

Upload folder using huggingface_hub
Browse files- .DS_Store +0 -0
- .gitattributes +1 -0
- 1_Pooling/config.json +10 -0
- 2_Dense/config.json +1 -0
- 2_Dense/model.safetensors +3 -0
- README.md +159 -3
- added_tokens.json +28 -0
- assets/.DS_Store +0 -0
- assets/1.png +0 -0
- config.json +33 -0
- config_sentence_transformers.json +10 -0
- merges.txt +0 -0
- model-00001-of-00004.safetensors +3 -0
- model-00002-of-00004.safetensors +3 -0
- model-00003-of-00004.safetensors +3 -0
- model-00004-of-00004.safetensors +3 -0
- model.safetensors.index.json +405 -0
- modeling_qzhou.py +664 -0
- modules.json +20 -0
- sentence_bert_config.json +4 -0
- special_tokens_map.json +31 -0
- tokenizer.json +3 -0
- tokenizer_config.json +246 -0
- vocab.json +0 -0
.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
1_Pooling/config.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"word_embedding_dimension": 4096,
|
| 3 |
+
"pooling_mode_cls_token": false,
|
| 4 |
+
"pooling_mode_mean_tokens": false,
|
| 5 |
+
"pooling_mode_max_tokens": false,
|
| 6 |
+
"pooling_mode_mean_sqrt_len_tokens": false,
|
| 7 |
+
"pooling_mode_weightedmean_tokens": false,
|
| 8 |
+
"pooling_mode_lasttoken": true,
|
| 9 |
+
"include_prompt": true
|
| 10 |
+
}
|
2_Dense/config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"in_features": 4096, "out_features": 1792, "bias": true, "activation_function": "torch.nn.modules.linear.Identity"}
|
2_Dense/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:101b92dd892283cdea788128b1cf031941a3b5c35e2e1a483daab893c870b82c
|
| 3 |
+
size 14683816
|
README.md
CHANGED
|
@@ -1,3 +1,159 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
tags:
|
| 4 |
+
- sentence-transformers
|
| 5 |
+
- sentence-similarity
|
| 6 |
+
- mteb
|
| 7 |
+
- retriever
|
| 8 |
+
---
|
| 9 |
+
# QZhou-Embedding-Zh
|
| 10 |
+
|
| 11 |
+
## Introduction
|
| 12 |
+
We are pleased to announce the release of our new model, QZhou-Embedding-Zh, built upon the architecture and parameters of the Qwen3-8B base model, QZhou-Embedding-Zh was developed using the data construction and training methodology of QZhou-Embedding, and also incorporated MRL embedding inference.
|
| 13 |
+
|
| 14 |
+
## Key Enhancements and Optimizations
|
| 15 |
+
|
| 16 |
+
To build a more powerful and outstanding model, we have adopted proven approaches from QZhou-Embedding and further introduced the following optimizations:
|
| 17 |
+
|
| 18 |
+
1. **Based on Qwen3 Model:** In our practice with QZhou-Embedding, the Qwen3 base model did not show significant advantages over Qwen2.5-7B-Instruct in the first stage (Retrieval). However, notable improvements were observed in Chinese-language tasks, likely due to Qwen3’s stronger Chinese capabilities. We upgraded the base model to Qwen3-8B while retaining the original model architecture, using a last_token pooling strategy.
|
| 19 |
+
|
| 20 |
+
2. **Support for MRL:** MRL (Multi-Representation Learning) is highly demanded in practical applications, especially under high-concurrency and low-latency scenarios. Addressing the lack of MRL support in QZhou-Embedding, QZhou-Embedding-Zh now incorporates this feature with the following dimension options: "128, 256, 512, 768, 1024, 1280, 1536, 1792". The default output dimension is set to 1792.
|
| 21 |
+
|
| 22 |
+
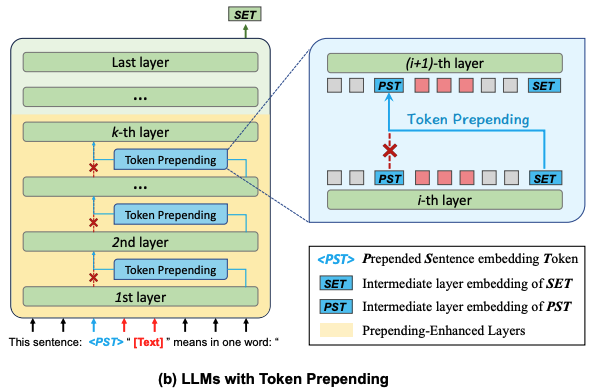
3. **Token Prepending:** Originally proposed by Fu et al(ACL 2025, Volume 1: Long Papers, 3168–3181), this technique addresses the limitations of the unidirectional attention mechanism in decoder-only models. By prepending each layer’s decoded sentence embedding to the beginning of the sentence in the next layer’s input, allowing earlier tokens to attend to the complete sentence information under the causal attention mechanism, Token Prepending significantly improving performance in STS tasks and classification tasks. We retained the Stage-1 training strategy unchanged and integrated Token Prepending during Stage-2 training, using the PromptEOL template construction method described in their paper. Experimental results demonstrate that Token Prepending is not only a training-free enhancement but also further improves performance when fine-tuned with supervised datasets.
|
| 23 |
+
|
| 24 |
+
## Token Prepending
|
| 25 |
+
### Introduction
|
| 26 |
+
Token Prepending is a simple yet effective technique proposed by Fu et al., the core idea is prepending each layer’s decoded sentence embedding to the beginning of the sentence in the next layer’s input, allowing earlier tokens to attend to the complete sentence information under the causal attention mechanism. TP technique is a plug-and-play technique neither introduces new parameters nor alters the existing ones, allowing it to be seamlessly integrated with various prompt-based sentence embedding methods and autoregressive LLMs. The architecture described in the original paper is as follows:
|
| 27 |
+
<div align="center">
|
| 28 |
+
<img src="assets/1.png" width="600" height="400"></img>
|
| 29 |
+
</div>
|
| 30 |
+
|
| 31 |
+
### Our Adaptations and Optimizations
|
| 32 |
+
According to the conclusions presented in the original paper, TP technique is completely training-free and requires no extra learnable parameters, serving as a plug-and-play technique to improve the various prompt-based methods. Since QZhou-Embedding-Zh is built upon the Qwen3 base model—retaining its unidirectional attention mechanism and employing last_token pooling—it is ideally suited for the application of the TP technique. To further explore its potential, we conducted training utilizing the TP technique, building upon the Stage 1 retrieval base model through the following procedure:
|
| 33 |
+
1. We modified the model forward script by applying the TP specifically from layer-1 to layer-7(index), namely prepending the last embeddings to the input before processing through these layers;
|
| 34 |
+
2. For the input template design, we have integrated the PromptEOL template on top of the instruction-based input, using <|im_start|>as a placeholder—corresponding to the \<PST\> token in the original paper—to facilitate subsequent TP operations. The full template structure is designed as follows:
|
| 35 |
+
```
|
| 36 |
+
"This sentence: <|im_start|>“Instruct: [instruction]\nQuery: [user_input]” means in one word: “
|
| 37 |
+
```
|
| 38 |
+
3. Stage 2 training was conducted using the updated model architecture and input structure.
|
| 39 |
+
|
| 40 |
+
## Usage
|
| 41 |
+
To facilitate model inference and CMTEB result replication on your own machine, we provide detailed specifications for environmental dependencies and model implementation.
|
| 42 |
+
|
| 43 |
+
### Requirements
|
| 44 |
+
- Python: 3.10.12
|
| 45 |
+
- Sentence Transformers: 3.4.1
|
| 46 |
+
- Transformers: 4.51.1
|
| 47 |
+
- PyTorch: 2.4.1
|
| 48 |
+
- Accelerate: 1.3.0
|
| 49 |
+
- Datasets: 3.6.0
|
| 50 |
+
- Tokenizers: 0.21.1
|
| 51 |
+
- mteb: 1.38.30
|
| 52 |
+
|
| 53 |
+
### Quickstart
|
| 54 |
+
Since QZhou-Embedding-Zh incorporates a dedicated MRL linear projection module built on the sentence-transformers framework, we now only provide inference code specifically designed for sentence-transformers compatibility.
|
| 55 |
+
|
| 56 |
+
```
|
| 57 |
+
from sentence_transformers import SentenceTransformer
|
| 58 |
+
from sklearn.preprocessing import normalize
|
| 59 |
+
|
| 60 |
+
def get_prompteol_input(text: str) -> str:
|
| 61 |
+
return f"This sentence: <|im_start|>“{text}” means in one word: “"
|
| 62 |
+
|
| 63 |
+
def get_detailed_instruct(task_description: str, query: str) -> str:
|
| 64 |
+
return f'Instruct: {task_description}\nQuery:{query}'
|
| 65 |
+
|
| 66 |
+
model = SentenceTransformer(
|
| 67 |
+
"Kingsoft-LLM/QZhou-Embedding-Zh",
|
| 68 |
+
model_kwargs={"device_map": "cuda", "trust_remote_code": True},
|
| 69 |
+
tokenizer_kwargs={"padding_side": "left", "trust_remote_code": True},
|
| 70 |
+
trust_remote_code=True
|
| 71 |
+
)
|
| 72 |
+
|
| 73 |
+
task= "Given a web search query, retrieve relevant passages that answer the query"
|
| 74 |
+
queries = [
|
| 75 |
+
get_prompteol_input(get_detailed_instruct(task, "光合作用是什么?")),
|
| 76 |
+
get_prompteol_input(get_detailed_instruct(task, "电话是谁发明的?"))
|
| 77 |
+
]
|
| 78 |
+
|
| 79 |
+
documents = [
|
| 80 |
+
get_prompteol_input("光合作用是绿色植物利用阳光、二氧化碳和水生成葡萄糖和氧气的过程。这一生化反应发生在叶绿体中。"),
|
| 81 |
+
get_prompteol_input("亚历山大·格拉汉姆·贝尔(Alexander Graham Bell)因于1876年发明了第一台实用电话而广受认可,并为此设备获得了美国专利第174,465号。")
|
| 82 |
+
]
|
| 83 |
+
|
| 84 |
+
query_embeddings = model.encode(queries, normalize_embeddings=False)
|
| 85 |
+
document_embeddings = model.encode(documents, normalize_embeddings=False)
|
| 86 |
+
|
| 87 |
+
dim=1792 # 128, 256, 512, 768, 1024, 1280, 1536, 1792
|
| 88 |
+
query_embeddings = normalize(query_embeddings[:, :dim])
|
| 89 |
+
document_embeddings = normalize(document_embeddings[:, :dim])
|
| 90 |
+
|
| 91 |
+
similarity = model.similarity(query_embeddings, document_embeddings)
|
| 92 |
+
print(similarity)
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
### Completely replicate the benchmark results
|
| 96 |
+
|
| 97 |
+
```
|
| 98 |
+
normalize=true
|
| 99 |
+
use_instruction=true
|
| 100 |
+
export TOKENIZERS_PARALLELISM=true
|
| 101 |
+
embed_dim=1792 # 128, 256, 512, 768, 1024, 1280, 1536, 1792
|
| 102 |
+
|
| 103 |
+
model_name_or_path=<model dir>
|
| 104 |
+
|
| 105 |
+
python3 ./run_cmteb_all.py \
|
| 106 |
+
--model_name_or_path ${model_name_or_path} \
|
| 107 |
+
--normalize ${normalize} \
|
| 108 |
+
--dim ${embed_dim} \
|
| 109 |
+
--use_instruction ${use_instruction} \
|
| 110 |
+
--output_dir <output dir>
|
| 111 |
+
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
## Citation
|
| 116 |
+
If you find our work worth citing, please use the following citation:<br>
|
| 117 |
+
**Technical Report:**
|
| 118 |
+
```
|
| 119 |
+
@misc{yu2025qzhouembeddingtechnicalreport,
|
| 120 |
+
title={QZhou-Embedding Technical Report},
|
| 121 |
+
author={Peng Yu and En Xu and Bin Chen and Haibiao Chen and Yinfei Xu},
|
| 122 |
+
year={2025},
|
| 123 |
+
eprint={2508.21632},
|
| 124 |
+
archivePrefix={arXiv},
|
| 125 |
+
primaryClass={cs.CL},
|
| 126 |
+
url={https://arxiv.org/abs/2508.21632},
|
| 127 |
+
}
|
| 128 |
+
```
|
| 129 |
+
**Token Prepending: A Training-Free Approach for Eliciting Better Sentence Embeddings from LLMs:**
|
| 130 |
+
```
|
| 131 |
+
@inproceedings{fu-etal-2025-token,
|
| 132 |
+
title = "Token Prepending: A Training-Free Approach for Eliciting Better Sentence Embeddings from {LLM}s",
|
| 133 |
+
author = "Fu, Yuchen and
|
| 134 |
+
Cheng, Zifeng and
|
| 135 |
+
Jiang, Zhiwei and
|
| 136 |
+
Wang, Zhonghui and
|
| 137 |
+
Yin, Yafeng and
|
| 138 |
+
Li, Zhengliang and
|
| 139 |
+
Gu, Qing",
|
| 140 |
+
booktitle = "Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
|
| 141 |
+
month = jul,
|
| 142 |
+
year = "2025",
|
| 143 |
+
publisher = "Association for Computational Linguistics",
|
| 144 |
+
url = "https://aclanthology.org/2025.acl-long.159/",
|
| 145 |
+
}
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
+
**Qwen3 Series:**
|
| 149 |
+
```
|
| 150 |
+
@misc{qwen3technicalreport,
|
| 151 |
+
title={Qwen3 Technical Report},
|
| 152 |
+
author={Qwen Team},
|
| 153 |
+
year={2025},
|
| 154 |
+
eprint={2505.09388},
|
| 155 |
+
archivePrefix={arXiv},
|
| 156 |
+
primaryClass={cs.CL},
|
| 157 |
+
url={https://arxiv.org/abs/2505.09388},
|
| 158 |
+
}
|
| 159 |
+
```
|
added_tokens.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</think>": 151668,
|
| 3 |
+
"</tool_call>": 151658,
|
| 4 |
+
"</tool_response>": 151666,
|
| 5 |
+
"<think>": 151667,
|
| 6 |
+
"<tool_call>": 151657,
|
| 7 |
+
"<tool_response>": 151665,
|
| 8 |
+
"<|box_end|>": 151649,
|
| 9 |
+
"<|box_start|>": 151648,
|
| 10 |
+
"<|endoftext|>": 151643,
|
| 11 |
+
"<|file_sep|>": 151664,
|
| 12 |
+
"<|fim_middle|>": 151660,
|
| 13 |
+
"<|fim_pad|>": 151662,
|
| 14 |
+
"<|fim_prefix|>": 151659,
|
| 15 |
+
"<|fim_suffix|>": 151661,
|
| 16 |
+
"<|im_end|>": 151645,
|
| 17 |
+
"<|im_start|>": 151644,
|
| 18 |
+
"<|image_pad|>": 151655,
|
| 19 |
+
"<|object_ref_end|>": 151647,
|
| 20 |
+
"<|object_ref_start|>": 151646,
|
| 21 |
+
"<|quad_end|>": 151651,
|
| 22 |
+
"<|quad_start|>": 151650,
|
| 23 |
+
"<|repo_name|>": 151663,
|
| 24 |
+
"<|video_pad|>": 151656,
|
| 25 |
+
"<|vision_end|>": 151653,
|
| 26 |
+
"<|vision_pad|>": 151654,
|
| 27 |
+
"<|vision_start|>": 151652
|
| 28 |
+
}
|
assets/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
assets/1.png
ADDED
|
config.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"QZhouModel"
|
| 4 |
+
],
|
| 5 |
+
"attention_bias": false,
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"auto_map": {
|
| 8 |
+
"AutoModel": "modeling_qzhou.QZhouModel"
|
| 9 |
+
},
|
| 10 |
+
"bos_token_id": 151643,
|
| 11 |
+
"eos_token_id": 151645,
|
| 12 |
+
"head_dim": 128,
|
| 13 |
+
"hidden_act": "silu",
|
| 14 |
+
"hidden_size": 4096,
|
| 15 |
+
"initializer_range": 0.02,
|
| 16 |
+
"intermediate_size": 12288,
|
| 17 |
+
"max_position_embeddings": 40960,
|
| 18 |
+
"max_window_layers": 36,
|
| 19 |
+
"model_type": "qwen3",
|
| 20 |
+
"num_attention_heads": 32,
|
| 21 |
+
"num_hidden_layers": 36,
|
| 22 |
+
"num_key_value_heads": 8,
|
| 23 |
+
"rms_norm_eps": 1e-06,
|
| 24 |
+
"rope_scaling": null,
|
| 25 |
+
"rope_theta": 1000000,
|
| 26 |
+
"sliding_window": null,
|
| 27 |
+
"tie_word_embeddings": false,
|
| 28 |
+
"torch_dtype": "bfloat16",
|
| 29 |
+
"transformers_version": "4.51.1",
|
| 30 |
+
"use_cache": true,
|
| 31 |
+
"use_sliding_window": false,
|
| 32 |
+
"vocab_size": 151936
|
| 33 |
+
}
|
config_sentence_transformers.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"__version__": {
|
| 3 |
+
"sentence_transformers": "3.4.1",
|
| 4 |
+
"transformers": "4.51.1",
|
| 5 |
+
"pytorch": "2.4.1+cu121"
|
| 6 |
+
},
|
| 7 |
+
"prompts": {},
|
| 8 |
+
"default_prompt_name": null,
|
| 9 |
+
"similarity_fn_name": "cosine"
|
| 10 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model-00001-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9b3ccd3acd3e1f5a508f1bd46b18318a4a3fafa9d90d852fc614825a33da4415
|
| 3 |
+
size 4902257056
|
model-00002-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e35325a89c3985669f0f4e7260593795b4e7f6e0fdd181d68593d7b50cf5a08e
|
| 3 |
+
size 4915959512
|
model-00003-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:50ae96454c69200c2f374ed3d3beb3f94739dc8970841eff4e8df8d30b958b40
|
| 3 |
+
size 4983067656
|
model-00004-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d0e76ec8c207af961424def0386393b37051fab776b73c1091c8146c20903de3
|
| 3 |
+
size 335570376
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,405 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 15136811008
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"embed_tokens.weight": "model-00001-of-00004.safetensors",
|
| 7 |
+
"layers.0.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 8 |
+
"layers.0.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 9 |
+
"layers.0.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 10 |
+
"layers.0.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 11 |
+
"layers.0.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 12 |
+
"layers.0.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 13 |
+
"layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 14 |
+
"layers.0.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 15 |
+
"layers.0.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 16 |
+
"layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 17 |
+
"layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 18 |
+
"layers.1.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 19 |
+
"layers.1.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 20 |
+
"layers.1.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 21 |
+
"layers.1.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 22 |
+
"layers.1.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 23 |
+
"layers.1.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 24 |
+
"layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 25 |
+
"layers.1.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 26 |
+
"layers.1.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 27 |
+
"layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 28 |
+
"layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 29 |
+
"layers.10.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 30 |
+
"layers.10.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 31 |
+
"layers.10.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 32 |
+
"layers.10.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 33 |
+
"layers.10.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 34 |
+
"layers.10.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 35 |
+
"layers.10.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 36 |
+
"layers.10.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 37 |
+
"layers.10.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 38 |
+
"layers.10.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 39 |
+
"layers.10.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 40 |
+
"layers.11.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 41 |
+
"layers.11.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 42 |
+
"layers.11.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 43 |
+
"layers.11.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 44 |
+
"layers.11.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 45 |
+
"layers.11.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 46 |
+
"layers.11.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 47 |
+
"layers.11.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 48 |
+
"layers.11.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 49 |
+
"layers.11.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 50 |
+
"layers.11.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 51 |
+
"layers.12.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 52 |
+
"layers.12.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 53 |
+
"layers.12.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 54 |
+
"layers.12.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 55 |
+
"layers.12.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 56 |
+
"layers.12.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 57 |
+
"layers.12.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 58 |
+
"layers.12.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 59 |
+
"layers.12.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 60 |
+
"layers.12.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 61 |
+
"layers.12.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 62 |
+
"layers.13.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 63 |
+
"layers.13.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 64 |
+
"layers.13.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 65 |
+
"layers.13.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 66 |
+
"layers.13.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 67 |
+
"layers.13.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 68 |
+
"layers.13.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 69 |
+
"layers.13.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 70 |
+
"layers.13.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 71 |
+
"layers.13.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 72 |
+
"layers.13.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 73 |
+
"layers.14.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 74 |
+
"layers.14.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 75 |
+
"layers.14.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 76 |
+
"layers.14.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 77 |
+
"layers.14.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 78 |
+
"layers.14.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 79 |
+
"layers.14.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 80 |
+
"layers.14.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 81 |
+
"layers.14.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 82 |
+
"layers.14.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 83 |
+
"layers.14.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 84 |
+
"layers.15.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 85 |
+
"layers.15.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 86 |
+
"layers.15.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 87 |
+
"layers.15.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 88 |
+
"layers.15.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 89 |
+
"layers.15.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 90 |
+
"layers.15.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 91 |
+
"layers.15.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 92 |
+
"layers.15.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 93 |
+
"layers.15.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 94 |
+
"layers.15.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 95 |
+
"layers.16.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 96 |
+
"layers.16.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 97 |
+
"layers.16.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 98 |
+
"layers.16.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 99 |
+
"layers.16.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 100 |
+
"layers.16.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 101 |
+
"layers.16.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 102 |
+
"layers.16.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 103 |
+
"layers.16.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 104 |
+
"layers.16.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 105 |
+
"layers.16.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 106 |
+
"layers.17.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 107 |
+
"layers.17.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 108 |
+
"layers.17.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 109 |
+
"layers.17.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 110 |
+
"layers.17.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 111 |
+
"layers.17.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 112 |
+
"layers.17.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 113 |
+
"layers.17.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 114 |
+
"layers.17.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 115 |
+
"layers.17.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 116 |
+
"layers.17.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 117 |
+
"layers.18.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 118 |
+
"layers.18.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 119 |
+
"layers.18.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 120 |
+
"layers.18.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 121 |
+
"layers.18.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 122 |
+
"layers.18.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 123 |
+
"layers.18.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 124 |
+
"layers.18.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 125 |
+
"layers.18.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 126 |
+
"layers.18.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 127 |
+
"layers.18.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 128 |
+
"layers.19.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 129 |
+
"layers.19.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 130 |
+
"layers.19.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 131 |
+
"layers.19.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 132 |
+
"layers.19.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 133 |
+
"layers.19.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 134 |
+
"layers.19.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 135 |
+
"layers.19.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 136 |
+
"layers.19.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 137 |
+
"layers.19.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 138 |
+
"layers.19.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 139 |
+
"layers.2.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 140 |
+
"layers.2.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 141 |
+
"layers.2.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 142 |
+
"layers.2.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 143 |
+
"layers.2.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 144 |
+
"layers.2.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 145 |
+
"layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 146 |
+
"layers.2.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 147 |
+
"layers.2.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 148 |
+
"layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 149 |
+
"layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 150 |
+
"layers.20.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 151 |
+
"layers.20.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 152 |
+
"layers.20.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 153 |
+
"layers.20.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 154 |
+
"layers.20.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 155 |
+
"layers.20.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 156 |
+
"layers.20.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 157 |
+
"layers.20.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 158 |
+
"layers.20.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 159 |
+
"layers.20.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 160 |
+
"layers.20.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 161 |
+
"layers.21.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 162 |
+
"layers.21.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 163 |
+
"layers.21.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 164 |
+
"layers.21.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 165 |
+
"layers.21.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 166 |
+
"layers.21.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 167 |
+
"layers.21.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 168 |
+
"layers.21.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 169 |
+
"layers.21.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 170 |
+
"layers.21.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 171 |
+
"layers.21.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 172 |
+
"layers.22.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 173 |
+
"layers.22.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 174 |
+
"layers.22.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 175 |
+
"layers.22.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 176 |
+
"layers.22.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 177 |
+
"layers.22.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 178 |
+
"layers.22.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 179 |
+
"layers.22.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 180 |
+
"layers.22.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 181 |
+
"layers.22.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 182 |
+
"layers.22.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 183 |
+
"layers.23.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 184 |
+
"layers.23.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 185 |
+
"layers.23.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 186 |
+
"layers.23.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 187 |
+
"layers.23.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 188 |
+
"layers.23.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 189 |
+
"layers.23.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 190 |
+
"layers.23.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 191 |
+
"layers.23.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 192 |
+
"layers.23.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 193 |
+
"layers.23.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 194 |
+
"layers.24.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 195 |
+
"layers.24.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 196 |
+
"layers.24.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 197 |
+
"layers.24.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 198 |
+
"layers.24.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 199 |
+
"layers.24.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 200 |
+
"layers.24.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 201 |
+
"layers.24.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 202 |
+
"layers.24.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 203 |
+
"layers.24.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 204 |
+
"layers.24.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 205 |
+
"layers.25.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 206 |
+
"layers.25.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 207 |
+
"layers.25.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 208 |
+
"layers.25.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 209 |
+
"layers.25.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 210 |
+
"layers.25.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 211 |
+
"layers.25.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 212 |
+
"layers.25.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 213 |
+
"layers.25.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 214 |
+
"layers.25.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 215 |
+
"layers.25.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 216 |
+
"layers.26.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 217 |
+
"layers.26.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 218 |
+
"layers.26.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 219 |
+
"layers.26.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 220 |
+
"layers.26.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 221 |
+
"layers.26.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 222 |
+
"layers.26.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 223 |
+
"layers.26.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 224 |
+
"layers.26.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 225 |
+
"layers.26.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 226 |
+
"layers.26.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 227 |
+
"layers.27.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 228 |
+
"layers.27.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 229 |
+
"layers.27.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 230 |
+
"layers.27.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 231 |
+
"layers.27.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 232 |
+
"layers.27.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 233 |
+
"layers.27.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 234 |
+
"layers.27.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 235 |
+
"layers.27.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 236 |
+
"layers.27.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 237 |
+
"layers.27.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 238 |
+
"layers.28.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 239 |
+
"layers.28.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 240 |
+
"layers.28.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 241 |
+
"layers.28.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 242 |
+
"layers.28.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 243 |
+
"layers.28.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 244 |
+
"layers.28.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 245 |
+
"layers.28.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 246 |
+
"layers.28.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 247 |
+
"layers.28.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 248 |
+
"layers.28.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 249 |
+
"layers.29.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 250 |
+
"layers.29.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 251 |
+
"layers.29.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 252 |
+
"layers.29.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 253 |
+
"layers.29.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 254 |
+
"layers.29.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 255 |
+
"layers.29.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 256 |
+
"layers.29.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 257 |
+
"layers.29.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 258 |
+
"layers.29.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 259 |
+
"layers.29.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 260 |
+
"layers.3.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 261 |
+
"layers.3.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 262 |
+
"layers.3.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 263 |
+
"layers.3.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 264 |
+
"layers.3.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 265 |
+
"layers.3.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 266 |
+
"layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 267 |
+
"layers.3.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 268 |
+
"layers.3.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 269 |
+
"layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 270 |
+
"layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 271 |
+
"layers.30.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 272 |
+
"layers.30.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 273 |
+
"layers.30.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 274 |
+
"layers.30.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 275 |
+
"layers.30.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 276 |
+
"layers.30.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 277 |
+
"layers.30.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 278 |
+
"layers.30.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 279 |
+
"layers.30.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 280 |
+
"layers.30.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 281 |
+
"layers.30.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 282 |
+
"layers.31.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 283 |
+
"layers.31.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 284 |
+
"layers.31.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 285 |
+
"layers.31.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 286 |
+
"layers.31.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 287 |
+
"layers.31.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 288 |
+
"layers.31.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 289 |
+
"layers.31.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 290 |
+
"layers.31.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 291 |
+
"layers.31.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 292 |
+
"layers.31.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 293 |
+
"layers.32.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 294 |
+
"layers.32.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 295 |
+
"layers.32.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 296 |
+
"layers.32.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 297 |
+
"layers.32.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 298 |
+
"layers.32.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 299 |
+
"layers.32.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 300 |
+
"layers.32.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 301 |
+
"layers.32.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 302 |
+
"layers.32.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 303 |
+
"layers.32.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 304 |
+
"layers.33.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 305 |
+
"layers.33.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 306 |
+
"layers.33.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 307 |
+
"layers.33.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 308 |
+
"layers.33.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 309 |
+
"layers.33.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 310 |
+
"layers.33.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 311 |
+
"layers.33.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 312 |
+
"layers.33.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 313 |
+
"layers.33.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 314 |
+
"layers.33.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 315 |
+
"layers.34.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 316 |
+
"layers.34.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 317 |
+
"layers.34.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 318 |
+
"layers.34.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 319 |
+
"layers.34.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 320 |
+
"layers.34.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 321 |
+
"layers.34.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 322 |
+
"layers.34.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 323 |
+
"layers.34.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 324 |
+
"layers.34.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 325 |
+
"layers.34.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 326 |
+
"layers.35.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 327 |
+
"layers.35.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
| 328 |
+
"layers.35.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
| 329 |
+
"layers.35.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
| 330 |
+
"layers.35.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 331 |
+
"layers.35.self_attn.k_norm.weight": "model-00004-of-00004.safetensors",
|
| 332 |
+
"layers.35.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 333 |
+
"layers.35.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
| 334 |
+
"layers.35.self_attn.q_norm.weight": "model-00004-of-00004.safetensors",
|
| 335 |
+
"layers.35.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 336 |
+
"layers.35.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 337 |
+
"layers.4.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 338 |
+
"layers.4.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 339 |
+
"layers.4.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 340 |
+
"layers.4.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 341 |
+
"layers.4.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 342 |
+
"layers.4.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 343 |
+
"layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 344 |
+
"layers.4.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 345 |
+
"layers.4.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 346 |
+
"layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 347 |
+
"layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 348 |
+
"layers.5.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 349 |
+
"layers.5.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 350 |
+
"layers.5.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 351 |
+
"layers.5.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 352 |
+
"layers.5.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 353 |
+
"layers.5.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 354 |
+
"layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 355 |
+
"layers.5.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 356 |
+
"layers.5.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 357 |
+
"layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 358 |
+
"layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 359 |
+
"layers.6.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 360 |
+
"layers.6.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 361 |
+
"layers.6.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 362 |
+
"layers.6.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 363 |
+
"layers.6.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 364 |
+
"layers.6.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 365 |
+
"layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 366 |
+
"layers.6.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 367 |
+
"layers.6.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 368 |
+
"layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 369 |
+
"layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 370 |
+
"layers.7.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 371 |
+
"layers.7.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 372 |
+
"layers.7.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 373 |
+
"layers.7.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 374 |
+
"layers.7.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 375 |
+
"layers.7.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 376 |
+
"layers.7.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 377 |
+
"layers.7.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 378 |
+
"layers.7.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 379 |
+
"layers.7.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 380 |
+
"layers.7.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 381 |
+
"layers.8.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 382 |
+
"layers.8.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 383 |
+
"layers.8.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 384 |
+
"layers.8.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 385 |
+
"layers.8.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 386 |
+
"layers.8.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 387 |
+
"layers.8.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 388 |
+
"layers.8.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 389 |
+
"layers.8.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 390 |
+
"layers.8.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 391 |
+
"layers.8.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 392 |
+
"layers.9.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 393 |
+
"layers.9.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 394 |
+
"layers.9.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 395 |
+
"layers.9.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 396 |
+
"layers.9.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 397 |
+
"layers.9.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 398 |
+
"layers.9.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 399 |
+
"layers.9.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 400 |
+
"layers.9.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 401 |
+
"layers.9.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 402 |
+
"layers.9.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 403 |
+
"norm.weight": "model-00004-of-00004.safetensors"
|
| 404 |
+
}
|
| 405 |
+
}
|
modeling_qzhou.py
ADDED
|
@@ -0,0 +1,664 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from functools import partial
|
| 3 |
+
from typing import Callable, Optional, Tuple, Union
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
from torch import nn
|
| 7 |
+
|
| 8 |
+
from transformers.activations import ACT2FN
|
| 9 |
+
from transformers.cache_utils import Cache, DynamicCache, SlidingWindowCache, StaticCache
|
| 10 |
+
from transformers.generation import GenerationMixin
|
| 11 |
+
from transformers.modeling_attn_mask_utils import AttentionMaskConverter
|
| 12 |
+
from transformers.modeling_flash_attention_utils import FlashAttentionKwargs
|
| 13 |
+
from transformers.modeling_outputs import (
|
| 14 |
+
BaseModelOutputWithPast,
|
| 15 |
+
CausalLMOutputWithPast,
|
| 16 |
+
QuestionAnsweringModelOutput,
|
| 17 |
+
SequenceClassifierOutputWithPast,
|
| 18 |
+
TokenClassifierOutput,
|
| 19 |
+
)
|
| 20 |
+
from transformers.modeling_rope_utils import ROPE_INIT_FUNCTIONS, dynamic_rope_update
|
| 21 |
+
from transformers.modeling_utils import ALL_ATTENTION_FUNCTIONS, PreTrainedModel
|
| 22 |
+
from transformers.processing_utils import Unpack
|
| 23 |
+
from transformers.utils import (
|
| 24 |
+
LossKwargs,
|
| 25 |
+
can_return_tuple,
|
| 26 |
+
logging,
|
| 27 |
+
replace_return_docstrings,
|
| 28 |
+
)
|
| 29 |
+
from transformers.utils.deprecation import deprecate_kwarg
|
| 30 |
+
from transformers.models.qwen3.configuration_qwen3 import Qwen3Config
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
logger = logging.get_logger(__name__)
|
| 34 |
+
|
| 35 |
+
_CHECKPOINT_FOR_DOC = "Qwen/Qwen3-8B"
|
| 36 |
+
_CONFIG_FOR_DOC = "Qwen3Config"
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class Qwen3RMSNorm(nn.Module):
|
| 40 |
+
def __init__(self, hidden_size, eps=1e-6):
|
| 41 |
+
"""
|
| 42 |
+
Qwen3RMSNorm is equivalent to T5LayerNorm
|
| 43 |
+
"""
|
| 44 |
+
super().__init__()
|
| 45 |
+
self.weight = nn.Parameter(torch.ones(hidden_size))
|
| 46 |
+
self.variance_epsilon = eps
|
| 47 |
+
|
| 48 |
+
def forward(self, hidden_states):
|
| 49 |
+
input_dtype = hidden_states.dtype
|
| 50 |
+
hidden_states = hidden_states.to(torch.float32)
|
| 51 |
+
variance = hidden_states.pow(2).mean(-1, keepdim=True)
|
| 52 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
|
| 53 |
+
return self.weight * hidden_states.to(input_dtype)
|
| 54 |
+
|
| 55 |
+
def extra_repr(self):
|
| 56 |
+
return f"{tuple(self.weight.shape)}, eps={self.variance_epsilon}"
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
class Qwen3MLP(nn.Module):
|
| 60 |
+
def __init__(self, config):
|
| 61 |
+
super().__init__()
|
| 62 |
+
self.config = config
|
| 63 |
+
self.hidden_size = config.hidden_size
|
| 64 |
+
self.intermediate_size = config.intermediate_size
|
| 65 |
+
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 66 |
+
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 67 |
+
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
| 68 |
+
self.act_fn = ACT2FN[config.hidden_act]
|
| 69 |
+
|
| 70 |
+
def forward(self, x):
|
| 71 |
+
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
|
| 72 |
+
return down_proj
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def rotate_half(x):
|
| 76 |
+
"""Rotates half the hidden dims of the input."""
|
| 77 |
+
x1 = x[..., : x.shape[-1] // 2]
|
| 78 |
+
x2 = x[..., x.shape[-1] // 2 :]
|
| 79 |
+
return torch.cat((-x2, x1), dim=-1)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
|
| 83 |
+
"""Applies Rotary Position Embedding to the query and key tensors.
|
| 84 |
+
|
| 85 |
+
Args:
|
| 86 |
+
q (`torch.Tensor`): The query tensor.
|
| 87 |
+
k (`torch.Tensor`): The key tensor.
|
| 88 |
+
cos (`torch.Tensor`): The cosine part of the rotary embedding.
|
| 89 |
+
sin (`torch.Tensor`): The sine part of the rotary embedding.
|
| 90 |
+
position_ids (`torch.Tensor`, *optional*):
|
| 91 |
+
Deprecated and unused.
|
| 92 |
+
unsqueeze_dim (`int`, *optional*, defaults to 1):
|
| 93 |
+
The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
|
| 94 |
+
sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
|
| 95 |
+
that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
|
| 96 |
+
k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
|
| 97 |
+
cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
|
| 98 |
+
the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
|
| 99 |
+
Returns:
|
| 100 |
+
`tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
|
| 101 |
+
"""
|
| 102 |
+
cos = cos.unsqueeze(unsqueeze_dim)
|
| 103 |
+
sin = sin.unsqueeze(unsqueeze_dim)
|
| 104 |
+
q_embed = (q * cos) + (rotate_half(q) * sin)
|
| 105 |
+
k_embed = (k * cos) + (rotate_half(k) * sin)
|
| 106 |
+
return q_embed, k_embed
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
| 110 |
+
"""
|
| 111 |
+
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
| 112 |
+
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
| 113 |
+
"""
|
| 114 |
+
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
|
| 115 |
+
if n_rep == 1:
|
| 116 |
+
return hidden_states
|
| 117 |
+
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
|
| 118 |
+
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def eager_attention_forward(
|
| 122 |
+
module: nn.Module,
|
| 123 |
+
query: torch.Tensor,
|
| 124 |
+
key: torch.Tensor,
|
| 125 |
+
value: torch.Tensor,
|
| 126 |
+
attention_mask: Optional[torch.Tensor],
|
| 127 |
+
scaling: float,
|
| 128 |
+
dropout: float = 0.0,
|
| 129 |
+
**kwargs,
|
| 130 |
+
):
|
| 131 |
+
key_states = repeat_kv(key, module.num_key_value_groups)
|
| 132 |
+
value_states = repeat_kv(value, module.num_key_value_groups)
|
| 133 |
+
|
| 134 |
+
attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
|
| 135 |
+
if attention_mask is not None:
|
| 136 |
+
causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
|
| 137 |
+
attn_weights = attn_weights + causal_mask
|
| 138 |
+
|
| 139 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
|
| 140 |
+
attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
|
| 141 |
+
attn_output = torch.matmul(attn_weights, value_states)
|
| 142 |
+
attn_output = attn_output.transpose(1, 2).contiguous()
|
| 143 |
+
|
| 144 |
+
return attn_output, attn_weights
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
class Qwen3Attention(nn.Module):
|
| 148 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 149 |
+
|
| 150 |
+
def __init__(self, config: Qwen3Config, layer_idx: int):
|
| 151 |
+
super().__init__()
|
| 152 |
+
self.config = config
|
| 153 |
+
self.layer_idx = layer_idx
|
| 154 |
+
self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
|
| 155 |
+
self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
|
| 156 |
+
self.scaling = self.head_dim**-0.5
|
| 157 |
+
self.attention_dropout = config.attention_dropout
|
| 158 |
+
self.is_causal = True
|
| 159 |
+
|
| 160 |
+
self.q_proj = nn.Linear(
|
| 161 |
+
config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
|
| 162 |
+
)
|
| 163 |
+
self.k_proj = nn.Linear(
|
| 164 |
+
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
|
| 165 |
+
)
|
| 166 |
+
self.v_proj = nn.Linear(
|
| 167 |
+
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
|
| 168 |
+
)
|
| 169 |
+
self.o_proj = nn.Linear(
|
| 170 |
+
config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
|
| 171 |
+
)
|
| 172 |
+
self.q_norm = Qwen3RMSNorm(self.head_dim, eps=config.rms_norm_eps) # unlike olmo, only on the head dim!
|
| 173 |
+
self.k_norm = Qwen3RMSNorm(self.head_dim, eps=config.rms_norm_eps) # thus post q_norm does not need reshape
|
| 174 |
+
self.sliding_window = config.sliding_window
|
| 175 |
+
if not (
|
| 176 |
+
self.config.use_sliding_window
|
| 177 |
+
and getattr(self.config, "sliding_window", None) is not None
|
| 178 |
+
and self.layer_idx >= self.config.max_window_layers
|
| 179 |
+
):
|
| 180 |
+
self.sliding_window = None
|
| 181 |
+
|
| 182 |
+
def forward(
|
| 183 |
+
self,
|
| 184 |
+
hidden_states: torch.Tensor,
|
| 185 |
+
position_embeddings: Tuple[torch.Tensor, torch.Tensor],
|
| 186 |
+
attention_mask: Optional[torch.Tensor],
|
| 187 |
+
past_key_value: Optional[Cache] = None,
|
| 188 |
+
cache_position: Optional[torch.LongTensor] = None,
|
| 189 |
+
**kwargs: Unpack[FlashAttentionKwargs],
|
| 190 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 191 |
+
input_shape = hidden_states.shape[:-1]
|
| 192 |
+
hidden_shape = (*input_shape, -1, self.head_dim)
|
| 193 |
+
|
| 194 |
+
query_states = self.q_norm(self.q_proj(hidden_states).view(hidden_shape)).transpose(1, 2)
|
| 195 |
+
key_states = self.k_norm(self.k_proj(hidden_states).view(hidden_shape)).transpose(1, 2)
|
| 196 |
+
value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
|
| 197 |
+
|
| 198 |
+
cos, sin = position_embeddings
|
| 199 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
|
| 200 |
+
|
| 201 |
+
if past_key_value is not None:
|
| 202 |
+
# sin and cos are specific to RoPE models; cache_position needed for the static cache
|
| 203 |
+
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
|
| 204 |
+
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
|
| 205 |
+
|
| 206 |
+
attention_interface: Callable = eager_attention_forward
|
| 207 |
+
if self.config._attn_implementation != "eager":
|
| 208 |
+
if self.config._attn_implementation == "sdpa" and kwargs.get("output_attentions", False):
|
| 209 |
+
logger.warning_once(
|
| 210 |
+
"`torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to "
|
| 211 |
+
'eager attention. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
|
| 212 |
+
)
|
| 213 |
+
else:
|
| 214 |
+
attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
|
| 215 |
+
|
| 216 |
+
attn_output, attn_weights = attention_interface(
|
| 217 |
+
self,
|
| 218 |
+
query_states,
|
| 219 |
+
key_states,
|
| 220 |
+
value_states,
|
| 221 |
+
attention_mask,
|
| 222 |
+
dropout=0.0 if not self.training else self.attention_dropout,
|
| 223 |
+
scaling=self.scaling,
|
| 224 |
+
sliding_window=self.sliding_window, # diff with Llama
|
| 225 |
+
**kwargs,
|
| 226 |
+
)
|
| 227 |
+
|
| 228 |
+
attn_output = attn_output.reshape(*input_shape, -1).contiguous()
|
| 229 |
+
|
| 230 |
+
attn_output = self.o_proj(attn_output)
|
| 231 |
+
return attn_output, attn_weights
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
class Qwen3DecoderLayer(nn.Module):
|
| 235 |
+
def __init__(self, config: Qwen3Config, layer_idx: int):
|
| 236 |
+
super().__init__()
|
| 237 |
+
self.hidden_size = config.hidden_size
|
| 238 |
+
self.self_attn = Qwen3Attention(config=config, layer_idx=layer_idx)
|
| 239 |
+
self.mlp = Qwen3MLP(config)
|
| 240 |
+
self.input_layernorm = Qwen3RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 241 |
+
self.post_attention_layernorm = Qwen3RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 242 |
+
if (
|
| 243 |
+
config.sliding_window and config._attn_implementation != "flash_attention_2"
|
| 244 |
+
): # diff with Llama is this warning
|
| 245 |
+
logger.warning_once(
|
| 246 |
+
f"Sliding Window Attention is enabled but not implemented for `{config._attn_implementation}`; "
|
| 247 |
+
"unexpected results may be encountered."
|
| 248 |
+
)
|
| 249 |
+
|
| 250 |
+
def forward(
|
| 251 |
+
self,
|
| 252 |
+
hidden_states: torch.Tensor,
|
| 253 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 254 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 255 |
+
past_key_value: Optional[Cache] = None,
|
| 256 |
+
output_attentions: Optional[bool] = False,
|
| 257 |
+
use_cache: Optional[bool] = False,
|
| 258 |
+
cache_position: Optional[torch.LongTensor] = None,
|
| 259 |
+
position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, # necessary, but kept here for BC
|
| 260 |
+
**kwargs: Unpack[FlashAttentionKwargs],
|
| 261 |
+
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
| 262 |
+
residual = hidden_states
|
| 263 |
+
|
| 264 |
+
hidden_states = self.input_layernorm(hidden_states)
|
| 265 |
+
|
| 266 |
+
# Self Attention
|
| 267 |
+
hidden_states, self_attn_weights = self.self_attn(
|
| 268 |
+
hidden_states=hidden_states,
|
| 269 |
+
attention_mask=attention_mask,
|
| 270 |
+
position_ids=position_ids,
|
| 271 |
+
past_key_value=past_key_value,
|
| 272 |
+
output_attentions=output_attentions,
|
| 273 |
+
use_cache=use_cache,
|
| 274 |
+
cache_position=cache_position,
|
| 275 |
+
position_embeddings=position_embeddings,
|
| 276 |
+
**kwargs,
|
| 277 |
+
)
|
| 278 |
+
hidden_states = residual + hidden_states
|
| 279 |
+
|
| 280 |
+
# Fully Connected
|
| 281 |
+
residual = hidden_states
|
| 282 |
+
hidden_states = self.post_attention_layernorm(hidden_states)
|
| 283 |
+
hidden_states = self.mlp(hidden_states)
|
| 284 |
+
hidden_states = residual + hidden_states
|
| 285 |
+
|
| 286 |
+
outputs = (hidden_states,)
|
| 287 |
+
if output_attentions:
|
| 288 |
+
outputs += (self_attn_weights,)
|
| 289 |
+
|
| 290 |
+
return outputs
|
| 291 |
+
|
| 292 |
+
|
| 293 |
+
class Qwen3RotaryEmbedding(nn.Module):
|
| 294 |
+
def __init__(self, config: Qwen3Config, device=None):
|
| 295 |
+
super().__init__()
|
| 296 |
+
# BC: "rope_type" was originally "type"
|
| 297 |
+
if hasattr(config, "rope_scaling") and config.rope_scaling is not None:
|
| 298 |
+
self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
|
| 299 |
+
else:
|
| 300 |
+
self.rope_type = "default"
|
| 301 |
+
self.max_seq_len_cached = config.max_position_embeddings
|
| 302 |
+
self.original_max_seq_len = config.max_position_embeddings
|
| 303 |
+
|
| 304 |
+
self.config = config
|
| 305 |
+
self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
|
| 306 |
+
|
| 307 |
+
inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
|
| 308 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 309 |
+
self.original_inv_freq = self.inv_freq
|
| 310 |
+
|
| 311 |
+
@torch.no_grad()
|
| 312 |
+
@dynamic_rope_update # power user: used with advanced RoPE types (e.g. dynamic rope)
|
| 313 |
+
def forward(self, x, position_ids):
|
| 314 |
+
inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1).to(x.device)
|
| 315 |
+
position_ids_expanded = position_ids[:, None, :].float()
|
| 316 |
+
|
| 317 |
+
device_type = x.device.type if isinstance(x.device.type, str) and x.device.type != "mps" else "cpu"
|
| 318 |
+
with torch.autocast(device_type=device_type, enabled=False): # Force float32
|
| 319 |
+
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
|
| 320 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 321 |
+
cos = emb.cos() * self.attention_scaling
|
| 322 |
+
sin = emb.sin() * self.attention_scaling
|
| 323 |
+
|
| 324 |
+
return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
|
| 325 |
+
|
| 326 |
+
|
| 327 |
+
class Qwen3PreTrainedModel(PreTrainedModel):
|
| 328 |
+
config_class = Qwen3Config
|
| 329 |
+
base_model_prefix = "model"
|
| 330 |
+
supports_gradient_checkpointing = True
|
| 331 |
+
_no_split_modules = ["Qwen3DecoderLayer"]
|
| 332 |
+
_skip_keys_device_placement = ["past_key_values"]
|
| 333 |
+
_supports_flash_attn_2 = True
|
| 334 |
+
_supports_sdpa = True
|
| 335 |
+
_supports_flex_attn = True
|
| 336 |
+
_supports_cache_class = True
|
| 337 |
+
_supports_quantized_cache = True
|
| 338 |
+
_supports_static_cache = True
|
| 339 |
+
_supports_attention_backend = True
|
| 340 |
+
|
| 341 |
+
def _init_weights(self, module):
|
| 342 |
+
std = self.config.initializer_range
|
| 343 |
+
if isinstance(module, nn.Linear):
|
| 344 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 345 |
+
if module.bias is not None:
|
| 346 |
+
module.bias.data.zero_()
|
| 347 |
+
elif isinstance(module, nn.Embedding):
|
| 348 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 349 |
+
if module.padding_idx is not None:
|
| 350 |
+
module.weight.data[module.padding_idx].zero_()
|
| 351 |
+
|
| 352 |
+
|
| 353 |
+
def find_token_indices(input_ids, token=151644):
|
| 354 |
+
assert (input_ids == token).any(dim=1).all(), f"Not all sequences contain the token {token}"
|
| 355 |
+
|
| 356 |
+
mask = (input_ids == token)
|
| 357 |
+
mask_float = mask.float()
|
| 358 |
+
first_match_indices = mask_float.argmax(dim=1)
|
| 359 |
+
|
| 360 |
+
return first_match_indices
|
| 361 |
+
|
| 362 |
+
|
| 363 |
+
class QZhouModel(Qwen3PreTrainedModel): # QZhou_Model is built upon the Qwen3Model framework with TP modifications.
|
| 364 |
+
"""
|
| 365 |
+
Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`Qwen3DecoderLayer`]
|
| 366 |
+
|
| 367 |
+
Args:
|
| 368 |
+
config: Qwen3Config
|
| 369 |
+
"""
|
| 370 |
+
|
| 371 |
+
def __init__(self, config: Qwen3Config):
|
| 372 |
+
super().__init__(config)
|
| 373 |
+
self.padding_idx = config.pad_token_id
|
| 374 |
+
self.vocab_size = config.vocab_size
|
| 375 |
+
|
| 376 |
+
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
| 377 |
+
self.layers = nn.ModuleList(
|
| 378 |
+
[Qwen3DecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
|
| 379 |
+
)
|
| 380 |
+
self.norm = Qwen3RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 381 |
+
self.rotary_emb = Qwen3RotaryEmbedding(config=config)
|
| 382 |
+
self.gradient_checkpointing = False
|
| 383 |
+
|
| 384 |
+
# Initialize weights and apply final processing
|
| 385 |
+
self.post_init()
|
| 386 |
+
|
| 387 |
+
def get_input_embeddings(self):
|
| 388 |
+
return self.embed_tokens
|
| 389 |
+
|
| 390 |
+
def set_input_embeddings(self, value):
|
| 391 |
+
self.embed_tokens = value
|
| 392 |
+
|
| 393 |
+
@can_return_tuple
|
| 394 |
+
def forward(
|
| 395 |
+
self,
|
| 396 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 397 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 398 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 399 |
+
past_key_values: Optional[Cache] = None,
|
| 400 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 401 |
+
use_cache: Optional[bool] = None,
|
| 402 |
+
output_attentions: Optional[bool] = None,
|
| 403 |
+
output_hidden_states: Optional[bool] = None,
|
| 404 |
+
cache_position: Optional[torch.LongTensor] = None,
|
| 405 |
+
**flash_attn_kwargs: Unpack[FlashAttentionKwargs],
|
| 406 |
+
) -> BaseModelOutputWithPast:
|
| 407 |
+
|
| 408 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 409 |
+
output_hidden_states = (
|
| 410 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 411 |
+
)
|
| 412 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 413 |
+
|
| 414 |
+
if (input_ids is None) ^ (inputs_embeds is not None):
|
| 415 |
+
raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
|
| 416 |
+
|
| 417 |
+
if self.gradient_checkpointing and self.training and use_cache:
|
| 418 |
+
logger.warning_once(
|
| 419 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`."
|
| 420 |
+
)
|
| 421 |
+
use_cache = False
|
| 422 |
+
|
| 423 |
+
# TODO (joao): remove this exception in v4.56 -- it exists for users that try to pass a legacy cache
|
| 424 |
+
if not isinstance(past_key_values, (type(None), Cache)):
|
| 425 |
+
raise ValueError("The `past_key_values` should be either a `Cache` object or `None`.")
|
| 426 |
+
|
| 427 |
+
if inputs_embeds is None:
|
| 428 |
+
inputs_embeds = self.embed_tokens(input_ids)
|
| 429 |
+
|
| 430 |
+
if use_cache and past_key_values is None:
|
| 431 |
+
past_key_values = DynamicCache()
|
| 432 |
+
|
| 433 |
+
if cache_position is None:
|
| 434 |
+
past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
|
| 435 |
+
cache_position = torch.arange(
|
| 436 |
+
past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
|
| 437 |
+
)
|
| 438 |
+
|
| 439 |
+
if position_ids is None:
|
| 440 |
+
position_ids = cache_position.unsqueeze(0)
|
| 441 |
+
|
| 442 |
+
causal_mask = self._update_causal_mask(
|
| 443 |
+
attention_mask, inputs_embeds, cache_position, past_key_values, output_attentions
|
| 444 |
+
)
|
| 445 |
+
|
| 446 |
+
hidden_states = inputs_embeds
|
| 447 |
+
|
| 448 |
+
# create position embeddings to be shared across the decoder layers
|
| 449 |
+
position_embeddings = self.rotary_emb(hidden_states, position_ids)
|
| 450 |
+
|
| 451 |
+
# decoder layers
|
| 452 |
+
all_hidden_states = () if output_hidden_states else None
|
| 453 |
+
all_self_attns = () if output_attentions else None
|
| 454 |
+
|
| 455 |
+
|
| 456 |
+
pst_token_indices = find_token_indices(input_ids, token=151644)
|
| 457 |
+
for decoder_layer in self.layers[: self.config.num_hidden_layers]:
|
| 458 |
+
if decoder_layer.self_attn.layer_idx >=1 and decoder_layer.self_attn.layer_idx <= 7:
|
| 459 |
+
B = hidden_states.shape[0]
|
| 460 |
+
previous_sentence_embeddings = hidden_states[:, -1, :].clone()
|
| 461 |
+
hidden_states[torch.arange(B), pst_token_indices, :] = previous_sentence_embeddings
|
| 462 |
+
|
| 463 |
+
if output_hidden_states:
|
| 464 |
+
all_hidden_states += (hidden_states,)
|
| 465 |
+
|
| 466 |
+
if self.gradient_checkpointing and self.training:
|
| 467 |
+
layer_outputs = self._gradient_checkpointing_func(
|
| 468 |
+
partial(decoder_layer.__call__, **flash_attn_kwargs),
|
| 469 |
+
hidden_states,
|
| 470 |
+
causal_mask,
|
| 471 |
+
position_ids,
|
| 472 |
+
past_key_values,
|
| 473 |
+
output_attentions,
|
| 474 |
+
use_cache,
|
| 475 |
+
cache_position,
|
| 476 |
+
position_embeddings,
|
| 477 |
+
)
|
| 478 |
+
else:
|
| 479 |
+
layer_outputs = decoder_layer(
|
| 480 |
+
hidden_states,
|
| 481 |
+
attention_mask=causal_mask,
|
| 482 |
+
position_ids=position_ids,
|
| 483 |
+
past_key_value=past_key_values,
|
| 484 |
+
output_attentions=output_attentions,
|
| 485 |
+
use_cache=use_cache,
|
| 486 |
+
cache_position=cache_position,
|
| 487 |
+
position_embeddings=position_embeddings,
|
| 488 |
+
**flash_attn_kwargs,
|
| 489 |
+
)
|
| 490 |
+
|
| 491 |
+
hidden_states = layer_outputs[0]
|
| 492 |
+
|
| 493 |
+
if output_attentions:
|
| 494 |
+
all_self_attns += (layer_outputs[1],)
|
| 495 |
+
|
| 496 |
+
hidden_states = self.norm(hidden_states)
|
| 497 |
+
|
| 498 |
+
# add hidden states from the last decoder layer
|
| 499 |
+
if output_hidden_states:
|
| 500 |
+
all_hidden_states += (hidden_states,)
|
| 501 |
+
|
| 502 |
+
return BaseModelOutputWithPast(
|
| 503 |
+
last_hidden_state=hidden_states,
|
| 504 |
+
past_key_values=past_key_values if use_cache else None,
|
| 505 |
+
hidden_states=all_hidden_states,
|
| 506 |
+
attentions=all_self_attns,
|
| 507 |
+
)
|
| 508 |
+
|
| 509 |
+
def _update_causal_mask(
|
| 510 |
+
self,
|
| 511 |
+
attention_mask: torch.Tensor,
|
| 512 |
+
input_tensor: torch.Tensor,
|
| 513 |
+
cache_position: torch.Tensor,
|
| 514 |
+
past_key_values: Cache,
|
| 515 |
+
output_attentions: bool = False,
|
| 516 |
+
):
|
| 517 |
+
if self.config._attn_implementation == "flash_attention_2":
|
| 518 |
+
if attention_mask is not None and past_key_values is not None:
|
| 519 |
+
is_padding_right = attention_mask[:, -1].sum().item() != input_tensor.size()[0]
|
| 520 |
+
if is_padding_right:
|
| 521 |
+
raise ValueError(
|
| 522 |
+
"You are attempting to perform batched generation with padding_side='right'"
|
| 523 |
+
" this may lead to unexpected behaviour for Flash Attention version of Qwen3. Make sure to "
|
| 524 |
+
" call `tokenizer.padding_side = 'left'` before tokenizing the input. "
|
| 525 |
+
)
|
| 526 |
+
if attention_mask is not None and 0.0 in attention_mask:
|
| 527 |
+
return attention_mask
|
| 528 |
+
return None
|
| 529 |
+
|
| 530 |
+
# For SDPA, when possible, we will rely on its `is_causal` argument instead of its `attn_mask` argument, in
|
| 531 |
+
# order to dispatch on Flash Attention 2. This feature is not compatible with static cache, as SDPA will fail
|
| 532 |
+
# to infer the attention mask.
|
| 533 |
+
past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
|
| 534 |
+
using_static_cache = isinstance(past_key_values, StaticCache)
|
| 535 |
+
using_sliding_window_cache = isinstance(past_key_values, SlidingWindowCache)
|
| 536 |
+
|
| 537 |
+
# When output attentions is True, sdpa implementation's forward method calls the eager implementation's forward
|
| 538 |
+
if (
|
| 539 |
+
self.config._attn_implementation == "sdpa"
|
| 540 |
+
and not (using_static_cache or using_sliding_window_cache)
|
| 541 |
+
and not output_attentions
|
| 542 |
+
):
|
| 543 |
+
if AttentionMaskConverter._ignore_causal_mask_sdpa(
|
| 544 |
+
attention_mask,
|
| 545 |
+
inputs_embeds=input_tensor,
|
| 546 |
+
past_key_values_length=past_seen_tokens,
|
| 547 |
+
sliding_window=self.config.sliding_window,
|
| 548 |
+
is_training=self.training,
|
| 549 |
+
):
|
| 550 |
+
return None
|
| 551 |
+
|
| 552 |
+
dtype, device = input_tensor.dtype, input_tensor.device
|
| 553 |
+
min_dtype = torch.finfo(dtype).min
|
| 554 |
+
sequence_length = input_tensor.shape[1]
|
| 555 |
+
# SlidingWindowCache or StaticCache
|
| 556 |
+
if using_sliding_window_cache or using_static_cache:
|
| 557 |
+
target_length = past_key_values.get_max_cache_shape()
|
| 558 |
+
# DynamicCache or no cache
|
| 559 |
+
else:
|
| 560 |
+
target_length = (
|
| 561 |
+
attention_mask.shape[-1]
|
| 562 |
+
if isinstance(attention_mask, torch.Tensor)
|
| 563 |
+
else past_seen_tokens + sequence_length + 1
|
| 564 |
+
)
|
| 565 |
+
|
| 566 |
+
# In case the provided `attention` mask is 2D, we generate a causal mask here (4D).
|
| 567 |
+
causal_mask = self._prepare_4d_causal_attention_mask_with_cache_position(
|
| 568 |
+
attention_mask,
|
| 569 |
+
sequence_length=sequence_length,
|
| 570 |
+
target_length=target_length,
|
| 571 |
+
dtype=dtype,
|
| 572 |
+
device=device,
|
| 573 |
+
cache_position=cache_position,
|
| 574 |
+
batch_size=input_tensor.shape[0],
|
| 575 |
+
config=self.config,
|
| 576 |
+
past_key_values=past_key_values,
|
| 577 |
+
)
|
| 578 |
+
|
| 579 |
+
if (
|
| 580 |
+
self.config._attn_implementation == "sdpa"
|
| 581 |
+
and attention_mask is not None
|
| 582 |
+
and attention_mask.device.type in ["cuda", "xpu"]
|
| 583 |
+
and not output_attentions
|
| 584 |
+
):
|
| 585 |
+
# Attend to all tokens in fully masked rows in the causal_mask, for example the relevant first rows when
|
| 586 |
+
# using left padding. This is required by F.scaled_dot_product_attention memory-efficient attention path.
|
| 587 |
+
# Details: https://github.com/pytorch/pytorch/issues/110213
|
| 588 |
+
causal_mask = AttentionMaskConverter._unmask_unattended(causal_mask, min_dtype)
|
| 589 |
+
|
| 590 |
+
return causal_mask
|
| 591 |
+
|
| 592 |
+
@staticmethod
|
| 593 |
+
def _prepare_4d_causal_attention_mask_with_cache_position(
|
| 594 |
+
attention_mask: torch.Tensor,
|
| 595 |
+
sequence_length: int,
|
| 596 |
+
target_length: int,
|
| 597 |
+
dtype: torch.dtype,
|
| 598 |
+
device: torch.device,
|
| 599 |
+
cache_position: torch.Tensor,
|
| 600 |
+
batch_size: int,
|
| 601 |
+
config: Qwen3Config,
|
| 602 |
+
past_key_values: Cache,
|
| 603 |
+
):
|
| 604 |
+
"""
|
| 605 |
+
Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
|
| 606 |
+
`(batch_size, key_value_length)`, or if the input `attention_mask` is already 4D, do nothing.
|
| 607 |
+
|
| 608 |
+
Args:
|
| 609 |
+
attention_mask (`torch.Tensor`):
|
| 610 |
+
A 2D attention mask of shape `(batch_size, key_value_length)` or a 4D attention mask of shape `(batch_size, 1, query_length, key_value_length)`.
|
| 611 |
+
sequence_length (`int`):
|
| 612 |
+
The sequence length being processed.
|
| 613 |
+
target_length (`int`):
|
| 614 |
+
The target length: when generating with static cache, the mask should be as long as the static cache, to account for the 0 padding, the part of the cache that is not filled yet.
|
| 615 |
+
dtype (`torch.dtype`):
|
| 616 |
+
The dtype to use for the 4D attention mask.
|
| 617 |
+
device (`torch.device`):
|
| 618 |
+
The device to place the 4D attention mask on.
|
| 619 |
+
cache_position (`torch.Tensor`):
|
| 620 |
+
Indices depicting the position of the input sequence tokens in the sequence.
|
| 621 |
+
batch_size (`torch.Tensor`):
|
| 622 |
+
Batch size.
|
| 623 |
+
config (`Qwen3Config`):
|
| 624 |
+
The model's configuration class
|
| 625 |
+
past_key_values (`Cache`):
|
| 626 |
+
The cache class that is being used currently to generate
|
| 627 |
+
"""
|
| 628 |
+
if attention_mask is not None and attention_mask.dim() == 4:
|
| 629 |
+
# In this case we assume that the mask comes already in inverted form and requires no inversion or slicing.
|
| 630 |
+
causal_mask = attention_mask
|
| 631 |
+
else:
|
| 632 |
+
min_dtype = torch.finfo(dtype).min
|
| 633 |
+
causal_mask = torch.full(
|
| 634 |
+
(sequence_length, target_length), fill_value=min_dtype, dtype=dtype, device=device
|
| 635 |
+
)
|
| 636 |
+
diagonal_attend_mask = torch.arange(target_length, device=device) > cache_position.reshape(-1, 1)
|
| 637 |
+
if config.sliding_window is not None:
|
| 638 |
+
# if we have sliding window, we should not attend to tokens beyond sliding window length, so we mask them out also
|
| 639 |
+
# the check is needed to verify is current checkpoint was trained with sliding window or not
|
| 640 |
+
if not isinstance(past_key_values, SlidingWindowCache) or sequence_length > target_length:
|
| 641 |
+
sliding_attend_mask = torch.arange(target_length, device=device) <= (
|
| 642 |
+
cache_position.reshape(-1, 1) - config.sliding_window
|
| 643 |
+
)
|
| 644 |
+
diagonal_attend_mask.bitwise_or_(sliding_attend_mask)
|
| 645 |
+
causal_mask *= diagonal_attend_mask
|
| 646 |
+
causal_mask = causal_mask[None, None, :, :].expand(batch_size, 1, -1, -1)
|
| 647 |
+
if attention_mask is not None:
|
| 648 |
+
causal_mask = causal_mask.clone() # copy to contiguous memory for in-place edit
|
| 649 |
+
if attention_mask.shape[-1] > target_length:
|
| 650 |
+
attention_mask = attention_mask[:, :target_length]
|
| 651 |
+
mask_length = attention_mask.shape[-1]
|
| 652 |
+
padding_mask = causal_mask[:, :, :, :mask_length] + attention_mask[:, None, None, :].to(
|
| 653 |
+
causal_mask.device
|
| 654 |
+
)
|
| 655 |
+
padding_mask = padding_mask == 0
|
| 656 |
+
causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
|
| 657 |
+
padding_mask, min_dtype
|
| 658 |
+
)
|
| 659 |
+
return causal_mask
|
| 660 |
+
|
| 661 |
+
|
| 662 |
+
__all__ = [
|
| 663 |
+
"QZhouModel"
|
| 664 |
+
]
|
modules.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"idx": 0,
|
| 4 |
+
"name": "0",
|
| 5 |
+
"path": "",
|
| 6 |
+
"type": "sentence_transformers.models.Transformer"
|
| 7 |
+
},
|
| 8 |
+
{
|
| 9 |
+
"idx": 1,
|
| 10 |
+
"name": "1",
|
| 11 |
+
"path": "1_Pooling",
|
| 12 |
+
"type": "sentence_transformers.models.Pooling"
|
| 13 |
+
},
|
| 14 |
+
{
|
| 15 |
+
"idx": 2,
|
| 16 |
+
"name": "2",
|
| 17 |
+
"path": "2_Dense",
|
| 18 |
+
"type": "sentence_transformers.models.Dense"
|
| 19 |
+
}
|
| 20 |
+
]
|
sentence_bert_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"max_seq_length": 40960,
|
| 3 |
+
"do_lower_case": false
|
| 4 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>",
|
| 5 |
+
"<|object_ref_start|>",
|
| 6 |
+
"<|object_ref_end|>",
|
| 7 |
+
"<|box_start|>",
|
| 8 |
+
"<|box_end|>",
|
| 9 |
+
"<|quad_start|>",
|
| 10 |
+
"<|quad_end|>",
|
| 11 |
+
"<|vision_start|>",
|
| 12 |
+
"<|vision_end|>",
|
| 13 |
+
"<|vision_pad|>",
|
| 14 |
+
"<|image_pad|>",
|
| 15 |
+
"<|video_pad|>"
|
| 16 |
+
],
|
| 17 |
+
"eos_token": {
|
| 18 |
+
"content": "<|im_end|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
},
|
| 24 |
+
"pad_token": {
|
| 25 |
+
"content": "<|endoftext|>",
|
| 26 |
+
"lstrip": false,
|
| 27 |
+
"normalized": false,
|
| 28 |
+
"rstrip": false,
|
| 29 |
+
"single_word": false
|
| 30 |
+
}
|
| 31 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b326efa3b3cb974b258836e76f8a992c77a1fa93b9d9126a1632a416bf663a20
|
| 3 |
+
size 11422933
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,246 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_prefix_space": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"151643": {
|
| 6 |
+
"content": "<|endoftext|>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"151644": {
|
| 14 |
+
"content": "<|im_start|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"151645": {
|
| 22 |
+
"content": "<|im_end|>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"151646": {
|
| 30 |
+
"content": "<|object_ref_start|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
},
|
| 37 |
+
"151647": {
|
| 38 |
+
"content": "<|object_ref_end|>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": true
|
| 44 |
+
},
|
| 45 |
+
"151648": {
|
| 46 |
+
"content": "<|box_start|>",
|
| 47 |
+
"lstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"rstrip": false,
|
| 50 |
+
"single_word": false,
|
| 51 |
+
"special": true
|
| 52 |
+
},
|
| 53 |
+
"151649": {
|
| 54 |
+
"content": "<|box_end|>",
|
| 55 |
+
"lstrip": false,
|
| 56 |
+
"normalized": false,
|
| 57 |
+
"rstrip": false,
|
| 58 |
+
"single_word": false,
|
| 59 |
+
"special": true
|
| 60 |
+
},
|
| 61 |
+
"151650": {
|
| 62 |
+
"content": "<|quad_start|>",
|
| 63 |
+
"lstrip": false,
|
| 64 |
+
"normalized": false,
|
| 65 |
+
"rstrip": false,
|
| 66 |
+
"single_word": false,
|
| 67 |
+
"special": true
|
| 68 |
+
},
|
| 69 |
+
"151651": {
|
| 70 |
+
"content": "<|quad_end|>",
|
| 71 |
+
"lstrip": false,
|
| 72 |
+
"normalized": false,
|
| 73 |
+
"rstrip": false,
|
| 74 |
+
"single_word": false,
|
| 75 |
+
"special": true
|
| 76 |
+
},
|
| 77 |
+
"151652": {
|
| 78 |
+
"content": "<|vision_start|>",
|
| 79 |
+
"lstrip": false,
|
| 80 |
+
"normalized": false,
|
| 81 |
+
"rstrip": false,
|
| 82 |
+
"single_word": false,
|
| 83 |
+
"special": true
|
| 84 |
+
},
|
| 85 |
+
"151653": {
|
| 86 |
+
"content": "<|vision_end|>",
|
| 87 |
+
"lstrip": false,
|
| 88 |
+
"normalized": false,
|
| 89 |
+
"rstrip": false,
|
| 90 |
+
"single_word": false,
|
| 91 |
+
"special": true
|
| 92 |
+
},
|
| 93 |
+
"151654": {
|
| 94 |
+
"content": "<|vision_pad|>",
|
| 95 |
+
"lstrip": false,
|
| 96 |
+
"normalized": false,
|
| 97 |
+
"rstrip": false,
|
| 98 |
+
"single_word": false,
|
| 99 |
+
"special": true
|
| 100 |
+
},
|
| 101 |
+
"151655": {
|
| 102 |
+
"content": "<|image_pad|>",
|
| 103 |
+
"lstrip": false,
|
| 104 |
+
"normalized": false,
|
| 105 |
+
"rstrip": false,
|
| 106 |
+
"single_word": false,
|
| 107 |
+
"special": true
|
| 108 |
+
},
|
| 109 |
+
"151656": {
|
| 110 |
+
"content": "<|video_pad|>",
|
| 111 |
+
"lstrip": false,
|
| 112 |
+
"normalized": false,
|
| 113 |
+
"rstrip": false,
|
| 114 |
+
"single_word": false,
|
| 115 |
+
"special": true
|
| 116 |
+
},
|
| 117 |
+
"151657": {
|
| 118 |
+
"content": "<tool_call>",
|
| 119 |
+
"lstrip": false,
|
| 120 |
+
"normalized": false,
|
| 121 |
+
"rstrip": false,
|
| 122 |
+
"single_word": false,
|
| 123 |
+
"special": false
|
| 124 |
+
},
|
| 125 |
+
"151658": {
|
| 126 |
+
"content": "</tool_call>",
|
| 127 |
+
"lstrip": false,
|
| 128 |
+
"normalized": false,
|
| 129 |
+
"rstrip": false,
|
| 130 |
+
"single_word": false,
|
| 131 |
+
"special": false
|
| 132 |
+
},
|
| 133 |
+
"151659": {
|
| 134 |
+
"content": "<|fim_prefix|>",
|
| 135 |
+
"lstrip": false,
|
| 136 |
+
"normalized": false,
|
| 137 |
+
"rstrip": false,
|
| 138 |
+
"single_word": false,
|
| 139 |
+
"special": false
|
| 140 |
+
},
|
| 141 |
+
"151660": {
|
| 142 |
+
"content": "<|fim_middle|>",
|
| 143 |
+
"lstrip": false,
|
| 144 |
+
"normalized": false,
|
| 145 |
+
"rstrip": false,
|
| 146 |
+
"single_word": false,
|
| 147 |
+
"special": false
|
| 148 |
+
},
|
| 149 |
+
"151661": {
|
| 150 |
+
"content": "<|fim_suffix|>",
|
| 151 |
+
"lstrip": false,
|
| 152 |
+
"normalized": false,
|
| 153 |
+
"rstrip": false,
|
| 154 |
+
"single_word": false,
|
| 155 |
+
"special": false
|
| 156 |
+
},
|
| 157 |
+
"151662": {
|
| 158 |
+
"content": "<|fim_pad|>",
|
| 159 |
+
"lstrip": false,
|
| 160 |
+
"normalized": false,
|
| 161 |
+
"rstrip": false,
|
| 162 |
+
"single_word": false,
|
| 163 |
+
"special": false
|
| 164 |
+
},
|
| 165 |
+
"151663": {
|
| 166 |
+
"content": "<|repo_name|>",
|
| 167 |
+
"lstrip": false,
|
| 168 |
+
"normalized": false,
|
| 169 |
+
"rstrip": false,
|
| 170 |
+
"single_word": false,
|
| 171 |
+
"special": false
|
| 172 |
+
},
|
| 173 |
+
"151664": {
|
| 174 |
+
"content": "<|file_sep|>",
|
| 175 |
+
"lstrip": false,
|
| 176 |
+
"normalized": false,
|
| 177 |
+
"rstrip": false,
|
| 178 |
+
"single_word": false,
|
| 179 |
+
"special": false
|
| 180 |
+
},
|
| 181 |
+
"151665": {
|
| 182 |
+
"content": "<tool_response>",
|
| 183 |
+
"lstrip": false,
|
| 184 |
+
"normalized": false,
|
| 185 |
+
"rstrip": false,
|
| 186 |
+
"single_word": false,
|
| 187 |
+
"special": false
|
| 188 |
+
},
|
| 189 |
+
"151666": {
|
| 190 |
+
"content": "</tool_response>",
|
| 191 |
+
"lstrip": false,
|
| 192 |
+
"normalized": false,
|
| 193 |
+
"rstrip": false,
|
| 194 |
+
"single_word": false,
|
| 195 |
+
"special": false
|
| 196 |
+
},
|
| 197 |
+
"151667": {
|
| 198 |
+
"content": "<think>",
|
| 199 |
+
"lstrip": false,
|
| 200 |
+
"normalized": false,
|
| 201 |
+
"rstrip": false,
|
| 202 |
+
"single_word": false,
|
| 203 |
+
"special": false
|
| 204 |
+
},
|
| 205 |
+
"151668": {
|
| 206 |
+
"content": "</think>",
|
| 207 |
+
"lstrip": false,
|
| 208 |
+
"normalized": false,
|
| 209 |
+
"rstrip": false,
|
| 210 |
+
"single_word": false,
|
| 211 |
+
"special": false
|
| 212 |
+
}
|
| 213 |
+
},
|
| 214 |
+
"additional_special_tokens": [
|
| 215 |
+
"<|im_start|>",
|
| 216 |
+
"<|im_end|>",
|
| 217 |
+
"<|object_ref_start|>",
|
| 218 |
+
"<|object_ref_end|>",
|
| 219 |
+
"<|box_start|>",
|
| 220 |
+
"<|box_end|>",
|
| 221 |
+
"<|quad_start|>",
|
| 222 |
+
"<|quad_end|>",
|
| 223 |
+
"<|vision_start|>",
|
| 224 |
+
"<|vision_end|>",
|
| 225 |
+
"<|vision_pad|>",
|
| 226 |
+
"<|image_pad|>",
|
| 227 |
+
"<|video_pad|>"
|
| 228 |
+
],
|
| 229 |
+
"bos_token": null,
|
| 230 |
+
"clean_up_tokenization_spaces": false,
|
| 231 |
+
"eos_token": "<|im_end|>",
|
| 232 |
+
"errors": "replace",
|
| 233 |
+
"extra_special_tokens": {},
|
| 234 |
+
"max_length": 32768,
|
| 235 |
+
"model_max_length": 40960,
|
| 236 |
+
"pad_to_multiple_of": null,
|
| 237 |
+
"pad_token": "<|endoftext|>",
|
| 238 |
+
"pad_token_type_id": 0,
|
| 239 |
+
"padding_side": "left",
|
| 240 |
+
"split_special_tokens": false,
|
| 241 |
+
"stride": 0,
|
| 242 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 243 |
+
"truncation_side": "right",
|
| 244 |
+
"truncation_strategy": "longest_first",
|
| 245 |
+
"unk_token": null
|
| 246 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|