

Update README.md
Browse files
README.md
CHANGED
|
@@ -76,6 +76,53 @@ Available in Dense and MoE architectures that scale from edge to cloud, with Ins
|
|
| 76 |
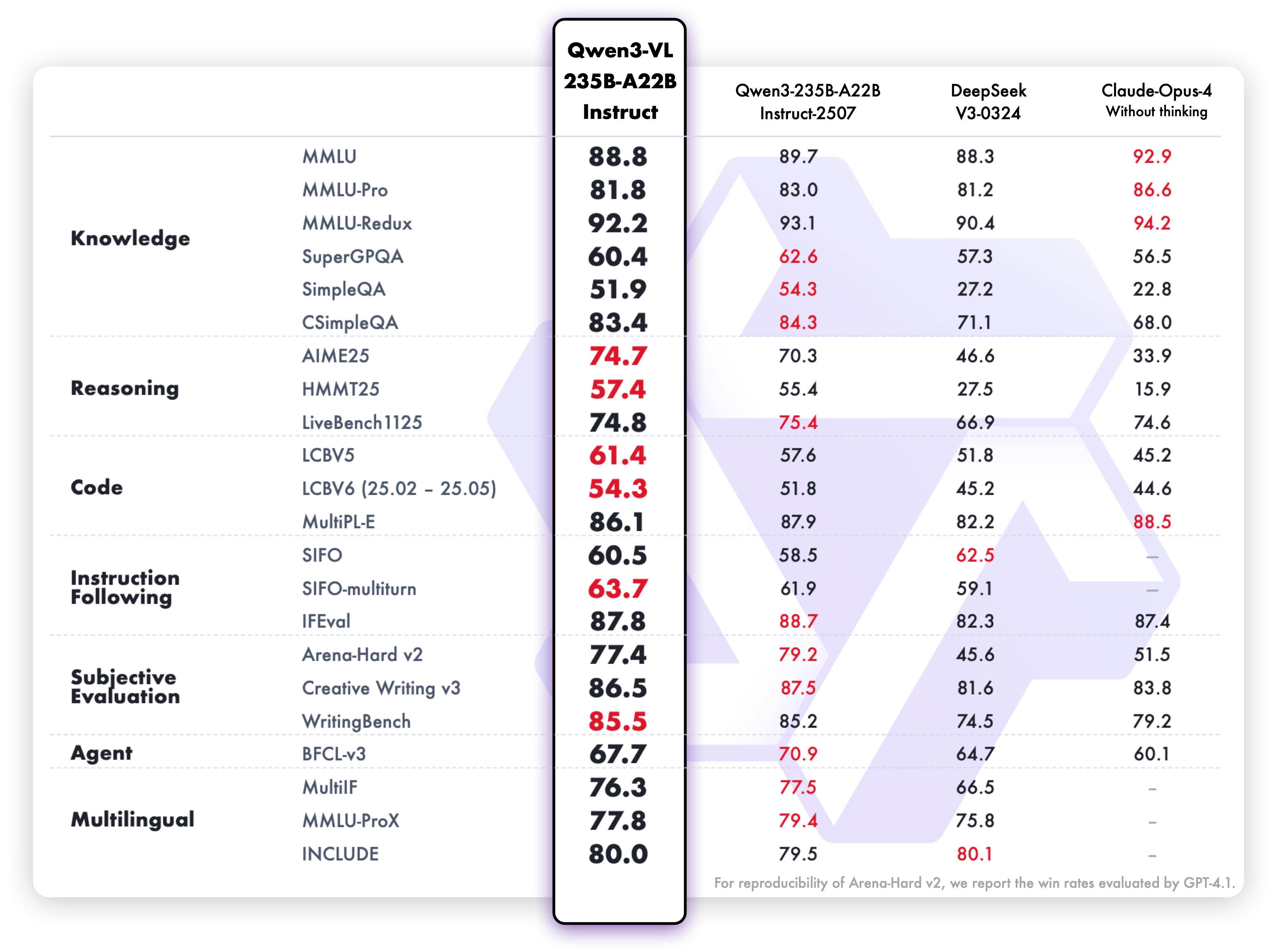
**Pure text performance**
|
| 77 |
|
| 78 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 79 |
|
| 80 |
## Citation
|
| 81 |
|
|
|
|
| 76 |
**Pure text performance**
|
| 77 |

|
| 78 |
|
| 79 |
+
## How to Use
|
| 80 |
+
|
| 81 |
+
To use these models with `llama.cpp`, please ensure you are using the **latest version**—either by [building from source](https://github.com/ggml-org/llama.cpp/blob/master/docs/build.md) or downloading the most recent [release](https://github.com/ggml-org/llama.cpp/releases/tag/b6907) according to the devices.
|
| 82 |
+
|
| 83 |
+
You can run inference via the command line or through a web-based chat interface.
|
| 84 |
+
|
| 85 |
+
### CLI Inference (`llama-mtmd-cli`)
|
| 86 |
+
|
| 87 |
+
For example, to run Qwen3-VL-2B-Instruct with an FP16 vision encoder and Q8_0 quantized LLM:
|
| 88 |
+
|
| 89 |
+
```bash
|
| 90 |
+
llama-mtmd-cli \
|
| 91 |
+
-m path/to/Qwen3VL-2B-Instruct-Q8_0.gguf \
|
| 92 |
+
--mmproj path/to/mmproj-Qwen3VL-2B-Instruct-F16.gguf \
|
| 93 |
+
--image test.jpeg \
|
| 94 |
+
-p "What is the publisher name of the newspaper?" \
|
| 95 |
+
--temp 0.7 --top-k 20 --top-p 0.8 -n 1024
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
### Web Chat (using `llama-server`)
|
| 99 |
+
|
| 100 |
+
To serve Qwen3-VL-235B-A22B-Instruct via an OpenAI-compatible API with a web UI:
|
| 101 |
+
|
| 102 |
+
```bash
|
| 103 |
+
llama-server \
|
| 104 |
+
-m path/to/Qwen3VL-235B-A22B-Instruct-Q4_K_M-split-00001-of-00003.gguf \
|
| 105 |
+
--mmproj path/to/mmproj-Qwen3VL-235B-A22B-Instruct-Q8_0.gguf
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
> **Tip**: For models split into multiple GGUF files, simply specify the first shard (e.g., `...-00001-of-00003.gguf`). llama.cpp will automatically load all parts.
|
| 109 |
+
|
| 110 |
+
Once the server is running, open your browser to `http://localhost:8080` to access the built-in chat interface, or send requests to the `/v1/chat/completions` endpoint. For more details, refer to the [official documentation](https://github.com/ggml-org/llama.cpp/blob/master/tools/server/README.md).
|
| 111 |
+
|
| 112 |
+
### Quantize Your Custom Model
|
| 113 |
+
|
| 114 |
+
You can further quantize the FP16 weights to other precision levels. For example, to quantize the model to 2-bit:
|
| 115 |
+
|
| 116 |
+
```bash
|
| 117 |
+
# Quantize to 2-bit (IQ2_XXS)
|
| 118 |
+
llama-quantize \
|
| 119 |
+
path/to/Qwen3VL-235B-A22B-Instruct-F16.gguf \
|
| 120 |
+
path/to/Qwen3VL-235B-A22B-Instruct-IQ2_XXS.gguf \
|
| 121 |
+
iq2_xxs 8
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
For a full list of supported quantization types and detailed instructions, refer to the [quantization documentation](https://github.com/ggml-org/llama.cpp/blob/master/tools/quantize/README.md).
|
| 125 |
+
|
| 126 |
|
| 127 |
## Citation
|
| 128 |
|