

Update README.md
Browse files
README.md
CHANGED
|
@@ -13,10 +13,10 @@ tags:
|
|
| 13 |
|
| 14 |
[HuggingFaceTB/SmolLM3-3B](https://huggingface.co/HuggingFaceTB/SmolLM3-3B) is quantized using [torchao](https://huggingface.co/docs/transformers/main/en/quantization/torchao) with 8-bit embeddings and 8-bit dynamic activations with 4-bit weight linears (`INT8-INT4`). It is then lowered to [ExecuTorch](https://github.com/pytorch/executorch) with several optimizations—custom SPDA, custom KV cache, and parallel prefill—to achieve high performance on the CPU backend, making it well-suited for mobile deployment.
|
| 15 |
|
| 16 |
-
We provide the [.pte file](https://huggingface.co/pytorch/SmolLM3-3B-INT8-INT4/blob/main/
|
| 17 |
|
| 18 |
# Running in a mobile app
|
| 19 |
-
The [.pte file](https://huggingface.co/pytorch/SmolLM3-3B-INT8-INT4/blob/main/
|
| 20 |
|
| 21 |
|
| 22 |
|
|
@@ -131,7 +131,7 @@ linear_config = Int8DynamicActivationIntxWeightConfig(
|
|
| 131 |
weight_scale_dtype=torch.bfloat16,
|
| 132 |
)
|
| 133 |
quant_config = ModuleFqnToConfig({"_default": linear_config, "model.embed_tokens": embedding_config})
|
| 134 |
-
quantization_config = TorchAoConfig(quant_type=quant_config,
|
| 135 |
|
| 136 |
# either use `untied_model_id` or `untied_model_local_path`
|
| 137 |
quantized_model = AutoModelForCausalLM.from_pretrained(untied_model_id, torch_dtype=torch.float32, device_map="auto", quantization_config=quantization_config)
|
|
|
|
| 13 |
|
| 14 |
[HuggingFaceTB/SmolLM3-3B](https://huggingface.co/HuggingFaceTB/SmolLM3-3B) is quantized using [torchao](https://huggingface.co/docs/transformers/main/en/quantization/torchao) with 8-bit embeddings and 8-bit dynamic activations with 4-bit weight linears (`INT8-INT4`). It is then lowered to [ExecuTorch](https://github.com/pytorch/executorch) with several optimizations—custom SPDA, custom KV cache, and parallel prefill—to achieve high performance on the CPU backend, making it well-suited for mobile deployment.
|
| 15 |
|
| 16 |
+
We provide the [.pte file](https://huggingface.co/pytorch/SmolLM3-3B-INT8-INT4/blob/main/model.pte) for direct use in ExecuTorch. *(The provided pte file is exported with the default max_seq_length/max_context_length of 2k.)*
|
| 17 |
|
| 18 |
# Running in a mobile app
|
| 19 |
+
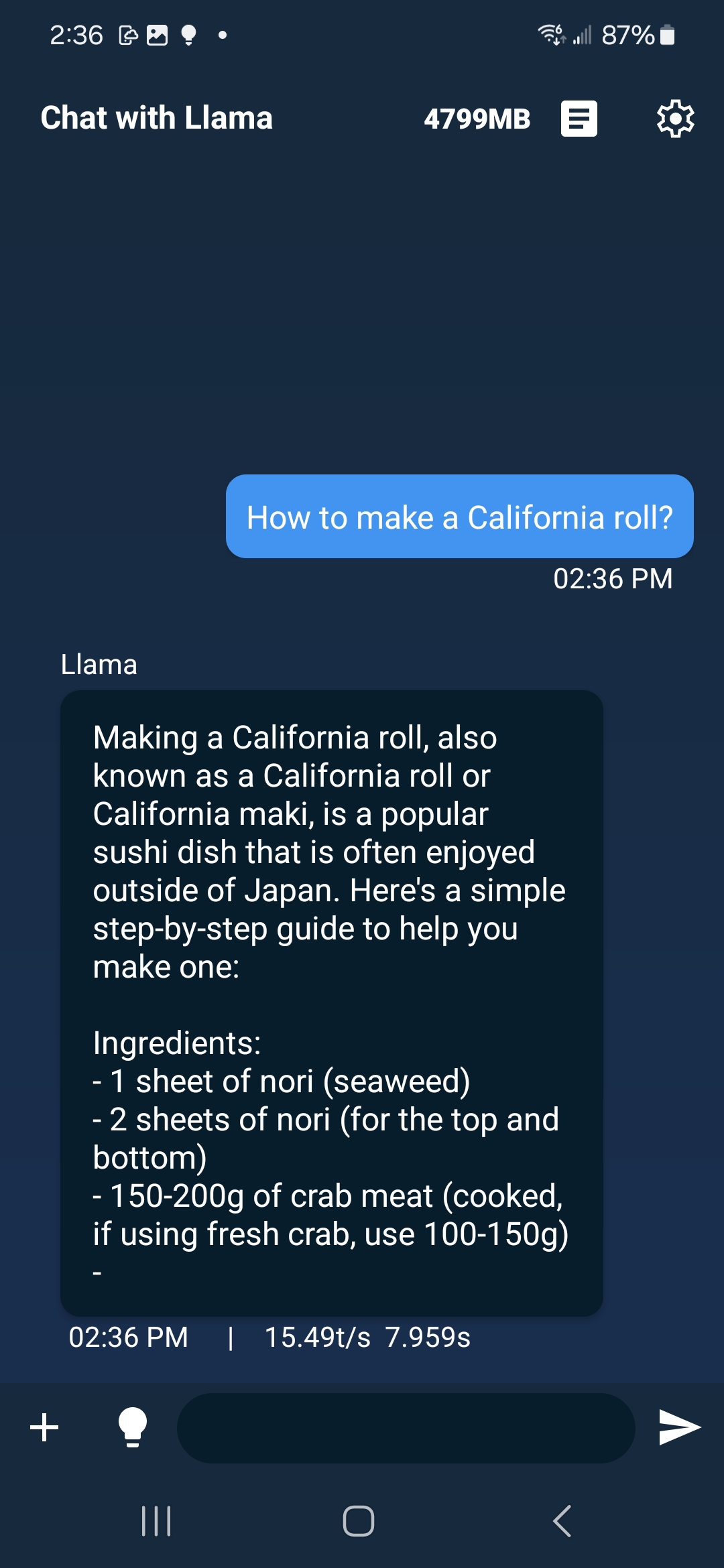
The [.pte file](https://huggingface.co/pytorch/SmolLM3-3B-INT8-INT4/blob/main/model.pte) can be run with ExecuTorch on a mobile phone. See the instructions for doing this in [iOS](https://pytorch.org/executorch/main/llm/llama-demo-ios.html) and [Android](https://docs.pytorch.org/executorch/main/llm/llama-demo-android.html). On Samsung Galaxy S22, the model runs at 15.5 tokens/s.
|
| 20 |
|
| 21 |

|
| 22 |
|
|
|
|
| 131 |
weight_scale_dtype=torch.bfloat16,
|
| 132 |
)
|
| 133 |
quant_config = ModuleFqnToConfig({"_default": linear_config, "model.embed_tokens": embedding_config})
|
| 134 |
+
quantization_config = TorchAoConfig(quant_type=quant_config, include_input_output_embeddings=True, modules_to_not_convert=[])
|
| 135 |
|
| 136 |
# either use `untied_model_id` or `untied_model_local_path`
|
| 137 |
quantized_model = AutoModelForCausalLM.from_pretrained(untied_model_id, torch_dtype=torch.float32, device_map="auto", quantization_config=quantization_config)
|