

End of training
Browse files- README.md +2 -1
- all_results.json +12 -8
- train_results.json +12 -8
- trainer_state.json +0 -0
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -4,6 +4,7 @@ license: apache-2.0
|
|
| 4 |
base_model: Qwen/Qwen3-8B
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
|
|
|
| 7 |
- generated_from_trainer
|
| 8 |
model-index:
|
| 9 |
- name: a1_math_formulas
|
|
@@ -15,7 +16,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 15 |
|
| 16 |
# a1_math_formulas
|
| 17 |
|
| 18 |
-
This model is a fine-tuned version of [Qwen/Qwen3-8B](https://huggingface.co/Qwen/Qwen3-8B) on
|
| 19 |
|
| 20 |
## Model description
|
| 21 |
|
|
|
|
| 4 |
base_model: Qwen/Qwen3-8B
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
| 7 |
+
- full
|
| 8 |
- generated_from_trainer
|
| 9 |
model-index:
|
| 10 |
- name: a1_math_formulas
|
|
|
|
| 16 |
|
| 17 |
# a1_math_formulas
|
| 18 |
|
| 19 |
+
This model is a fine-tuned version of [Qwen/Qwen3-8B](https://huggingface.co/Qwen/Qwen3-8B) on the mlfoundations-dev/a1_math_formulas dataset.
|
| 20 |
|
| 21 |
## Model description
|
| 22 |
|
all_results.json
CHANGED
|
@@ -1,12 +1,16 @@
|
|
| 1 |
{
|
|
|
|
|
|
|
| 2 |
"epoch": 5.0,
|
| 3 |
"loss_nan_ranks": 0,
|
| 4 |
-
"loss_rank_avg": 0.
|
| 5 |
-
"
|
| 6 |
-
"
|
| 7 |
-
"
|
| 8 |
-
"
|
| 9 |
-
"
|
| 10 |
-
"
|
| 11 |
-
"
|
|
|
|
|
|
|
| 12 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"achieved_tflops_per_gpu": 2.476802423960275,
|
| 3 |
+
"achieved_tflops_per_gpu_theoretical": 481.0824479208898,
|
| 4 |
"epoch": 5.0,
|
| 5 |
"loss_nan_ranks": 0,
|
| 6 |
+
"loss_rank_avg": 0.29739144444465637,
|
| 7 |
+
"mfu_percent": 0.1750390405625636,
|
| 8 |
+
"mfu_percent_theoretical": 33.998759570380905,
|
| 9 |
+
"total_flos": 1.3775029894633226e+18,
|
| 10 |
+
"train_loss": 0.31707094306887884,
|
| 11 |
+
"train_runtime": 34760.1149,
|
| 12 |
+
"train_samples_per_second": 4.545,
|
| 13 |
+
"train_steps_per_second": 0.142,
|
| 14 |
+
"valid_targets_mean": 4348.2,
|
| 15 |
+
"valid_targets_min": 876
|
| 16 |
}
|
train_results.json
CHANGED
|
@@ -1,12 +1,16 @@
|
|
| 1 |
{
|
|
|
|
|
|
|
| 2 |
"epoch": 5.0,
|
| 3 |
"loss_nan_ranks": 0,
|
| 4 |
-
"loss_rank_avg": 0.
|
| 5 |
-
"
|
| 6 |
-
"
|
| 7 |
-
"
|
| 8 |
-
"
|
| 9 |
-
"
|
| 10 |
-
"
|
| 11 |
-
"
|
|
|
|
|
|
|
| 12 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"achieved_tflops_per_gpu": 2.476802423960275,
|
| 3 |
+
"achieved_tflops_per_gpu_theoretical": 481.0824479208898,
|
| 4 |
"epoch": 5.0,
|
| 5 |
"loss_nan_ranks": 0,
|
| 6 |
+
"loss_rank_avg": 0.29739144444465637,
|
| 7 |
+
"mfu_percent": 0.1750390405625636,
|
| 8 |
+
"mfu_percent_theoretical": 33.998759570380905,
|
| 9 |
+
"total_flos": 1.3775029894633226e+18,
|
| 10 |
+
"train_loss": 0.31707094306887884,
|
| 11 |
+
"train_runtime": 34760.1149,
|
| 12 |
+
"train_samples_per_second": 4.545,
|
| 13 |
+
"train_steps_per_second": 0.142,
|
| 14 |
+
"valid_targets_mean": 4348.2,
|
| 15 |
+
"valid_targets_min": 876
|
| 16 |
}
|
trainer_state.json
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
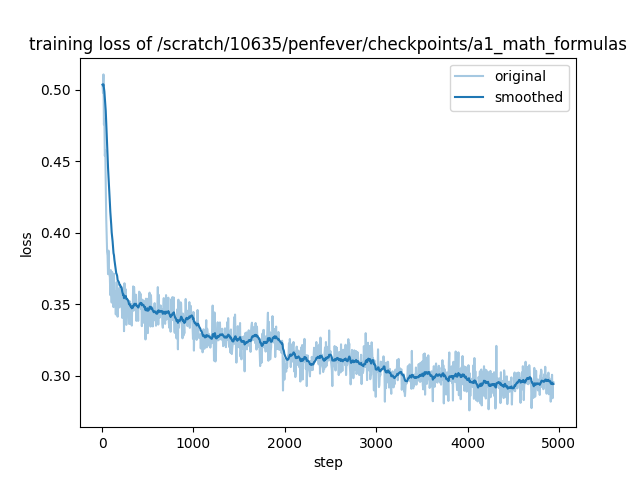
training_loss.png
CHANGED

|
|