t2i],
|
| 797 |
+
fn=generate_viz_wrapper_t2i,
|
| 798 |
+
)
|
| 799 |
+
|
| 800 |
+
run_button_ui_t2i.click(
|
| 801 |
+
fn=generate_viz_wrapper_t2i,
|
| 802 |
+
inputs=[
|
| 803 |
+
prompt_input_box_t2i,
|
| 804 |
+
steps_slider_t2i,
|
| 805 |
+
guidance_scale_slider_t2i,
|
| 806 |
+
scheduler_radio_t2i
|
| 807 |
+
],
|
| 808 |
+
outputs=[output_image_t2i, output_status_t2i]
|
| 809 |
+
)
|
| 810 |
+
|
| 811 |
+
clear_button_ui_t2i.click(
|
| 812 |
+
fn=lambda: (None, ""),
|
| 813 |
+
inputs=None,
|
| 814 |
+
outputs=[output_image_t2i, output_status_t2i],
|
| 815 |
+
queue=False
|
| 816 |
+
)
|
| 817 |
+
|
| 818 |
+
think_button_lm.click(
|
| 819 |
+
fn=toggle_thinking_mode_lm,
|
| 820 |
+
inputs=[thinking_mode_lm],
|
| 821 |
+
outputs=[thinking_mode_lm, think_button_lm]
|
| 822 |
+
)
|
| 823 |
+
|
| 824 |
+
think_button_mmu.click(
|
| 825 |
+
fn=toggle_thinking_mode_mmu,
|
| 826 |
+
inputs=[thinking_mode_mmu],
|
| 827 |
+
outputs=[thinking_mode_mmu, think_button_mmu]
|
| 828 |
+
)
|
| 829 |
+
|
| 830 |
+
|
| 831 |
+
|
| 832 |
+
def initialize_default_model():
|
| 833 |
+
default_model = "MMaDA-8B-Base"
|
| 834 |
+
result = handle_model_selection_change(default_model)
|
| 835 |
+
return default_model, result
|
| 836 |
+
|
| 837 |
+
demo.load(
|
| 838 |
+
fn=initialize_default_model,
|
| 839 |
+
inputs=None,
|
| 840 |
+
outputs=[model_select_radio, model_load_status_box],
|
| 841 |
+
queue=True
|
| 842 |
+
)
|
| 843 |
+
|
| 844 |
+
def clear_outputs():
|
| 845 |
+
return None, None, None # Clear image, visualization, and final text
|
| 846 |
+
|
| 847 |
+
clear_button_ui_lm.click(
|
| 848 |
+
fn=clear_outputs,
|
| 849 |
+
inputs=None,
|
| 850 |
+
outputs=[image_upload_box, output_visualization_box_lm, output_final_text_box_lm],
|
| 851 |
+
queue=False
|
| 852 |
+
)
|
| 853 |
+
clear_button_ui_mmu.click(
|
| 854 |
+
fn=clear_outputs,
|
| 855 |
+
inputs=None,
|
| 856 |
+
outputs=[image_upload_box, output_visualization_box_mmu, output_final_text_box_mmu],
|
| 857 |
+
queue=False
|
| 858 |
+
)
|
| 859 |
+
|
| 860 |
+
run_button_ui_lm.click(
|
| 861 |
+
fn=generate_viz_wrapper_lm,
|
| 862 |
+
inputs=[
|
| 863 |
+
prompt_input_box_lm,
|
| 864 |
+
steps_slider_lm,
|
| 865 |
+
gen_length_slider_lm,
|
| 866 |
+
block_length_slider_lm,
|
| 867 |
+
temperature_slider_lm,
|
| 868 |
+
cfg_scale_slider_lm,
|
| 869 |
+
remasking_dropdown_lm,
|
| 870 |
+
thinking_mode_lm
|
| 871 |
+
],
|
| 872 |
+
outputs=[output_visualization_box_lm, output_final_text_box_lm]
|
| 873 |
+
)
|
| 874 |
+
|
| 875 |
+
run_button_ui_mmu.click(
|
| 876 |
+
fn=generate_viz_wrapper,
|
| 877 |
+
inputs=[
|
| 878 |
+
image_upload_box,
|
| 879 |
+
prompt_input_box_mmu,
|
| 880 |
+
steps_slider_mmu,
|
| 881 |
+
gen_length_slider_mmu,
|
| 882 |
+
block_length_slider_mmu,
|
| 883 |
+
temperature_slider_mmu,
|
| 884 |
+
cfg_scale_slider_mmu,
|
| 885 |
+
remasking_dropdown_mmu,
|
| 886 |
+
thinking_mode_mmu
|
| 887 |
+
],
|
| 888 |
+
outputs=[output_visualization_box_mmu, output_final_text_box_mmu]
|
| 889 |
+
)
|
| 890 |
+
|
| 891 |
+
|
| 892 |
+
if __name__ == "__main__":
|
| 893 |
+
print(f"Starting Gradio App. Attempting to use device: {DEVICE}")
|
| 894 |
+
demo.launch(share=True)
|
assets/WX-mmada-2.jpeg
ADDED

|
Git LFS Details
|
assets/WX-mmada-3.jpeg
ADDED

|
Git LFS Details
|
assets/WX-mmada.jpeg
ADDED

|
Git LFS Details
|
assets/example_compare.png
ADDED

|
Git LFS Details
|
assets/llm.png
ADDED

|
assets/mmu.png
ADDED
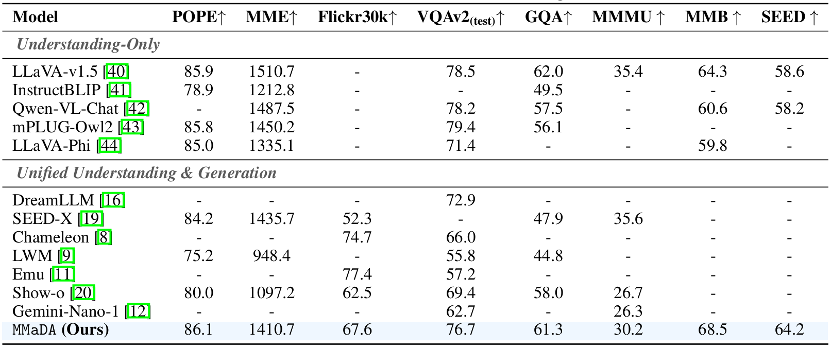
|
assets/pipeline.png
ADDED

|
Git LFS Details
|
assets/random.png
ADDED
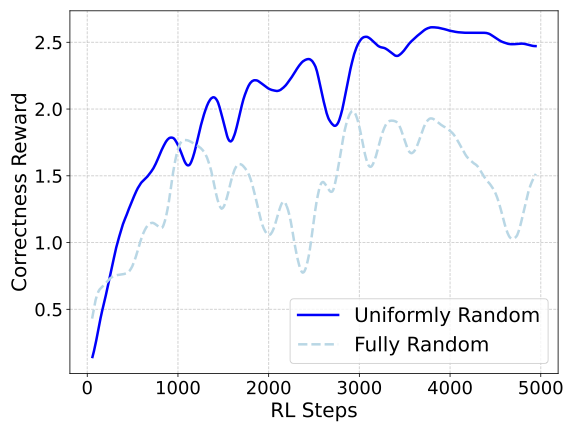
|
assets/reward_trend.png
ADDED

|
assets/showcase0.8.gif
ADDED

|
Git LFS Details
|
assets/t2i.png
ADDED

|
assets/title.png
ADDED

|
Git LFS Details
|
assets/wx-mmada-0613.jpeg
ADDED

|
Git LFS Details
|
configs/mmada_demo.yaml
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
wandb:
|
| 2 |
+
entity: null
|
| 3 |
+
# run_id: askkz9i2
|
| 4 |
+
resume: 'auto'
|
| 5 |
+
|
| 6 |
+
experiment:
|
| 7 |
+
project: "demo"
|
| 8 |
+
name: "mmada-demo"
|
| 9 |
+
output_dir: "mmada-demo"
|
| 10 |
+
|
| 11 |
+
model:
|
| 12 |
+
vq_model:
|
| 13 |
+
type: "magvitv2"
|
| 14 |
+
vq_model_name: "showlab/magvitv2"
|
| 15 |
+
|
| 16 |
+
mmada:
|
| 17 |
+
pretrained_model_path: "Gen-Verse/MMaDA-8B-Base"
|
| 18 |
+
w_clip_vit: False
|
| 19 |
+
new_vocab_size: 134656
|
| 20 |
+
llm_vocab_size: 126464
|
| 21 |
+
codebook_size: 8192
|
| 22 |
+
num_vq_tokens: 1024
|
| 23 |
+
num_new_special_tokens: 0
|
| 24 |
+
tie_word_embeddings: False
|
| 25 |
+
|
| 26 |
+
gradient_checkpointing: True
|
| 27 |
+
|
| 28 |
+
dataset:
|
| 29 |
+
gen_type: "imagenet1k"
|
| 30 |
+
und_type: "captioning"
|
| 31 |
+
combined_loader_mode: "max_size_cycle"
|
| 32 |
+
params:
|
| 33 |
+
train_t2i_shards_path_or_url: "/data_storage/shared/datasets/imagenet-1k/data/train"
|
| 34 |
+
train_mmu_shards_path_or_url: [ "/data_storage/shared/datasets/SA-1B/sa_{000000..000999}.tar",
|
| 35 |
+
"/data_storage/shared/datasets/cc12m/raw/raw/{0000..0999}.tar",
|
| 36 |
+
"/data_storage/shared/datasets/laion-aesthetics-12m/{00000..01209}.tar"
|
| 37 |
+
]
|
| 38 |
+
train_lm_shards_path_or_url: "/data_storage/shared/datasets/falcon-refinedweb/data/data/*.parquet"
|
| 39 |
+
add_caption_prompt: True
|
| 40 |
+
external_caption_path: "/data_storage/shared/datasets/SAM-LLaVA-Captions10M"
|
| 41 |
+
external_journeydb_caption_path: "/data_storage/shared/datasets/journeydb_anno/train_journeydb_anno.json"
|
| 42 |
+
external_laion12m_caption_path: "/data_storage/shared/datasets/laion-aesthetic-12m-captions"
|
| 43 |
+
external_cc12m_caption_path: "/data_storage/shared/datasets/cc12m/captions"
|
| 44 |
+
validation_prompts_file: "validation_prompts/imagenet_prompts.txt"
|
| 45 |
+
shuffle_buffer_size: 1000
|
| 46 |
+
num_workers: 32
|
| 47 |
+
resolution: 512
|
| 48 |
+
pin_memory: True
|
| 49 |
+
persistent_workers: True
|
| 50 |
+
|
| 51 |
+
preprocessing:
|
| 52 |
+
max_seq_length: 512 # for text tokens
|
| 53 |
+
resolution: 512
|
| 54 |
+
center_crop: False
|
| 55 |
+
random_flip: False
|
| 56 |
+
|
| 57 |
+
optimizer:
|
| 58 |
+
name: adamw
|
| 59 |
+
params: # default adamw params
|
| 60 |
+
learning_rate: 5e-5
|
| 61 |
+
scale_lr: False # scale learning rate by total batch size
|
| 62 |
+
beta1: 0.9
|
| 63 |
+
beta2: 0.999
|
| 64 |
+
weight_decay: 0.01
|
| 65 |
+
epsilon: 1e-8
|
| 66 |
+
|
| 67 |
+
lr_scheduler:
|
| 68 |
+
scheduler: "cosine"
|
| 69 |
+
params:
|
| 70 |
+
learning_rate: ${optimizer.params.learning_rate}
|
| 71 |
+
warmup_steps: 8000
|
| 72 |
+
|
| 73 |
+
training:
|
| 74 |
+
gradient_accumulation_steps: 4
|
| 75 |
+
noise_type: "mask"
|
| 76 |
+
batch_size_t2i: 5
|
| 77 |
+
batch_size_lm: 1
|
| 78 |
+
batch_size_mmu: 2
|
| 79 |
+
mixed_precision: "bf16"
|
| 80 |
+
enable_tf32: True
|
| 81 |
+
seed: 10086
|
| 82 |
+
max_train_steps: 500000
|
| 83 |
+
overfit_one_batch: False
|
| 84 |
+
cond_dropout_prob: 0.1
|
| 85 |
+
min_masking_rate: 0.0
|
| 86 |
+
label_smoothing: 0.0
|
| 87 |
+
max_grad_norm: 1
|
| 88 |
+
guidance_scale: 1.5
|
| 89 |
+
generation_timesteps: 12
|
| 90 |
+
t2i_coeff: 1.0
|
| 91 |
+
lm_coeff: 0.1
|
| 92 |
+
mmu_coeff: 1.0
|
| 93 |
+
|
| 94 |
+
mask_schedule:
|
| 95 |
+
schedule: "cosine"
|
configs/mmada_pretraining_stage1_llada_instruct.yaml
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
wandb:
|
| 2 |
+
entity: null
|
| 3 |
+
# run_id: askkz9i2
|
| 4 |
+
resume: 'auto'
|
| 5 |
+
|
| 6 |
+
experiment:
|
| 7 |
+
project: "mmada-training-stage1"
|
| 8 |
+
name: "mmada-training-stage1-llada-instruct"
|
| 9 |
+
output_dir: "mmada-training-stage1-llada-instruct"
|
| 10 |
+
max_train_examples_t2i: 40000000
|
| 11 |
+
max_train_examples_mmu: 40000000
|
| 12 |
+
save_every: 10000
|
| 13 |
+
eval_every: 2500
|
| 14 |
+
generate_every: 1000
|
| 15 |
+
log_every: 50
|
| 16 |
+
log_grad_norm_every: 100
|
| 17 |
+
resume_from_checkpoint: "latest"
|
| 18 |
+
|
| 19 |
+
model:
|
| 20 |
+
vq_model:
|
| 21 |
+
type: "magvitv2"
|
| 22 |
+
vq_model_name: "showlab/magvitv2"
|
| 23 |
+
mmada:
|
| 24 |
+
pretrained_model_path: "GSAI-ML/LLaDA-8B-Instruct"
|
| 25 |
+
w_clip_vit: False
|
| 26 |
+
new_vocab_size: 134656
|
| 27 |
+
llm_vocab_size: 126464
|
| 28 |
+
codebook_size: 8192
|
| 29 |
+
num_vq_tokens: 256
|
| 30 |
+
num_new_special_tokens: 0
|
| 31 |
+
tie_word_embeddings: False
|
| 32 |
+
|
| 33 |
+
gradient_checkpointing: True
|
| 34 |
+
|
| 35 |
+
dataset:
|
| 36 |
+
gen_type: "imagenet1k"
|
| 37 |
+
und_type: "captioning"
|
| 38 |
+
combined_loader_mode: "max_size_cycle"
|
| 39 |
+
params:
|
| 40 |
+
train_t2i_shards_path_or_url: "/data_storage/shared/datasets/imagenet-1k/data/train"
|
| 41 |
+
train_mmu_shards_path_or_url: [ "/data_storage/shared/datasets/SA-1B/sa_{000000..000999}.tar",
|
| 42 |
+
"/data_storage/shared/datasets/cc12m/raw/raw/{0000..0999}.tar",
|
| 43 |
+
"/data_storage/shared/datasets/laion-aesthetics-12m/{00000..00999}.tar"
|
| 44 |
+
]
|
| 45 |
+
train_lm_shards_path_or_url: "/data_storage/shared/datasets/falcon-refinedweb/data/data/*.parquet"
|
| 46 |
+
add_caption_prompt: True
|
| 47 |
+
external_caption_path: "/data_storage/shared/datasets/SAM-LLaVA-Captions10M"
|
| 48 |
+
external_journeydb_caption_path: "/data_storage/shared/datasets/journeydb_anno/train_journeydb_anno.json"
|
| 49 |
+
external_laion12m_caption_path: "/data_storage/shared/datasets/laion-aesthetic-12m-captions"
|
| 50 |
+
external_cc12m_caption_path: "/data_storage/shared/datasets/cc12m/captions"
|
| 51 |
+
validation_prompts_file: "validation_prompts/imagenet_prompts.txt"
|
| 52 |
+
mmu_image_root: "/data_storage/ty/MMaDA/mmu_validation"
|
| 53 |
+
shuffle_buffer_size: 1000
|
| 54 |
+
num_workers: 32
|
| 55 |
+
resolution: 256
|
| 56 |
+
pin_memory: True
|
| 57 |
+
persistent_workers: True
|
| 58 |
+
|
| 59 |
+
preprocessing:
|
| 60 |
+
max_seq_length: 128 # for text tokens
|
| 61 |
+
resolution: 256
|
| 62 |
+
center_crop: False
|
| 63 |
+
random_flip: False
|
| 64 |
+
|
| 65 |
+
optimizer:
|
| 66 |
+
name: adamw
|
| 67 |
+
params: # default adamw params
|
| 68 |
+
learning_rate: 1e-4
|
| 69 |
+
scale_lr: False # scale learning rate by total batch size
|
| 70 |
+
beta1: 0.9
|
| 71 |
+
beta2: 0.999
|
| 72 |
+
weight_decay: 0.01
|
| 73 |
+
epsilon: 1e-8
|
| 74 |
+
|
| 75 |
+
lr_scheduler:
|
| 76 |
+
scheduler: "cosine"
|
| 77 |
+
params:
|
| 78 |
+
learning_rate: ${optimizer.params.learning_rate}
|
| 79 |
+
warmup_steps: 5000
|
| 80 |
+
|
| 81 |
+
training:
|
| 82 |
+
gradient_accumulation_steps: 2
|
| 83 |
+
noise_type: "mask"
|
| 84 |
+
batch_size_t2i: 7
|
| 85 |
+
batch_size_lm: 2
|
| 86 |
+
batch_size_mmu: 6
|
| 87 |
+
mixed_precision: "bf16"
|
| 88 |
+
enable_tf32: True
|
| 89 |
+
seed: 10086
|
| 90 |
+
max_train_steps: 500000
|
| 91 |
+
overfit_one_batch: False
|
| 92 |
+
cond_dropout_prob: 0.1
|
| 93 |
+
min_masking_rate: 0.0
|
| 94 |
+
label_smoothing: 0.0
|
| 95 |
+
max_grad_norm: 1
|
| 96 |
+
guidance_scale: 1.5
|
| 97 |
+
generation_timesteps: 12
|
| 98 |
+
t2i_coeff: 1.0
|
| 99 |
+
lm_coeff: 0.1
|
| 100 |
+
mmu_coeff: 1.0
|
configs/mmada_pretraining_stage2_llada_instruct.yaml
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
wandb:
|
| 2 |
+
entity: null
|
| 3 |
+
# run_id: askkz9i2
|
| 4 |
+
resume: 'auto'
|
| 5 |
+
|
| 6 |
+
experiment:
|
| 7 |
+
project: "mmada-training-stage2"
|
| 8 |
+
name: "mmada-training-stage2-llada-instruct"
|
| 9 |
+
output_dir: "mmada-training-stage2-llada-instruct"
|
| 10 |
+
max_train_examples_t2i: 40000000
|
| 11 |
+
max_train_examples_mmu: 40000000
|
| 12 |
+
save_every: 10000
|
| 13 |
+
eval_every: 2500
|
| 14 |
+
generate_every: 1000
|
| 15 |
+
log_every: 50
|
| 16 |
+
log_grad_norm_every: 100
|
| 17 |
+
resume_from_checkpoint: "latest"
|
| 18 |
+
val_every: 50
|
| 19 |
+
max_val_examples_t2i: 2000
|
| 20 |
+
|
| 21 |
+
model:
|
| 22 |
+
vq_model:
|
| 23 |
+
type: "magvitv2"
|
| 24 |
+
vq_model_name: "showlab/magvitv2"
|
| 25 |
+
|
| 26 |
+
mmada:
|
| 27 |
+
tokenizer_path: "GSAI-ML/LLaDA-8B-Instruct"
|
| 28 |
+
pretrained_model_path: "path/to/your/checkpoint"
|
| 29 |
+
w_clip_vit: False
|
| 30 |
+
new_vocab_size: 134656
|
| 31 |
+
llm_vocab_size: 126464
|
| 32 |
+
codebook_size: 8192
|
| 33 |
+
num_vq_tokens: 256
|
| 34 |
+
num_new_special_tokens: 0
|
| 35 |
+
tie_word_embeddings: False
|
| 36 |
+
|
| 37 |
+
gradient_checkpointing: True
|
| 38 |
+
|
| 39 |
+
dataset:
|
| 40 |
+
gen_type: "t2i"
|
| 41 |
+
und_type: "captioning"
|
| 42 |
+
combined_loader_mode: "max_size_cycle"
|
| 43 |
+
params:
|
| 44 |
+
train_t2i_shards_path_or_url: [ "/data_storage/shared/datasets/SA-1B/sa_{000000..000999}.tar",
|
| 45 |
+
"/data_storage/shared/datasets/cc12m/raw/raw/{0000..0999}.tar",
|
| 46 |
+
"/data_storage/shared/datasets/laion-aesthetics-12m/{00000..00999}.tar"
|
| 47 |
+
]
|
| 48 |
+
train_mmu_shards_path_or_url: [ "/data_storage/shared/datasets/SA-1B/sa_{000000..000999}.tar",
|
| 49 |
+
"/data_storage/shared/datasets/cc12m/raw/raw/{0000..0999}.tar",
|
| 50 |
+
"/data_storage/shared/datasets/laion-aesthetics-12m/{00000..00999}.tar"
|
| 51 |
+
]
|
| 52 |
+
train_lm_shards_path_or_url: "/data_storage/shared/datasets/falcon-refinedweb/data/data/*.parquet"
|
| 53 |
+
add_caption_prompt: True
|
| 54 |
+
external_caption_path: "/data_storage/shared/datasets/SAM-LLaVA-Captions10M"
|
| 55 |
+
external_journeydb_caption_path: "/data_storage/shared/datasets/journeydb_anno/train_journeydb_anno.json"
|
| 56 |
+
external_laion12m_caption_path: "/data_storage/ty/datasets/laion-aesthetics-12m-images-2"
|
| 57 |
+
external_cc12m_caption_path: "/data_storage/shared/datasets/cc12m/new_captions"
|
| 58 |
+
validation_prompts_file: "validation_prompts/text2image_prompts.txt"
|
| 59 |
+
mmu_image_root: "/data_storage/ty/MMaDA/mmu_validation"
|
| 60 |
+
shuffle_buffer_size: 1000
|
| 61 |
+
num_workers: 32
|
| 62 |
+
resolution: 256
|
| 63 |
+
pin_memory: True
|
| 64 |
+
persistent_workers: True
|
| 65 |
+
|
| 66 |
+
preprocessing:
|
| 67 |
+
max_seq_length: 256 # for text tokens
|
| 68 |
+
resolution: 256
|
| 69 |
+
center_crop: False
|
| 70 |
+
random_flip: False
|
| 71 |
+
|
| 72 |
+
optimizer:
|
| 73 |
+
name: adamw
|
| 74 |
+
params: # default adamw params
|
| 75 |
+
learning_rate: 5e-5
|
| 76 |
+
scale_lr: False # scale learning rate by total batch size
|
| 77 |
+
beta1: 0.9
|
| 78 |
+
beta2: 0.999
|
| 79 |
+
weight_decay: 0.01
|
| 80 |
+
epsilon: 1e-8
|
| 81 |
+
|
| 82 |
+
lr_scheduler:
|
| 83 |
+
scheduler: "cosine"
|
| 84 |
+
params:
|
| 85 |
+
learning_rate: ${optimizer.params.learning_rate}
|
| 86 |
+
warmup_steps: 5000
|
| 87 |
+
min_lr_scale: 0.1
|
| 88 |
+
|
| 89 |
+
training:
|
| 90 |
+
gradient_accumulation_steps: 2
|
| 91 |
+
noise_type: "mask"
|
| 92 |
+
batch_size_t2i: 7
|
| 93 |
+
batch_size_lm: 2
|
| 94 |
+
batch_size_mmu: 3
|
| 95 |
+
mixed_precision: "bf16"
|
| 96 |
+
enable_tf32: True
|
| 97 |
+
seed: 10086
|
| 98 |
+
max_train_steps: 1000000
|
| 99 |
+
overfit_one_batch: False
|
| 100 |
+
cond_dropout_prob: 0.1
|
| 101 |
+
min_masking_rate: 0.0
|
| 102 |
+
label_smoothing: 0.0
|
| 103 |
+
max_grad_norm: 1
|
| 104 |
+
guidance_scale: 3
|
| 105 |
+
generation_timesteps: 12
|
| 106 |
+
t2i_coeff: 1.0
|
| 107 |
+
lm_coeff: 0.1
|
| 108 |
+
mmu_coeff: 0.5
|
| 109 |
+
validation_seed: 42
|
configs/mmada_pretraining_stage3_llada_instruct.yaml
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
wandb:
|
| 2 |
+
entity: null
|
| 3 |
+
# run_id: askkz9i2
|
| 4 |
+
resume: 'auto'
|
| 5 |
+
|
| 6 |
+
experiment:
|
| 7 |
+
project: "mmada-training-stage3"
|
| 8 |
+
name: "mmada-training-stage3-llada-instruct"
|
| 9 |
+
output_dir: "mmada-training-stage3-llada-instruct"
|
| 10 |
+
max_train_examples_t2i: 40000000 #
|
| 11 |
+
max_train_examples_mmu: 40000000 #
|
| 12 |
+
save_every: 10000
|
| 13 |
+
eval_every: 2500
|
| 14 |
+
generate_every: 1000
|
| 15 |
+
log_every: 50
|
| 16 |
+
log_grad_norm_every: 100
|
| 17 |
+
resume_from_checkpoint: "latest"
|
| 18 |
+
val_every: 50
|
| 19 |
+
max_val_examples_t2i: 2000
|
| 20 |
+
|
| 21 |
+
model:
|
| 22 |
+
vq_model:
|
| 23 |
+
type: "magvitv2"
|
| 24 |
+
vq_model_name: "showlab/magvitv2"
|
| 25 |
+
|
| 26 |
+
mmada:
|
| 27 |
+
tokenizer_path: "GSAI-ML/LLaDA-8B-Instruct"
|
| 28 |
+
pretrained_model_path: "path/to/your/checkpoint"
|
| 29 |
+
w_clip_vit: False
|
| 30 |
+
new_vocab_size: 134656
|
| 31 |
+
llm_vocab_size: 126464
|
| 32 |
+
codebook_size: 8192
|
| 33 |
+
num_vq_tokens: 256
|
| 34 |
+
num_new_special_tokens: 0
|
| 35 |
+
tie_word_embeddings: False
|
| 36 |
+
|
| 37 |
+
gradient_checkpointing: True
|
| 38 |
+
|
| 39 |
+
dataset:
|
| 40 |
+
gen_type: "t2i"
|
| 41 |
+
und_type: "captioning"
|
| 42 |
+
combined_loader_mode: "max_size_cycle"
|
| 43 |
+
params:
|
| 44 |
+
train_t2i_shards_path_or_url: [ #
|
| 45 |
+
"/data_storage/shared/datasets/JourneyDB/train/imgs/data/train/imgs/{000..199}.tgz",
|
| 46 |
+
"/data_storage/shared/datasets/laion-aesthetics-12m/{00000..00999}.tar",
|
| 47 |
+
"/data_storage/shared/datasets/text-to-image-2M/data_512_2M"
|
| 48 |
+
]
|
| 49 |
+
train_mmu_shards_path_or_url: [ "/data_storage/shared/datasets/SA-1B/sa_{000000..000999}.tar", #
|
| 50 |
+
"/data_storage/shared/datasets/cc12m/raw/raw/{0000..0999}.tar",
|
| 51 |
+
"/data_storage/shared/datasets/laion-aesthetics-12m/{00000..00999}.tar"
|
| 52 |
+
]
|
| 53 |
+
train_lm_shards_path_or_url: "/data_storage/ty/shared/datasets/3-instruct-datasets/parquet/*.parquet"
|
| 54 |
+
add_caption_prompt: True
|
| 55 |
+
external_caption_path: "/data_storage/shared/datasets/SAM-LLaVA-Captions10M"
|
| 56 |
+
external_journeydb_caption_path: "/data_storage/shared/datasets/journeydb_anno/train_journeydb_anno.json"
|
| 57 |
+
external_laion12m_caption_path: "/data_storage/ty/datasets/laion-aesthetics-12m-images-2"
|
| 58 |
+
external_cc12m_caption_path: "/data_storage/shared/datasets/cc12m/new_captions"
|
| 59 |
+
external_text_to_image_2M_512_caption_path: "/data_storage/shared/datasets/text-to-image-2M/data_512_2M_captions"
|
| 60 |
+
validation_prompts_file: "validation_prompts/text2image_prompts.txt"
|
| 61 |
+
mmu_image_root: "/data_storage/ty/MMaDA/mmu_validation"
|
| 62 |
+
lm_chat_validation_jsonl: "/data_storage/ty/MMaDA/lm_chat_validation/questions.jsonl"
|
| 63 |
+
shuffle_buffer_size: 1000
|
| 64 |
+
num_workers: 32
|
| 65 |
+
resolution: 512
|
| 66 |
+
pin_memory: True
|
| 67 |
+
persistent_workers: True
|
| 68 |
+
|
| 69 |
+
preprocessing:
|
| 70 |
+
max_seq_length: 512 # for text tokens 512
|
| 71 |
+
resolution: 512
|
| 72 |
+
center_crop: False
|
| 73 |
+
random_flip: False
|
| 74 |
+
|
| 75 |
+
optimizer:
|
| 76 |
+
name: adamw
|
| 77 |
+
params: # default adamw params
|
| 78 |
+
learning_rate: 5e-5
|
| 79 |
+
scale_lr: False # scale learning rate by total batch size
|
| 80 |
+
beta1: 0.9
|
| 81 |
+
beta2: 0.999
|
| 82 |
+
weight_decay: 0.01
|
| 83 |
+
epsilon: 1e-8
|
| 84 |
+
|
| 85 |
+
lr_scheduler:
|
| 86 |
+
scheduler: "cosine"
|
| 87 |
+
params:
|
| 88 |
+
learning_rate: ${optimizer.params.learning_rate}
|
| 89 |
+
warmup_steps: 5000
|
| 90 |
+
min_lr_scale: 0.1
|
| 91 |
+
|
| 92 |
+
training:
|
| 93 |
+
gradient_accumulation_steps: 4 # 4
|
| 94 |
+
noise_type: "mask"
|
| 95 |
+
batch_size_t2i: 4 # 3~4
|
| 96 |
+
batch_size_lm: 1
|
| 97 |
+
batch_size_mmu: 1
|
| 98 |
+
mixed_precision: "bf16"
|
| 99 |
+
enable_tf32: True
|
| 100 |
+
seed: 10086
|
| 101 |
+
max_train_steps: 1000000
|
| 102 |
+
overfit_one_batch: False
|
| 103 |
+
cond_dropout_prob: 0.1
|
| 104 |
+
min_masking_rate: 0.0
|
| 105 |
+
label_smoothing: 0.0
|
| 106 |
+
max_grad_norm: 1
|
| 107 |
+
guidance_scale: 3
|
| 108 |
+
generation_timesteps: 12
|
| 109 |
+
t2i_coeff: 1.0
|
| 110 |
+
lm_coeff: 0.4 # ~0.5
|
| 111 |
+
mmu_coeff: 0.5
|
| 112 |
+
validation_seed: 42
|
configs/mmada_pretraining_stage3_llada_instruct_512_cot.yaml
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
wandb:
|
| 2 |
+
entity: null
|
| 3 |
+
# run_id: askkz9i2
|
| 4 |
+
resume: 'auto'
|
| 5 |
+
|
| 6 |
+
experiment:
|
| 7 |
+
project: "mmada-training-stage3"
|
| 8 |
+
name: "mmada-training-stage3-llada-instruct-512-cot-uni"
|
| 9 |
+
output_dir: "mmada-training-stage3-llada-instruct-512-cot-uni"
|
| 10 |
+
max_train_examples_t2i: 40000000 #
|
| 11 |
+
max_train_examples_mmu: 40000000 #
|
| 12 |
+
save_every: 10000
|
| 13 |
+
eval_every: 2500
|
| 14 |
+
generate_every: 1000
|
| 15 |
+
log_every: 50
|
| 16 |
+
log_grad_norm_every: 100
|
| 17 |
+
# resume_from_checkpoint: False
|
| 18 |
+
resume_from_checkpoint: "latest"
|
| 19 |
+
val_every: 50
|
| 20 |
+
max_val_examples_t2i: 2000
|
| 21 |
+
|
| 22 |
+
model:
|
| 23 |
+
vq_model:
|
| 24 |
+
type: "magvitv2"
|
| 25 |
+
vq_model_name: "showlab/magvitv2"
|
| 26 |
+
|
| 27 |
+
mmada:
|
| 28 |
+
tokenizer_path: "GSAI-ML/LLaDA-8B-Instruct"
|
| 29 |
+
pretrained_model_path: "path/to/your/checkpoint"
|
| 30 |
+
w_clip_vit: False
|
| 31 |
+
new_vocab_size: 134656
|
| 32 |
+
llm_vocab_size: 126464
|
| 33 |
+
codebook_size: 8192
|
| 34 |
+
num_vq_tokens: 1024
|
| 35 |
+
num_new_special_tokens: 0
|
| 36 |
+
tie_word_embeddings: False
|
| 37 |
+
|
| 38 |
+
gradient_checkpointing: True
|
| 39 |
+
|
| 40 |
+
dataset:
|
| 41 |
+
gen_type: "t2i"
|
| 42 |
+
und_type: "captioning"
|
| 43 |
+
combined_loader_mode: "max_size_cycle"
|
| 44 |
+
params:
|
| 45 |
+
train_t2i_shards_path_or_url: [ "/data_storage/shared/datasets/JourneyDB/train/imgs/data/train/imgs/{000..199}.tgz",
|
| 46 |
+
"/data_storage/shared/datasets/laion-aesthetics-12m-filter/{00000..00999}.tar",
|
| 47 |
+
# "/data_storage/shared/datasets/text-to-image-2M/data_512_2M/data_{000000..000046}.tar"
|
| 48 |
+
]
|
| 49 |
+
train_mmu_shards_path_or_url: [ "/data_storage/shared/datasets/multimodal_cot/ai2d/new_images.tar",
|
| 50 |
+
"/data_storage/shared/datasets/multimodal_cot/clevr/images.tar",
|
| 51 |
+
"/data_storage/shared/datasets/multimodal_cot/docvqa/images.tar",
|
| 52 |
+
"/data_storage/shared/datasets/multimodal_cot/geo/images.tar",
|
| 53 |
+
"/data_storage/shared/datasets/laion-aesthetics-12m/{00000..00999}.tar",
|
| 54 |
+
]
|
| 55 |
+
train_lm_shards_path_or_url: "/data_storage/shared/datasets/3-cot-sft/parquet/*.parquet"
|
| 56 |
+
add_caption_prompt: True
|
| 57 |
+
external_caption_path: "/data_storage/shared/datasets/SAM-LLaVA-Captions10M"
|
| 58 |
+
external_journeydb_caption_path: "/data_storage/shared/datasets/journeydb_anno/train_journeydb_anno.json"
|
| 59 |
+
external_laion12m_caption_path: "/data_storage/ty/datasets/laion-aesthetics-12m-images-2"
|
| 60 |
+
external_cc12m_caption_path: "/data_storage/shared/datasets/cc12m/new_captions"
|
| 61 |
+
external_text_to_image_2M_512_caption_path: "/data_storage/shared/datasets/text-to-image-2M/data_512_2M_captions"
|
| 62 |
+
external_ai2d_caption_path: "/data_storage/shared/datasets/multimodal_cot/ai2d/new_metadata.csv"
|
| 63 |
+
external_clevr_caption_path: "/data_storage/shared/datasets/multimodal_cot/clevr/metadata.csv"
|
| 64 |
+
external_docvqa_caption_path: "/data_storage/shared/datasets/multimodal_cot/docvqa/metadata.csv"
|
| 65 |
+
external_geo_caption_path: "/data_storage/shared/datasets/multimodal_cot/geo/metadata.csv"
|
| 66 |
+
validation_prompts_file: "validation_prompts/text2image_prompts.txt"
|
| 67 |
+
mmu_image_root: "/data_storage/ty/MMaDA/mmu_validation"
|
| 68 |
+
mmu_validation_prompts_file: "/data_storage/ty/MMaDA/mmu_validation/prompts.jsonl"
|
| 69 |
+
lm_chat_validation_jsonl: "/data_storage/ty/MMaDA/lm_chat_validation/questions.jsonl"
|
| 70 |
+
shuffle_buffer_size: 1000
|
| 71 |
+
num_workers: 32
|
| 72 |
+
resolution: 512
|
| 73 |
+
pin_memory: True
|
| 74 |
+
persistent_workers: True
|
| 75 |
+
|
| 76 |
+
preprocessing:
|
| 77 |
+
max_seq_length: 512 # for text tokens in t2i & mmu
|
| 78 |
+
max_lm_text_length: 1536 # for text tokens in lm/lm_chat
|
| 79 |
+
resolution: 512
|
| 80 |
+
center_crop: False
|
| 81 |
+
random_flip: False
|
| 82 |
+
|
| 83 |
+
optimizer:
|
| 84 |
+
name: adamw
|
| 85 |
+
params: # default adamw params
|
| 86 |
+
learning_rate: 5e-5
|
| 87 |
+
scale_lr: False # scale learning rate by total batch size
|
| 88 |
+
beta1: 0.9
|
| 89 |
+
beta2: 0.999
|
| 90 |
+
weight_decay: 0.01
|
| 91 |
+
epsilon: 1e-8
|
| 92 |
+
|
| 93 |
+
lr_scheduler:
|
| 94 |
+
scheduler: "cosine"
|
| 95 |
+
params:
|
| 96 |
+
learning_rate: ${optimizer.params.learning_rate}
|
| 97 |
+
warmup_steps: 5000
|
| 98 |
+
min_lr_scale: 0.1
|
| 99 |
+
|
| 100 |
+
training:
|
| 101 |
+
gradient_accumulation_steps: 4 # 4
|
| 102 |
+
noise_type: "mask"
|
| 103 |
+
batch_size_t2i: 1
|
| 104 |
+
batch_size_lm: 2
|
| 105 |
+
batch_size_mmu: 1
|
| 106 |
+
mixed_precision: "bf16"
|
| 107 |
+
enable_tf32: True
|
| 108 |
+
seed: 10086
|
| 109 |
+
max_train_steps: 1000000
|
| 110 |
+
overfit_one_batch: False
|
| 111 |
+
cond_dropout_prob: 0.1
|
| 112 |
+
min_masking_rate: 0.0
|
| 113 |
+
label_smoothing: 0.0
|
| 114 |
+
max_grad_norm: 1
|
| 115 |
+
guidance_scale: 5
|
| 116 |
+
generation_timesteps: 20
|
| 117 |
+
t2i_coeff: 1.0
|
| 118 |
+
lm_coeff: 0.5
|
| 119 |
+
mmu_coeff: 0.5
|
| 120 |
+
|
| 121 |
+
validation:
|
| 122 |
+
quantative_prompts_file: "/data_storage/ty/MMaDA/validation_prompts/quantative.txt"
|
| 123 |
+
quantative_batch_size: 8
|
configs/mmada_pretraining_stage4_llada_instruct.yaml
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
wandb:
|
| 2 |
+
entity: null
|
| 3 |
+
# run_id: askkz9i2
|
| 4 |
+
resume: 'auto'
|
| 5 |
+
|
| 6 |
+
experiment:
|
| 7 |
+
project: "mmada-training-stage4"
|
| 8 |
+
name: "mmada-training-stage4-llada-instruct"
|
| 9 |
+
output_dir: "mmada-training-stage4-llada-instruct"
|
| 10 |
+
max_train_examples_t2i: 40000000 #
|
| 11 |
+
max_train_examples_mmu: 40000000 #
|
| 12 |
+
save_every: 10000
|
| 13 |
+
eval_every: 2500
|
| 14 |
+
generate_every: 1000
|
| 15 |
+
log_every: 50
|
| 16 |
+
log_grad_norm_every: 100
|
| 17 |
+
resume_from_checkpoint: "latest"
|
| 18 |
+
val_every: 50
|
| 19 |
+
max_val_examples_t2i: 2000
|
| 20 |
+
|
| 21 |
+
model:
|
| 22 |
+
vq_model:
|
| 23 |
+
type: "magvitv2"
|
| 24 |
+
vq_model_name: "showlab/magvitv2"
|
| 25 |
+
|
| 26 |
+
mmada:
|
| 27 |
+
tokenizer_path: "GSAI-ML/LLaDA-8B-Instruct"
|
| 28 |
+
pretrained_model_path: "/data_storage/ty/MMaDA/mmada-training-stage3-llada-instruct-512-cot-uni/checkpoint-210000/unwrapped_model"
|
| 29 |
+
w_clip_vit: False
|
| 30 |
+
new_vocab_size: 134656
|
| 31 |
+
llm_vocab_size: 126464
|
| 32 |
+
codebook_size: 8192
|
| 33 |
+
num_vq_tokens: 1024
|
| 34 |
+
num_new_special_tokens: 0
|
| 35 |
+
tie_word_embeddings: False
|
| 36 |
+
|
| 37 |
+
gradient_checkpointing: True
|
| 38 |
+
|
| 39 |
+
dataset:
|
| 40 |
+
gen_type: "t2i"
|
| 41 |
+
und_type: "captioning"
|
| 42 |
+
combined_loader_mode: "max_size_cycle"
|
| 43 |
+
params:
|
| 44 |
+
train_t2i_shards_path_or_url: [ "/data_storage/shared/datasets/JourneyDB/train/imgs/data/train/imgs/{000..199}.tgz",
|
| 45 |
+
"/data_storage/shared/datasets/laion-aesthetics-12m-filter/{00000..00999}.tar",
|
| 46 |
+
# "/data_storage/shared/datasets/text-to-image-2M/data_512_2M/data_{000000..000046}.tar"
|
| 47 |
+
]
|
| 48 |
+
train_mmu_shards_path_or_url: [ "/data_storage/shared/datasets/multimodal_cot/ai2d/new_images.tar",
|
| 49 |
+
"/data_storage/shared/datasets/multimodal_cot/clevr/images.tar",
|
| 50 |
+
"/data_storage/shared/datasets/multimodal_cot/docvqa/images.tar",
|
| 51 |
+
"/data_storage/shared/datasets/multimodal_cot/geo/images.tar",
|
| 52 |
+
]
|
| 53 |
+
train_lm_shards_path_or_url: "/data_storage/shared/datasets/falcon-refinedweb/data/data/*.parquet"
|
| 54 |
+
train_instruct_shards_path_or_url: "/data_storage/shared/datasets/stage4_instruct/*.parquet"
|
| 55 |
+
add_caption_prompt: True
|
| 56 |
+
external_caption_path: "/data_storage/shared/datasets/SAM-LLaVA-Captions10M"
|
| 57 |
+
external_journeydb_caption_path: "/data_storage/shared/datasets/journeydb_anno/train_journeydb_anno.json"
|
| 58 |
+
external_laion12m_caption_path: "/data_storage/ty/datasets/laion-aesthetics-12m-images-2"
|
| 59 |
+
external_cc12m_caption_path: "/data_storage/shared/datasets/cc12m/new_captions"
|
| 60 |
+
external_text_to_image_2M_512_caption_path: "/data_storage/shared/datasets/text-to-image-2M/data_512_2M_captions"
|
| 61 |
+
external_ai2d_caption_path: "/data_storage/shared/datasets/multimodal_cot/ai2d/new_metadata.csv"
|
| 62 |
+
external_clevr_caption_path: "/data_storage/shared/datasets/multimodal_cot/clevr/metadata.csv"
|
| 63 |
+
external_docvqa_caption_path: "/data_storage/shared/datasets/multimodal_cot/docvqa/metadata.csv"
|
| 64 |
+
external_geo_caption_path: "/data_storage/shared/datasets/multimodal_cot/geo/metadata.csv"
|
| 65 |
+
external_vqa_caption_path: "/data_storage/shared/datasets/LLaVA-Instruct-150K/llava_v1_5_mix665k.json"
|
| 66 |
+
external_clevr2_caption_path: "/data_storage/ty/datasets/Clevr_CoGenT_TrainA_70K_Complex/captions.json"
|
| 67 |
+
external_geo170k_caption_path: "/data_storage/ty/shared/datasets/Geo170K/Geo170K/all.json"
|
| 68 |
+
vqa_images_path: "/data_storage/shared/datasets/LLaVA-Instruct-150K-images"
|
| 69 |
+
clevr2_images_path: "/data_storage/ty/datasets/Clevr_CoGenT_TrainA_70K_Complex/images"
|
| 70 |
+
geo170k_images_path: "/data_storage/ty/shared/datasets/Geo170K/Geo170K/images"
|
| 71 |
+
validation_prompts_file: "validation_prompts/text2image_prompts.txt"
|
| 72 |
+
mmu_image_root: "/data_storage/ty/MMaDA/mmu_validation"
|
| 73 |
+
mmu_validation_prompts_file: "/data_storage/ty/MMaDA/mmu_validation/prompts_with_vqa.json"
|
| 74 |
+
lm_chat_validation_jsonl: "/data_storage/ty/MMaDA/lm_chat_validation/questions.jsonl"
|
| 75 |
+
shuffle_buffer_size: 1000
|
| 76 |
+
num_workers: 16
|
| 77 |
+
resolution: 512
|
| 78 |
+
pin_memory: True
|
| 79 |
+
persistent_workers: True
|
| 80 |
+
|
| 81 |
+
preprocessing:
|
| 82 |
+
max_seq_length: 512 # for text tokens in t2i & mmu
|
| 83 |
+
max_lm_text_length: 1536 # for text tokens in lm/lm_chat
|
| 84 |
+
resolution: 512
|
| 85 |
+
center_crop: False
|
| 86 |
+
random_flip: False
|
| 87 |
+
|
| 88 |
+
optimizer:
|
| 89 |
+
name: adamw
|
| 90 |
+
params: # default adamw params
|
| 91 |
+
learning_rate: 5e-5
|
| 92 |
+
scale_lr: False # scale learning rate by total batch size
|
| 93 |
+
beta1: 0.9
|
| 94 |
+
beta2: 0.999
|
| 95 |
+
weight_decay: 0.01
|
| 96 |
+
epsilon: 1e-8
|
| 97 |
+
|
| 98 |
+
lr_scheduler:
|
| 99 |
+
scheduler: "cosine"
|
| 100 |
+
params:
|
| 101 |
+
learning_rate: ${optimizer.params.learning_rate}
|
| 102 |
+
warmup_steps: 5000
|
| 103 |
+
min_lr_scale: 0.1
|
| 104 |
+
|
| 105 |
+
training:
|
| 106 |
+
gradient_accumulation_steps: 4 # 4
|
| 107 |
+
noise_type: "mask"
|
| 108 |
+
batch_size_t2i: 1
|
| 109 |
+
batch_size_lm: 2
|
| 110 |
+
batch_size_mmu: 1
|
| 111 |
+
mixed_precision: "bf16"
|
| 112 |
+
enable_tf32: True
|
| 113 |
+
seed: 10086
|
| 114 |
+
max_train_steps: 1000000
|
| 115 |
+
overfit_one_batch: False
|
| 116 |
+
cond_dropout_prob: 0.1
|
| 117 |
+
min_masking_rate: 0.0
|
| 118 |
+
label_smoothing: 0.0
|
| 119 |
+
max_grad_norm: 1
|
| 120 |
+
guidance_scale: 5
|
| 121 |
+
generation_timesteps: 20
|
| 122 |
+
t2i_coeff: 0.05
|
| 123 |
+
lm_coeff: 0.6
|
| 124 |
+
mmu_coeff: 0.4
|
| 125 |
+
cot_in_mmu_coeff: 3.5
|
| 126 |
+
vqa_in_mmu_coeff: 5.5
|
| 127 |
+
clevr2_in_mmu_coeff: 0.5
|
| 128 |
+
geo170k_in_mmu_coeff: 0.5
|
| 129 |
+
base_in_lm_coeff: 0.02
|
| 130 |
+
instruct_in_lm_coeff: 0.98
|
| 131 |
+
|
| 132 |
+
validation:
|
| 133 |
+
quantative_prompts_file: "/data_storage/ty/MMaDA/validation_prompts/quantative.txt"
|
| 134 |
+
quantative_batch_size: 8
|
generate.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
from transformers import AutoTokenizer, AutoModel
|
| 6 |
+
from models import MMadaModelLM
|
| 7 |
+
|
| 8 |
+
def add_gumbel_noise(logits, temperature):
|
| 9 |
+
'''
|
| 10 |
+
The Gumbel max is a method for sampling categorical distributions.
|
| 11 |
+
According to arXiv:2409.02908, for MDM, low-precision Gumbel Max improves perplexity score but reduces generation quality.
|
| 12 |
+
Thus, we use float64.
|
| 13 |
+
'''
|
| 14 |
+
if temperature == 0:
|
| 15 |
+
return logits
|
| 16 |
+
logits = logits.to(torch.float64)
|
| 17 |
+
noise = torch.rand_like(logits, dtype=torch.float64)
|
| 18 |
+
gumbel_noise = (- torch.log(noise)) ** temperature
|
| 19 |
+
return logits.exp() / gumbel_noise
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def get_num_transfer_tokens(mask_index, steps):
|
| 23 |
+
'''
|
| 24 |
+
In the reverse process, the interval [0, 1] is uniformly discretized into steps intervals.
|
| 25 |
+
Furthermore, because LLaDA employs a linear noise schedule (as defined in Eq. (8)),
|
| 26 |
+
the expected number of tokens transitioned at each step should be consistent.
|
| 27 |
+
|
| 28 |
+
This function is designed to precompute the number of tokens that need to be transitioned at each step.
|
| 29 |
+
'''
|
| 30 |
+
mask_num = mask_index.sum(dim=1, keepdim=True)
|
| 31 |
+
|
| 32 |
+
base = mask_num // steps
|
| 33 |
+
remainder = mask_num % steps
|
| 34 |
+
|
| 35 |
+
num_transfer_tokens = torch.zeros(mask_num.size(0), steps, device=mask_index.device, dtype=torch.int64) + base
|
| 36 |
+
|
| 37 |
+
for i in range(mask_num.size(0)):
|
| 38 |
+
num_transfer_tokens[i, :remainder[i]] += 1
|
| 39 |
+
|
| 40 |
+
return num_transfer_tokens
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
@ torch.no_grad()
|
| 44 |
+
def generate(model, prompt, steps=128, gen_length=128, block_length=128, temperature=0.,
|
| 45 |
+
cfg_scale=0., remasking='low_confidence', mask_id=126336, attention_mask=None):
|
| 46 |
+
'''
|
| 47 |
+
Args:
|
| 48 |
+
model: Mask predictor.
|
| 49 |
+
prompt: A tensor of shape (B, L), where B is batch size.
|
| 50 |
+
steps: Sampling steps, less than or equal to gen_length.
|
| 51 |
+
gen_length: Generated answer length.
|
| 52 |
+
block_length: Block length, less than or equal to gen_length. If less than gen_length, it means using semi_autoregressive remasking.
|
| 53 |
+
temperature: Categorical distribution sampling temperature.
|
| 54 |
+
cfg_scale: Unsupervised classifier-free guidance scale.
|
| 55 |
+
remasking: Remasking strategy. 'low_confidence' or 'random'.
|
| 56 |
+
mask_id: The toke id of [MASK] is 126336.
|
| 57 |
+
'''
|
| 58 |
+
if attention_mask is not None and 0.0 in attention_mask:
|
| 59 |
+
attention_bias = (attention_mask[:, :, None] & attention_mask[:, None, :]).bool().unsqueeze(1)
|
| 60 |
+
print(f"attention_bias: {attention_bias}")
|
| 61 |
+
else:
|
| 62 |
+
attention_bias = None
|
| 63 |
+
batch_size = prompt.shape[0]
|
| 64 |
+
x = torch.full((batch_size, prompt.shape[1] + gen_length), mask_id, dtype=torch.long).to(model.device)
|
| 65 |
+
x[:, :prompt.shape[1]] = prompt.clone()
|
| 66 |
+
|
| 67 |
+
prompt_index = (x != mask_id)
|
| 68 |
+
|
| 69 |
+
assert gen_length % block_length == 0
|
| 70 |
+
num_blocks = gen_length // block_length
|
| 71 |
+
|
| 72 |
+
assert steps % num_blocks == 0
|
| 73 |
+
steps = steps // num_blocks
|
| 74 |
+
|
| 75 |
+
for num_block in range(num_blocks):
|
| 76 |
+
block_mask_index = (x[:, prompt.shape[1] + num_block * block_length: prompt.shape[1] + (num_block + 1) * block_length:] == mask_id)
|
| 77 |
+
num_transfer_tokens = get_num_transfer_tokens(block_mask_index, steps)
|
| 78 |
+
for i in range(steps):
|
| 79 |
+
mask_index = (x == mask_id)
|
| 80 |
+
if cfg_scale > 0.:
|
| 81 |
+
un_x = x.clone()
|
| 82 |
+
un_x[prompt_index] = mask_id
|
| 83 |
+
x_ = torch.cat([x, un_x], dim=0)
|
| 84 |
+
logits = model(x_).logits
|
| 85 |
+
logits, un_logits = torch.chunk(logits, 2, dim=0)
|
| 86 |
+
logits = un_logits + (cfg_scale + 1) * (logits - un_logits)
|
| 87 |
+
else:
|
| 88 |
+
logits = model(x, attention_bias=attention_bias).logits
|
| 89 |
+
|
| 90 |
+
logits_with_noise = add_gumbel_noise(logits, temperature=temperature)
|
| 91 |
+
x0 = torch.argmax(logits_with_noise, dim=-1) # b, l
|
| 92 |
+
|
| 93 |
+
if remasking == 'low_confidence':
|
| 94 |
+
p = F.softmax(logits.to(torch.float64), dim=-1)
|
| 95 |
+
x0_p = torch.squeeze(
|
| 96 |
+
torch.gather(p, dim=-1, index=torch.unsqueeze(x0, -1)), -1) # b, l
|
| 97 |
+
elif remasking == 'random':
|
| 98 |
+
x0_p = torch.rand((x0.shape[0], x0.shape[1]), device=x0.device)
|
| 99 |
+
else:
|
| 100 |
+
raise NotImplementedError(remasking)
|
| 101 |
+
|
| 102 |
+
x0_p[:, prompt.shape[1] + (num_block + 1) * block_length:] = -np.inf
|
| 103 |
+
|
| 104 |
+
x0 = torch.where(mask_index, x0, x)
|
| 105 |
+
confidence = torch.where(mask_index, x0_p, -np.inf)
|
| 106 |
+
# print(confidence.shape)
|
| 107 |
+
transfer_index = torch.zeros_like(x0, dtype=torch.bool, device=x0.device)
|
| 108 |
+
for j in range(confidence.shape[0]):
|
| 109 |
+
_, select_index = torch.topk(confidence[j], k=num_transfer_tokens[j, i])
|
| 110 |
+
transfer_index[j, select_index] = True
|
| 111 |
+
x[transfer_index] = x0[transfer_index]
|
| 112 |
+
|
| 113 |
+
return x
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def main():
|
| 117 |
+
device = 'cuda'
|
| 118 |
+
model = MMadaModelLM.from_pretrained("/data_storage/ty/MMaDA/mmada-training-stage4-llada-instruct/checkpoint-170000/unwrapped_model", trust_remote_code=True, torch_dtype=torch.bfloat16).to(device).eval()
|
| 119 |
+
tokenizer = AutoTokenizer.from_pretrained("/data_storage/ty/MMaDA/mmada-training-stage4-llada-instruct/checkpoint-170000/unwrapped_model", trust_remote_code=True)
|
| 120 |
+
tokenizer.chat_template = "{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{{ '<|start_header_id|>assistant<|end_header_id|>\n' }}"
|
| 121 |
+
prompt = "Lily can run 12 kilometers per hour for 4 hours. After that, she runs 6 kilometers per hour. How many kilometers can she run in 8 hours?"
|
| 122 |
+
m = [{"role": "user", "content": prompt}, ]
|
| 123 |
+
prompt = tokenizer.apply_chat_template(m, add_generation_prompt=True, tokenize=False)
|
| 124 |
+
input_ids = tokenizer(text=prompt, return_tensors="pt", padding=True, padding_side="left")['input_ids']
|
| 125 |
+
input_ids = torch.tensor(input_ids).to(device)
|
| 126 |
+
out = generate(model, input_ids, steps=128, gen_length=128, block_length=128, temperature=1, cfg_scale=0., remasking='low_confidence')
|
| 127 |
+
print(tokenizer.batch_decode(out[:, input_ids.shape[1]:], skip_special_tokens=True))
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
if __name__ == '__main__':
|
| 131 |
+
main()
|
inference_mmu.py
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2025 MMaDA Team
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
import os
|
| 17 |
+
os.environ["TOKENIZERS_PARALLELISM"] = "true"
|
| 18 |
+
from PIL import Image
|
| 19 |
+
from tqdm import tqdm
|
| 20 |
+
import numpy as np
|
| 21 |
+
import torch
|
| 22 |
+
import wandb
|
| 23 |
+
from models import MAGVITv2, MMadaConfig, MMadaModelLM
|
| 24 |
+
from training.prompting_utils import UniversalPrompting
|
| 25 |
+
from training.utils import get_config, flatten_omega_conf, image_transform
|
| 26 |
+
from transformers import AutoTokenizer, AutoConfig
|
| 27 |
+
|
| 28 |
+
def resize_vocab(model, config):
|
| 29 |
+
print(f"Resizing token embeddings to {config.new_vocab_size}")
|
| 30 |
+
model.resize_token_embeddings(config.new_vocab_size)
|
| 31 |
+
|
| 32 |
+
def get_vq_model_class(model_type):
|
| 33 |
+
if model_type == "magvitv2":
|
| 34 |
+
return MAGVITv2
|
| 35 |
+
else:
|
| 36 |
+
raise ValueError(f"model_type {model_type} not supported.")
|
| 37 |
+
|
| 38 |
+
if __name__ == '__main__':
|
| 39 |
+
|
| 40 |
+
config = get_config()
|
| 41 |
+
resume_wandb_run = config.wandb.resume
|
| 42 |
+
run_id = config.wandb.get("run_id", None)
|
| 43 |
+
if run_id is None:
|
| 44 |
+
resume_wandb_run = False
|
| 45 |
+
run_id = wandb.util.generate_id()
|
| 46 |
+
config.wandb.run_id = run_id
|
| 47 |
+
|
| 48 |
+
wandb_config = {k: v for k, v in flatten_omega_conf(config, resolve=True)}
|
| 49 |
+
|
| 50 |
+
wandb.init(
|
| 51 |
+
project="demo",
|
| 52 |
+
name=config.experiment.name + '_mmu',
|
| 53 |
+
config=wandb_config,
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 57 |
+
tokenizer = AutoTokenizer.from_pretrained(config.model.mmada.pretrained_model_path, padding_side="left")
|
| 58 |
+
|
| 59 |
+
uni_prompting = UniversalPrompting(tokenizer, max_text_len=config.dataset.preprocessing.max_seq_length,
|
| 60 |
+
special_tokens=("<|soi|>", "<|eoi|>", "<|sov|>", "<|eov|>", "<|t2i|>", "<|mmu|>", "<|t2v|>", "<|v2v|>", "<|lvg|>"),
|
| 61 |
+
ignore_id=-100, cond_dropout_prob=config.training.cond_dropout_prob, use_reserved_token=True)
|
| 62 |
+
|
| 63 |
+
vq_model = get_vq_model_class(config.model.vq_model.type)
|
| 64 |
+
vq_model = vq_model.from_pretrained(config.model.vq_model.vq_model_name).to(device)
|
| 65 |
+
vq_model.requires_grad_(False)
|
| 66 |
+
vq_model.eval()
|
| 67 |
+
|
| 68 |
+
model = MMadaModelLM.from_pretrained(config.model.mmada.pretrained_model_path, trust_remote_code=True, torch_dtype=torch.bfloat16)
|
| 69 |
+
model.to(device)
|
| 70 |
+
|
| 71 |
+
mask_token_id = model.config.mask_token_id
|
| 72 |
+
|
| 73 |
+
temperature = 0.8 # 1.0 = no change, < 1.0 = less random, > 1.0 = more random, in predictions
|
| 74 |
+
top_k = 1 # retain only the top_k most likely tokens, clamp others to have 0 probability
|
| 75 |
+
file_list = os.listdir(config.mmu_image_root)
|
| 76 |
+
file_list = [f for f in file_list if f.lower().endswith(('.jpg', '.png', '.jpeg'))]
|
| 77 |
+
responses = ['' for i in range(len(file_list))]
|
| 78 |
+
images = []
|
| 79 |
+
config.question = config.question.split(' *** ')
|
| 80 |
+
for i, file_name in enumerate(tqdm(file_list)):
|
| 81 |
+
image_path = os.path.join(config.mmu_image_root, file_name)
|
| 82 |
+
image_ori = Image.open(image_path).convert("RGB")
|
| 83 |
+
image = image_transform(image_ori, resolution=config.dataset.params.resolution).to(device)
|
| 84 |
+
image = image.unsqueeze(0)
|
| 85 |
+
images.append(image)
|
| 86 |
+
image_tokens = vq_model.get_code(image) + len(uni_prompting.text_tokenizer)
|
| 87 |
+
batch_size = 1
|
| 88 |
+
|
| 89 |
+
for question in config.question:
|
| 90 |
+
input_ids = uni_prompting.text_tokenizer(['<|start_header_id|>user<|end_header_id|>\n' + "Please describe this image in detail." +'<eot_id><|start_header_id|>assistant<|end_header_id|>\n'])['input_ids']
|
| 91 |
+
input_ids = torch.tensor(input_ids).to(device)
|
| 92 |
+
|
| 93 |
+
input_ids = torch.cat([
|
| 94 |
+
(torch.ones(input_ids.shape[0], 1) * uni_prompting.sptids_dict['<|mmu|>']).to(device),
|
| 95 |
+
(torch.ones(input_ids.shape[0], 1) * uni_prompting.sptids_dict['<|soi|>']).to(device),
|
| 96 |
+
image_tokens,
|
| 97 |
+
(torch.ones(input_ids.shape[0], 1) * uni_prompting.sptids_dict['<|eoi|>']).to(device),
|
| 98 |
+
(torch.ones(input_ids.shape[0], 1) * uni_prompting.sptids_dict['<|sot|>']).to(device),
|
| 99 |
+
input_ids
|
| 100 |
+
], dim=1).long()
|
| 101 |
+
output_ids = model.mmu_generate(input_ids, max_new_tokens=1024, steps=512, block_length=1024)
|
| 102 |
+
text = uni_prompting.text_tokenizer.batch_decode(output_ids[:, input_ids.shape[1]:], skip_special_tokens=True)
|
| 103 |
+
print(text)
|
| 104 |
+
responses[i] += f'User: ' + question + f'\n Answer : ' + text[0] + '\n'
|
| 105 |
+
|
| 106 |
+
images = torch.cat(images, dim=0)
|
| 107 |
+
images = torch.clamp((images + 1.0) / 2.0, min=0.0, max=1.0)
|
| 108 |
+
images *= 255.0
|
| 109 |
+
images = images.permute(0, 2, 3, 1).cpu().numpy().astype(np.uint8)
|
| 110 |
+
pil_images = [Image.fromarray(image) for image in images]
|
| 111 |
+
|
| 112 |
+
wandb_images = [wandb.Image(image, caption=responses[i]) for i, image in enumerate(pil_images)]
|
| 113 |
+
wandb.log({"multimodal understanding": wandb_images}, step=0)
|
| 114 |
+
|
inference_t2i.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2025 MMaDA Team
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
import os
|
| 17 |
+
import inspect
|
| 18 |
+
|
| 19 |
+
os.environ["TOKENIZERS_PARALLELISM"] = "true"
|
| 20 |
+
from PIL import Image
|
| 21 |
+
from tqdm import tqdm
|
| 22 |
+
import numpy as np
|
| 23 |
+
import torch
|
| 24 |
+
import wandb
|
| 25 |
+
from models import MAGVITv2, get_mask_schedule, MMadaModelLM, MMadaConfig
|
| 26 |
+
from training.prompting_utils import UniversalPrompting
|
| 27 |
+
from training.utils import get_config, flatten_omega_conf, image_transform
|
| 28 |
+
from transformers import AutoTokenizer, AutoConfig, AutoModel
|
| 29 |
+
import torch.nn.functional as F
|
| 30 |
+
|
| 31 |
+
def resize_vocab(model, config):
|
| 32 |
+
print(f"Resizing token embeddings to {config.new_vocab_size}")
|
| 33 |
+
model.resize_token_embeddings(config.new_vocab_size)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def get_vq_model_class(model_type):
|
| 37 |
+
if model_type == "magvitv2":
|
| 38 |
+
return MAGVITv2
|
| 39 |
+
else:
|
| 40 |
+
raise ValueError(f"model_type {model_type} not supported.")
|
| 41 |
+
|
| 42 |
+
if __name__ == '__main__':
|
| 43 |
+
|
| 44 |
+
config = get_config()
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
resume_wandb_run = config.wandb.resume
|
| 48 |
+
run_id = config.wandb.get("run_id", None)
|
| 49 |
+
if run_id is None:
|
| 50 |
+
resume_wandb_run = False
|
| 51 |
+
run_id = wandb.util.generate_id()
|
| 52 |
+
config.wandb.run_id = run_id
|
| 53 |
+
|
| 54 |
+
wandb_config = {k: v for k, v in flatten_omega_conf(config, resolve=True)}
|
| 55 |
+
|
| 56 |
+
wandb.init(
|
| 57 |
+
project="demo",
|
| 58 |
+
name=config.experiment.name + '_t2i',
|
| 59 |
+
config=wandb_config,
|
| 60 |
+
)
|
| 61 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 62 |
+
tokenizer = AutoTokenizer.from_pretrained(config.model.mmada.pretrained_model_path, padding_side="left")
|
| 63 |
+
|
| 64 |
+
uni_prompting = UniversalPrompting(tokenizer, max_text_len=config.dataset.preprocessing.max_seq_length, special_tokens=("<|soi|>", "<|eoi|>", "<|sov|>", "<|eov|>", "<|t2i|>", "<|mmu|>", "<|t2v|>", "<|v2v|>", "<|lvg|>"),ignore_id=-100, cond_dropout_prob=config.training.cond_dropout_prob, use_reserved_token=True)
|
| 65 |
+
|
| 66 |
+
vq_model = get_vq_model_class(config.model.vq_model.type)
|
| 67 |
+
vq_model = vq_model.from_pretrained(config.model.vq_model.vq_model_name).to(device)
|
| 68 |
+
vq_model.requires_grad_(False)
|
| 69 |
+
vq_model.eval()
|
| 70 |
+
model = MMadaModelLM.from_pretrained(config.model.mmada.pretrained_model_path, trust_remote_code=True, torch_dtype=torch.bfloat16)
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
model.to(device)
|
| 74 |
+
|
| 75 |
+
mask_token_id = model.config.mask_token_id
|
| 76 |
+
if config.get("validation_prompts_file", None) is not None:
|
| 77 |
+
config.dataset.params.validation_prompts_file = config.validation_prompts_file
|
| 78 |
+
config.training.batch_size = config.batch_size
|
| 79 |
+
|
| 80 |
+
config.training.guidance_scale = config.guidance_scale
|
| 81 |
+
config.training.generation_timesteps = config.generation_timesteps
|
| 82 |
+
|
| 83 |
+
with open(config.dataset.params.validation_prompts_file, "r") as f:
|
| 84 |
+
validation_prompts = f.read().splitlines()
|
| 85 |
+
|
| 86 |
+
for step in tqdm(range(0, len(validation_prompts), config.training.batch_size)):
|
| 87 |
+
prompts = validation_prompts[step:step + config.training.batch_size]
|
| 88 |
+
|
| 89 |
+
image_tokens = torch.ones((len(prompts), config.model.mmada.num_vq_tokens),
|
| 90 |
+
dtype=torch.long, device=device) * mask_token_id
|
| 91 |
+
input_ids, attention_mask = uni_prompting((prompts, image_tokens), 't2i_gen')
|
| 92 |
+
if config.training.guidance_scale > 0:
|
| 93 |
+
uncond_input_ids, uncond_attention_mask = uni_prompting(([''] * len(prompts), image_tokens), 't2i_gen')
|
| 94 |
+
else:
|
| 95 |
+
uncond_input_ids = None
|
| 96 |
+
uncond_attention_mask = None
|
| 97 |
+
|
| 98 |
+
if config.get("mask_schedule", None) is not None:
|
| 99 |
+
schedule = config.mask_schedule.schedule
|
| 100 |
+
args = config.mask_schedule.get("params", {})
|
| 101 |
+
mask_schedule = get_mask_schedule(schedule, **args)
|
| 102 |
+
else:
|
| 103 |
+
mask_schedule = get_mask_schedule(config.training.get("mask_schedule", "cosine"))
|
| 104 |
+
with torch.no_grad():
|
| 105 |
+
gen_token_ids = model.t2i_generate(
|
| 106 |
+
input_ids=input_ids,
|
| 107 |
+
uncond_input_ids=uncond_input_ids,
|
| 108 |
+
attention_mask=attention_mask,
|
| 109 |
+
uncond_attention_mask=uncond_attention_mask,
|
| 110 |
+
guidance_scale=config.training.guidance_scale,
|
| 111 |
+
temperature=config.training.get("generation_temperature", 1.0),
|
| 112 |
+
timesteps=config.training.generation_timesteps,
|
| 113 |
+
noise_schedule=mask_schedule,
|
| 114 |
+
noise_type=config.training.get("noise_type", "mask"),
|
| 115 |
+
seq_len=config.model.mmada.num_vq_tokens,
|
| 116 |
+
uni_prompting=uni_prompting,
|
| 117 |
+
config=config,
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
gen_token_ids = torch.clamp(gen_token_ids, max=config.model.mmada.codebook_size - 1, min=0)
|
| 121 |
+
images = vq_model.decode_code(gen_token_ids)
|
| 122 |
+
|
| 123 |
+
images = torch.clamp((images + 1.0) / 2.0, min=0.0, max=1.0)
|
| 124 |
+
images *= 255.0
|
| 125 |
+
images = images.permute(0, 2, 3, 1).cpu().numpy().astype(np.uint8)
|
| 126 |
+
pil_images = [Image.fromarray(image) for image in images]
|
| 127 |
+
|
| 128 |
+
wandb_images = [wandb.Image(image, caption=prompts[i]) for i, image in enumerate(pil_images)]
|
| 129 |
+
wandb.log({"generated_images": wandb_images}, step=step)
|
lm_chat_validation/description.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<|start_header_id|>user<|end_header_id|>
|
| 2 |
+
From the following items, select the one that belongs to animals:
|
| 3 |
+
1. Apple
|
| 4 |
+
2. Sun
|
| 5 |
+
3. Dog<eot_id><|start_header_id|>assistant<|end_header_id|>
|
lm_chat_validation/questions.jsonl
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"question":"Write a short poem with the theme of the sea."}
|
| 2 |
+
{"question":"From the following items, select the one that belongs to animals:\n1. Apple\n2. Sun\n3. Dog"}
|
| 3 |
+
{"question":"Please answer the following question based on the context provided.\nContext: \nGood Friday is a Christian holiday commemorating the crucifixion of Jesus and his death at Calvary. It is observed during Holy Week as part of the Paschal Triduum. It is also known as Holy Friday, Great Friday, Great and Holy Friday (also Holy and Great Friday), and Black Friday.\nQuestion: \nExtract the various ways to say Good Friday from the text. Separate them with a new line."}
|
| 4 |
+
{"question":"Write a speech introducing yourself to the audience."}
|
| 5 |
+
{"question":"Please answer the following question based on the context provided.\nContext:\nThe Maurice \"Rocket\" Richard Trophy, also known as the Rocket Richard Trophy, is awarded annually to the leading goal scorer in the National Hockey League (NHL). It was donated to the NHL by the Montreal Canadiens in 1998–99 and is named in honour of legendary Montreal Canadiens right winger Maurice \"Rocket\" Richard. First won by Teemu Selanne, it is currently held by Auston Matthews, who scored 60 goals during the 2021–22 NHL season.\nQuestion:\nWhat is the Maurice Richard Trophy"}
|
| 6 |
+
{"question":"Explain what an embedding layer is and its purpose in Machine Learning."}
|
| 7 |
+
{"question":"You should first think about the reasoning process in the mind and then provide the user with the answer. The reasoning process is enclosed within <think> </think> tags, i.e. <think> reasoning process here </think> answer here\nA rectangular prism has a length of 5 units, a width of 4 units, and a height of 3 units. What is the volume of the prism?\n"}
|
| 8 |
+
{"question":"You should first think about the reasoning process in the mind and then provide the user with the answer. The reasoning process is enclosed within <think> </think> tags, i.e. <think> reasoning process here </think> answer here\nEvaluate $ (1 + i)^4 $.\n"}
|
| 9 |
+
{"question":"You should first think about the reasoning process in the mind and then provide the user with the answer. The reasoning process is enclosed within <think> </think> tags, i.e. <think> reasoning process here </think> answer here\nGiven $\\tan\\beta= \\frac {1}{2}$, find the value of $\\sin^2\\beta-3\\sin\\beta\\cos\\beta+4\\cos^2\\beta$.\n"}
|
| 10 |
+
{"question":"You should first think about the reasoning process in the mind and then provide the user with the answer. The reasoning process is enclosed within <think> </think> tags, i.e. <think> reasoning process here </think> answer here\nJames has 7 apples. 4 of them are red, and 3 of them are green. If he chooses 2 apples at random, what is the probability that both the apples he chooses are green?\n"}
|
| 11 |
+
{"question":"You should first think about the reasoning process in the mind and then provide the user with the answer. The reasoning process is enclosed within <think> </think> tags, i.e. <think> reasoning process here </think> answer here\nThe user will describe something indirectly, and you need to infer and answer what that thing is (without any explanation). If there are multiple possible answers, choose one of them.\nThe thing: A staple food in many Asian countries\n"}
|
mmu_validation/Decoupling Visual Encoding.png
ADDED

|
Git LFS Details
|
mmu_validation/ai2d.png
ADDED

|
Git LFS Details
|
mmu_validation/clevr.jpg
ADDED

|
mmu_validation/docvqa.png
ADDED

|
mmu_validation/dog.png
ADDED

|
mmu_validation/geo.jpg
ADDED

|
mmu_validation/llava1.jpg
ADDED

|
Git LFS Details
|
mmu_validation/llava2.jpg
ADDED

|
mmu_validation/prompts.jsonl
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"file_name": "clevr.jpg", "prompt": "<|start_header_id|>user<|end_header_id|>\nYou should first think about the reasoning process in the mind and then provide the user with the answer. The reasoning process is enclosed within <think> </think> tags, i.e. <think> reasoning process here </think> answer here\nHow many objects are there in total in this picture?<eot_id><|start_header_id|>assistant<|end_header_id|>\n"}
|
| 2 |
+
{"file_name": "geo.jpg", "prompt": "<|start_header_id|>user<|end_header_id|>\nYou should first think about the reasoning process in the mind and then provide the user with the answer. The reasoning process is enclosed within <think> </think> tags, i.e. <think> reasoning process here </think> answer here\nAs shown in the figure, in ABCD, angle ADC = 135° and angle CAD = 23°, then angle CAB is equal to ().<eot_id><|start_header_id|>assistant<|end_header_id|>\n"}
|
| 3 |
+
{"file_name": "docvqa.png", "prompt": "<|start_header_id|>user<|end_header_id|>\nYou should first think about the reasoning process in the mind and then provide the user with the answer. The reasoning process is enclosed within <think> </think> tags, i.e. <think> reasoning process here </think> answer here\nWhat is written in first rectangle at the top of the page?.<eot_id><|start_header_id|>assistant<|end_header_id|>\n"}
|
| 4 |
+
{"file_name": "ai2d.png", "prompt": "<|start_header_id|>user<|end_header_id|>\nYou should first think about the reasoning process in the mind and then provide the user with the answer. The reasoning process is enclosed within <think> </think> tags, i.e. <think> reasoning process here </think> answer here\nAccording to the given food web, what will be the result of decrease in phytoplanktons?\nOptions:\n0: The planktivores will increase\n1: Decrease in zooplankton\n2: Increase in adult game fish\n3: The detritivores will lose its energy.\nPlease choose and answer with only the index number (0, 1, 2, or 3).<eot_id><|start_header_id|>assistant<|end_header_id|>\n"}
|
| 5 |
+
{"file_name": "dog.png", "prompt": "<|start_header_id|>user<|end_header_id|>\nPlease describe this image in detail.<eot_id><|start_header_id|>assistant<|end_header_id|>\n"}
|
| 6 |
+
{"file_name": "sofa_under_water.jpg", "prompt": "<|start_header_id|>user<|end_header_id|>\nPlease describe this image in detail.<eot_id><|start_header_id|>assistant<|end_header_id|>\n"}
|
| 7 |
+
{"file_name": "sunflower.jpg", "prompt": "<|start_header_id|>user<|end_header_id|>\nPlease describe this image in detail.<eot_id><|start_header_id|>assistant<|end_header_id|>\n"}
|
| 8 |
+
{"file_name": "woman.jpg", "prompt": "<|start_header_id|>user<|end_header_id|>\nPlease describe this image in detail.<eot_id><|start_header_id|>assistant<|end_header_id|>\n"}
|
| 9 |
+
{"file_name": "llava1.jpg", "prompt": "<|start_header_id|>user<|end_header_id|>\nPlease describe this image in detail.<eot_id><|start_header_id|>assistant<|end_header_id|>\n"}
|
| 10 |
+
{"file_name": "llava2.jpg", "prompt": "<|start_header_id|>user<|end_header_id|>\nPlease describe this image in detail.<eot_id><|start_header_id|>assistant<|end_header_id|>\n"}
|
mmu_validation/prompts_with_vqa.json
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"file_name": "clevr.jpg",
|
| 4 |
+
"messages": [
|
| 5 |
+
{
|
| 6 |
+
"role": "user",
|
| 7 |
+
"content": "You should first think about the reasoning process in the mind and then provide the user with the answer. The reasoning process is enclosed within <think> </think> tags, i.e. <think> reasoning process here </think> answer here\nHow many objects are there in total in this picture?"
|
| 8 |
+
}
|
| 9 |
+
]
|
| 10 |
+
},
|
| 11 |
+
{
|
| 12 |
+
"file_name": "geo.jpg",
|
| 13 |
+
"messages": [
|
| 14 |
+
{
|
| 15 |
+
"role": "user",
|
| 16 |
+
"content": "You should first think about the reasoning process in the mind and then provide the user with the answer. The reasoning process is enclosed within <think> </think> tags, i.e. <think> reasoning process here </think> answer here\nAs shown in the figure, in ABCD, angle ADC = 135° and angle CAD = 23°, then angle CAB is equal to ()."
|
| 17 |
+
}
|
| 18 |
+
]
|
| 19 |
+
},
|
| 20 |
+
{
|
| 21 |
+
"file_name": "docvqa.png",
|
| 22 |
+
"messages": [
|
| 23 |
+
{
|
| 24 |
+
"role": "user",
|
| 25 |
+
"content": "You should first think about the reasoning process in the mind and then provide the user with the answer. The reasoning process is enclosed within <think> </think> tags, i.e. <think> reasoning process here </think> answer here\nWhat is written in first rectangle at the top of the page?."
|
| 26 |
+
}
|
| 27 |
+
]
|
| 28 |
+
},
|
| 29 |
+
{
|
| 30 |
+
"file_name": "ai2d.png",
|
| 31 |
+
"messages": [
|
| 32 |
+
{
|
| 33 |
+
"role": "user",
|
| 34 |
+
"content": "You should first think about the reasoning process in the mind and then provide the user with the answer. The reasoning process is enclosed within <think> </think> tags, i.e. <think> reasoning process here </think> answer here\nAccording to the given food web, what will be the result of decrease in phytoplanktons?\nOptions:\n0: The planktivores will increase\n1: Decrease in zooplankton\n2: Increase in adult game fish\n3: The detritivores will lose its energy.\nPlease choose and answer with only the index number (0, 1, 2, or 3)."
|
| 35 |
+
}
|
| 36 |
+
]
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
"file_name": "dog.png",
|
| 40 |
+
"messages": [
|
| 41 |
+
{
|
| 42 |
+
"role": "user",
|
| 43 |
+
"content": "Please describe this image in detail."
|
| 44 |
+
}
|
| 45 |
+
]
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"file_name": "sofa_under_water.jpg",
|
| 49 |
+
"messages": [
|
| 50 |
+
{
|
| 51 |
+
"role": "user",
|
| 52 |
+
"content": "Please describe this image in detail."
|
| 53 |
+
}
|
| 54 |
+
]
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
"file_name": "sunflower.jpg",
|
| 58 |
+
"messages": [
|
| 59 |
+
{
|
| 60 |
+
"role": "user",
|
| 61 |
+
"content": "Please describe this image in detail."
|
| 62 |
+
}
|
| 63 |
+
]
|
| 64 |
+
},
|
| 65 |
+
{
|
| 66 |
+
"file_name": "woman.jpg",
|
| 67 |
+
"messages": [
|
| 68 |
+
{
|
| 69 |
+
"role": "user",
|
| 70 |
+
"content": "Please describe this image in detail."
|
| 71 |
+
}
|
| 72 |
+
]
|
| 73 |
+
},
|
| 74 |
+
{
|
| 75 |
+
"file_name": "llava1.jpg",
|
| 76 |
+
"messages": [
|
| 77 |
+
{
|
| 78 |
+
"role": "user",
|
| 79 |
+
"content": "What are the colors of the bus in the image?"
|
| 80 |
+
},
|
| 81 |
+
{
|
| 82 |
+
"role": "assistant",
|
| 83 |
+
"content": "The bus in the image is white and red."
|
| 84 |
+
},
|
| 85 |
+
{
|
| 86 |
+
"role": "user",
|
| 87 |
+
"content": "What feature can be seen on the back of the bus?"
|
| 88 |
+
}
|
| 89 |
+
]
|
| 90 |
+
},
|
| 91 |
+
{
|
| 92 |
+
"file_name": "llava2.jpg",
|
| 93 |
+
"messages": [
|
| 94 |
+
{
|
| 95 |
+
"role": "user",
|
| 96 |
+
"content": "Who wrote this book?\nAnswer the question using a single word or phrase."
|
| 97 |
+
},
|
| 98 |
+
{
|
| 99 |
+
"role": "assistant",
|
| 100 |
+
"content": "Clear Englebert"
|
| 101 |
+
},
|
| 102 |
+
{
|
| 103 |
+
"role": "user",
|
| 104 |
+
"content": "What is the title of this book?"
|
| 105 |
+
},
|
| 106 |
+
{
|
| 107 |
+
"role": "assistant",
|
| 108 |
+
"content": "Feng Shui for Love & Money"
|
| 109 |
+
},
|
| 110 |
+
{
|
| 111 |
+
"role": "user",
|
| 112 |
+
"content": "What type of book is this?"
|
| 113 |
+
}
|
| 114 |
+
]
|
| 115 |
+
}
|
| 116 |
+
]
|
mmu_validation/sofa_under_water.jpg
ADDED

|
Git LFS Details
|
models/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .modeling_magvitv2 import VQGANEncoder, VQGANDecoder, LFQuantizer, MAGVITv2
|
| 2 |
+
from .sampling import *
|
| 3 |
+
from .modeling_mmada import MMadaModelLM, MMadaConfig
|
models/__pycache__/__init__.cpython-311.pyc
ADDED
|
Binary file (430 Bytes). View file
|
|
|
models/__pycache__/common_modules.cpython-311.pyc
ADDED
|
Binary file (19.7 kB). View file
|
|
|
models/__pycache__/configuration_llada.cpython-311.pyc
ADDED
|
Binary file (9.23 kB). View file
|
|
|
models/__pycache__/misc.cpython-311.pyc
ADDED
|
Binary file (2.27 kB). View file
|
|
|
models/__pycache__/modeling_llada.cpython-311.pyc
ADDED
|
Binary file (75.1 kB). View file
|
|
|